什么是哈希索引
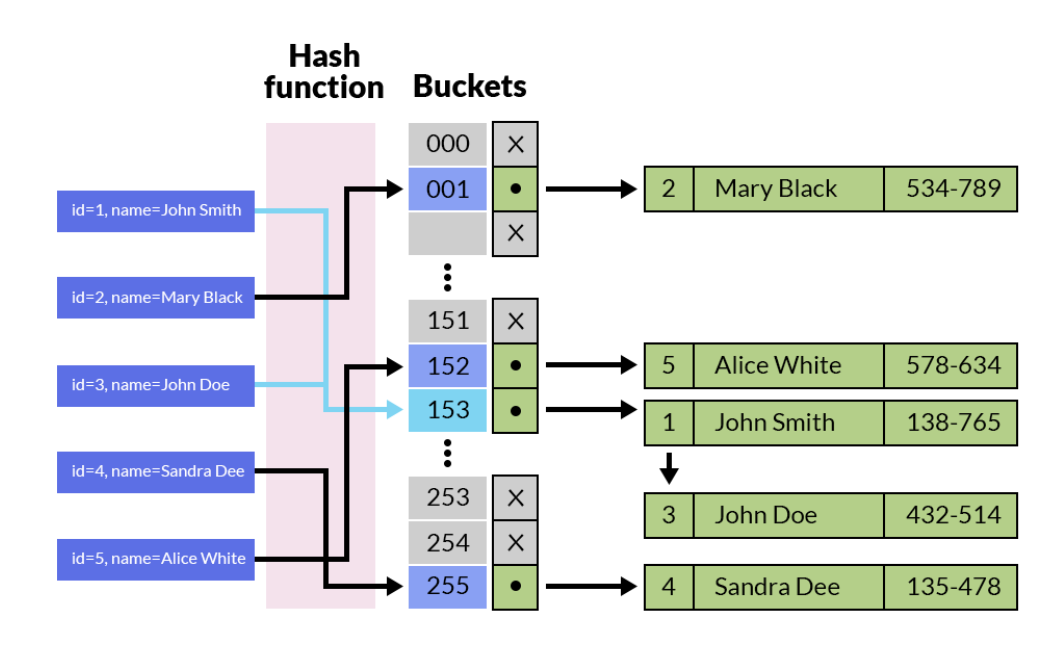
哈希索引是基于内存的支持,底层结构就是链式哈希表,增删改查的时间复杂度都是O(1)。
通过将索引键(如数据库表的主键、Redis 的 Key)经过哈希函数计算得到哈希值,再将哈希值映射到对应的存储位置(槽位),从而快速定位数据的物理地址或内存地址。
InnoDB自适应哈希索引
AHI 完全存储在 InnoDB 的 缓冲池(Buffer Pool) 中,属于缓冲池内部的一块专用内存区域,并非独立于缓冲池的单独内存空间。
结构
哈希表数组(Hash Bucket Array)
- 核心存储结构:数组的每个元素(哈希桶)是一个指向 "哈希链表" 的指针。
- 哈希函数:InnoDB 会对索引键(如 B+ 树索引的键值)计算哈希值,根据哈希值将键值映射到对应的哈希桶。
- 内存占用:哈希表数组的大小由 InnoDB 动态调整,默认初始大小较小,随热点数据增多而扩容(避免哈希冲突过于频繁)。
哈希链表(Hash Chain)
- 解决哈希冲突:当多个索引键的哈希值映射到同一个哈希桶时,会通过链表形式存储(链地址法)。
- 链表节点内容:每个节点存储 3 类核心信息:
- 索引键的完整值(或前缀,取决于 AHI 的构建策略);
- 对应的 B+ 树索引类型(聚簇索引 / 二级索引);
- 数据页在缓冲池中的内存地址(或页号),以及页内数据的偏移量(直接定位到具体行数据)。
不使用自适应哈希索引的查询过程
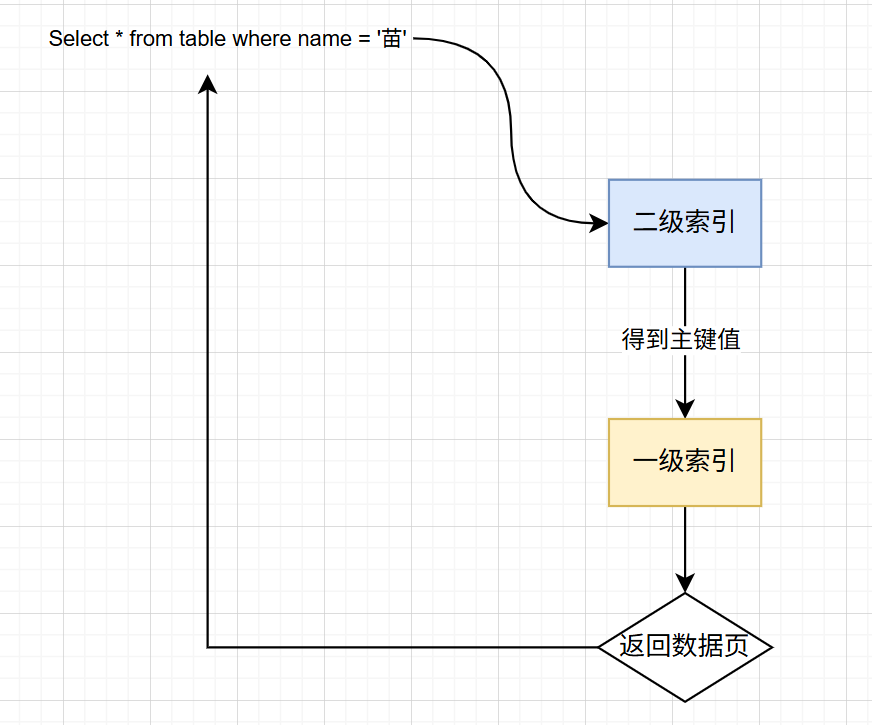
- 解析与优化器决策 :优化器选择
name二级索引(等值查询适合二级索引),避免全表扫描。 - 二级索引 B + 树遍历(从根到叶) :
- 与聚簇索引遍历逻辑一致:从二级索引根节点开始,逐层查找
name='苗'对应的子节点,直到叶子节点。 - 二级索引叶子节点存储「索引键(username)+ 主键 id」(如
('苗', 100)),通过二分查找定位到username='苗'对应的主键 id=100。 - 关键:二级索引遍历同样无 AHI 加速,需完整走 B + 树逐层查找(启用 AHI 时,热点
username会通过哈希表直接获取主键 id)。
- 与聚簇索引遍历逻辑一致:从二级索引根节点开始,逐层查找
- 回表查询(聚簇索引查找) :
- 拿到主键 id=100 后,需通过聚簇索引查询完整行数据(即回表),回表流程与聚簇索引等值查询完全一致(从根到叶遍历 B + 树,定位叶子节点的完整行)。
- 数据整合与返回:将回表获取的完整行数据返回给应用。
使用自适应哈希索引的查询过程
在AHI中,key就是经常被访问的索引,value就是索引对应的物理数据页的位置。
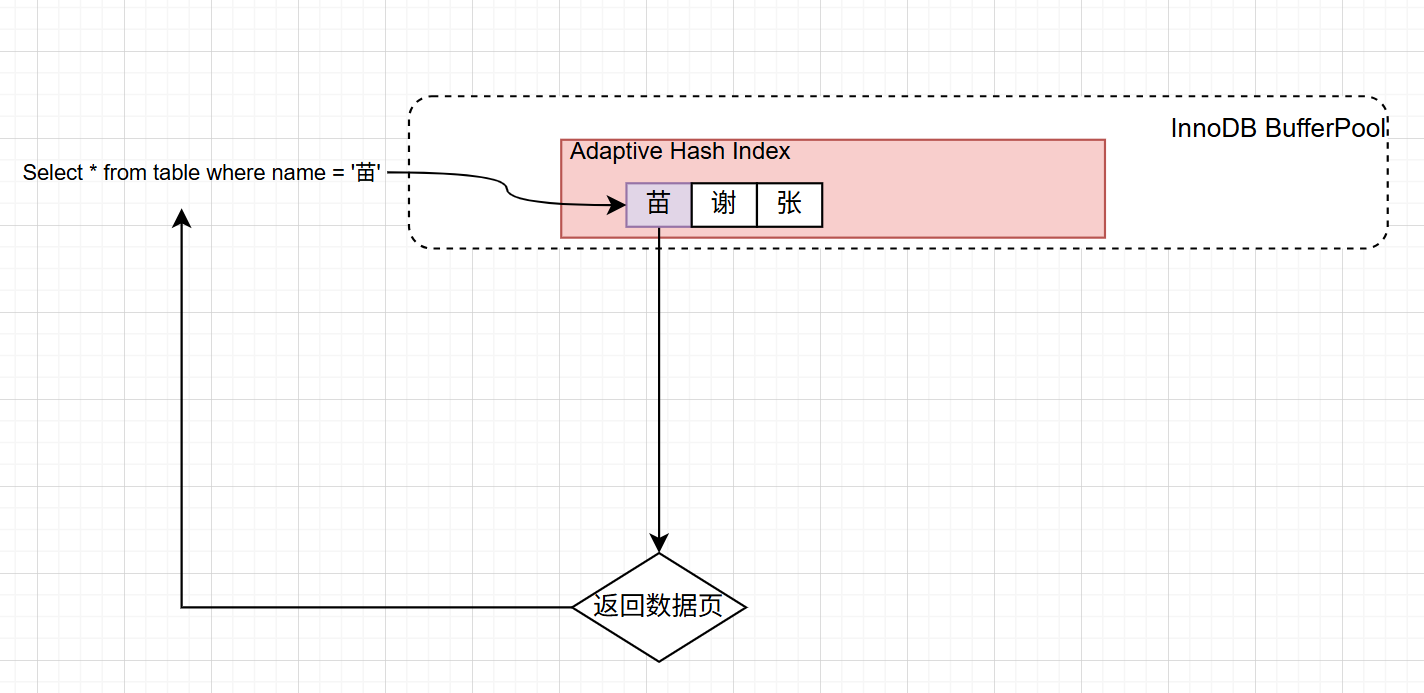
InnoDB 会持续监控所有索引的查询操作,尤其是等值查询。它会为每个索引键维护一个访问计数器,记录其被查询的次数。当某个索引键的访问次数达到内部阈值时,InnoDB 会将其视为热点数据,并触发 AHI 的构建。
当后续有相同的等值查询时,InnoDB 会先检查 AHI 的哈希表:
- 如果找到匹配的索引键(哈希命中),直接通过存储的物理地址访问数据页,跳过 B+ 树的遍历。
- 如果未找到(哈希未命中),则 fallback 到传统的 B+ 树查询,并更新该索引键的访问计数器。
基于主键的查找,大部分都是哈希查找。
AHI 的哈希表大小是有限的(默认占用缓冲池的 1/6),当哈希表满时,InnoDB 会根据LRU(最近最少使用)算法 淘汰掉访问频率较低的索引键,为新的热点数据腾出空间。当索引键对应的记录被删除或更新时,InnoDB 会同步更新 AHI 中的对应条目,确保数据一致性。
条件
只有满足以下条件,二级索引的索引键才会被 InnoDB 自动加入到自适应哈希索引中:
- 查询类型必须是等值查询
- AHI 仅支持等值查询 (
=),不支持范围查询(>、<、BETWEEN)、模糊查询(LIKE)或排序(ORDER BY)等。
- 索引键值的访问频率足够高
-
InnoDB 会监控索引键的访问次数,只有当某个索引键被查询的次数达到一定阈值时,才会将其加入 AHI。
-
这个阈值由 InnoDB 内部算法动态决定,无法手动配置。
- 索引键值的选择性足够好
-
选择性是指索引键值的唯一程度 (
选择性 = 唯一索引值数量 / 总记录数)。 -
AHI 更倾向于缓存选择性高的索引键(如主键、唯一索引),因为这些索引键的等值查询命中率更高,能显著提升性能。
-
对于选择性极低的索引(如
gender字段,只有男 / 女两个值),即使访问频率高,InnoDB 也可能不会将其加入 AHI,因为哈希冲突的概率太高,优化效果有限。
- 索引必须是 B+ 树索引
- AHI 仅作用于 InnoDB 的B+ 树索引(包括聚簇索引和二级索引),不支持哈希索引、全文索引或空间索引。
总结
自适应哈希索引可以看作为索引的索引,只有热索引才有资格建立起哈希索引以方便数据页的查找。但维护哈希索引也需要一定的开销,要根据具体的情况来决定是否开启自适应哈希索引。