文章目录
Linux多线程之自旋锁和读写锁
自旋锁
1、问题引入
我们在写多线程代码的时候会遇到线程安全方面的问题,因此就需要加锁进行线程保护。一般我们会使用互斥锁或者其他锁进行保护,当多个线程竞争一把锁的时候,申请成功则进入临界区进行临界资源的访问,申请失败则进行阻塞等待,知道锁释放了,这些阻塞的线程才重新被唤醒进行锁的竞争。
当遇到以下场景的时候:
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
int tickets = 5000;
void GetTickets(pthread_mutex_t *ptr_mutex)
{
while (true)
{
pthread_mutex_lock(ptr_mutex);
if (tickets != 0)
{
std::cout << "thraead:" << gettid() << " get a ticket, number is " << tickets << std::endl;
tickets--;
pthread_mutex_unlock(ptr_mutex);
}
else
break;
}
}
void *headler(void *ptr)
{
GetTickets((pthread_mutex_t *)ptr);
}
int main()
{
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
pthread_t c1, c2, c3, c4, c5;
pthread_create(&c1, nullptr, headler, &mutex);
pthread_create(&c2, nullptr, headler, &mutex);
pthread_create(&c3, nullptr, headler, &mutex);
pthread_create(&c4, nullptr, headler, &mutex);
pthread_create(&c5, nullptr, headler, &mutex);
pthread_join(c1, nullptr);
pthread_join(c2, nullptr);
pthread_join(c3, nullptr);
pthread_join(c4, nullptr);
pthread_join(c5, nullptr);
return 0;
}这是一个抢票的场景,共有5000张票,有5个线程去抢。这里的票数tickets为临界资源,受到互斥锁mutex的保护,当一个线程申请到锁进行抢票的时候,其他4个线程都被阻塞,释放锁的时有进行唤醒。
这个场景下临界区非常短,在极短的时间内就可以执行完成,甚至我这里使用了打印,真正的逻辑只有判断和tickets自减,这样一来,其他线程的阻塞和唤醒的开销以及线程切换的开销就显得非常大,每一个线程都需要耗费时间在阻塞和唤醒上。所以,C++还存在自旋锁来帮助我们解决这个问题。
2、自旋锁介绍
自旋锁与互斥锁在功能上相同,都是保护临界区,任意时刻只能有一个线程申请到锁,访问临界区
不同的时,自旋锁在申请失败时不会阻塞挂起,而是进行轮询检测,不断的区检测锁是否被释放,释放了之后再去竞争,这样就避免了阻塞和唤醒的开销。就像进程等待的时候有阻塞等待和轮询等待两种方式一样。因为这种轮训检测就像是在旋转一样,因此叫做自旋锁
自旋锁适用于临界区很短,执行很快的场景。
自旋锁的工作原理:
自旋锁通过原子操作来实现,当线程尝试获取锁时,会使用CAS(Compare-and-Swap)操作来尝试修改锁的状态。如果锁已经被占用,线程会在一个循环中不断尝试获取锁,而不是立即放弃CPU,进入阻塞状态。
自旋锁的优缺点:
- 优点:避免了线程上下文切换的开销,响应速度快
- 缺点:占用CPU资源,如果锁被长时间持有,会导致CPU空转
适用场景:
- 临界区代码执行时间非常短(通常小于线程切换的时间)
- 多核CPU环境(单核CPU上自旋锁没有意义)
- 不能用于可睡眠的上下文(如内核中断处理下半部)
3、接口介绍
定义和初始化
c
// 静态定义并初始化自旋锁
DEFINE_SPINLOCK(lock_name);
// 动态初始化自旋锁
spinlock_t lock_name;
spin_lock_init(&lock_name);基本加锁操作
c
// 获取自旋锁(忙等待)
void spin_lock(spinlock_t *lock);
// 释放自旋锁
void spin_unlock(spinlock_t *lock);
// 尝试获取锁(非阻塞)
// 成功返回1,失败返回0
int spin_trylock(spinlock_t *lock);自旋锁的变种:
c
// 禁止中断的自旋锁(用于中断上下文)
void spin_lock_irq(spinlock_t *lock);
void spin_unlock_irq(spinlock_t *lock);
// 保存中断状态的自旋锁
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags);
// 禁止软中断的自旋锁
void spin_lock_bh(spinlock_t *lock);
void spin_unlock_bh(spinlock_t *lock);读写锁
1、读写者模型
举个例子:
在上课的场景中,老师会在黑板上书写教学内容,并且约定必须等待老师完成书写后,学生们才能开始抄写笔记。
在这个过程中,黑板作为一个共享的访问场所,老师扮演着"写者"的角色,负责向黑板中写入新的内容,而学生们则充当"读者"的角色,从黑板上读取老师书写的内容。这个模型的核心特点在于:当老师进行书写操作时,同一时间只能有一位老师持有书写权限,即写操作是互斥的,这样可以保证书写内容的完整性和一致性;
而在老师完成书写并释放权限后,多位学生可以同时进行抄写操作,即读操作可以是完全并发的,这大大提高了学习效率;
此外,这个模型还允许多个写者交替执行,即当一位老师完成书写后,其他老师也可以接着上来继续书写,形成了一个动态的、多角色的协作系统。
这个课堂场景模拟经典的"读者-写者"同步模型,体现了在共享资源访问中不同角色之间的协同与互斥关系,其中写者与写者之间需要互斥访问,读者与写者之间也需要保持同步,而读者与读者之间则可以共享资源,实现高效并发。
在实际中,除了有生产消费模型之外,还有读者写者模型,与生产消费模型类似,也是有一类线程向另外一类线程通过特定的场所提供资源,从而达到多个线程并发式的协同工作。
如果不了解生产消费模型,可以参考我的文章:Linux生产消费模型
与生产消费模型类似:
在读写模型中也存在1个场所,是用来进行数据(资源)读写的场所,
存在两种角色,读者以及写者,写者向场所中写入数据,读者读取数据
存在3种关系,读者与读者之间为互斥关系,写者与写者之间是并发关系(没有互斥,可以同时进行读取数据,但是不拿走,给自己拷贝一份即可,一遍其他读者进行读取),读者与写者之间是互斥与同步关系,只有写着写入完成读者才可以读取。
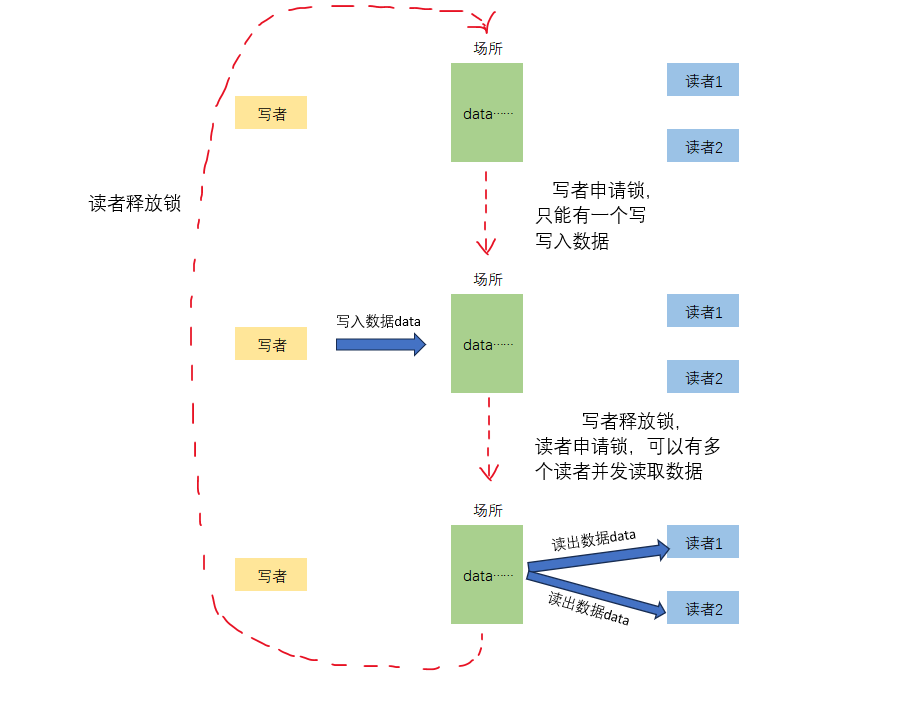
生产消费模型与读写者模型最大的区别在于:
生产消费模型中消费者之间为互斥关系,消费者会消费数据,而在读写模型中读者之间没有互斥关系,并且不会拿走(消费)数据。
2、读写锁详细介绍
读写锁的特点:
- 多个读者可以同时持有读锁
- 写者必须独占写锁,写锁被持有时,其他读者和写者都不能获取锁
- 读写锁提供了比互斥锁更好的并发性,在读多写少的场景下性能优势明显
读写锁的优先级策略:
- 读者优先:
只要有一个读者持有了读锁,后续所有到达的读者都可以无需等待地直接获取读锁,即使有写者正在等待。
读者优先具有以下特点:
- 当第一个读者到来时,它会获取读锁。
- 后续到来的读者,如果发现当前已经有读者持锁(无论是否也有写者在等待),它们会直接共享读锁,进入临界区。
- 当一个写者到来时,如果当前有读者正在读,它必须阻塞等待。
- 写者必须等待直到当前所有正在读的读者以及已经在排队等待的读者都完成后(即读锁计数降为0),才能获取写锁。
潜在问题:写者饥饿
在这种策略下,如果读者源源不断地到来(即读请求的间隔时间很短,总能有新的读者在写者之前到达),那么写者可能永远无法获得执行的机会,导致"饥饿"现象。例如,在一个数据库系统中,如果某个热门数据一直被频繁读取,那么更新该数据的写操作可能被无限期推迟。
适用场景: 适用于读操作极其频繁,而写操作非常稀少且对实时性要求不高的场景。它的优势在于能够最大化读并发性能。
- 写者优先:
核心思想: 一旦有写者开始等待,就应尽快满足其请求,阻止新的读者插队,以保障写者的执行权。
写者优先具有以下特点:
- 当没有写者等待时,读者的行为与"读者优先"策略类似,可以并发读取。
- 当一个写者到来并开始等待后,系统会设置一个"写者等待"的标志。
- 此后,所有新到来的读者不能立即获取读锁,而是必须阻塞等待,即使当前有其他读者正在读。
- 写者需要等待当前正在执行的读者完成工作。
- 当前所有正在读的读者完成后,写者会立即获得锁并执行写操作。
- 写者完成后,会唤醒所有在它之后等待的读者(如果有的话),然后才考虑是否允许新的写者执行。
潜在问题:读者饥饿(或并发性降低)
这种策略虽然有效防止了写者饥饿,但牺牲了一部分读并发性。在写操作频繁的场景下,读者可能需要等待较长的时间,因为写者会不断地"插队"到读者前面。这可能导致读操作的吞吐量下降和响应时间变长。
适用场景: 适用于写操作相对较多,或者写操作的实时性要求高于读操作的场景,例如需要保证数据能及时更新。
在实际编程中,选择哪种策略取决于应用程序的具体需求,需要在读性能、写性能和公平性之间做出权衡。pthread库中的读写锁默认读者优先的策略。
读写锁的实现原理:
读写锁通常使用一个整型变量来表示状态,高位表示读者数量,低位表示写者状态,通过原子操作来维护这个状态。
3、POSIX读写锁接口
c
// 初始化读写锁
int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *attr);
// 销毁读写锁
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
// 读锁定
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
// 写锁定
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
// 解锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);4、代码示例
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <pthread.h>
int cnt = 0;
std::string message;
void *writework(void *ptr)
{
pthread_rwlock_t *rwlock = (pthread_rwlock_t *)ptr;
while (true)
{
pthread_rwlock_wrlock(rwlock);
cnt++;
message = "This is " + std::to_string(cnt) + "piece message";
pthread_rwlock_unlock(rwlock);
sleep(1);
}
}
void *readwork(void *ptr)
{
pthread_rwlock_t *rwlock = (pthread_rwlock_t *)ptr;
while (true)
{
pthread_rwlock_rdlock(rwlock);
std::cout<< "Thread id: " << gettid() << "Get message :" << message << std::endl;
pthread_rwlock_unlock(rwlock);
usleep(500000);
}
}
int main()
{
pthread_t w1;
pthread_t r1;
pthread_t r2;
pthread_rwlock_t *rwlock = new pthread_rwlock_t;
pthread_rwlock_init(rwlock, nullptr);
pthread_create(&w1, nullptr, writework, rwlock);
pthread_create(&r1, nullptr, readwork, rwlock);
pthread_create(&r2, nullptr, readwork, rwlock);
pthread_join(w1, nullptr);
pthread_join(r1, nullptr);
pthread_join(r2, nullptr);
return 0;
}
写线程1秒钟写一次,读线程0.5秒读一次,2个读线程可以并发的读取数据。
5、读写锁的注意事项
死锁风险:
c
// 错误的用法:同一个线程尝试获取写锁后再获取读锁
pthread_rwlock_wrlock(&rwlock);
// 临界区
pthread_rwlock_rdlock(&rwlock); // 可能导致死锁升级和降级:
- 锁升级:读锁升级为写锁(通常不支持,可能导致死锁)
- 锁降级:写锁降级为读锁(通常支持,是安全的)
性能考虑:
- 在读多写少的场景下,读写锁性能优于互斥锁
- 在写操作频繁的场景下,读写锁可能比互斥锁性能更差
总结对比
| 特性 | 互斥锁 | 自旋锁 | 读写锁 |
|---|---|---|---|
| 阻塞机制 | 睡眠等待 | 忙等待 | 读者不阻塞读者,写者阻塞所有 |
| 开销 | 上下文切换开销大 | CPU空转开销 | 中等 |
| 适用场景 | 临界区较长 | 临界区很短,多核CPU | 读多写少 |
| 并发性 | 差 | 中等 | 好(读并发) |
选择建议:
- 临界区执行时间短(小于线程切换时间)且为多核环境 → 自旋锁
- 读操作远多于写操作 → 读写锁
- 其他情况 → 互斥锁
正确选择锁类型对于多线程程序的性能至关重要,需要根据具体的应用场景和性能要求来做出合适的选择。