就在AI界为Yann LeCun离职Meta的消息震惊时,一份意外的"告别礼物"悄然出现在arXiv上------这位图灵奖得主与Randall Balestriero合作的新论文 《LeJEPA:一种简约且可扩展的联合嵌入预测架构》 ,提出了仅需50行代码的自监督学习新框架。
这或许是LeCun在Meta的最后一篇论文。
- 论文地址: arxiv.org/pdf/2511.08...
- 论文名称: LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics

2025年7月,Meta做出令人意外的任命------28岁的Scale AI创始人Alexandr Wang成为首席AI官,职位高于LeCun。这一决定在AI圈引起轩然大波。仅仅一个月后,前谷歌大脑研究员赵晟佳被任命为超级智能实验室首席科学家,LeCun在Meta的决策权被进一步削弱。

权力结构的调整在10月达到高潮:LeCun领导的FAIR实验室裁员600余人,其中包括核心研究员田渊栋。这支曾经开创了卷积神经网络等突破性技术的团队,如今面临大幅缩编。
"FAIR正在被边缘化,这已经不是什么秘密了。"一位前Meta员工透露,"当扎克伯格把赌注都压在LLM上时,LeCun的世界模型研究就失去了内部支持。"
LeCun与Meta管理层的分歧早已不是秘密。这位AI先驱多次公开批评大语言模型是"死胡同",无法实现真正的智能。他主张开发能够通过感知数据学习物理规律的"世界模型"。

新框架LeJEPA:仅50行代码的简洁解决方案
这篇由LeCun与Randall Balestriero合作的论文,提出了一种名为LeJEPA的新框架,旨在解决当前联合嵌入预测架构方法中存在的多种失效模式。
JEPA方法由于缺乏明确的实践指南和系统理论,目前相关研究大多是临时性探索。而这篇论文给出了一套完整的JEPA理论,并将其具体落地为LeJEPA------一种轻量、可扩展且有坚实理论基础的训练目标。
研究人员证明,若要最小化下游任务的预测风险,JEPA的嵌入理想情况下应服从各向同性高斯分布。为此,他们提出了新的目标函数SIGReg,用于约束嵌入向该理想分布收敛。
LeJEPA融合了JEPA和SIGReg思想,兼具多方面的理论和实践优势:
- 只需要一个权衡超参数
- 时间与内存复杂度均为线性
- 在超参数、架构以及不同领域之间表现稳定
- 不依赖启发式技巧,适合分布式训练
- 仅需约50行代码即可实现
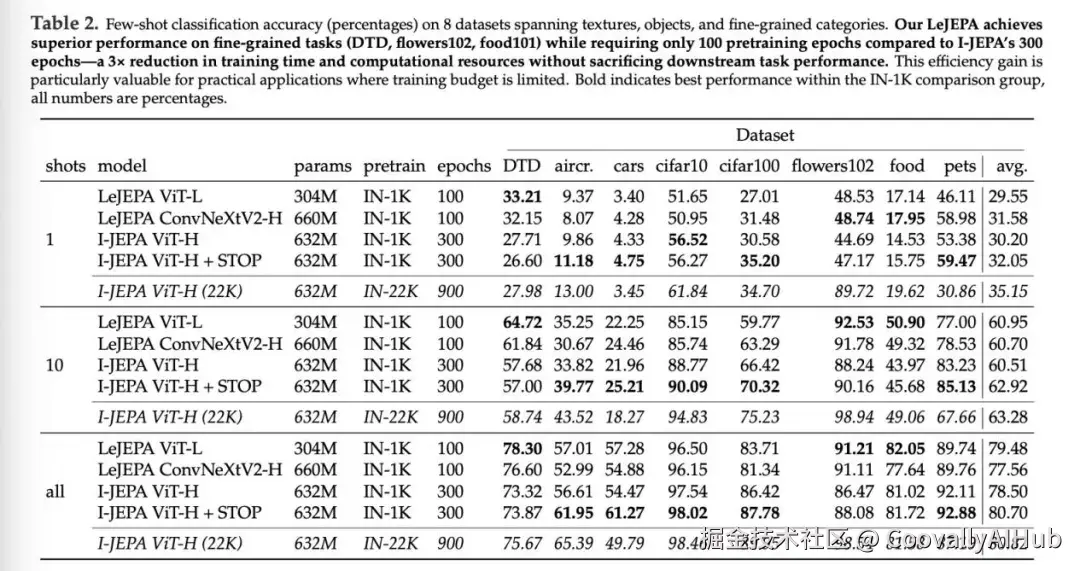
如图1所示,在使用ImageNet-1K进行预训练并对冻结骨干网络做线性评估的设定下,LeJEPA在ViT-H/14上可达到79%的精度,表现出色。
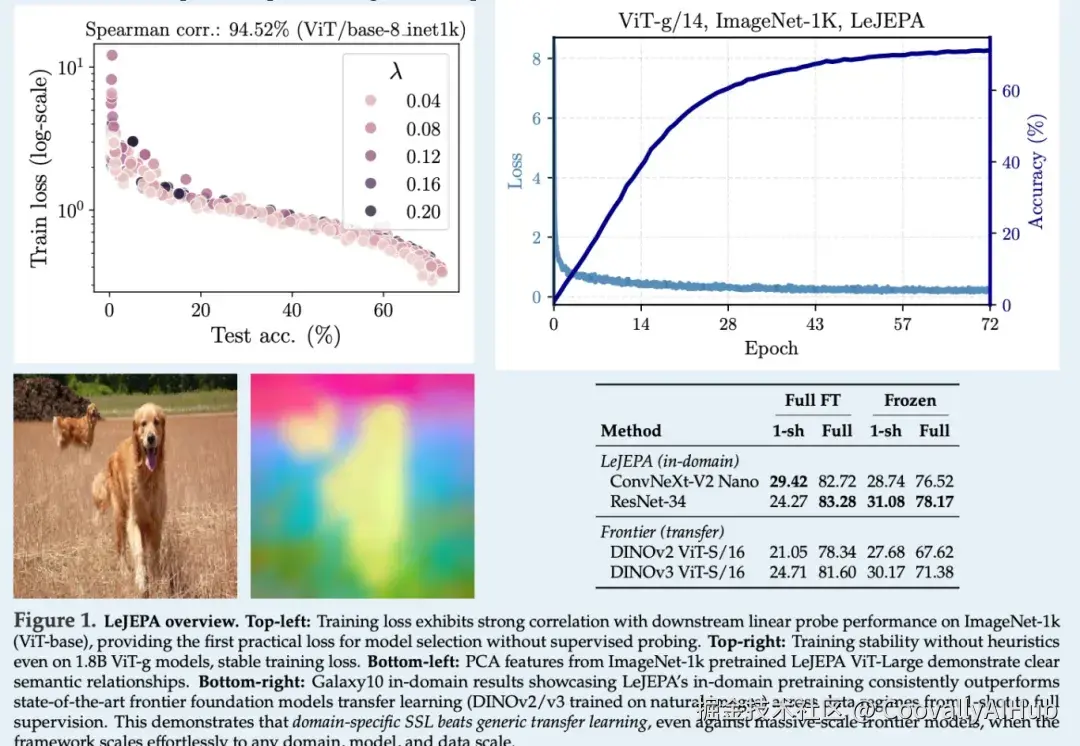
自监督学习的核心挑战与LeJEPA的解决路径
在AI领域,一个长期存在的核心问题是让模型学会对世界及其变化形成可用于实际决策的表征。
无论是图像识别、机器人,还是物理学、太空探索,都会面临一个共同问题:如何仅凭观测数据,学习到一个结构清晰、便于操作的高维嵌入空间?
使用深度网络将观测映射到嵌入是解决这一难题的标准第一步。第二步,也是尚未标准化的部分,是如何训练这些网络参数。
JEPA提出一条路径:通过最大化语义相关视图的嵌入之间的一致性预测来训练网络。这些"视图"可以包括掩码、裁剪、模糊、时间或空间平移等多种变换操作。然而,JEPA的预测任务存在一些失败模式,例如表征崩溃------网络将所有输入映射到几乎相同的嵌入(完全崩溃),或只落在低维子空间上(维度崩溃)。
有关JEPA的理论基础研究在很大程度上仍处于空白状态,而LeCun的这项研究正是要打破这一循环。
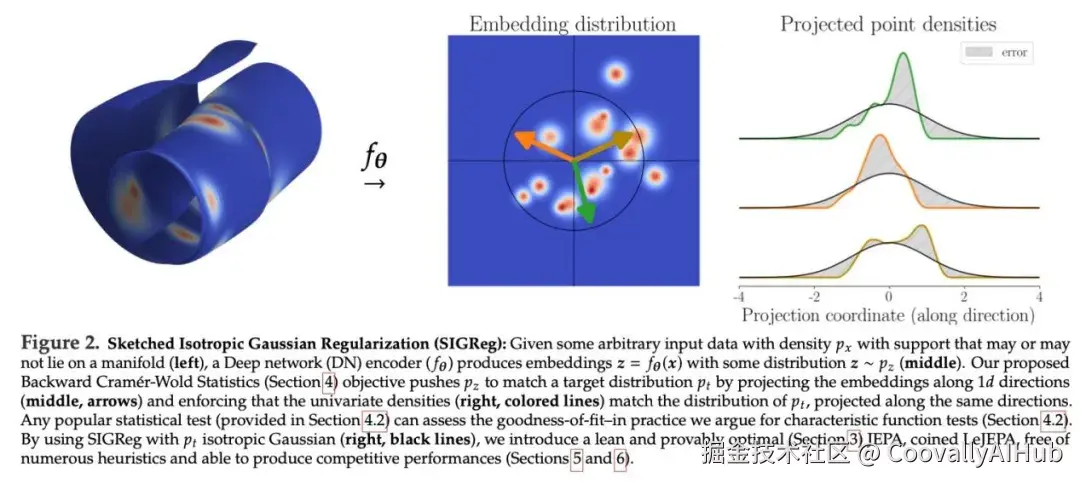
理论基础:各向同性高斯分布是最优嵌入
研究人员通过重新审视支撑JEPA的基础设计原则,提炼出一种全新且精简的JEPA"原则":解决预测任务,同时强制嵌入服从各向同性高斯分布。
他们证明,为了在任意下游任务上最小化经验风险,嵌入应该服从各向同性高斯分布。
研究人员首先通过分析线性探针来确定嵌入的最优分布,这是评估冻结编码器时最常用的方法之一。
为了对预训练编码器进行更灵活的评估,研究人员还分析了两类广泛使用的非线性方法:基于半径的k-NN方法和核方法。
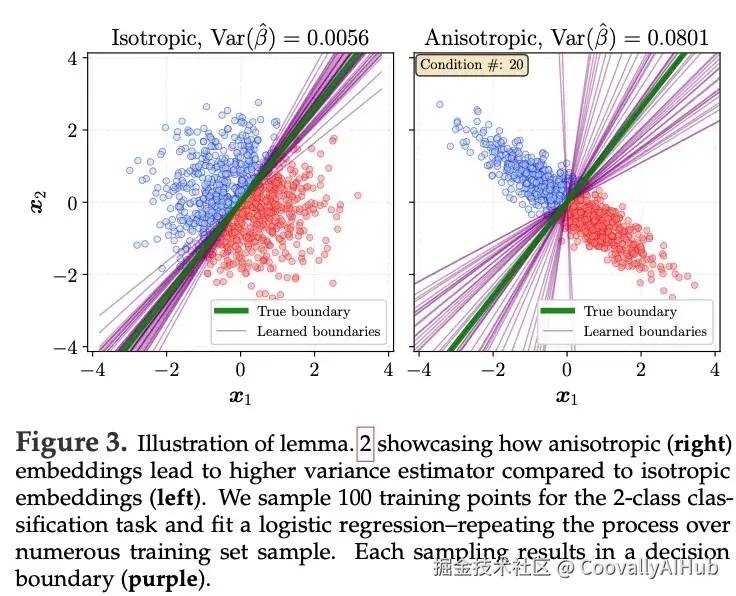
上图展示了各向异性嵌入如何比各向同性嵌入产生更高的方差估计值。研究人员对二分类任务抽取了100个训练点,并拟合逻辑回归模型------在多个训练集样本上重复此过程。每次抽样都会产生一个决策边界。
SIGReg:高维空间中的高斯正则化
在证明各向同性高斯分布是最优嵌入分布之后,研究人员引入了SIGReg------一个同时具有可微性、可扩展性、理论可证明性以及可解释性的分布匹配目标函数。
它建立在三个关键创新之上:
首先,研究人员将分布匹配表述为在原假设下的统计假设检验;
其次,构造了一类检验,在保持线性复杂度和高效多GPU扩展的同时,保证梯度和曲率均有界。
第三,SIGReg避免了维度灾难,从而彻底消除了退化的捷径解。

图4展示了具有不同Sobolev平滑系数α的球面上分布示例。由于目标密度(各向同性高斯分布)是平滑的,嵌入的α系数会迅速增长,从而使SIGReg不受维度灾难的影响。
研究人员证明,SIGReg绘制Epps-Pulley测试图是稳定且可扩展的。
图5显示了构建的数据密度图。其"X"分布的边缘分布为标准高斯分布,协方差为单位矩阵。
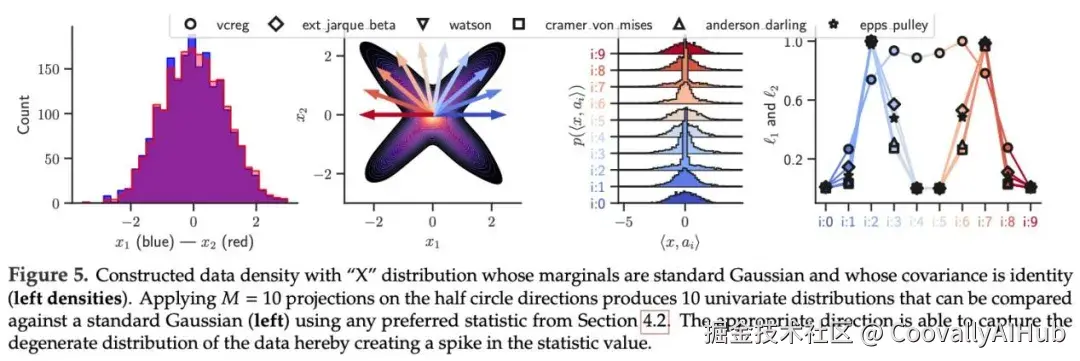
图6展示了从一个1024维标准高斯分布中抽取100个样本,并改变前两个坐标以生成"X"分布。对于每个统计量,研究人员对样本执行梯度下降以最小化其值。
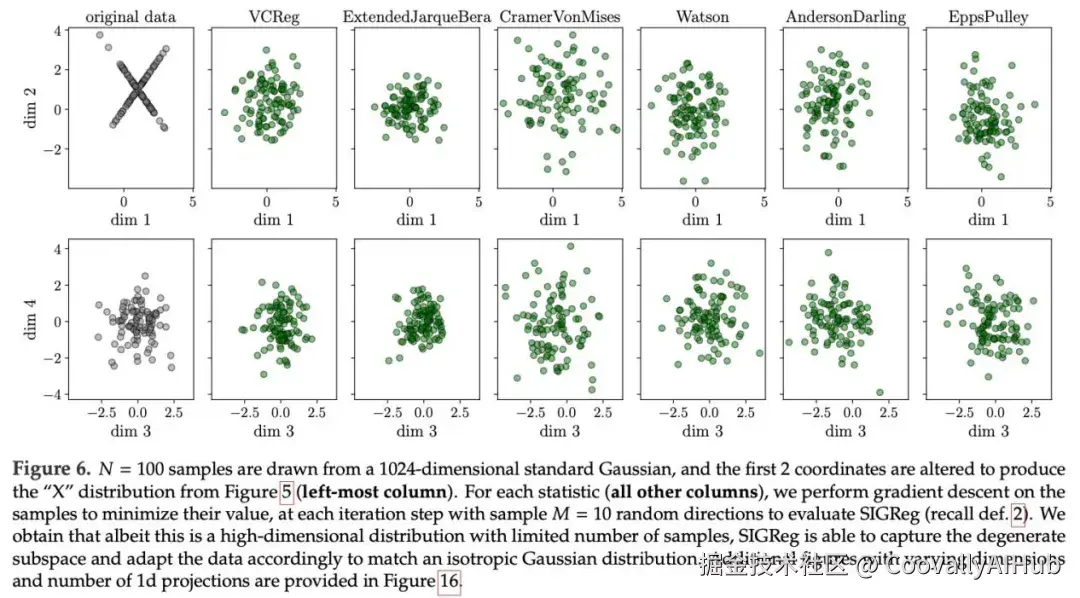
结果表明,尽管这是一个高维分布且样本数量有限,但SIGReg能够捕获退化子空间并相应地调整数据以匹配各向同性高斯分布。
LeJEPA的实际表现:跨架构跨领域的稳定性
在确定各向同性高斯分布是基础模型的最佳嵌入分布,并引入SIGReg来实现该分布之后,研究人员推出了完整的LeJEPA框架,并通过全面实验验证其有效性。
图9展示了使用LeJEPA开箱即用的ImageNet-10预训练和冻结骨干网络线性评估方法在timm模型上的应用。研究人员对学习率和权重衰减进行了交叉验证。
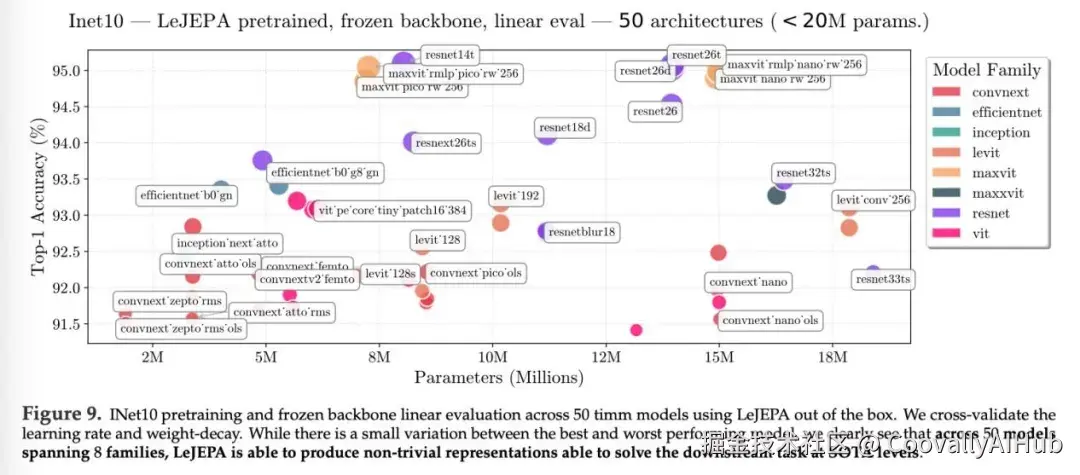
虽然最佳模型和最差模型之间存在细微差异,但在涵盖8个模型系列的50个模型中,LeJEPA能够生成非平凡的表示,从而以SOTA水平解决下游任务。
跨架构稳定性是LeJEPA的关键优势之一。大多数现代自监督学习方法都针对Vision Transformer进行了优化,而LeJEPA无需修改,即可在各种不同的架构系列中运行。
为了验证这一结论,研究人员使用ImageNet-10数据集预训练了来自8个不同架构系列的约50个模型,这些模型均来自timm库,且参数量均小于2000万。
所有模型均能学习到高质量的表征,在冻结骨干线性探测的情况下,Top-1准确率达到了91.5%到95%。结果表明,在监督学习环境中表现良好的模型,例如ResNet和Vision Transformer,也同样适用于LeJEPA。
自监督学习的一个关键优势在于学习能够跨任务和领域泛化的通用表征。然而,当前前沿的基础模型(如DINOv2/v3、I-JEPA)都是在自然图像上进行预训练的,这迫使特定领域的从业者需要收集大量的标签来进行监督式微调。
事实上,大多数前沿模型无法直接在这些领域进行训练,因为样本数量可能很少,而且重新搜索超参数会非常耗时。
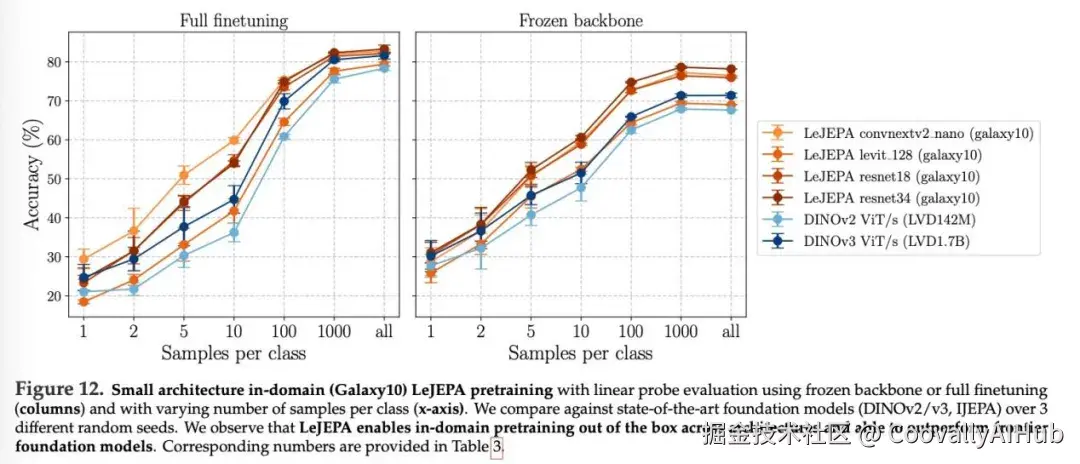
图12展示了使用冻结骨干网络或完全微调以及不同类别样本数的LeJEPA在小型架构上的域内预训练,并结合线性探针评估。研究人员将其与最先进的基础模型在3个不同的随机种子上进行了比较。
结果表明,LeJEPA能够开箱即用地在不同架构上进行域内预训练,并且性能优于目前最先进的基础模型。
LeJEPA的涌现能力:自发的分割与语义理解
LeJEPA通过自监督学习习得了丰富的语义表征,展现出令人惊讶的涌现能力。
图13展示了基于最后一层阈值的涌现式目标分割,LeJEPA无需显式监督即可自然地学习分割和跟踪显著目标(如每个视频右侧的注意力图所示)。

图14展示了LeJEPA通过自监督学习习得的丰富语义表征。在没有任何监督的情况下,LeJEPA自发地构建出语义丰富的表征:暖色(红色/品红色/粉色)始终用于表示前景物体(鹦鹉的身体、狗的脸),而冷色(青色/绿色/黄色)则用于表示背景和树叶。

这种涌现的物体-背景分离和感知分组,完全基于未标记的数据,揭示了世界的视觉结构。
研究人员在多个领域、超过60种架构上验证了LeJEPA,其中包括参数规模高达18亿的巨型模型版本。结果证明,尽管其核心设计非常简单,LeJEPA的核心实现代码不足50行,但仍能够达到当前最先进方法的性能。
结语
在提交的论文中,LeJEPA框架展现出令人惊讶的涌现能力------无需显式监督,即可自然学习分割和跟踪显著目标,自发构建丰富的语义表征。
在论文插图里,暖色始终表示前景物体,冷色表示背景,展现出类似人类感知的分组能力。这一切,完全基于未标记数据学习而得。
这或许正是LeCun想传达的信息:不需要海量标注数据,不需要暴力扩展模型规模,AI依然可以学会理解世界。
随着这篇论文的发布,LeCun在Meta的篇章即将落幕。但对AI界来说,一位摆脱束缚的顶尖科学家,或许能带来更多惊喜。