在电商大厂的技术面试中,面试官常常会问到一些关于系统架构、性能优化、分布式设计以及常见的并发问题。下面我们通过一些常见的问题和解答,来帮助你更好地准备面试。
1. 项目中要进行分布式扩展应该怎么做? 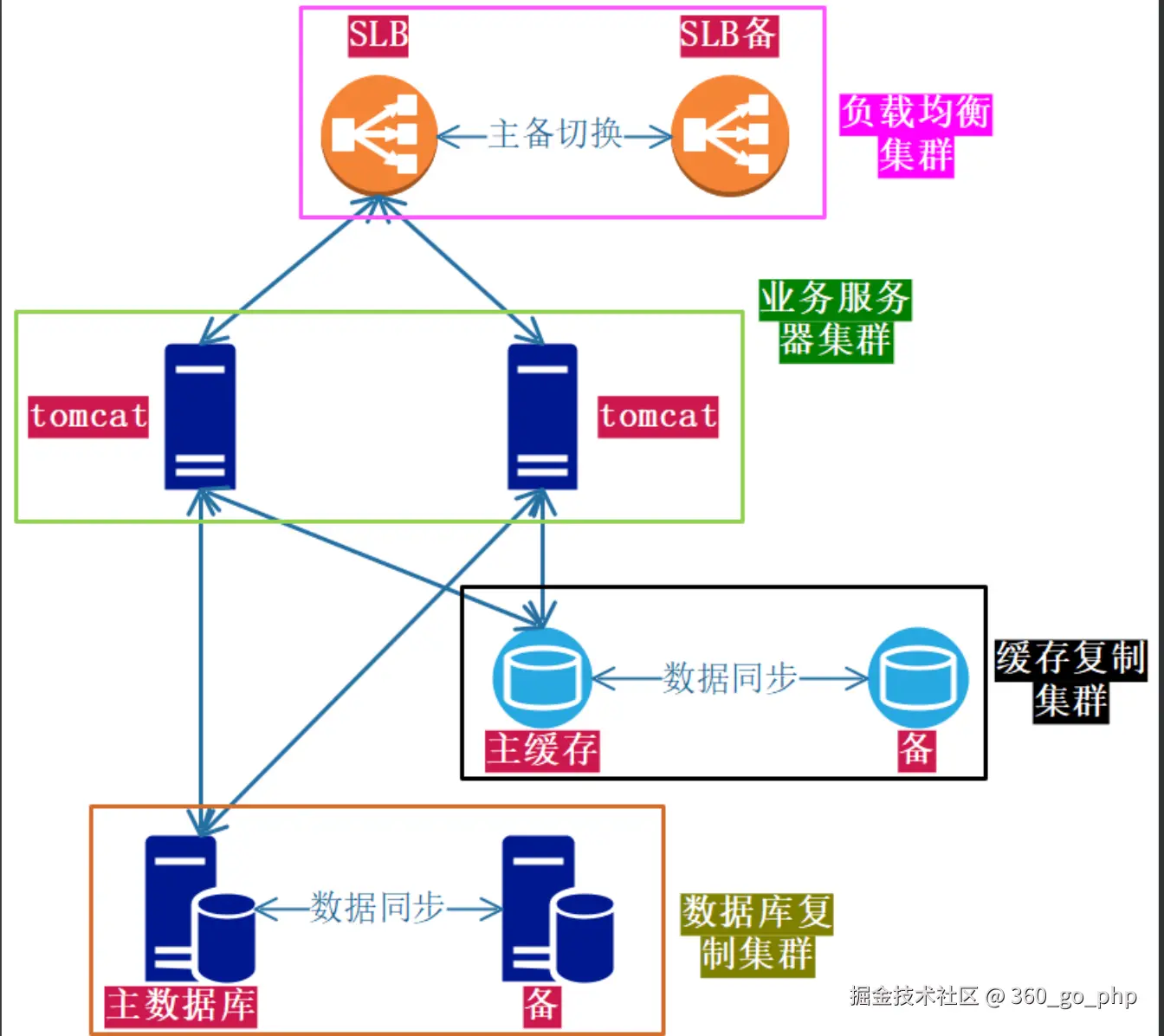 编辑
编辑
分布式扩展的目标是确保系统能够应对更高的并发和流量压力,保持高可用性和可扩展性。要实现分布式扩展,可以采取以下几种方法: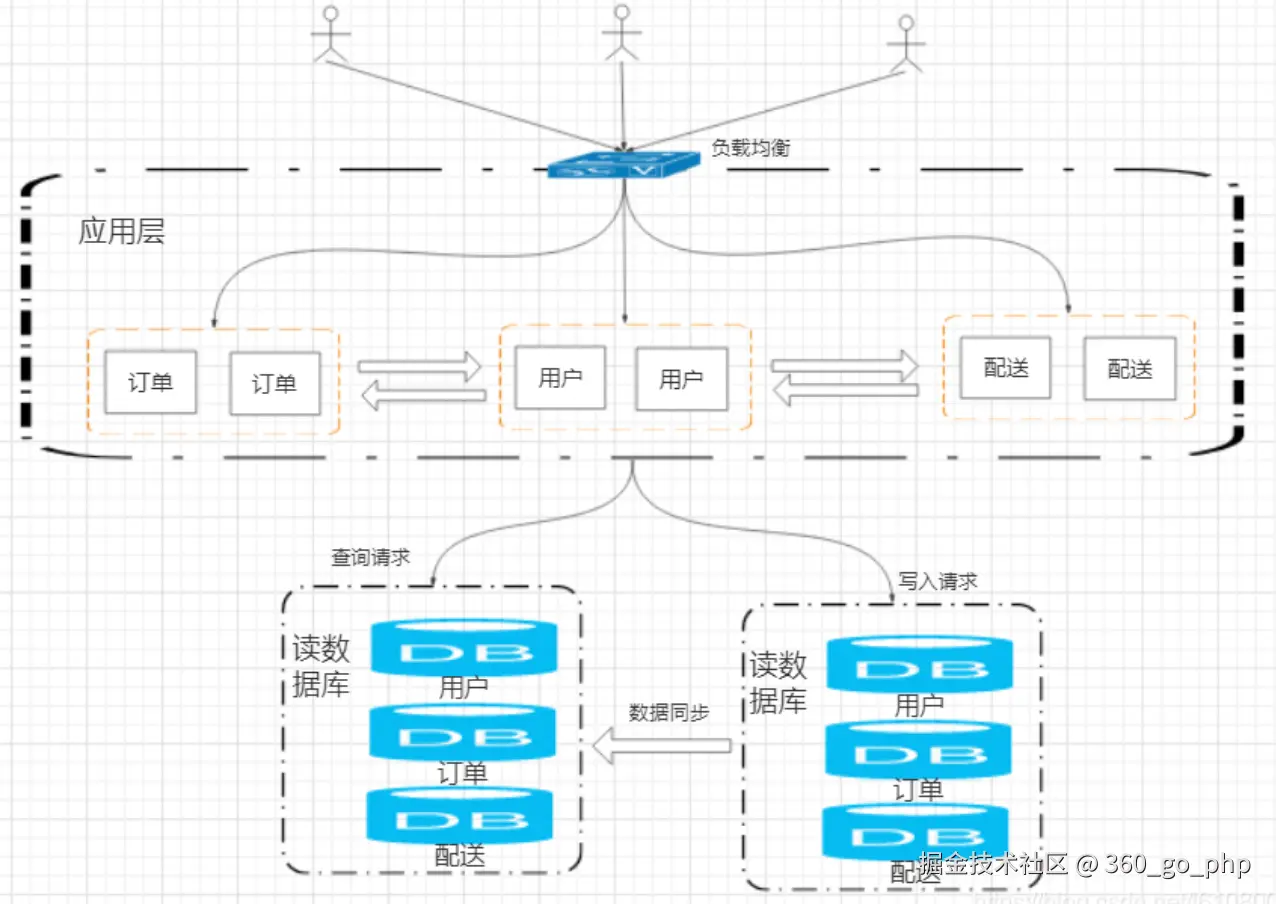 编辑
编辑
-
水平扩展(Scale Out) :增加更多的服务器或节点,分摊负载。常见的做法包括使用负载均衡器(如Nginx、LVS等)将请求分发到多个应用服务器。
 编辑
编辑 -
分库分表:将数据库拆分为多个实例,避免单一数据库成为瓶颈。分表可以通过按业务功能或按数据量来划分。
-
使用分布式缓存:例如使用Redis、Memcached等来减轻数据库的压力,将热点数据缓存到内存中。
-
消息队列:采用如Kafka、RabbitMQ等分布式消息队列来解耦系统各个部分,使得高并发的请求能够被异步处理。
-
微服务架构:将系统拆分成多个微服务,每个微服务都可以独立扩展,支持按需进行水平扩展。
2. 缓存和 MySQL 数据一致性如何保证? 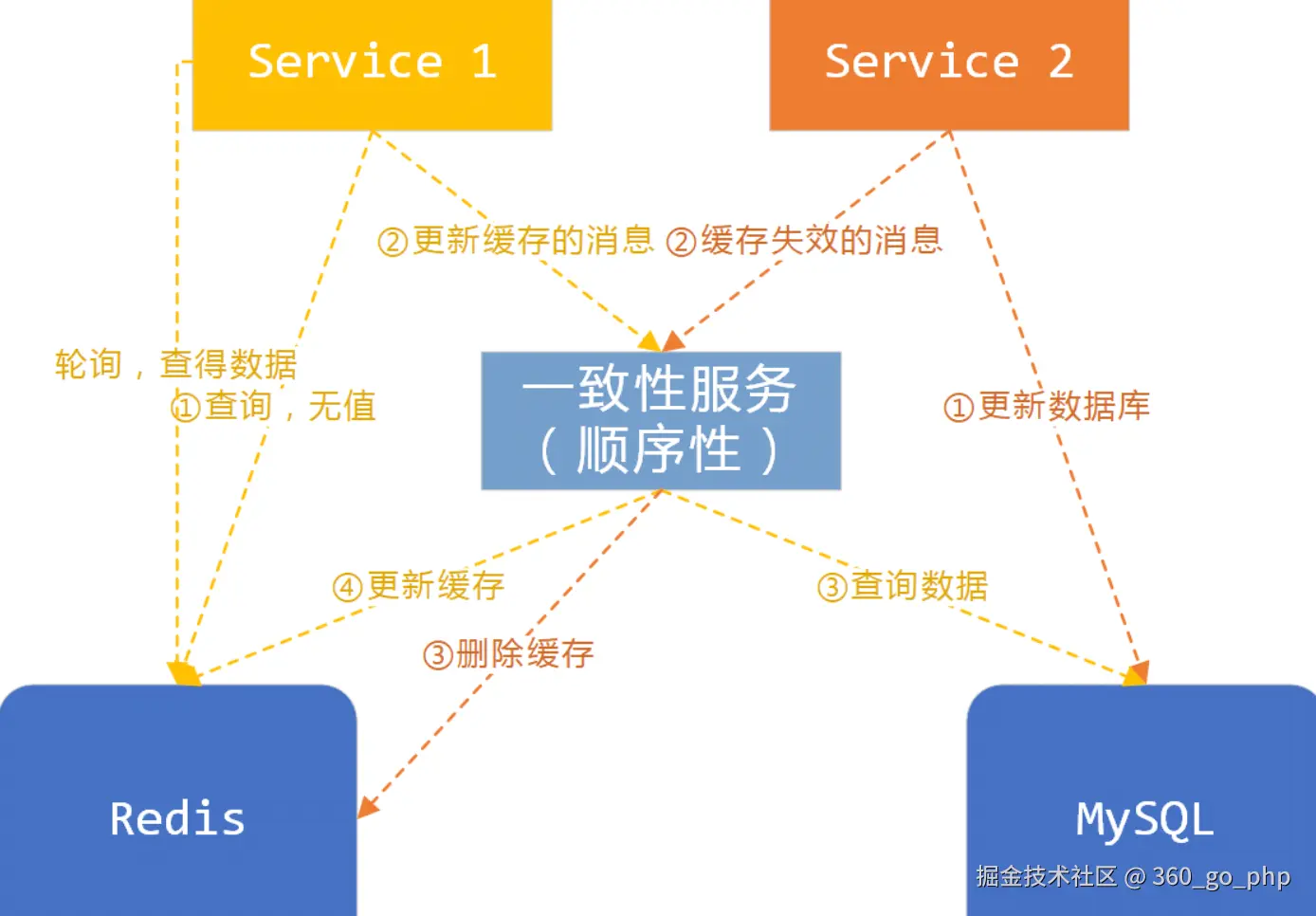 编辑
编辑
缓存和 MySQL 数据一致性是分布式系统中常见的挑战,以下是几种常见的解决方案: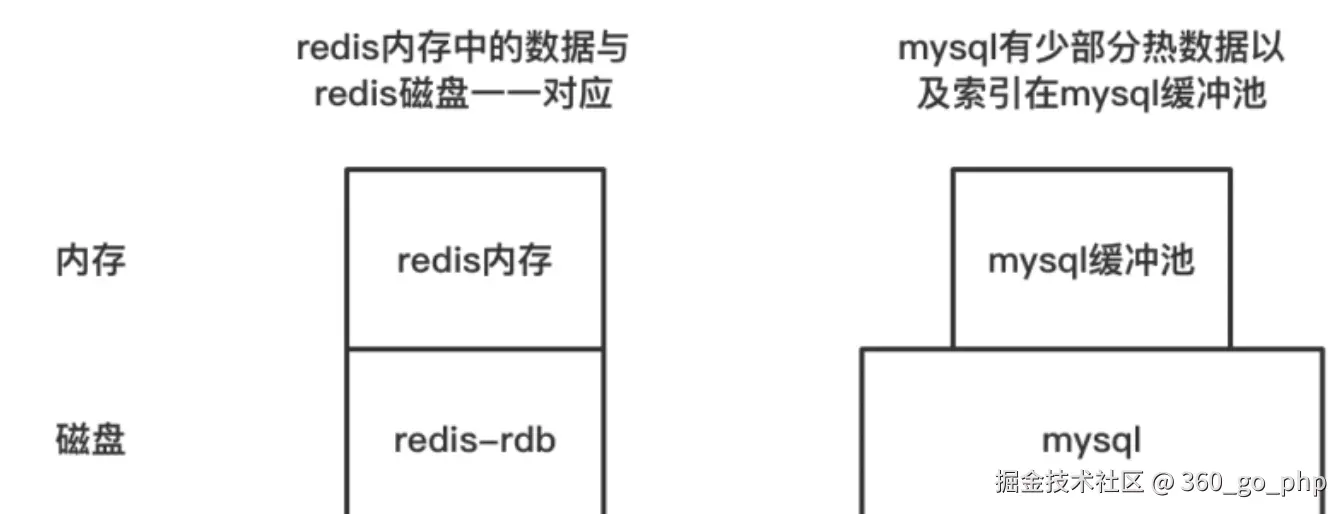 编辑
编辑
-
缓存失效策略 :在更新数据库时,及时清除缓存或更新缓存。可以使用
cache-aside模式,只有在需要时才从数据库加载数据,并缓存结果。 编辑
编辑 -
双写一致性 :当数据既写入数据库,又写入缓存时,需要保证写入顺序,通常可以采用事务性机制保证一致性,或者通过异步机制在数据库更新后再更新缓存。
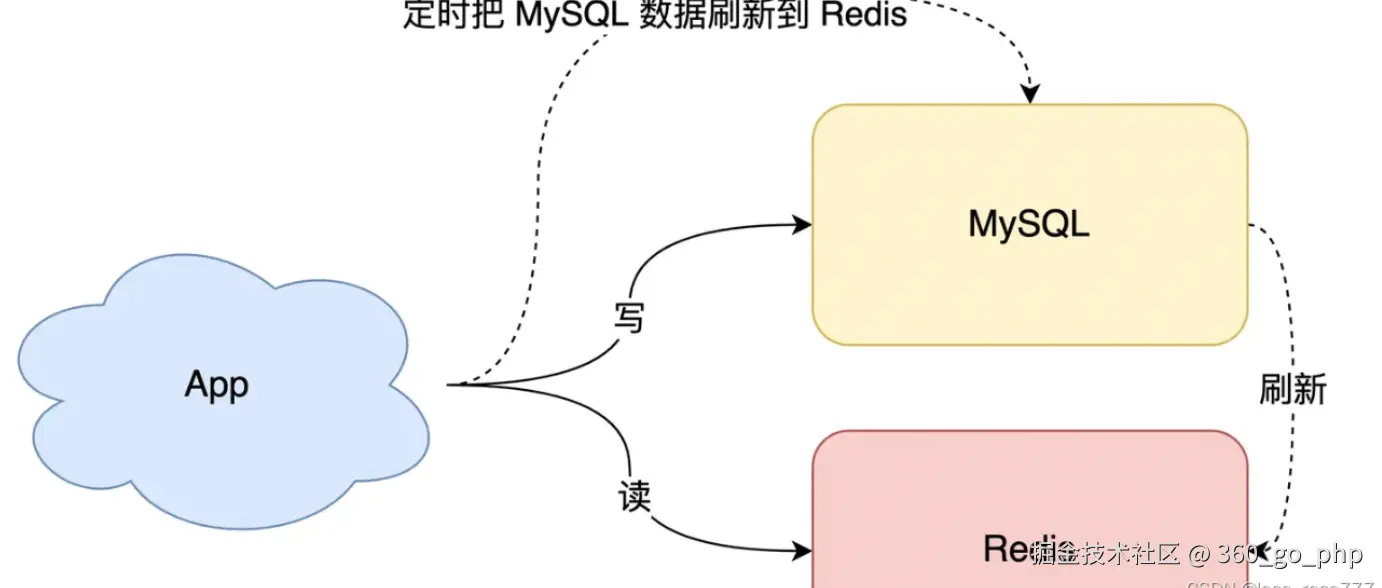 编辑
编辑 -
TTL(过期时间)策略 :设置缓存的过期时间,定期刷新缓存内容。虽然这种方法不能实时保证一致性,但可以减小缓存失效对一致性的影响。
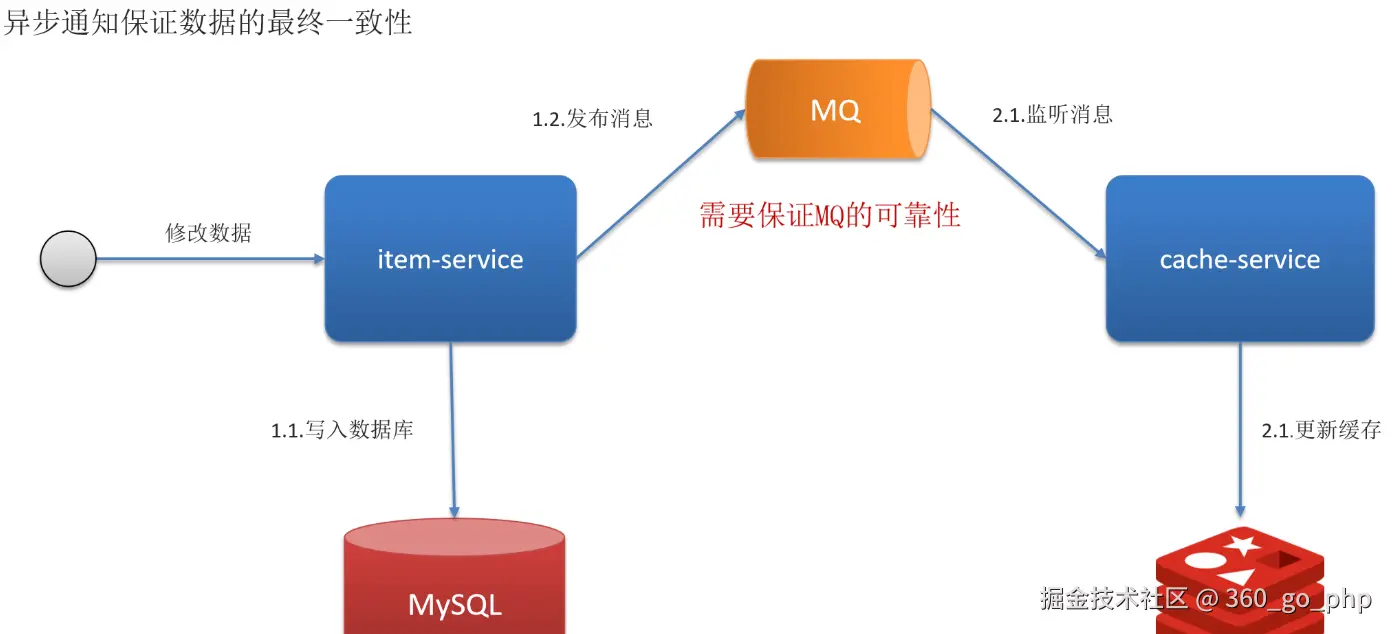 编辑
编辑 -
分布式锁 :可以使用分布式锁来确保多个服务或线程在同一时间内只会有一个去更新缓存和数据库,防止并发导致的数据不一致。
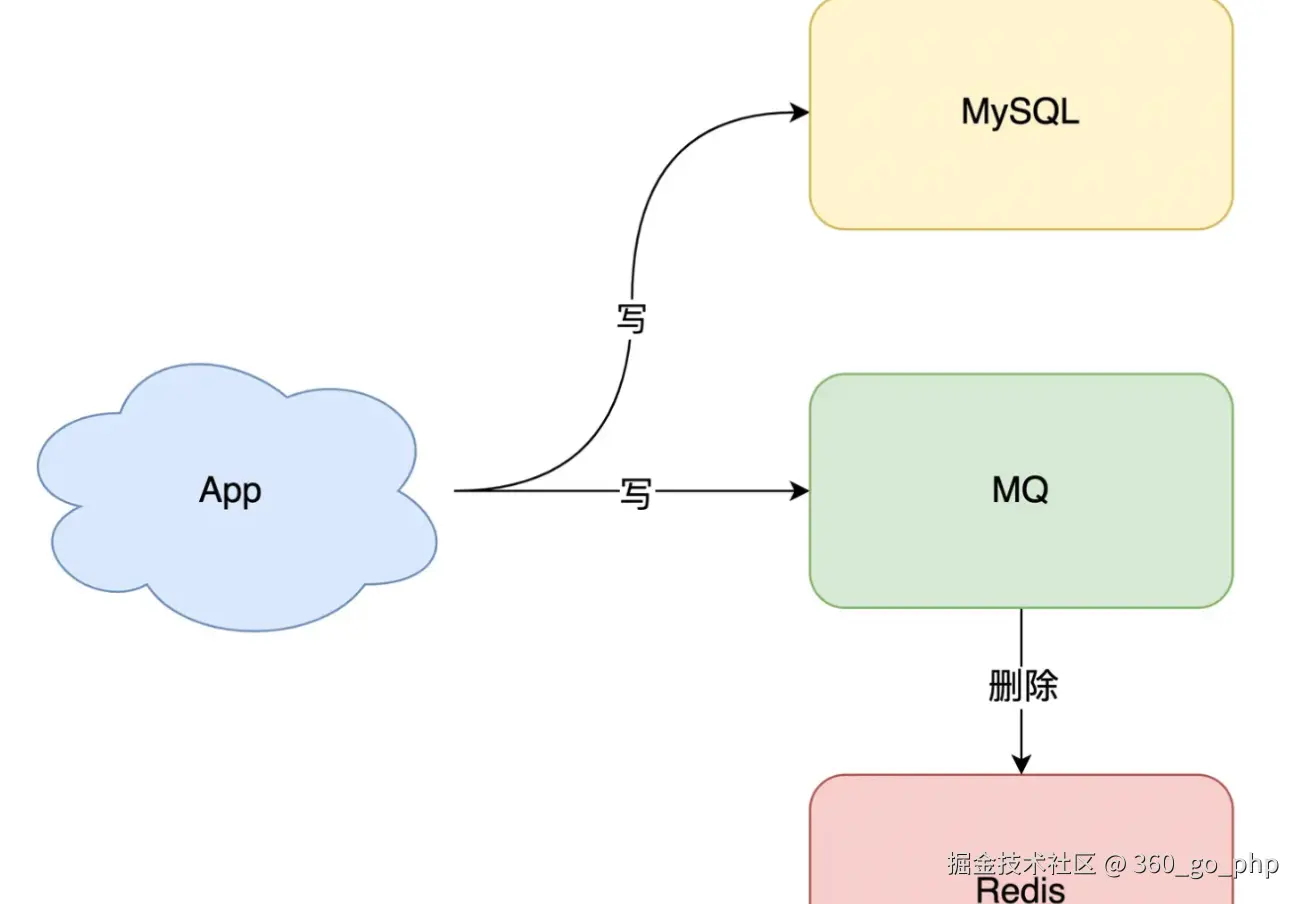 编辑
编辑 -
事件驱动和消息队列:通过事件驱动机制(例如使用Kafka、RabbitMQ等)来通知缓存更新,确保缓存与数据库的一致性。
3. 微信步数排行,假设百万级用户,怎么排序,实时更新?
对于百万级用户的步数排行,实时排序和更新是一个非常具有挑战性的任务。可以采取以下方法来优化:
-
分组排序:将用户分为多个组,每组内进行排序。可以根据步数的范围来划分,例如步数较少的用户分为一组,步数较多的用户分为另一组。这样可以避免大范围排序的性能瓶颈。
-
分度值不均匀:根据步数的分布特征,分组的大小可以是动态的。例如,步数为0到2000的用户可能是一个小组,步数为2000到4000的用户可以拆分为五个小组,步数较多的用户则可以分为更少的组。
-
实时更新:在每个组内保持一个排名,通过增量更新(比如用户步数增加时,仅更新该用户所在组的排名)来减少每次计算的负担。组内排序更新可以使用高效的数据结构,如堆、平衡二叉树等。
-
异步计算:使用后台任务处理步数变化时的排序更新,避免实时计算带来的延迟。可以通过异步队列来定期或按需计算和更新排行榜。
4. 发生了 OOM,应该怎么去分析解决?JVM 调优
OOM(OutOfMemoryError)通常是由于内存不足引起的。分析和解决OOM问题的步骤包括:
-
分析堆内存使用情况:通过分析JVM的堆转储(heap dump)文件,找出内存泄漏或者内存分配不合理的地方。
-
JVM垃圾回收日志:通过分析GC日志,观察垃圾回收的情况。频繁的Full GC可能是内存问题的症状,可以根据日志来调整堆内存大小或垃圾回收策略。
-
调整JVM内存参数 :增加堆内存的大小(
-Xmx和-Xms参数),或者调整年轻代、老年代的比例,优化内存的分配和回收策略。 -
内存泄漏检测:使用工具(如VisualVM、YourKit)来分析代码中是否存在内存泄漏,比如对象未被正确释放,导致堆内存逐渐增长。
-
优化代码:检查代码中是否存在内存泄漏,避免大量对象的创建,及时释放不再使用的对象。
5. 什么时候发生线程的上下文切换?
线程的上下文切换是在多线程环境中,操作系统为了实现并发执行而在不同的线程之间切换执行的过程。上下文切换发生的原因有:
-
时间片用完:每个线程会分配一个时间片,时间片用完后,操作系统会进行上下文切换,切换到下一个线程。
-
线程阻塞/等待 :当线程调用
wait()、sleep()、join()等方法进入阻塞或等待状态时,操作系统会选择其他线程运行。 -
线程的优先级变化:如果线程的优先级发生变化,操作系统可能会进行上下文切换,选择优先级更高的线程执行。
-
I/O操作:当线程进行I/O操作(如读写文件、数据库查询等)时,通常会被挂起,操作系统会切换到其他可运行的线程。
6. CAS是硬件实现还是软件实现?
CAS(Compare and Swap,比较并交换)是由硬件实现的原子操作。它通过硬件指令(如x86的CMPXCHG指令)来保证操作的原子性,避免了多线程情况下的竞态条件。在Java中,CAS是通过Unsafe类中的方法来实现的,它利用了底层硬件提供的原子操作。
7. 除了 wait 和 notifyAll,还有什么办法实现类似的功能?
除了wait()和notifyAll(),还可以使用以下方法实现线程的协调和通信:
-
CountDownLatch :
CountDownLatch用于等待一组线程完成任务。例如,等待所有线程执行完毕后再继续执行。 -
CyclicBarrier :
CyclicBarrier用于让一组线程在某个屏障点同步。当线程到达屏障时会被阻塞,直到所有线程都到达该点。 -
Semaphore :
Semaphore控制线程对共享资源的访问。可以指定最多允许多少线程同时访问某个资源。 -
Exchanger :
Exchanger允许两个线程交换数据,它提供了一个双向的同步机制。
8. 微信抢红包设计(只讲了类似多线程抢、Semaphore,缓存)
微信抢红包的设计主要依赖于并发控制和高效的缓存策略。常见的设计步骤如下:
-
并发控制 :可以使用
Semaphore来控制每个用户抢红包的并发数。确保不会有过多的线程同时抢一个红包,避免系统崩溃。 -
缓存:红包的剩余金额和状态可以存储在Redis等缓存中,以提高访问速度和减少对数据库的压力。
-
抢红包算法:通过算法来确保红包金额的随机性,并且每个用户抢到的红包金额符合预定的总金额。
9. 海量文件找重复次数最多的个数(分治)
对于海量文件中的重复数据,分治算法是一种有效的解决方式。可以通过以下步骤实现:
-
分割文件:将大文件拆分为多个小块,分别进行处理。
-
排序和归并:每个小块内进行排序和计数,找出重复次数最多的元素。然后,使用归并算法将这些局部结果合并,得到全局的重复元素。
-
分治优化:根据内存和处理能力,可以调整每次拆分的粒度,逐步缩小文件的范围,直到找到重复次数最多的元素。
总结
电商大厂的技术面试通常考察候选人的系统设计、性能优化、并发控制等方面的能力。通过对分布式扩展、数据一致性、缓存优化、并发控制等问题的深入理解和实际