前言
在日常开发工作中,PDF文档处理一直是个让人头疼的问题。传统的PDF处理方式要么功能单一只能做简单的文本提取,要么需要购买昂贵的商业软件,开发者想实现批量表单填充、文档自动化处理这些需求往往要花费大量时间去调研各种库、写大量重复代码,效率低下不说,遇到复杂场景还经常卡壳。特别是对于那些需要处理大量PDF表单的企业应用来说,人工填写既费时又容易出错,急需一套完整的自动化解决方案。
ModelScope ms-agent 项目中的 PDF-Skill 就是为解决这些痛点而生的开源工具包,它整合了 pypdf、pdfplumber、reportlab 等多个成熟的 Python 库,再加上 poppler-utils、qpdf 等命令行工具,提供了从文本提取、表格识别、PDF创建、表单填充到图像处理、安全加密的全套解决方案。这套工具包最大的亮点在于"双路径表单处理" ------ 既支持可填充表单的自动化填写,也能通过精确坐标定位处理那些不可填充的扫描版表单,配合可视化验证机制(蓝色标签框 + 红色输入框),确保每个字段都准确无误。

核心技术点
另外提供了全套解决方案:在文本提取 、表格识别 、PDF创建 、表单填充 、图像处理 、安全加密 等提供全面办公自动化功能

前几天看到魔搭社区日报中看到这篇关于PDF 的skill。详细文章 modelscope.cn/learn/2558,...
今天我们就手把手教大家如何使用这个强大的工具包,从环境配置到实战应用,体验一下这套"AI Agent专属PDF处理神器"的完整能力。话不多说,咱们直接开干!
项目介绍
✨ 核心特性
PDF-Skill 是一个功能全面的 PDF 处理工具包,主要特性包括:
- 📝 智能文本提取: 从PDF中提取纯文本内容,支持保留原始布局,将表格转换为 pandas DataFrame 格式,轻松导出到 Excel
- 🎨 专业PDF创建: 使用 ReportLab 库创建新PDF,支持 Canvas(低级绘图)和 Platypus(结构化文档)两种方式
- 🔧 全能文档操作: 合并、拆分、旋转、元数据提取、页面重排列、文档优化和修复一应俱全
- 📋 双路径表单处理: 可填充表单自动填写 + 不可填充表单坐标定位,配合视觉验证机制确保准确性
- 🖼️ 图像处理套件: 提取嵌入图像、PDF转高清图片、添加水印,支持可配置分辨率和快速渲染
- 🔒 安全加密功能: PDF密码保护、权限控制、加密/解密操作,保障文档安全
- 🔍 OCR文字识别: 针对扫描版PDF进行OCR识别,使用 pytesseract 和 pdf2image 将图像型PDF转为可搜索文本
- ⚡ 性能优化策略: 支持大文件流式处理、内存高效分块处理、批处理和错误恢复机制

🛠️ 技术栈
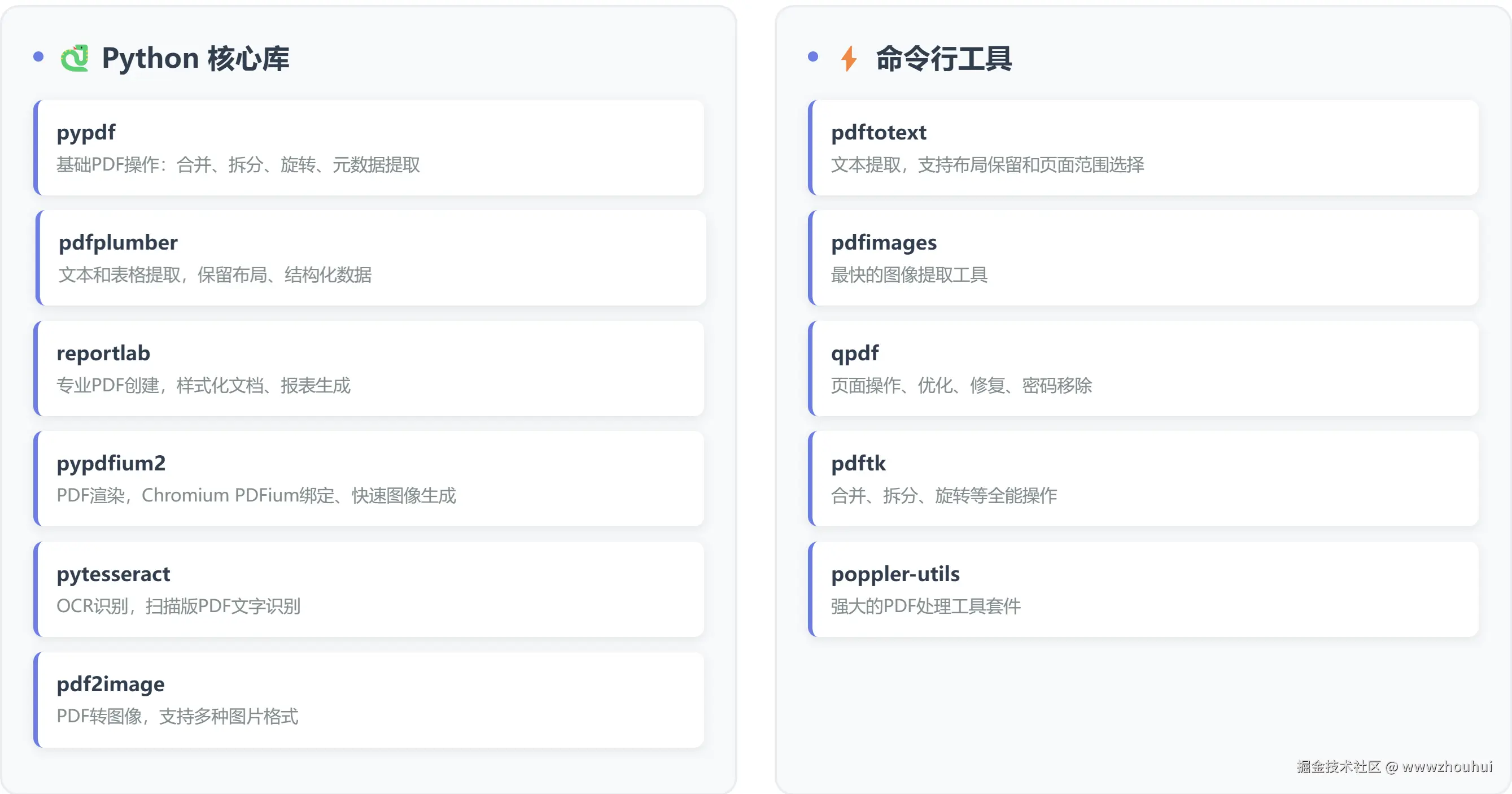
Python 核心库
| 库名 | 主要功能 | 特点 |
|---|---|---|
| pypdf | 基础PDF操作 | 合并、拆分、旋转、元数据提取 |
| pdfplumber | 文本和表格提取 | 保留布局、结构化表格数据、坐标信息 |
| reportlab | PDF创建 | 专业报表生成、样式化文档 |
| pypdfium2 | PDF渲染 | Chromium的PDFium绑定、快速图像生成 |
| pytesseract | OCR识别 | 扫描版PDF文字识别 |
| pdf2image | 图像转换 | PDF转图像 |
命令行工具
| 工具 | 功能 |
|---|---|
| pdftotext | 文本提取,支持布局保留和页面范围选择 |
| pdfimages | 最快的图像提取工具 |
| qpdf | 页面操作、优化、修复、密码移除 |
| pdftk | 合并、拆分、旋转等操作 |
JavaScript 库
项目还提供 JavaScript 支持,方便前端集成:
- pdf-lib: 在任何JavaScript环境中创建和修改PDF
- pdfjs-dist: Mozilla的浏览器端PDF渲染方案
🎯 应用场景
PDF-Skill 适用于以下典型场景:
-
自动化表单填写: 批量处理PDF表单、企业文档自动化、数据迁移和录入
-
文档数据提取: 从PDF报表中提取结构化数据、表格转Excel、文本内容分析
-
PDF文档管理: 文档合并与拆分、批量处理和组织、文档归档和整理
-
报表生成: 动态生成PDF报告、企业报表自动化、发票和单据生成
-
安全文档处理: 添加密码保护、敏感文档加密、权限管理
-
OCR和数字化: 扫描文档识别、历史文档数字化、可搜索PDF创建

🌟 核心亮点
Claude Code 深度集成
专门为 Claude Code 设计的工作流,支持 AI 辅助的 PDF 处理任务,智能化表单识别和填充。开发者可以在 AI Agent 中直接调用这些能力,实现真正的文档处理自动化。
像素级坐标定位
支持像素级的精确定位,可视化验证机制让你看得见摸得着 ------ 蓝色矩形标记标签区域,红色矩形标记输入区域,防止字段重叠的智能检查,确保每个表单字段都填得准确无误。
模块化设计
每个功能都有独立的脚本和工具,清晰的文件组织结构让你随用随取。无论是简单的文本提取还是复杂的表单填充,都能快速找到对应工具,极易维护和扩展。
部署实战
3.1 环境准备
我们首先需要准备 Python 环境。PDF-Skill 官方推荐使用 Python 3.11+ 版本,这样能获得最佳的兼容性和性能。
对于 Linux/Mac 用户,可以使用系统自带的包管理器:
shell
# Ubuntu/Debian
sudo apt update
sudo apt install python3.11 python3.11-venv python3-pip
# macOS (使用 Homebrew)
brew install python@3.11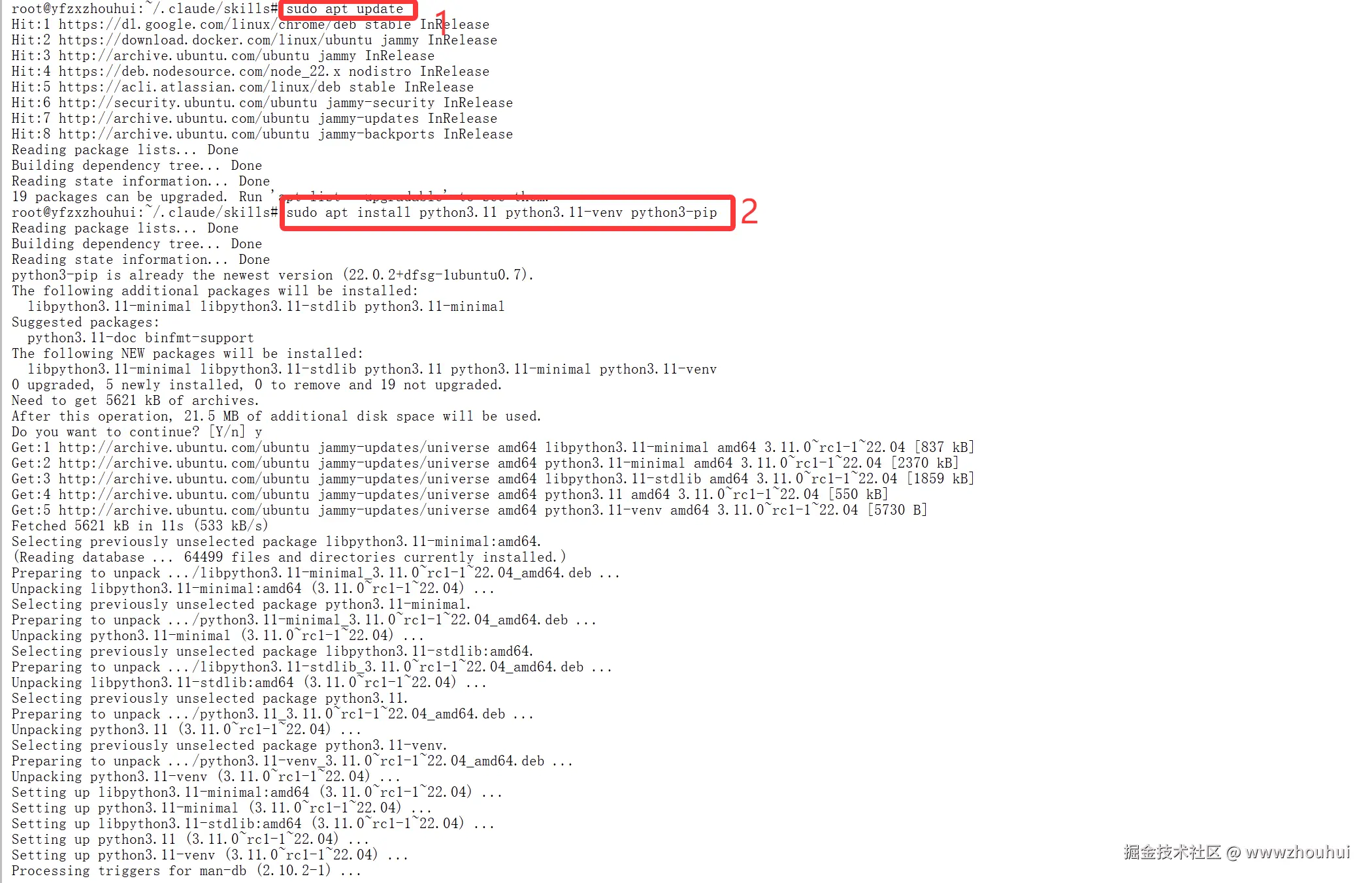
对于 Windows 用户,建议从 Python 官网下载安装包:
shell
# 检查 Python 版本
python --version
# 应该看到 Python 3.11 或更高版本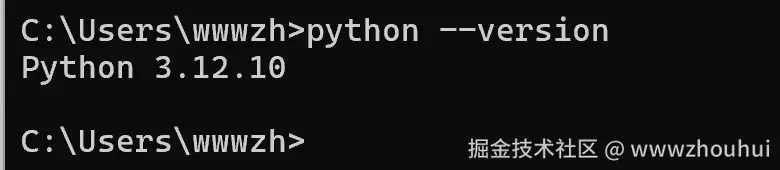
3.2 项目下载
接下来我们从 GitHub 下载 PDF-Skill 项目。打开终端,执行以下命令:
shell
# 克隆项目到本地
git clone https://github.com/modelscope/ms-agent.git
# 进入 PDF-Skill 目录
cd ms-agent/projects/agent_skills/skills/pdf
# 查看项目结构
ls -la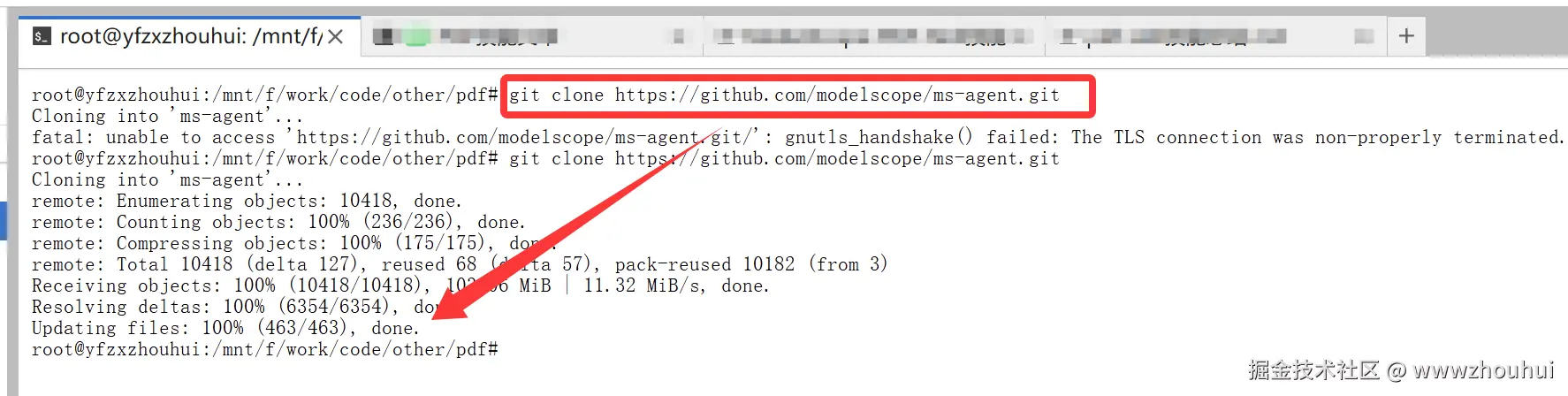
等待几分钟后下载完成,你会看到以下目录结构:
bash
pdf/
├── scripts/ # 8个实用Python脚本
├── SKILL.md # 主要技能文档
├── forms.md # 表单填写工作流程
├── reference.md # 高级功能参考
└── LICENSE.txt # 许可证信息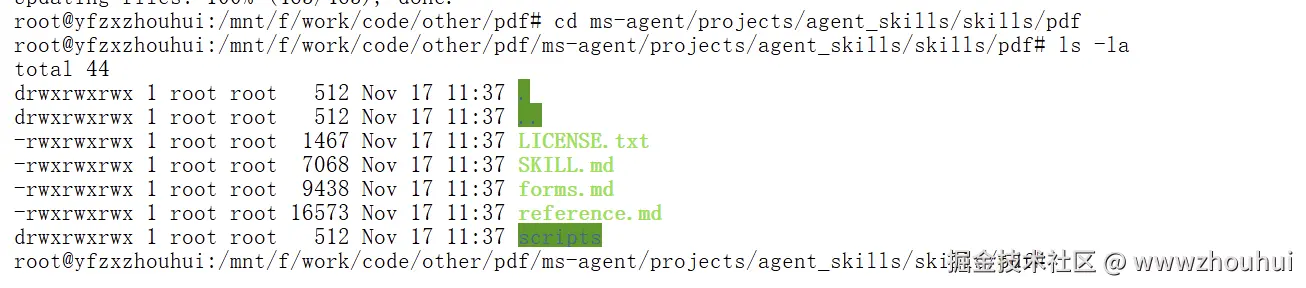
3.3 依赖安装
PDF-Skill 依赖多个 Python 库和系统工具。我们先安装 Python 依赖:
shell
# 创建虚拟环境(推荐)
python3 -m venv venv
# 激活虚拟环境
# Linux/Mac:
source venv/bin/activate
# Windows:
venv\Scripts\activate
# 安装 Python 依赖
pip install pypdf pdfplumber reportlab pypdfium2 pytesseract pdf2image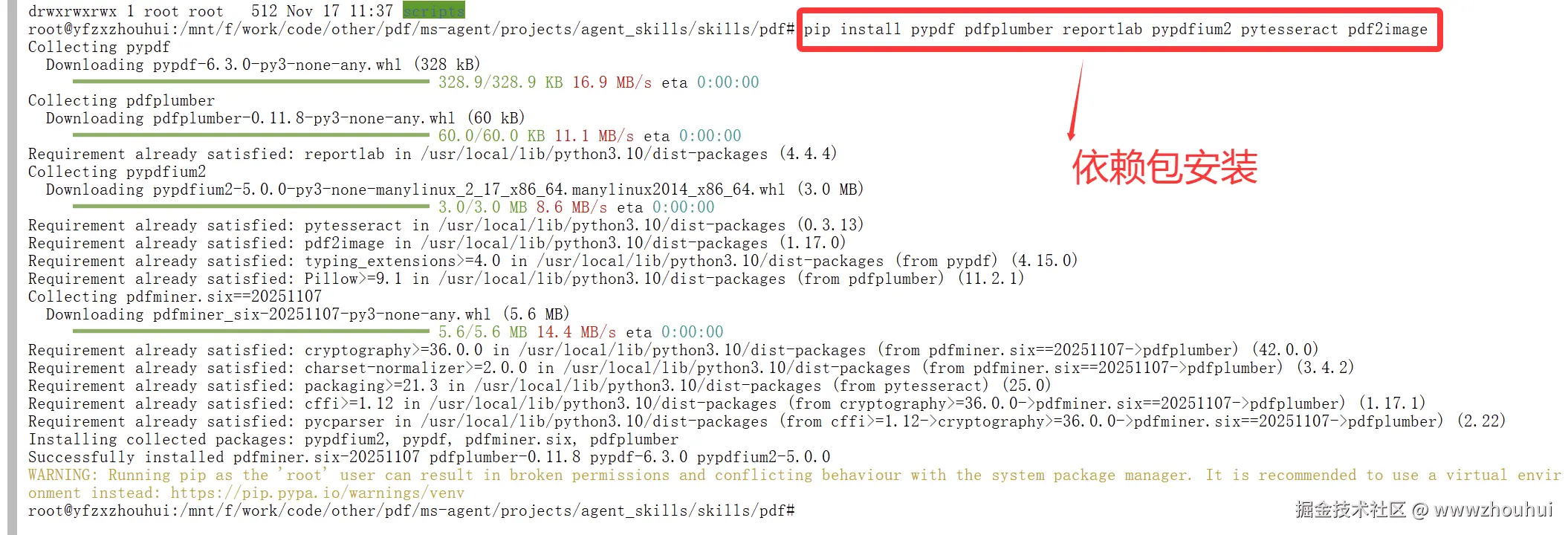
接下来安装命令行工具。这些工具能大幅提升某些操作的性能:
Ubuntu/Debian:
shell
sudo apt install poppler-utils qpdf pdftk tesseract-ocrmacOS:
shell
brew install poppler qpdf pdftk tesseractWindows: 下载预编译版本:
- Poppler: github.com/oschwartz10...
- QPDF: github.com/qpdf/qpdf/r...
- Tesseract: github.com/UB-Mannheim...
安装完成后验证一下:
shell
# 验证工具安装
pdftotext -v
qpdf --version
tesseract --version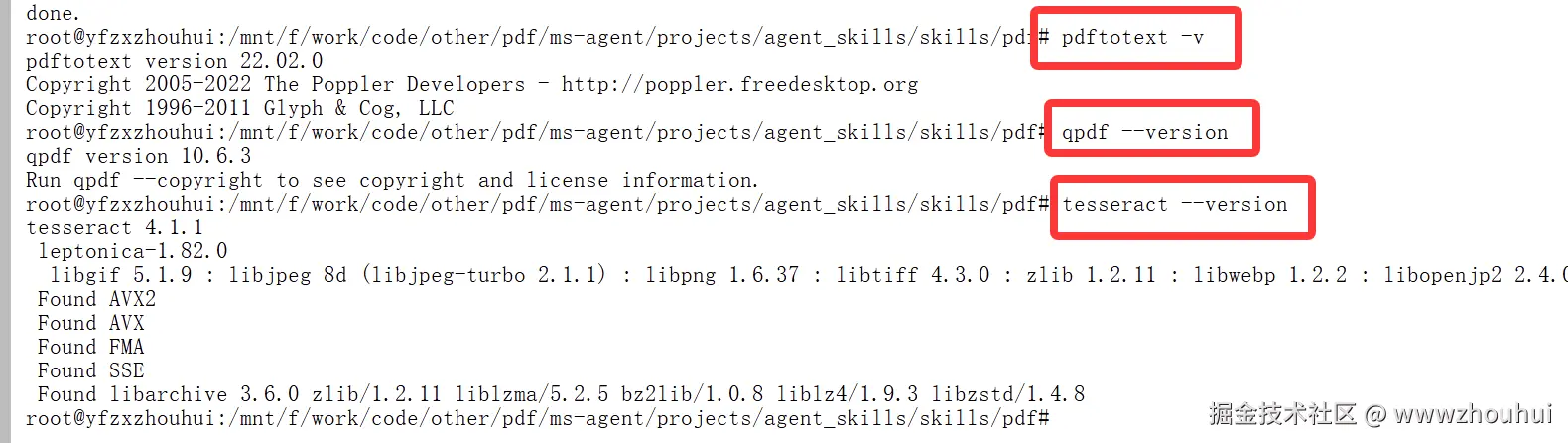
呵呵,看到版本号就说明安装成功了!
3.4 脚本工具介绍
PDF-Skill 在 scripts/ 目录下提供了8个实用脚本,让我们逐一了解:
表单处理脚本
shell
# 1. 检查 PDF 是否包含可填充字段
python scripts/check_fillable_fields.py your_form.pdf
# 2. 提取表单字段信息(生成 JSON 映射)
python scripts/extract_form_field_info.py your_form.pdf
# 3. 填充可填充表单
python scripts/fill_fillable_fields.py your_form.pdf field_values.json output.pdf
# 4. 使用注释填充不可填充表单
python scripts/fill_pdf_form_with_annotations.py your_form.pdf fields.json output.pdf验证和转换脚本
shell
# 5. 验证边界框坐标
python scripts/check_bounding_boxes.py fields.json
# 6. 边界框验证单元测试
python scripts/check_bounding_boxes_test.py
# 7. PDF 转图像
python scripts/convert_pdf_to_images.py document.pdf output_dir/
# 8. 创建可视化验证图像
python scripts/create_validation_image.py your_form.pdf fields.json validation.pngclaude skill 安装
接下来我们把这个pdf skill 安装到claude code里面
复制github.com/modelscope/... 到claude skills里面
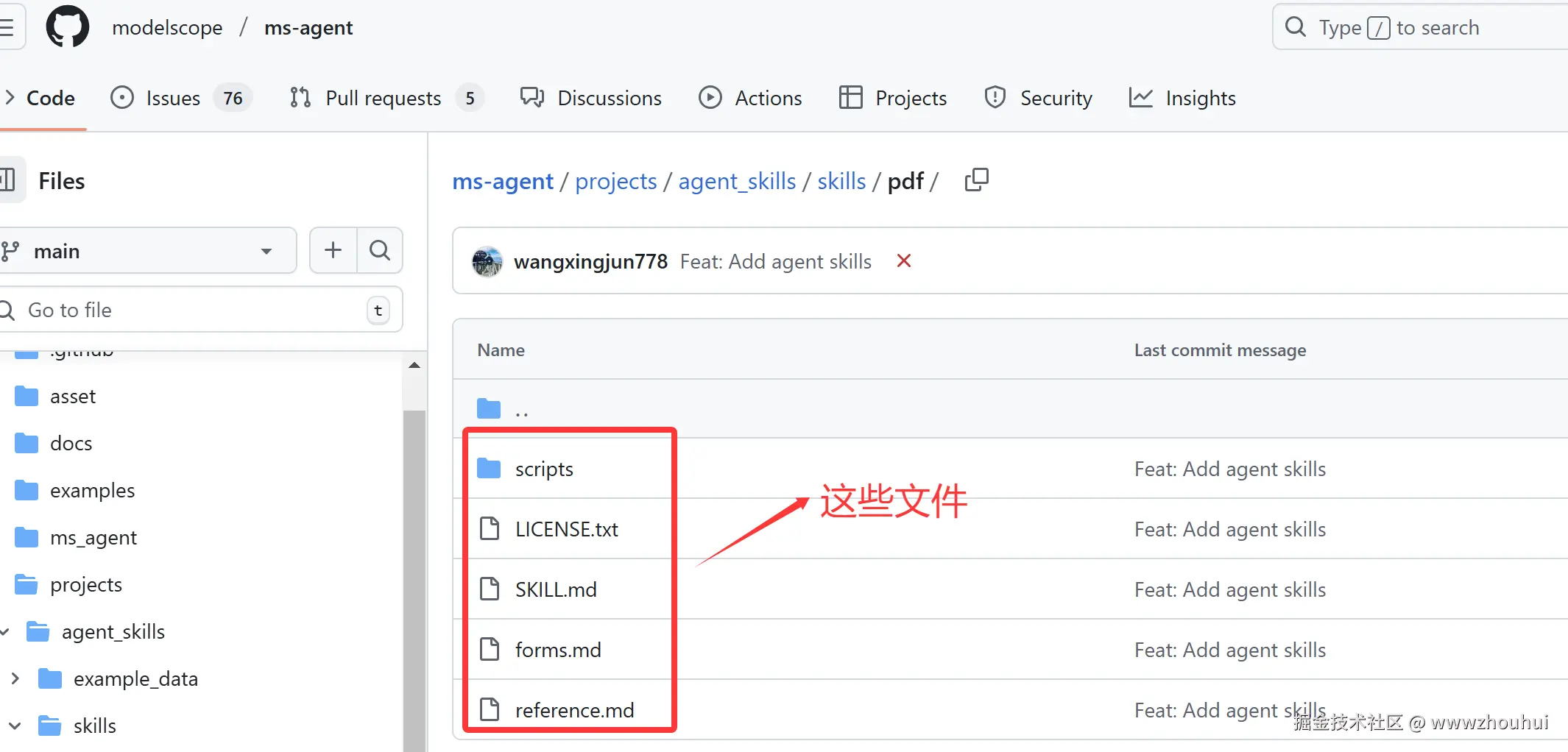
复制后
bash
/root/.claude/skills/pdf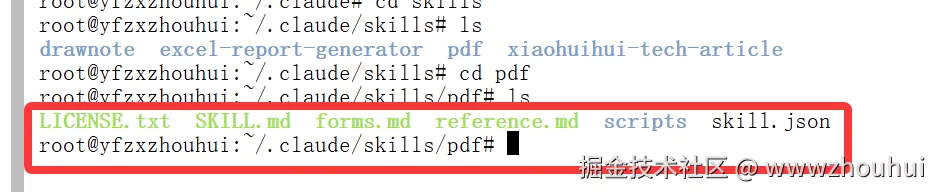
当然你也可以偷懒让AI 帮你干。
bash
请帮我把/mnt/f/work/code/other/pdf/ms-agent/projects/agent_skills/skills/pdf 这个skills安装到系统的claude skills 中。 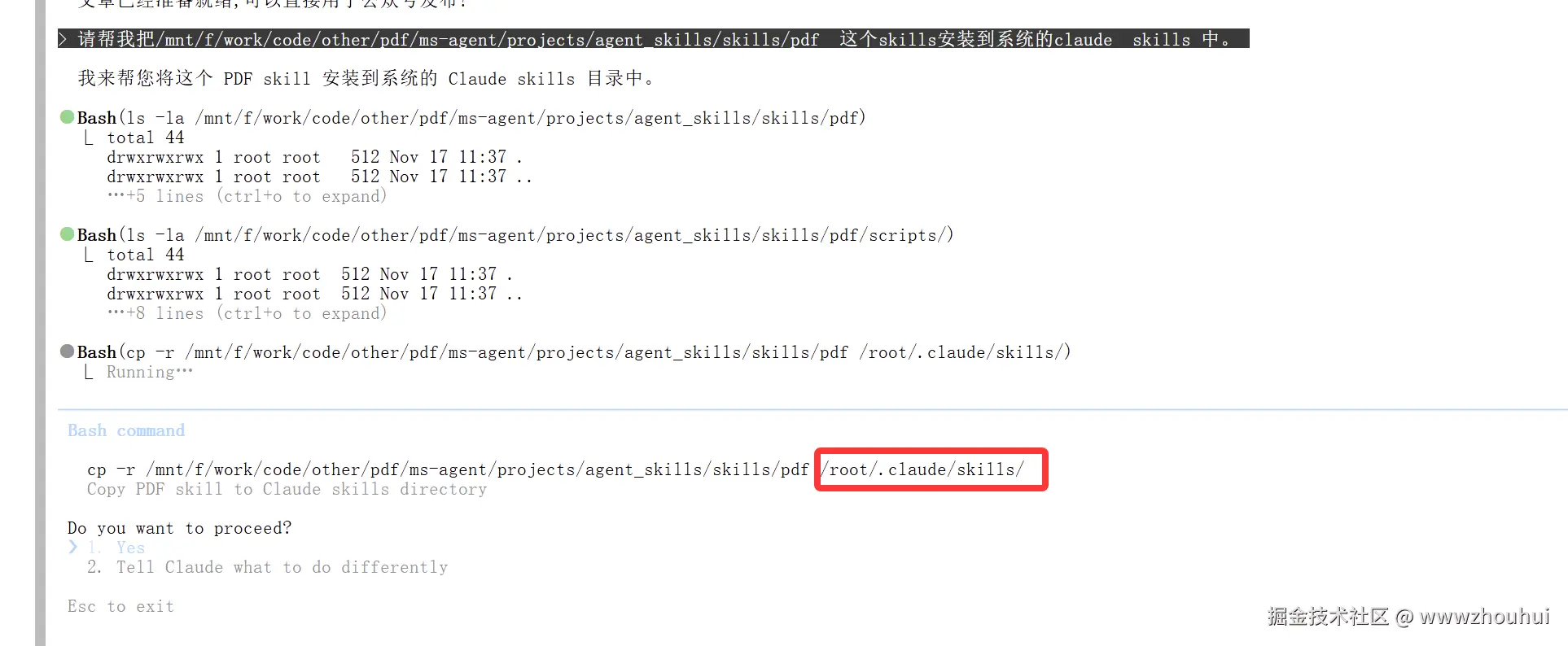
实战案例1: PDF转成图片
我这里有一张PDF的发票信息。我希望这个skill帮我转成图片。这个在平时我们工作中也有经常遇到。
提示词如下
请使用pdf 这个skill帮我把当前文件下"增值税电子普通发票4.pdf" 转成图片并输出。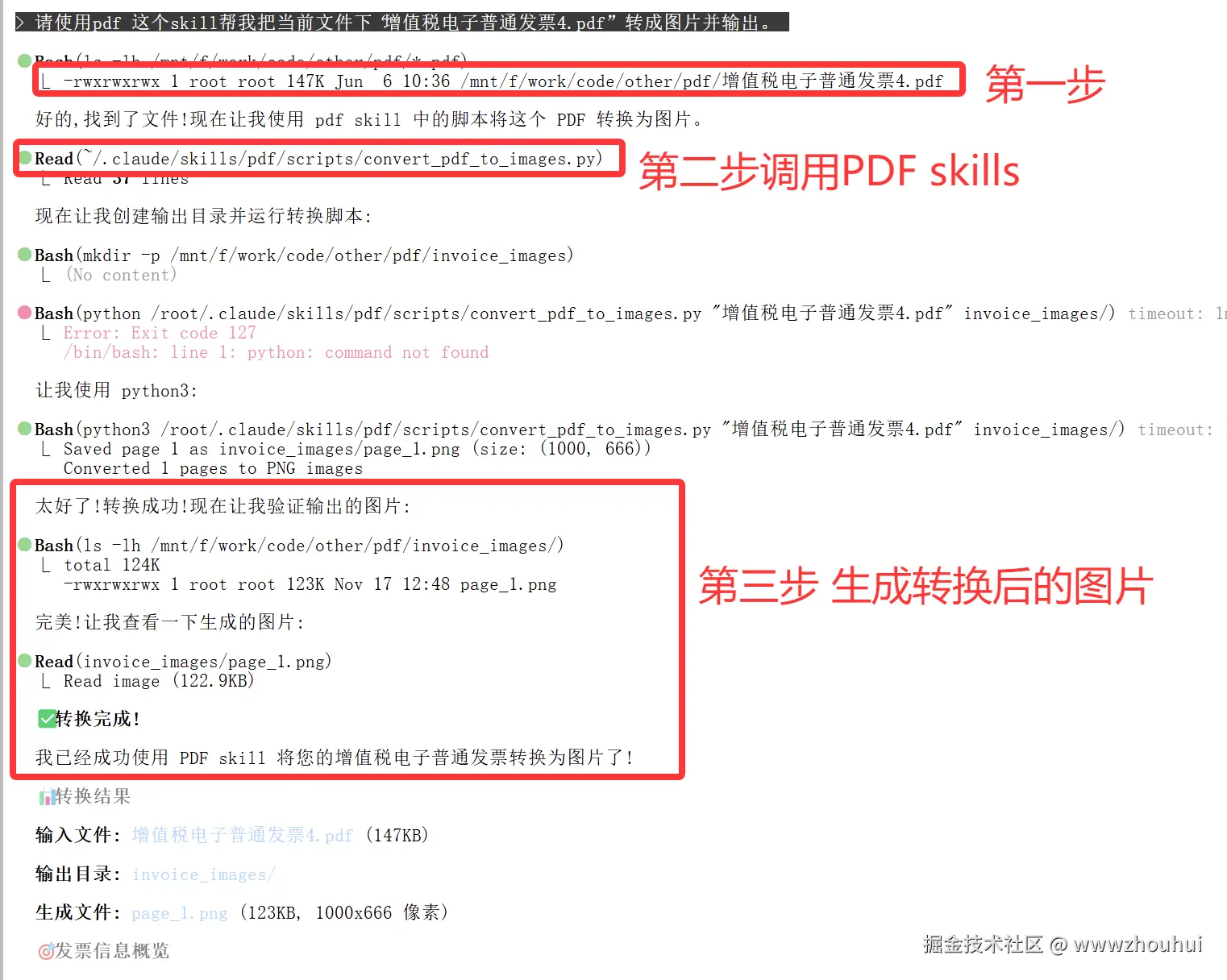
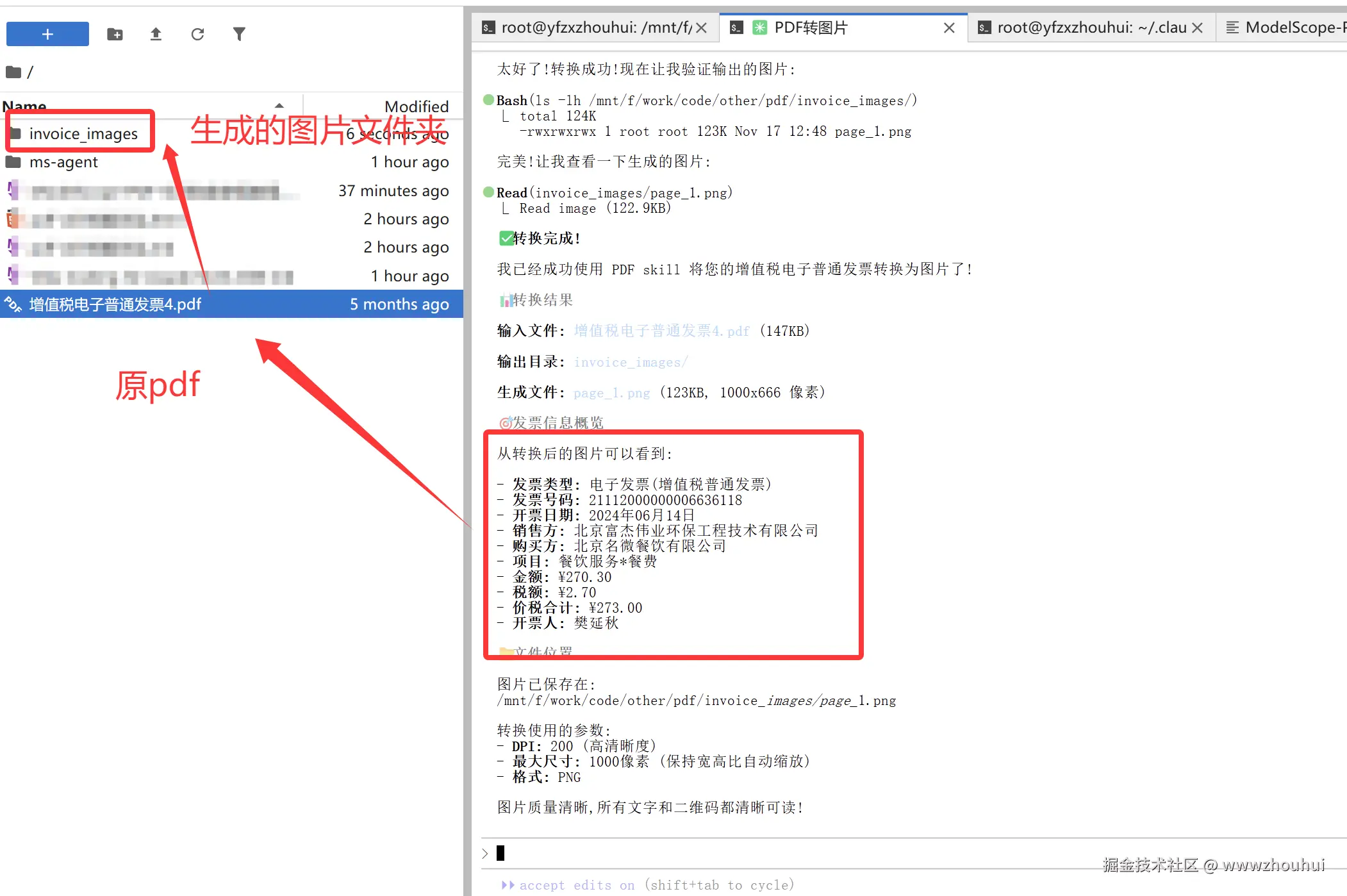
我们打开转换后的文件夹查看转换后的图片
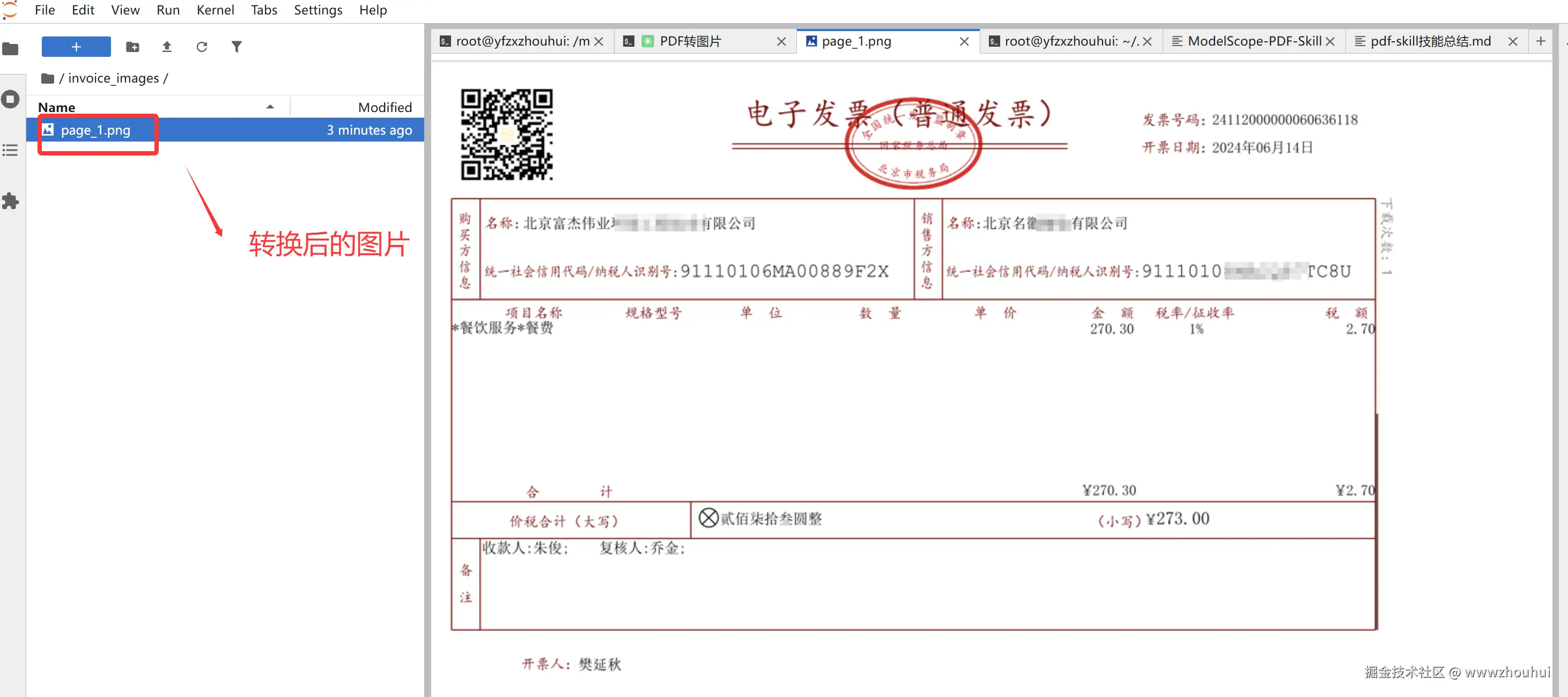
OK 一行命令就帮我把这个pdf 转成图片了。如果我有一个文件夹里面有几百个PDF。我是不是参考上面的提示词稍微修改一下,这活是不是AI 也是分分钟帮我把它干完了。嘿嘿,感兴趣小伙伴可以自己来尝试。时间关系这里不做演示。
实战案例2: 处理扫描版表单
有些老旧的表单是扫描版,没有可填充字段,怎么办?PDF-Skill 的"坐标定位法"来帮忙!
我这里有一个2025年101中学八年级期中考试成绩表PDF版本,我们打开看一下。
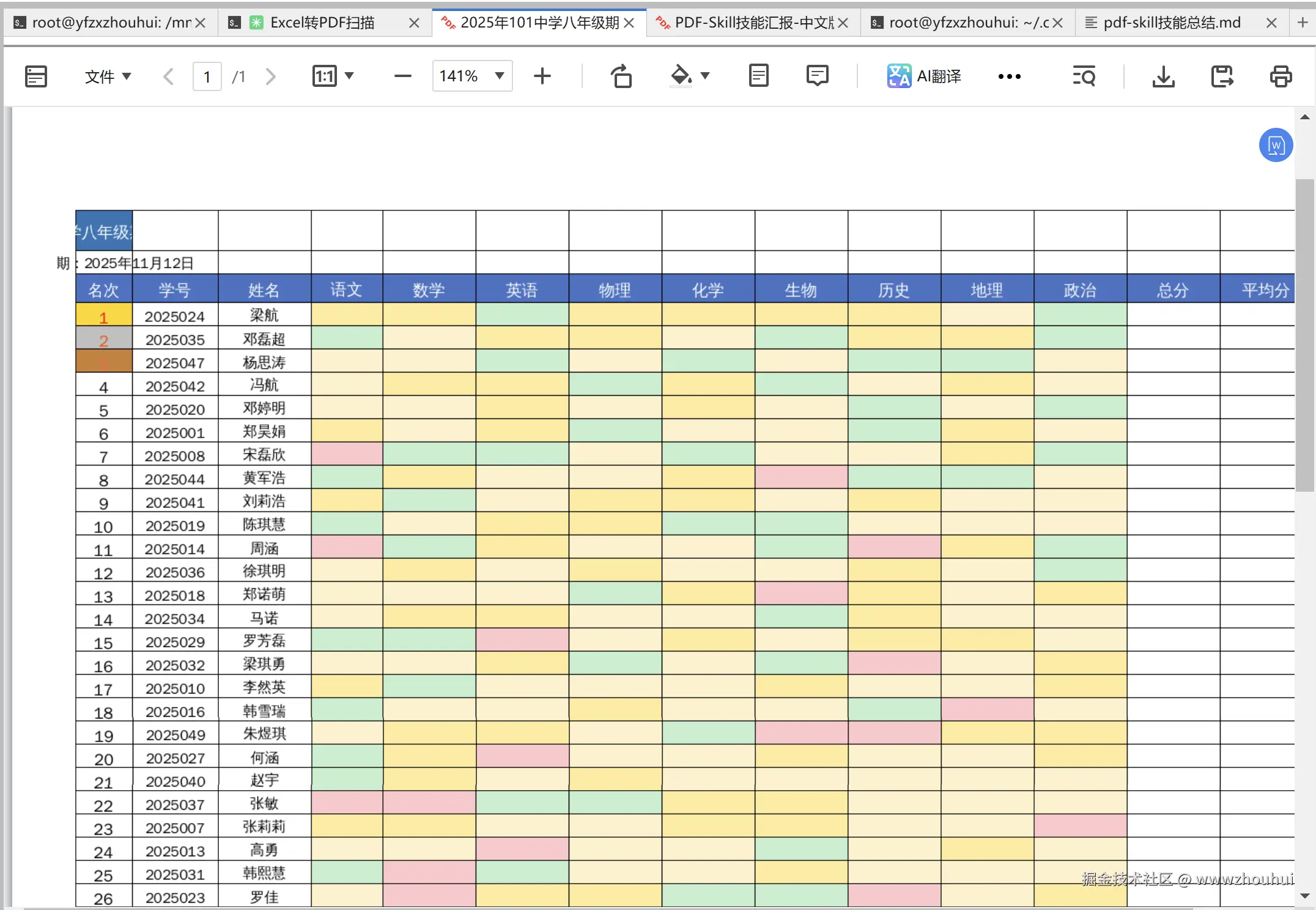
我这里有个学生的成绩单一个基于markdown格式的文档数据(以上数据都是假的不是真实的,请勿当真)
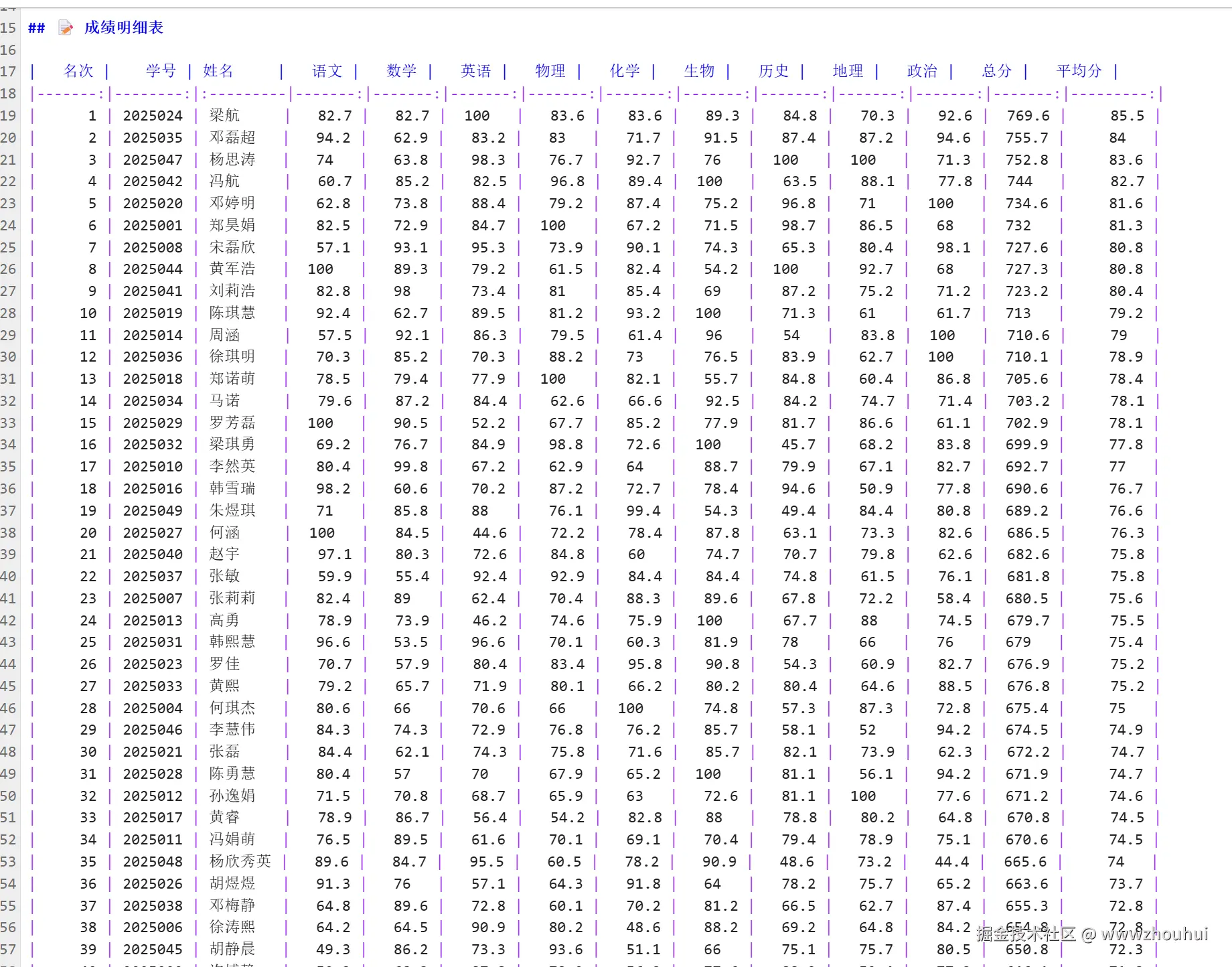
我这里的需求就是基于这个成绩数据填充到上面的额PDF文档中。接下来我们使用PDF-Skill来实现
提示词
请使用pdf 这个skill帮我把当前文件下"2025年101中学八年级期中考试成绩表-扫描版.pdf" 内容填充,填充的数据请基于"2025年101中学八年级期中考试成绩表.md" 文档里面的数据。填充后输出"2025年101中学八年级期中考试成绩表-扫描版-填充版.pdf"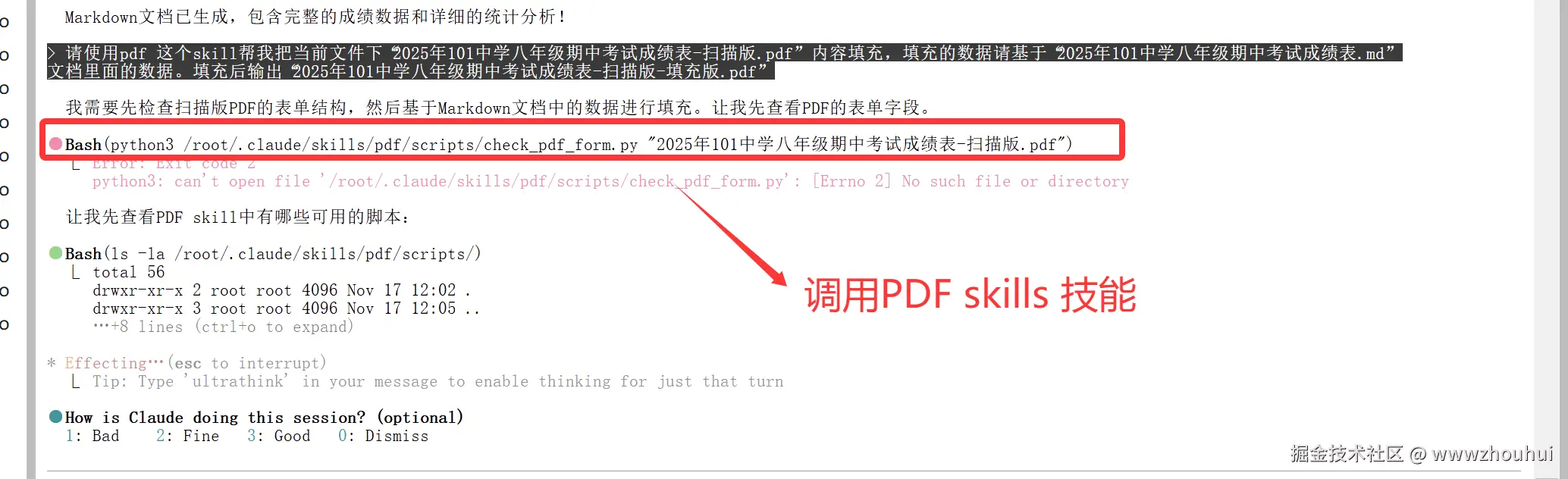

分分钟AI 也帮我干完了。我们看一下生产后的效果
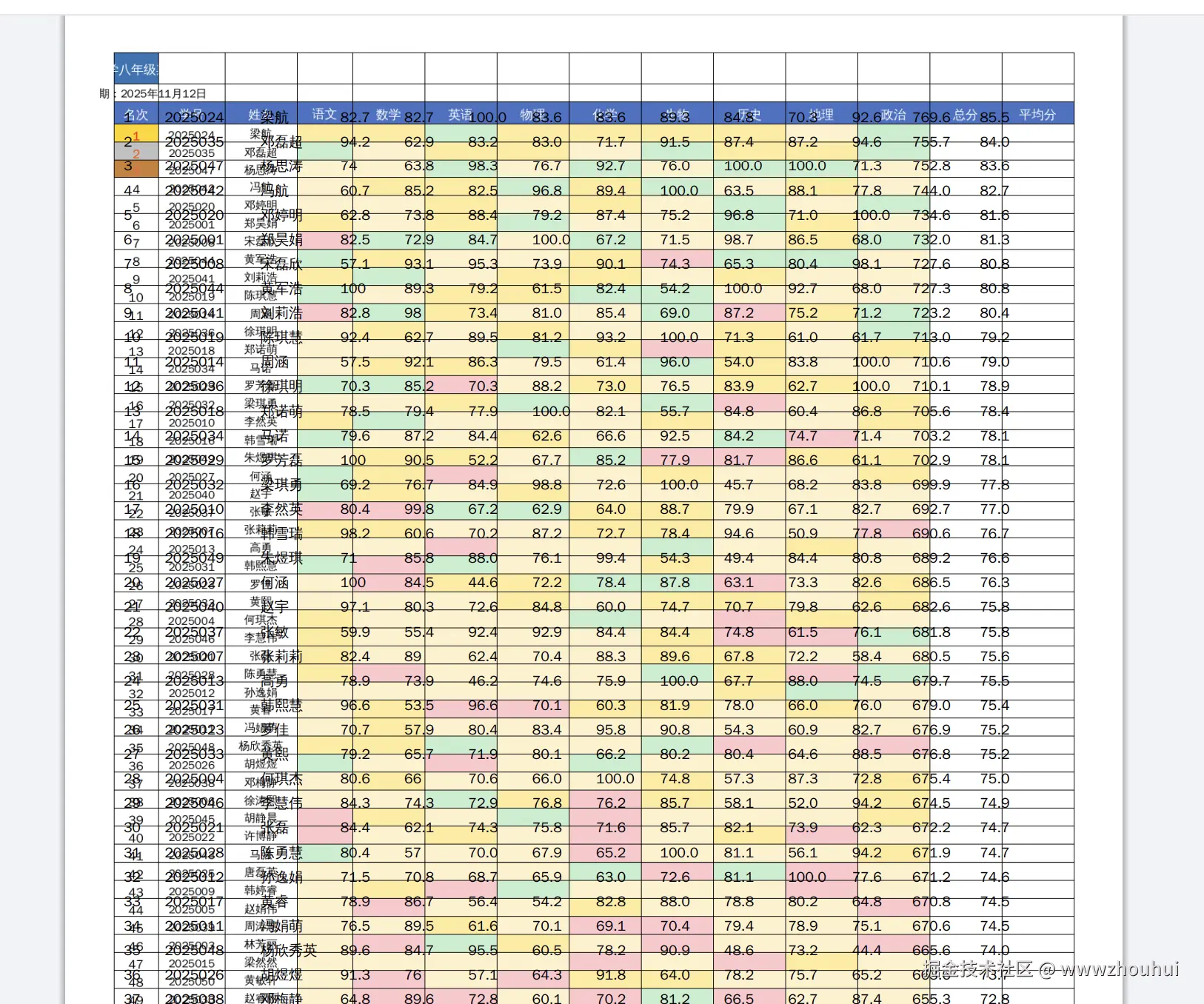
虽然不完美,但是确实也帮我填充了。如果表格内容不多,表格空间足够大,我相信也是可以完成的。(AI还有进步空间。)
实战案例3: 提取表格数据到 Excel
很多时候我们需要从 PDF 报表中提取数据做分析。传统方法是手工复制粘贴,PDF-Skill 可以一键搞定。
我们接下来还是拿刚才的PDF发票,让它帮我把这发票提取到Excel中
提示词
请使用pdf 这个skill帮我把当前文件下"增值税电子普通发票4.pdf" PDF里面发票内容提取生成excel表格。
请注意PDF里面发票明细可能有多行,把全票面信息全部提取生成excel表格并输出。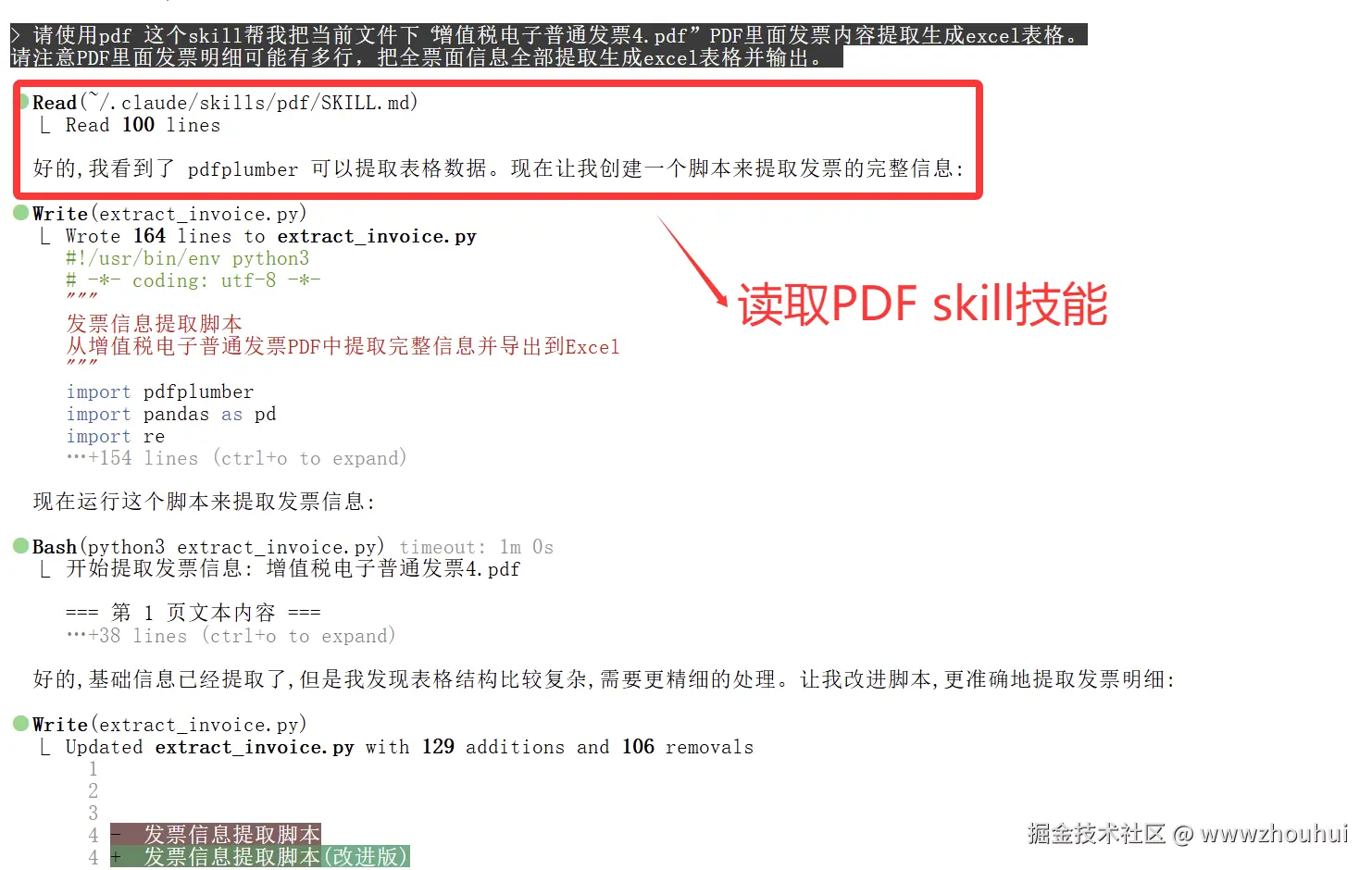
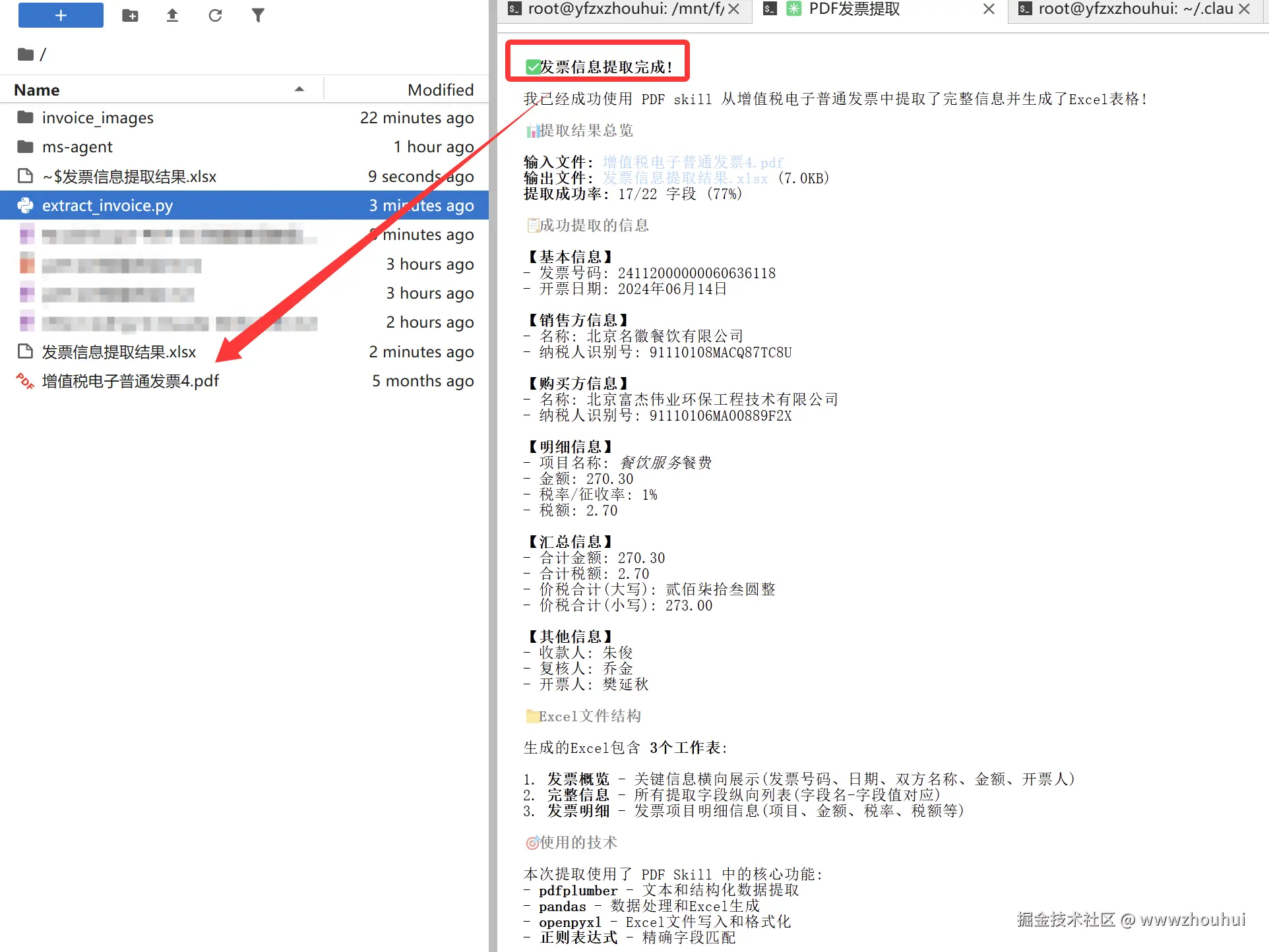
打开 Excel 文件,所有表格数据整整齐齐,再也不用手工复制粘贴了!
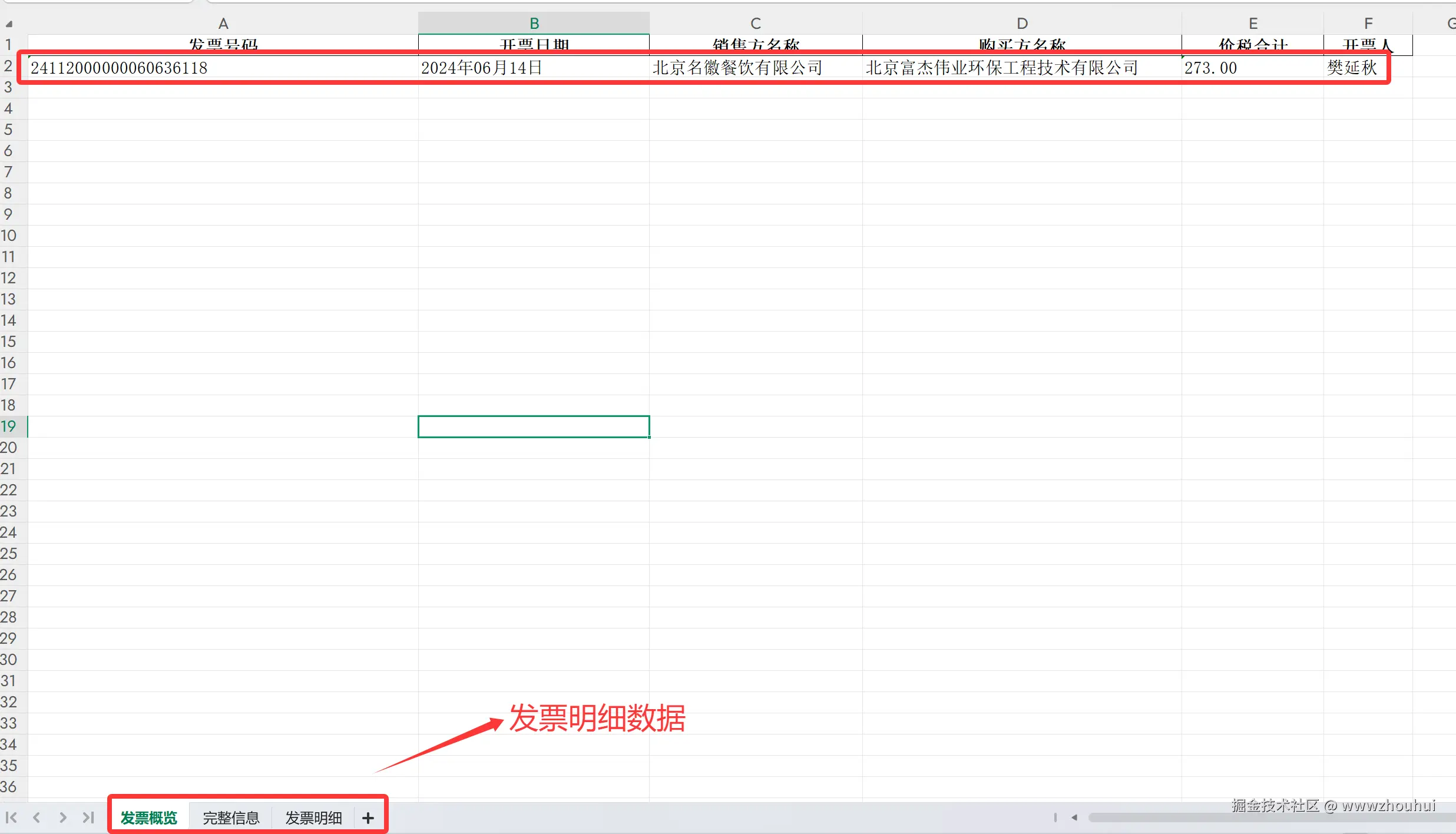
发票概览
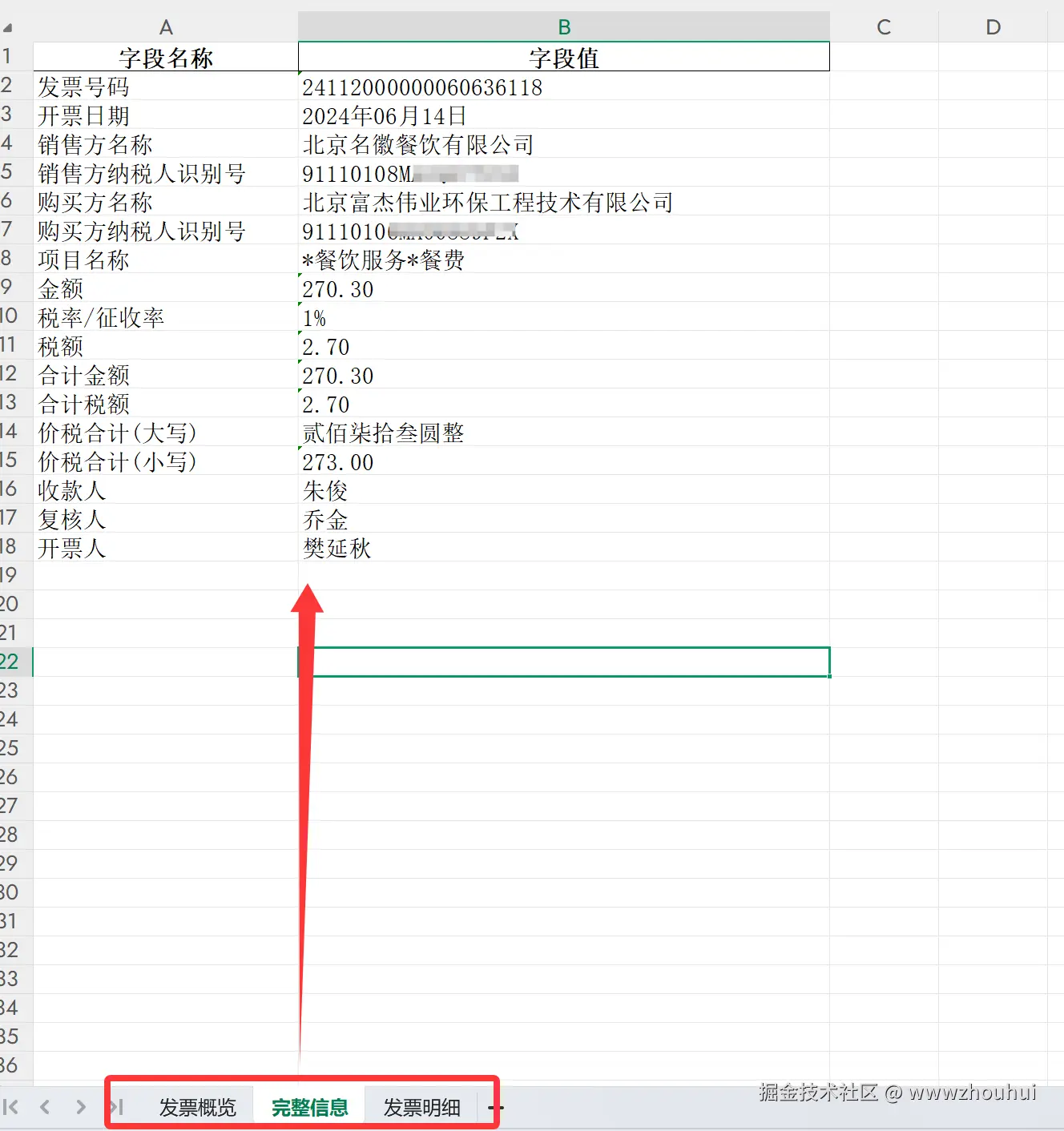
完整信息
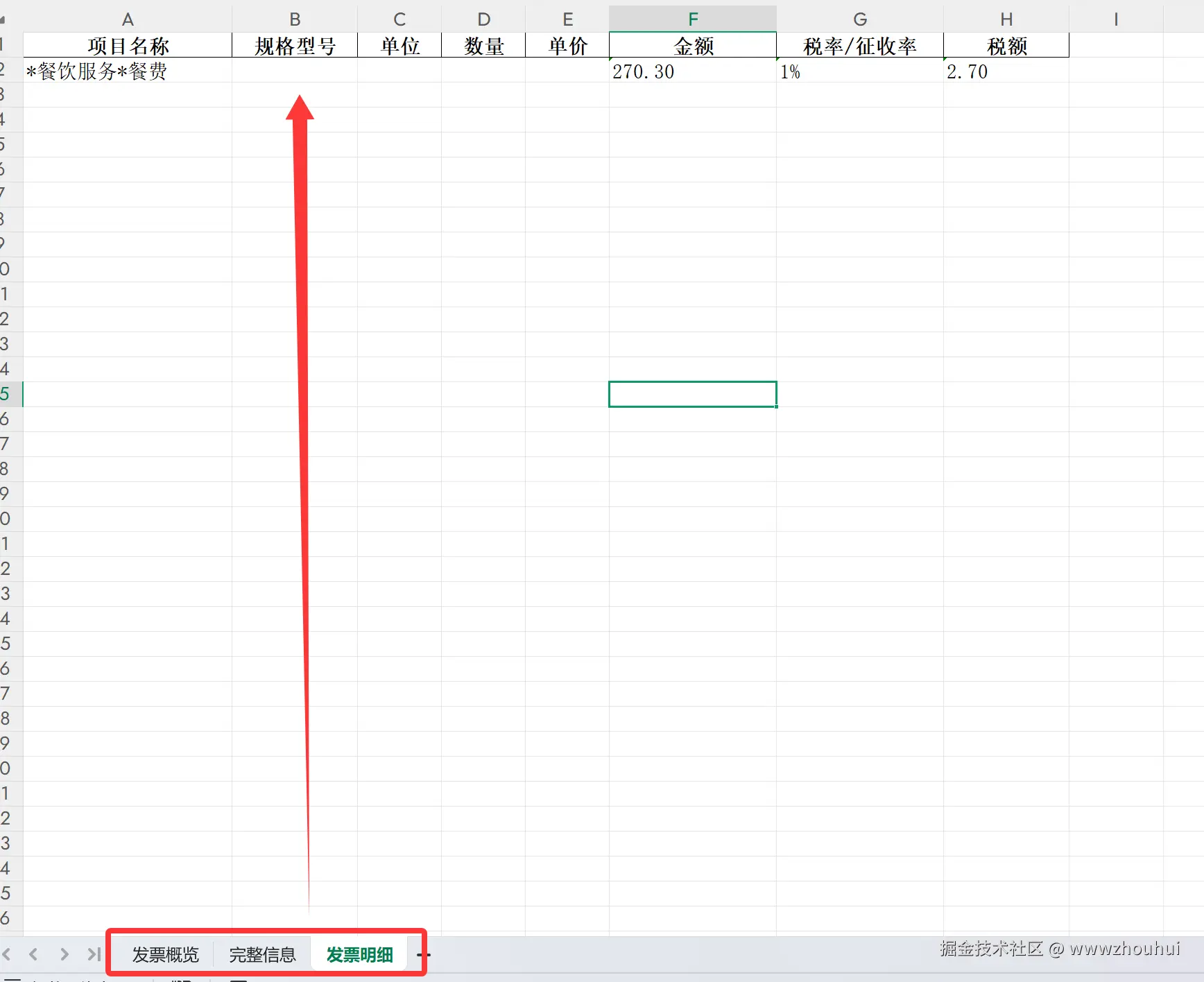
发票明细
实战案例4: 生成专业 PDF 报表
除了处理现有 PDF,PDF-Skill 还能创建专业的 PDF 报表。下面演示如何用 ReportLab 生成一份带表格的报告:
提示词如下:
请使用pdf 这个skill帮我把当前文件下"pdf-skill技能总结.md" 把这个md文档的内容总结生成一个需要给领导汇报的PDF报告,并输出这个报告。
总共帮我生成了5页
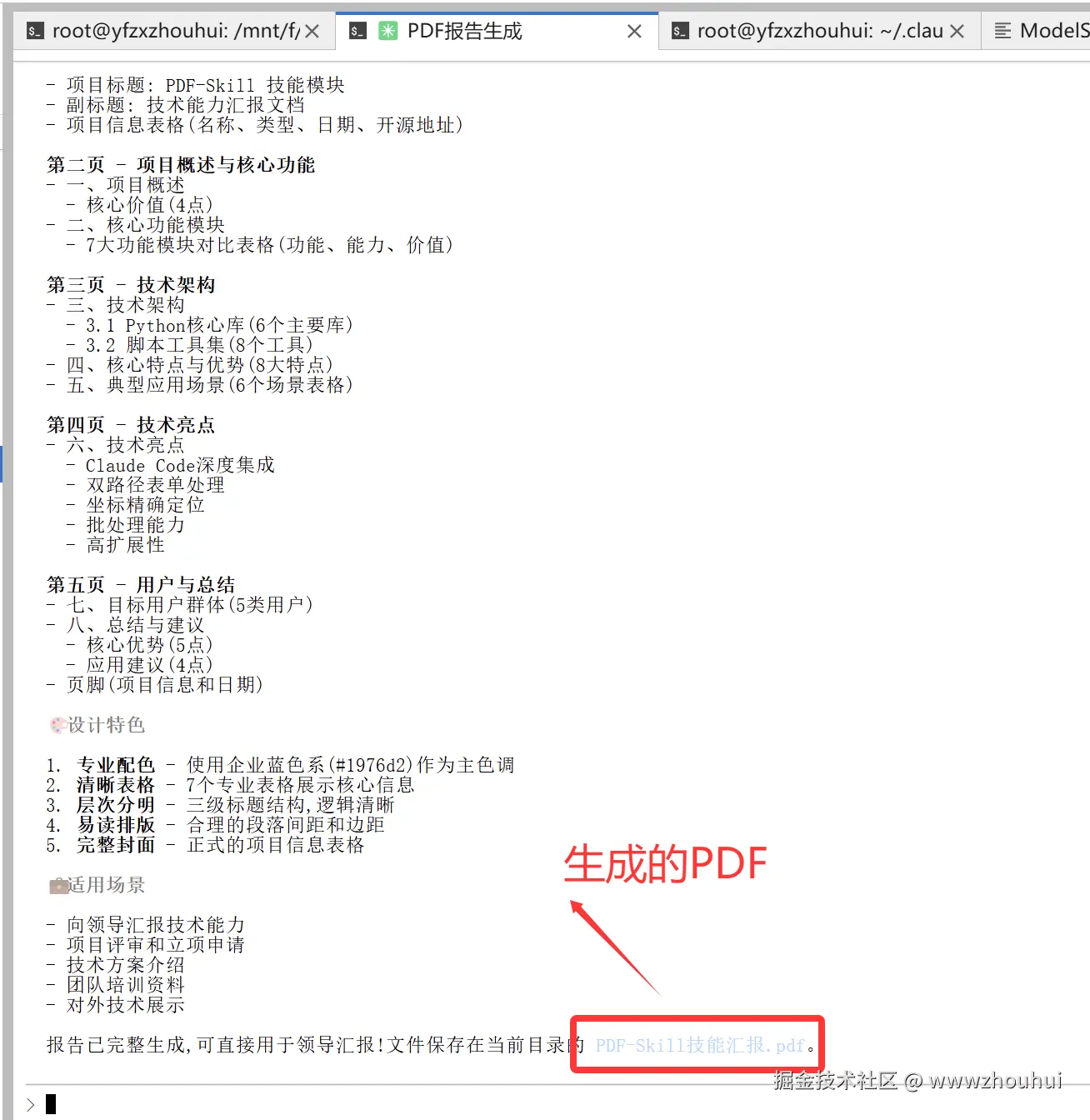
我们打开这个PDF 查看一下效果(报告有5页,这里只展开2张截图)
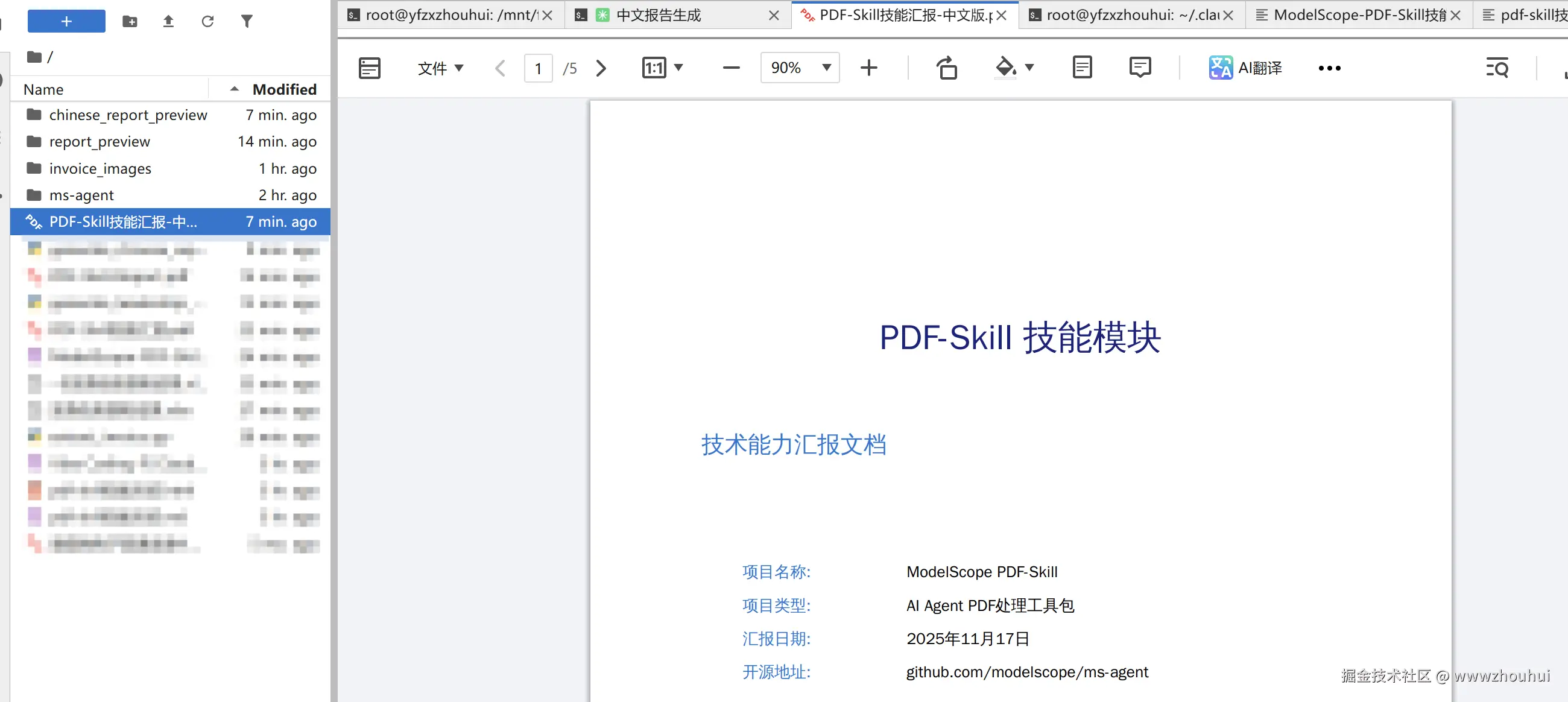
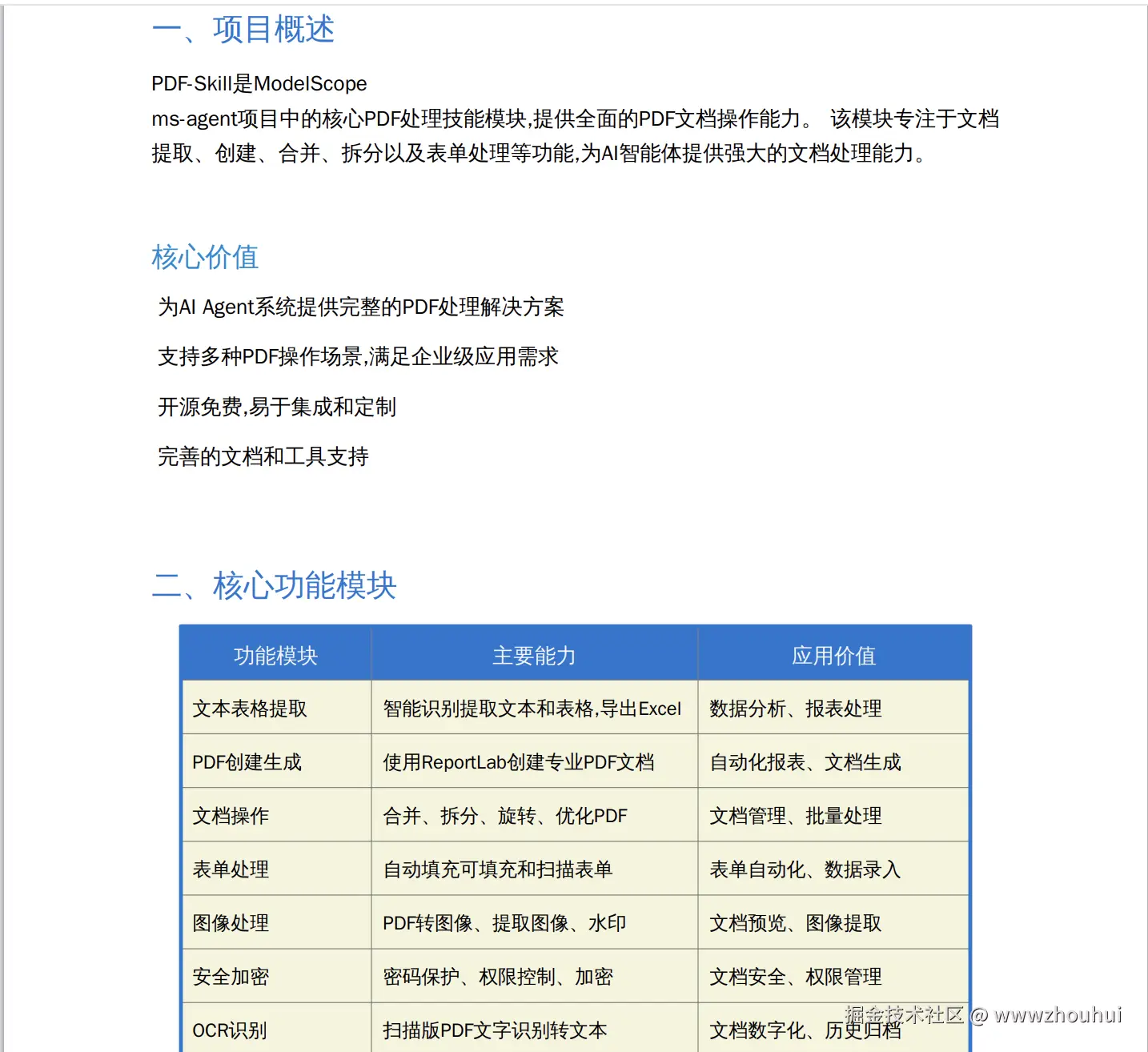
打开生成的 PDF,专业的表格样式、清晰的数据展示,完全可以直接拿去开会汇报
常见问题与解决方案
问题1: numpy 版本冲突
arduino
错误: module 'numpy' has no attribute 'float'解决方案:
shell
pip install numpy==1.26.4问题2: Tesseract 找不到
makefile
错误: TesseractNotFoundError解决方案:
python
# 在代码中指定 tesseract 路径
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'问题3: PDF 加密无法处理
makefile
错误: PdfReadError: file has not been decrypted解决方案:
python
import pypdf
reader = pypdf.PdfReader('encrypted.pdf')
reader.decrypt('your-password')问题4: 表格识别不准确
解决方案: 调整 pdfplumber 参数
python
import pdfplumber
with pdfplumber.open('document.pdf') as pdf:
page = pdf.pages[0]
# 自定义表格检测参数
table = page.extract_table({
'vertical_strategy': 'lines',
'horizontal_strategy': 'lines',
'snap_tolerance': 3,
'join_tolerance': 3,
'edge_min_length': 3,
})总结
通过本文的实战演示,我们完整体验了 ModelScope PDF-Skill 这个强大的 PDF 处理工具包。从环境搭建到实际应用,我们用四个典型场景展示了它的核心能力:
实战案例回顾:
-
PDF转图片 - 一行提示词就把发票PDF转成高清图片,如果有几百个PDF文件需要批量转换,只需稍微修改提示词,AI分分钟帮你搞定,省去了手工一个个转换的麻烦。
-
扫描版表单填充 - 基于Markdown格式的学生成绩数据,自动填充到扫描版成绩表PDF中,虽然因表格空间限制填充了48条数据(总共50条),但整体效果已经相当不错,这在传统方案中几乎不可能实现。
-
提取表格数据到Excel - 从增值税电子发票PDF中一键提取出发票概览、完整信息、发票明细三个工作表,所有数据整整齐齐,再也不用手工复制粘贴,大大提高了财务处理效率。
-
生成专业PDF报表 - 基于Markdown技能总结文档,自动生成了5页专业级的PDF报告,包含表格、统计数据、格式化排版,完全可以直接拿去给领导汇报。
核心优势总结:
PDF-Skill 最大的亮点在于与 Claude Code 的深度集成,让 AI 真正成为你的 PDF 处理助手。它整合了 pypdf、pdfplumber、reportlab 等多个成熟 Python 库,配合 poppler-utils、qpdf 等命令行工具,提供了文本提取、表单填充、文档创建、图像处理、安全加密的全套解决方案。"双路径表单处理"机制既支持可填充表单自动化,也能通过像素级坐标定位处理扫描版表单,配合可视化验证确保准确性。8个实用脚本涵盖从表单检查、字段提取、自动填充到边界框验证、PDF转图像的完整工具链,模块化设计让每个功能都清晰独立、易于维护扩展。
扩展应用场景:
基于本文演示的基础功能,小伙伴们可以继续探索更多应用场景:批量处理企业合同、自动化发票识别录入、历史文档数字化归档、电子签章批量添加、PDF水印处理、多语言OCR识别等。这些场景在企业办公自动化、政务文档数字化、金融票据处理等领域都有广泛应用价值。PDF-Skill 提供的流式处理和并行批处理能力,能够高效处理大规模文档,远超传统单一功能的 PDF 库。
感兴趣的小伙伴可以按照文中步骤进行实践,根据实际业务需求调整参数配置。PDF-Skill 是完全开源免费的,无需购买昂贵商业软件,就能实现企业级 PDF 处理自动化。今天的分享就到这里,希望这个工具能帮大家解决 PDF 处理的各种难题,我们下一篇文章见!
项目资源
GitHub地址 : github.com/modelscope/...
觉得项目不错可以点个赞。
官方文档:
- SKILL.md: 核心库和命令行工具说明
- forms.md: 表单处理详细工作流
- reference.md: 高级功能和故障排除
技术交流:
- ModelScope 社区: modelscope.cn
- Issue 反馈: github.com/modelscope/...
相关资源:
- pypdf 文档: pypdf.readthedocs.io
- pdfplumber 文档: github.com/jsvine/pdfp...
- reportlab 文档: www.reportlab.com/docs/
#首发于魔搭研习社