什么是手写数字识别?
我们要解决的问题很简单:让计算机学会识别手写的 0-9 这 10 个数字。就像银行自动识别支票上的数字、快递单自动识别收件人电话那样,只不过我们用的是经典的 MNIST 数据集(包含 6 万张训练图和 1 万张测试图)。
第一步:搭建神经网络(model.py)
先来看模型结构,我们要搭建一个简单的卷积神经网络,包含这些层:
第二步:训练模型(train.py)
有了模型结构,接下来就是训练了。训练过程就像教小孩认数字:先看例子(训练集),再做测试(测试集),不断纠正错误。
-
卷积层:提取图像的边缘、轮廓等特征
-
展平层:把二维图像转换成一维数据
-
全连接层:对特征进行进一步处理
-
输出层:输出 10 个数字的预测概率
python# 从 TensorFlow 的 Keras 模块中导入需要的层: # Dense:全连接层(用于分类计算), # Flatten:展平层(把二维图像转成一维数据), # Conv2D:卷积层(提取图像特征) from tensorflow.keras.layers import Dense, Flatten, Conv2D # 从 Keras 导入 Model 类:用于自定义模型(继承这个类就能自己搭建网络结构) from tensorflow.keras import Model # 定义自己的模型类 MyModel,继承自 Keras 的 Model 类(相当于"抄作业",直接用 Model 的基础功能) class MyModel(Model): # 初始化函数:创建模型时自动执行,用来定义网络的所有层 def __init__(self): # 调用父类(Model)的初始化方法,确保模型基础功能能正常使用 super(MyModel, self).__init__() # 定义第1层:卷积层(Conv2D),核心作用是"提取图像的局部特征"(比如线条、轮廓) # 参数解释: # 32:输出特征图数量(相当于用32种不同的"滤镜"去扫图像,得到32个特征结果) # 3:卷积核大小(3x3的正方形,每次扫图像的3x3区域) # activation='relu':激活函数(把负数变成0,让模型能学习复杂的非线性特征,避免简单线性计算) self.conv1 = Conv2D(32, 3, activation='relu') # 定义第2层:展平层(Flatten),核心作用是"把二维图像数据转成一维数组" # 因为卷积层输出的是二维特征图,全连接层需要一维数据才能计算,这里是"中间转换器" self.flatten = Flatten() # 定义第3层:全连接层(Dense),核心作用是"对提取的特征做进一步计算" # 参数解释: # 128:该层的神经元数量(128个神经元同时计算,相当于128个不同的计算逻辑) # activation='relu':继续用relu激活函数,增加模型的学习能力 self.d1 = Dense(128, activation='relu') # 定义第4层:输出层(全连接层),核心作用是"输出最终分类结果" # 参数解释: # 10:输出神经元数量(对应10个类别,比如MNIST的0-9手写数字) # activation='softmax':激活函数(把输出转成"概率",10个值总和为1,最大的那个就是预测的类别) self.d2 = Dense(10, activation='softmax') # 调用函数:模型接收输入数据时执行,定义数据在网络中的"流动路径"(前向传播过程) # x:输入的图像数据,shape(格式)是 [batch, 28, 28, 1](后面会详细解释) # **kwargs:兼容其他参数(不用管,固定写法) def call(self, x, **kwargs): # 第一步:输入数据x经过卷积层conv1,提取特征 # 输入x格式:[batch, 28, 28, 1] → batch:一次训练的图片数量,28x28:图片像素,1:灰度图(只有1个颜色通道) # 输出格式:[batch, 26, 26, 32] → 26x26:卷积后图像大小(计算逻辑:(28 - 3 + 1)/1 = 26,因为3x3卷积核不填充边缘),32:32个特征图 x = self.conv1(x) # 第二步:卷积后的特征图经过展平层flatten,转成一维数组 # 输入格式:[batch, 26, 26, 32] → 二维特征图(26x26)+32个特征图 # 输出格式:[batch, 21632] → 一维数组(计算逻辑:26×26×32 = 21632,把所有特征值排成一列) x = self.flatten(x) # 第三步:一维特征经过全连接层d1,做特征融合计算 # 输入格式:[batch, 21632] → 展平后的一维特征 # 输出格式:[batch, 128] → 128个神经元的计算结果(提炼核心特征) x = self.d1(x) # 第四步:最终经过输出层d2,输出10个类别的概率 # 输入格式:[batch, 128] → d1层的128个核心特征 # 输出格式:[batch, 10] → 10个值(每个值是对应类别的概率,比如第3个值最大就是预测为类别3) return self.d2(x) -
卷积层:就像人眼先看到线条和轮廓,计算机也需要先提取这些基础特征
-
展平层:因为全连接层只能处理一维数据,需要这个 "转换器"
-
全连接层:把提取到的特征进行组合,发现更复杂的模式(比如 "圆形 + 竖线" 可能是数字 9)
-
输出层:给出每个数字的概率,概率最大的就是模型的预测结果
python
# 兼容Python2和Python3的语法(比如print函数、编码格式),现在Python3可省略,但保留不影响
from __future__ import absolute_import, division, print_function, unicode_literals
# 导入TensorFlow库(核心深度学习框架)
import tensorflow as tf
# 从model.py文件中导入我们之前定义的自定义CNN模型MyModel(就是那个含卷积层、全连接层的模型)
from model import MyModel
# 定义主函数:程序入口(运行脚本时会自动执行main())
def main():
# 加载MNIST数据集:TensorFlow自带的手写数字数据集(6万张训练图,1万张测试图)
mnist = tf.keras.datasets.mnist
# 1. 下载并加载数据集
# mnist.load_data():自动下载(首次运行)并拆分数据为"训练集"和"测试集"
# x_train:训练集图像(60000张,每张28x28像素),y_train:训练集标签(60000个,0-9的数字)
# x_test:测试集图像(10000张,每张28x28像素),y_test:测试集标签(10000个,0-9的数字)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据归一化:把图像像素值从0-255(灰度图范围)缩放到0-1之间
# 原因:神经网络对0-1区间的数值更敏感,训练更快、效果更好
x_train, x_test = x_train / 255.0, x_test / 255.0
# 2. 给图像添加"通道维度"
# 之前自定义的MyModel要求输入格式是 [batch, 28, 28, 1](最后一维是通道数)
# 而mnist.load_data()加载的图像格式是 [28,28](无通道数),所以用tf.newaxis添加最后一维
# 最终x_train格式:[60000, 28, 28, 1],x_test格式:[10000, 28, 28, 1]
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
# 3. 创建数据生成器(方便批量训练和打乱数据)
# tf.data.Dataset.from_tensor_slices:把图像和标签配对,生成数据集
# shuffle(10000):每次训练前打乱10000个样本(避免模型"死记硬背",提高泛化能力)
# batch(32):每次训练取32个样本一起计算(批量计算更快,还能稳定训练过程)
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(32)
# 测试集不需要打乱,只需要批量处理
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
# 4. 初始化我们自定义的CNN模型(就是之前写的MyModel类)
model = MyModel()
# 5. 定义损失函数(衡量模型预测值和真实值的差距)
# SparseCategoricalCrossentropy:适用于"标签是整数"的分类任务(比如y_train是0-9的数字)
# 对比:如果标签是one-hot编码(比如[0,1,0]表示类别1),就用CategoricalCrossentropy
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
# 6. 定义优化器(更新模型参数,减小损失)
# Adam:目前最常用的优化器,自动调整学习率,训练稳定且快
optimizer = tf.keras.optimizers.Adam()
# 7. 定义训练过程的"监控指标"(实时看训练效果)
# Mean:计算平均损失(比如一批32个样本的平均损失)
train_loss = tf.keras.metrics.Mean(name='train_loss')
# SparseCategoricalAccuracy:计算训练准确率(预测对的样本数/总样本数)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
# 8. 定义测试过程的"监控指标"(看模型在新数据上的效果)
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
# 9. 定义训练步骤(单个批次的训练逻辑)
# @tf.function:把函数编译成TensorFlow图模式,训练速度更快(不用每次都重新构建计算图)
def train_step(images, labels):
# tf.GradientTape:"梯度磁带",记录计算过程,方便后续求导(反向传播的核心)
with tf.GradientTape() as tape:
# 模型预测:把批次图像输入模型,得到预测结果(每个样本10个类别概率)
predictions = model(images)
# 计算损失:用损失函数对比预测结果和真实标签的差距
loss = loss_object(labels, predictions)
# 求梯度:根据损失,计算模型所有可训练参数(权重、偏置)的梯度(导数)
gradients = tape.gradient(loss, model.trainable_variables)
# 优化器更新参数:用梯度调整参数,减小损失(梯度下降的核心步骤)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 更新监控指标:把当前批次的损失和准确率加入统计
train_loss(loss)
train_accuracy(labels, predictions)
# 10. 定义测试步骤(单个批次的测试逻辑)
@tf.function # 同样编译成图模式,测试更快
def test_step(images, labels):
# 模型预测(测试时不记录梯度,节省资源)
predictions = model(images)
# 计算测试损失
t_loss = loss_object(labels, predictions)
# 更新测试指标
test_loss(t_loss)
test_accuracy(labels, predictions)
# 11. 定义训练轮数(EPOCHS:把所有训练数据完整过一遍叫1个epoch)
EPOCHS = 5 # 5轮足够,再多可能过拟合(训练集准确率高,测试集准确率下降)
# 12. 开始训练循环(每轮训练+测试)
for epoch in range(EPOCHS):
# 重置指标:每轮开始前清空上一轮的损失和准确率(避免累计)
train_loss.reset_state() # 清空训练损失记录
train_accuracy.reset_state() # 清空训练准确率记录
test_loss.reset_state() # 清空测试损失记录
test_accuracy.reset_state() # 清空测试准确率记录
# 遍历训练集的所有批次:逐个批次训练
for images, labels in train_ds:
train_step(images, labels) # 执行单个批次的训练
# 遍历测试集的所有批次:逐个批次测试(不更新模型参数)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels) # 执行单个批次的测试
# 打印每轮的训练/测试结果
# template:字符串模板,用format填充数值
template = 'Epoch {}, 训练损失: {}, 训练准确率: {:.2f}%, 测试损失: {}, 测试准确率: {:.2f}%'
print(template.format(
epoch + 1, # 轮数从1开始(默认从0计数,+1更直观)
train_loss.result(), # 本轮平均训练损失
train_accuracy.result() * 100, # 训练准确率(×100转成百分比)
test_loss.result(), # 本轮平均测试损失
test_accuracy.result() * 100 # 测试准确率(×100转成百分比)
))
# 程序入口:如果直接运行这个脚本,就执行main()函数
if __name__ == '__main__':
main()# 兼容Python2和Python3的语法(比如print函数、编码格式),现在Python3可省略,但保留不影响
from __future__ import absolute_import, division, print_function, unicode_literals
# 导入TensorFlow库(核心深度学习框架)
import tensorflow as tf
# 从model.py文件中导入我们之前定义的自定义CNN模型MyModel(就是那个含卷积层、全连接层的模型)
from model import MyModel
# 定义主函数:程序入口(运行脚本时会自动执行main())
def main():
# 加载MNIST数据集:TensorFlow自带的手写数字数据集(6万张训练图,1万张测试图)
mnist = tf.keras.datasets.mnist
# 1. 下载并加载数据集
# mnist.load_data():自动下载(首次运行)并拆分数据为"训练集"和"测试集"
# x_train:训练集图像(60000张,每张28x28像素),y_train:训练集标签(60000个,0-9的数字)
# x_test:测试集图像(10000张,每张28x28像素),y_test:测试集标签(10000个,0-9的数字)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据归一化:把图像像素值从0-255(灰度图范围)缩放到0-1之间
# 原因:神经网络对0-1区间的数值更敏感,训练更快、效果更好
x_train, x_test = x_train / 255.0, x_test / 255.0
# 2. 给图像添加"通道维度"
# 之前自定义的MyModel要求输入格式是 [batch, 28, 28, 1](最后一维是通道数)
# 而mnist.load_data()加载的图像格式是 [28,28](无通道数),所以用tf.newaxis添加最后一维
# 最终x_train格式:[60000, 28, 28, 1],x_test格式:[10000, 28, 28, 1]
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
# 3. 创建数据生成器(方便批量训练和打乱数据)
# tf.data.Dataset.from_tensor_slices:把图像和标签配对,生成数据集
# shuffle(10000):每次训练前打乱10000个样本(避免模型"死记硬背",提高泛化能力)
# batch(32):每次训练取32个样本一起计算(批量计算更快,还能稳定训练过程)
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(32)
# 测试集不需要打乱,只需要批量处理
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
# 4. 初始化我们自定义的CNN模型(就是之前写的MyModel类)
model = MyModel()
# 5. 定义损失函数(衡量模型预测值和真实值的差距)
# SparseCategoricalCrossentropy:适用于"标签是整数"的分类任务(比如y_train是0-9的数字)
# 对比:如果标签是one-hot编码(比如[0,1,0]表示类别1),就用CategoricalCrossentropy
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
# 6. 定义优化器(更新模型参数,减小损失)
# Adam:目前最常用的优化器,自动调整学习率,训练稳定且快
optimizer = tf.keras.optimizers.Adam()
# 7. 定义训练过程的"监控指标"(实时看训练效果)
# Mean:计算平均损失(比如一批32个样本的平均损失)
train_loss = tf.keras.metrics.Mean(name='train_loss')
# SparseCategoricalAccuracy:计算训练准确率(预测对的样本数/总样本数)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
# 8. 定义测试过程的"监控指标"(看模型在新数据上的效果)
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
# 9. 定义训练步骤(单个批次的训练逻辑)
# @tf.function:把函数编译成TensorFlow图模式,训练速度更快(不用每次都重新构建计算图)
def train_step(images, labels):
# tf.GradientTape:"梯度磁带",记录计算过程,方便后续求导(反向传播的核心)
with tf.GradientTape() as tape:
# 模型预测:把批次图像输入模型,得到预测结果(每个样本10个类别概率)
predictions = model(images)
# 计算损失:用损失函数对比预测结果和真实标签的差距
loss = loss_object(labels, predictions)
# 求梯度:根据损失,计算模型所有可训练参数(权重、偏置)的梯度(导数)
gradients = tape.gradient(loss, model.trainable_variables)
# 优化器更新参数:用梯度调整参数,减小损失(梯度下降的核心步骤)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 更新监控指标:把当前批次的损失和准确率加入统计
train_loss(loss)
train_accuracy(labels, predictions)
# 10. 定义测试步骤(单个批次的测试逻辑)
@tf.function # 同样编译成图模式,测试更快
def test_step(images, labels):
# 模型预测(测试时不记录梯度,节省资源)
predictions = model(images)
# 计算测试损失
t_loss = loss_object(labels, predictions)
# 更新测试指标
test_loss(t_loss)
test_accuracy(labels, predictions)
# 11. 定义训练轮数(EPOCHS:把所有训练数据完整过一遍叫1个epoch)
EPOCHS = 5 # 5轮足够,再多可能过拟合(训练集准确率高,测试集准确率下降)
# 12. 开始训练循环(每轮训练+测试)
for epoch in range(EPOCHS):
# 重置指标:每轮开始前清空上一轮的损失和准确率(避免累计)
train_loss.reset_state() # 清空训练损失记录
train_accuracy.reset_state() # 清空训练准确率记录
test_loss.reset_state() # 清空测试损失记录
test_accuracy.reset_state() # 清空测试准确率记录
# 遍历训练集的所有批次:逐个批次训练
for images, labels in train_ds:
train_step(images, labels) # 执行单个批次的训练
# 遍历测试集的所有批次:逐个批次测试(不更新模型参数)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels) # 执行单个批次的测试
# 打印每轮的训练/测试结果
# template:字符串模板,用format填充数值
template = 'Epoch {}, 训练损失: {}, 训练准确率: {:.2f}%, 测试损失: {}, 测试准确率: {:.2f}%'
print(template.format(
epoch + 1, # 轮数从1开始(默认从0计数,+1更直观)
train_loss.result(), # 本轮平均训练损失
train_accuracy.result() * 100, # 训练准确率(×100转成百分比)
test_loss.result(), # 本轮平均测试损失
test_accuracy.result() * 100 # 测试准确率(×100转成百分比)
))
# 程序入口:如果直接运行这个脚本,就执行main()函数
if __name__ == '__main__':
main()训练过程讲解
-
数据准备:
- 加载数据后进行归一化(0-255→0-1),这是神经网络的常见操作
- 添加通道维度,让数据格式符合模型要求
-
核心训练逻辑:
- 每轮训练:用训练集更新模型参数,然后用测试集评估效果
- 梯度下降:通过计算损失的梯度,不断调整模型参数,让预测越来越准
- 批量训练:每次用 32 张图片一起训练,既高效又稳定
-
训练结果 :运行后会看到类似这样的输出:
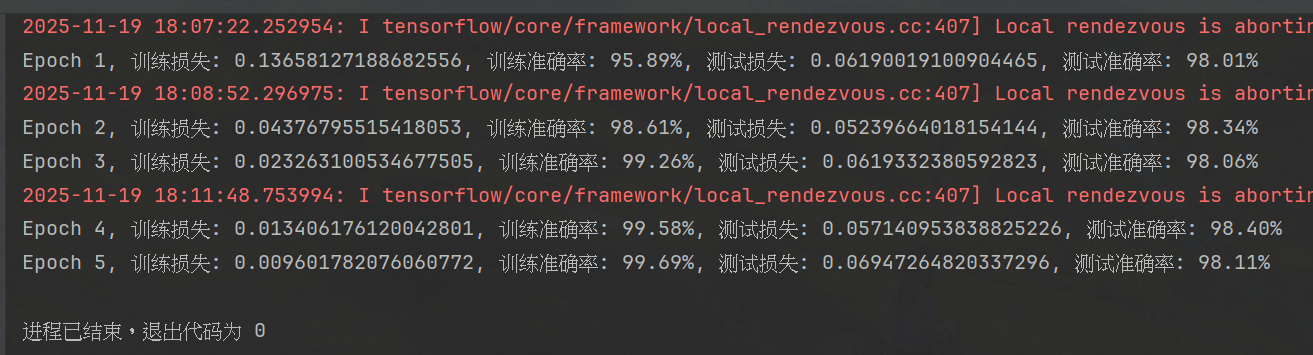
简单来说,卷积层就像一系列 "特征探测器",会逐步学习到数字的关键特征:
- 第一层可能学到识别边缘和线条
- 后续层会组合这些边缘,学习到更复杂的形状(比如圆圈、拐角)
- 最后通过全连接层判断这些形状组合起来是哪个数字