本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
概述
Kafka是apache基金会下的产品,和Rabbit MQ,Rocket MQ类似,它也是一个作为MQ消息队列性质的存在。只是它的运用场景与后两者有所区分,主要是运用于数据分析领域的大体量的日志收集。其同样具有MQ的异步,削峰,解耦的三大特性,但是具体的实现和架构,和后两者有较大的区别。
简单来说,前者更加侧重于数据吞吐量,集群容错性,对于功能的完善和复杂度,消息的可靠性,则是有所牺牲,缺少死信队列,延迟队列等高级功能,并且可能存在数据的丢失,但是Kafka也在一直优化该问题,目前理论上已经可以理解成数据不会丢失了。
一、安装Kafka
同样是选择在linux服务器的环境进行安装和使用,首先需要准备一台虚拟机,并且安装好java的环境。
Kafka的安装包,可以在官网下载,官网下载安装包,但是速度很慢,可以使用阿里云镜像网站加速下载:国内Kafka镜像网站下载
下载完成后,上传到服务器的指定目录上,因为要配合ZK使用,所以推荐放在和ZK在同一个路径下:

解压完成后,先启动ZK,然后进入Kafka解压出的文件夹,执行:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
然后使用JPS命令验证是否启动成功:

上图所示即是启动成功,QuorumPeerMain是ZK的进程,Kafka则是刚刚启动的。
二、Kafka基本使用
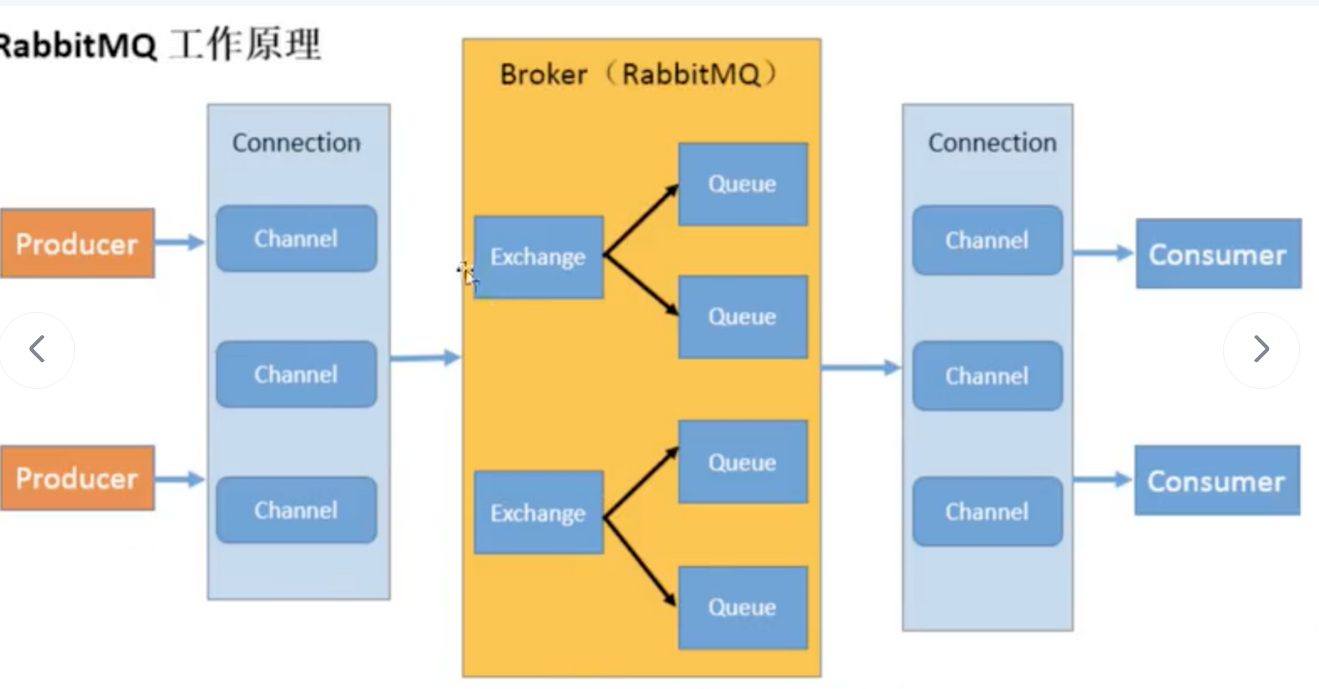
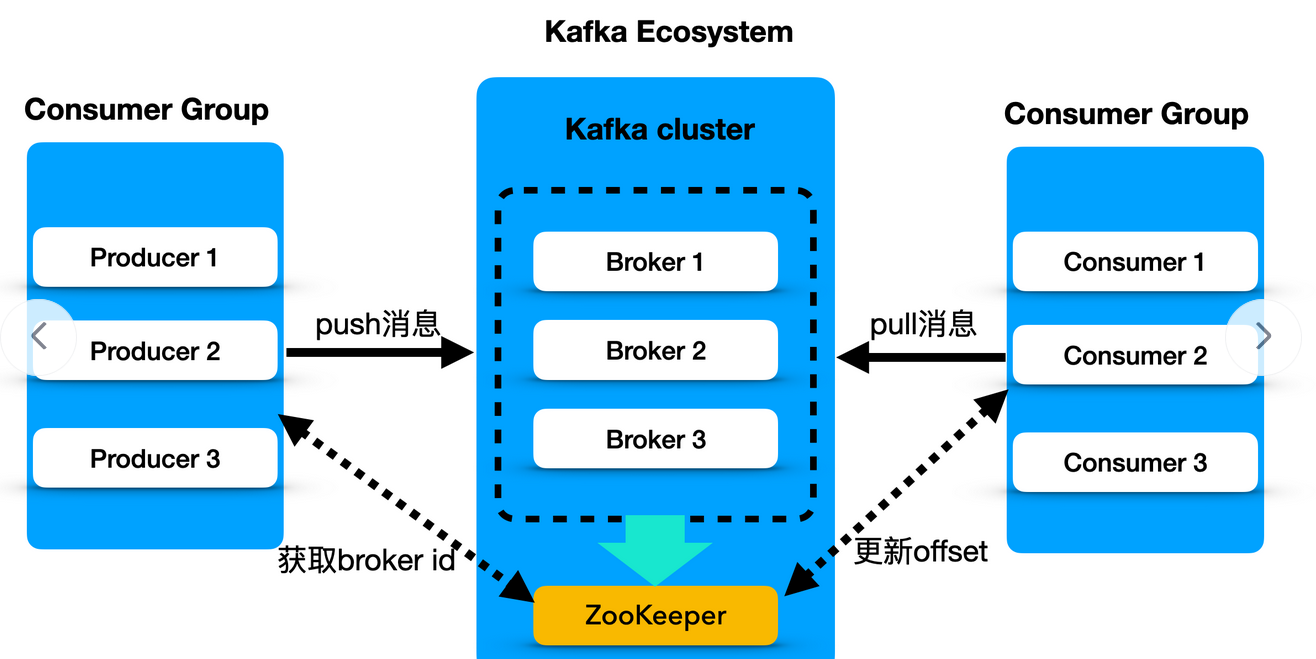
Kafka的基础工作机制是消息发送者可以将消息发送到kafka上指定的topic,而消息消费者,可以从指定的topic上消费消息,这里可以和Rabbit MQ对比一下:
- Rabbit MQ是生产者先将消息发送到Channel通道中,然后再由通道发送给具体的交换机,交换机和队列绑定,消费者也是通过通道从对立中拉取消息。
- Kafka则是省去了很多中间步骤,生产者直接将消息发送到topic上,然后消费者拉取。
2.1、创建Topic
所以首先需要创建一个topic:
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092

bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092 -- 查询topic

2.2、创建生产者
创建生产者:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
发送消息,按CTRL + C退出

2.3、启动消费者
然后启动一个消费者,从队列中获取消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
这里没有接收到消息,是因为生产者发送消息时,没有同步启动消费者,如果需要获取历史消息,则需要加上--from-beginning。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test

还可以指定具体的偏移量:--partition 0 --offset 2,代表从0号partition 的第 2个消息开始读:

以上便是Kafka最基本的使用。
2.4、分组消费
Kafka中同样存在着消费者组的概念:
- 如果某个消费者组下有两个消费者,有一条消息,那么这条消息,
只会被其中一个消费者消费 - 如果有两个消费者组,有一条消息,那么这条消息
可以同时被两个消费者组消费。
例:创建两个消费者组,第一个消费者组有两个消费者,第二个消费者组只有一个消费者:
#两个消费者实例属于同一个消费者组
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property
group.id=testGrroup --topic test
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property
group.id=testGrroup --topic test
#这个消费者实例属于不同的消费者组
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property
group.id=testGrroup1 --topic test
生产者发送消息

消费者组1的消费者1没有收到

消费者组1的消费者2收到

消费者组2的消费者收到

查看消费者组的偏移量,这里透露了几个关键的信息:
- PARTITION:为0,说明当前只有一个
PARTITION,PARTITION代表的时分区编号,之前所说,生产者将信息发送到topic,topic只是业务上的名称,实际上消息还是保存在PARTITION上的 - CURRENT-OFFSET:当前偏移量,代表用户当前消费到的位置
- LOG-END-OFFSET:TOPIC中最新消息的偏移量
- LAG:滞后量,为LOG-END-OFFSET - CURRENT-OFFSET,滞后量为 0 表示消费者消费进度与最新消息同步,没有消息积压

总结
Kafka的核心概念:
- 客户端:包含生产者和消费者
- TOPIC:消息中转的逻辑单元,生产者将消息发送到TOPIC,消费者从TOPIC拉取消息。
- PARTITION:是TOPIC中真正存储消息的单元,每一个PARTITION的结构是先进先出的队列
- 服务端:指的是Kafka服务器。
- 消费者组:一个消费者组可以包含多个消费者,但是一个消费者只能属于同一个消费者组。
(如果同一个消费者既是A消费者组,也是B消费者组的成员,怎么确定该消费者组消费消息的偏移量?)。同一条消息,可以被多个消费者组消费,但是如果一个消费者组中有多个消费者,该条消息只能被其中一个消费者消费。 - Offset:偏移量(Offset)在 Kafka 中是「消费者组级别」的核心概念,Kafka 中不存在「未加入消费者组的消费者」------ 所有消费者必须归属某个消费者组,否则无法消费主题消息。即使在创建消费者时没有显式的指定消费者组, Kafka 会自动为其分配一个临时消费者组

关于TOPIC,PARTITION,消费者组的关联:
- Topic 可以包含多个 Partition(推荐生产环境设置多个,提升吞吐和可用性);
- 一个 Partition 可以被多个消费者组消费(每个组独立维护消费进度,实现广播消费);
假设:
- Topic T 有 1 个 Partition(P1);
- 有 3 个消费者组(G1、G2、G3),都订阅了 Topic T;
- 每个组内有 1 个消费者(C1、C2、C3)。
消费逻辑: - 消息 M 写入 P1 后,G1 的 C1 会消费 M(G1 的偏移量更新为 M 的下一个位置);
- 同时,G2 的 C2 会消费 M(G2 的偏移量独立更新);
- G3 的 C3 也会消费 M(G3 的偏移量独立更新);
- 三个组的消费进度完全隔离:哪怕 G1 已经消费到偏移量 10,G2 仍可从偏移量 0 重新消费 P1 的所有消息。
组内的多个消费者是负载均衡 ,一个Partition被多个消费者组消费,是广播机制