目录
目标检测作为计算机视觉领域的核心任务之一,其发展历程中涌现出众多优秀算法。YOLO系列算法以其独特的"单阶段"检测思想,在速度与精度的平衡上取得了显著成果。今天,我们将深入探讨YOLO系列的第三个重要版本------YOLOv3,看看它在前作基础上做出了哪些令人瞩目的改进。
一、YOLOv3的整体性能表现
在目标检测领域,我们通常关注两个关键指标:检测精度(通常用mAP衡量)和推理速度(通常用毫秒级的推理时间表示)。下图清晰地展示了YOLOv3与其他主流检测算法在这两个维度上的对比情况。
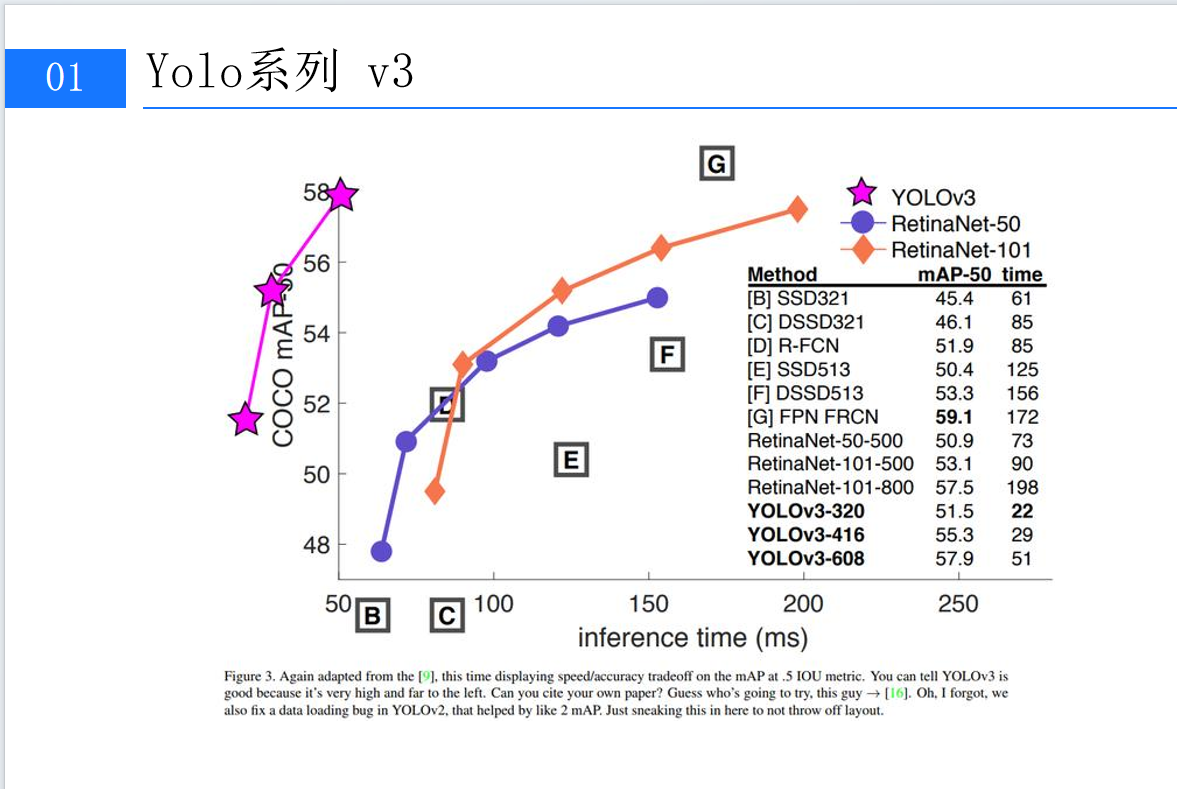
如图所示,YOLOv3在保持较快推理速度的同时,实现了较高的检测精度。特别值得注意的是,YOLOv3在COCO mAP指标上表现优异,而且其推理时间相对较短,这使得它在实际应用中具有很强的竞争力。图中不仅展示了YOLOv3与RetinaNet系列算法的对比,还包含了SSD等其他主流检测算法的性能数据,为我们提供了全面的性能参考。
二、YOLOv3的核心改进点
YOLOv3最大的改进在于网络结构的优化,这一改进使其特别适合小目标检测任务。那么,YOLOv3具体做了哪些优化呢?
首先,YOLOv3在特征处理方面更加细致,它巧妙地融入了多种持续特征图信息来预测不同规格的物体。这种多尺度特征融合的思想,使得网络能够同时关注图像中的全局信息和局部细节,从而提升了对不同大小目标的检测能力。
其次,YOLOv3设计了更加丰富的先验框系统。具体来说,它采用了3种不同的scale(尺度),每种scale又包含3个不同规格的先验框,总共形成了9种先验框。这种多样化的先验框设计,让模型能够更好地适应各种形状和大小的目标物体。
最后,YOLOv3对传统的softmax函数进行了改进,使其能够用于预测多标签任务。这一改进增强了模型的表达能力,使其能够处理更加复杂的检测场景。
三、多尺度检测策略
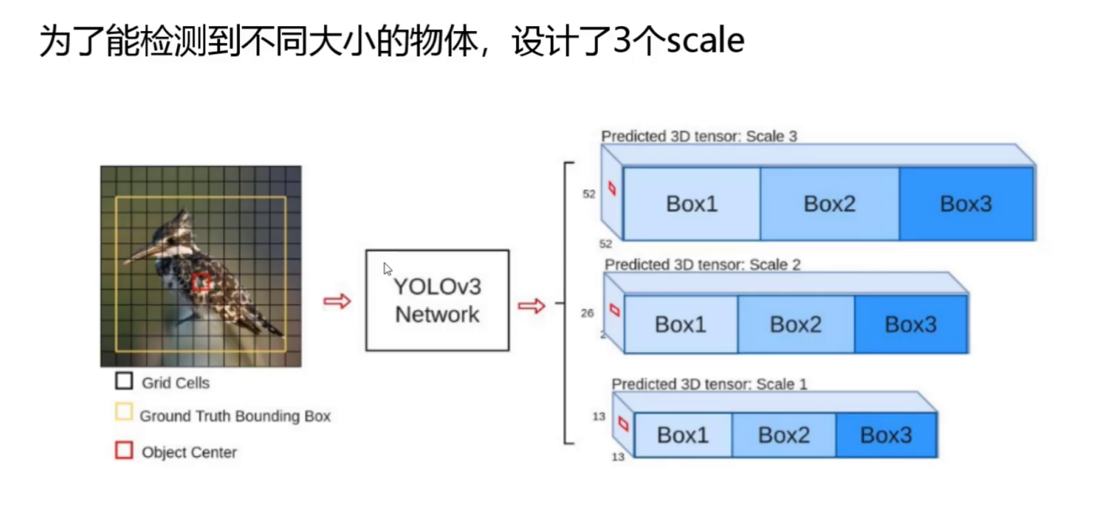
为了能够检测到不同大小的物体,YOLOv3设计了三个尺度的预测机制,这是其重要的创新之一。为什么需要多尺度检测呢?因为在实际场景中,目标物体的大小差异可能非常显著,从小型的昆虫到大型车辆,单一尺度的检测器难以兼顾所有情况。
YOLOv3通过在不同层次的特征图上进行预测,实现了对不同尺度目标的有效检测。如下面展示的结构所示,网络包含了Scale 1(13×13)、Scale 2(26×26)和Scale 3(52×52)三个不同尺度的预测层。每个尺度都包含多个预测框(Box1、Box2、Box3),这些预测框能够在各自擅长的尺度范围内检测目标物体。
https://via.placeholder.com/600x400?text=YOLOv3+多尺度检测
从图中我们可以看到,网络通过网格划分的方式定位目标,黄色框标注了真实边界框,红色点表示物体中心位置。这种多尺度预测机制使得YOLOv3能够同时关注图像中的大尺度和小尺度特征,大大提升了对不同大小目标的检测能力。
四、经典的尺度变换方法对比
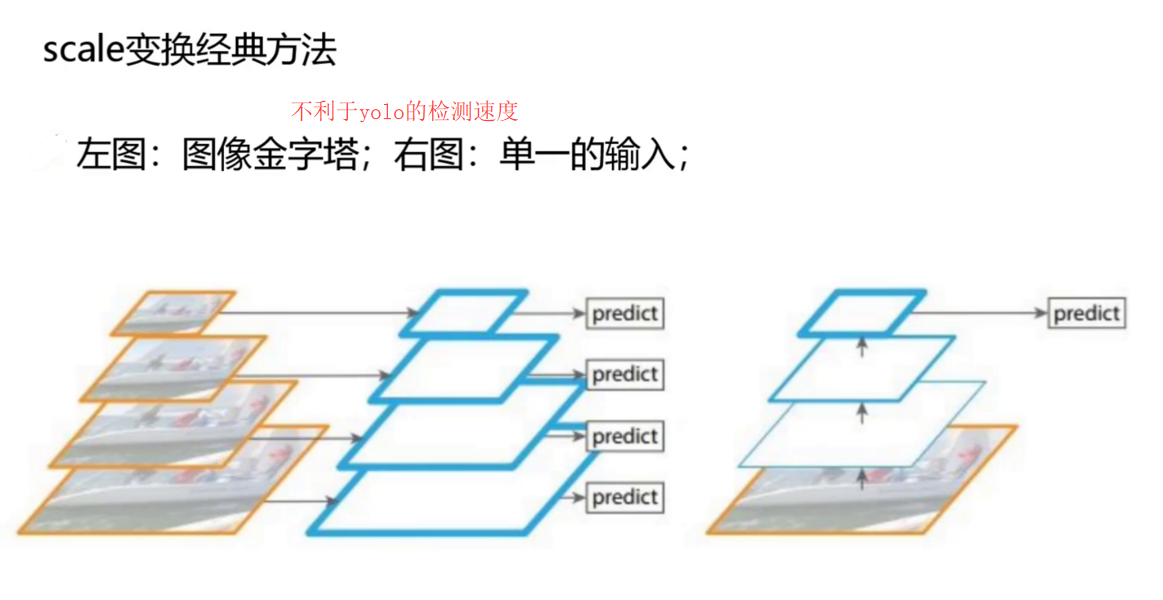
在目标检测领域,处理不同尺度目标的传统方法主要有两种:图像金字塔和单一输入配合多层次预测。YOLOv3在这些经典方法的基础上进行了创新和改进。
下图展示了两种传统尺度变换方法的对比。左侧的"图像金字塔"方法通过对原始图像进行不同比例的缩放,生成多层大小不一的图像,每层图像对应一个独立的预测层。这种方法虽然直观,但计算成本较高,不利于检测速度的提升。
相比之下,右侧的"单一的输入"方法只使用一层图像作为输入,但在网络的不同层次上进行多层次预测。这种方法计算效率更高,更符合现代实时检测的需求。
YOLOv3在吸收这些经典方法优点的基础上,采用了更加高效的单一输入配合多层次特征融合的策略,既保证了检测精度,又维持了较快的检测速度。
五、特征融合策略的演进
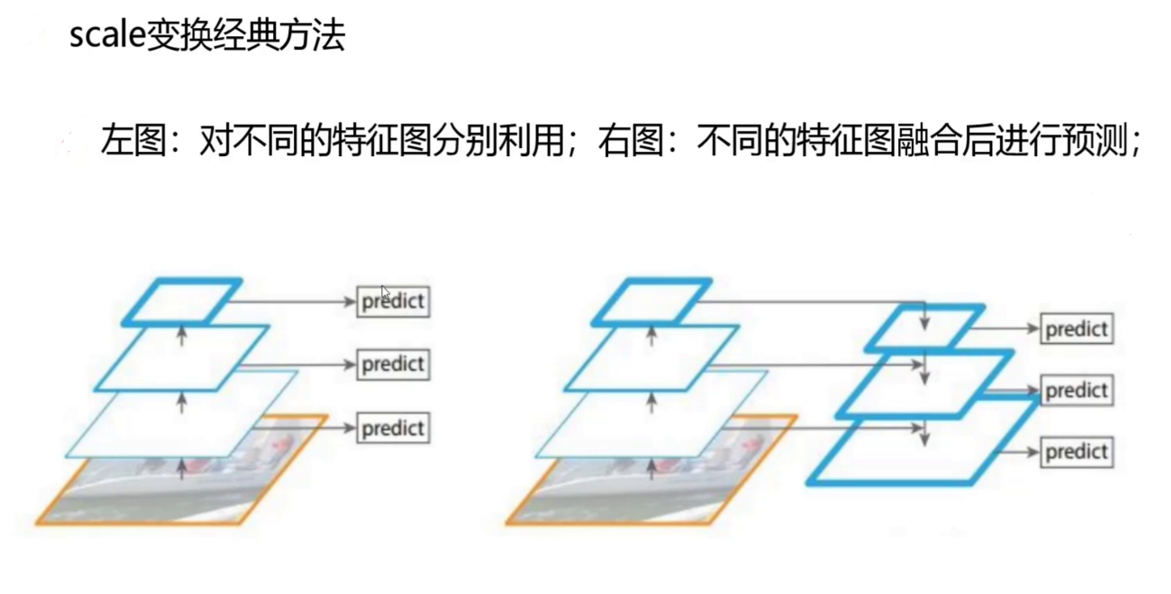
在多尺度检测中,如何有效利用不同层次的特征图是一个关键问题。传统方法主要有两种策略:一种是对不同的特征图分别利用 ,另一种是将不同的特征图融合后进行预测。
如下图所示,左侧展示了分别利用不同特征图的策略,每层特征图都独立指向一个预测层。而右侧则展示了特征图融合后进行预测的策略,不同层次的特征图先通过融合操作整合信息,然后共同指向多个预测层。
YOLOv3在多尺度检测中采用了更加精细的特征融合策略,通过在不同层次的特征图之间建立连接,实现了信息的有效传递和融合,从而提升了检测性能,如下图右侧所示。
六、残差连接的应用
现代深度学习网络往往包含很多层,随着网络深度的增加,梯度消失和网络退化问题变得越来越突出。为了解决这些问题,残差连接(Residual Connection)成为了现代网络架构的重要组件。
YOLOv3也运用了ResNet的思想,通过堆叠更多层来进行特征提取,同时引入了残差连接来缓解深层网络的训练难题。如下图所示,残差连接的基本原理是让输入x经过一系列变换(包括weight layer、relu等操作)后,与原输入x相加(H(x)=F(x)+x),然后再进行relu操作。
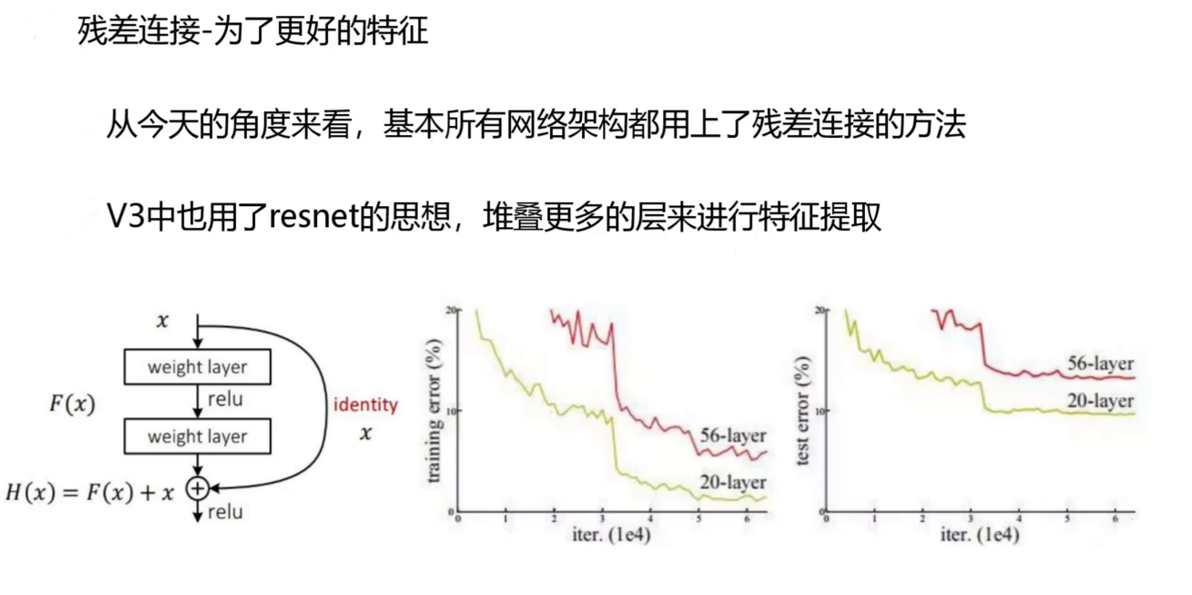
从图中我们还可以看到,YOLOv3通过实验对比了不同深度网络的训练误差和测试误差变化情况。这种残差连接的设计使得YOLOv3能够堆叠更多网络层进行特征提取,同时保持良好的训练效果和泛化能力。
七、核心网络架构:Darknet-53
YOLOv3的核心网络架构是基于Darknet-53构建的,这是一个专门为检测任务设计的高效卷积神经网络。与许多其他网络架构不同,Darknet-53没有使用池化层和全连接层,完全由卷积层构成,这种设计使得网络更加灵活且易于调整。
下图展示了Darknet-53的核心架构,它通过下采样(通过stride为2的卷积操作实现)逐步提取高层次特征,同时设置了3种不同的scale以配置更多先验框,从而适应不同大小的目标检测需求。
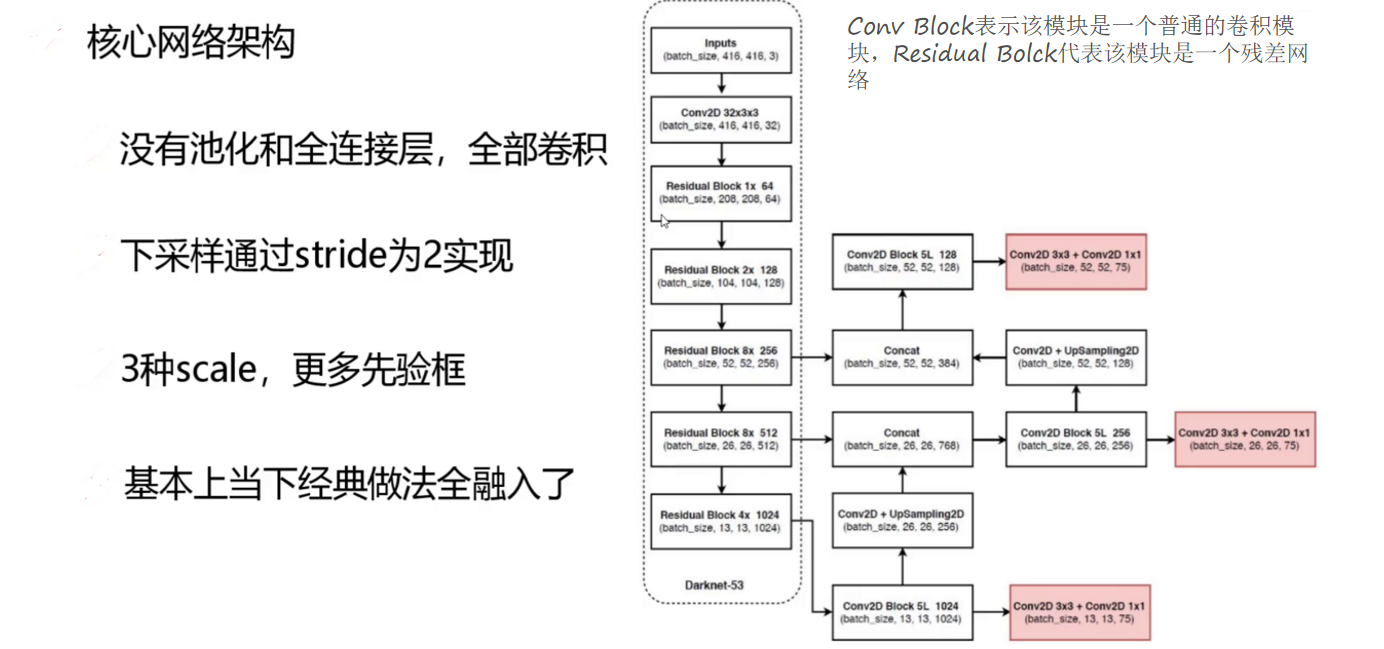
Darknet-53网络融合了当前深度学习领域的诸多经典做法,在保持较高检测精度的同时,实现了较快的推理速度。这种精心设计的网络架构为YOLOv3的优秀性能奠定了坚实基础。
通过以上分析,我们可以看到YOLOv3在多个方面都做出了重要改进,从网络结构设计到多尺度检测策略,从特征融合方法到核心网络架构,每一项改进都体现了研究者对目标检测任务的深入理解和精心优化。这些改进共同造就了YOLOv3在速度与精度平衡上的卓越表现。
(本文为YOLOv3详解的上篇,下篇我们将继续深入探讨YOLOv3的其他技术细节和实际应用。)