HNSW,Hierarchical Navigable Small World,分层导航小世界网络
目前 RAG、推荐系统、图像检索等场景中最常用的 近似最近邻(ANN)向量索引算法 之一
核心优势是「检索速度极快 + 精度高」,能高效支撑百万级~亿级高维向量的快速检索
也是很多向量数据库(如 Milvus、Weaviate、Pinecone)的默认推荐索引
Hierarchical ˌhaɪəˈrɑːkɪk(ə)l 分等级的,等级制度的
Navigable ˈnævɪɡəb(ə)l 可航行的;可驾驶的;适于航行的
HNSW 像 "多层导航地图"
想象你要在一个超大城市(对应 "海量向量空间")找最像你的人(对应 "目标向量的近邻"):
「暴力检索」:
挨家挨户敲门询问,虽然能找到最像的人,但效率极低
「IVF 索引」:
先按区域(对应 "簇")划分城市,只在你所在区域内敲门,效率提升但区域内仍需遍历
「HNSW 索引」:给城市做了「多层导航图」
- 顶层(高速路):稀疏连接(只连接少数核心区域),帮你快速定位大致方向(比如 "城东区域")
- 中层(主干道):中等密度连接,帮你缩小范围到 "城东某街道"
- 底层(社区小路):稠密连接,帮你精准找到 "街道上最像你的人"
检索时从顶层往下 "导航",不用遍历所有区域,速度大幅提升
核心原理
HNSW 的本质是「构建多层有向图」,通过 "分层导航" 减少无效遍历:
核心结构:多层导航图
每个向量是图中的一个「节点」
节点之间的「边」表示向量之间的 "近邻关系"(比如余弦相似度高于阈值)
图分为多层:上层节点连接稀疏(跨区域导航),下层节点连接稠密(局部精准查找)
每个节点会出现在多个层中(比如同时在顶层、中层、底层),但上层的节点数量远少于下层(类似 "金字塔结构")
索引构建:怎么搭建这个图
逐个插入向量节点:新节点先在「最底层」找到它的几个近邻节点(比如 10 个),建立连接
随机决定节点的 "层数":用概率算法(类似跳表)决定新节点能到哪一层(少数节点能到顶层,多数节点只在底层)
逐层建立连接:若节点能到中层 / 顶层,在对应层也找到近邻节点建立连接,最终形成多层导航结构
检索过程:怎么快速找近邻
从「顶层的某个起始节点」开始,沿着边找到当前层中 "最像目标向量" 的节点
向下进入下一层,以该节点为起点,继续找更像的节点
重复步骤 2,直到进入最底层,在底层找到 "最像目标向量" 的几个节点(即最终的近邻结果)
关键特点(优点 + 缺点)
优点
「速度极快」:检索时间复杂度接近 O (log n),比 IVF 系列快一个数量级,亿级向量也能做到毫秒级响应
「精度高」:近似精度远超 PQ 类压缩索引,接近 IVF-FLAT(无量化损失),满足大多数 RAG 场景需求
「适配高维向量」:对 128 维、256 维、768 维(大模型 Embedding 常用维度)的向量兼容性极好,不会因维度升高导致性能暴跌
缺点
「索引构建耗时」:插入向量时需要逐层建立连接,比 IVF 索引的构建速度慢(但检索时能补回这个时间成本)
「动态更新效率一般」:新增 / 删除向量时,需调整多层图的连接关系,高频动态数据场景(如实时新增百万级向量)不如 IVF 灵活
「内存占用较高」:需要存储节点的多层连接关系,内存消耗比 IVF-PQ 高(但远低于 IVF-FLAT 的原始向量存储)
适用场景
数据规模:百万级~亿级高维向量(RAG 场景最核心的适用范围)
核心需求:追求 "速度 + 精度" 平衡(比如 RAG 问答系统需要快速返回相关文档,且不能丢失关键信息)
典型场景:大模型 RAG 检索、图像 / 视频相似性检索、推荐系统的召回阶段、智能客服的知识库检索等
与其他索引的核心区别
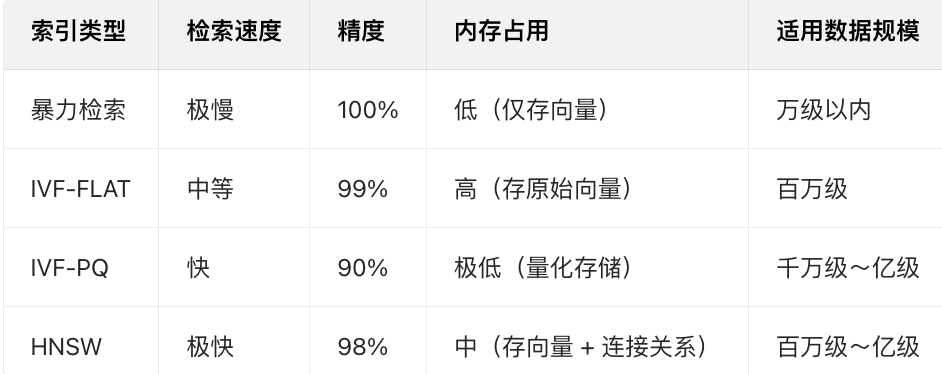
简单记
HNSW 是「速度和精度的最优解」,如果场景是 "大规模高维向量 + 需要快速精准检索",选 HNSW 准没错