在电商大厂的技术面试中,除了编程能力和算法知识的考察外,还会深入探讨系统设计、性能优化和一些高级技术细节,尤其是在涉及JVM调优、并发编程、加密算法等方面时,面试者需要展现出扎实的理论基础和丰富的实战经验。以下是一些常见的技术面试问题及解答。
1. JVM设计角度下,GC优化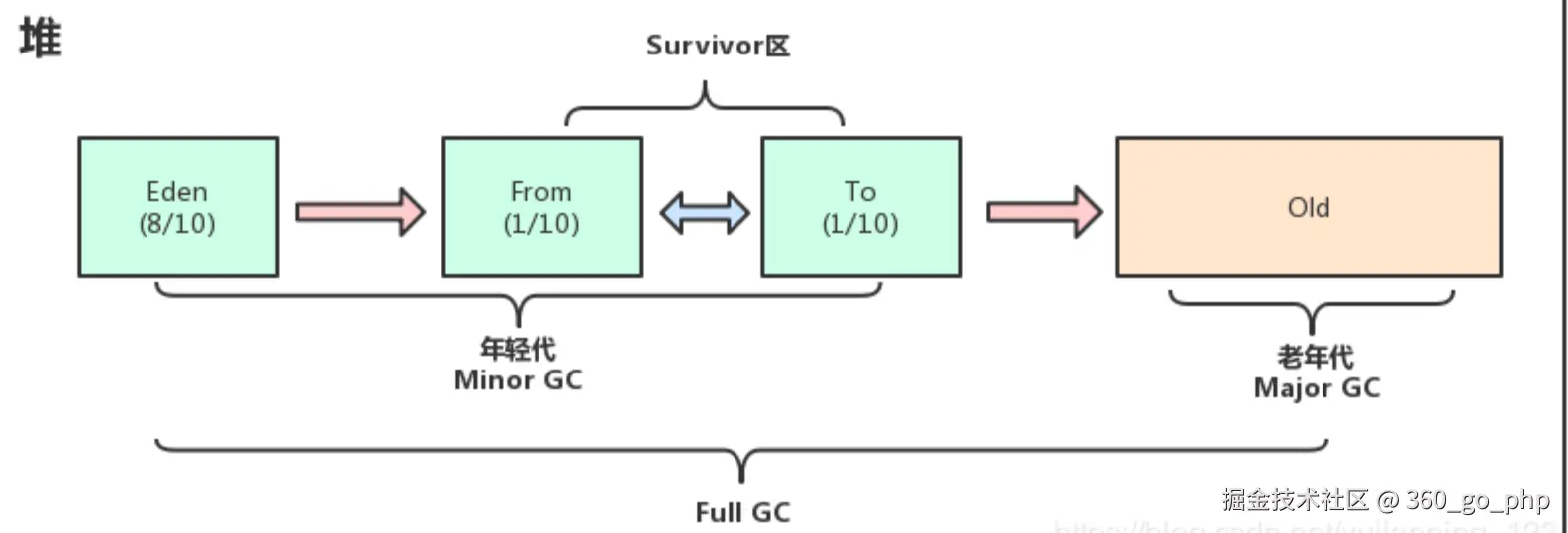 编辑
编辑
在JVM的垃圾回收(GC)优化方面,首先需要理解GC的工作原理。常见的JVM垃圾回收器有Serial、Parallel、CMS、G1、ZGC和Shenandoah等,每种垃圾回收器有不同的特点和适用场景。优化GC时可以从以下几个方面入手:
- 选择合适的垃圾回收器:例如,G1适用于低延迟的应用,ZGC和Shenandoah适用于大内存和低延迟场景。
- 堆内存设置 :合理配置JVM的堆内存大小,避免频繁的GC。通过调整
-Xms(初始堆大小)和-Xmx(最大堆大小)来避免堆内存不足导致的频繁GC。 - 调优GC参数 :例如,使用
-XX:MaxGCPauseMillis来控制GC停顿时间,-XX:NewRatio来控制年轻代与老年代的比例,合理配置-XX:ParallelGCThreads来优化并行垃圾回收。 - 减少对象创建:通过对象池化和对象复用来减少垃圾产生,尤其是在高并发场景下,减少垃圾回收的影响。
2. 设计MD5函数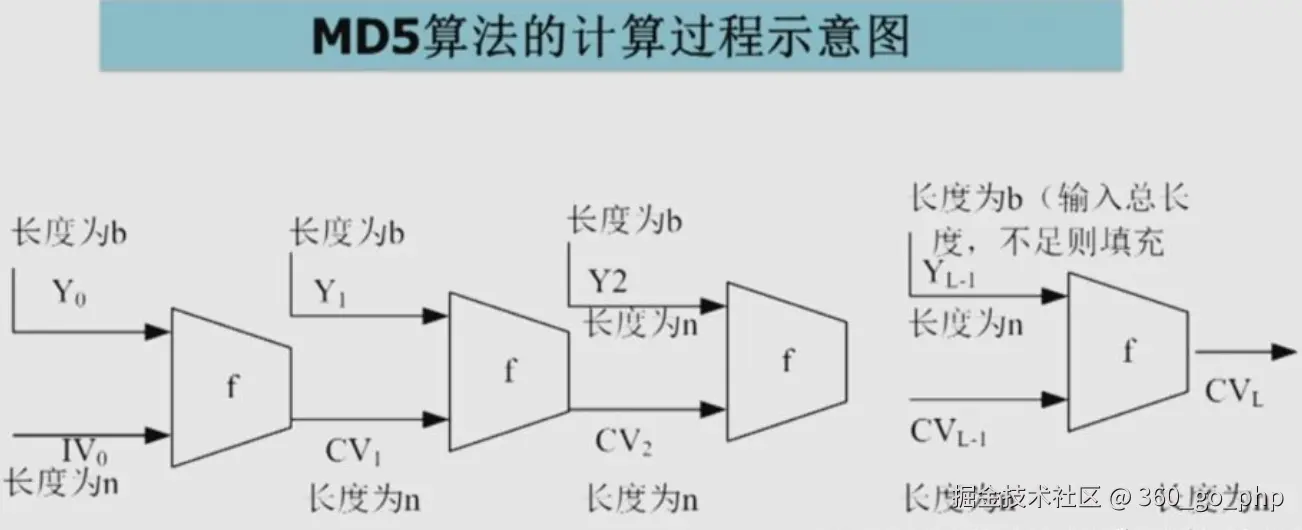 编辑
编辑
MD5是一种广泛使用的哈希算法,它将输入的任意长度的数据映射为固定长度的128位哈希值。在不使用HashMap和映射的情况下,设计一个类似的MD5哈希算法可以通过以下步骤:
- 分块处理:将输入数据按块分割,每块512位(64字节),并将数据填充到符合MD5要求的大小。
- 初始化常量:定义常量值(例如,A、B、C、D等)作为MD5的初始值。
- 处理循环:根据MD5的工作原理,通过非线性函数(如F、G、H、I)对数据进行处理,使用常量进行加法计算。
- 输出结果:最终生成一个128位的哈希值。
java
public class SimpleMD5 {
public String generateMD5(String input) {
// 转换为字节数组
byte[] data = input.getBytes(StandardCharsets.UTF_8);
// 填充数据,使其满足512位的块大小
// 执行MD5算法的处理逻辑...
// 最终返回哈希值
return Arrays.toString(data);
}
} 3. CPU占用过高的排查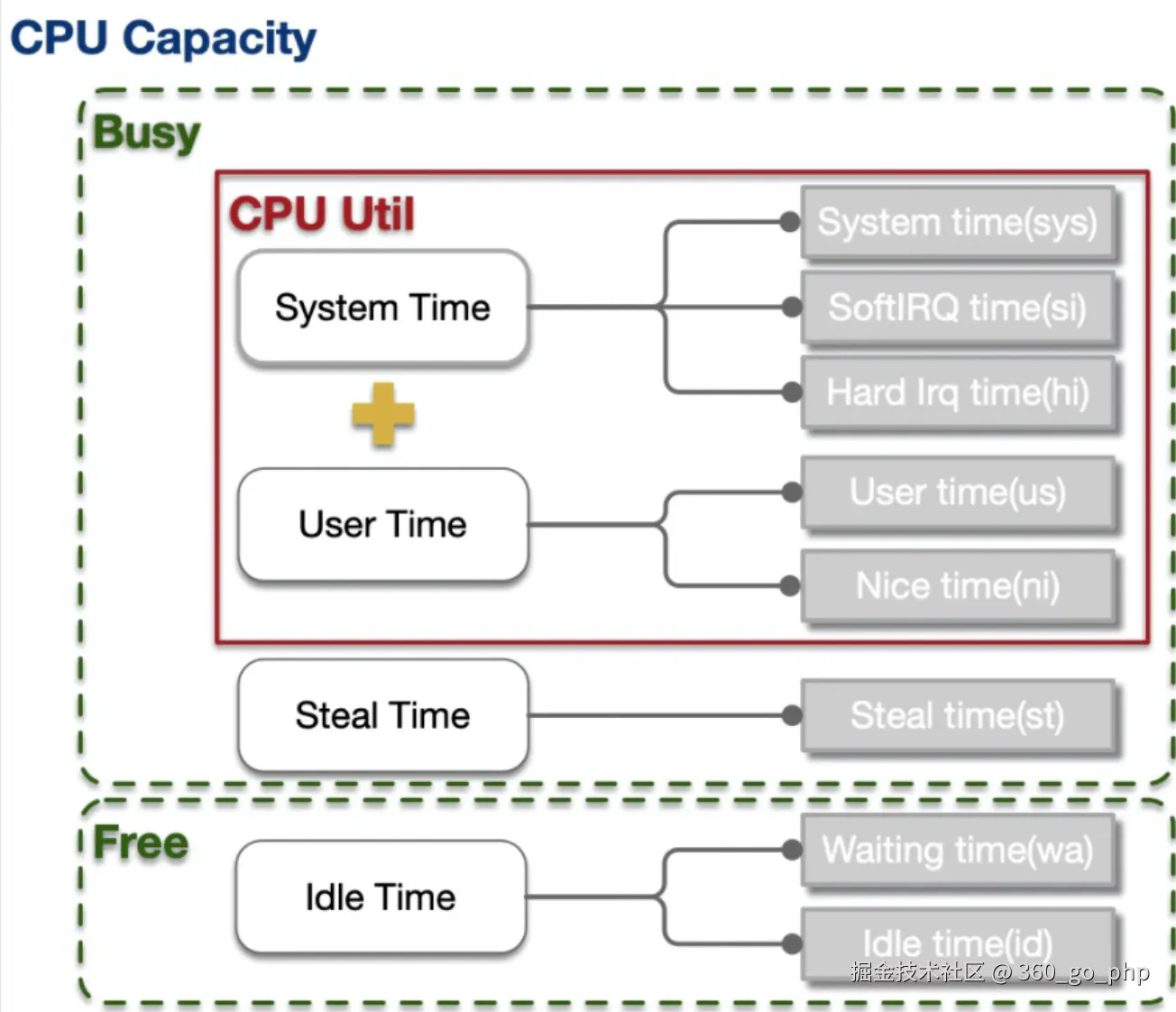 编辑
编辑
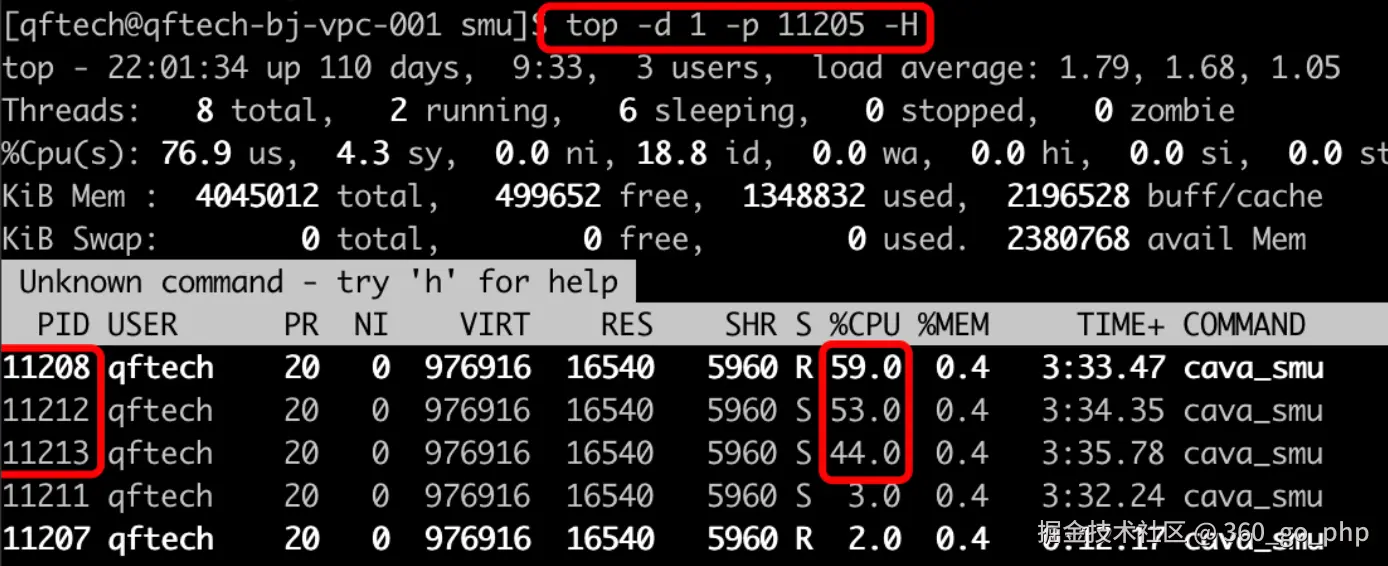
当发现CPU占用一直很高时,首先可以从以下几个方面进行排查:
- 使用性能分析工具 :如
jstack、VisualVM、jconsole等工具查看线程栈,分析是否存在死循环或高耗时的线程。 编辑
编辑 - 查看线程状态 :可以通过
top命令或htop查看哪些进程占用了大量的CPU,进一步用jstack或jmap等工具定位线程的调用栈。 - 优化算法 :检查代码中是否存在低效算法或高复杂度操作,优化数据结构,减少不必要的计算。
 编辑
编辑 - 垃圾回收 :检查GC是否频繁触发,可以通过
-XX:+PrintGCDetails参数查看GC日志,判断是否存在频繁的Full GC或Minor GC,进而优化堆内存或选择合适的GC策略。
4. 设计一个垃圾回收器以提高回收效率
如果让你自己设计一个垃圾回收器,首先需要考虑以下几个目标:
- 并行性:可以支持多线程并行工作,提高吞吐量。
- 低延迟:减少停顿时间,尤其在大内存的应用中尤为重要,类似ZGC和Shenandoah的设计。
- 增量回收:通过增量式的GC,减少每次回收的停顿时间。
- 回收策略:对于不同的内存区域(如年轻代、老年代),采用不同的回收策略。年轻代采用复制算法,老年代采用标记-整理算法。
- 智能预测:通过分析历史数据预测垃圾回收的时间和范围,从而提前准备,避免长时间的停顿。
5. 设计一个不使用HashMap的MD5生成算法
MD5本质上是一个哈希算法,可以不依赖于HashMap来实现。通过设计自定义的哈希函数和使用一些位运算,可以实现类似的功能。
- 位运算:将字符串每个字符的ASCII值通过位运算转换为一个唯一的哈希值。
- 随机性:通过对数据进行混合处理,并引入随机因子,可以提高哈希的分布性。
java
public class CustomMD5 {
public long generateMD5(String input) {
long hash = 0;
for (int i = 0; i < input.length(); i++) {
hash = hash * 31 + input.charAt(i); // 使用质数31避免冲突
}
return hash & 0xFFFFFFFFFFFFFFFFL; // 返回64位的哈希值
}
} 6. 利用Java现有的东西设计类似Synchronized的对象
在Java中,我们可以通过ThreadLocal来为每个线程提供一个独立的副本,从而避免不同线程之间的冲突。ThreadLocal可以确保每个线程拥有独立的数据,不需要同步,能够有效避免线程安全问题。
java
public class ThreadLocalExample {
private static final ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public void increment() {
threadLocal.set(threadLocal.get() + 1);
}
public int getValue() {
return threadLocal.get();
}
} 7. Synchronized锁定.class与实例的区别 编辑
编辑
- 锁定实例 :
synchronized(this)表示锁住当前对象实例,多个线程在操作不同实例时不会相互干扰。 - 锁定类 :
synchronized(ClassName.class)表示锁住整个类,所有线程只能通过同一个类的锁进行访问,这在类级别上是共享的。
8. EXPLAIN中的key字段的值等于ref时,是否触发索引?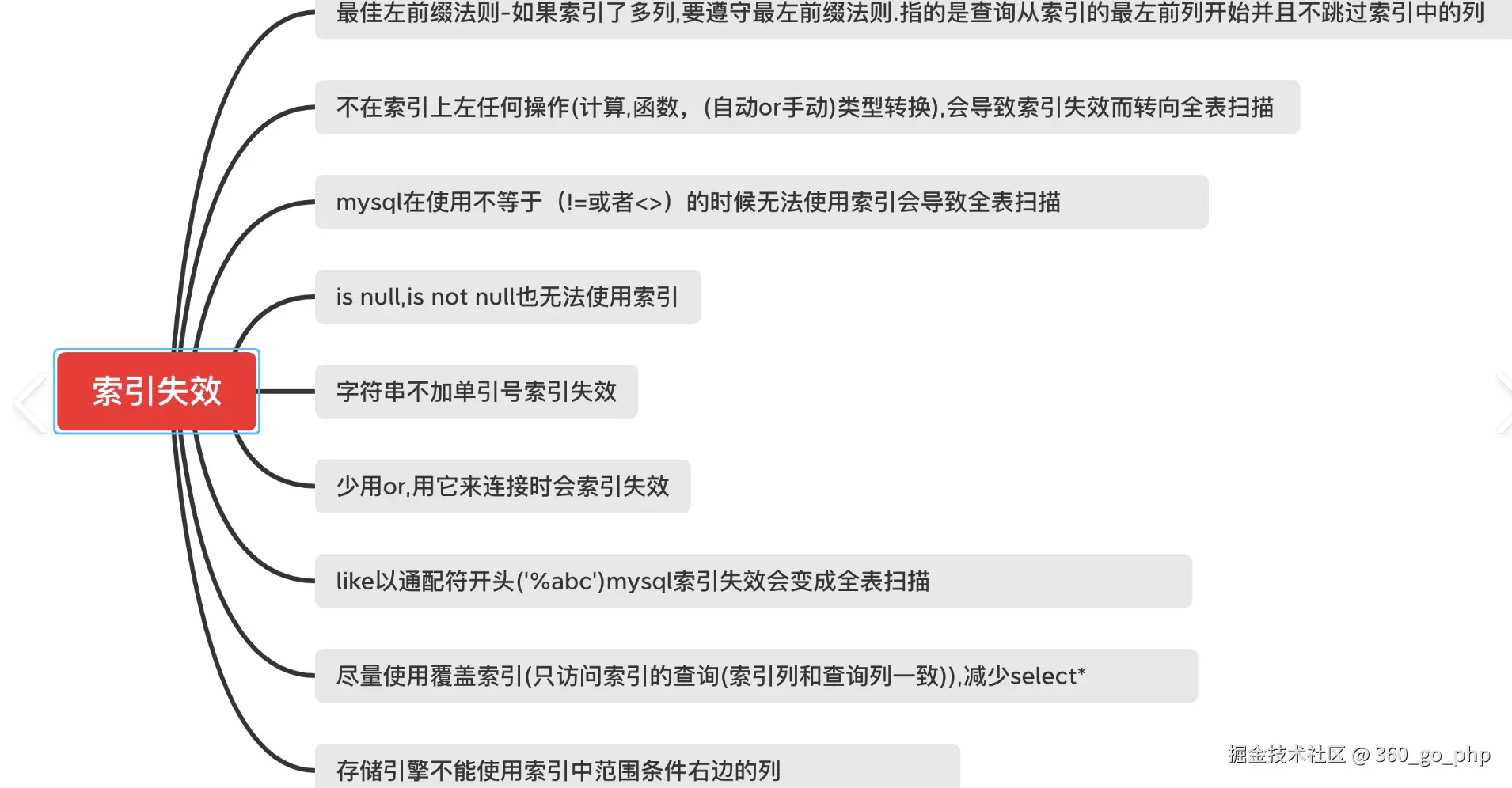 编辑
编辑
EXPLAIN的key字段表示查询中使用的索引,当key为ref时,表示使用了某个索引列来进行查询。ref本身是一个常量值或列的引用,表示索引的使用,但ref不等于key。
9. 实现单点登录和权限控制
- 单点登录:可以使用OAuth2.0、JWT等技术实现。通过令牌(Token)进行身份验证,跨多个应用共享用户登录状态。
- 权限控制:根据用户角色控制不同的访问权限,通常使用角色权限模型,结合RBAC(角色访问控制)实现。
- 密码泄露安全性:使用加密技术(如PBKDF2、bcrypt)存储密码。即使密码泄露,也能保障安全。
10. Spring中的循环依赖解决
Spring通过三级缓存(实例、构造器注入、setter注入)来解决循环依赖。首先创建一个对象的代理,然后通过后置处理器设置真实对象。解决循环依赖的关键是使用依赖注入和AOP的结合。
如果自己实现,可以采用类似代理模式,先生成一个空的代理对象,待依赖注入完成后,再替换为真实对象。
通过这些问题和解答,我们可以看到电商大厂的技术面试不仅考察编程能力,更注重系统设计、优化方案和解决复杂问题的能力。在准备面试时,不仅要掌握基础的知识,还需要具备良好的系统思维和问题解决能力。