之前仔细学习过大模型的推理解析,但只是针对通用的早期大模型,并没有针对目前流行的MoE的在模型的推理进行解析。比如:DeepSeek。也就是针对通用的早期Transformer架构进行了学习。
之前讲解推理过程时,也没有针对Prefill和Decode两阶段做详细的解释,今天借着对DeepSeek V3.1的推理解析,深入理解上面的几个问题。因为刚好,DeepSeek对传统架构做了一些优化,
通过这些详细的讲解,也可以进一步理解大模型推理优化的原理。之前我也列出过一篇推理优化的原理文章,可以对照。
一:DeepSeek的优化点
我们之前讲过基于Transformer的Decode架构的推理过程,也讲过针对类似推理的优化原理。我们先来看看,DeepSeek都用了哪些优化的方案。
1.1:架构改造
对于FFN过程进行了优化,从Dense变成Sparse。我们认为Dense就是密集不可分的运算,Sparse就是稀疏可并行的任务。
这其实也算是算法层面的优化。核心思路是我们提供多个专家,每次只激活少量,这样可以减少每次推理所需的计算量和内存带宽,实现更快的推理速度。这其实也降低了超大模型部署的成本。之前我们提到的KTransformer的优化方案也是基于这个。
1.2:KV cache优化
了解 Transformer架构的都清楚,在 Attention 阶段,最重要的就是QKV计算,如何在这里进行优化,是非常关键的。KV cache的优化可以大大降低内存需求,同时也就提升了可支撑的上下文的长度,优化了内存使用效率。
1.3:系统协同优化
DeepSeek把 Prefill / Decode 拆成两个子系统,完成两者的解藕,这两个阶段对硬件资源的要求是不同的,前者偏计算,后者属于对内存有较高要求(为什么?后面会讲)。解藕后可以为他们分配不同的硬件资源进行独立的优化,避免相互干扰,从而同时优化首字延迟和生成token的吞吐量。这是很好的思路。
1.4:大量的工程优化
在架构上变更,还要有一些小的工程改造来配合,DeepSeek为些做了一些小的创新。
如:采用混合精度:FP8 + BF16
FP8可以降低参数占用显存,也可以在相同带宽下吞吐量更高。BF16可以保证运算过程中的更高精度。
如:为MLA 进一步优化 FlashMLA,在SRAM里计算 softmax,在硬件层面优化。
如:Fused MoE kernel,把MoE路由,专家内MLP计算,融合到一个大的kernel.
二:DeepSeek模型介绍:
首先,我们看看整体的推理过程,如下:
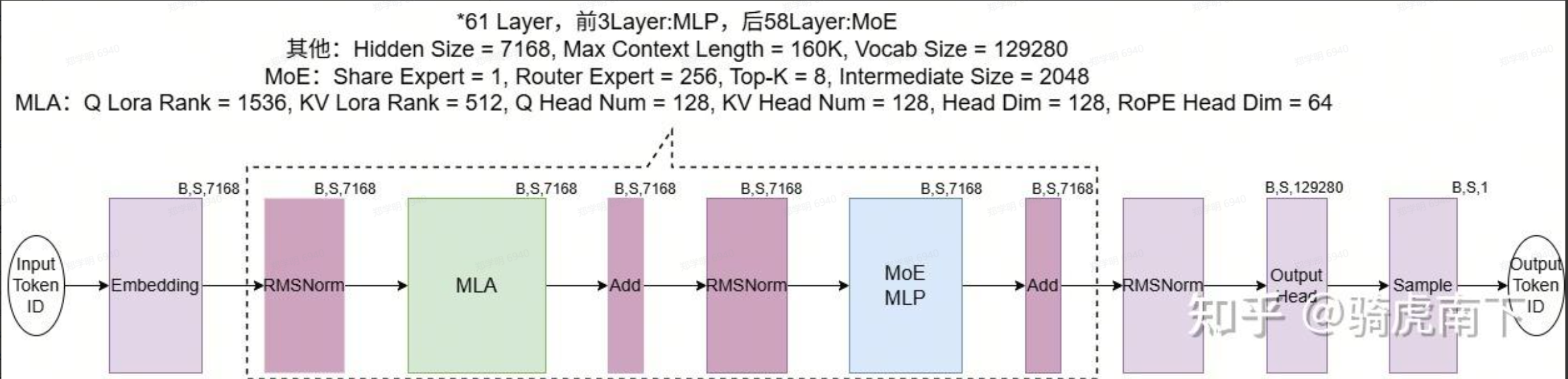
也可以换一个角度来看:
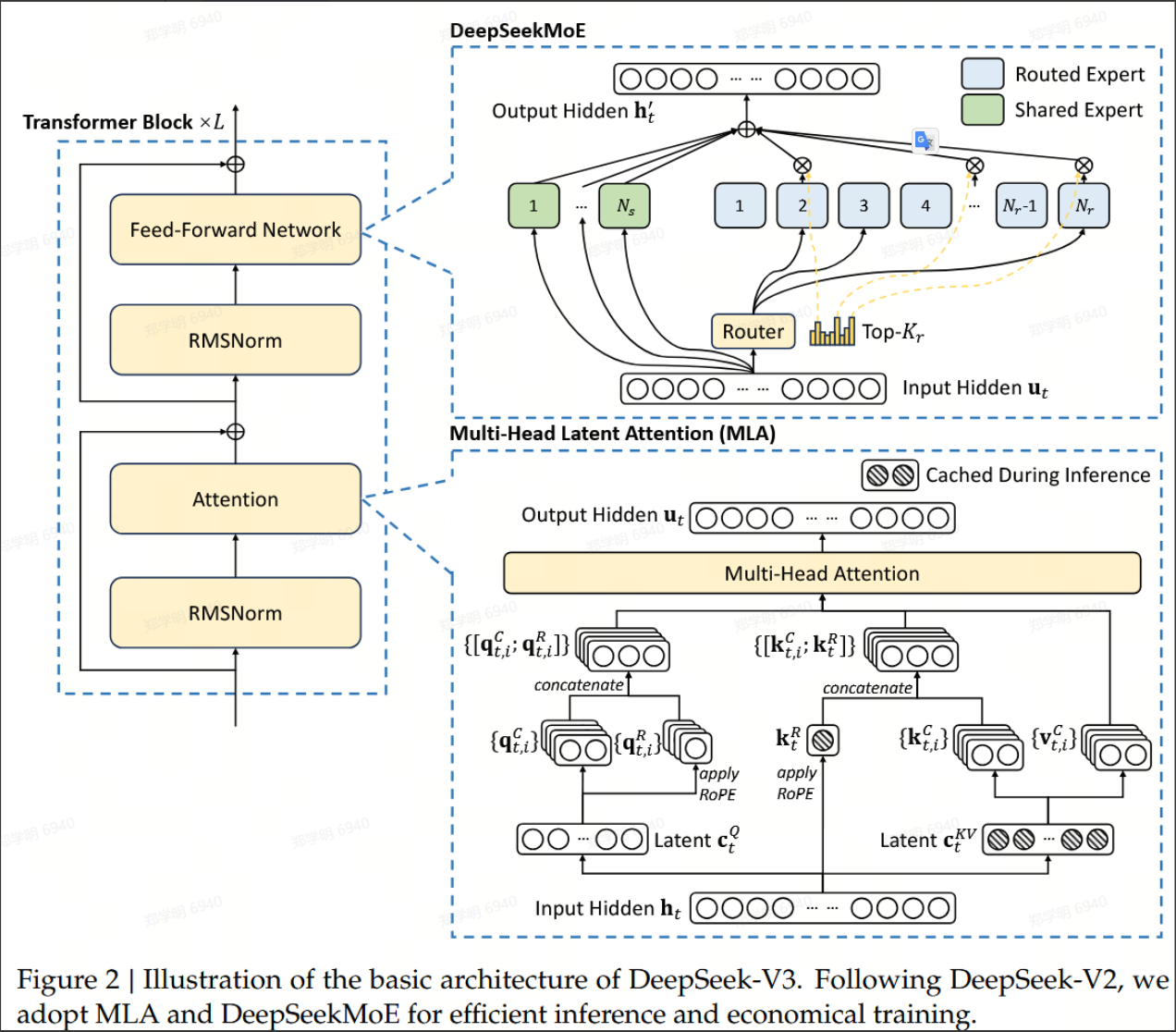
下面,我们再详细的介绍每种优化的细节,结合之前Transformer的理解,就彻底明白DeeepSeek的推理过程了。
三:MLA(Multi-Head Latent Attention)
看一下MLA的整体结构:
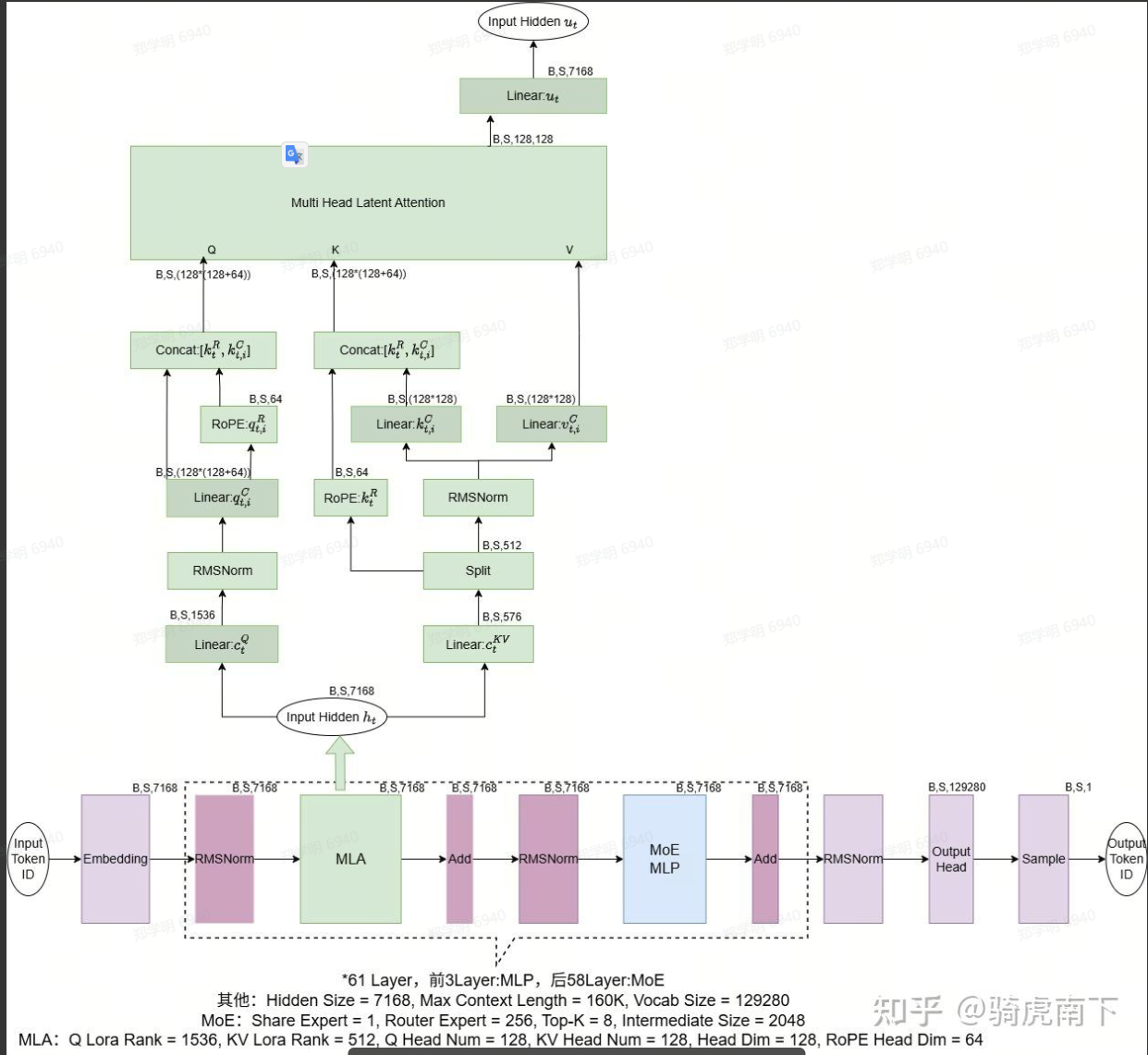
我们再来回顾一下,传统的Attension是要干什么?
简单的理解,就是计算输入token序列中,每个token相对于其它token的关注权重(包括了多种场景),理解为输入的一大串内容构造了一个复杂的场景,我们计算出它们与所有全集token的关联关系,然后到下一步,我们就可以通过训练好的神经网络,预测下一个词了。这里我啰嗦了一下,因为这个概念真的很抽象。
那Attentsion是怎么实现的呢?熟悉的词来了,Q * K * V。大家可以理解,输入token的序列越长,这个运算量肯定就越大。
DeepSeek的处理方案:这是解决长上下文推理内存瓶颈的关键。标准Transformer在生成每个新词元时,都需要读取之前所有词元的键值对(KV缓存),内存消耗巨大。MLA通过一种共享潜在投影的技术,将原本需要为每个注意力头单独存储的庞大 KV 矩阵,压缩为一个小得多的共享表示,从而将KV缓存内存占用降低至传统方法的十分之一以下,让处理超长文本变得可行且高效。
这种机制叫做多头潜在注意力(MLA),Multi-Head Latent Attension。传统的叫做 MHA,Multiple Head Attention。
这个MLA属于压缩技术,解决MHA可能因为长上下文面临KV缓存爆炸的问题。
核心理念是:不直接存储庞大的原始KV矩阵,而是存储一个轻量级的"蓝图",在需要时实时重构出所需的KV信息。也就是节省内存。
MLA核心思路:把所有 head 的 K/V 先压到同一个低维"latent 向量",只缓存这个 latent,真正用时再展开成各个 head 的 K/V。
这里的重在在于生成潜在向量(也就是轻量级的蓝图),也就是延迟计算,它带来的损失不是精度上的,而是计算开销的转移。属于以计算换内存的做法。
更具体一点说一下过程:
对输入 hidden x:
-
先投影到 RoPE 保留的部分 ,算出带位置编码的
q_rope, k_rope; -
再通过一组线性层,把 K/V 低秩联合压缩 到一个共享 latent 空间
z_K, z_V。
-
缓存时,只存
z_K, z_V这套 latent(维度远小于拼在一起的所有 head 的 K/V)。 -
下次 decode 时,需要算注意力:
-
用 per-head 的投影矩阵,把
z_K, z_V展开回每个 head 的 K/V; -
再按普通 attention 流程算
softmax(QK^T)V。
-
这等价于:多做了一些小矩阵乘(解压),换来了 KV cache 大幅缩水。
达到的实际效果惊人:
KV Cache 从 几百K 降到 70 KB。降低约 6 倍。
不但存储降了,当Decode时,获取KV值的长度也减少,效率提升。
不知道明白了没有?如果不知道细节,那就简单理解为,我们把 KV Cache要使用的内存打下来了。
四:MoE (Mixture of Expert)
看一下MoE的结构:
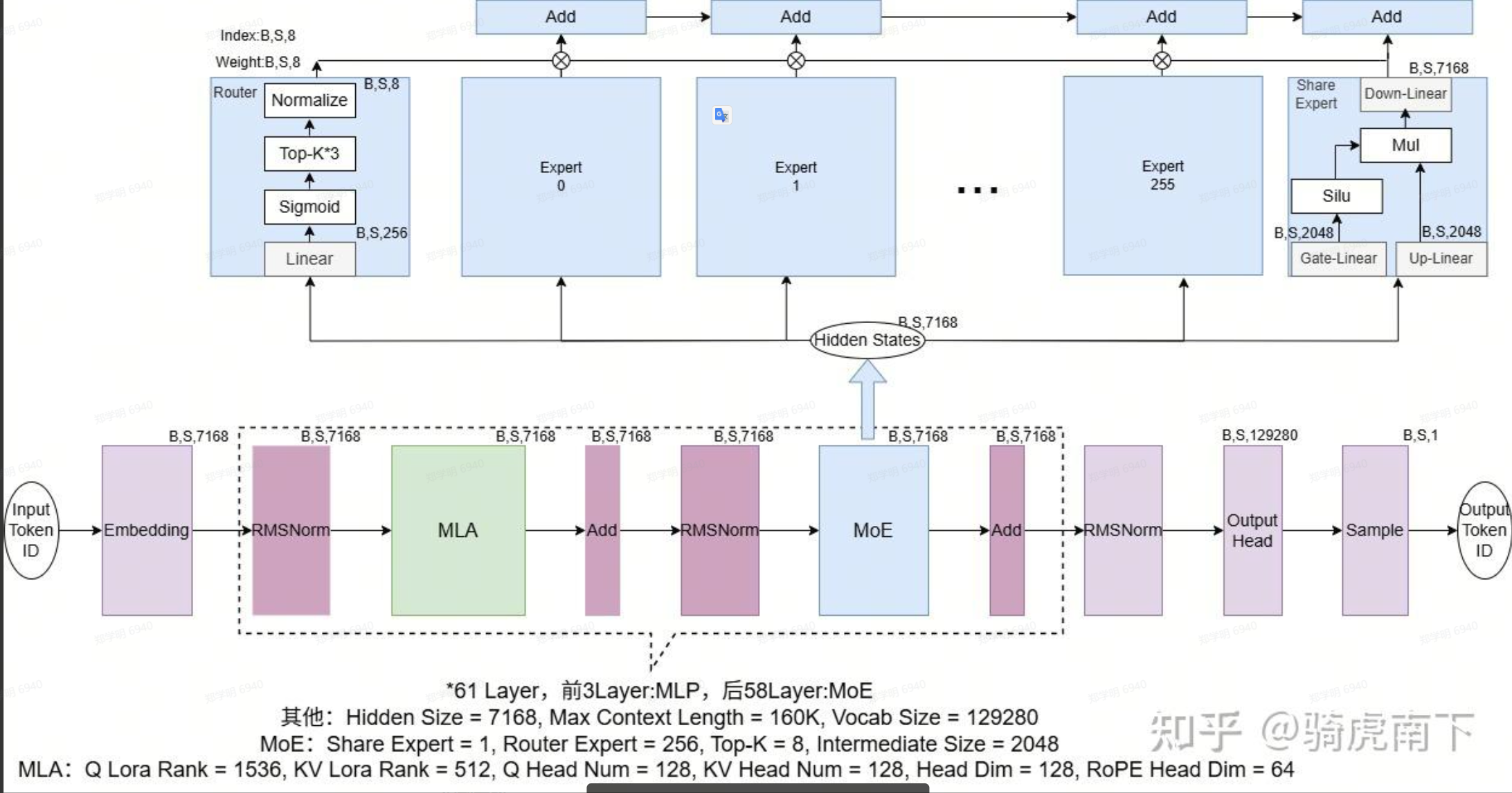
对于FFN,我们一般来说用的就是使用的是多层感知机(MLP Multi-Layer Perceptron),这是标准的神经网络的做法,对于传统的Transformer,每个block也就是一个大的MLP,在输入token时,都进入这个全模型的MLP,全参数一起运算。按理,这个参数会非常的大,对于上千亿参数的模型,这里差不多就是几百B的规模,这里会有大量的FLPs消耗,属于非稀疏的运算。
MLP的网络结构,我们这里就不讲了,和之前Transformer中的基本是一致的。
对于DeepSeek采用了MoE架构:
1个共享专家:所有token都会通过,负责公共知识(语法,常见词等)。
256个路由专家:按token的不同内容先路由,每个专家负责不同的领域(代码,数学,不同领域)。
对于每个token的处理:
在Router,通过Gete网络选出 Top-8 routed expoerts;
加上共享专家。
对计算的结果进行加权求和,综合打分。
以DeepSeek 671B 模型为例,每个token激活的参数:约 37B。
同样的"模型容量(671B)",但 每个 token 只算 37B 这部分,相当于用 稀疏计算 换了大容量。
这么做的价值很大:
1: token计算量降低了一个数量级。质量差不多。
2:256个专家可以切到不同算力芯片,容易做到并行运算。
3:质量并没有下降,因为Shared expert保证了知识一致性,Routed experts 负责各自领域 的"细瘦身",再加上 DeepSeek 的Multi-Tolen Prediction的训练目标,整体性能不差。
注意一下:
DeepSeek在做整体运算的时候有 61层,前3层的实际上并没有使用MoE,其实是使用的是 Dense MLP,后面的58层才是使用的 MoE-FFN。也就前三层,你可以认为没有专家,在做一些通识的判断。
这么做是为啥呢?
可以简单的理解为:先用 大宽度 Dense MLP 给所有 token 打一个统一、稳定的 high-level 表示,再交给 MoE 去做"细分",这样细分时更加精准。
也补看一下MLP模块

五:Prefill / Decode
将Prefill 和 Decode 两阶段分开,优势明显。
Prefill 阶段强调高吞吐,可以把多个Request的Prefill 变成比较大的Micro-batch,把MoE的 all-to-all 和其它计算重叠起来。
Decode 阶段强调低延迟,多并发,它对时间比较敏感 。
简单总结就是:
Prefill:短、重;Decode:长、细。
-
Prefill 一次性处理整段 prompt,FLOPs 很多但时间较短;
-
Decode 每次只处理 1 token,但要持续很久、要接很多 request。
把两者拆成不同实例:
-
可以对 Prefill 做「高吞吐调度」,对 Decode 做「低延迟调度」;
-
故障、扩缩容也可以分开处理,更容易运营大集群。
六:FP8 / BF16 + FlashMLA / Fused MoE
5.1:混合精度
最后我们再看一下什么是 FP8/BF16 混用,有什么作用?
FP8 是 8 bit 浮点数格式,现在主流有两种编码:E4M3,ESM2:NVIDIA制定的标准。BF16 是 Google主推的格式,它的范围大,但精度低,适合训练使用,不容易爆掉。
显然,FP8比传统的 FP16 更省空间,模型体积更小,短阵吞吐更高,KV更小。在训练时,一般是 采用 FP8 + FP16/BF16 混 合精度,这样稳定性更高;
在推理时,权重使用FP8,计算时可以提升到BF16 / FP16 /FP32。这样可以兼顾存储和运算的效率。
在推理场景里,你可以理解为:
权重:尽可能 FP8;
中间激活 / KV cache / 累加:BF16 为主(少量关键地方 FP32)。
5.2:FlashMLA
在解码阶段算力还行,但是当长上下文时,每一步都要去遍历历史KV,这时内存访问带宽成为很大的问题:
FlashMLA 做的事:
-
像 FlashAttention 一样 tile 到 SRAM / register,避免重复读写 HBM
-
不显式构造完整注意力矩阵;
-
分块加载 latent-K/V(已经是压缩形式)到片上,对当前 token 逐块 accumulate。
-
-
专门为解码优化:变长 batch / paged KV
-
支持 paged KV cache(block size 64) + variable-length 序列;
-
推理引擎(SGLang, vLLM)在调度时可以对不同请求的 prefix 做共享 / 合并,FlashMLA 内核能高效处理这些 "ragged batch"。
-
-
精度 & 格式友好:BF16 / FP8 友好设计
-
内核支持 BF16;
-
与 DeepSeek 的 Quant 方案(latent/indexer key vector quantization 等)配合,使得 FP8/BF16 混合推理成为可能。
-
对 decode 阶段:
• 注意力这块从 "强烈带宽受限"→"接近硬件极限 IO + 足够算力";
• 具体公开数据里,H800 上可以做到 ~3000 GB/s 内存流水线、百 TFLOPs 级别算力利用。
对 prefill 阶段:
• 一般仍然使用 FlashAttention / MLA 的"naive kernel",prefill 通常更偏 compute-bound;
• FlashMLA 的设计重点就是 decode,prefill 只是"正常快"而不是"变态快"。
5.3:Fused MoE
fused 融合的意思,核心思想是将 一些运算融合到一个或更少的kernel里执行。
MoE推理时,有几类开销:
1: 路由,排序,gather/scatter 本身的内存读写。
2:分散的运算任务,很难把GPU的 tensor core吃满。
3:如果是多卡,会存在通讯搬运。
Fused MoE 做的事:
把多个步骤融合到一个"长生命"kernel 里
在单个 kernel 内完成:
-
gate 计算 → top-k;
-
sort / align / index 计算;
-
把 token 搬到专家输入 buffer(在 shared memory / register 中完成);
-
调用 grouped GEMM 做多专家 MLP;
-
最后在 epilogue 中做 scaling + scatterAdd 回原序列位置。
-
类似 FlashMoE 那种"一核到底"的实现甚至可以把"多次 kernel launch"降到一次。
利用 grouped GEMM,提升小 batch 专家的利用率
-
多个 expert 的 weight 做一个大 block,输入按"专家×token"排成大矩阵;
-
对硬件来说就是一个大 GEMM,更容易跑满 Tensor Core / 矢量单元。
跨卡通信的优化(有些实现)
-
在 EP 模式下,部分实现会把 All-to-All 和 GEMM 的一部分融合,
或至少尽量 overlap 通信和计算(比如 GEMM-ReduceScatter / AllGather-GEMM 风格)。
延迟 :减少 kernel 数量 + 减少中间 tensor 写回 HBM,
单层 MoE 的 token latency 显著下降;
吞吐:更高的 expert GEMM 利用率 → 同样硬件下可支持更大 MoE 模型或更大 batch;
多卡扩展性:通信与计算更好地重叠,8/16/32 卡 EP 时扩展曲线更平滑。
七:参数规模
最后我们来看一下主要的性能参数和相应的组成。
讨论性能之前,我们来看一下DeepSeek的参数的组成:
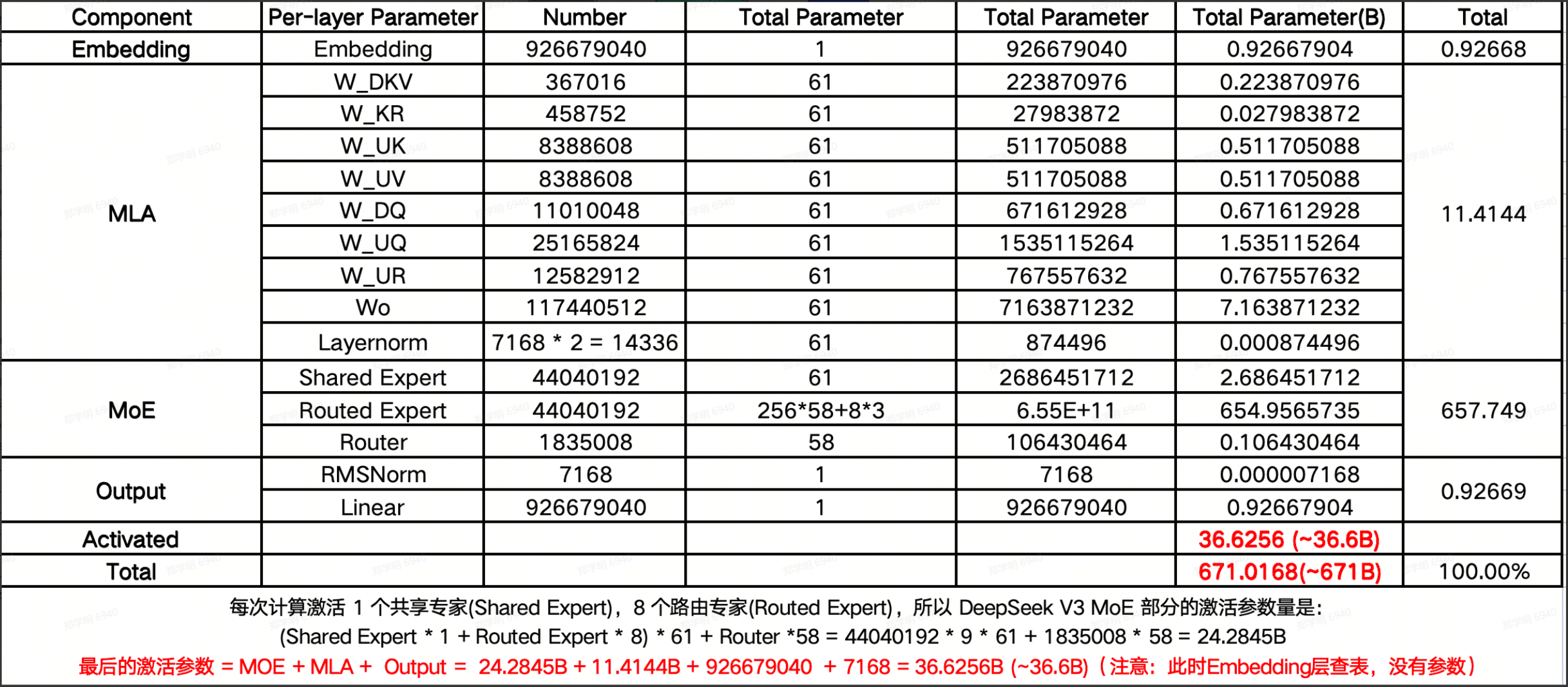

八:推理性能
我们主要考虑的性能是:
Prefill:首字延迟
Decode:token/s
当然,对于Prefill 受很大影响的是上下文的长度,一般会有 256,1 K,8K延迟的说法。另外,在吐出token时,也部分受上下文的影响。
另外,也要考虑支持的并发数,在有并发的情况下,两个参数性能自然会下降。
如果模型有量化版本,不同量化版本的性能差异也会比较大。
具体的计算,实际上和我们采用算力芯片的运算能力,访问内存的速度/带宽有较大的关系,如果存在跨算力卡的情况,那还和卡间的通讯带宽有较大关系。
我们一般了解到的业界最强的英伟达GPU,它强在哪里?
1:它的算力最强,这个是先发优势,其它厂商都是追赶。一些数据格式和算法都是NVIDIA在定义。
2:它有HBM技术,内存访问最强,可以获得最大的内存访问带宽。
3:它有NVLink网络技术,多卡的集群通讯很强。
我们这里不说它的生态,因为这和覆盖率有关,还是性能层面的问题。我们也可以通过今天对DeepSeek的分析看得出,DeepSeek实际上还是在工程层面做了一些微创新。(MoE并不是DeepSeek发明的)。
如果我们要实际计算性能,那就按照推理的过程,按照数据流经过的硬件,再考虑并行的相互影响,可以推导出相应的性能。而推导性能的过程中,自然也会思考性能可能的优化点。
以后有时间,找一个硬件产品+推理引擎来推导一下性能。