目录
一、排序的概念及分类
排序顾名思义就是把一列数据整理成从大到小或从小到大的顺序的过程,就像我们之前接触过的冒泡排序和堆排序。排序在我们日常生活中还是停常用的,就比如现在的双11,你搜索自己想买的物品后就可以让它按价格从大到小排序,方便选购。
我们今天会提到几种常见的排序算法,插入排序(直接插入排序和希尔排序),选择排序(选择排序和堆排序),交换排序(冒泡排序和快速排序),归并排序和计数排序。我们不仅要讨论它们的实现还要讨论它们的时间和空间复杂度还有稳定性。
注意:我们这里实现的排序都按从小到大排序。
二、直接插入排序
直接插入排序就是让一个数组中end+1位置的数据不断与end到0位置的数进行比较,遇到比她小的数就停下插入到那个数前面。我们注意在用代码实现它的时候要先单独把end+1位置的数据储存起来因为在比较的过程中比它大的数要往后挪。如图
// 插入排序
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1;i++)
{
int end = i;
int ret = a[end + 1];
while (end >= 0)
{
if (a[end] > ret)
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = ret;
}
}三、希尔排序
希尔排序是在插入排序的基础上创建的,它的思路是先对数组进行预排序然后再对完整的进行一次排序,就是先把数组按固定的间隔gyp分成多个子数组,分别用直接插入晶须排序优化再逐步缩小间隔重复操作,最终间隔为1时就是插入排序。
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
// +1保证最后一个gap一定是1
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}四、选择排序
选择排序就是在数组中庸两个指针mini和maxi遍历数组找到最大值和最小值放在数组最左和最右两边,然后缩小范围重复操作,知道左边left大于等于右边right结束。相当于每次遍历都确定两个数的位置。
// 选择排序
void SelectSort(int* a, int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int mini = left;
int maxi = left;
for (int i = left; i < right - left + 1; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[left], &a[mini]);
if (maxi == left)
{
maxi = mini;
}
Swap(&a[right], &a[maxi]);
left++;
right--;
}
}五、堆排序
一般升序要建大堆,从非叶子节点开始遍历,向下调整成大堆,然后不断把堆顶的最大值放到最后再通过减小范围把数固定在队尾保护数不再被移动。
// 堆排序
void AdjustDwon(int* a, int n, int root)
{
int child = root * 2 + 1;
while (child < n)
{
if ((child + 1) < n && a[child + 1] > a[child])
{
child++;
}
if (a[child] > a[root])
{
Swap(&a[child], &a[root]);
root = child;
child = root * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
//非叶子
//遍历,调整大堆
for (int i = n / 2 - 1; i >= 0; i--)
{
AdjustDwon(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDwon(a, end, 0);
end--;
}
}六、冒泡排序
冒泡排序是我们很久之前就学习过的排序,它是想法是将数组中的数据从开始的那两个开始不停的将数据两个两个进行比较这样一趟下来最大的那个数就被移到了最后的位置。然后第二趟排序也是一样的操作但不同的是最后一个数(上一趟排好的最大的数)不用参与。这个方法就像是一趟下来确定一个数的位置,然后n-1趟就可以完成排序。
void Swap(int* p, int* q)
{
int tmp = *p;
*p = *q;
*q = tmp;
}
// 冒泡排序
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - i - 1; j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], &a[j + 1]);
}
}
}
}七、快速排序
快速排序有几种思路去实现,hoare,前后指针等
1.hoare
基本的实现思路大家可以看下面的动图
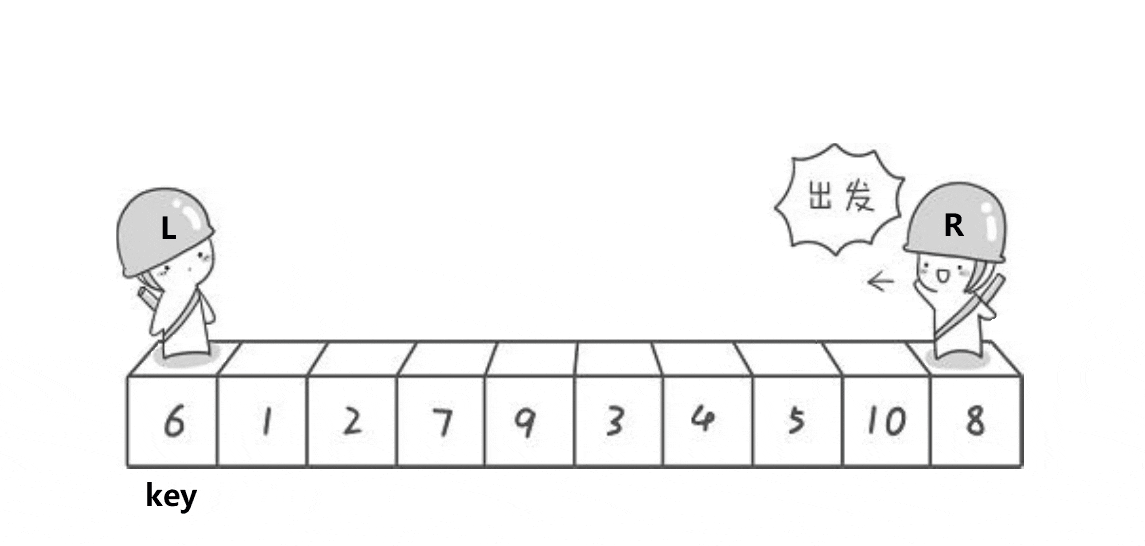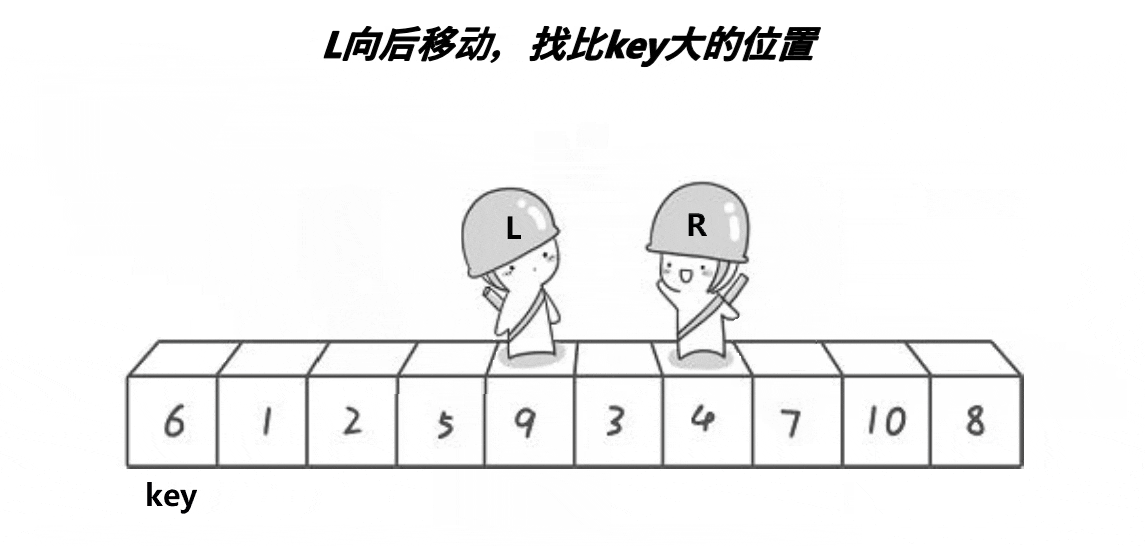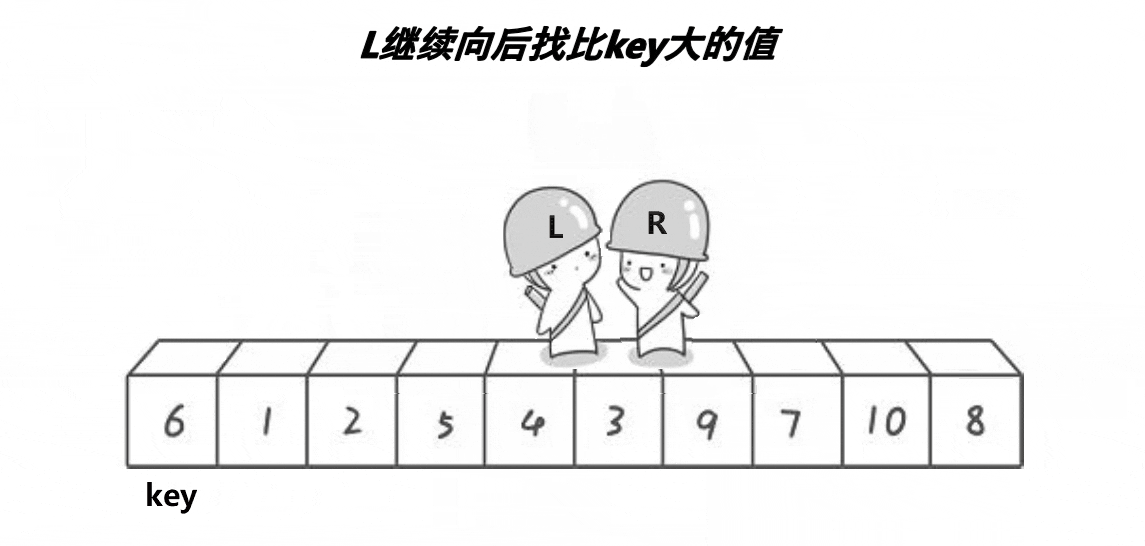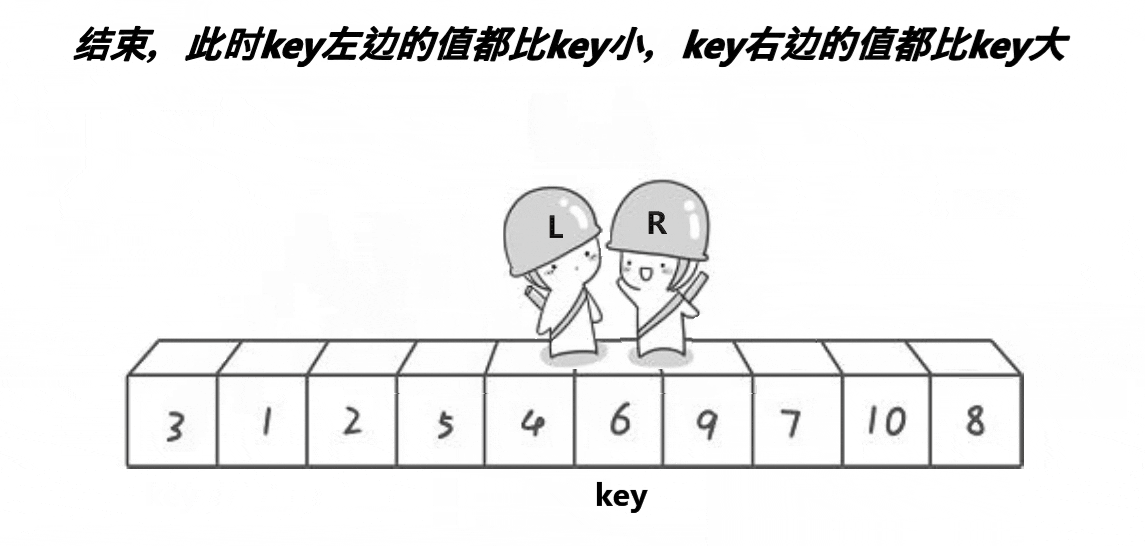
// 快速排序hoare版本
void PartSort1(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int head = left;
int end = right;
int keyi = left;
while (head < end)
{
while (head < end && a[end] >= a[keyi])
{
end--;
}
while (head < end && a[head] <= a[keyi])
{
head++;
}
Swap(&a[head], &a[end]);
}
Swap(&a[head], &a[keyi]);
keyi = head;
PartSort1(a, left, keyi - 1);
PartSort1(a, keyi + 1, right);
}2.前后指针法
基本的实现思路大家可以看下面的动图
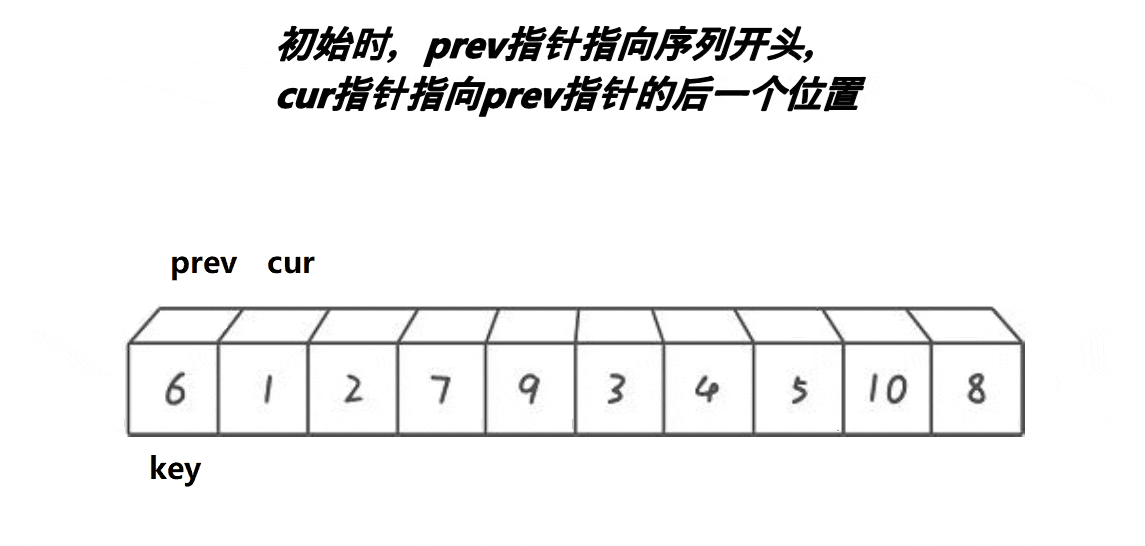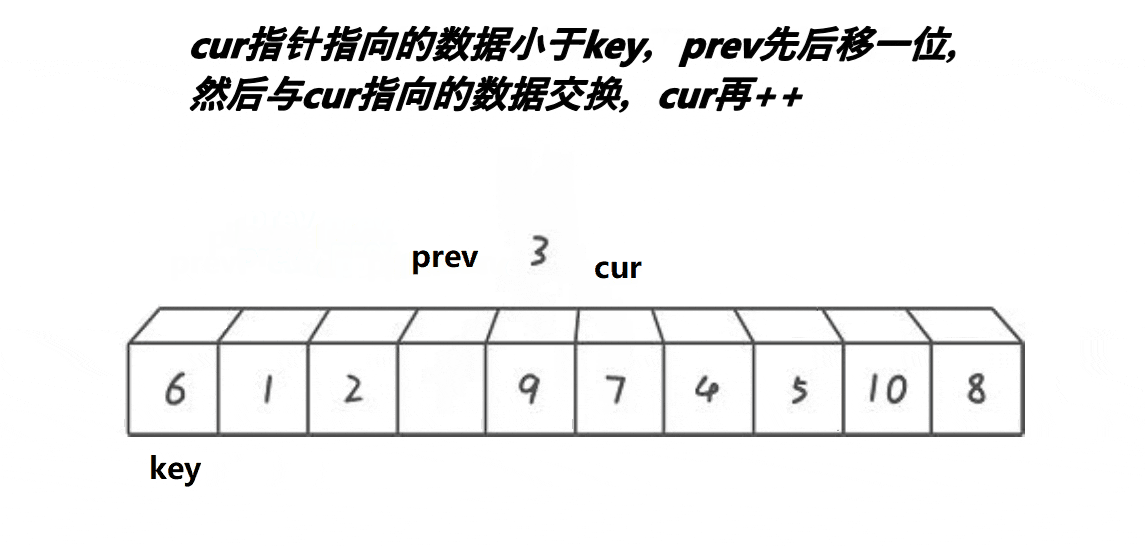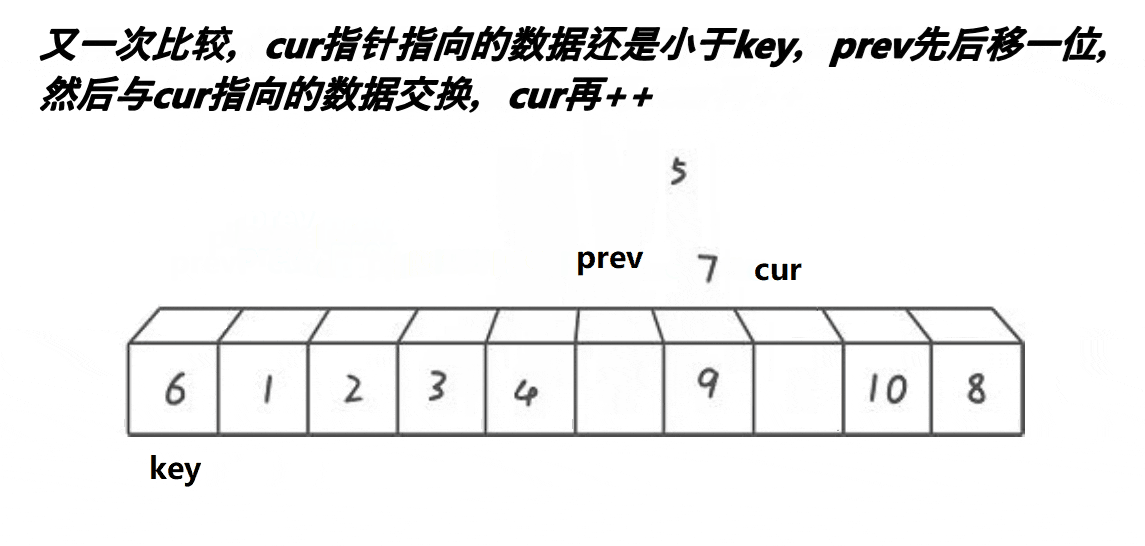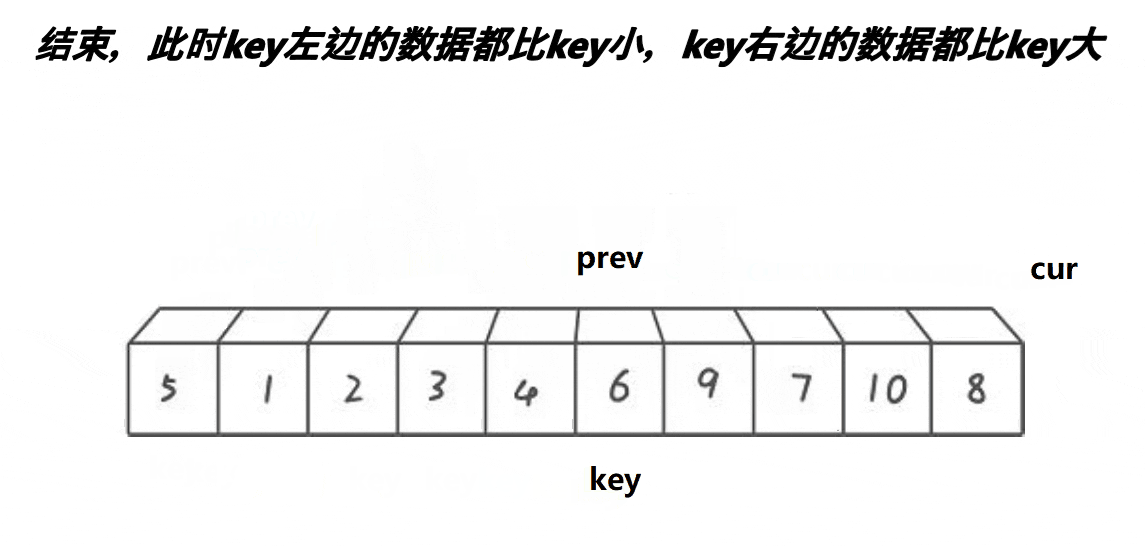
// 快速排序前后指针法
void PartSort3(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = left;
int perv = left;
int pcur = perv + 1;
while (pcur <= right)
{
if (a[pcur] < a[keyi] && ++perv != pcur)
{
Swap(&a[perv], &a[pcur]);
}
pcur++;
}
Swap(&a[perv], &a[keyi]);
keyi = perv;
PartSort3(a, left, keyi - 1);
PartSort3(a, keyi + 1, right);
}3.优化快速排序
我们在思考快速排序的思路时可以去思考排序可能会遇到的情况然后如何去优化排序,使我们的快速排序的运行速度更快。我们一般会进行三数取中和小区间优化方法。
所谓三数取中是从数组的左中右三个位置选取一个中间值作为keyi,降低我们刚刚那种只选择最右边的数作为keyi会遇到极端情况的概率。我们简单画个图就可以看出来这个排序的过程的整理有些像二叉树,极端情况的深度比非极端情况的要深很多,因此我们最好还是要尽力避免。
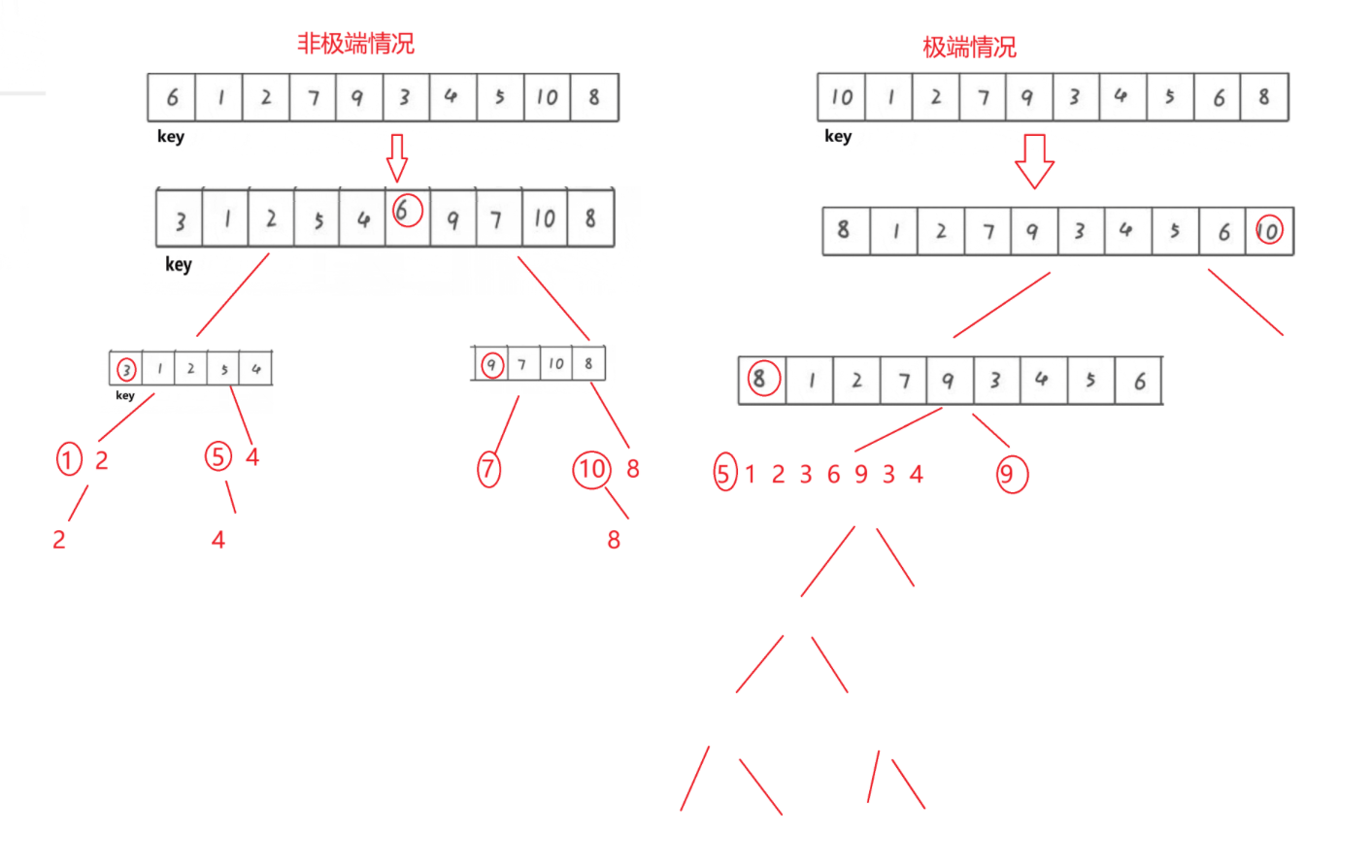
int GetMidi(int* a, int left, int right)
{
int midi = (left + right) / 2;
// left midi right
if (a[left] < a[midi])
{
if (a[midi] < a[right])
{
return midi;
}
else if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
else // a[left] > a[midi]
{
if (a[midi] > a[right])
{
return midi;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
}所谓小区间优化就是在区间的长度小于某个值的时候(比如10)改用插入排序,避免递归造成的开销。我们简单画个图就可以看出来这些小区间的递归还是占据了很大一部分空间。
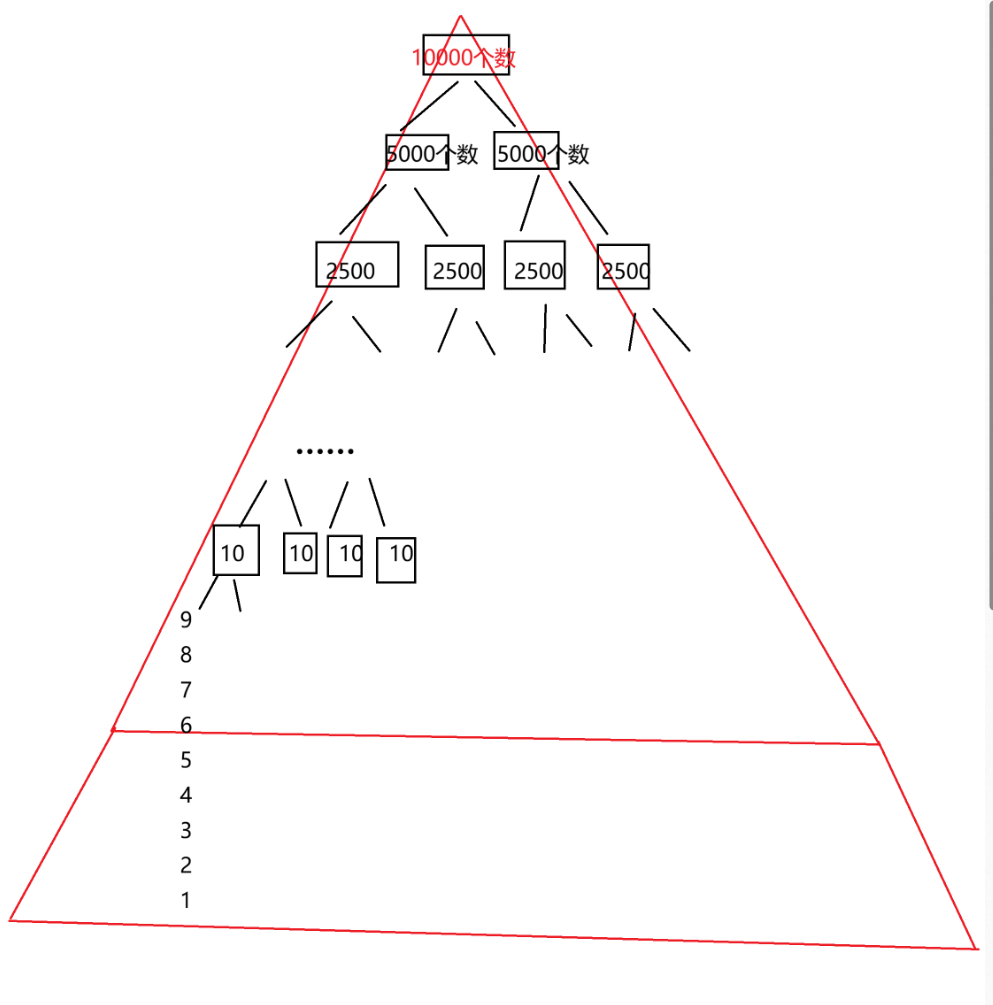
4.非递归实现快速排序
-
用栈存储区间:递归时的左右区间(left, right)用栈保存,每次从栈中取出一个区间处理。
-
划分区间:对取出的区间执行快速排序的划分操作(如前后指针法),得到基准值的最终位置keyi。
-
压入子区间:将划分后的左区间(left, keyi-1)和右区间(keyi+1, right)压入栈(注意:要先压较大的区间,避免栈溢出,也可以随意顺序)。
-
循环直到栈空:重复"取区间→划分→压子区间"的过程,直到栈中无待处理的区间。
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
{
ST sp;
STInit(&sp);STPush(&sp, right); STPush(&sp, left); while (!STEmpty(&sp)) { int left = STTop(&sp); STPop(&sp); int right = STTop(&sp); STPop(&sp); int head = left; int end = right; int keyi = left; while (head < end) { while (head < end && a[end] >= a[keyi]) { end--; } while (head < end && a[head] <= a[keyi]) { head++; } Swap(&a[head], &a[end]); } Swap(&a[head], &a[keyi]); keyi = head; if (keyi + 1 < right) { STPush(&sp, right); STPush(&sp, keyi + 1); } if (left < keyi - 1) { STPush(&sp, keyi - 1); STPush(&sp, left); } } STDestroy(&sp);}
八、归并排序
归并排序的思路是拆分和合并,拆分是将当前数组从中间分为左右两个子数组,递归拆分左、右子数组,直到子数组长度为1,合并要将两个有序的子数组合并为一个有序数组:
• 用一个临时数组存储合并结果;
• 双指针分别遍历两个子数组,每次选较小的元素放入临时数组;
• 处理剩余未遍历完的子数组元素。
void _MergeSort(int* a, int* tmp, int left, int right)
{
if (left >= right)
{
return;
}
int midi = (left + right) / 2;
_MergeSort(a, tmp, left, midi);
_MergeSort(a, tmp, midi + 1, right);
int head1 = left;
int end1 = midi;
int head2 = midi + 1;
int end2 = right;
int i = left;
while (head1 <= end1 && head2 <= end2)
{
if (a[head1] <= a[head2])
{
tmp[i++] = a[head1++];
}
else
{
tmp[i++] = a[head2++];
}
}
while (head1 <= end1)
{
tmp[i++] = a[head1++];
}
while (head2 <= end2)
{
tmp[i++] = a[head2++];
}
memcpy(a + left, tmp + left, (right - left + 1) * sizeof(int));
}
// 归并排序递归实现
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("fail malloc");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}非递归实现归并排序
归并排序的非递归实现,思路是直接按"子数组长度"逐步合并(无需递归拆分):从长度为1的子数组开始,两两合并为长度为2的有序数组;再合并为长度为4的;直到合并出完整的有序数组。但是其中还有一些细节需要特别注意。
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("fail malloc");
return;
}
int gyp = 1;
while (gyp < n)
{
for (int i = 0; i < n; i = i + gyp * 2)
{
int head1 = i;
int end1 = i + gyp - 1;
int head2 = i + gyp;
int end2 = i + 2 * gyp - 1;
int j = i;
if (head2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (head1 <= end1 && head2 <= end2)
{
if (a[head1] <= a[head2])
{
tmp[j++] = a[head1++];
}
else
{
tmp[j++] = a[head2++];
}
}
while (head1 <= end1)
{
tmp[j++] = a[head1++];
}
while (head2 <= end2)
{
tmp[j++] = a[head2++];
}
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}
gyp = gyp * 2;
}
free(tmp);
tmp = NULL;
}九、计数排序
计数排序的思路是
-
找极值:确定数组中最小(min)和最大(max)元素,得到计数范围 max - min + 1;
-
统计次数:用计数数组 count 记录每个元素的出现次数;
-
还原数组:遍历计数数组,按元素出现次数依次将元素放回原数组。
// 计数排序
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] < min)
min = a[i];if (a[i] > max) max = a[i]; } int range = max - min + 1; //printf("%d\n", range); int* count = (int*)calloc(range, sizeof(int)); if (count == NULL) { perror("calloc fail"); return; } // 统计次数 for (int i = 0; i < n; i++) { count[a[i] - min]++; } // 排序 int j = 0; for (int i = 0; i < range; i++) { while (count[i]--) { a[j++] = i + min; } } free(count);}
十、排序的时间和空间复杂度的整理
|------|------------|----------|-----|
| 排序 | 时间复杂度 | 空间复杂度 | 稳定性 |
| 插入排序 | O(n^ 2) | O(1) | 稳定 |
| 希尔排序 | O(n^ 1.3) | O(1) | 不稳定 |
| 选择排序 | O(n^ 2) | O(1) | 不稳定 |
| 堆排序 | O(n*logN) | O(1) | 不稳定 |
| 冒泡排序 | O(n^ 2) | O(1) | 稳定 |
| 快速排序 | O(n*logN) | O(logN) | 不稳定 |
| 归并排序 | O(n*logN) | O(N) | 稳定 |
| 计数排序 | O(n+range) | O(range) | 稳定 |