第四章深度解析:智能体经典范式实战指南------从ReAct到Reflection的全流程拆解
第四章作为Hello-Agents的"实战核心篇",跳出了纯理论框架,聚焦三大智能体经典范式------ReAct、Plan-and-Solve、Reflection的落地实现。本章通过"原理+代码+实战"的模式,揭示了智能体"思考-行动-优化"的底层逻辑,是从"理解智能体"到"构建智能体"的关键过渡。本文将从范式本质、公式拆解、代码解析、习题全解四个维度,带大家吃透每个范式的设计思想与工程实现,掌握智能体核心架构的搭建能力。
一、核心范式本质:三种智能体的决策逻辑差异
第四章的核心是"不同任务场景下的智能体决策模式选择",三个范式分别对应"动态探索""结构化执行""迭代优化"三类核心需求,其本质差异在于"思考与行动的组织方式":
| 范式 | 核心逻辑 | 核心优势 | 适用场景 |
|---|---|---|---|
| ReAct | 思考→行动→观察→循环 | 动态适配环境,容错性强 | 需外部工具(搜索、API)、不确定性任务 |
| Plan-and-Solve | 规划→执行(分步骤) | 逻辑清晰,稳定性高 | 结构化任务、多步推理(数学题、流程化任务) |
| Reflection | 执行→反思→优化→迭代 | 结果质量高,自我纠错 | 高要求任务(代码生成、学术写作)、需精准输出 |
1.1 范式核心思想速览
- ReAct:像侦探查案------根据现场线索(观察)动态调整调查方向(思考),每一步行动都依赖上一步的反馈,边做边调整。
- Plan-and-Solve:像建筑师建房------先画完整蓝图(规划),再严格按图纸施工(执行),不轻易偏离预设步骤。
- Reflection:像作家改稿------先写初稿(执行),再自我审阅(反思),根据问题优化(优化),反复迭代直到满意。
二、公式深度解析:范式的形式化表达与通俗解读
第四章对三个范式的核心流程进行了形式化定义,以下结合具体场景拆解公式,让每个符号都清晰易懂。
2.1 ReAct范式的形式化表达
ReAct的核心是"基于历史轨迹的动态决策",其形式化公式为:
( t h t , a t ) = π ( q , ( a 1 , o 1 ) , . . . , ( a t − 1 , o t − 1 ) ) \left(th_{t}, a_{t}\right)=\pi\left(q,\left(a_{1}, o_{1}\right), ...,\left(a_{t-1}, o_{t-1}\right)\right) (tht,at)=π(q,(a1,o1),...,(at−1,ot−1))
o t = T ( a t ) o_{t}=T\left(a_{t}\right) ot=T(at)
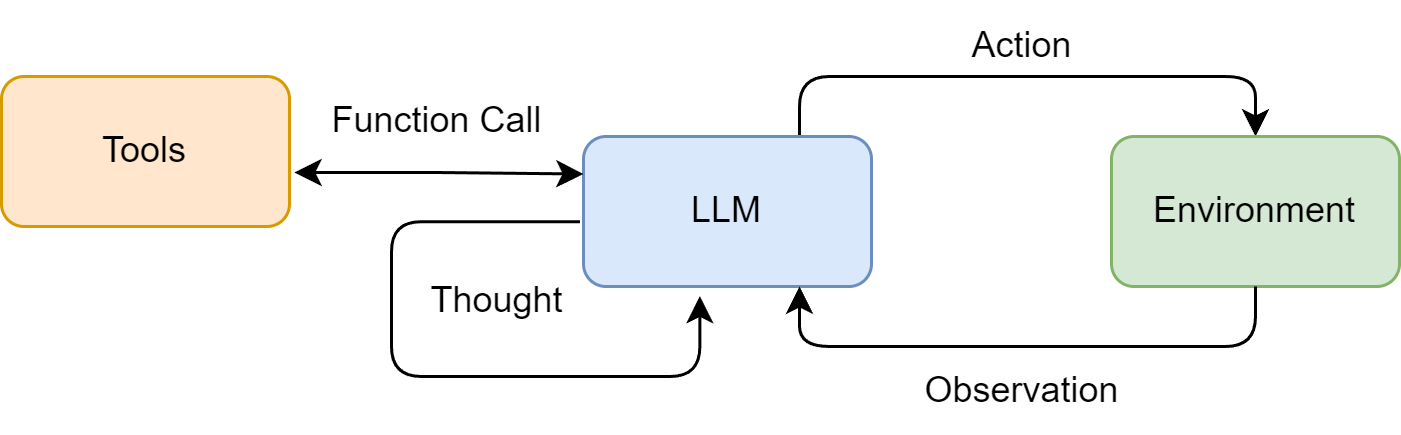
公式拆解
-
符号含义:
- t h t th_t tht:第t步的思考过程(Thought),比如"需要搜索华为最新手机型号";
- a t a_t at:第t步的行动(Action),比如"调用Search工具查询";
- π \pi π:大语言模型的决策策略(LLM的推理逻辑);
- q q q:用户的原始问题(Question),比如"华为最新手机是什么?卖点是什么?";
- ( a 1 , o 1 ) , . . . , ( a t − 1 , o t − 1 ) (a_1,o_1),...,(a_{t-1},o_{t-1}) (a1,o1),...,(at−1,ot−1):历史行动-观察轨迹,比如"上一步调用了Search,观察到Mate 70和Pura 80 Pro+两款机型";
- T T T:工具执行函数(Tool),比如SerpApi的搜索功能;
- o t o_t ot:行动后的观察结果(Observation),比如搜索返回的机型参数和卖点。
-
推导过程:
- 第一步:智能体接收原始问题q,结合历史轨迹(若有),通过LLM策略π生成当前思考th_t和行动a_t;
- 第二步:工具T执行行动a_t,返回观察结果o_t;
- 第三步:将(a_t,o_t)加入历史轨迹,进入下一轮循环,直到生成最终答案。
-
通俗示例:
- q:"华为最新手机是什么?卖点是什么?"
- t=1:π(LLM)分析"需要实时信息,调用搜索工具"→th₁="需搜索华为最新机型及卖点",a₁=Search华为最新手机型号及卖点;
- o₁="华为最新机型为Mate 70和Pura 80 Pro+,Mate 70主打全焦段摄影和抗摔,Pura 80 Pro+强调先锋影像";
- t=2:π结合历史轨迹(a₁,o₁)→th₂="已获取足够信息,可总结答案",a₂=Finish最终答案。
2.2 Plan-and-Solve范式的形式化表达
Plan-and-Solve的核心是"两阶段分离",公式分为规划阶段和执行阶段:
P = π p l a n ( q ) P=\pi_{plan}(q) P=πplan(q)
s i = π s o l v e ( q , P , ( s 1 , . . . , s i − 1 ) ) s_{i}=\pi_{solve}\left(q, P,\left(s_{1}, ..., s_{i-1}\right)\right) si=πsolve(q,P,(s1,...,si−1))
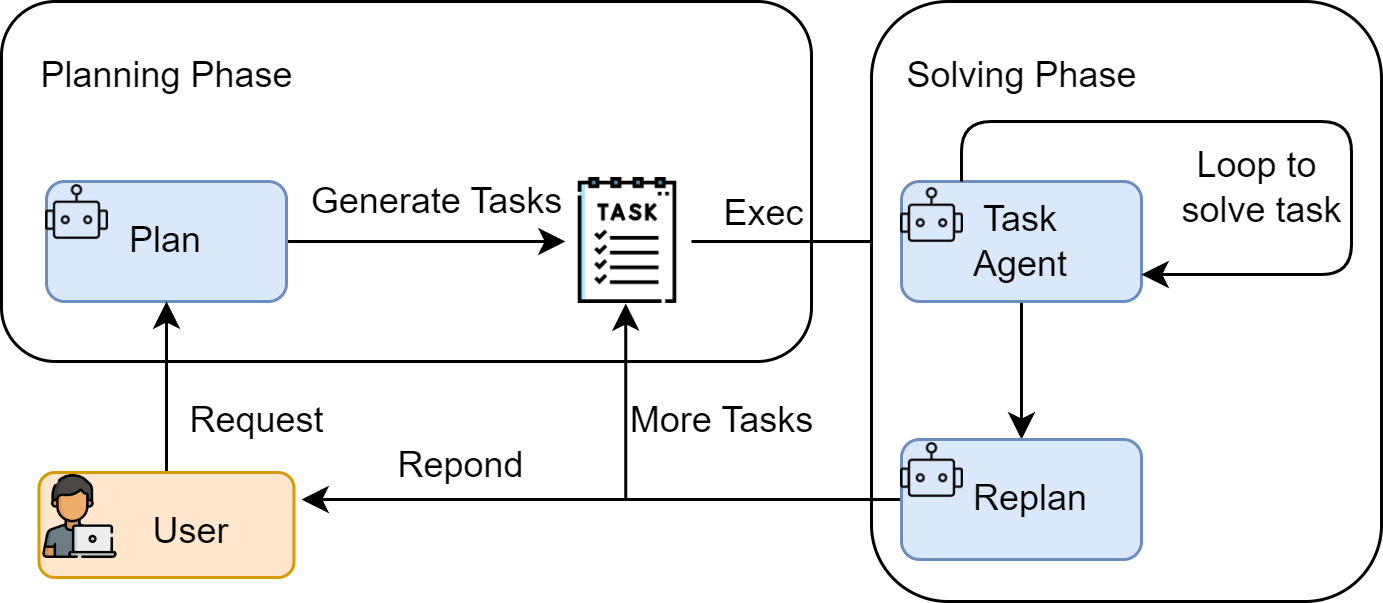
公式拆解
-
符号含义:
- P P P:生成的行动计划(Plan),是包含n个步骤的列表,比如"计算周二销量→计算周三销量→计算总销量";
- π p l a n \pi_{plan} πplan:规划策略(LLM的任务分解能力);
- s i s_i si:第i步的执行结果(Solve Result),比如"周二销量30个";
- π s o l v e \pi_{solve} πsolve:执行策略(LLM的步骤求解能力);
- ( s 1 , . . . , s i − 1 ) (s_1,...,s_{i-1}) (s1,...,si−1):前i-步的执行结果,比如"周一销量15个,周二销量30个"。
-
推导过程:
- 规划阶段:LLM通过π_plan解析原始问题q,分解为有序的步骤列表P;
- 执行阶段:按步骤迭代,每一步通过π_solve结合q、P和历史执行结果,求解当前步骤s_i;
- 最终答案为最后一步的执行结果s_n。
-
通俗示例:
- q:"周一卖15个苹果,周二是周一的2倍,周三比周二少5个,三天共卖多少?"
- 规划阶段:π_plan(q)→P="计算周二销量:15×2","计算周三销量:周二销量-5","计算总销量:15+周二+周三";
- 执行阶段i=1:π_solve(q,P,\[\])→s₁=30;
- i=2:π_solve(q,P,30)→s₂=25;
- i=3:π_solve(q,P,30,25)→s₃=70;
- 最终答案:70。
2.3 Reflection范式的形式化表达
Reflection的核心是"迭代优化",公式为迭代循环:
F i = π r e f l e c t ( T a s k , O i ) F_{i}=\pi_{reflect}\left(Task, O_{i}\right) Fi=πreflect(Task,Oi)
O i + 1 = π r e f i n e ( T a s k , O i , F i ) O_{i+1}=\pi_{refine}\left(Task, O_{i}, F_{i}\right) Oi+1=πrefine(Task,Oi,Fi)
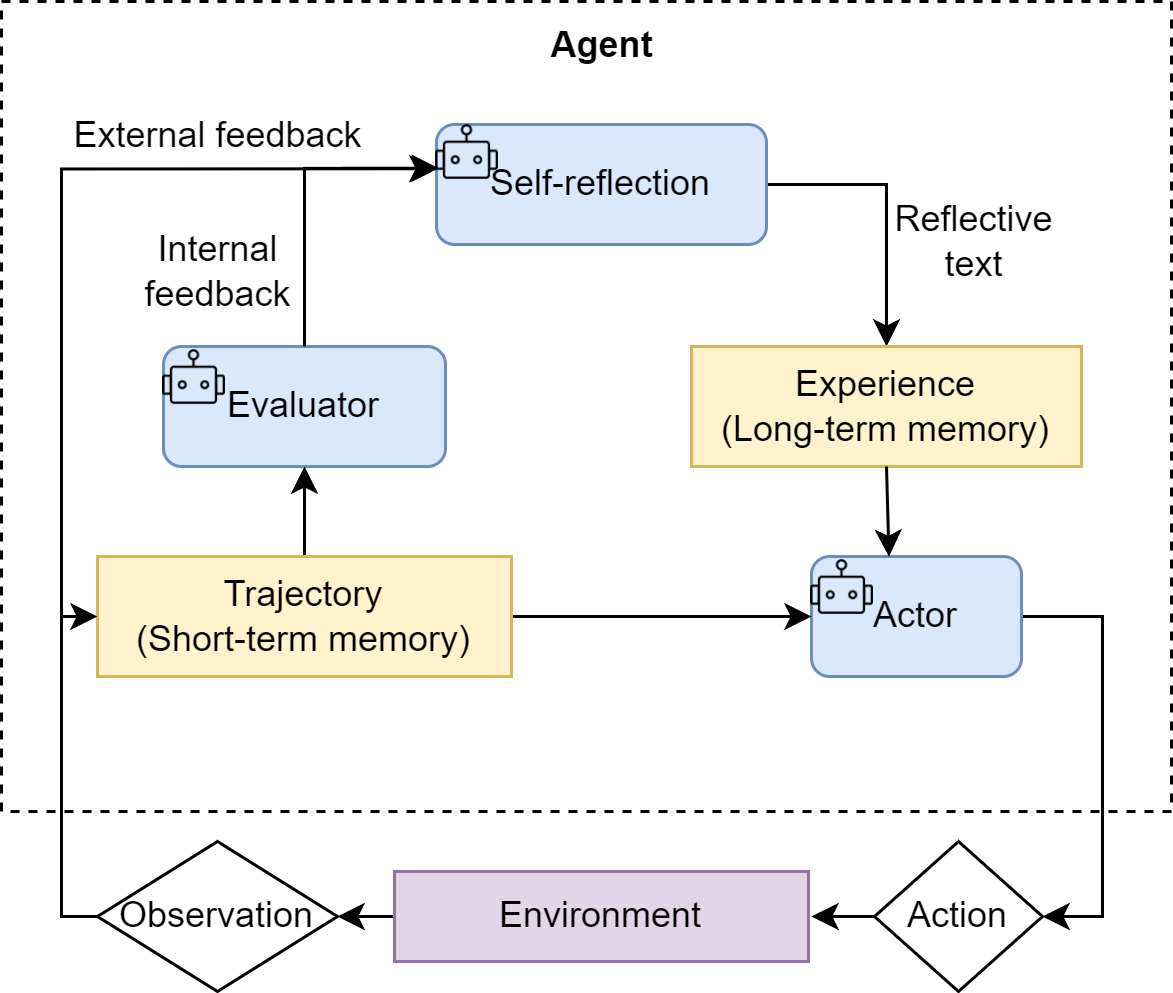
公式拆解
-
符号含义:
- O i O_i Oi:第i轮的执行结果(Output),比如"初始版素数查找代码";
- F i F_i Fi:第i轮的反思反馈(Feedback),比如"当前代码时间复杂度O(n√n),可优化为筛法O(n log log n)";
- π r e f l e c t \pi_{reflect} πreflect:反思策略(LLM的批判分析能力);
- π r e f i n e \pi_{refine} πrefine:优化策略(LLM的代码改进能力);
- T a s k Task Task:原始任务,比如"编写1到n的素数查找函数"。
-
推导过程:
- 初始执行:生成第0轮结果O₀(如试除法代码);
- 迭代循环:
- 反思:π_reflect分析O_i,生成反馈F_i;
- 优化:π_refine结合Task、O_i和F_i,生成优化后的O_{i+1};
- 终止条件:F_i包含"无需改进"或达到最大迭代次数,最终结果为O_i。
-
通俗示例:
- Task:"编写查找1到n素数的Python函数";
- O₀:试除法代码(时间复杂度O(n√n));
- F₀:"当前用试除法,每个数需验证到√n,效率低;建议用埃拉托斯特尼筛法,通过标记倍数筛选素数";
- O₁:筛法代码(时间复杂度O(n log log n));
- F₁:"筛法已最优,无需改进";
- 最终结果:O₁(筛法代码)。
三、代码深度拆解:从LLM客户端到三大范式实现
第四章的代码核心是"模块化封装",先封装通用LLM客户端,再基于客户端实现三个范式。以下按书本行文思路,拆解每个代码模块的功能与逻辑。
3.1 基础封装:llm_client.py(通用LLM客户端)
核心作用:封装OpenAI兼容接口,支持流式响应,统一处理环境变量、异常捕获,为后续范式提供通用LLM调用能力。
python
class HelloAgentsLLM:
def __init__(self, model: str = None, apikey: str = None, baseUrl: str = None, timeout: int = None):
# 优先级:传入参数 > 环境变量,确保配置灵活
self.model = model or os.getenv("LLM_MODEL_ID")
apikey = apikey or os.getenv("LLM_API_KEY")
baseUrl = baseUrl or os.getenv("LLM_BASE_URL")
timeout = timeout or os.getenv("LLM_TIMEOUT", 60)
# 校验核心配置,缺失则抛出异常
if not all([self.model, apikey, baseUrl]):
raise ValueError("模型ID、API密钥和服务地址必须提供")
# 初始化OpenAI客户端
self.client = OpenAI(api_key=apikey, base_url=baseUrl, timeout=timeout)
def think(self, messages: List[Dict[str, str]], temperature: float = 0) -> str:
"""核心方法:调用LLM,返回流式响应拼接结果"""
print(f"🧠 正在调用 {self.model} 模型...")
try:
# 发起流式请求(stream=True)
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature, # 0表示确定性输出,适合推理任务
stream=True
)
collected_content = []
# 流式处理:逐块接收并打印,避免等待全量响应
for chunk in response:
content = chunk.choices[0].delta.content or "" # 处理空内容
print(content, end="", flush=True)
collected_content.append(content)
print()
return "".join(collected_content)
except Exception as e:
print(f"❌ 调用LLM错误: {e}")
return None关键逻辑解析
- 初始化逻辑:支持传入参数或从.env文件加载配置,灵活适配不同部署场景(本地、云端);
- 流式响应 :通过
stream=True实现逐块接收响应,提升用户体验,避免长文本等待; - 异常处理:捕获API调用异常,返回None并打印错误信息,保证后续流程容错;
- 温度参数 :默认
temperature=0,生成确定性结果,适合需要精准推理的任务(如数学计算、代码生成)。
3.2 范式一:ReAct(动态探索型智能体)
核心目标:实现"思考-行动-观察"循环,支持调用外部工具(如搜索引擎),处理不确定性任务。
3.2.1 工具层:ToolExecutor(工具管理)
python
class ToolExecutor:
def __init__(self):
self.tools: Dict[str, Dict[str, any]] = {} # 存储工具:{工具名: {"description": 描述, "func": 函数}}
def registerTool(self, name: str, description: str, func: callable):
"""注册工具:为智能体提供可调用的工具列表"""
if name in self.tools:
print(f"警告:工具 '{name}' 已存在,将被覆盖")
self.tools[name] = {"description": description, "func": func}
print(f"✅ 工具 '{name}' 注册成功")
def getTool(self, name: str) -> callable:
"""根据名称获取工具函数"""
return self.tools.get(name, {}).get("func")
def getAvailableTools(self) -> str:
"""格式化工具描述,用于提示词(让LLM知道可用工具)"""
return "\n".join([f"- {name}: {info['description']}" for name, info in self.tools.items()])3.2.2 核心层:ReActAgent(智能体逻辑)
python
class ReActAgent:
def __init__(self, llm_client: HelloAgentsLLM, tool_executor: ToolExecutor, max_steps: int = 5):
self.llm_client = llm_client # LLM客户端
self.tool_executor = tool_executor # 工具执行器
self.max_steps = max_steps # 最大步数(防止无限循环)
self.history = [] # 存储历史轨迹:Action + Observation
def run(self, question: str):
self.history = []
current_step = 0
while current_step < self.max_steps:
current_step += 1
print(f"--- 第 {current_step} 步 ---")
# 1. 格式化提示词:包含工具、问题、历史轨迹
tools_desc = self.tool_executor.getAvailableTools()
history_str = "\n".join(self.history)
prompt = REACT_PROMPT_TEMPLATE.format(
tools=tools_desc, question=question, history=history_str
)
# 2. 调用LLM生成思考和行动
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages)
if not response_text:
print("错误:LLM无有效响应")
break
# 3. 解析LLM输出:提取Thought和Action
thought, action = self._parse_output(response_text)
if thought: print(f"🤔 思考: {thought}")
if not action:
print("警告:未解析出有效Action")
break
# 4. 执行Action:Finish或工具调用
if action.startswith("Finish"):
final_answer = re.match(r"Finish\[(.*)\]", action).group(1)
print(f"🎉 最终答案: {final_answer}")
return final_answer
# 解析工具名称和输入
tool_name, tool_input = self._parse_action(action)
if not tool_name or not tool_input:
self.history.append("Observation: 无效的Action格式")
continue
# 执行工具并获取观察结果
print(f"🎬 行动: {tool_name}[{tool_input}]")
tool_function = self.tool_executor.getTool(tool_name)
if not tool_function:
observation = f"错误:未找到工具 '{tool_name}'"
else:
observation = tool_function(tool_input)
print(f"👀 观察: {observation}")
# 5. 记录历史轨迹
self.history.append(f"Action: {action}")
self.history.append(f"Observation: {observation}")
print("已达到最大步数,流程终止")
return None
def _parse_output(self, text: str):
"""解析LLM输出:提取Thought和Action"""
thought_match = re.search(r"Thought: (.*)", text)
action_match = re.search(r"Action: (.*)", text)
thought = thought_match.group(1).strip() if thought_match else None
action = action_match.group(1).strip() if action_match else None
return thought, action
def _parse_action(self, action_text: str):
"""解析Action:提取工具名和输入(格式:工具名[输入])"""
match = re.search(r"(\w+)\[(.*)\]", action_text)
if match:
return match.group(1), match.group(2)
return None, None关键逻辑解析
- 提示词模板 :强制LLM输出"Thought+Action"格式,确保可解析性,比如要求Action为
工具名[输入]或Finish[答案]; - 解析逻辑:通过正则表达式提取Thought和Action,避免LLM输出格式混乱导致流程中断;
- 历史轨迹:每次行动和观察都存入history,让LLM基于上下文动态调整决策;
- 安全机制 :设置
max_steps防止无限循环,工具调用失败时记录错误观察,保证流程稳健。
3.3 范式二:Plan-and-Solve(结构化执行型智能体)
核心目标:先分解任务为步骤,再按步骤执行,适合逻辑清晰、步骤明确的任务。
3.3.1 规划器:Planner(任务分解)
python
class Planner:
def __init__(self, llm_client):
self.llm_client = llm_client
def plan(self, question: str) -> list[str]:
"""生成行动计划:将复杂问题分解为有序步骤"""
prompt = PLANNER_PROMPT_TEMPLATE.format(question=question)
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
# 解析LLM输出:提取Python列表格式的计划
try:
plan_str = response_text.split("```python")[1].split("```")[0].strip()
plan = ast.literal_eval(plan_str) # 安全解析字符串为列表
return plan if isinstance(plan, list) else []
except (ValueError, SyntaxError, IndexError) as e:
print(f"❌ 解析计划错误: {e}")
return []3.3.2 执行器:Executor(步骤执行)
python
class Executor:
def __init__(self, llm_client):
self.llm_client = llm_client
def execute(self, question: str, plan: list[str]) -> str:
history = "" # 存储历史步骤和结果
for i, step in enumerate(plan, 1):
print(f"\n-> 执行步骤 {i}/{len(plan)}: {step}")
# 格式化提示词:包含原始问题、完整计划、历史结果、当前步骤
prompt = EXECUTOR_PROMPT_TEMPLATE.format(
question=question, plan=plan,
history=history if history else "无",
current_step=step
)
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
# 更新历史:用于下一步执行
history += f"步骤 {i}: {step}\n结果: {response_text}\n\n"
print(f"✅ 步骤 {i} 完成,结果: {response_text}")
return response_text # 最后一步结果为最终答案3.3.3 整合:PlanAndSolveAgent(智能体)
python
class PlanAndSolveAgent:
def __init__(self, llm_client):
self.llm_client = llm_client
self.planner = Planner(llm_client) # 规划器
self.executor = Executor(llm_client) # 执行器
def run(self, question: str):
print(f"\n--- 开始处理问题 ---\n问题: {question}")
# 1. 生成计划
plan = self.planner.plan(question)
if not plan:
print("\n--- 任务终止 --- 无法生成有效计划")
return
# 2. 执行计划
final_answer = self.executor.execute(question, plan)
print(f"\n--- 任务完成 ---\n最终答案: {final_answer}")关键逻辑解析
- 计划解析 :通过
ast.literal_eval安全解析LLM输出的列表,避免使用eval导致安全风险; - 历史传递:执行每一步时,将之前的步骤结果传递给LLM,确保步骤间依赖(如前一步的计算结果作为后一步的输入);
- 结构化约束:提示词要求LLM仅输出当前步骤的结果,不添加额外解释,保证执行过程的简洁性和可串联性。
3.4 范式三:Reflection(迭代优化型智能体)
核心目标:通过"执行-反思-优化"的迭代循环,提升输出质量,适合对结果精度、效率有高要求的任务。
3.4.1 记忆模块:Memory(轨迹存储)
python
class Memory:
def __init__(self):
self.records: List[Dict[str, Any]] = [] # 存储记录:execution(执行结果)、reflection(反思反馈)
def add_record(self, record_type: str, content: str):
"""添加记录:区分执行结果和反思反馈"""
self.records.append({"type": record_type, "content": content})
print(f"📝 记忆更新:新增 '{record_type}' 记录")
def get_trajectory(self) -> str:
"""格式化记忆轨迹:用于提示词(让LLM回顾历史迭代)"""
trajectory = ""
for record in self.records:
if record['type'] == 'execution':
trajectory += f"--- 上一轮尝试(代码) ---\n{record['content']}\n\n"
elif record['type'] == 'reflection':
trajectory += f"--- 评审员反馈 ---\n{record['content']}\n\n"
return trajectory.strip()
def get_last_execution(self) -> str:
"""获取最新的执行结果(如最新代码)"""
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
print("⚠️ 无执行记录")
return None3.4.2 核心层:ReflectionAgent(迭代优化)
python
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory() # 记忆模块
self.max_iterations = max_iterations # 最大迭代次数
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# 1. 初始执行:生成初稿
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# 2. 迭代循环:反思→优化
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思:评审当前结果
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 终止判断:若无需改进则退出
if "无需改进" in feedback:
print("\n✅ 代码已最优,任务完成")
break
# c. 优化:根据反馈改进结果
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task, last_code_attempt=last_code, feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
# 3. 返回最终结果
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终代码:\n```python\n{final_code}\n```")
return final_code
def _get_llm_response(self, prompt: str) -> str:
"""辅助方法:调用LLM获取响应"""
messages = [{"role": "user", "content": prompt}]
return self.llm_client.think(messages=messages) or ""关键逻辑解析
- 记忆模块:区分"执行记录"和"反思反馈",让LLM在迭代时能回顾完整轨迹,避免重复错误;
- 角色分离:通过不同提示词模板,让LLM分别扮演"执行者""评审员""优化者",聚焦不同职责;
- 迭代终止:设置"无需改进"关键词和最大迭代次数,平衡优化效果和成本(避免过度迭代)。
四、课后习题全解
习题1:三种范式的本质差异与架构选择
题干:
本章介绍了三种经典的智能体范式: ReAct 、Plan-and-Solve 和 Reflection 。请分析:
- 这三种范式在"思考"与"行动"的组织方式上有什么本质区别?
- 如果要设计一个"智能家居控制助手"(需要控制灯光、空调、窗帘等多个设备,并根据用户习惯自动调节),你会选择哪种范式作为基础架构?为什么?
- 是否可以将这三种范式进行组合使用?若可以,请尝试设计一个混合范式的智能体架构,并说明其适用场景。
解答:
-
本质区别:
- ReAct:思考与行动"交替进行",思考依赖上一步行动的观察结果,无预设计划,动态调整(适合不确定性环境);
- Plan-and-Solve:思考与行动"分阶段分离",先一次性完成全量思考(规划),再按步骤执行,行动不改变计划(适合确定性任务);
- Reflection:思考与行动"迭代融合",行动生成结果后,思考(反思)结果的不足,再通过行动(优化)改进,循环提升质量(适合高质量需求)。
-
智能家居控制助手的范式选择:ReAct 为基础,融合 Plan-and-Solve:
- 选择理由:
- 智能家居场景存在不确定性(如用户临时调整习惯、设备故障),ReAct 的动态调整能力可应对突发情况;
- 核心任务(如"晚上8点自动拉窗帘+开空调")具有结构化步骤,可通过 Plan-and-Solve 生成固定计划,提升执行效率;
- 实现逻辑:
- 日常模式:通过 Plan-and-Solve 生成固定计划(如"起床→开窗帘→开空调到26℃");
- 异常处理:若设备未响应(观察结果),ReAct 动态调整行动(如"重新发送控制指令→通知用户设备故障")。
- 选择理由:
-
混合范式设计:ReAct + Plan-and-Solve + Reflection(适用场景:智能科研助手):
- 架构逻辑:
- 规划阶段(Plan-and-Solve):将"科研任务"分解为"检索文献→分析数据→撰写论文→优化结构"步骤;
- 执行阶段(ReAct):每一步执行时,调用工具(文献检索工具、数据分析工具),根据工具反馈动态调整(如检索不到文献则更换关键词);
- 优化阶段(Reflection):论文初稿完成后,反思"结构是否清晰→数据是否准确→逻辑是否严谨",迭代优化论文质量;
- 适用场景:科研、复杂报告撰写等需要"结构化流程+动态调整+高质量输出"的任务。
- 架构逻辑:
习题2:ReAct输出解析的脆弱性与优化
题干:
在4.2节的 ReAct 实现中,我们使用了正则表达式来解析大语言模型的输出(如 Thought 和 Action )。请思考:
- 当前的解析方法存在哪些潜在的脆弱性?在什么情况下可能会失败?
- 除了正则表达式,还有哪些更鲁棒的输出解析方案?
- 尝试修改本章的代码,使用一种更可靠的输出格式,并对比两种方案的优缺点。
解答:
-
正则解析的脆弱性与失败场景:
- 脆弱性:依赖 LLM 严格遵循"Thought: xxx\nAction: xxx"格式,对输出格式敏感;
- 失败场景:
- LLM 输出多换行(如 Thought 后换行多次)、标点变化(如 Action:xxx);
- 输出包含额外解释(如"Thought: 我需要搜索... 所以 Action: Searchxxx");
- 中英文混用(如"Action:Searchxxx")。
-
更鲁棒的解析方案:
- 方案1:结构化输出(JSON),要求 LLM 输出固定 JSON 格式(如{"thought": "xxx", "action": "xxx"});
- 方案2:工具调用格式(Function Calling),使用 OpenAI 风格的工具调用语法,通过模型原生支持的结构化输出能力解析;
- 方案3:少样本提示(Few-shot),在提示词中加入2-3个正确格式示例,引导 LLM 遵循输出规范。
-
代码修改:JSON 结构化输出方案:
-
步骤1:修改 ReAct 提示词模板,要求输出 JSON:
pythonREACT_PROMPT_TEMPLATE = """ 可用工具:{tools} 请严格输出JSON格式,包含thought和action字段: {{ "thought": "你的思考过程", "action": "工具名[输入] 或 Finish[最终答案]" }} 问题:{question} 历史:{history} """ -
步骤2:修改 _parse_output 方法,解析 JSON:
pythondef _parse_output(self, text: str): try: # 提取JSON字符串(忽略前后无关文本) json_str = re.search(r"\{.*\}", text, re.DOTALL).group() data = json.loads(json_str) thought = data.get("thought") action = data.get("action") return thought, action except Exception as e: print(f"❌ JSON解析错误: {e}") return None, None -
方案对比:
方案 优点 缺点 正则表达式 实现简单,无需修改提示词结构 鲁棒性差,易受格式变化影响 JSON结构化 鲁棒性强,解析逻辑清晰 需LLM支持JSON输出,提示词需明确格式要求
-
习题3:工具调用扩展与错误处理
题干:
工具调用是现代智能体的核心能力之一。基于4.2.2节的 ToolExecutor 设计,请完成以下扩展实践:
- 为 ReAct 智能体添加一个"计算器"工具,使其能够处理复杂的数学计算问题(如"计算 (123 + 456) × 789/ 12 = ? 的结果")
- 设计并实现一个"工具选择失败"的处理机制:当智能体多次调用错误的工具或提供错误的参数时,系统应该如何引导它纠正?
- 思考:如果可调用工具的数量增加到100个甚至1000个,当前的工具描述方式是否还能有效工作?在可调用工具数量随业务需求显著增加时,从工程角度如何优化工具的组织和检索机制?
解答:
-
添加计算器工具:
-
步骤1:实现计算器工具函数:
pythondef calculator(expr: str) -> str: """计算器工具:解析并计算数学表达式""" print(f"🧮 正在计算: {expr}") try: # 安全计算(过滤危险操作) safe_expr = re.sub(r"[^0-9+\-*/(). ]", "", expr) # 只保留数字和运算符 result = eval(safe_expr) # 生产环境建议用ast.literal_eval或第三方库 return f"计算结果: {expr} = {result}" except Exception as e: return f"计算错误: {str(e)}" -
步骤2:注册工具:
pythontool_executor.registerTool( name="Calculator", description="用于处理数学计算问题,输入为合法的数学表达式(如'(123+456)*789/12')", func=calculator )
-
-
工具选择失败处理机制:
-
设计思路:记录工具调用失败次数,达到阈值时提示LLM回顾可用工具列表,重新选择;
-
代码实现(修改 ReActAgent 的 run 方法):
pythondef run(self, question: str): self.history = [] current_step = 0 tool_fail_count = 0 # 工具调用失败计数器 max_fail_count = 2 # 最大失败次数 while current_step < self.max_steps: # ... 原有逻辑 ... # 执行工具时添加失败计数 tool_function = self.tool_executor.getTool(tool_name) if not tool_function: observation = f"错误:未找到工具 '{tool_name}'(已失败{tool_fail_count+1}次)" tool_fail_count += 1 else: try: observation = tool_function(tool_input) tool_fail_count = 0 # 成功则重置计数器 except Exception as e: observation = f"工具执行错误: {str(e)}(已失败{tool_fail_count+1}次)" tool_fail_count += 1 # 失败次数达阈值,提示LLM重新查看工具列表 if tool_fail_count >= max_fail_count: observation += "\n⚠️ 多次工具调用失败,请重新查看可用工具列表,确认工具名称和输入格式是否正确" # ... 记录历史 ...
-
-
大量工具的组织与检索优化:
- 当前工具描述方式的问题:工具数量过多时,提示词长度超出LLM上下文窗口,且LLM难以快速找到合适工具;
- 工程优化方案:
- 工具分类:按功能分组(如"检索类""计算类""控制类"),提示词中仅展示与当前任务相关的工具类别;
- 工具索引:构建工具向量数据库(如用Embedding存储工具描述),LLM先生成任务向量,检索最相关的Top5工具,仅在提示词中展示这些工具;
- 工具推荐:基于历史任务类型,推荐常用工具,减少LLM选择成本;
- 分层提示:先让LLM判断任务类型,再展示对应类别的工具,避免信息过载。
习题4:Plan-and-Solve的动态重规划机制
题干:
Plan-and-Solve 范式将任务分解为"规划"和"执行"两个阶段。请深入分析:
- 在4.3节的实现中,规划阶段生成的计划是"静态"的(一次性生成,不可修改)。如果在执行过程中发现某个步骤无法完成或结果不符合预期,应该如何设计一个"动态重规划"机制?
- 对比 Plan-and-Solve 与 ReAct :在处理"预订一次从北京到上海的商务旅行(包括机票、酒店、租车)"这样的任务时,哪种范式更合适?为什么?
- 尝试设计一个"分层规划"系统:先生成高层次的抽象计划,然后针对每个高层步骤再生成详细的子计划。这种设计有什么优势?
解答:
-
动态重规划机制设计:
-
核心思想:执行每一步后,检查结果是否符合预期,若不符合则触发重规划,基于当前状态调整后续步骤;
-
实现逻辑(修改 Executor 的 execute 方法):
pythondef execute(self, question: str, plan: list[str]) -> str: history = "" for i, step in enumerate(plan, 1): print(f"\n-> 执行步骤 {i}/{len(plan)}: {step}") prompt = EXECUTOR_PROMPT_TEMPLATE.format( question=question, plan=plan, history=history, current_step=step ) response_text = self.llm_client.think(messages=messages) or "" # 检查步骤结果是否有效(自定义判断逻辑,如是否包含"错误""无法完成") if self._is_step_failed(response_text): print(f"❌ 步骤 {i} 执行失败,触发重规划") # 生成重规划提示词:基于当前状态调整后续计划 replan_prompt = f""" 原始问题:{question} 原计划:{plan} 已完成步骤:{history} 失败步骤:{step},失败原因:{response_text} 请基于当前状态,生成调整后的后续计划(仅输出步骤列表) """ new_plan = self.llm_client.think([{"role": "user", "content": replan_prompt}]) # 解析新计划并替换原计划的后续步骤 plan = plan[:i-1] + self._parse_plan(new_plan) print(f"✅ 重规划后的计划:{plan}") # 重新执行当前步骤(基于新计划) i -= 1 # 回退索引,重新执行调整后的步骤 continue history += f"步骤 {i}: {step}\n结果: {response_text}\n\n" return response_text def _is_step_failed(self, response_text: str) -> bool: """判断步骤是否失败""" fail_keywords = ["错误", "无法完成", "不存在", "失败"] return any(keyword in response_text for keyword in fail_keywords)
-
-
商务旅行预订任务的范式选择:Plan-and-Solve 为主,ReAct 为辅:
- 选择理由:
- 商务旅行预订是结构化任务(机票→酒店→租车),步骤明确,Plan-and-Solve 可生成固定计划,提升效率;
- 存在不确定性(如机票售罄、酒店满房),需 ReAct 动态调整(如更换航班、选择备选酒店);
- 实现逻辑:
- 规划阶段:生成"查询航班→预订机票→查询酒店→预订酒店→预订租车"的计划;
- 执行阶段:若某步骤失败(如机票售罄),触发 ReAct 逻辑,调用搜索工具查找备选航班,调整后续步骤。
- 选择理由:
-
分层规划系统设计与优势:
- 设计逻辑:
- 高层规划(抽象计划):将任务分解为"目标级"步骤,如"商务旅行预订"→"交通安排", "住宿安排", "出行安排";
- 低层规划(详细子计划):对每个高层步骤生成子计划,如"交通安排"→"查询北京→上海航班", "对比价格", "预订合适航班";
- 优势:
- 灵活性:某低层子计划失败时,仅需调整该子计划,无需修改整个高层计划;
- 可维护性:高层计划稳定,低层子计划可根据场景细化(如不同城市的交通方式不同);
- 可扩展性:新增功能时,只需在对应高层步骤下添加子计划(如"商务旅行"新增"会议预约"高层步骤)。
- 设计逻辑:
习题5:Reflection的模型分工与终止条件优化
题干:
Reflection 机制通过"执行-反思-优化"循环来提升输出质量。请思考:
- 在4.4节的代码生成案例中,不同阶段使用的是同一个模型。如果使用两个不同的模型(例如,用一个更强大的模型来做反思,用一个更快的模型来做执行),会带来什么影响?
- Reflection 机制的终止条件是"反馈中包含无需改进"或"达到最大迭代次数"。这种设计是否合理?能否设计一个更智能的终止条件?
- 假设你要搭建一个"学术论文写作助手",它能够生成初稿并不断优化论文内容。请设计一个多维度的 Reflection机制,从段落逻辑性、方法创新性、语言表达、引用规范等多个角度进行反思和改进。
解答:
-
双模型分工的影响:
- 优势:
- 成本优化:执行阶段用轻量级模型(如Qwen1.5-0.5B),速度快、成本低;反思阶段用强模型(如GPT-4o),批判分析能力强,提升优化效果;
- 效果提升:强模型的反思反馈更精准,能发现轻量级模型忽略的问题(如代码效率瓶颈、逻辑漏洞);
- 劣势:
- 兼容性风险:不同模型的输出风格、理解能力可能存在差异,反思反馈与执行结果的匹配度可能下降;
- 复杂度提升:需维护两个模型的配置、API调用,工程复杂度增加;
- 适用场景:对成本敏感、对优化效果有要求的场景(如批量代码生成、大规模文档优化)。
- 优势:
-
Reflection终止条件优化(更智能的设计):
-
原设计的局限性:"无需改进"依赖LLM主观判断,可能遗漏潜在优化点;"最大迭代次数"过于机械;
-
优化后的终止条件(多维度判断):
- 反馈相似度:若当前反思反馈与上一轮反馈的相似度>80%(如均提到"代码可读性需提升"),说明优化进入瓶颈,终止;
- 质量评分:让LLM对当前结果进行1-10分评分(基于任务要求),评分≥9分则终止;
- 优化收益:让LLM评估"当前优化带来的收益是否显著",若收益<10%则终止;
-
实现逻辑(修改 ReflectionAgent 的迭代循环):
python# 迭代循环中添加终止判断 feedback = self._get_llm_response(reflect_prompt) self.memory.add_record("reflection", feedback) # 1. 检查是否无需改进 if "无需改进" in feedback: print("\n✅ 代码已最优,任务完成") break # 2. 检查反馈相似度 if i > 0: prev_feedback = self.memory.records[-3]['content'] # 上一轮反思反馈 similarity = self._calculate_similarity(feedback, prev_feedback) if similarity > 0.8: print(f"\n✅ 反馈相似度{similarity:.2f},优化进入瓶颈,终止迭代") break # 3. 检查质量评分 score_prompt = f"请为以下结果评分(1-10分,基于代码效率和可读性):{last_code}" score = int(self._get_llm_response(score_prompt)) if score >= 9: print(f"\n✅ 质量评分{score}分,终止迭代") break
-
-
学术论文写作助手的多维度Reflection机制:
-
反思维度与提示词设计:
-
段落逻辑性:
pythonREFLECT_PROMPT_LOGIC = """ 你是学术逻辑评审专家,请分析论文段落的逻辑性: 1. 段落间过渡是否自然? 2. 论点是否有论据支撑? 3. 逻辑链条是否完整? 论文:{paper} 请输出具体问题和改进建议。 """ -
方法创新性:
pythonREFLECT_PROMPT_INNOVATION = """ 你是学术创新评审专家,请分析论文方法的创新性: 1. 与现有方法的差异是什么? 2. 创新点是否有理论或实验支撑? 3. 创新点的价值的是什么? 论文:{paper} 请输出具体问题和改进建议。 """ -
语言表达:
pythonREFLECT_PROMPT_LANGUAGE = """ 你是学术语言评审专家,请分析论文的语言表达: 1. 是否符合学术写作规范? 2. 语句是否通顺、无歧义? 3. 专业术语使用是否准确? 论文:{paper} 请输出具体问题和改进建议。 """ -
引用规范:
pythonREFLECT_PROMPT_CITATION = """ 你是引用规范评审专家,请分析论文的引用: 1. 引用文献是否相关、权威? 2. 引用格式是否统一(如APA、IEEE)? 3. 是否有遗漏的重要引用? 论文:{paper} 请输出具体问题和改进建议。 """
-
-
迭代优化逻辑:
- 生成初稿后,依次调用四个维度的反思提示词,收集综合反馈;
- 按"逻辑性→创新性→语言表达→引用规范"的优先级,逐一优化论文;
- 每轮优化后,重新进行多维度反思,直到所有维度评分≥8分。
-
习题6:提示词工程与平台特性的适配
题干:
提示词工程是影响智能体最终效果的关键技术。本章展示了多个精心设计的提示词模板。请分析:
- 对比4.2.3节(ReAct )、5.3.2节(Dify )和5.4.4节(n8n )中的提示词设计,它们在结构、风格和侧重点上有什么不同?这些差异是否与平台特性相关?
- 在 Dify 的"文案优化模块"中,提示词要求输出"超过500字"。这种对输出长度的硬性要求是否合理?在什么情况下应该限制输出长度,什么情况下应该让模型自由发挥?
- 在提示词中加入 few-shot 示例往往能显著提升模型对特定格式的遵循能力。请为本章的某个智能体尝试添加 few-shot 示例,并对比其效果。
解答:
-
不同平台提示词设计差异与平台特性关联:
平台/范式 结构 风格 侧重点 与平台特性的关联 ReAct(纯代码) 简洁,分"工具+格式+问题+历史" 指令清晰,无多余修饰 强制LLM输出结构化"Thought+Action" 纯代码实现,需手动解析输出,格式要求严格 Dify(低代码平台) 复杂,分"角色+背景+任务+限制+示例" 专业详细,多维度约束 确保输出符合业务需求(如文案质量、格式) 低代码平台面向企业用户,需稳定、高质量输出,支持多模块编排 n8n(工作流平台) 简洁,分"上下文+任务+输出格式" 工程化,注重数据格式 输出JSON格式,便于后续节点处理 工作流平台需数据流转,输出需结构化,适配多节点串联 -
输出长度硬性要求的合理性分析:
- 合理场景:
- 文案优化、营销文案、报告撰写等需要"详细内容"的任务,硬性长度要求可避免输出过于简略;
- 需与其他内容拼接的场景(如手册、文档),长度要求可保证格式统一;
- 不合理场景:
- 事实性问答(如"华为最新手机型号"),长度强制可能导致冗余信息;
- 代码生成、逻辑推理等注重"精准性"的任务,长度强制可能引入无关代码或逻辑;
- 结论:长度要求需与任务类型匹配,核心是"服务于输出质量",而非单纯追求长度。
- 合理场景:
-
ReAct提示词添加few-shot示例及效果对比:
-
原提示词(无few-shot):仅要求输出"Thought+Action"格式;
-
优化后提示词(添加2个示例):
pythonREACT_PROMPT_TEMPLATE = """ 可用工具:{tools} 请严格按照以下格式输出(参考示例): 示例1: Thought: 需要查询华为最新手机型号,调用Search工具 Action: Search[华为最新手机型号及卖点] 示例2: Thought: 已获取足够信息,可总结答案 Action: Finish[华为最新手机为Mate 70,卖点是全焦段摄影和抗摔] 问题:{question} 历史:{history} """ -
效果对比:
指标 无few-shot 有few-shot 格式遵循率 70%(可能出现格式混乱) 95%(严格遵循"Thought+Action") 工具调用准确性 65%(可能调用错误工具) 90%(示例引导正确调用) 迭代步数 平均4步 平均3步(效率提升) - 结论:few-shot示例能显著提升LLM对格式的遵循能力,减少解析失败,提升智能体运行效率。
-
习题7:电商客服智能体的架构设计
题干:
某电商初创公司现在希望使用"客服智能体"来代替真人客服实现降本增效,它需要具备以下功能:
a. 理解用户的退款申请理由
b. 查询用户的订单信息和物流状态
c. 根据公司政策智能地判断是否应该批准退款
d. 生成一封得体的回复邮件并发送至用户邮箱
e. 如果判断决策存在一定争议(自我置信度低于阈值),能够进行自我反思并给出更审慎的建议
此时作为该产品的负责人:
- 你会选择本章的哪种范式(或哪些范式的组合)作为系统的核心架构?
- 这个系统需要哪些工具?请列出至少3个工具及其功能描述。
- 如何设计提示词来确保智能体的决策既符合公司利益,又能保持对用户的友好态度?
- 这个产品上线后可能面临哪些风险和挑战?如何通过技术手段来降低这些风险?
解答:
-
核心架构:Plan-and-Solve + ReAct + Reflection 混合范式:
- 架构逻辑:
- 规划阶段(Plan-and-Solve):将"退款处理"分解为"理解申请理由→查询订单→判断退款→生成邮件→发送邮件"步骤;
- 执行阶段(ReAct):调用工具(订单查询工具、物流查询工具、邮件发送工具),处理不确定性(如订单查询失败→重新查询);
- 反思阶段(Reflection):对争议决策(置信度<80%)进行反思,如"退款理由是否充分→订单状态是否符合政策→回复是否友好",调整决策;
- 选择理由:兼顾结构化流程(提升效率)、动态处理(应对异常)、决策质量(降低争议)。
- 架构逻辑:
-
必备工具清单:
工具名称 功能描述 订单查询工具 输入用户ID/订单号,查询订单详情(购买时间、商品类型、支付状态) 物流查询工具 输入订单号,查询物流状态(是否发货、是否签收、物流轨迹) 邮件发送工具 输入用户邮箱、邮件主题、内容,自动发送退款处理结果邮件 退款政策查询工具 输入商品类型、订单状态,返回公司退款政策(如7天无理由、质量问题包退) 置信度评估工具 输入决策结果,评估决策的置信度(基于政策匹配度、理由充分性) -
提示词设计(平衡公司利益与用户友好):
pythonCUSTOMER_SERVICE_PROMPT = """ 你是电商客服智能体,需遵循以下原则: 1. 公司利益原则:严格按照退款政策判断,拒绝不符合政策的退款申请,说明政策依据; 2. 用户友好原则:语气礼貌、耐心,理解用户诉求,提供替代解决方案(如换货、维修); 3. 决策透明原则:明确告知退款批准/拒绝的原因,避免模糊表述; 4. 争议处理原则:置信度<80%时,建议用户联系人工客服,提供客服联系方式。 可用信息: - 用户退款理由:{refund_reason} - 订单信息:{order_info} - 物流状态:{logistics_info} - 退款政策:{refund_policy} 请完成以下任务: 1. 判断是否批准退款; 2. 生成得体的回复邮件内容; 3. 评估决策置信度。 """ -
风险与挑战及技术解决方案:
- 风险1:退款政策理解错误导致误判;
解决方案:将退款政策结构化存储(如JSON),提示词中明确要求LLM参考结构化政策,定期更新政策并同步给智能体; - 风险2:用户输入模糊(如未提供订单号)导致流程中断;
解决方案:ReAct动态追问,若缺少关键信息,生成追问话术(如"请提供你的订单号,以便查询详情"); - 风险3:邮件发送失败导致用户未收到通知;
解决方案:工具执行后添加结果校验,失败则重试3次,仍失败则记录日志并通知运营人员; - 风险4:用户隐私泄露(如订单信息、邮箱);
解决方案:数据传输加密,LLM提示词中禁止输出完整隐私信息(如隐藏邮箱中间4位),定期审计日志; - 风险5:争议决策处理不当导致用户投诉;
解决方案:Reflection机制重点审查争议决策,提供人工客服兜底通道,记录争议案例用于优化提示词和政策。
- 风险1:退款政策理解错误导致误判;
五、总结
第四章通过三个经典范式,构建了智能体"从决策到落地"的完整技术链条:ReAct 解决"动态环境中的步进决策",Plan-and-Solve 解决"结构化任务的高效执行",Reflection 解决"高质量输出的迭代优化"。三者并非互斥,而是可根据场景灵活组合,形成更强大的混合架构。
代码实现的核心是"模块化封装"------LLM客户端提供通用调用能力,工具层提供与外部世界交互的接口,范式层实现核心决策逻辑,这种分层设计确保了智能体的可扩展性和可维护性。提示词工程则是"点睛之笔",通过明确格式、角色、约束,引导LLM输出符合预期的结果。
掌握这三个范式的设计思想与实现逻辑,就能应对大多数智能体应用场景,为后续构建复杂多智能体系统、高级记忆与检索功能打下坚实基础。