4.子任务四:Hive 安装配置
只在master节点操作
(1) 将Hive 3.1.2的安装包解压到/root/software目录下;
(2) 在"/etc/profile"文件中配置Hive环境变量HIVE_HOME和PATH的值,并让配置文件立即生效;
(3) 查看Hive版本,检测Hive环境变量是否设置成功;
(4) 切换到 $HIVE_HOME/conf 目录下,将hive-env.sh.template文件复制一份并重命名为hive-env.sh;然后,使用vim编辑器进行编辑,在文件中配置HADOOP_HOME、HIVE_CONF_DIR以及HIVE_AUX_JARS_PATH参数的值,将原有值删除并将前面的注释符#去掉;配置完成,保存退出;
(5) 将 /root/software 目 录 下 的 MySQL 驱动包mysql-connector-java-5.1.47-bin.jar 拷 贝 到 H I V E H O M E / l i b 目录下;( 6 )在 HIVE_HOME/lib目录下; (6) 在 HIVEHOME/lib目录下;(6)在HIVE_HOME/conf目录下创建一个名为hive-site.xml的文件,并使用vim编辑器进行编辑;
配置如下内容:

(7) 使用schematool命令,通过指定元数据库类型为"mysql",来初始化源数据库的元数据;
(8) 使用CLI启动Hive,进入Hive客户端;在Hive默认数据库下创建一个名为student的管理表;
---------------------------------------------------------------------------分割线---------------------------------------
(1) 将Hive 3.1.2的安装包解压到/root/software目录下;
bash
# 进入software文件夹下面:
cd /root/software
tar -xvf hive-name.tar.gz
# 对得到的文件重新命名:
mv 旧文件夹名字 新文件夹名字(如hive)(2) 在"/etc/profile"文件中配置Hive环境变量HIVE_HOME和PATH的值,并让配置文件立即生效;
bash
# 进入根目录~
cd ~
vim /etc/profile
# 新增Hive环境变量HIVE_HOME和PATH的值(下图)
export HIVE_HOME=/root/software/hive
export PATH=$PATH:$HIVE_HOME/bin
# 保存esc:wq
# 置文件立即生效
source /etc/profile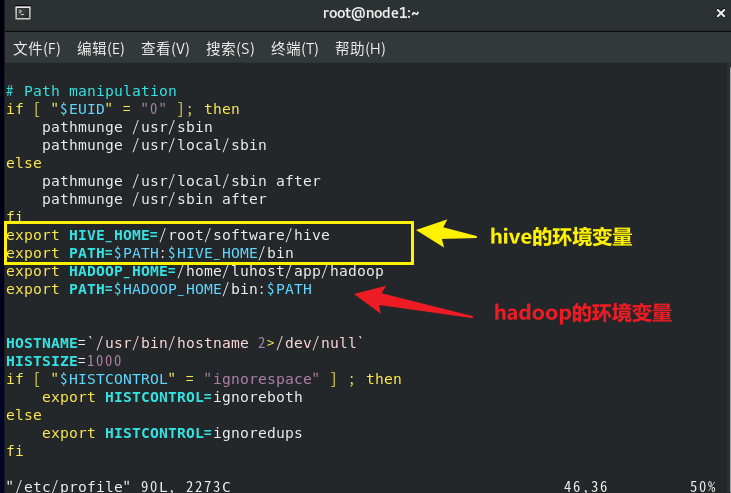
(3) 查看Hive版本,检测Hive环境变量是否设置成功;
bash
hive --version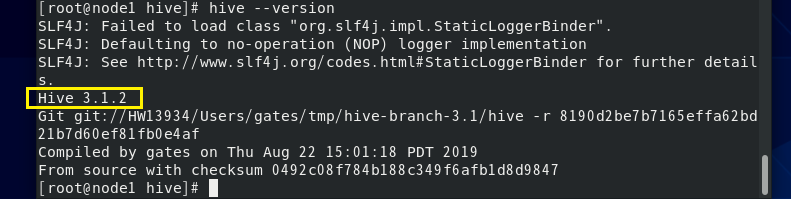
(4) 切换到 $HIVE_HOME/conf 目录下,将hive-env.sh.template文件复制一份并重命名为hive-env.sh;然后,使用vim编辑器进行编辑,在文件中配置HADOOP_HOME、HIVE_CONF_DIR以及HIVE_AUX_JARS_PATH参数的值,将原有值删除并将前面的注释符#去掉;配置完成,保存退出;
bash
# `$HIVE_HOME/conf` = root/software/hive(hive的安装目录)
cd root/software/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
# 在打开的hive-env.sh文件里面增加
HADOOP_HOME=/home/luhost/app/hadoop
export HIVE_CONF_DIR=/root/software/hive/conf
export HIVE_AUX_JARS_PATH=/root/software/hive/bin
# 配置完成,保存退出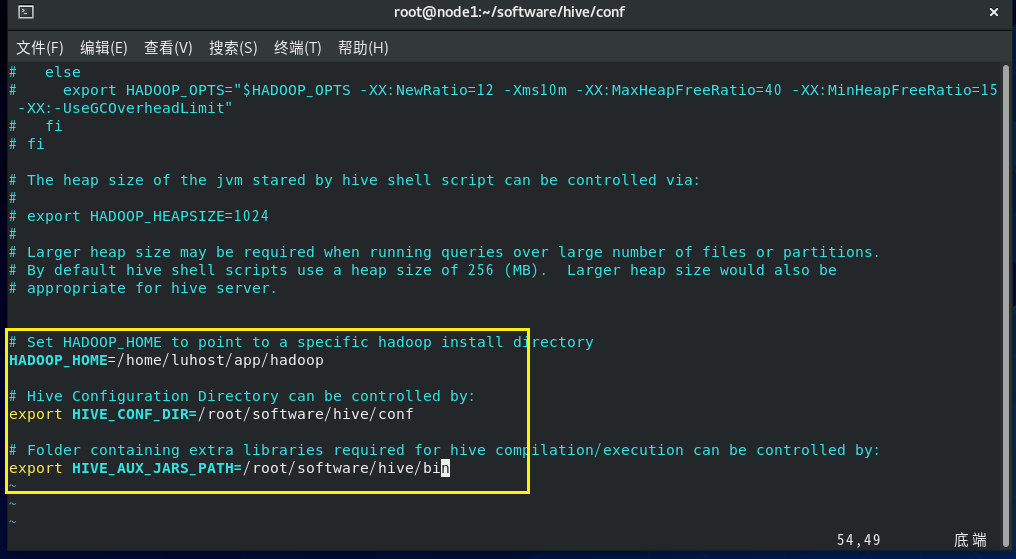
(5) 将 /root/software 目 录 下 的 MySQL 驱动包mysql-connector-java-5.1.47-bin.jar 拷 贝 到$HIVE_HOME/lib目录下;
bash
cp /root/software/mysql-connector-java-5.1.47-bin.jar root/software/hive/lib(6) 在$HIVE_HOME/conf目录下创建一个名为hive-site.xml的文件,并使用vim编辑器进行编辑;
配置如下内容:
bash
cd root/software/hive/conf
vim hive-site.xml
对打开的文件进行增加下面的部分(注意登录的数据库名称和密码):
xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
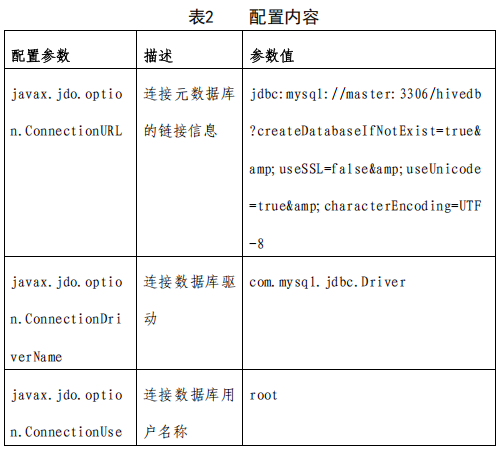
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123Mysql!</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/root/software/hive/warehouse</value>
</property>
</configuration>(7) 使用schematool命令,通过指定元数据库类型为"mysql",来初始化源数据库的元数据;
bash
# 进入hive
bin/schematool -dbType mysql -initSchema -verbose
# 成功的标志:schematool sucessfully!(8) 使用CLI启动Hive,进入Hive客户端;在Hive默认数据库下创建一个名为student的管理表;
- 直接hive文件夹
bash
#直接hive文件夹下输入hive- 在 Hive CLI 中执行以下 SQL 语句,创建仅包含id和name字段的管理表:
sql
-- 在default数据库下创建student管理表
CREATE TABLE student (
id INT, -- 学生ID(整数类型)
name STRING -- 学生姓名(字符串类型)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','; -- 字段间用逗号分隔(可根据实际数据格式调整)- 验证表创建结果
sql
show tables;
问题
在(7)中出现问题Eror: Table 'CTLGS' already exists (state=42S01,code=1050),解决:
bash
Eror: Table 'CTLGS' already exists (state=42S01,code=1050)
Closing: 0: jdbc:mysql://node1:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
Underlying cause: java.io.IOException : Schema script failed, errorcode 2
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:594)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:567)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1517)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: java.io.IOException: Schema script failed, errorcode 2
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:1226)
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:1204)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:590)
... 8 more
*** schemaTool failed ***报错信息 Table 'CTLGS' already exists 表明 MySQL 元数据库(hivedb)中已经存在 Hive 元数据相关的表(如 CTLGS),再次执行 -initSchema 初始化会因表已存在而失败。这通常是因为之前已经执行过初始化操作,或元数据库中残留了旧数据。
方法:删除现有元数据库,重新初始化(推荐,适用于新环境)
如果是首次配置 Hive 且元数据库中没有重要数据,可直接删除 hivedb 数据库,重新执行初始化:
(1) 登录 MySQL:
bash
mysql -u root -p(2) 删除现有 hivedb 数据库(注意:会清空所有元数据,谨慎操作):
sql
DROP DATABASE IF EXISTS hivedb;(3) 退出 MySQL:
sql
exit;(4) 重新执行 Hive 元数据初始化命令:
bash
bin/schematool -dbType mysql -upgradeSchema