文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F048
视频
待发布
1 系统简介
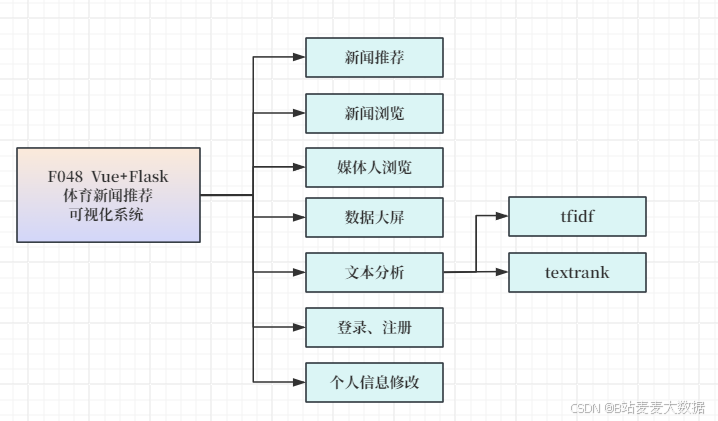
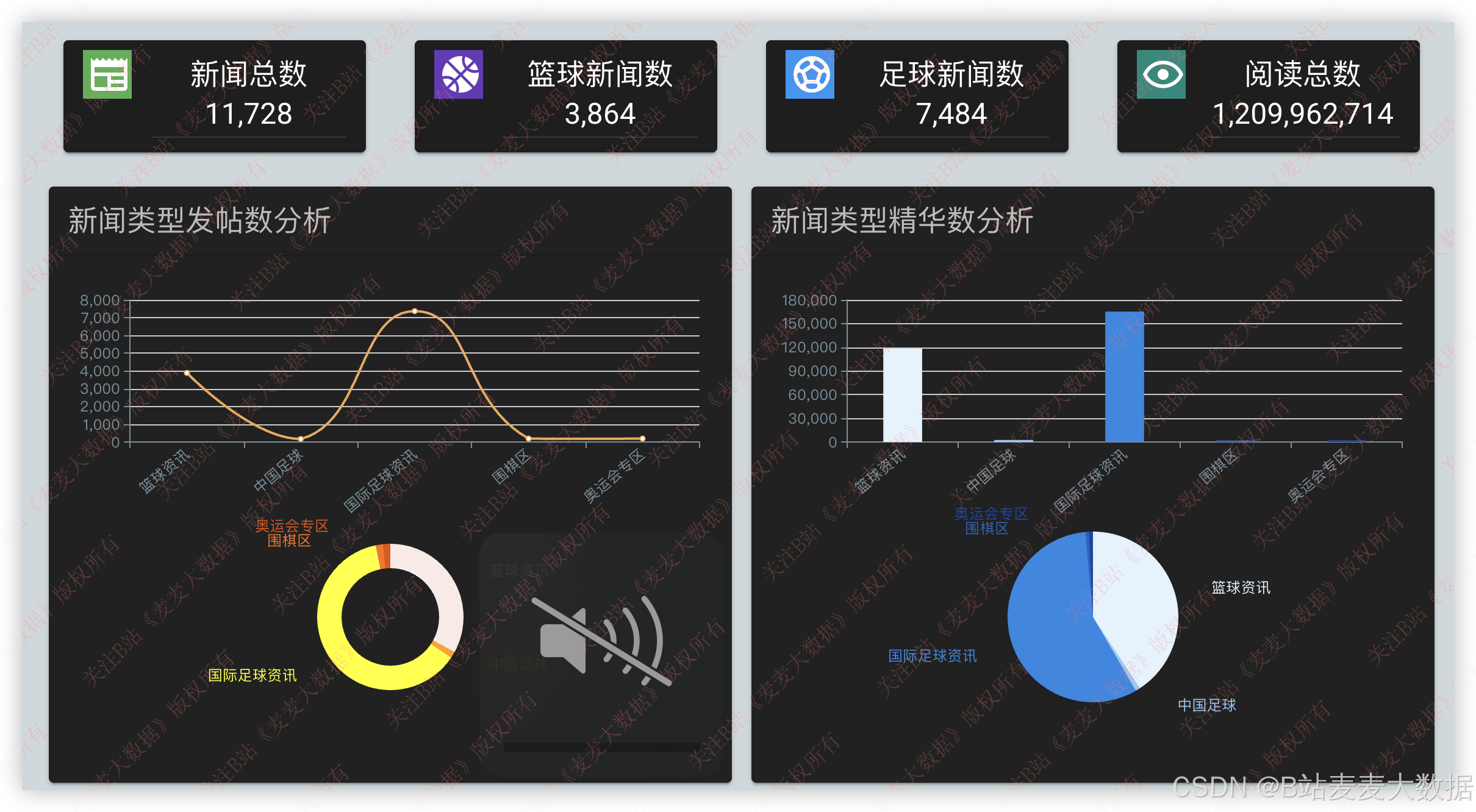
系统简介:本系统是一个基于Vue+Flask构建的体育新闻推荐系统,其核心功能围绕体育新闻的展示、推荐、媒体信息管理和用户交互展开。主要包括:用户管理模块,提供登录、注册、修改个人信息及密码功能,确保系统的安全性和个性化体验;体育新闻推荐模块,根据用户需求推荐相关体育新闻,并提供新闻卡片查看功能;媒体人信息模块,支持对各类体育媒体人的信息搜索和查询;数据可视化分析模块,通过动态柱状图、环图、饼图、折线图等形式展示新闻总数、发帖数、类型分析、精华媒体分析及查看量分析;文本算法分析模块,利用textrank、TF-IDF等算法对新闻内容进行关键主题提取和关键词分析,为用户提供深度的新闻洞察。
2 功能设计
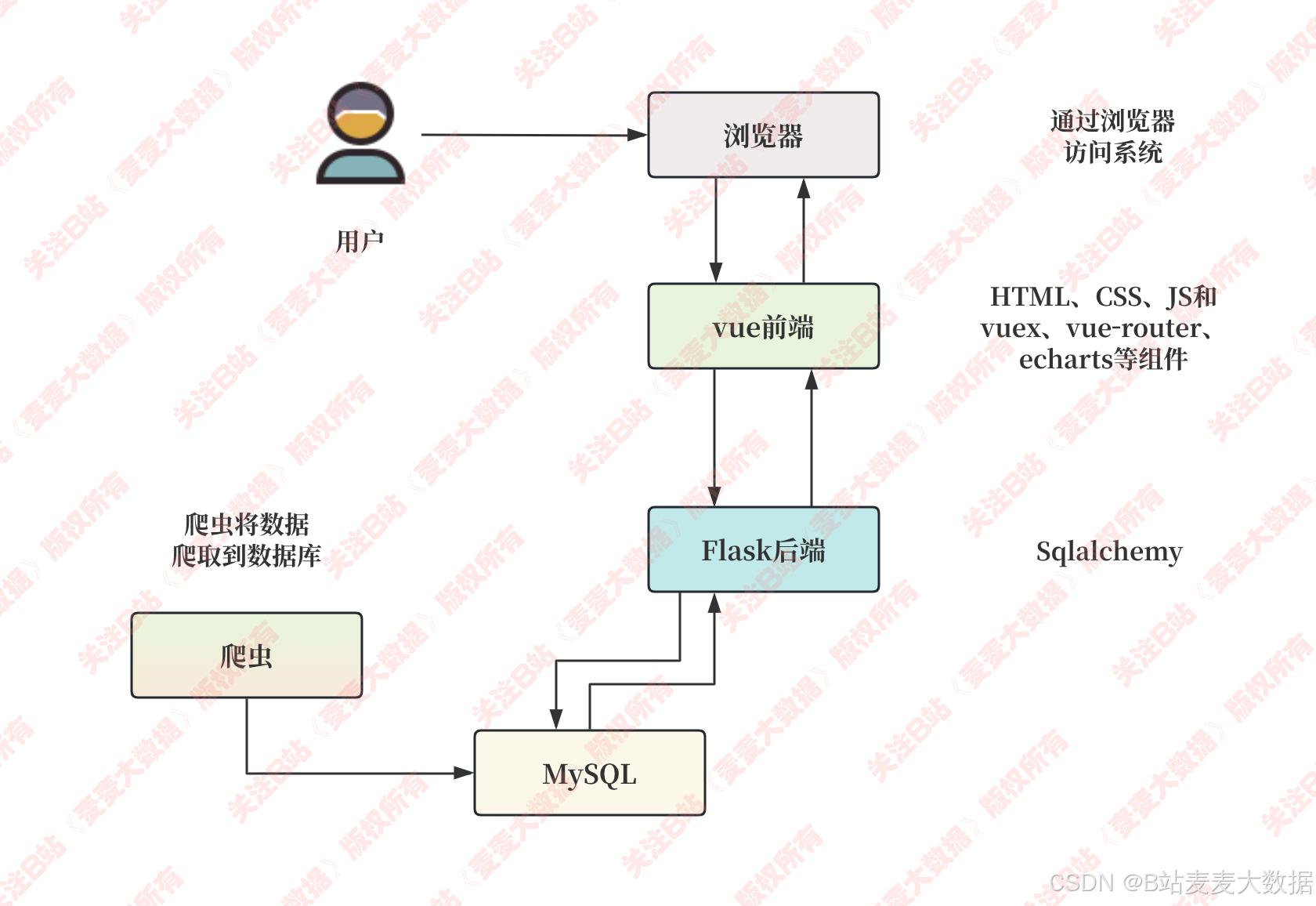
该系统采用典型的B/S(浏览器/服务器)架构模式。用户通过浏览器访问Vue前端界面,该前端由HTML、CSS、JavaScript以及Vue.js生态系统中的Vuex(用于状态管理)、Vue Router(用于路由导航)和Echarts(用于数据可视化)等组件构建。前端通过API请求与Flask后端进行数据交互,Flask后端则负责业务逻辑处理,并利用SQLAlchemy(或类似ORM工具)与MySQL数据库进行持久化数据存储。系统还集成了自然语言处理技术,通过textrank和TF-IDF算法实现新闻内容的关键主题提取和关键词分析。同时,系统包含一个独立的爬虫模块,负责从外部来源抓取体育新闻数据,并将其导入MySQL数据库,为整个系统提供数据支撑。
2.1系统架构图
2.2 功能模块图
3 功能展示
3.1 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换,背景是一个视频,循环播放。
登录需要验证用户名和密码是否正确,如果不正确会有错误提示 。

注册需要验证用户名是否存在 ,如果错误会有提示。

3.2 主页 & 新闻推荐
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。

主页可以搜索体育新闻,也可以进行新闻推荐。
3.3 新闻详情

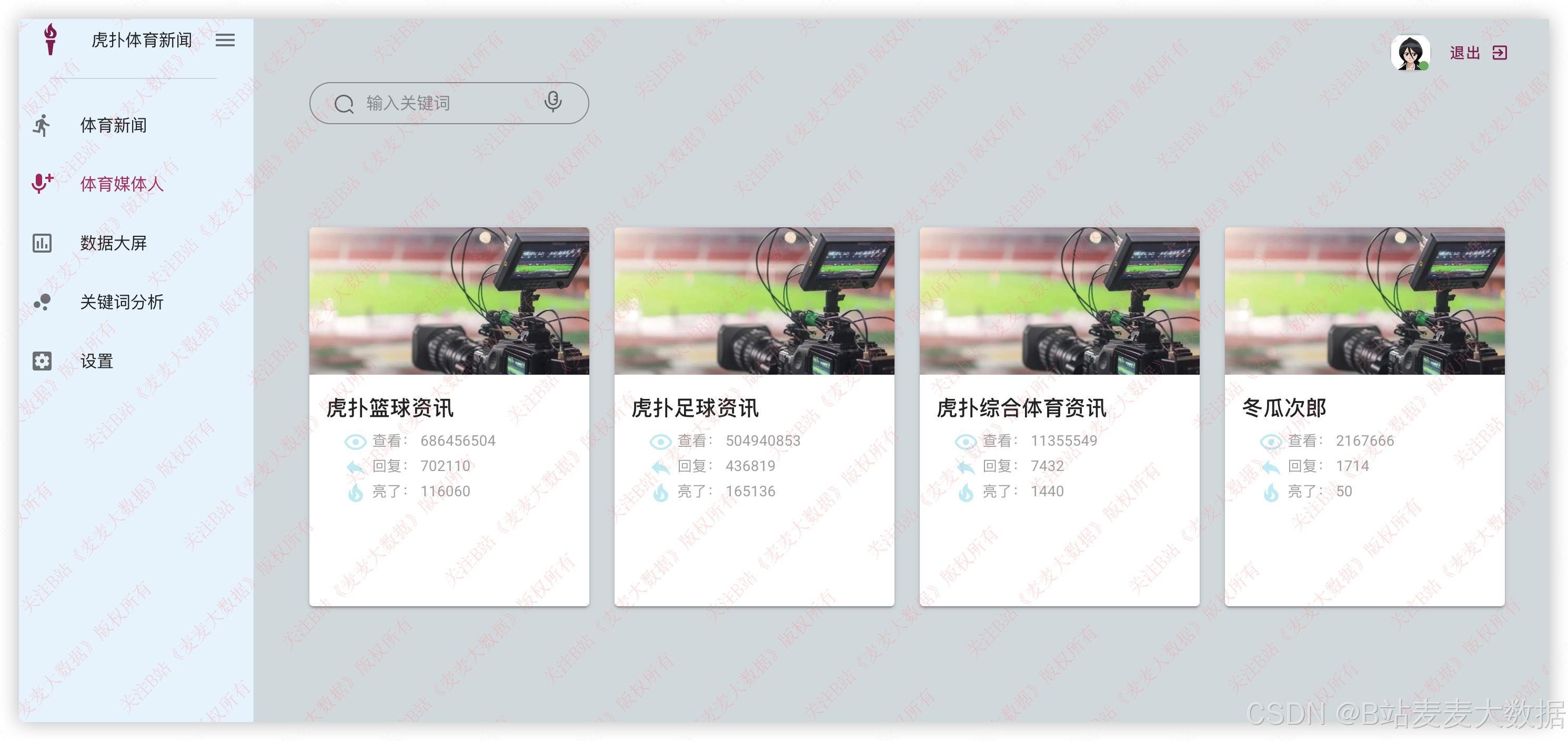
3.4 媒体人搜索
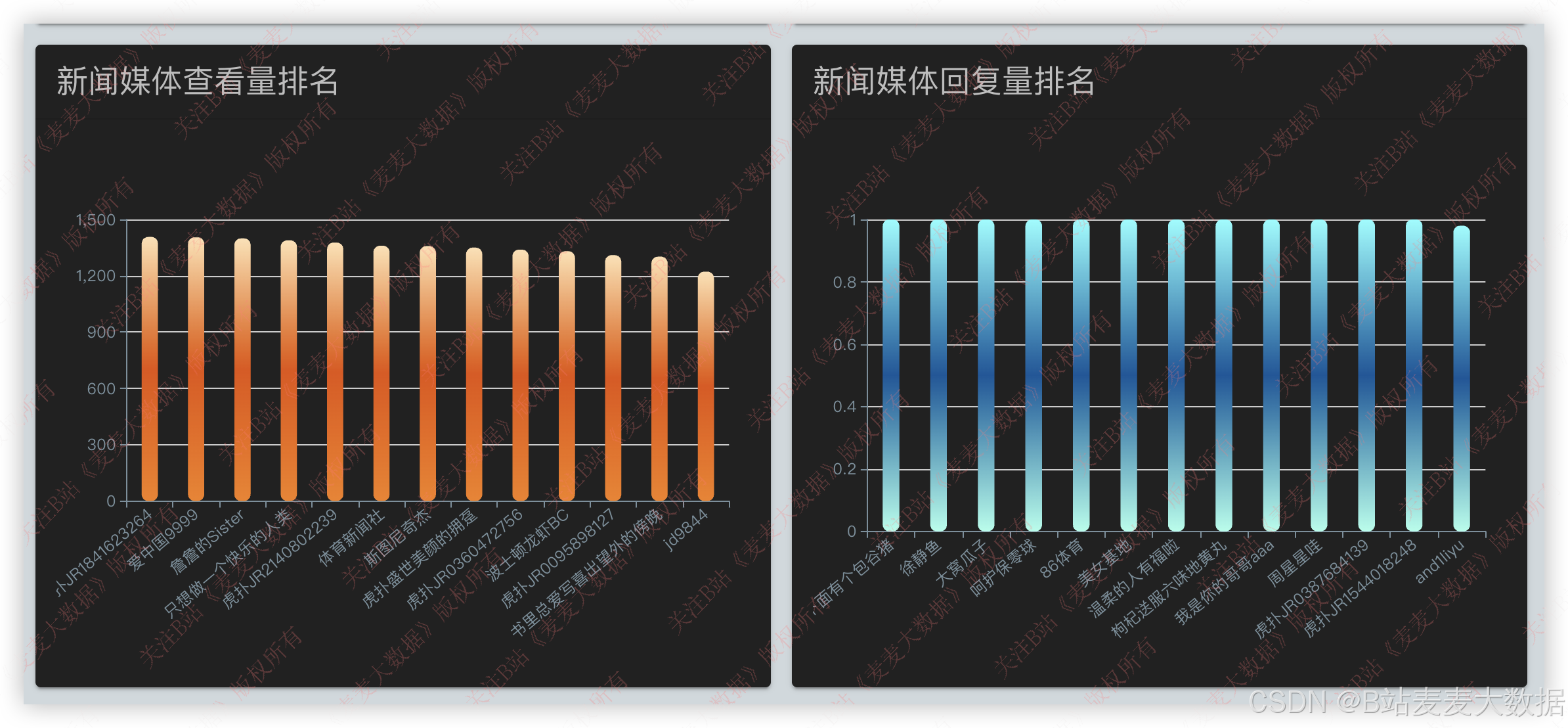
3.5 数据可视化分析
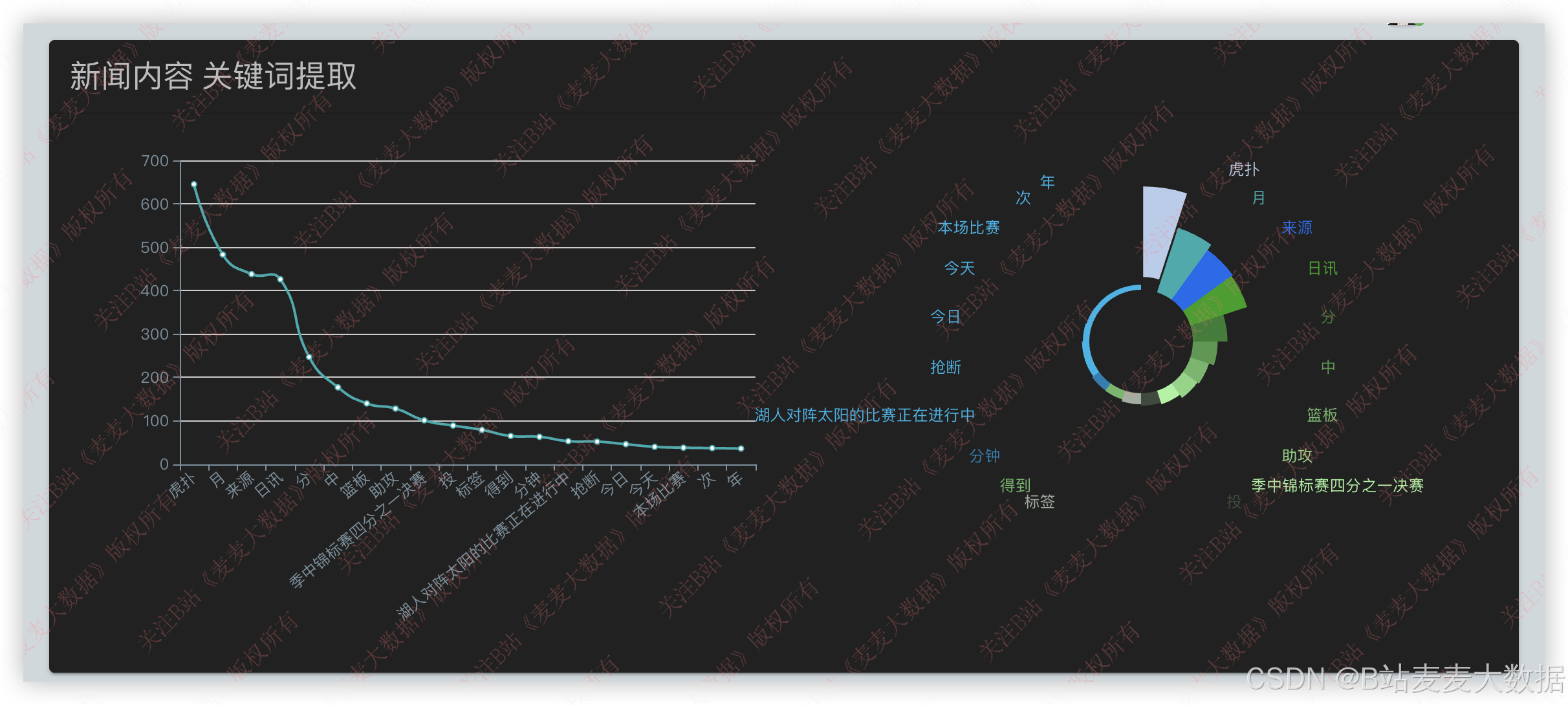
3.6 文本分析
textrank 和 tfidf 算法
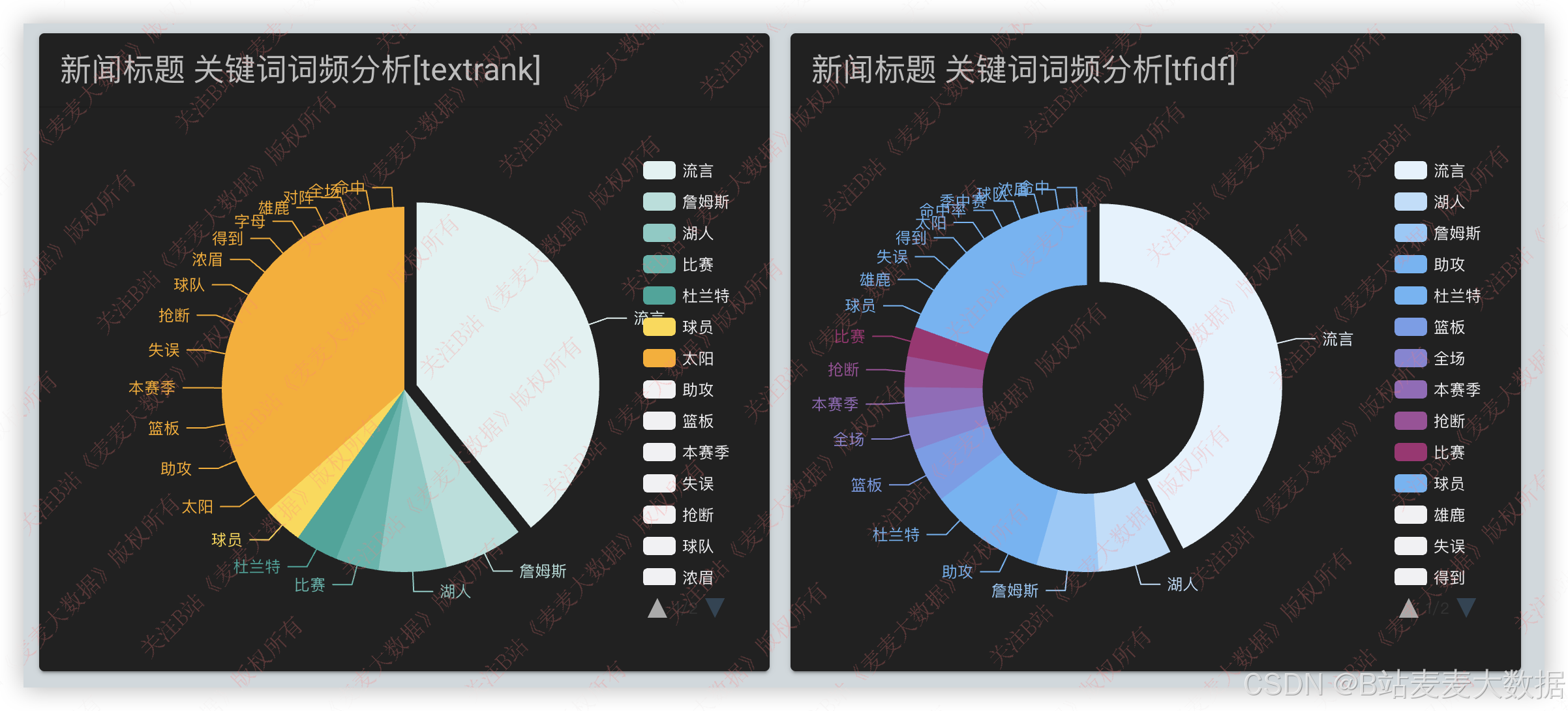
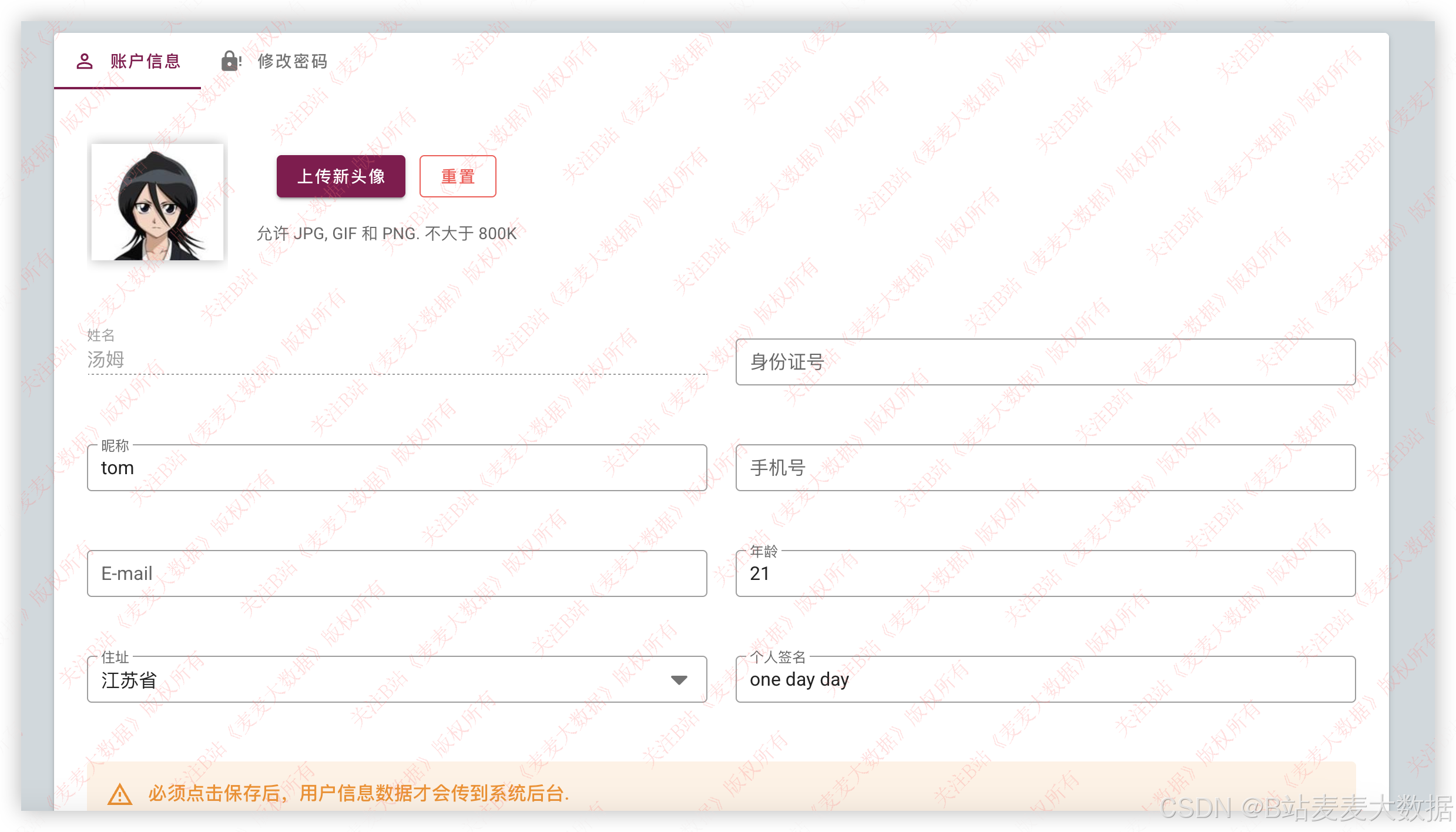
3.7 个人设置
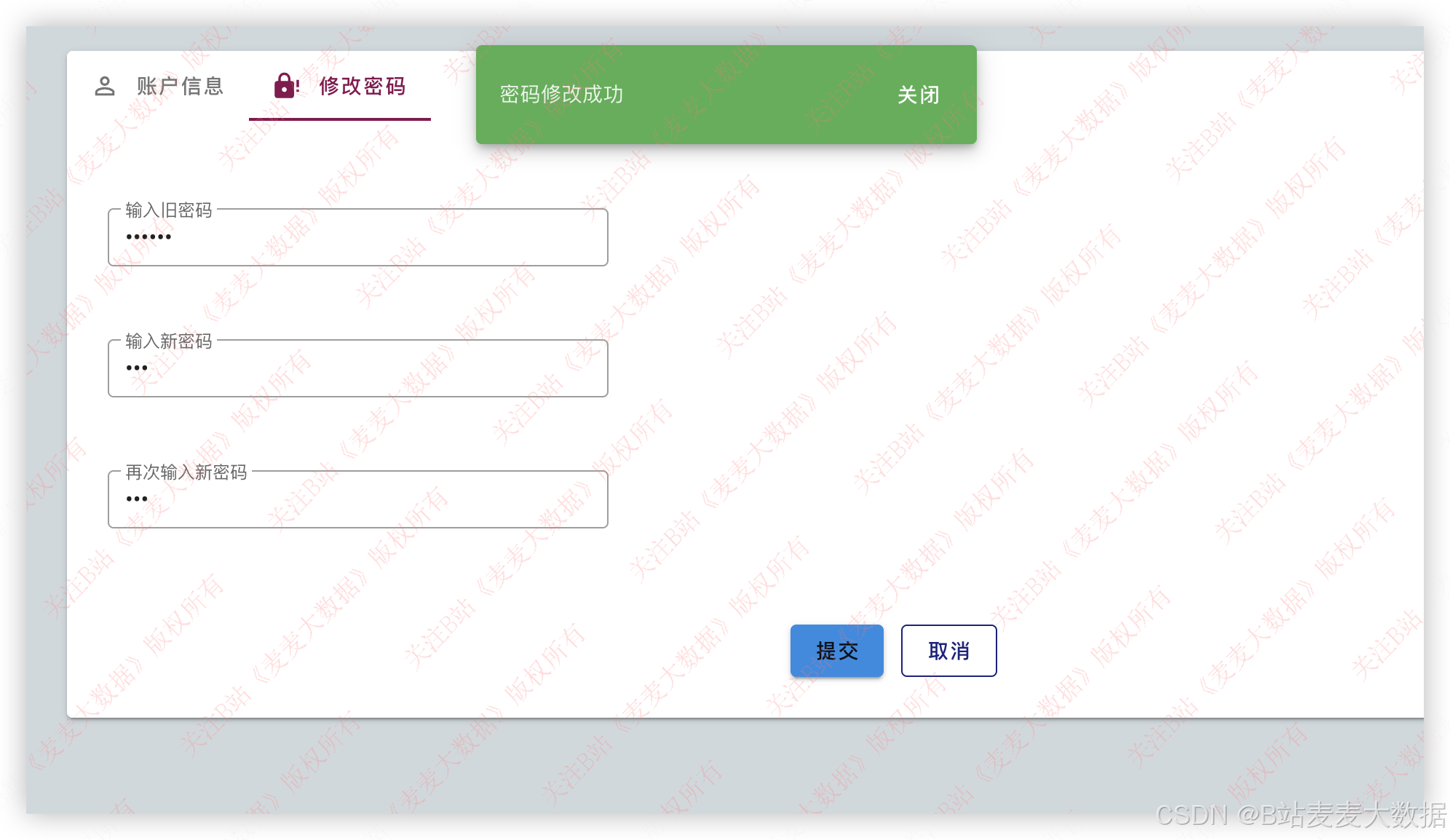
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
4程序代码
4.1 代码说明
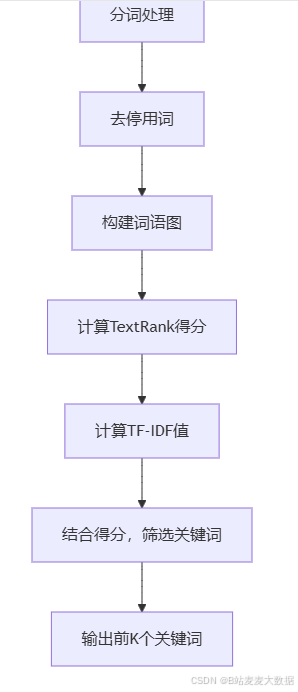
代码介绍:以下是基于TextRank和TF-IDF实现的体育新闻内容关键词分析算法的Python代码。该代码通过结合TextRank算法和TF-IDF技术,提取体育新闻中的关键词。首先,代码对新闻内容进行分词和去停用词处理,然后构建词图并利用TextRank算法计算词语的重要性得分。接着,结合TF-IDF进一步筛选关键词,最后输出前K个关键词。
4.2 流程图
4.3 代码实例
python
import jieba
from collections import defaultdict
import networkx as nx
from sklearn.feature_extraction.text import TfidfVectorizer
class KeywordExtractor:
def __init__(self, stop_words_path):
self.stop_words = set()
with open(stop_words_path, 'r', encoding='utf-8') as f:
for line in f:
self.stop_words.add(line.strip())
def textrank_tfidf(self, text, k=10):
# 分词
words = jieba.lcut(text)
# 去停用词
filtered_words = [word for word in words if word not in self.stop_words]
# 构建词图
graph = defaultdict(float)
for i in range(len(filtered_words)-1):
current = filtered_words[i]
next_word = filtered_words[i+1]
graph[(current, next_word)] += 1.0
# TextRank计算
G = nx.DiGraph()
for edge, weight in graph.items():
G.add_edge(edge[0], edge[1], weight=weight)
pr = nx.pagerank(G, weight='weight', tol=1e-08)
textrank_words = sorted(pr.items(), key=lambda x: x[1], reverse=True)
# TF-IDF计算
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform([' '.join(filtered_words)])
feature_names = vectorizer.get_feature_names_out()
tfidf_values = dict(zip(feature_names, tfidf.toarray()[0]))
# 结合TextRank和TF-IDF
combined_scores = defaultdict(float)
for word, _ in textrank_words:
combined_scores[word] += pr[word] * tfidf_values.get(word, 0)
# 返回前k个关键词
return [word for word, score in sorted(combined_scores.items(), key=lambda x: x[1], reverse=True)[:k]]
# 示例使用
extractor = KeywordExtractor('stopwords.txt')
news_text = """
XX赛事精彩瞬间:C罗梅开二度,曼联2-1逆转利兹联。
"""
keywords = extractor.textrank_tfidf(news_text, k=5)
print("关键词:", keywords)