note
- 提出了自我奖励的语言模型,通过迭代训练框架实现了模型在指令跟随能力和奖励建模能力上的持续提升。尽管目前的研究还存在许多未探索的领域,如安全性评估和迭代训练的扩展,但该方法展示了模型在不断改进方面的潜力。
文章目录
- note
- 一、研究背景
- 二、研究方法
- 三、实验设计
-
- [1. 数据收集](#1. 数据收集)
- [2. 实验步骤](#2. 实验步骤)
- [3. 评估指标](#3. 评估指标)
- 四、结果分析
- 五、论文评价
- 六、相关问题
-
- 问题1:自我奖励的语言模型在训练过程中是如何实现自我指令生成的?
- 问题2:在实验中,自我奖励的语言模型在不同阶段的性能表现如何?
- 问题3:自我奖励的语言模型在奖励建模能力上有哪些改进?
-
- [1. 使用EFT数据增强模型性能](#1. 使用EFT数据增强模型性能)
- [2. 自我训练过程持续提升能力](#2. 自我训练过程持续提升能力)
- [3. 人类评估验证结果有效性](#3. 人类评估验证结果有效性)
- Reference
一、研究背景
Self-Rewarding Language Models
- 研究问题:这篇文章要解决的问题是如何通过自我奖励的语言模型(Self-Rewarding Language Models)来实现超人类智能代理。具体来说,现有的方法通常依赖于人类偏好数据来训练奖励模型,然后使用这些模型来训练大型语言模型(LLM),但这种方法存在瓶颈,即人类偏好数据的大小和质量限制。
- 研究难点:该问题的研究难点包括:人类偏好数据的质量和数量限制;奖励模型的固定性无法在LLM训练过程中进行改进;如何在不增加外部数据的情况下,通过自我奖励机制实现模型的持续改进。
- 相关工作:该问题的研究相关工作包括:从人类偏好数据中学习奖励模型的强化学习从人类反馈(RLHF)方法;避免训练奖励模型的直接偏好优化(DPO)方法;以及其他迭代偏好训练方案,如成对厌恶优化(PCO)。
二、研究方法
这篇论文提出了自我奖励的语言模型来解决超人类智能代理的问题。具体来说,
1、自我指令生成:首先,模型通过少样本提示生成新的提示,并从自身生成多个候选响应。然后,模型使用LLM作为评委来评估这些响应,分数范围为0到5。
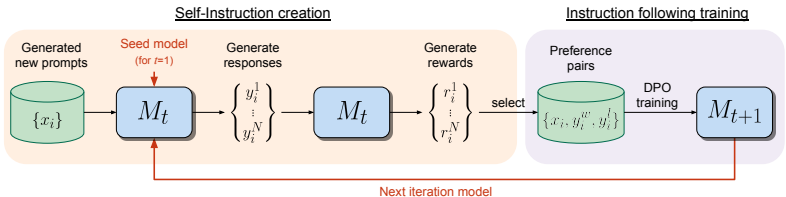
2、迭代训练框架
模型在每次迭代中使用自我生成的偏好数据来训练自己。初始阶段,模型使用种子数据进行监督微调(SFT),然后通过AI反馈训练(AIFT)数据来增强训练集。迭代训练过程如下:
- 初始模型( M 0 M_{0} M0):基础预训练的LLM,未进行微调。
- 第一次迭代( M 1 M_{1} M1):在IFT和SFT种子数据上进行SFT微调。
- 第二次迭代( M 2 M_{2} M2) :在 M 1 M_{1} M1生成的AIFT数据上进行DPO训练。
- 第三次迭代( M 3 M_{3} M3) :在 M 2 M_{2} M2生成的AIFT数据上进行DPO训练。
3、LLM作为评委:
模型通过LLM作为评委来评估自身生成的响应,并将其作为下一次迭代的训练数据。这种机制使得奖励模型可以在训练过程中不断改进。
三、实验设计
1. 数据收集
- 基础模型 :实验使用 Llama 2 70B 作为基础预训练模型。
- 种子数据 :种子数据来源于 Open Assistant 数据集中的高质量对话示例,这些数据用于:
- 监督微调(SFT)
- 训练"LLM作为评委"的评估器
2. 实验步骤
实验包含三次迭代训练:
- 初始模型 (M₁) :使用IFT和EFT种子数据进行SFT微调,得到初始模型 ( M_{1} )。
- 第二次迭代 (M₂) :使用 ( M_{1} ) 生成的AIFT数据进行DPO训练,得到模型 ( M_{2} )。
- 第三次迭代 (M₃) :使用 ( M_{2} ) 生成的AIFT数据进行DPO训练,得到模型 ( M_{3} )。
3. 评估指标
实验从以下两个方面评估模型性能:
- 指令跟随能力 :使用 GPT-4 评估器 在多个测试提示上进行评估。
- 奖励建模能力 :通过模型排名与人类排名之间的相关性来衡量。

四、结果分析
1、指令跟随能力:
- M1模型 :在头对头评估中胜率为 30.5%,与仅使用IFT数据的SFT基线模型表现相似。
- M2模型 :在头对头评估中胜率达到 55.5%,表现显著优于M1和SFT基线模型。
- M3模型 :在头对头评估中胜率为 47.7%,性能进一步优化,优于M2和SFT基线。
- AlpacaEval 2.0 基准测试 :M3在该排行榜上的胜率为 20.44%,其表现超过了Claude 2、Gemini Pro和GPT-4 0613等现有前沿模型。
2、奖励建模能力
- 数据增强效果:使用EFT数据对模型进行增强后,其作为LLM评委的性能相比仅使用IFT数据时,在各项指标上均有提升。
- 自我训练增益 :自我训练过程持续提高了模型的奖励建模(即评判)能力。具体表现为:
- M₂模型 在各项指标上均优于 M₁模型。
- M₃模型 在各项指标上均优于 M₂模型。
- 评估有效性:通过人类评估验证了上述自动评估结果的准确性,证实后期迭代模型(M₂, M₃)的评判能力确实优于前期模型(M₁)。
五、论文评价
1、优点与创新
自我奖励语言模型:提出了自我奖励语言模型(Self-Rewarding Language Models),能够在训练过程中自我生成和评估新的指令示例,从而提高模型的整体性能。
迭代DPO框架:采用了类似于Xu等人(2023)提出的迭代DPO(Iterative DPO)框架,通过自我生成的偏好数据来训练模型,避免了传统方法中冻结奖励模型的瓶颈。
多任务学习:将奖励建模任务和指令跟随任务整合到同一系统中,实现了任务之间的迁移学习。
自我改进的奖励模型:奖励模型在训练过程中不断更新,而不是固定不变,从而提高了模型自我改进的能力。
实验结果:在AlpacaEval 2.0排行榜上,经过三次迭代训练的模型在多个指标上优于现有的许多系统,包括Claude 2、Gemini Pro和GPT-4 0613。
2、不足与反思
迭代次数有限:目前仅在单一设置中运行了三次迭代,未来需要研究更多迭代和不同语言模型在不同设置下的"扩展规律"。
模型生成长度增加:观察到模型生成长度增加,已知长度与质量估计相关,需要更深入地理解这一现象及其在结果中的具体表现。
奖励操纵的可能性:需要探讨在框架内是否会发生所谓的"奖励操纵"(reward hacking),以及在什么情况下会发生。
安全性评估:未来的研究方向包括进行安全性评估和在框架内探索安全性训练,以提高模型的安全性。
更多评估:需要进一步的评估,包括安全性评估和理解迭代训练的极限。
六、相关问题
问题1:自我奖励的语言模型在训练过程中是如何实现自我指令生成的?
自我奖励的语言模型通过少样本提示生成新的提示,并从自身生成多个候选响应。具体步骤如下:
生成新提示:使用少样本提示从原始种子IFT数据中采样生成新的提示。
生成候选响应:模型根据新生成的提示生成多个多样的候选响应。
自我评估:模型使用LLM作为评委来评估这些候选响应,分数范围为0到5。评估过程通过LLM-as-a-Judge机制实现,即将响应评估任务转化为指令跟随任务。
通过这种方式,模型能够在每次迭代中生成新的训练数据,并在下一次迭代中使用这些数据来进一步改进自身。
问题2:在实验中,自我奖励的语言模型在不同阶段的性能表现如何?
| 模型版本 | 训练方式 | 头对头评估胜率 | 性能对比说明 |
|---|---|---|---|
| 初始模型 ( M 0 M_{0} M0) | 基于基础预训练的LLM,未进行微调 | 30.5% | - |
| 第一次迭代 ( M 1 M_{1} M1) | 在IFT和EFT种子数据上进行SFT微调 | 30.5% | 性能与 M 0 M_{0} M0 相似 |
| 第二次迭代 ( M 2 M_{2} M2) | 在 M 1 M_{1} M1 生成的AIFT数据上进行DPO训练 | 55.5% | 显著优于 M 1 M_{1} M1 和SFT基线 |
| 第三次迭代 ( M 3 M_{3} M3) | 在 M 2 M_{2} M2 生成的AIFT数据上进行DPO训练 | 47.7% | 进一步优化 ,优于 M 2 M_{2} M2 和SFT基线 |
权威基准测试结果:
在 AlpacaEval 2.0 排行榜 上,最终迭代模型 M 3 M_{3} M3 的胜率为 20.44% ,其表现超过了 Claude 2 、Gemini Pro 和 GPT-4 0613 等现有前沿模型。
问题3:自我奖励的语言模型在奖励建模能力上有哪些改进?
1. 使用EFT数据增强模型性能
相比于仅使用IFT数据,使用EFT数据显著增强了模型作为LLM评委的性能,各项指标均有提升。
- 具体示例 :Pairwise Accuracy 从 65.1% 提高到 78.7%。
2. 自我训练过程持续提升能力
通过自我训练过程,模型的奖励建模能力得到进一步提高。
- 性能对比 : M 2 M_{2} M2 在各项指标上均优于 M 1 M_{1} M1,而 M 3 M_{3} M3 在各项指标上均优于 M 2 M_{2} M2。
- 具体示例 : M 2 M_{2} M2 的 Pairwise Accuracy 达到 80.4% ,显著高于 M 1 M_{1} M1 的 78.7%。
3. 人类评估验证结果有效性
通过人类评估验证了上述自动评估结果的准确性。
- 结论 :后期迭代模型( M 2 M_{2} M2, M 3 M_{3} M3)在各项指标上均优于前期迭代模型( M 1 M_{1} M1)。
- 核心意义 :这证明了自我奖励机制能够有效地提高模型的奖励建模能力。
Reference
1 Self-Rewarding Language Models