一. 检索增强技术生成导论
1 基础理论
1.1 检索增强生成(RAG)定义
检索增强生成是一种结合大型语言模型(LLM)与外部信息检索的技术范式,通过引入新信息来增强 LLM 的生成能力,弥补其知识局限性。
1.2 LLM 的固有能力与局限性
- 固有能力:LLM 具备文本总结(Summarize Text)、代码生成(Generate Code)、内容重写(Rewrite Content)等强大的生成能力。
- 局限性:
- 无法访问私有数据库(Private Databases),即不能获取保密信息;
- 对难以访问的信息(Hard to access information)处理不足,这类信息因未广泛在线存在而无法被 LLM 获取;
- 缺乏实时数据(Real time data),LLM 基于历史数据训练,无法自动更新以获取最新信息。
2 技术架构
2.1 核心流程:两阶段处理
RAG 在回答问题时遵循 "检索 - 生成" 两步走流程:
- 检索阶段(Retrieval):收集与问题相关的信息,例如针对特定问题进行广泛研究(Extensive Research)以获取外部数据。
- 生成阶段(Generation):LLM 基于检索到的信息进行推理并生成响应(Reason & Respond),对检索信息进行综合(Synthesize research)。
2.2 技术模块组成
- 信息检索模块:负责从外部数据源(如新闻报道、论坛帖子等)中检索与用户查询相关的信息。
- LLM 生成模块:接收用户 prompt 和检索到的新信息(New information),结合自身知识生成最终响应。
|-----------------------------------------------------------------------------------------------------------------------------|
| 【补充说明】 实际技术架构中,信息检索模块通常依赖向量数据库、语义检索算法(如 BM25、Embedding 相似度匹配)等技术实现高效信息召回;LLM 生成模块则需进行 prompt 工程,将检索结果合理融入 prompt 以引导生成。 |
3 实践应用
3.1 典型问答场景
针对不同类型的问题,RAG 展现出差异化的处理方式:
- 对于常识性问题(如 "Why are hotels expensive on the weekend?"),无需额外收集信息,LLM 直接基于自身知识响应(Respond based on your knowledge)。
- 对于需要特定领域或最新信息的问题(如 "Why doesn't Vancouver have more hotel capacity close to downtown?""Why are hotels in Vancouver super expensive this coming weekend?"),需通过检索模块收集新闻报道、论坛帖子等新信息,再由 LLM 综合信息生成回答。
3.2 其他潜在应用
- 企业知识库问答:利用 RAG 检索企业私有数据库中的文档、数据,为员工或客户提供精准回答。
- 实时资讯整合:结合新闻、社交媒体等实时数据,生成具备时效性的分析、摘要内容。
|---------------------------------------------------------------|
| 【补充说明】 此外,RAG 还可应用于学术研究(检索论文数据库生成综述)、电商导购(检索商品信息生成推荐)等场景。 |
二. RAG实际应用
1 基础理论
1.1 RAG 应用的核心逻辑
检索增强生成(RAG)在实际应用中,通过检索特定领域 / 场景的知识源(如代码库、企业内部文档、专业数据、互联网资源、个人数据等),为大型语言模型(LLM)提供上下文,从而生成贴合场景、精准且具时效性的内容,解决 LLM 在特定知识、实时信息、私有信息上的局限性。
1.2 应用场景的共性与差异
- 共性:均依赖 "检索特定知识源 + LLM 生成" 的技术路径,以弥补 LLM 固有知识缺陷。
- 差异:知识源类型不同(代码、企业文档、专业数据、互联网、个人数据),服务对象和需求不同(开发者、企业客户、专业从业者、普通用户、个人)。
2 技术架构
2.1 通用架构模块
RAG 在各应用场景的技术架构均包含以下核心模块:
- 特定知识源:如代码库、企业内部手册 / FAQ、法律医疗文档、互联网网页、个人通讯 / 日程数据等。
- 检索模块:负责从知识源中检索与需求相关的信息。
|----------------------------------------------------------|
| 【补充说明】 通常采用向量数据库、语义相似度算法(如 Embedding 匹配)、关键词检索等技术实现。 |
- LLM 生成模块:将检索到的信息与用户需求结合,生成定制化响应。
2.2 各场景架构差异
|---------|---------------------|----------------|--------------|
| 应用场景 | 知识源类型 | 检索重点 | 生成目标 |
| 代码生成 | 项目代码库(类、函数、定义、编码风格) | 项目特定的代码上下文、逻辑 | 符合项目风格的代码、问答 |
| 企业聊天机器人 | 企业内部文档(手册、支持指南、FAQ) | 产品信息、政策、沟通风格 | 贴合企业的客户问答 |
| 专业知识领域 | 专业文档(案例、期刊、私有数据) | 法律条款、医疗病例等专业细节 | 精准、保密的专业回答 |
| 搜索引擎整合 | 互联网网页 | 实时、权威的网页信息 | 信息摘要、问答 |
| 个性化 RAG | 个人数据(通讯、邮件、日程、联系人) | 个人行为习惯、信息上下文 | 个性化助手响应 |
点击图片可查看完整电子表格
三. RAG架构概览
1 基础理论
1.1 RAG 的定义
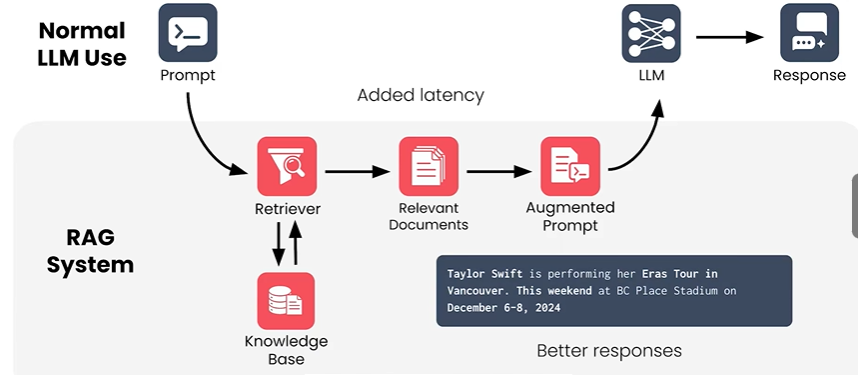
检索增强生成(RAG)是一种通过检索外部知识库的相关信息来增强大型语言模型(LLM)生成能力的技术架构,核心是为 LLM 补充特定上下文,以生成更准确、贴合场景的响应。
1.2 与普通 LLM 使用的差异
- 普通 LLM 使用:直接接收用户Prompt,由 LLM 独立生成Response,依赖模型内置的训练知识。
- RAG 系统:在Prompt和 LLM 之间引入 检索(Retriever)和知识库(Knowledge Base) 模块,通过检索相关文档生成增强Prompt(Augmented Prompt),再由 LLM 生成响应,可融入实时、专属信息,提升回答质量。
2 技术架构
2.1 核心模块组成
- Retriever(检索器) :负责从知识库中检索与用户Prompt相关的信息,是连接用户需求与外部知识的桥梁。
- Knowledge Base(知识库):存储各类领域知识、文档、数据等外部信息的集合,为检索提供素材。
- Relevant Documents(相关文档) :Retriever 从知识库中检索出的与用户Prompt高度相关的文档片段。
- Augmented Prompt(增强提示) :将用户原始Prompt与相关文档结合,形成更丰富的输入提示,传递给 LLM。
- LLM(大型语言模型) :基于增强提示生成最终的Response,利用外部知识提升回答的准确性和相关性。
2.2 工作流程
- 用户输入Prompt,进入 RAG 系统。
- Retriever在Knowledge Base中检索相关信息,得到Relevant Documents。
- 将原始Prompt与Relevant Documents整合,生成Augmented Prompt。
- LLM 基于Augmented Prompt生成Response,得到更优质的回答(如贴合实时事件的回答)。
|---------------------------------------------------------------------------------------------------------|
| 【补充说明】 实际技术流程中,Retriever 的检索算法通常包含语义相似度计算(如 Embedding 向量匹配)、关键词检索等;知识库的构建需进行文档拆分、向量化等预处理步骤,以提升检索效率。 |
3 实践应用
3.1 实时事件问答场景
以图片中 "Taylor Swift 演唱会信息" 为例,知识库中存储了该演唱会的实时信息(温哥华 BC Place 体育场,2024 年 12 月 6-8 日),当用户询问相关问题时,Retriever检索到该信息并生成增强Prompt,LLM 据此生成准确的回答,解决了普通 LLM 因训练数据时效性不足而无法精准回答的问题。
3.2 典型场景延伸
- 企业知识库问答:检索企业内部文档(如产品手册、政策文件),生成符合企业业务的响应。
- 专业领域咨询:在法律、医疗等领域,检索案例库、期刊文献,为用户提供精准的专业建议。
- 此外,RAG 还可应用于代码生成(检索项目代码库)、个性化助手(检索个人数据)等场景,均遵循 "检索 - 增强提示 - LLM 生成" 的架构逻辑。
四. 信息检索技术导论
1. 基础理论
1.1 核心概念
- 检索器(Retriever):在信息检索流程中,负责理解用户请求并从知识库(Knowledge Base)中筛选相似文档的模块。
- 知识库(Knowledge Base):存储各类文档信息的数据库,是检索器检索操作的数据源。
- 相关性(Relevance):文档与用户请求之间的关联程度,通常以量化分值(如图片中 "0.95""0.6" 等)表示,分值越高相关性越强。
1.2 检索基本问题
- 理解请求含义:如 "What does the prompt mean?",即解析用户输入的查询意图。
- 匹配相似文档:如 "What documents in the knowledge base are similar?",即从知识库中检索与用户请求相似的文档。
2. 技术架构
2.1 核心模块
- 检索器(Retriever):作为信息检索的核心模块,负责连接用户请求与知识库,执行文档检索操作。
- 知识库(Knowledge Base):存储各类文档的数据库,为检索器提供检索对象。
2.2 典型流程(以 "家庭制作纽约风格披萨" 查询为例)
- 接收用户请求:How can I make New York style pizza at home?
- 检索器解析请求:理解 "纽约风格披萨""家庭制作" 等关键意图。
- 检索器从知识库检索相似文档:如 "Pizza Basics""Sauce Secrets""Cooking at Home" 等,并给出相关性分值。
- 返回检索结果:将相关性较高的文档返回给用户。
五. 检索器架构综述
1. 基础理论
1.1 核心检索方法
- 关键词检索(Keyword Search) 检索包含与提示词完全一致词汇的文档。其核心是基于词汇的精确匹配,聚焦于文本表面的词语重合度。
- 语义检索(Semantic Search) 检索与提示词含义相似的文档,不依赖于词汇的完全匹配,更关注文本背后的语义关联。
1.2 混合检索的价值
混合检索是结合多种检索方法的策略,旨在平衡精确性与语义理解能力,提升检索效果的全面性。
2. 技术架构
2.1 单检索方法流程
- 关键词检索流程从知识库(Knowledge Base)中检索含精确关键词的文档,通常返回 20-50 篇文档,再经元数据过滤(Metadata Filter),根据文档元数据筛选出符合刚性标准的文档。
- 语义检索流程从知识库中检索语义相似的文档,同样返回 20-50 篇文档,再经元数据过滤,筛选出符合元数据标准的文档。
2.2 混合检索架构(Hybrid Search)
混合检索整合以下三个关键模块:
- 关键词检索模块:确保对用户提示词中精确词汇的敏感性,捕捉字面匹配的相关文档。
- 语义检索模块:发现含义相似的文档,即使无词汇匹配也能检索到语义关联内容。
- 元数据过滤模块:基于刚性标准排除不符合条件的文档,进一步精炼检索结果。
|------------------------------------------------------------|
| 工业界通常会设计权重分配机制,根据业务场景对关键词检索、语义检索的贡献度设置不同权重,再结合元数据过滤得到最终结果。 |
3. 实践应用
检索器架构广泛应用于问答系统、企业知识管理、搜索引擎等场景。例如在 "家庭制作纽约风格披萨" 的问答场景中,可通过关键词检索捕捉 "纽约披萨""家庭制作" 等精确词汇的文档,通过语义检索捕捉 "披萨制作方法""美式披萨技巧" 等语义关联的文档,再通过元数据过滤(如筛选 "家庭烹饪" 分类下的文档)得到精准结果。
六. 元数据过滤技术
1 基础理论
1.1 核心概念
元数据过滤技术是一种利用严格标准 (rigid criteria),基于标题、作者、创建日期、访问权限等元数据对文档进行筛选,以缩小文档范围的技术手段。其筛选逻辑为符合全部条件的文档才会被显示。
1.2 技术特征
- 过滤逻辑:基于元数据的精确匹配,属于 "硬过滤",仅返回满足所有条件的结果。
- 与 "真搜索" 的区别:并非真正意义上的内容搜索,而是基于元数据属性的筛选。
2 技术架构
2.1 关键模块
以《The Daily Maple》场景为例,核心筛选维度模块包括:
- 标题(Title)
- 发布日期(Publication Date)
- 作者(Author)
- 栏目(Section)
- 标签(Tags)
- 访问权限(Access Privileges)
2.2 典型实现示例
以 SQL 语句为例,实现基于元数据的过滤:
|--------------------------------------------------------------------|
| SQL SELECT * FROM articles WHERE publication_date = '2023-10-01'; |
或多条件组合:
|---------------------------------------------------------------------------------|
| Plain Text section = "Opinion" author = "Michael Chen" date = June to July 2024 |
3 实践应用
3.1 典型场景
- 媒体内容管理:如《The Daily Maple》类媒体平台,按发布日期、作者、栏目等维度筛选文章。
- 企业文档管理:基于创建日期、作者、访问权限等元数据筛选内部文档。
- 数字图书馆:按书名、作者、出版时间等元数据筛选图书资源。
七. 关键词搜索:BM25算法
1 基础理论
1.1 核心概念
BM25(Best Matching 25)是一系列评分函数中的第 25 个变体,是关键词搜索领域用于衡量文档与查询关键词相关性的算法。它通过对单个关键词计算评分,再将所有关键词的评分求和,得到文档的总相关性评分。
1.2 与 TF-IDF 的区别
|----------------------------------------|------------------------------------------------------|------------------------------------------------------------|
| 维度 | TF-IDF | BM25 |
| 词频饱和度(Term Frequency Saturation) | 词频翻倍,评分翻倍(如 "pizza" 出现 10 次得 Score X,20 次得 Score 2X) | 词频增长,评分增长趋于饱和(如 "pizza" 出现 10 次得 Score X,20 次得 Score 1.3X) |
| 文档长度归一化(Document Length Normalization) | 对长文档惩罚过重(Short Doc 得分高,Long Doc 惩罚重) | 对长文档惩罚更温和(Short Doc 得分高,Long Doc 惩罚小) |
2 技术架构
2.1 核心公式
BM25 单个关键词的评分公式为:
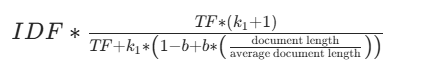
总相关性评分是所有关键词评分的总和。
2.2 可调节参数
- k1 (词频饱和度控制)
- 作用:控制词频对评分的影响程度。
- 范围:通常在 1.2 到 2.0 之间。
- 效果:值越高,词频的影响越大;值越低,词频的影响越小。
- b(长度归一化控制)
- 作用:控制文档长度归一化的程度。
- 范围:在 0(无归一化)到 1(完全归一化)之间。
- 效果:平衡对短文档和长文档的偏好。
3 实践应用
3.1 典型场景
BM25 是生产环境中检索系统的标准关键词搜索算法,广泛应用于:
- 搜索引擎:对网页内容进行关键词相关性排序。
- 企业知识库:在大量文档中快速检索与关键词相关的内容。
- 学术论文库:按关键词匹配度筛选相关论文。
八. 语义搜索
1 基础理论
1.1 核心概念
语义搜索是一种将查询(Prompt)和文档 分别转换为向量,通过比较向量的相似度来生成相关性分数,从而检索文档的技术。
1.2 与关键词搜索的区别
|--------|-------------------|-----------------------------|
| 维度 | 关键词搜索 | 语义搜索 |
| 向量分配方式 | 统计词频(count words) | 使用嵌入模型(use embedding model) |
| 处理逻辑 | 基于词的精确匹配 | 基于语义的向量相似度匹配 |
1.3 语义向量的关键特性(Key Takeaways)
- 语义向量具有抽象性和一定随机性。
- 训练前:向量在空间中的位置无语义意义。
- 训练后:由于相似文本的向量形成聚类,空间位置具备了语义意义。
- 向量可比性:仅能比较同一嵌入模型生成的向量。
2 技术架构
2.1 嵌入模型(Embedding Models)
- 功能 :将 tokens(词、句、文档等语言单元)映射到向量空间的特定位置,以向量形式表示其语义。
- 维度特性:
- 可支持 2 维、3 维,甚至100-1000 + 维。
- 维度越多,越能形成语义聚类,捕捉细微的语义关系(如 "food" 和 "cuisine" 向量距离近,"cat" 和 "trombone" 向量距离远)。
- 粒度类型:
- 词嵌入模型(Word Embedding Model):处理单个词,如 "cat""happy"。
- 句嵌入模型(Sentence Embedding Model):处理句子,如 "The weather is nice""What a lovely day"。
- 文档嵌入模型(Document Embedding Model):处理整个文档。
2.2 语义搜索流程
- 向量转换:文档和查询(Prompt)分别通过嵌入模型转换为向量。
- 相似度计算:在向量空间中比较这些向量,生成相似度分数。
- 结果排序:根据向量距离对文档排序,返回最接近的文档。
2.3 嵌入模型的训练
2.3.1 样本对设计
- 正样本对:语义相似的文本对,如 "Good Morning" 和 "Hello",在向量空间中应距离较近。
- 负样本对:语义无关的文本对,如 "Good Morning" 和 "That's a noisy trombone",在向量空间中应距离较远。
2.3.2 初始状态
嵌入模型的向量是随机初始化的,例如 "Good morning" 在未训练的模型中会被映射为随机向量。
2.3.3 对比训练过程(Contrastive Training Process)
- 阶段特征:
- 训练开始时(Beginning of Training):向量处于随机位置,如文本 "He could smell the roses""A field of fragrant flowers""The lion roared majestically" 的向量分布无规律。
- 训练中(Training):对语义相似的正样本向量 "拉"(靠近)、语义无关的负样本向量 "推"(远离),实现 "Pushing and pulling" 的动态调整。
- 训练后(After Training):形成有意义的嵌入(Meaningful Embeddings),语义相似的文本向量聚类(如 "He could smell the roses" 和 "A field of fragrant flowers" 的向量靠近)。
- 大规模扩展(Scaling up Contrastive Learning) :实际训练中,每个向量会同时在多个方向被推拉,利用数百或数千维的高维度空间,为向量的推拉提供更多可操作空间。通过构建数百万计的正负样本对(with complex relationships),最终使相似文本的向量形成聚类。
3 实践应用
3.1 典型场景
- 智能问答系统:理解用户问题的语义,从知识库中精准检索答案(如企业内部知识问答、客服机器人)。
- 学术文献检索:基于论文的语义内容,检索与研究主题高度相关的文献(如 ResearchGate、知网的语义检索功能)。
- 电商搜索:理解用户购物意图(如 "找一双轻便的跑步鞋"),检索语义匹配的商品(如淘宝、京东的智能搜索)。
九. 混合搜索策略
1. 基础理论
1.1 核心概念
混合搜索是一种融合元数据过滤、关键词搜索、语义搜索等多种搜索策略的检索范式,通过多策略协同与融合,兼顾检索效率与语义理解能力,提升检索结果的准确性与全面性。
1.2 关键搜索策略
- 元数据过滤(Metadata Filtering) :利用文档元数据中存储的刚性标准缩小搜索结果范围。特点是快速、易用,属于 "是 / 否" 型过滤,但无法单独使用。
- 关键词搜索(Keyword Search) :基于文档与提示中关键词的匹配程度对文档评分。特点是速度快,在关键词精确匹配场景表现突出,但依赖严格的精确匹配。
- 语义搜索(Semantic Search) :基于文档与提示的语义相似性对文档评分并排序。特点是灵活性高,但速度较慢、计算成本高。
2. 技术架构
2.1 检索流程
混合搜索由 "检索器(Retriever)" 发起,遵循以下流程:
- 检索器并行触发关键词搜索 和语义搜索,各返回固定数量(如 50 份)的文档列表。
- 对两个文档列表分别应用元数据过滤,筛选出符合刚性条件的文档(如关键词搜索列表剩余 35 份,语义搜索列表剩余 30 份)。
- 融合两个筛选后的列表,形成最终排名,返回 "top_k" 最相似文档。
2.2 融合算法:互反排名融合(Reciprocal Rank Fusion)
- 核心机制:
- 奖励在各检索列表中排名靠前的文档。
- 可控制关键词搜索与语义搜索排名的权重。
- 评分规则为 "排名的倒数",例如第 1 名得 1 分,第 2 名得 0.5 分,依此类推。
- 总分为所有排名列表的分数之和,用于计算最终排名,公式为:
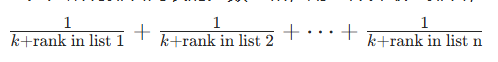
- 参数 k 的影响:
- 当 k = 0 时,排名靠前的文档会大幅跃升至整体排名顶部,第 1 名与第 10 名的分数差异达 10 倍。
- 当 k = 50 时,单一高排名对整体排名的主导性减弱,第 1 名与第 10 名的分数差异仅为 1.2 倍。
2.3 权重调节:Beta 参数(Weighting Semantic vs. Keyword)
通过beta(β)参数调节语义搜索与关键词搜索的权重占比:
- 当 beta = 0.8 时,语义搜索占比 80%,关键词搜索占比 20%。
- 当 beta = 0.7 时,语义搜索占比 70%,关键词搜索占比 30%。
- 应用原则:若场景对精确关键词匹配要求较高,需设置较低的 beta 值。
十. 检索质量评估
1. 基础理论
1.1 评估三要素
- The Prompt:待评估的具体提示。
- Ranked Results:按排名顺序返回的文档。
- Ground Truth:所有被标注为相关或不相关的文档。
|----------------------------------------------------|
| 评估的前提是需要知道正确答案(ground truth),否则无法有效衡量检索结果的准确性。 |
1.2 核心指标概念
- 精确率(Precision) :衡量返回的文档中有多少是相关的,公式为 相关且检索到的 / 总检索到的。
- 召回率(Recall) :衡量有多少相关文档被返回,公式为 相关且检索到的 / 总相关的。
2. 技术架构
2.1 基础指标计算示例
以 "知识库中有 10 个相关文档" 为例:
- 第一次运行:检索 12 份文档,其中 8 份相关。
- 精确率:8/12 = 66%
- 召回率:8/10 = 80%
- 第二次运行:检索 15 份文档,其中 9 份相关。
- 精确率:9/15 = 60%
- 召回率:9/10 = 90%
- 特点:精确率惩罚返回不相关文档 ,召回率惩罚遗漏相关文档。
2.2 平均准确率均值(Mean Average Precision, MAP@K)
- 定义:评估前 K 个文档中相关文档的平均准确率,基于 "平均准确率(Average Precision)" 指标。
- 计算步骤:
- 仅对相关文档的精确率求和。
- 除以相关文档的数量,得到单条提示的平均准确率(AP)。
- 对多条提示的 AP 值取平均,得到MAP。
- 示例 :排名 1(相关,精确率 1.0)、4(相关,精确率 0.5)、5(相关,精确率 0.6),求和1 + 0.5 + 0.6 = 2.1,除以 3(相关文档数),得到AP = 0.7,MAP 为多条提示的 AP 平均值。

2.3 互反排名(Reciprocal Rank)与平均互反排名(Mean Reciprocal Rank, MRR)
- 互反排名 :衡量返回列表中第一个相关文档的排名 ,公式为 1 / 排名。
- 示例:第一个相关文档在排名 1 得1.0,排名 2 得0.5,排名 4 得0.25。
- 平均互反排名:对多个提示的互反排名取平均。
- 计算步骤:
- 对所有检索的互反排名求和。
- 除以检索次数。
- 示例 :四次检索的互反排名分别为1.0、0.33、0.17、0.5,求和2.0,除以 4,得到MRR = 0.5。
3. 实践应用
3.1 指标的应用场景
- 召回率(或 Recall@K):最常被引用的指标,捕捉 "找到相关文档" 的核心目标。
- 精确率与 MAP:评估不相关文档的比例及排名的有效性。
- 平均互反排名 :衡量模型在排名顶部的表现(即第一个相关文档出现的位置好坏)。
3.2 指标的作用
- 评估检索器性能。
- 检查调整(如算法优化、参数调整)是否提升结果。
- 工业界典型场景:
- 电商搜索:用精确率保障结果相关性,减少用户看到不相关商品的概率。
- 学术检索:用召回率确保科研人员不遗漏潜在相关文献。
十一. 近似最近邻(ANN)算法
1.基础理论
1.1 核心定义
近似最近邻(ANN)算法是一种在高维数据场景中用于快速查找近似最近邻的方法,其核心特性包括:
- 效率优势:显著快于 KNN(K 近邻)算法;
- 精度权衡:不保证找到绝对最近的文档,以部分精度损失换取检索效率的提升。
1.2 与 KNN 的区别
|-------|------------------|---------------|
| 维度 | KNN(精确最近邻) | ANN(近似最近邻) |
| 精度 | 保证找到绝对最近邻 | 不保证找到绝对最近邻 |
| 时间复杂度 | 线性(需计算与所有数据点的距离) | 亚线性(依赖额外数据结构) |
| 适用场景 | 小规模、低维数据 | 大规模、高维数据 |
2.技术架构
2.1 基础技术:可导航小世界(Navigable Small World, NSW)
2.1.1 构建过程
- 计算所有文档向量之间的距离;
- 为每个文档添加一个图节点;
- 将每个节点与其最近邻节点连接,形成邻近图(Proximity Graph);
- 可通过在邻近图的边之间移动来遍历图,实现近似最近邻检索。
2.1.2 检索机制
在邻近图中进行搜索时,可能无法找到最接近的向量,因为算法在每一步选择当前最优路径,而非全局最优路径,但支持找到多个最近邻。
2.2 层次化改进:分层可导航小世界(Hierarchical Navigable Small World, HNSW)
2.2.1 技术原理
通过增强可导航小世界(NSW)来加速搜索的早期阶段,依赖层次化邻近图实现高效检索。
2.2.2 层次结构(示例)
- Layer 3:随机筛选至仅 10 个向量,构建最高层的邻近图以实现快速导航;
- Layer 2:随机筛选至 100 个向量,构建中间层的邻近图用于中间导航;
- Layer 1:包含所有 1000 个向量,构建完整的邻近图以实现精确的最终搜索。
2.2.3 检索流程
- Layer 3:选择随机候选向量,在顶层搜索以尽可能接近目标(实现 "早期大跳跃");
- Layer 2:从 Layer 3 的最佳候选开始,通过 Layer 2 的邻近图完成常规搜索;
- Layer 1:从 Layer 2 的最佳候选开始,通过 Layer 1 的邻近图完成常规搜索(进入 Layer 1 后已接近查询向量)。
2.2.4 效率优势
- 各层向量数量呈指数级减少 (如 1000→100→10),使时间复杂度近似对数级;
- 对比 KNN 的线性时间复杂度,HNSW 在大规模数据下显著快于 KNN,支持扩展到数十亿向量的规模。
3.实践应用
3.1 典型场景
- 大规模图像检索:如电商平台的商品图相似性匹配;
- 推荐系统:相似物品、用户的快速匹配;
- 自然语言处理:语义相似性搜索(如文本向量的近似近邻检索)。
3.2 性能表现
随着数据集规模增大,ANN(以 HNSW 为代表)的计算时间呈对数级增长,而 KNN 呈线性增长,因此在大规模数据场景下 ANN 的效率优势极为突出。
十二. 向量数据库技术
1. 基础理论
1.1 核心定义
向量数据库是专为向量搜索设计 的数据库,用于存储高维向量并通过近似最近邻(ANN)算法执行向量搜索。
1.2 与关系型数据库的区别
|--------|--------------|--------------------|
| 维度 | 关系型数据库 | 向量数据库 |
| 向量搜索效率 | 类似低效的 KNN 搜索 | 针对 ANN 搜索优化,效率显著更优 |
| 适用场景 | 结构化数据的关联查询 | 高维向量的语义 / 相似性检索 |
2.技术架构
2.1 典型操作流程
向量数据库的核心操作包括:
- 数据库设置(Database setup)
- 加载文档(Load documents)
- 为关键词搜索创建稀疏向量(Create sparse vectors for keyword search)
- 为语义搜索创建密集向量(Create dense vectors for semantic search)
- 创建 HNSW 索引以支撑 ANN 算法(Create HNSW index to power ANN algorithm)
- 执行搜索(Run searches!)
2.2 核心组件:Weaviate
Weaviate 是一款主流开源向量数据库,具备以下特性:
- 支持构建HNSW 索引和高效计算向量距离;
- 可扩展性强,能支撑大规模向量数据的快速检索;
- 提供简洁的 API 接口,支持数据管理与多类型搜索操作。
2.3 索引机制:HNSW(分层可导航小世界)
向量数据库依赖HNSW 索引实现高效 ANN 搜索,其层次化图结构使检索时间复杂度近似对数级,具体原理可参考《近似最近邻(ANN)算法》中 HNSW 的层次结构与检索流程。
3.实践应用
3.1 操作流程
3.1.1 数据库配置(以 Weaviate 为例)
通过代码定义集合、向量化器和属性:
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from weaviate.classes.config import Configure, Property, DataType client.collections.create( "Article", vectorizer_config=Configure.Vectorizer.text2vec_openai(), properties= Property(name="title", data_type=DataType.TEXT), Property(name="body", data_type=DataType.TEXT), ) |
- 功能:创建集合(Creates collection)、指定向量化器(Specifies vectorizer)、指定属性(Specifies Properties)。
3.1.2 数据加载
支持批量导入并处理异常:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python with collection.batch.fixed_size(batch_size=200) as batch: for data_row in data_rows: batch.add_object(properties=data_row) if batch.number_errors > 10: print("Batch import stopped due to excessive errors.") break failed_objects = collection.batch.failed_objects if failed_objects: print(f"Number of failed imports: {len(failed_objects)}") print(f"First failed object: {failed_objects0}") |
- 功能:批量添加数据(Batch adding data)、错误检测(Detecting errors)、失败处理(Handling failures)。
3.2 搜索功能
3.2.1 向量搜索(语义搜索示例)
通过near_text执行基于文本的向量检索:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from weaviate.classes.query import MetadataQuery articles = client.collections.get("Article") response = articles.query.near_text( query="hotel capacity in downtown Vancouver", limit=2, return_metadata=MetadataQuery(distance=True) ) for o in response.objects: print(o.properties) print(o.metadata.distance) |
- 功能:指定集合(Specifies Collection)、执行 "near_text" 向量搜索(Performs vector search with "near_text")、获取向量距离元数据(Asks for vector distances)。
3.2.2 混合搜索
融合向量搜索与关键词搜索,通过alpha调整权重:
|--------------------------------------------------------------------------------------------------------------------------------------------------|
| Python response = articles.query.hybrid( query="Vancouver hotel capacity", alpha=0.25, limit=3, ) for o in response.objects: print(o.properties) |
- 功能:混合搜索(Hybrid search)、权重调整(如alpha=0.25表示 25% 向量搜索权重、75% 关键词搜索权重)。
3.2.3 带元数据过滤的混合搜索
在混合搜索中添加属性过滤条件:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python response = articles.query.hybrid( query = 'History of urban development in Vancouver', filters = Filter.by_property('title').contains_any('Vancouver'), alpha = 0.3, limit = 4 ) for o in response.objects: print(o.properties) |
- 功能:元数据过滤(Adding a metadata filter),进一步缩小检索范围。
3.3 完整工作流
向量数据库的典型工作流包含三个阶段:
- 配置数据库(Configure Database)
- 加载并索引数据(Load and Index Data)
- 执行搜索(Perform Searches)
十三. 文本分块技术
1. 基础理论
1.1 核心概念
文本分块(Chunking):将长文本(如文档、书籍)拆分为更小、更易处理的片段(Chunk)的技术,是大语言模型(LLM)应用中文本预处理的关键环节。
1.2 分块的必要性
- 解决 Token 限制:LLM 存在上下文窗口(Token 数)上限,分块可适配模型输入限制。
- 提升相关性:避免整书 / 整文档压缩为单一向量导致的信息平均化,使检索结果更精准。
- 优化 LLM 上下文输入:仅向 LLM 传递与查询相关的分块内容,避免上下文窗口被无关信息填满。
1.3 不分块的问题
- 信息压缩失真:整书语义被压缩为单一向量,无法清晰表达特定主题、章节或页面内容。
- 检索相关性差:向量是全内容的 "平均表示",搜索结果匹配度低。
- 上下文窗口过载:检索时返回整书,快速耗尽 LLM 的上下文容量。
2. 技术架构
2.1 分块粒度
可按不同层级拆分文本:
- 粗粒度:页面(Page)、章节(Chapter)
- 中粒度:段落(Paragraph)
- 细粒度:句子(Sentence)
2.2 分块策略
2.2.1 固定尺寸分块(Fixed Size Chunking)
- 定义:按固定字符数 / Token 数拆分文本(如每 250 字符为一个分块)。
- 优势:实现简单、分块大小统一。
- 不足:可能拆分完整语义单元(如截断句子 / 段落)。
2.2.2 重叠分块(Overlapping Chunking)
- 定义:分块间保留部分重叠内容(如 250 字符分块,重叠 25 字符,即 10% 重叠率)。
- 优势:减少语义单元被截断的概率,使边缘内容同时存在于多个分块中,提升检索相关性。
- 不足:增加分块数量,提高存储 / 计算成本。
2.2.3 递归字符拆分(Recursive Character Splitting)
- 定义:按文档结构特征(如换行符)递归拆分文本,优先保留语义单元完整性。
- 优势:适配文档天然结构,分块更符合人类阅读的语义边界。
- 不足:分块尺寸不固定,需额外处理极端长度的分块。
2.3 分块尺寸平衡
- 过大的分块(如章节级):单分块包含过多主题,向量表示模糊,易填满 LLM 上下文窗口。
- 过小的分块(如单词级):丢失上下文信息,降低检索相关性。
- 最优分块:平衡 "信息覆盖" 与 "语义聚焦",需结合场景调整尺寸。
2.4 分块后流程
分块是检索增强生成(RAG) 流程的前置步骤,完整链路为:
1.文本分块 → 2. 分块向量化(Embedding) → 3. 向量入库(向量数据库) → 4. 查询时检索相关分块 → 5. 将分块作为上下文传入 LLM 生成回答。
3. 实践应用
- 知识库检索:企业文档、学术论文的精准检索与问答。
- LLM 应用开发:ChatPDF、智能文档助手等工具的核心预处理环节。
- 信息抽取:从长文本中提取特定主题的片段(如合同条款、新闻要点)。
十四.《高级分块方法论》
1. 基础理论
1.1 核心概念
高级分块方法论:区别于基础分块(固定尺寸、递归字符拆分等),以语义逻辑、语言模型能力、上下文增强为核心,实现更贴合文本语义与使用场景的分块技术,是检索增强生成(RAG)中提升内容利用率的关键优化方向。
2. 技术架构
2.1 语义分块(Semantic Chunking)
2.1.1 核心流程
- 逐句处理文档:按句子顺序遍历文本;
- 向量化与对比:将当前分块与下一句分别转换为向量,计算二者的余弦距离;
- 阈值判断:若余弦距离低于阈值(语义相似度高),则将下一句加入当前分块;
- 语义拆分:若余弦距离超过阈值(语义主题变化),则新建分块。
2.1.2 优缺点
- 优势:贴合作者的思维逻辑;分块边界更智能;检索的召回率与精准度更高;
- 劣势:计算成本高;需要重复进行向量计算。
2.2 基于语言模型的分块(Language Based Chunking)
2.2.1 核心原理
通过提示大语言模型(LLM)对文档进行分块,在提示词中明确分块规则(如保持概念完整性、新主题出现时拆分),借助 LLM 的语义理解能力完成分块。
2.2.2 特点
- 分块效果优异,能精准保留语义单元;
- 随着 LLM 成本降低,经济性逐步提升;
- 本质是 "黑箱方法",分块逻辑依赖 LLM 的内部决策。
2.3 上下文感知分块(Context-Aware Chunking)
2.3.1 核心流程
- 基于基础分块方法得到初始分块;
- 通过 LLM 为每个分块补充上下文信息(如分块主题、关联内容);
- 补充后的分块存入知识库,检索器从知识库中获取分块并传入 LLM 生成回答。
2.3.2 特点
- 预处理成本较高(需 LLM 逐块补充上下文);
- 优势:大幅提升检索相关性,且不影响搜索速度;
- 补充的上下文同时提升检索精准度与 LLM 回答的质量。
2.4 分块方法选择策略
- 固定尺寸 / 递归字符拆分:作为基础默认方案,实现简单、成本低;
- 语义分块 / 基于 LLM 的分块:性能更高,但复杂度与成本增加,需通过实验验证投入产出比;
- 上下文感知分块:可作为各类分块技术的 "优化增强方案",以一定预处理成本换取检索效果提升。
十五. 查询语句解析
1. 基础理论
1.1 核心概念
查询语句解析是检索增强生成(RAG)流程中优化用户查询、提升检索精准度的预处理技术,核心是通过对原始查询的转换、增强,让检索器更精准地匹配目标内容,主要包含 "查询重写""查询增强" 等技术分支。
1.2 关键技术分支
1.2.1 查询重写(Query Rewriting)
利用大语言模型(LLM)将用户模糊、冗余的原始查询,转换为更适配检索系统的优化查询的技术。
1.2.2 假设文档嵌入(Hypothetical Document Embeddings,HyDE)
通过 LLM 生成 "理想查询结果文档",以该文档的嵌入向量替代原始查询向量进行检索的增强技术。
2. 技术架构
2.1 查询重写(Query Rewriting)
2.1.1 核心流程
- 输入:用户原始模糊查询(Messy Prompt)
- 处理:通过 "查询重写 LLM" 对原始查询进行优化
- 输出:优化后的查询(Optimized Prompt)
- 后续:将优化后的查询传入检索器(Retriever)执行检索
2.1.2 查询优化规则
- 澄清模糊表述;
- 适配专业术语(如医疗领域规范术语);
- 补充同义词以提升匹配概率;
- 移除不必要 / 干扰信息。
2.1.3 实践要点
- 需迭代优化查询重写的提示词(Prompt);
- 优化后的检索收益显著,足以覆盖其成本。
2.2 假设文档嵌入(HyDE)
2.2.1 核心逻辑
- 传统检索:检索器匹配 "原始查询向量" 与 "知识库文档向量";
- HyDE 检索:检索器匹配 "理想假设文档的向量" 与 "知识库文档向量"(理想假设文档由 LLM 基于原始查询生成)。
2.2.2 核心流程
- 输入:用户原始查询(如 "左肩疼痛伴拇指、食指麻木该怎么办?")
- 生成假设文档:LLM 基于原始查询,生成 "理想回答文档";
- 向量转换:将假设文档传入嵌入模型,生成其向量;
- 检索:以假设文档的向量为依据,在知识库中匹配实际文档。
2.2.3 技术特点
- 优势:可提升检索性能;
- 劣势:增加检索延迟与计算成本。
3. 实践应用
3.1 查询重写的典型场景
- 专业领域检索:医疗文档、法律条文等需适配专业术语的场景;
- 模糊查询优化:用户表述冗余、意图不清晰的日常查询场景。
3.2 HyDE 的典型场景
- 复杂意图检索:用户查询为抽象问题(如诊断类、建议类查询),需通过理想文档明确检索方向的场景;
- 低资源知识库检索:知识库文档覆盖度低时,通过假设文档增强匹配精准度的场景。
十六. 交叉编码器与 ColBERT 模型
1. 基础理论
1.1 交叉编码器(Cross-Encoder)核心概念
交叉编码器是语义检索领域的精准匹配模型 ,其核心逻辑是直接对 "查询 - 文档" 对进行联合编码,捕捉二者的深度上下文交互关系,最终输出 0-1 区间的相关性得分(区别于 Bi-Encoder 的 "独立编码 + 向量匹配" 模式)。
1.2 ColBERT 模型核心概念
ColBERT(Contextualized Late Interaction Over BERT)是一种折中型语义编码模型,核心是 "融合 Bi-Encoder 与 Cross-Encoder 的优势":既保留 Bi-Encoder 的预计算、可扩展性特点,又具备 Cross-Encoder 捕捉查询与文档深度交互的能力,属于 "上下文晚期交互" 架构。
2. 技术架构
2.1 交叉编码器技术架构
2.1.1 核心流程
- 拼接输入:将单个查询与单个文档逐一对接,拼接为 "查询 + 文档" 文本对;
- 联合编码:将拼接后的文本对输入 Cross-Encoder 模型,模型深度理解二者的上下文交互关系;
- 生成得分:直接输出该查询 - 文档对的相关性得分(0-1,得分越高相关性越强)。
2.1.2 关键特点
- 不单独生成查询 / 文档的独立向量,依赖 "查询 - 文档对" 的联合输入;
- 能精准捕捉查询与文档的交互逻辑,匹配精度高于 Bi-Encoder。
2.2 ColBERT 模型技术架构
2.2.1 核心设计思路
- 预计算文档向量:像 Bi-Encoder 一样提前对文档编码,保障检索效率;
- 捕捉深度交互:像 Cross-Encoder 一样,通过 Token 级匹配实现查询与文档的上下文交互。
2.2.2 编码机制
- Token 级向量生成:不为整个查询 / 文档生成单一向量,而是为查询、文档中的每个 Token 单独生成向量;
- 预编码文档:文档的 Token 向量可提前计算存储,查询的 Token 向量在接收到请求后实时生成。
2.2.3 得分计算逻辑
- Token 级匹配:每个查询 Token 的向量,在文档的 Token 向量中寻找最相似的匹配项;
- 综合得分:整合所有查询 Token 的匹配结果,得到最终的查询 - 文档相关性得分。
3. 实践应用
3.1 交叉编码器的典型场景
- 检索结果精排:作为 Bi-Encoder 等粗检索技术的 "后处理环节",提升小批量候选文档的匹配精度;
- 小范围精准匹配:适用于文档数量较少(非百万 / 十亿级)的场景,如特定知识库的定向查询。
3.2 ColBERT 的典型场景
- 近实时大规模检索:需要平衡 "检索质量" 与 "响应速度" 的场景,如企业级知识库、实时问答系统;
- 简化检索流程:以单一模型实现 "粗筛 + 精排" 的效果,替代 Bi-Encoder+Cross-Encoder 的两阶段架构。
十七. 检索结果重排序技术
1. 基础理论
1.1 核心概念
检索结果重排序(Reranking)是检索增强生成(RAG)流程中,介于 "初始检索" 与 "LLM 内容生成" 之间的优化环节:通过精准匹配技术对初始检索得到的候选文档重新排序,提升文档与用户查询的相关性匹配精度,为 LLM 提供更优质的上下文输入。
1.2 重排序的核心目的
- 弥补初始检索的不足:初始检索(如混合搜索)虽高效,但结果精准度有限("Fast but Imprecise");
- 优化 LLM 输入质量:将候选文档重新排序后,仅向 LLM 传递最优的 3-5 个文档,提升最终回答的准确性与相关性。
2. 技术架构
2.1 核心流程
2.1.1 完整链路
用户查询 → 初始检索(从知识库获取候选文档) → 重排序引擎处理 → 输出最优文档顺序 → 传入 LLM 生成内容
2.1.2 各环节作用
- 初始检索:快速筛选出一批候选文档(数量较多,优先保证召回率);
- 重排序:对候选文档进行精准打分与排序(聚焦相关性精度,仅处理少量候选文档)。
2.2 重排序引擎的关键模块
2.2.1 Cross Encoder 模块
利用 Cross Encoder 对 "用户查询 - 候选文档" 对进行联合编码,直接输出二者的相关性得分,再基于得分对候选文档重新排序(核心是捕捉查询与文档的深度上下文交互关系)。
2.2.2 LLM Based Scoring 模块
- 技术逻辑 :使用微调后的 LLM对 "用户查询 - 候选文档" 的相关性进行评估,输出 0-1 区间的相关性得分;
- 特点:匹配精度高,但计算成本与延迟较高,仅适用于 "初始过滤后的少量候选文档" 重排序。
十八. Transformer架构解析
1. 基础理论
1.1 核心组件:Encoder 与 Decoder
- 1.1.1 Encoder 功能处理原始文本(如德语段落),生成文本的深度上下文语义理解;主要用于嵌入模型,以构建丰富的文本语义表示。
- 1.1.2 Decoder 功能利用 Encoder 输出的深度语义理解,生成目标语言文本(如英语翻译);大部分大语言模型(LLM)仅包含 Decoder 组件,因聚焦文本生成任务。
1.2 Attention 机制核心定义
Attention 是确定 "哪些其他 token 对当前 token 的含义影响最大" 的机制;在该机制下,每个 token 可获取其他所有 token 的含义与位置信息。
2. 技术架构
2.1 输入处理:Input Embeddings
将输入文本的每个 token 与对应的位置编码(如 pos_0、pos_1)结合,转换为向量表示(如0.12, 0.87, ..., 0.45),作为 Transformer 的输入。
2.2 Transformer Layers 与 Attention Heads
- 结构Transformer Layers 包含多个 Attention Heads 子模块,是语义处理的核心单元。
- Attention Heads 的功能每个 Head 自主学习文本中的抽象模式(非人工定义规则),例如:
- Head 1:学习物体关系(如 "fox" 与 "brown" 的关联);
- Head 2:学习空间关系(如 "fox" 与 "sat""next" 的关联)。
- Attention Heads 的数量小模型通常使用 8 或 16 个 Attention Heads,大模型可使用超过 100 个。
2.3 迭代优化流程(Iterative Refinement)
流程为:Input Embeddings → Attention → Feed Forward → Updated Token Embeddings,该流程会重复多次(模型通常包含 8 到 64 层),每次迭代逐步优化语义理解(如明确 "dog" 作为主语、关联 "brown" 和 "sat" 等)。
2.4 文本生成流程
- 概率分布预测基于优化后的 Embeddings,模型对词汇表中所有 token 的 "下一个出现概率" 进行排序(如 "and" 占 32%、"in" 占 25% 等)。
- 生成循环每次生成一个 token 后,需重新执行完整流程(从 Input Embeddings 开始),直到达到 token 数量限制或触发结束 token(EOS)。
- 输出处理生成的 token 序列解 token 化后,返回给用户作为最终响应。
3. 实践应用
3.1 组件级应用
- Encoder:用于嵌入模型,提供文本的丰富语义表示,支撑语义检索、文本聚类等任务。
- Decoder:作为 LLM 的核心组件,支持翻译、内容创作、对话交互等文本生成类任务。
3.2 系统级应用:检索增强生成(RAG)
RAG 的工作原理:LLM 通过 Attention 机制处理 prompt 中注入的检索信息,结合前馈层中的通用知识,实现更精准、有依据的内容生成。
十九. LLM 采样策略
1. 基础理论
1.1 采样策略核心定义
LLM 采样策略是文本生成过程中,模型选择 "下一个 token" 的规则体系,决定了生成文本的确定性、多样性与合理性。
1.2 基础采样方法:贪心解码(Greedy Decoding)
- 定义:在文本生成的每一步,始终选择概率最高的 token 的采样策略。
- 核心特点:
- 确定性:相同输入对应固定输出;
- 文本风格:内容偏通用、多样性不足;
- 潜在问题:易陷入循环(如重复 "which the data confirms");
- 适用场景:代码补全、调试等对准确性要求高的场景。
1.3 概率分布调节参数:温度(Temperature)
- 定义:改变 LLM 生成 token 的概率分布形状的参数;
- 不同温度的效果:
- Temperature=0:等价于贪心解码;
- Temperature=0.5:概率分布更 "尖锐"(高概率 token 占比更高);
- Temperature=1:保持模型原始概率分布;
- Temperature=1.2:概率分布更 "平缓"(token 概率差异缩小,多样性提升);
- Temperature=5:概率分布极平缓,易生成无意义内容。
2. 技术架构
2.1 高级采样方法
2.1.1 Top-K 采样
- 定义:仅从概率最高的 k 个 token 中选择下一个 token,忽略其余低概率 token;
- 示例:Top-K=5 时,仅考虑概率排名前 5 的 token。
2.1.2 Top-P 采样(核采样)
- 定义:从 "累积概率低于指定阈值" 的 token 集合中选择下一个 token;
- 示例:Top-P=85% 时,包含 token 直到其累积概率超过 85%。
2.1.3 Top-K 与 Top-P 的对比
- Top-P 更具动态性:
- Top-K:无论概率分布形状如何,始终包含固定数量的 token;
- Top-P:根据模型对当前内容的 "确定性" 调整 token 数量(模型越不确定,包含的 token 越多)。
2.2 Token 特定优化策略
2.2.1 重复惩罚(Repetition Penalties)
- 功能:降低已使用过的 token 的概率,抑制重复内容;
- 作用:防止生成循环、冗余句式、特定词汇过度使用。
2.2.2 对数几率偏差(Logit Biases)
- 定义:直接调整模型原始计算的 token 概率(通过加减数值)的策略;
- 典型应用:
- 过滤脏话(如降低低俗词汇概率);
- 增强分类器 LLM 中的特定类别概率。
3. 实践应用
3.1 场景化参数配置
- 代码 / 事实类场景:选择低温度 + 低 Top-P(优先保证准确性、确定性);
- 创意类场景:探索高温度 + 高 Top-P(优先提升内容多样性、创意性);
- 配置流程:先根据场景设定温度与 Top-P,再按需添加重复惩罚、对数几率偏差等策略。
3.2 特定策略的落地场景
- 重复惩罚:适用于长文本生成(如文章、对话),避免内容冗余;
- 对数几率偏差:适用于内容审核(过滤违规词汇)、分类任务(增强目标类别权重)。
二十. 大语言模型选择方法论
1. 基础理论
1.1 核心定义
大语言模型(LLM)选择方法论是结合 LLM 的技术特征、质量表现、成本效率等维度,匹配业务需求的模型选型框架,核心目标是实现 "能力适配、成本可控、体验达标"。
1.2 模型核心特征维度
1.2.1 模型规模
- 小模型:1 -- 100 亿参数;
- 大模型:100 -- 5000 亿 + 参数;
- 特点:大模型能力更全面,但部署与使用成本更高。
1.2.2 成本
- 计费方式:按 "百万 token" 固定收费(输入与输出 token 的单价可能不同);
- 趋势:新发布、参数规模更大的模型通常成本更高。
1.2.3 上下文窗口
- 定义:模型可同时处理的 "提示词(prompt)+ 生成内容(completion)" 的最大 token 数量;
- 注意:超出窗口的内容无法处理,且仍按实际 token 数计费。
1.2.4 延迟与速度
- 核心指标:首 token 响应时间(用户等待首个内容的时长)、每秒生成 token 数(内容输出效率)。
1.2.5 训练截止日期
- 定义:模型训练数据覆盖的最后时间节点;
- 价值:日期越新,越适合处理近期事件、新信息相关的任务。
1.3 质量评估的核心分类
- 不存在单一权威的 LLM 质量评估列表,主流分为三类:自动化基准、人工评估基准、LLM-as-a-judge 基准。
2. 技术架构:质量评估的基准模块
2.1 自动化基准
- 核心逻辑:通过代码执行的标准化评估,常见形式为多学科选择题测试。
- 典型示例:MMLU(覆盖 57 个从 STEM 到人文领域的学科)。
- 特点:高效、客观、标准化,适用于知识储备、逻辑推理等能力的初步筛选。
2.2 人工评估基准
- 流程:让匿名 LLM 对同一 prompt 生成响应,由人类选择偏好的结果,通过 ELO 算法生成模型能力排行榜。
- 典型示例:LLM Arena(主流的人工分级排名平台)。
- 特点:能捕捉自动化基准遗漏的 "细微质量"(如表达流畅性、内容相关性)。
2.3 LLM-as-a-judge 基准
- 流程:用一个 LLM 作为 "评委",将目标模型的响应与参考答案对比,输出 "胜率" 以衡量性能。
- 优劣势:成本低、灵活性高,但存在 "评委偏向自家模型" 的固有偏见。
2.4 优质基准的特质
- 与项目需求强相关;
- 能有效区分高低性能模型;
- 结果可复现(测试间输出稳定);
- 与实际业务场景的性能对齐;
- 需规避数据污染(避免模型训练时见过基准题目)。
3. 实践应用:模型选择流程
3.1 需求匹配核心特征
- 知识密集型任务(如行业问答):优先选大模型 + 训练截止日期较新的模型;
- 低延迟场景(如实时客服):优先选小模型 + 高每秒 token 生成速度的模型;
- 长文本处理(如文档总结):优先选大上下文窗口的模型。
3.2 选择适配的质量基准
- 知识类任务:采用自动化基准(如 MMLU)评估知识储备;
- 交互 / 创作类任务:采用人工评估基准(如 LLM Arena)评估内容体验;
- 低成本快速评估:采用 LLM-as-a-judge 基准完成初步筛选。
3.3 成本 - 性能平衡决策
在满足 "核心特征 + 质量基准" 要求的前提下,结合模型的 token 计费标准、部署成本,选择性价比最优的模型。
二十一. 提示词工程 - 增强指令构建
1. 基础理论
1.1 增强指令的核心载体:消息格式(Messages Format)
核心字段
- Content:消息的文本内容;
- Role:消息对应的角色,仅支持 "system""user""assistant" 三类。
角色定义
- System:提供高层指令,用于定义并影响 LLM 的行为逻辑;
- User:记录用户发送的提示内容;
- Assistant:记录 LLM 此前生成的响应内容。
1.2 增强指令的核心单元:系统提示词(System Prompt)
定义:为 LLM 提供行为准则的高层指令集合,包含语气要求与执行流程规范。
核心组成维度:
- 高层指令(High-Level Instructions):定义 LLM 的基础行为(如知识截止日期后的信息处理规则);
- 语气与人格(Tone & Personality):定义 LLM 的沟通方式、安全约束、输出格式、交互风格等。
2. 技术架构
2.1 消息格式的结构规范
- 以 "messages" 数组为容器,每个元素是包含 "role" 和 "content" 的对象,按交互时序排列(系统指令通常置于数组首位)。
2.2 系统提示词的模块架构
- 高层指令模块:明确 LLM 的基础行为边界(如知识截止后的信息响应规则);
- 语气与人格模块:覆盖沟通语气(如分步推理)、安全规则(如拒绝有害请求)、输出格式(如 Markdown)、交互偏好(如好奇型互动)。
2.3 增强指令的整合框架:提示词模板(Prompt Template)
- 结构化整合三类信息:
- 系统指令(System Instructions):行为准则类内容;
- 对话历史(Conversation History):过往的 user/assistant 交互记录;
- 检索信息(Retrieved Information):外部获取的文档片段及来源(如 RAG 场景)。
3. 实践应用
3.1 系统提示词的构建原则
- 响应风格控制:明确要求 LLM 输出 "详细内容" 或 "简洁回答";
RAG 场景专属指令:
- 仅使用检索到的文档内容回答;
- 自主判断文档与问题的相关性;
- 在响应中引用信息来源;
全局生效规则:系统提示词会附加到 LLM 处理的每一条提示中。
3.2 提示词模板的典型应用场景
- 适用于需整合多源信息的任务(如 RAG 应用):通过模板统一系统指令、对话上下文、外部检索内容的输入结构,提升 LLM 响应的相关性与准确性。
二十二. 高级提示词工程技术
1. 基础理论
1.1 核心定位
高级提示词工程是在基础提示词基础上,通过示例嵌入、推理引导、上下文优化等技术,提升大语言模型(LLM)响应的准确性、一致性与场景适配性的方法体系。
1.2 核心子技术的基础定义
上下文学习(In Context Learning):在提示词中嵌入问答示例,让 LLM 学习响应的结构、语气与逻辑的技术。
推理增强技术:引导 LLM 分步推导,以提升复杂任务(如逻辑解释、多步骤问题)准确性的技术。
上下文窗口管理:优化提示词中上下文内容的占用,平衡信息完整性与 LLM 上下文容量的策略。
2. 技术架构
2.1 上下文学习的技术模块
样本类型
- 单样本学习(One-shot):仅嵌入 1 个问答示例;
- 少样本学习(Few-shot):嵌入多个问答示例。
基础实现方式:将示例硬编码(Hard-coding)到提示词中。
检索增强式上下文学习流程为:索引优质对话(如成功的客服聊天)→ 检索与当前请求相关的信息 → 将示例注入提示词。
2.2 推理增强的技术模块
思维链(Chain Of Thought)流程:输入问题 → 生成推导步骤 → 遵循步骤推导 → 输出最终结果;核心是让 LLM "出声思考"(Think aloud),分步解释推理过程。
推理标记(Reasoning Tokens)LLM 在响应中记录的推导中间内容(如 "雪 = 白色→反射阳光"),用于支撑最终结论的合理性。
推理模型特性推理标记可提升准确性,但会增加 token 消耗(提升成本)、降低响应速度;在 RAG 场景中能增强信息相关性与整合效果。
2.3 上下文窗口管理的技术模块
高级场景的上下文结构推理模型 + RAG 场景下,上下文包含:初始提示词 + 推理标记 + RAG文档片段 + 响应标记。
上下文修剪(Context Pruning)移除无价值内容的策略:单轮对话中跳过无价值的提示技术、多轮对话中移除旧消息(如仅保留最近 5 条)、推理模型中移除历史推理标记。
相关块筛选仅保留与最新问题相关的内容块,避免冗余信息占用窗口。
3. 实践应用
3.1 上下文学习的应用
- 客服机器人嵌入过往客户请求与优质响应示例,统一回复的格式、语气(如包含客户姓名、订单号的标准化回复)。
- 标准化任务如格式转换、分类任务,通过示例定义输出结构(如 "输入:A;输出:类别 X")。
3.2 推理增强的应用
- 复杂逻辑问答如解释 "雪天戴墨镜的原因",通过分步推理(雪→反射阳光→含紫外线→墨镜防护)提升逻辑完整性。
- RAG 场景提升 LLM 对检索文档的整合能力与结论的相关性。
3.3 上下文窗口管理的应用
- 多轮对话通过修剪旧消息,避免上下文窗口溢出,同时保留关键交互信息。
- 长内容任务使用长上下文模型支撑深度多轮对话,同时仅注入相关内容块,保持提示词高效。
二十三. 幻觉处理机制
1. 基础理论
1.1 幻觉的核心概念
- 定义:大语言模型(LLM)生成内容中出现的事实矛盾、虚构信息的现象(图片中明确 "事实不一致可体现幻觉");
- 影响:降低输出内容的可信度,可能误导用户决策。
1.2 幻觉处理的方法分类
- 检测类:通过验证内容一致性识别幻觉;
- 抑制类:通过外部信息约束 LLM 生成事实内容;
- 验证类:通过引用、评估体系提升内容的可验证性。
1.3 基础检测方法:自一致性方法
- 定义:对同一提示重复生成多个响应,通过检查响应间的事实一致性,判断是否存在幻觉的技术。
2. 技术架构
2.1 幻觉检测模块:自一致性方法
- 流程:重复生成同一提示的响应 → 对比响应中的事实信息 → 存在矛盾则判定为幻觉;
- 局限性:实际应用中成本高 (多次调用 LLM)、可靠性不足(一致的响应也可能是共同幻觉)。
2.2 幻觉抑制模块:基于 RAG 的事实锚定
- 流程:
- 检索与用户请求相关的文档;
- 将文档中的事实信息注入提示词;
- 通过系统提示约束 LLM "仅基于检索信息生成事实性内容"(图片核心约束逻辑);
- 效果:减少无依据的虚构内容,提升输出的事实准确性。
2.3 验证增强模块:引用技术
2.3.1 基础引用生成(Citation Generation)
- 方法:通过系统提示指令 LLM 在每个句子 / 段落末尾标注来源(如12);
- 作用:提升内容可验证性,便于人工核对事实;
- 局限性:LLM 可能虚构引用(图片明确 "LLMs 可幻觉式生成引用")。
2.3.2 上下文引用(ContextCite)
功能:
- 将响应中的句子与检索到的文档关联;
- 为句子标记对应的支撑文档;
延伸作用:可生成精准引用,或作为幻觉评估依据(如识别对文档的误解释)。
2.4 幻觉评估模块:ALCE 基准
组成:预构建的知识库 + 样本问题;
评估对象:RAG 系统的响应;
核心指标:
- 流畅性(Fluency):内容的清晰与通顺程度;
- 正确性(Correctness):内容的事实准确程度;
- 引用质量(Citation Quality):引用与正确来源的契合程度。
3. 实践应用
3.1 客服场景
- 应用:通过 RAG 检索企业政策文档,结合系统提示抑制 LLM 虚构优惠 / 规则(如图片中 "老年折扣" 的准确回复);
- 价值:避免因幻觉导致的服务纠纷。
3.2 知识问答场景
- 应用:结合 ContextCite 为回答关联知识库来源,同时通过 ALCE 基准评估回答的事实准确性;
- 价值:提升专业知识输出的可信度,便于用户验证信息。
3.3 内容创作场景
- 应用:通过基础引用生成标注信息来源,辅助创作者核对事实;
- 价值:降低内容中的事实错误风险。
二十四. 大模型性能评估
1. 基础理论
1.1 评估的核心定位
大模型性能评估是衡量其在特定系统(如 RAG)中履行实际职责的效果,需与模型在系统中的角色强绑定,而非孤立评估模型能力。
1.2 RAG 系统中 LLM 的核心职责
- 前提假设:检索器会返回相关信息(可能混杂少量无关文档);
- 具体职责:清晰生成响应、整合相关信息、引用信息来源、忽略无关内容;
- 特性:这些职责存在一定主观性,难以用绝对客观的标准定义。
1.3 评估的核心思路
- 直接评估:聚焦 LLM 自身职责,设计匹配其任务的专项指标(如 RAGAS 体系);
- 间接评估:通过系统整体的性能反馈,推断 LLM 对系统表现的影响。
2. 技术架构
2.1 直接评估:RAGAS 指标体系
RAGAS 是针对 RAG 系统中 LLM 性能的专用评估框架,核心指标包括:
2.1.1 响应相关性(Response Relevancy)
定义:衡量 LLM 响应与用户 prompt 的关联程度(不关注内容的事实准确性);
评估流程:
- 由评估 LLM 生成若干 "可导出当前响应的样本 prompt";
- 将原始 prompt 与样本 prompt 转换为向量,计算两两之间的余弦相似度;
- 对相似度得分取平均值,作为最终的相关性指标;
特点:仅验证 "从响应反向匹配 prompt" 的关联度,不检查内容的事实性。
2.1.2 忠实性(Faithfulness)
定义:衡量 LLM 响应与检索到的信息的一致性;
评估流程:
- 识别响应中所有的事实主张;
- 通过 LLM 调用,判断每个主张是否被检索信息支撑;
- 被支撑的主张占比,即为忠实性得分;
特点:直接约束 LLM 基于检索信息生成内容,是抑制幻觉的核心评估指标。
2.1.3 其他 RAGAS 指标
- 覆盖维度:噪声敏感性、引用质量等;
- 共性特点:因 LLM 职责复杂,所有指标均在一定程度上依赖 "LLM-as-a-judge"(以其他 LLM 作为评估者)。
2.2 间接评估:系统级反馈与测试
- 核心思路:通过系统整体表现推断 LLM 性能;
- 具体方法:
- 收集系统级用户反馈(如点赞 / 点踩);
- 开展 A/B 测试:对比不同 LLM 版本的系统表现,需隔离 LLM 的变化,确保结果仅反映其影响。
3. 实践应用
3.1 RAG 场景的 LLM 专项评估
- 适用场景:知识问答、智能客服等 RAG 落地场景;
- 应用方式:用 "响应相关性" 评估 LLM 是否贴合用户需求,用 "忠实性" 评估 LLM 是否基于检索信息生成内容,减少幻觉风险。
3.2 产品级 LLM 性能评估
- 适用场景:面向终端用户的 LLM 集成产品(如对话机器人);
- 应用方式:通过用户的点赞 / 点踩反馈、A/B 测试(对比不同 LLM 版本的产品体验),间接评估 LLM 对产品效果的影响。
二十五. 自主式 RAG 系统
1. 基础理论
1.1 核心定义
自主式 RAG 系统是融合 Agent 自主决策能力与 RAG 信息检索能力的系统,通过多个专用大语言模型(LLM) 分工执行任务,自主完成复杂需求的处理(如拆分任务、调用工具、优化结果)。
1.2 核心思路
将复杂任务拆解为多个步骤,为每个步骤分配专用 LLM 或外部工具,通过工作流逻辑串联各环节,实现任务的自动化拆分、执行与优化。
2. 技术架构
2.1 核心功能模块
以 "智能客服" 场景的示例系统为例,核心模块包括:
- Router LLM:接收用户请求,判断是否需要调用 RAG(如 "是否需要检索知识库"),实现任务路由。
- Knowledge Base:存储待检索的事实性信息(如企业政策),为 RAG 提供数据支撑。
- Retriever:从知识库中检索与请求相关的文档片段。
- Evaluator LLM:评估检索文档的相关性,决定是否需要重新检索。
- LLM+ Citation LLM:基于检索文档生成响应,并完成信息来源的引用标注。
2.2 系统本质:工作流流程图
- 每个 LLM 负责任务流中一个特定环节,以文本为输入 / 输出完成单步任务;
- 模型选型策略:
- 轻量级模型:用于路由、评估等简单任务;
- 大模型:用于响应生成等复杂任务;
- 专用模型:用于引用标注等细分功能。
2.3 典型工作流类型
- 顺序工作流:按固定步骤依次调用不同 LLM(如parser→re-writer→citation→...),适用于流程固定的任务。
- 条件工作流:通过 Router LLM 根据请求内容选择分支(如 "调用检索器 / 直接调用 LLM / 调用 Agent"),适用于动态分支的任务。
- 迭代工作流:通过LLM writer生成内容→LLM evaluator评估反馈→多次迭代优化,适用于需要质量打磨的任务。
- 并行工作流:由 Orchestrator 分配任务给多个 LLM Agent 并行处理,再由 Synthesizer 整合结果,适用于多子任务同步执行的场景。
3. 实践应用
3.1 典型场景
- 智能客服:处理 "是否提供学生折扣" 类请求,通过 Router 判断检索需求、Evaluator 验证文档相关性,最终生成带引用的响应。
- 复杂内容创作:通过顺序工作流 完成 "解析需求→改写内容→添加引用";通过迭代工作流优化内容质量。
- 多维度信息整合:通过并行工作流同步完成多个子任务(如多领域信息检索),提升处理效率。
3.2 实现方式
- 简单系统:手动编写工作流逻辑(如少量步骤的顺序 / 条件流程)。
- 复杂系统:借助专用工具、库或平台(如 Agent 框架)构建与管理工作流。
二十六. RAG 与微调技术比较
1. 基础理论
1.1 微调(Fine-Tuning)核心概念
- 定义:通过自有数据重新训练大语言模型(LLM),更新其内部参数的技术;
- 实现方式:监督微调(SFT)
- 基于标注示例重新训练模型;
- 指令微调:教会模型遵循任务要求的行为;
- 核心特点:主要优化 LLM 的 "输出方式",而非新增知识。
1.2 RAG(检索增强生成)核心概念
- 定义:通过检索外部知识库的相关信息并注入提示词,辅助 LLM 生成响应的技术;
- 核心特点:为 LLM 补充 "知识内容"(如新信息、事实性数据),不改变模型内部参数。
1.3 核心差异
- 微调:聚焦 "如何输出"(优化行为方式);
- RAG:聚焦 "输出依据"(补充知识内容)。
2. 技术架构
2.1 微调的技术流程
- 步骤 1:向模型喂入任务指令;
- 步骤 2:将模型输出与正确答案对比;
- 步骤 3:调整模型内部参数以优化输出匹配度。
2.2 RAG 的技术架构
- 核心模块:知识库(存储信息)、检索器(查找相关内容)、LLM(结合检索内容生成响应);
- 流程:接收用户请求→检索知识库→将相关信息注入提示词→LLM 生成响应。
3. 实践应用
3.1 微调的适用场景
- 领域专业化任务:如初步医疗诊断、法律简报总结;
- 窄场景任务:Agent 系统中小模型的特定任务优化;
- 单一聚焦任务:需要统一任务遵循行为的场景。
3.2 RAG 的适用场景
- 需要新信息的任务:LLM 训练数据未覆盖的内容(如近期事件);
- 事实性内容生成:需基于外部知识库确保准确性的场景。
3.3 两者结合的场景
- 模式:RAG 提供当前、准确的信息,微调优化 LLM 对这些信息的使用方式;
- 价值:兼顾知识的新鲜度与输出的专业性。
二十七. 生产部署的挑战
1. 基础理论
1.1 核心定义
生产部署的挑战是指大语言模型(尤其是 RAG 系统)从测试环境落地到实际业务场景时,因环境复杂性、用户交互不确定性、数据特性等因素产生的各类适配与运行问题,核心目标是解决 "测试性能" 到 "生产可用性" 的 gap。
1.2 核心挑战分类
- 性能扩展挑战:流量增长引发的系统延迟、负载上升及成本增加问题,核心矛盾是 "高流量" 与 "高性能" 的平衡。
- 提示词不可预测性挑战:用户请求的多样性与创造性导致的请求类型无法完全覆盖问题,核心矛盾是 "预设测试场景" 与 "实际用户交互" 的差异。
- 现实数据杂乱挑战:业务数据的碎片化、非文本化(如 PDF、幻灯片)及元数据缺失问题,核心矛盾是 "理想结构化数据" 与 "实际非结构化数据" 的适配。
- 安全与隐私挑战:RAG 系统处理专有 / 敏感数据时的隐私保护与授权访问问题,核心矛盾是 "数据可用性" 与 "信息安全性" 的平衡。
2. 技术架构:挑战对应的核心模块
2.1 性能扩展的资源架构模块
- 核心组件:计算资源池、负载均衡器、内存管理单元;
- 作用:支撑流量波动下的系统运行,但流量增长会直接提升该模块的延迟、负载及资源成本。
2.2 提示词不可预测性的请求处理模块
- 核心组件:请求接收接口、意图识别单元;
- 局限:无法通过测试覆盖所有用户请求类型,需应对非预期请求的处理逻辑。
2.3 现实数据杂乱的数据处理模块
- 核心组件:多格式数据提取工具(针对 PDF、幻灯片等)、数据清洗单元;
- 作用:将非文本、碎片化数据转换为知识库可使用的格式,但需适配各类杂乱数据的特性。
2.4 安全与隐私的安全架构模块
- 核心组件:数据加密单元、权限控制接口;
- 设计原则:需实现 "隐私原生" 的架构,在保障授权访问的同时避免敏感数据泄露。
3. 实践应用:挑战对应的业务场景
3.1 性能扩展挑战:高流量业务系统
- 场景:电商客服、大规模用户问答等高并发 RAG 系统;
- 表现:峰值流量时系统响应延迟增加,资源成本显著上升。
3.2 提示词不可预测性挑战:开放用户交互场景
- 场景:公开的 AI 聊天机器人、用户自由提问的知识问答系统;
- 表现:用户提出非预期请求(如 "我该吃多少块石头"),需系统具备合理的兜底处理逻辑。
3.3 现实数据杂乱挑战:企业多格式文档 RAG 系统
- 场景:基于企业内部 PDF、幻灯片、图片类资料构建的 RAG 知识库;
- 表现:需先通过提取工具处理非文本数据,才能支撑后续的检索与生成。
3.4 安全与隐私挑战:敏感领域 RAG 系统
- 场景:金融客户数据查询、医疗病历辅助分析的 RAG 系统;
- 要求:系统需原生支持敏感数据的隐私保护,同时保障授权用户的正常访问。
二十八. RAG 评估策略标准
1. 基础理论
1.1 核心定义
RAG 评估策略是衡量检索增强生成(RAG)系统性能、输出质量与用户体验的标准化方法体系,核心目标是识别系统问题、验证优化效果。
1.2 核心指标分类
- 软件性能指标:聚焦系统运行效率,跟踪延迟、吞吐量、内存占用、计算资源使用等量化维度;
- 质量指标:聚焦输出与用户体验,衡量用户满意度、系统输出的准确性与合理性。
2. 技术架构
2.1 评估跟踪方式
- 聚合统计:跟踪长期趋势,识别系统性能的退化问题;
- 详细日志:追踪单个提示在 RAG 流程中的全链路轨迹,定位具体环节的问题;
- 实验验证:通过 A/B 测试对比系统变更的效果,运行安全可控的优化实验。
2.2 评估者类型
代码型评估者
- 特点:成本最低、实现最简单;
- 适用场景:记录每秒处理的提示数、验证 JSON 输出格式的单元测试。
LLM 作为裁判(LLM-as-a-Judge)
- 特点:平衡成本与灵活性,比代码型更灵活、比人类反馈更便宜;
- 适用场景:判断检索文档与提示的相关性,需依赖清晰的评估规则(如 "相关 / 不相关" 标签)。
人类反馈
- 特点:成本最高,但能覆盖代码和 LLM 遗漏的主观质量维度;
- 形式:点赞 / 点踩评分、详细文本反馈、预编译测试数据集、人工质量评估。
2.3 评估范围
- 组件级评估:针对 RAG 单个模块(如检索器),识别问题的具体位置与原因(如 "检索器延迟");
- 系统级评估:针对端到端全流程,识别系统整体存在的问题(如 "端到端延迟")。
2.4 细分指标体系
软件性能指标:延迟、吞吐量、内存使用、每秒 token 数;
质量指标:
- 检索器相关:人类标注数据集、召回率 & 精确率;
- LLM(RAGAS)相关:响应相关性、引用质量、噪声过滤;
- 综合质量:人类标注、LLM 作为裁判、点赞 / 点踩、响应质量。
3. 实践应用
3.1 组件级优化场景
- 检索器性能调优:通过代码型评估者跟踪 "检索器延迟",结合人类反馈评估 "检索文档相关性",定位检索模块的效率与质量问题。
3.2 系统级监控场景
- 端到端性能保障:通过 "聚合统计" 跟踪整体延迟、吞吐量的长期趋势,及时识别系统性能退化。
3.3 输出质量提升场景
- 响应准确性优化:用 "LLM 作为裁判" 评估 "引用准确性",结合人类的 "详细文本反馈",打磨系统输出的合理性与专业性。
二十九. 日志监控与可观测性
1. 基础理论
1.1 核心定义
日志监控与可观测性(以 LLM 场景为例)是针对大语言模型(尤其是 RAG 系统)的全生命周期管理体系,核心载体是LLM 可观测性平台------ 这类平台聚焦于捕获系统级 / 组件级指标、记录系统流量、支持实验验证,典型代表为 Arize 推出的开源平台 Phoenix。
1.2 核心目标
实现对 LLM 系统(从原型到生产环境)的全链路状态监控、问题定位与迭代优化,覆盖性能、质量、流量等多维度的管理需求。
2. 技术架构
2.1 核心工具体系
LLM 专用可观测性平台:如 Phoenix,核心能力包括:
- 捕获系统级与组件级的指标数据;
- 记录系统的流量信息;
- 支持基于新系统设置的实验验证。
传统监控工具:如 Datadog、Grafana,用于补充 LLM 专用平台的覆盖缺口,满足通用监控需求(如服务器资源、通用流量等)。
2.2 关键功能模块
全链路追踪(Traces)
- 功能:跟踪单个 prompt 在 RAG 全流程中的路径;
- 展示信息:初始文本 prompt、发送给检索器的查询、检索器返回的 chunk、重排器的处理结果、最终给 LLM 的 prompt、生成的响应、各环节延迟;
- 价值:分析每个步骤对 prompt 最终性能的影响,定位流程中的问题环节。
实验与报告模块
- 功能:
- 交互式测试系统的 prompt;
- A/B 测试系统变更(如 prompt 模板调整)的效果;
- 生成关键系统指标的定期报告。
3. 实践应用
3.1 RAG 系统的全链路问题定位
通过 Traces 功能追踪 prompt 的流转路径,定位检索、重排、LLM 生成等环节的性能瓶颈(如检索延迟过高)或质量问题(如检索 chunk 相关性不足)。
3.2 系统优化的实验验证
利用实验模块开展 A/B 测试,对比不同系统设置(如 prompt 模板、检索策略)的效果,结合报告中的指标(如 ROUGE 得分)评估优化价值。
3.3 生产环境的综合监控
组合 LLM 专用可观测平台与传统监控工具,同时覆盖 LLM 系统的专用指标(如 prompt 处理延迟)与通用指标(如服务器内存占用),实现生产环境的全面监控。
三十. 定制化评估体系
1. 基础理论
1.1 核心定义
定制化评估体系是基于定制数据集,结合系统全链路数据开展的针对性评估方法,核心目标是精准定位系统问题、匹配业务场景的优化需求。
1.2 定制数据集的核心特性
- 数据构成:系统过往接收的 prompt 及其在系统中流转的信息集合;
- 存储灵活性:对存储的数据类型有极高的自由度;
- 评估关联性:存储的内容直接决定可开展的评估类型;
- 数据默认项:prompt 与响应是支撑系统级评估的基础数据,详细评估需补充各组件的流转数据;
- 规模风险:数据集易快速膨胀,需关注存储与管理成本。
2. 技术架构
2.1 核心模块
2.1.1 定制数据集模块
- 功能:存储 prompt、响应、组件流转数据等信息,是定制化评估的基础数据载体。
2.1.2 多维度分析模块
- 主题性能分析:按业务主题(如退款、账户设置)统计响应质量,识别不同主题的性能差异;
- 组件性能分析:评估系统各模块的关键指标(如上下文精度、回答相关性、检索 chunk 数量等),定位组件级问题。
2.1.3 日志分析模块
- 功能:检查请求的 prompt 流转路径,定位系统流程中的错误(如路由分类错误)。
2.1.4 数据可视化与聚类模块
- 可视化:展示系统性能的宏观趋势,辅助快速识别异常;
- 聚类工具:识别系统的使用趋势,支持按请求簇进行分群评估。
3. 实践应用
3.1 业务主题的性能优化
通过 "主题性能分析" 识别薄弱业务主题(如 "产品延迟" 类请求响应质量仅 58%),结合 "组件性能分析" 定位根因(如检索 chunk 数量不足),针对性优化检索策略。
3.2 系统流程错误的修复
结合用户反馈(如图表质量低)与 "日志分析",定位路由 LLM 的分类错误(将图表请求误路由至扩散模型),更新系统 prompt 调整路由逻辑(将图表请求路由至图表生成器)。
3.3 系统使用趋势的洞察
通过 "聚类工具" 分析用户请求的分布趋势,匹配资源分配与优化重点(如高频请求主题优先优化)。
三十一. 模型量化技术
1. 基础理论
1.1 核心定义
模型量化是通过压缩大语言模型(LLM)、嵌入模型等 AI 模型参数的位宽,以降低内存占用、计算成本的技术,核心目标是在最小化性能损失的前提下,实现模型的轻量化部署与高效运行。
1.2 核心价值
- 量化前:模型(LLM / 嵌入)尺寸大、内存与计算资源消耗高;
- 量化后:模型体积更小、运行速度更快、部署成本更低,同时质量或检索相关性的损失处于可控范围。
1.3 LLM 量化的核心逻辑
- 典型 LLM 的参数位宽为 16 位,模型参数规模达 10 亿~1 万亿级,内存占用量极高;
- 量化技术将参数压缩为 8 位或 4 位等效值,大幅缩减模型的内存占用 footprint。
2. 技术架构
2.1 主流量化类型
2.1.1 8 位 / 4 位整数量化
- 技术特点:实现方式简单,属于轻量级量化方案;
- 性能表现:
- 嵌入模型:recall@K 等检索基准指标仅下降数个百分点;
- LLM:标准能力基准测试分数仅出现轻微下降;
- 核心优势:以极小的性能损失,换取内存与计算成本的大幅降低。
2.1.2 1 位量化(针对嵌入模型)
- 技术特点:将参数压缩为二进制值(仅 0 或 1),模型尺寸压缩 32 倍;
- 性能表现:检索或推理性能下降较为明显;
- 适配策略:采用 "快速 1 位检索 + 全精度重排" 的混合流程,平衡检索速度与结果相关性。
2.1.3 套娃量化(Matryoshka Quantization)
- 技术逻辑:将向量维度按信息重要性排序(早期维度包含更多区分性信息);
- 灵活检索方式:
- 选择部分维度(如前 100 维)实现快速检索;
- 采用 "短向量快速搜索 + 全向量精准重排" 的分阶段策略,兼顾检索效率与结果精度。
量化的通用技术流程(学术界 / 工业界公认步骤):
- 校准:使用验证集数据统计模型参数的分布特征;
- 量化:将高比特参数映射为低比特值(如 16 位→8 位);
- (可选)量化感知训练:在模型训练阶段引入量化误差,提升量化后模型的鲁棒性。
3. 实践应用
3.1 资源受限设备的模型部署
将量化后的 LLM / 嵌入模型部署于嵌入式设备、边缘计算节点等资源有限的环境(如 8 位量化 LLM 适配手机端智能助手应用)。
3.2 RAG 系统的检索环节优化
- 采用 1 位量化嵌入模型,实现大规模知识库的毫秒级快速检索;
- 搭配全精度重排模块修正检索结果,在保证检索速度的同时,维持结果的相关性。
3.3 大规模 LLM 的成本控制
对 10 亿级以上参数的 LLM 进行 4 位 / 8 位量化,降低服务器内存占用与计算资源消耗,适配大规模业务场景(如企业级对话机器人)的部署需求。
三十二. 成本与响应质量的平衡
1. 基础理论
1.1 核心定义
是针对 RAG 系统的成本控制体系,聚焦于平衡两大核心成本(向量数据库的存储 / 查询成本 、大语言模型的推理 / 生成成本)与系统响应质量,核心目标是在成本可控的前提下,避免响应质量出现显著下降。
1.2 平衡的核心逻辑
通过针对性技术优化策略,在 "降低资源投入" 与 "维持响应质量" 之间找到适配业务场景的平衡点 ------ 既不盲目压缩成本导致质量滑坡,也不过度投入资源造成浪费。
2. 技术架构
2.1 LLM 成本优化策略
2.1.1 采用更小的模型
- 使用小尺寸核心模型,或在 Agent 组件中部署小模型;
- 模型可原生为小尺寸,或通过量化技术压缩体积;
- 将小模型微调至单一特定任务,提升任务适配性以弥补模型尺寸的性能差距。
2.1.2 缩减 Prompt 规模
- 减少检索文档数量(降低top_k值),减少 prompt 中的上下文内容;
- 通过系统 prompt 引导更精简的响应,或直接设置回复的 token 数量限制。
2.1.3 专用端点部署模型
- 选择云服务商(如 AWS、Google Cloud、together.ai)提供的专用端点;
- 专用端点仅服务自身应用流量,按 GPU 小时付费(替代按 token 的 API 计费),适配大规模请求场景。
2.2 向量数据库成本优化策略
2.2.1 存储分层管理
- RAM:速度最快、成本最高,用于存储 HNSW 索引以保障快速检索;
- SSD 磁盘:速度适中、成本较低,用于存储访问频率较低的向量;
- 云对象存储:速度最慢、成本最低,用于存储文档内容。
2.2.2 多租户管理
- 按所属用户拆分数据库中的文档,每个租户拥有独立 HNSW 索引;
- 动态将租户数据迁移至 RAM 或低速存储,提升资源利用效率。
2.2.3 按需加载与时区优化
- 按需加载:仅在需要时将租户数据加载至 RAM;
- 时区优化:仅在租户所在区域的日间活跃时段,将其数据迁移至高速存储。
3. 实践应用
3.1 企业智能客服 RAG 系统
- LLM 侧:用量化小模型处理请求路由,用微调小模型回复常见问题,核心复杂回复用大模型;
- Prompt 侧:将检索top_k从 10 缩减至 5,同时用系统 prompt 引导精简回复;
- 价值:降低了 LLM 调用与 prompt 的 token 成本,同时维持了客服回复的准确性。
3.2 多租户知识库系统
- 向量数据库侧:采用 "多租户管理 + 时区优化",低活跃租户数据存于 SSD / 对象存储,仅在其活跃时段加载至 RAM;
- 价值:在保障各租户检索速度的前提下,大幅降低了向量数据库的存储成本。
三十三. 时延与响应质量平衡
1. 基础理论
1.1 核心定义
时延是 RAG 系统完成请求处理的响应延迟;"时延与响应质量平衡" 是在降低系统延迟的前提下,维持或小幅牺牲响应质量,适配业务的体验与效率需求。
1.2 RAG 系统的时延构成
RAG 流程的时延分为三个环节:
- Query Processing(请求处理)
- Retrieval(检索)
- LLM Generation(LLM 生成)其中,LLM 生成是主要时延瓶颈(核心来自 transformer 计算),检索与数据库环节的时延相对高效。
2. 技术架构
2.1 LLM 时延优化策略
- 2.1.1 小尺寸 / 量化 LLM:在相同硬件条件下,小模型或经量化压缩的 LLM 运行速度更快,直接减少生成环节的时延。
- 2.1.2 Router LLM:通过路由 LLM 判断请求流程,跳过不必要的步骤(如无需检索的请求直接调用 LLM),避免冗余环节增加时延。
2.2 缓存优化策略
- 2.2.1 直接缓存:对相似请求(通过相似度匹配)直接返回缓存的响应,完全跳过 LLM 生成环节,大幅降低时延。
- 2.2.2 个性化缓存:将缓存响应与用户请求传入小而快的 LLM,调整内容以提升响应的相关性,兼顾时延与质量。
2.3 检索时延优化策略
- 2.3.1 量化嵌入:使用二进制 / 低比特量化的向量,提升检索计算的效率。
- 2.3.2 数据库分片:将大索引拆分到多个实例,降低单实例的检索压力。
- 2.3.3 利用服务商工具:依托向量数据库平台的原生优化功能,简化检索时延的调优。
3. 实践应用
3.1 智能客服场景
- 用 Router LLM 识别无需检索的常见请求(如 "重置密码"),跳过检索环节;
- 对高频请求启用直接缓存,相似度达 95% 以上时直接返回缓存响应,将响应时延从秒级压缩至毫秒级。
3.2 大规模企业知识库场景
- 采用 "量化嵌入 + 数据库分片" 优化检索时延,保障百万级文档知识库的检索速度;
- 结合个性化缓存,用小 LLM 调整缓存内容,既维持了响应速度,又避免了缓存内容与用户需求的偏差。
三十四. 安全防护机制
1. 基础理论
1.1 核心定义
是针对 RAG(检索增强生成)等 AI 系统的敏感数据、知识库安全的防护体系,核心目标是防止未授权访问、数据泄露与恶意攻击,保障数据的保密性与访问可控性。
1.2 核心安全风险类型
- 知识库泄露:恶意用户通过精心构造的提示词,获取知识库中的敏感信息(如企业 Q4 收入预测);
- 租户数据隔离不足:多租户场景下不同用户的数据未有效隔离,导致越权访问;
- LLM 数据泄露:包含知识库内容的增强提示传入 LLM 后,会失去对数据安全的控制;
- 数据库黑客攻击:知识库与传统数据库类似可被直接攻击,且向量数据库需在解密内存中存储向量(满足 ANN 算法运行要求),增加了数据暴露风险;
- 向量重建风险:近期研究显示,黑客可从非加密的密集向量中重建原始文本。
2. 技术架构
2.1 知识库泄露防护
- 核心策略:用户身份验证,确保仅授权用户能访问对应权限的信息。
2.2 数据租户隔离策略
- 单独租户模式:每个用户仅能访问自身授权的数据库,实现物理级数据隔离;
- 单一数据库模式:所有文档存储在同一数据库,通过元数据过滤实现逻辑级租户数据隔离。
2.3 LLM 数据泄露防护
- 核心策略:全本地 / 本地部署 RAG 系统,避免敏感数据(含增强提示)流向外部 LLM。
2.4 数据库黑客攻击防护
- 文本块加密:按需加密文本块,在构建提示时再解密;
- 安全 - 复杂度平衡:在添加防护措施的同时,控制系统时延等性能损耗。
2.5 向量重建风险缓解技术
- 向密集向量中添加噪声;
- 对向量执行变换处理;
- 降低向量维度(同时保留向量间距离,保障检索效果)。
3. 实践应用
3.1 企业敏感知识库场景
采用 "用户身份验证 + 单独租户模式",防止恶意用户获取财务预测、核心业务数据等敏感信息。
3.2 多租户 SaaS 知识库场景
采用 "单一数据库 + 元数据过滤",在控制部署成本的同时,实现不同租户数据的逻辑隔离。
3.3 高敏感数据场景(如医疗 / 金融)
采用全本地部署 RAG 系统,避免患者病历、客户金融信息等敏感数据流出本地环境。
3.4 大规模向量数据库场景
结合 "文本块加密 + 向量加噪",在保障检索可用性的前提下,降低黑客攻击与向量重建的风险。
RAG 技术发展的挑战与趋势总结
RAG(检索增强生成)技术作为提升大语言模型效果的关键方案,在实际落地与技术演进中仍面临多重挑战,同时也展现出清晰的发展方向,成为自然语言处理领域的重要研究与应用焦点。
从现存挑战来看,RAG 技术的难点贯穿检索、生成、部署、评估等全流程。在检索环节,核心难题集中在效率与准确性的平衡,不仅要应对海量数据下的检索延迟、高维向量检索的 "高维诅咒" 与索引成本,还需解决检索精准性不足(如关键词检索的语义理解局限、语义检索的领域适配性差)、分块策略的场景适配与语义感知欠缺等问题;生成环节则受困于大语言模型的幻觉、随机性,以及计算成本高、上下文窗口容量受限的约束;部署与应用层面,存在隐私安全风险(如向量重建、数据泄露)、多 LLM 协同的复杂度与一致性问题,且微调与 RAG 融合时还面临领域泛化性下降、检索内容超出上下文容量等问题;评估与优化领域,面临基准饱和、评估偏差、工具集成成本高、成本优化与质量平衡难等挑战,单一工具或方法难以满足全维度的监控与评估需求。
在发展趋势上,RAG 技术正朝着多模态、轻量化、智能化与深度融合的方向迈进。多模态融合成为核心方向,检索、知识库、语义搜索均逐步拓展至图像、音频等多模态数据的处理;轻量化部署与优化持续推进,通过模型量化、知识蒸馏、小型语义模型替代大模型等方式,降低技术落地的成本与硬件门槛,同时私有化部署也成为企业数据场景的重要需求;检索与生成、初始检索与重排序、LLM 与检索器的深度一体化设计,以及工具链的标准化与集成化,大幅提升了系统的端到端性能与易用性;智能化与自适应能力不断强化,从自适应的权重优化、分块策略,到动态的资源调度、采样参数调整,让 RAG 系统能更好适配不同场景;安全与隐私防护技术升级,轻量型向量加密、隐私计算与实时风险检测的结合,保障了敏感数据的安全使用;评估与监控体系也走向混合化、自动化,融合代码型、LLM 与人类反馈的评估框架,以及 "观测 - 评估 - 优化" 的闭环,推动 RAG 系统持续迭代优化。
整体而言,RAG 技术的发展始终围绕 "解决效率与精度的平衡、适配复杂场景需求、保障安全与易用性" 三大核心目标展开,未来随着技术的不断突破,其在垂直领域的落地应用也将更为深入和广泛。