引言:
在掌握了双链表这种灵活的动态数据结构之后,我们不难发现,它在插入和删除操作上提供了极大的自由度。然而,在解决特定问题时,我们有时并不需要如此全面的操作能力。恰恰相反,限制操作的自由度,往往能带来更高的效率和更清晰的逻辑。
这就是我们今天要探讨的栈 (Stack)。
栈:
栈 (stack)是限定仅在表尾 进行插入或删除操作的线性表 。因此对栈来说,表尾端有特殊含义,称为栈顶 (top),相应地,表头端称为栈底( bottom)。不含元素的空表称为空栈。
假设 S=(,
,
,
,
),则称
为栈底元素 ,
为栈顶元素 。栈中元素按
,
,
的次序进栈,退栈的第一个元素应为栈顶元素。换句话说,栈的修改时按照后进先出的原则进行的。因此,栈又称为后进先出(Last In First Out,LIFO)的线性表。

栈的顺序结构实现:
cpp
#define MAXSIZE 100
typedef int ElemType;
typedef struct{
ElemType data[MAXSIZE];
int top;
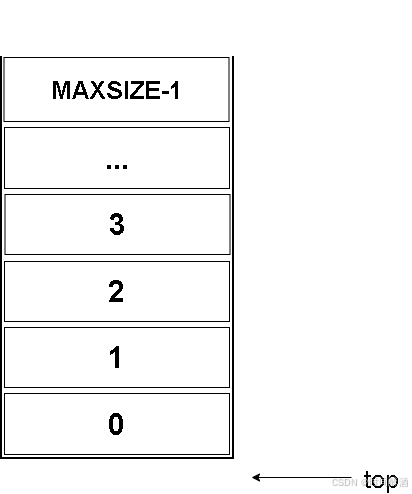
}Stack;栈的顺序结构-初始化
cpp
void initStack(Stack* s)
{
s->top = -1;
}如下所示:
栈的顺序结构-判断栈是否为空
cpp
//判断栈是否为空
int isEmpty(Stack* s)
{
if (s->top == -1)
{
printf("空的\n");
return 1;
}
else
{
return 0;
}
}栈的顺序结构-进栈/压栈
cpp
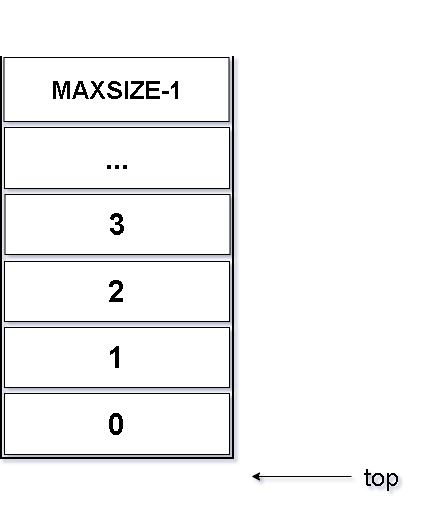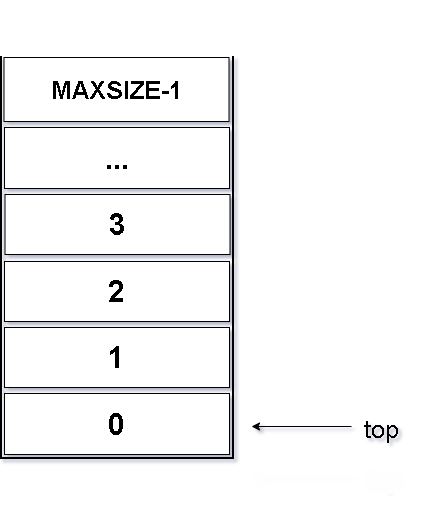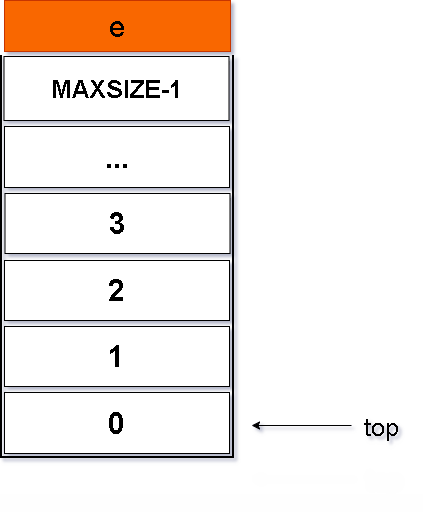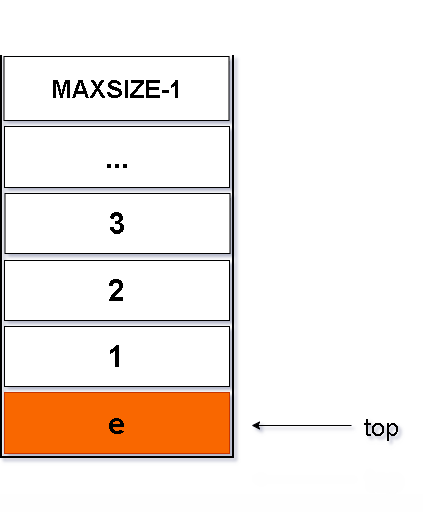
//栈的顺序结构-进栈/压栈
int push(Stack* s, ElemType e)
{
if (s->top >= MAXSIZE - 1)
{
printf("满了\n");
return 0;
}
s->top++;
s->data[s->top] = e;
return 1;
}图解如下:
栈的顺序结构-出栈
cpp
//栈的顺序结构-出栈
ElemType pop(Stack* s, ElemType* e)
{
if (s->top == -1)
{
printf("空的\n");
return 0;
}//有isEmpt可省略
*e = s->data[s->top];
s->top--;
return 1;
}图解如下:
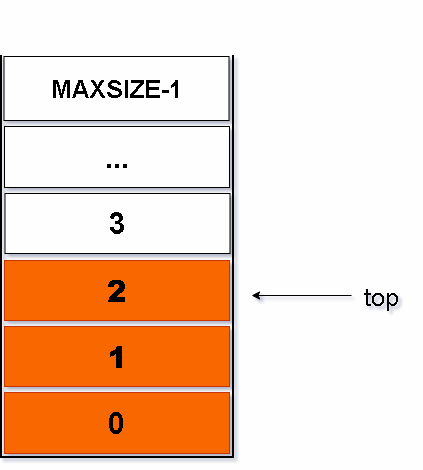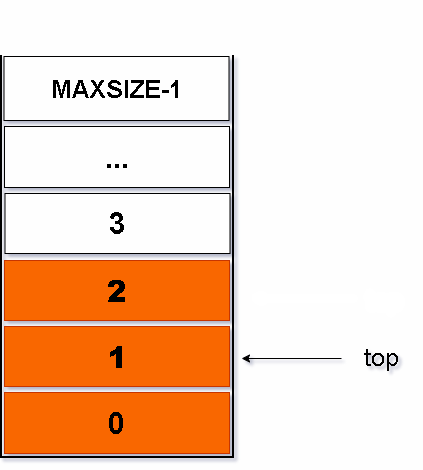
常见问题以及代码解释:
1.push(Stack* s, ElemType e) vs pop(Stack* s, ElemType* e) 为什么这两个函数为什么在参数传递上有所不同?
想象一下你有一个 储物盒(Stack),这个盒子里面可以放很多小东西(ElemType类型的)。
push(Stack* s, ElemType e) - 进栈/压栈
Stack* s: 这个是你传递进来的 储物盒本身 。*表示这是一个指针,意思是"指向储物盒的地址",这样函数才能直接操作你原来的盒子,而不是复制一个副本来操作。ElemType e: 这个是你想要 放进储物盒里的小东西。它就是一个普通的"值"。你把它直接"塞"进去。
所以,push 操作就是:"这个盒子 (s),我给你一个东西 (e),你把它放进去。"
pop(Stack* s, ElemType* e) - 出栈
Stack* s: 同样,这是你要从里面取东西出来的 储物盒本身。ElemType* e: 这里的*e是一个 "空位"的地址 。你可以理解成,你给函数一个 "用于存放取出来东西的空盘子" ,并且这个盘子有一个 "位置标识" ,这样函数才能把取出来的东西 "放回" 到你指定的盘子里。
2.为什么会有这种设计?
这种设计 (pop 用 ElemType* e 作为输出参数) 在 C 语言中非常常见,主要有以下原因:
- 函数返回值限制: C 语言中的函数默认只能有一个返回值。如果
pop函数需要同时返回"操作是否成功"和"取出的元素值",就不能直接把元素值作为返回值。所以,它用返回值表示成功/失败,用输出参数*e来传递取出的元素。 - 效率: 有时直接把大型数据结构通过返回值传递可能效率不高(需要复制),而通过指针传递(复制地址)或者在调用者预留的空间中填充数据,效率可能更高。
3.e vs *e
e是 "地址"*e是 "通过这个地址能访问到的地方(以及对那个地方进行读写操作)"
*e 不是一个"东西",而是一个"动作"或者"指令"。
这个"动作"叫做解引用 (dereferencing)。
我们再回到储物盒的例子:
ElemType* e: 你可以想象e是一个小纸条,纸条上写着一个 房间号 。这个房间号指向一个可以放"小东西"(ElemType类型)的 特定座位/位置。*e: 这个*符号就是告诉计算机:"请根据e纸条上的房间号,找到那个座位,然后'看看那里有什么'或者'把东西放到那里'。"
所以,*e 不是"房间号本身"(那是 e),也不是"房间里的东西"(那是 s->data[s->top]),而是"去那个房间找东西/放东西"这个"过程"或"操作"。
4.那为什么我们常说 *e 是"e 指向的值"?
这是因为,一旦你执行了 *e 这个"动作",你 得到的结果 就是那个"房间"里的"值"。
- 当你 读取
*e时,你得到的是e指向的那个内存地址里存储的值。 - 当你 写入
*e时,你是在改变e指向的那个内存地址里存储的值。
栈的顺序结构-获取栈顶元素
cpp
//栈的顺序结构-获取栈顶元素
int getTop(Stack* s, ElemType* e)
{
if (s->top == -1)
{
printf("空的\n");
return 0;
}
*e = s->data[s->top];
return 1;
}mian函数:
cpp
int main(int argc, char const* argv[])
{
Stack s;
initStack(&s);
push(&s, 10);
push(&s, 20);
push(&s, 30);
ElemType e;
pop(&s, &e);
printf("%d\n", e);
getTop(&s, &e);
printf("%d\n", e);
return 0;
}结果如下:

完整代码:
cpp
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct stack
{
ElemType data;
struct stack *next;
}Stack;
Stack* initStack()
{
Stack* s = (Stack*)malloc(sizeof(Stack));
s->data = 0;
s->next = NULL;
return s;
}
int isEmpty(Stack* s)
{
if (s->next == NULL)
{
printf("空的\n");
return 1;
}
else
{
return 0;
}
}
int push(Stack* s, ElemType e)
{
Stack* p = (Stack*)malloc(sizeof(Stack));
p->data = e;
p->next = s->next;
s->next = p;
return 1;
}
int pop(Stack* s, ElemType* e)
{
if (s->next == NULL)
{
printf("空的\n");
return 0;
}
*e = s->next->data;
Stack* q = s->next;
s->next = q->next;
free(q);
return 1;
}
int getTop(Stack* s, ElemType* e)
{
if (s->next == NULL)
{
printf("空的\n");
return 0;
}
*e = s->next->data;
return 1;
}
int main(int argc, char const* argv[])
{
Stack* s = initStack();
push(s, 10);
push(s, 20);
push(s, 30);
ElemType e;
pop(s, &e);
printf("%d\n", e);
getTop(s, &e);
printf("%d\n", e);
}普通栈 vs 链式栈
- 普通栈 (基于数组): 就像一个固定大小的 盒子(只有一个口),你只能往盒子里装东西,最多装到盒子满了为止。
- 链式栈 (基于链表): 就像一个 连续的餐盘,你可以随意往餐盘上加菜(或拿走),餐盘的长度可以随着你加菜而无限增长(理论上)。(详见上一期)
栈的链式结构实现:
cpp
typedef int ElemType;
typedef struct stack
{
ElemType data;
struct stack *next;
}Stack;栈的链式结构实现 - 初始化
cpp
Stack* initStack()
{
Stack* s = (Stack*)malloc(sizeof(Stack));
s->data = 0;
s->next = NULL;
return s;
}栈的链式结构实现 - 判断栈是否为空
cpp
int isEmpty(Stack* s)
{
if (s->next == NULL)
{
printf("空的\n");
return 1;
}
else
{
return 0;
}
}栈的链式结构实现 - 进栈/压栈(头插法)
cpp
int push(Stack* s, ElemType e)
{
Stack* p = (Stack*)malloc(sizeof(Stack));
p->data = e;
p->next = s->next;
s->next = p;
return 1;
}栈的链式结构实现 - 出栈
cs
int pop(Stack* s, ElemType* e)
{
if (s->next == NULL)
{
printf("空的\n");
return 0;
}
*e = s->next->data;
Stack* q = s->next;
s->next = q->next;
free(q);
return 1;
}栈的链式结构实现 - 获取栈顶元素
cpp
int getTop(Stack* s, ElemType* e)
{
if (s->next == NULL)
{
printf("空的\n");
return 0;
}
*e = s->next->data;
return 1;
}main函数
cpp
int main(int argc, char const* argv[])
{
Stack* s = initStack();
push(s, 10);
push(s, 20);
push(s, 30);
ElemType e;
pop(s, &e) :
printf("%d\n", e);
getTop(s, &e);
printf("%d\n", e);
return 0;
}结果如下:

完整代码:
cpp
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct stack
{
ElemType data;
struct stack *next;
}Stack;
Stack* initStack()
{
Stack* s = (Stack*)malloc(sizeof(Stack));
s->data = 0;
s->next = NULL;
return s;
}
int isEmpty(Stack* s)
{
if (s->next == NULL)
{
printf("空的\n");
return 1;
}
else
{
return 0;
}
}
int push(Stack* s, ElemType e)
{
Stack* p = (Stack*)malloc(sizeof(Stack));
p->data = e;
p->next = s->next;
s->next = p;
return 1;
}
int pop(Stack* s, ElemType* e)
{
if (s->next == NULL)
{
printf("空的\n");
return 0;
}
*e = s->next->data;
Stack* q = s->next;
s->next = q->next;
free(q);
return 1;
}
int getTop(Stack* s, ElemType* e)
{
if (s->next == NULL)
{
printf("空的\n");
return 0;
}
*e = s->next->data;
return 1;
}
int main(int argc, char const* argv[])
{
Stack* s = initStack();
push(s, 10);
push(s, 20);
push(s, 30);
ElemType e;
pop(s, &e);
printf("%d\n", e);
getTop(s, &e);
printf("%d\n", e);
}总结:
至此,我们深入探讨了栈的两种常见实现方式:顺序结构(基于数组) 和 链式结构(基于链表)。
- 顺序栈 结构简洁,易于理解,在内存分配固定且大小已知的情况下,具有高效的访问速度。然而,它也存在容量限制,需要预先定义
MAXSIZE,容量不足时需要动态扩容,增加了实现的复杂度。 - 链式栈 则以其动态可变的特性而著称。它不受固定大小的限制,可以随着元素的增减自动调整,理论上可以存储无限个元素(受限于系统内存)。通过使用哨兵节点,我们进一步优化了链式栈的入栈和出栈操作,使其逻辑更加清晰,边界处理也更加优雅。
选择哪种结构?
- 如果你的程序对内存使用有严格的限制,或者知道栈的最大容量,并且频繁进行栈操作,顺序栈 可能是一个不错的选择。
- 如果栈需要存储大量数据,或者其大小变化很大,链式栈 会是更灵活、更优的选择。