背景
为了将大模型能力与公司现有工作流程深度融合,从而提升整体工作效率,公司计划在本地部署开源大模型。本调研报告旨在系统评估当前主流开源大模型,为本地化部署提供选型依据。
如果讲各类模型参数,对于领导和业务人员来说太晦涩难懂,我们将从生成内容这个易于理解的角度去介绍各类大模型,我们公司的需求主要集中在文本生成、文生图、图生文、视频生文、音频生文,所以我们从这些角度去介绍大模型。
主流开源大模型概述
目前主流的开源大模型分别是Qwen、DeepSeek和Llama,下面从技术演进代表性模型、核心定位与优势、模型架构关键创新、应用场景侧重四个方面介绍一下这三个大模型
| 特性维度 | Qwen (通义千问 - 阿里巴巴) | DeepSeek (深度求索) | Llama (Meta) |
|---|---|---|---|
| 技术演进代表性模型 | Qwen1 -> Qwen1.5 -> Qwen2 -> Qwen2.5-> Qwen3 | DeepSeek LLM -> DeepSeek-V2 -> DeepSeek-V3-> DeepSeek-R1 | LLaMA -> LLaMA 2-> LLaMA 3-> LLaMA 3.1 405B |
| 核心定位与优势 | 全面均衡,中文能力突出,多模态支持丰富,电商场景整合好 | 极致性价比,强大的数学与代码推理能力,推理成本控制出色 | 开源社区基石,生态庞大,工具链成熟,学术界和工业界应用广泛 |
| 模型架构关键创新 | 全系列使用GQA,引入MoE(如Qwen3-235B-A22B),VL系列集成视觉编码器与跨模态注意力 | 高效的混合专家模型(MoE),如DeepSeek-V3总参数量671B,但每次推理仅激活37B参数 | 从标准的Transformer架构出发,Llama 3 使用超过15万亿token的公开数据预训练,训练效率相比前代提升3倍 |
| 应用场景侧重 | 企业服务、多语言业务、内容创作、智能客服、多模态交互 | 编程开发、复杂逻辑推理、数学问题求解、金融分析 | 学术研究、构建AI基础设施、快速原型验证、跨设备AI部署 |
从对中文理解和回复的效果来评估,Qwen和DeepSeek要优于Llama,后面主要是从Qwen和DeepSeek两个系列模型中选取符合用户需求的专业模型。
文本生成大模型是其他模态大模型的基座,我们先介绍文本生成大模型。
文本生成大模型
文本生成大模型大概分成有思考过程的思考模型和没有思考过程的指令模型,Qwen3分为Thinking和Instruct两个模式,DeepSeek分为R1和V3,下面做个简单对比。
| 对比维度 | 思考模型 (Thinking) - Qwen3-Thinking | 思考模型 (Thinking) - DeepSeek-R1 |
|---|---|---|
| 核心定位 | 全能型思考者,均衡发展 | 专业推理专家,深度与精度至上 |
| 技术架构 | 混合专家模型 (MoE),总参数量大但激活参数少 | 稠密模型 |
| 推理性能 | 综合能力强,在数学(如AIME25达81.5分)、代码等多领域表现优异 | 推理深度极致,在数学(AIME25达87.5%准确率)和复杂逻辑任务上常领先 |
| 输出特点 | 思考链较长(平均token 3882),步骤详尽 | 思考链极深(平均token 可达23K),探索更彻底 |
| 硬件与成本 | 部署成本相对较低(约为DeepSeek-R1的1/3) | 计算资源需求更高,推理成本较高 |
| 最佳适用场景 | 需要较强推理能力,且对成本和部署便利性有要求的综合业务场景 | 极限挑战:最复杂的数学、科学及逻辑推理问题 |
| 对比维度 | 指令模型 (Instruct) - Qwen3-Instruct | 指令模型 (Instruct) - DeepSeek-V3 |
|---|---|---|
| 核心定位 | 高效执行者,快速响应 | 高性价比的通用基座 |
| 技术架构 | 混合专家模型 (MoE) | 混合专家模型 (MoE),总参数671B,激活37B |
| 推理性能 | 满足绝大多数通用任务,响应速度快 | 通用能力强,适合高并发交互与信息检索 |
| 输出特点 | 响应直接,输出简洁 | 响应速度快,吞吐量高 |
| 硬件与成本 | 部署成本极具优势,资源需求低 | 性价比突出,API服务定价极具竞争力 |
| 最佳适用场景 | 高并发客服、内容摘要、实时问答等效率优先的场景 | 构建高性能、低成本的通用AI服务底座 |
思考模型和指令模型又分满血版和非满血版
- 满血版大模型,主要面向复杂推理场景、高效指令执行任务,代表
- Qwen3-235B-A22B-Thinking
- Qwen3-235B-A22B-Instruct
- Deepseek-R1-0528
- Deepseek-V3-671B
- 非满血版大模型,主要适用于对智能要求不高但速度要求较高的场景,代表:
- Qwen3-72B-Instruct(或者Qwen2.5-72B-Instruct)
- DeepSeek-R1-Distill-Llama-70B
多模态大模型
根据业务需求,多模态我们主要是从文生图、图生文(含OCR)、视频解析、音频解析四个维度进行模型介绍。
- 文生图专家:HunyuanImage 3.0和 Qwen-Image在这方面是顶级专家。
- 图生文/OCR专家:DeepSeek-OCR和 PaddleOCR在文字识别和文档结构化方面是专业级选手。
- 纯视觉语言模型:Qwen3-VL-235B-A22B(Qwen3-VL-30B-A3B、Qwen2.5-VL-72B)擅长图文理解和推理,但不支持音频
- 全能王(四模态支持):Qwen3-Omni-30B-A3B-Instruct(Qwen2.5-Omni)是唯一同时支持图、文、视频、音频的模型。
四维能力对比
| 模型名称 | 文生图 | 图生文 | 视频解析 | 音频解析 |
|---|---|---|---|---|
| Qwen3-VL-235B-A22B | ★★★ | ★★★★★ | ★★★★ | × |
| Qwen-Image | ★★★★★ | ★★ | × | × |
| HunyuanImage 3.0 | ★★★★★+ | × | × | × |
| Qwen3-Omni-30B-A3B-Instruct | × | ★★★★★ | ★★★★★ | ★★★★★ |
| DeepSeek-OCR | × | ★★★★★ | × | × |
| PaddleOCR | × | ★★★★★ | × | × |
分项深度解读
文生图
顶级专家:HunyuanImage 3.0和 Qwen-Image。它们是专门的文生图模型,在图像质量、细节、美学上追求极致。
附带功能:VL系列(如Qwen3-VL-235B-A22B)支持文生图,但这属于"锦上添花"的功能,生成质量和可控性不如专业模型。
不支持:Omni系列和OCR模型不支持文生图。它们专注于多模态理解,而非生成。
图生文(这是一个宽泛的概念,包含不同层次的能力)
为了更清晰地理解各模型在图生文方面的能力侧重,下图展示了它们在"文字识别"和"语义理解"两个维度上的位置: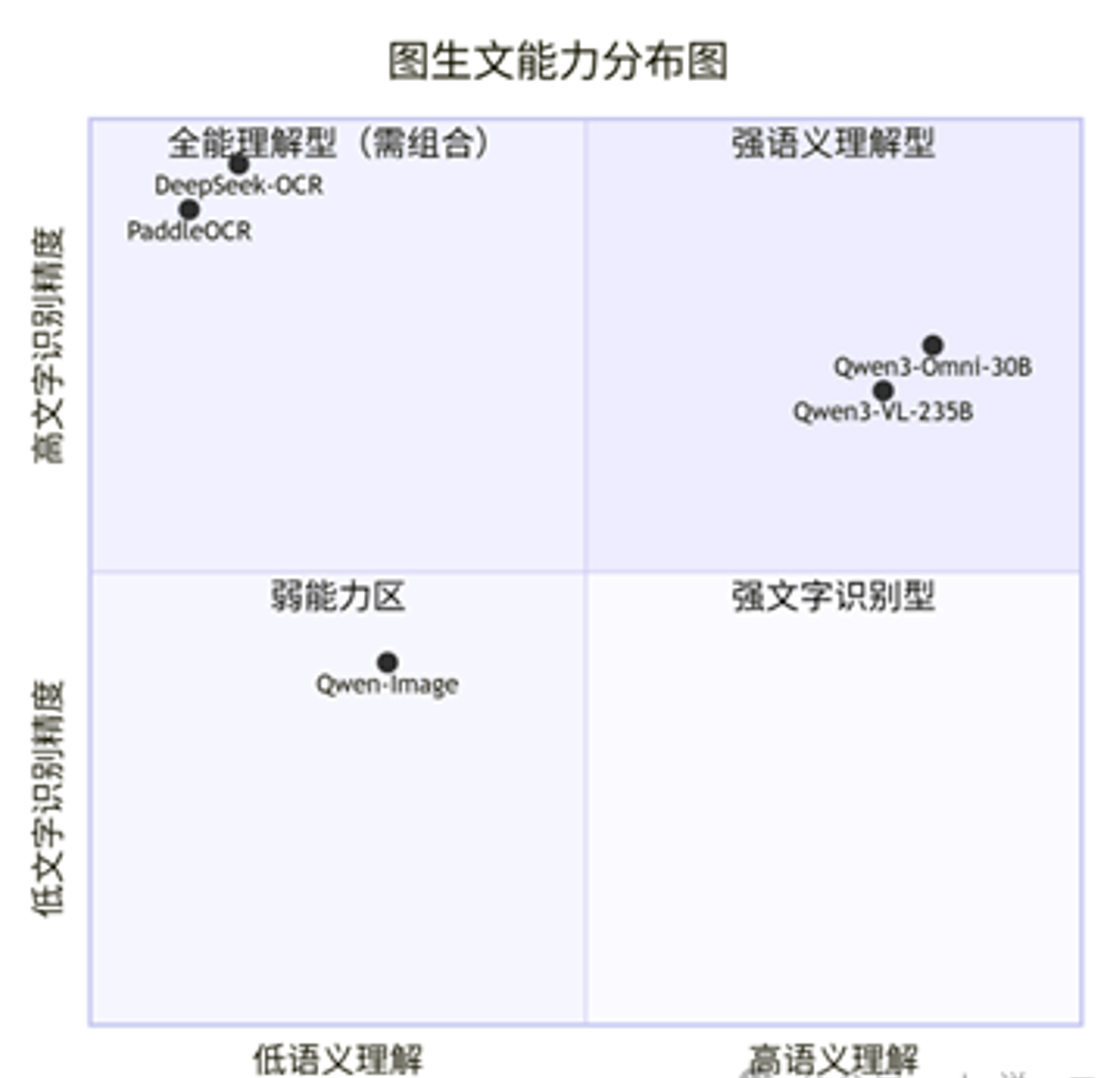
文字识别专家:DeepSeek-OCR和 PaddleOCR。它们在图生文谱系的最底层------文字识别上做到极致,目标是精准"抄写",但无法理解深层含义。
语义理解专家:VL系列和 Omni系列。它们在谱系的高层------语义理解上表现卓越。它们能"看懂"图片,进行深度的推理、问答、总结。虽然也具备一定的OCR能力,但在需要精确还原原文的场景下,其可靠性不如专业OCR模型。
弱能力区:文生图专家(HunyuanImage 3.0, Qwen-Image)的图生文能力很弱。
视频解析
最佳选择:Omni系列(Qwen3-Omni-30B-A3B-Instruct, Qwen2.5-Omni)。它们是原生支持视频模态的模型,能直接处理视频片段,进行时序理解。
替代方案:VL系列通常通过"抽帧"方式处理视频(将视频转为图片序列),因此缺乏对时序、动作的深度理解。
不支持:文生图模型和OCR模型不支持视频解析。
音频解析
唯一选择:Omni系列(Qwen3-Omni-30B-A3B-Instruct, Qwen2.5-Omni)。它们是列表中唯二明确支持音频模态的模型,可进行语音识别、音频内容理解等。
重要提示:VL系列、文生图模型、OCR模型均不支持音频解析。
选型决策指南
- 需求全覆盖(图+文+视频+音频)唯一选择:Qwen3-Omni-30B-A3B-Instruct。
- 需求:专业级文生图首选:HunyuanImage 3.0(质量至上)。次选:Qwen-Image。
- 需求:高精度文档文字识别(OCR)首选:PaddleOCR(生态成熟)或 DeepSeek-OCR(精度顶尖)。
- 需求:复杂的图片/视频理解与推理(无需音频)
- 极致性能:Qwen3-VL-235B-A22B。
- 平衡之选:Qwen3-VL-30B-A3B。
另外更多大模型面试题
