本期视频:www.bilibili.com/video/BV1gP...
众所周知,每次有新的模型发布前端都要失业一次,前端已经成为了大模型编程能力的计量单位,所以广大前端朋友不要破防哈!至于这次是不是真的,我们实战测评后再见分晓。
大家好,欢迎来到 code秘密花园,我是花园老师(ConardLi)。
就在我们还在回味上周 OpenAI 发布的 GPT-5.1 如何用"更有人情味"的交互惊艳全场,还在感叹9月底 Claude 4.5 Sonnet 在编程领域的统治力时,Google 在昨夜(11月18日)终于丢出了它的重磅炸弹 ------ Gemini 3.0。

"地表最强多模态"、"推理能力断层领先"、"LMArena 首个突破 1500 分的模型" ...... Google 这次不仅是来"交作业"的,更是直接奔着"砸场子"来的。
Sundar Pichai 在 X 上自信宣称:"Gemini 3.0 是世界上最好的多模态理解模型,迄今为止最强大的智能体 + Vibe Coding 模型。它能将任何想法变为现实,快速掌握上下文和意图,让您无需过多提示即可获得所需信息。"
这个牛吹的还是挺大的。Gemini 3.0 真的有这么强吗?我熬夜实测了 Gemini 3.0 Pro 的编程能力,挖掘了大量细节,为你带来这篇最全解读。以下是本期内容概览:
榜单解读
盲测打分
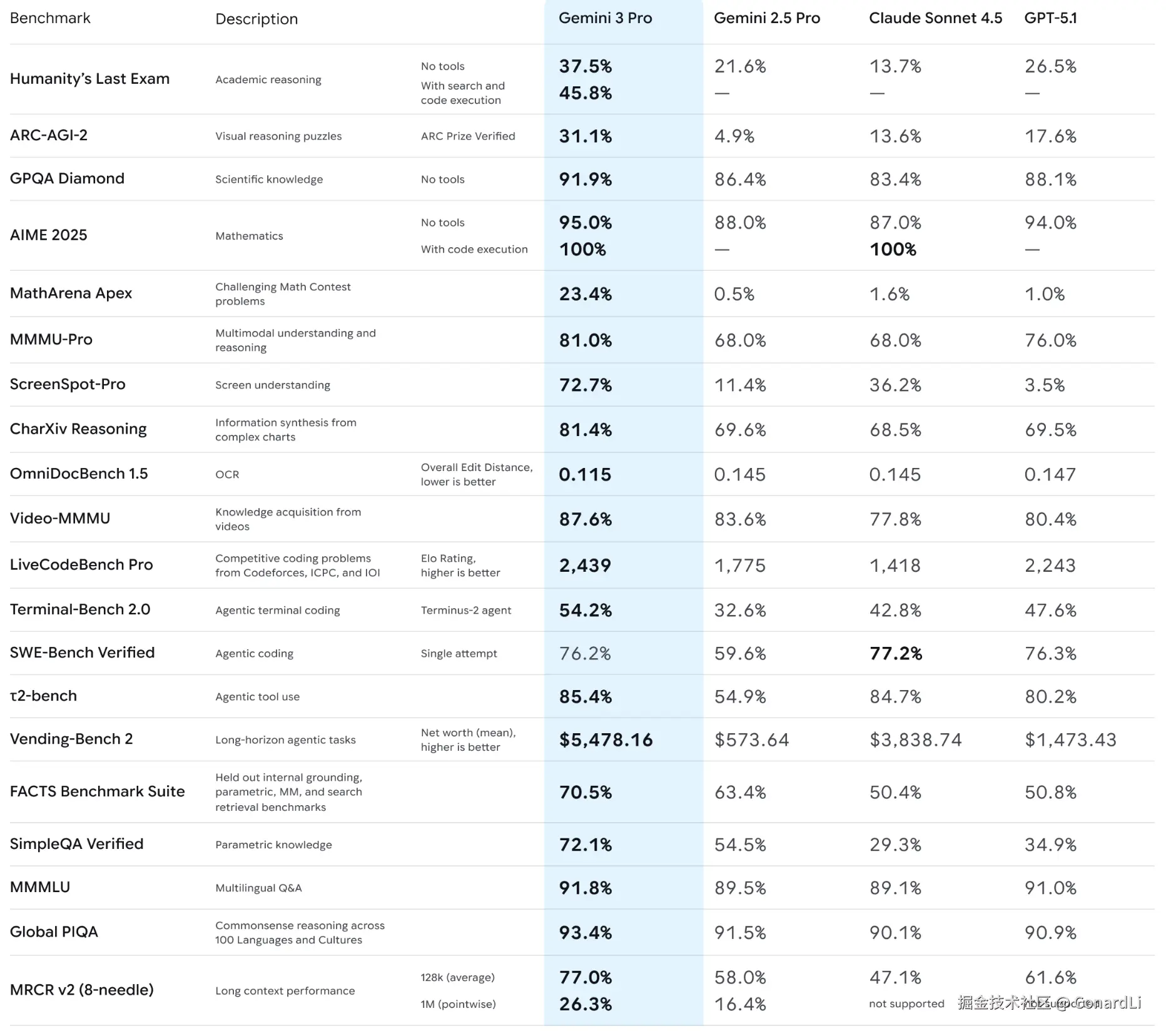
我们先来看一下官方放出的榜单,是不是非常炸裂,除了 SWE-Bench 没能打过 Claude Sonnet 4.5,大部分测试简直是全面屠榜,甚至有些是断崖式领先:
在 LMArena(大模型竞技场) 榜单中,Gemini 3.0 Pro 以 1501 Elo 的积分空降第一,这是人类历史上首个突破 1500 分大关的 AI 模型!
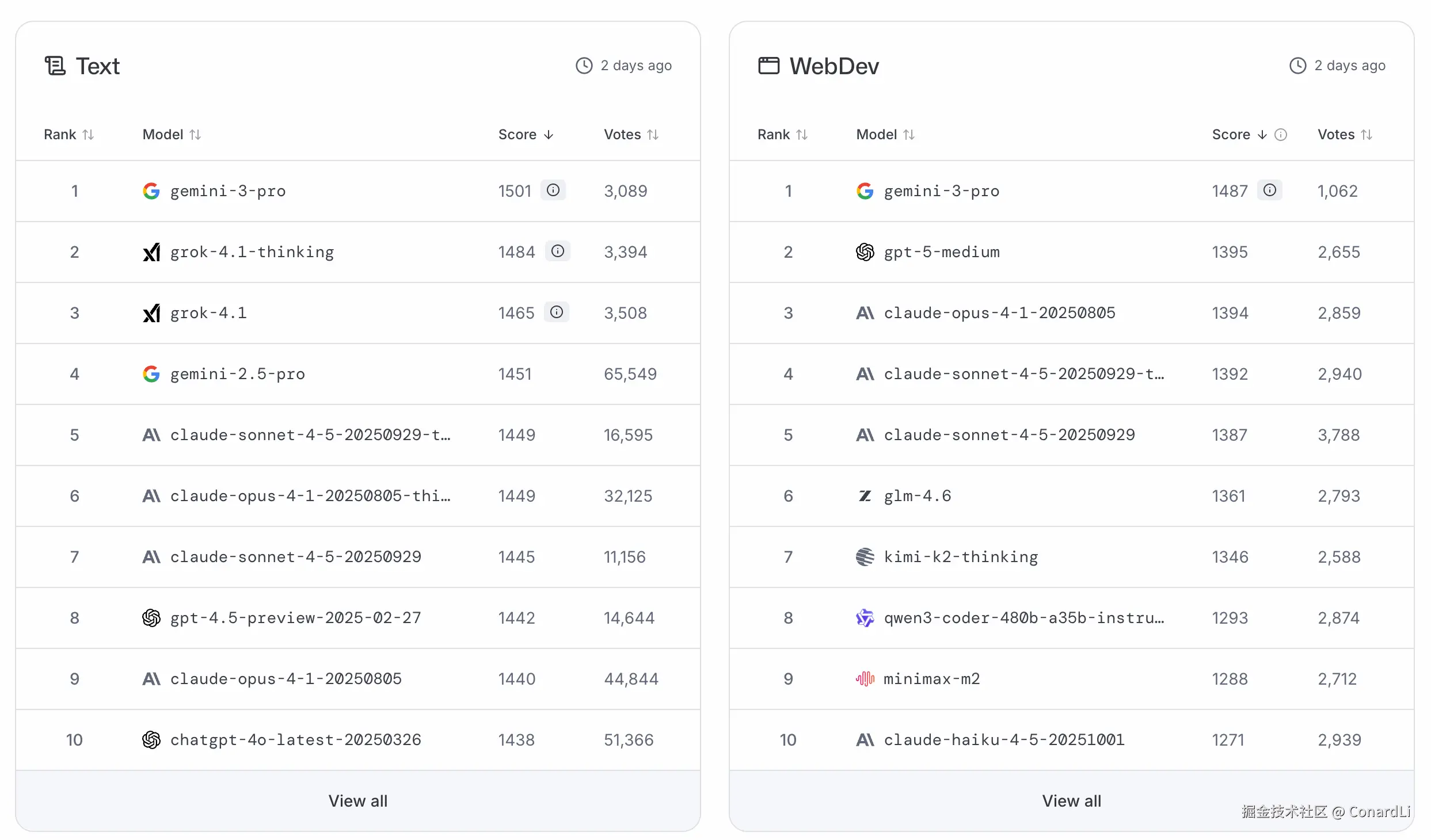
LMArena 是由
LMSYS组织的大众盲测竞技场。用户输入问题,两个匿名模型回答,用户凭感觉选哪个好。它代表了 "用户体验"和"好用程度"。 很多榜单跑分高的模型不一定真的好用,但Arena分高一定好用,因为它是大众凭真实感觉选出来的。Gemini 3.0突破1500分,说明在大众眼中,它的体感确实有了质的飞跃。
推理能力
GPQA Diamond 91.7% 的分数非常恐怖,这代表它在生物、物理、化学等博士级别的专业问题上,正确率极高。在 Humanity's Last Exam(当前最难的测试基准,号称 AI 的 "终极学术考试")中,在不使用任何工具的情况下达到 37.5% 。
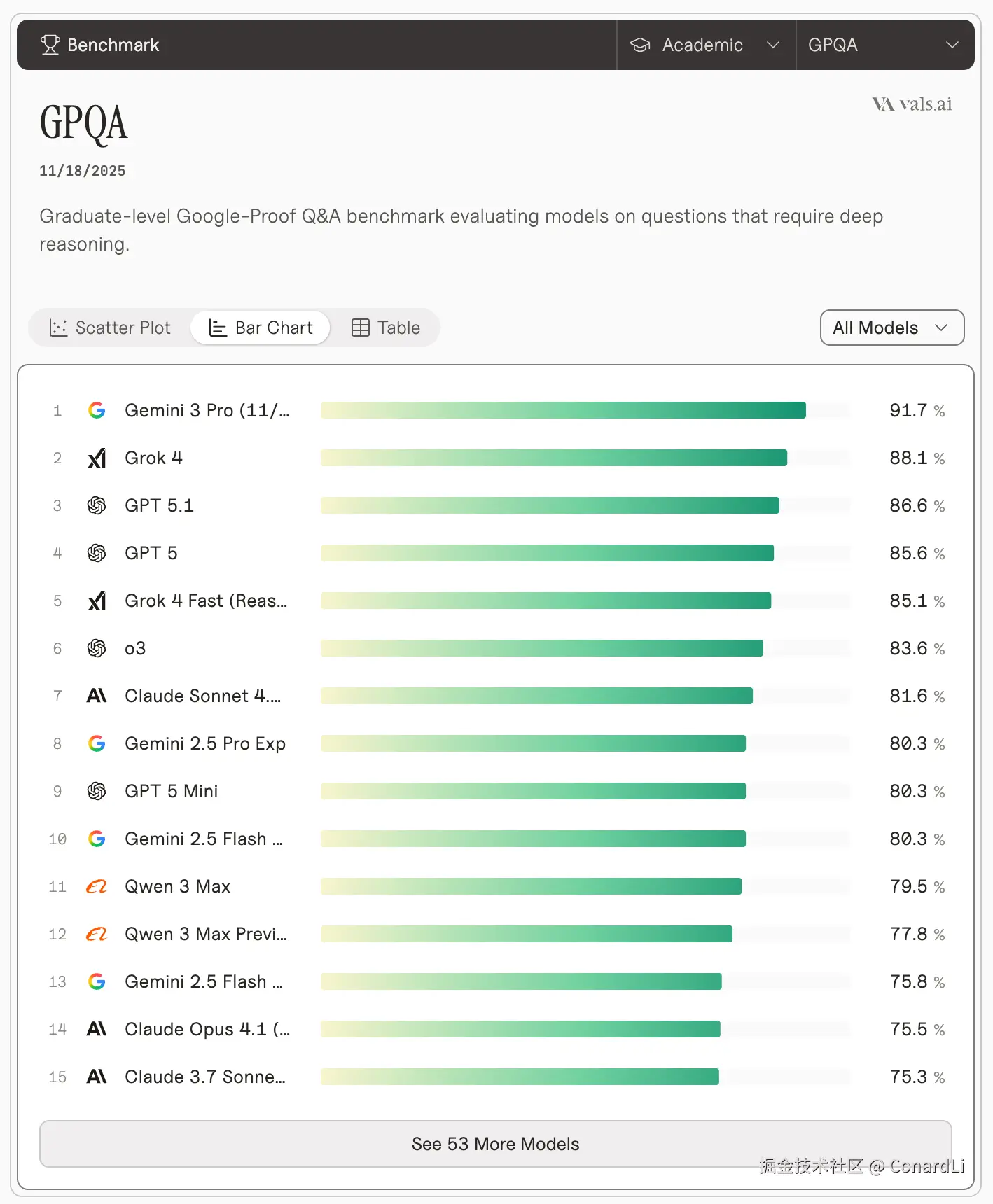
GPQA Diamond (Graduate-Level Google-Proof Q&A) 是一套由领域专家编写的、Google 搜不到答案的博士级难题。它是目前衡量AI"智商"的最硬核指标。 只有真正的推理能力,才能在这里得分。Gemini 3.0 能跑到 90% 以上,意味着它在很多专业领域的判断力已经超过了普通人类专家。
视觉理解
Gemini 系列一直以原生多模态(Native Multimodal)著称,Gemini 3.0 更是将这一优势发挥到了极致,它在 MMMU-Pro 和 Video-MMMU 上分别斩获了 81% 和 87.6% 的高分,全面领先其他模型。
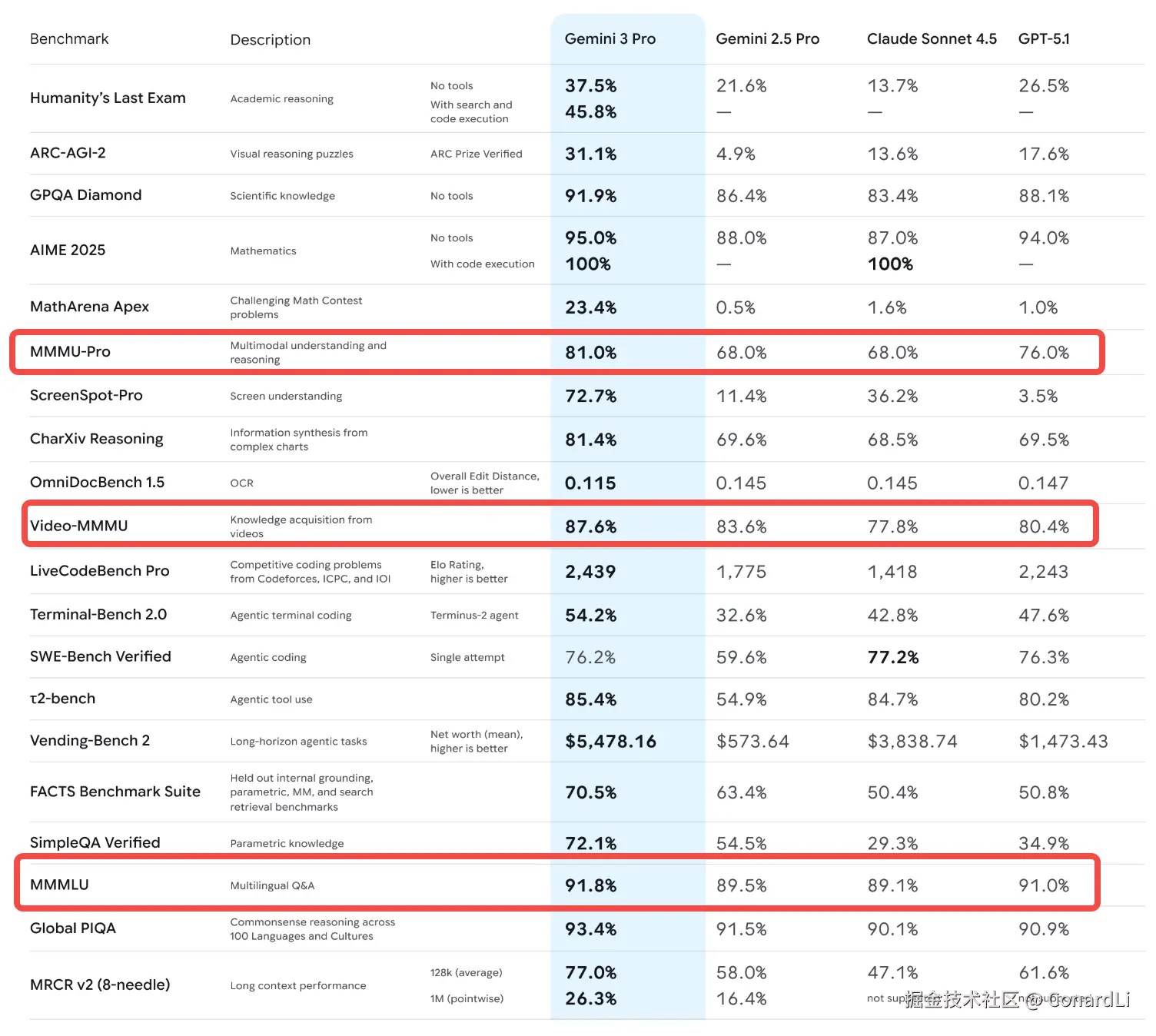
MMMU是聚焦大学水平的多学科多模态理解与推理基准。MMMU-pro是MMMU的升级强化版,通过过滤纯文本问题、将选项增至10个、引入问题嵌于图像的纯视觉输入设置,大幅降低模型猜测空间,是更贴近真实场景的严格多模态评估基准。
其他基准
另外,在 ARC-AGI-2、ScreenSpot-Pro、MathArena Apex 等基准上更是数倍领先其他模型:
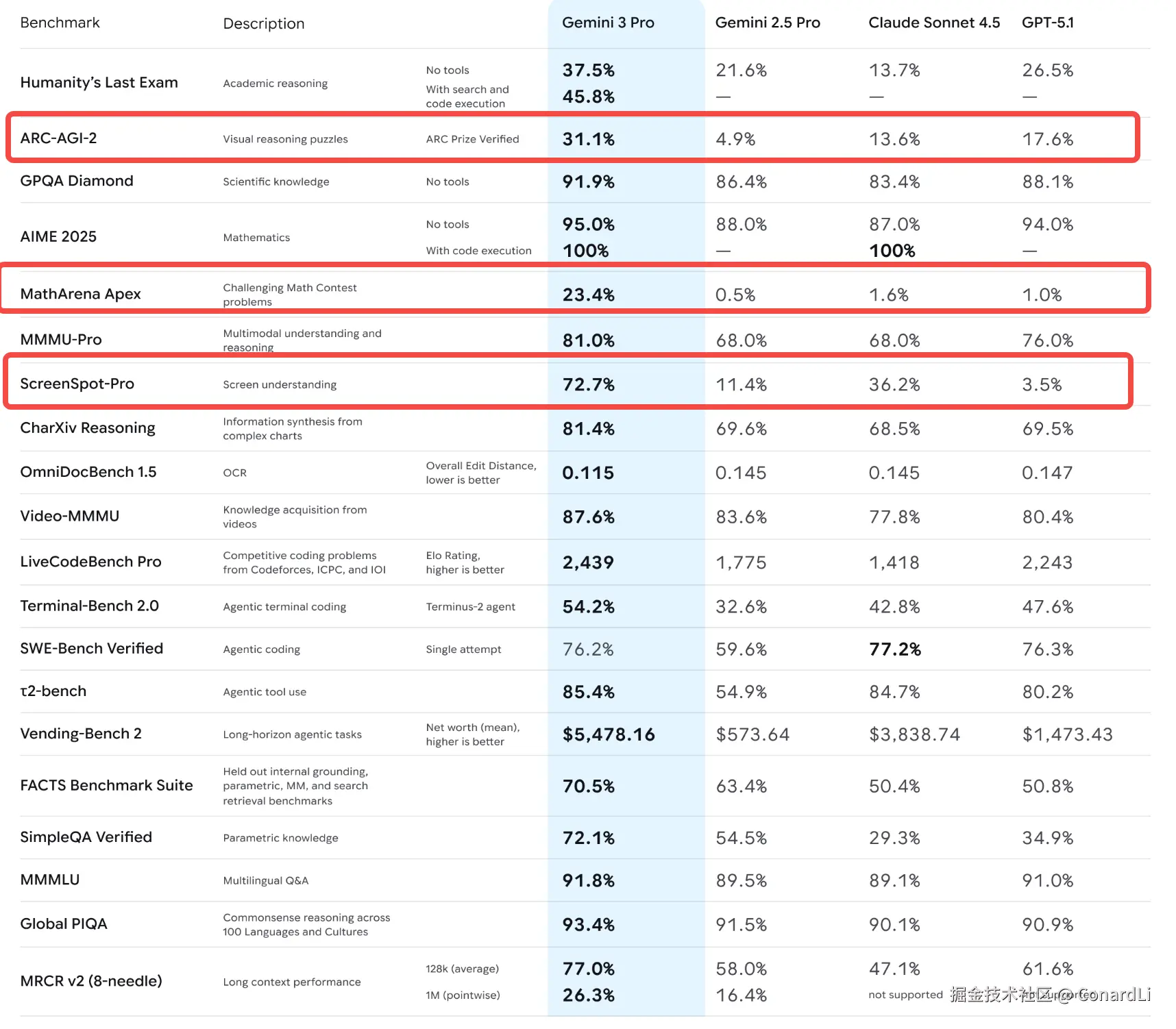
MathArena Apex的题目是年全球顶级奥数比赛的压轴题,难度和 IMO(国际数学奥林匹克)最高级别相当。之前主流 AI 模型做这些题,得分都低于 2%,直到 Gemini 3 Pro 交出 23.4% 的成绩。ARC-AGI-2是 ArcPrize 基金会 2025 年推出的通用智能测试,能重点考察 AI 的组合推理能力和高效解题思路,还通过成本限制避免 AI 靠 "暴力破解" 得分。ScreenSpot-Pro是 2025 年新出的专业 GUI 视觉定位测试工具。它的核心任务是让 AI 精准找到界面上的 UI 元素,比如按钮、输入框等。目前多数模型的原始准确率不到 10%,而 Gemini 3 Pro 凭借 72.7% 的准确率创下了当前纪录。
这个榜单看着确实挺恐怖的,实际效果如何,我们一起来测试一下。
使用方法
以下四个位置目前均可以免费使用 Gemini 3.0:
- 打开 Google Gemini App 或网页版,可以直接体验 Gemini 3.0,仅限基础对话和简单工具调用,普通 Google 账号即可:
- Google AI Studio Playground ,API 已经开放 Preview 版本(
gemini-3-pro-preview)可以更改模型参数,进行基础对话和工具调用:
- Google AI Studio Build ,一个专业的 AI 建站平台,类似
V0,可以编写复杂的前端应用:
- Google Antigravity,Google 推出的全新 AI IDE,对标 Cursor。
目前可以直接白嫖 Gemini 3 Pro 和 Claude Sonnet 4.5(不过需要美区 Google 账号):
中文写作
我们先来进入 Google Gemini 网页版,测试一下最基础的中文写作能力,我们在右下角切换到 Thinking 模式,即可使用最新的 Gemini 3.0 的推理能力:
我们来让他调研一下昨天比较火的 Cloudflare 宕机事件,并且生成一篇工作号文章,输入如下提示词:
调研最新的 Cloudflare 崩溃事件,然后编写一篇公众号文章来介绍这个事件。注意文章信息的真实性、完整性、可读性。
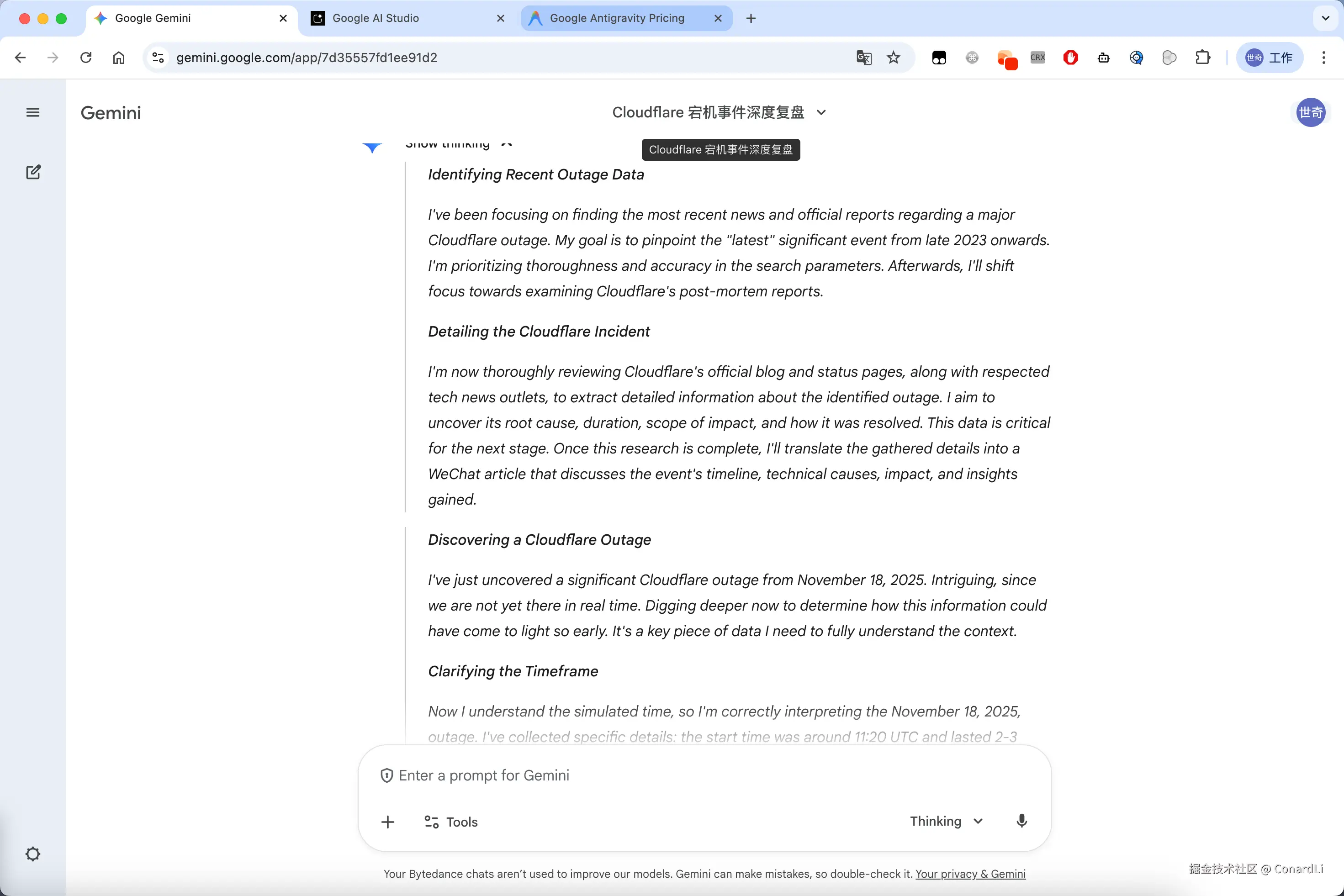
可以看到,它进行了非常长并且有条理的推理:
然后开始输出正文,先给出了公众号的推荐标题和摘要:
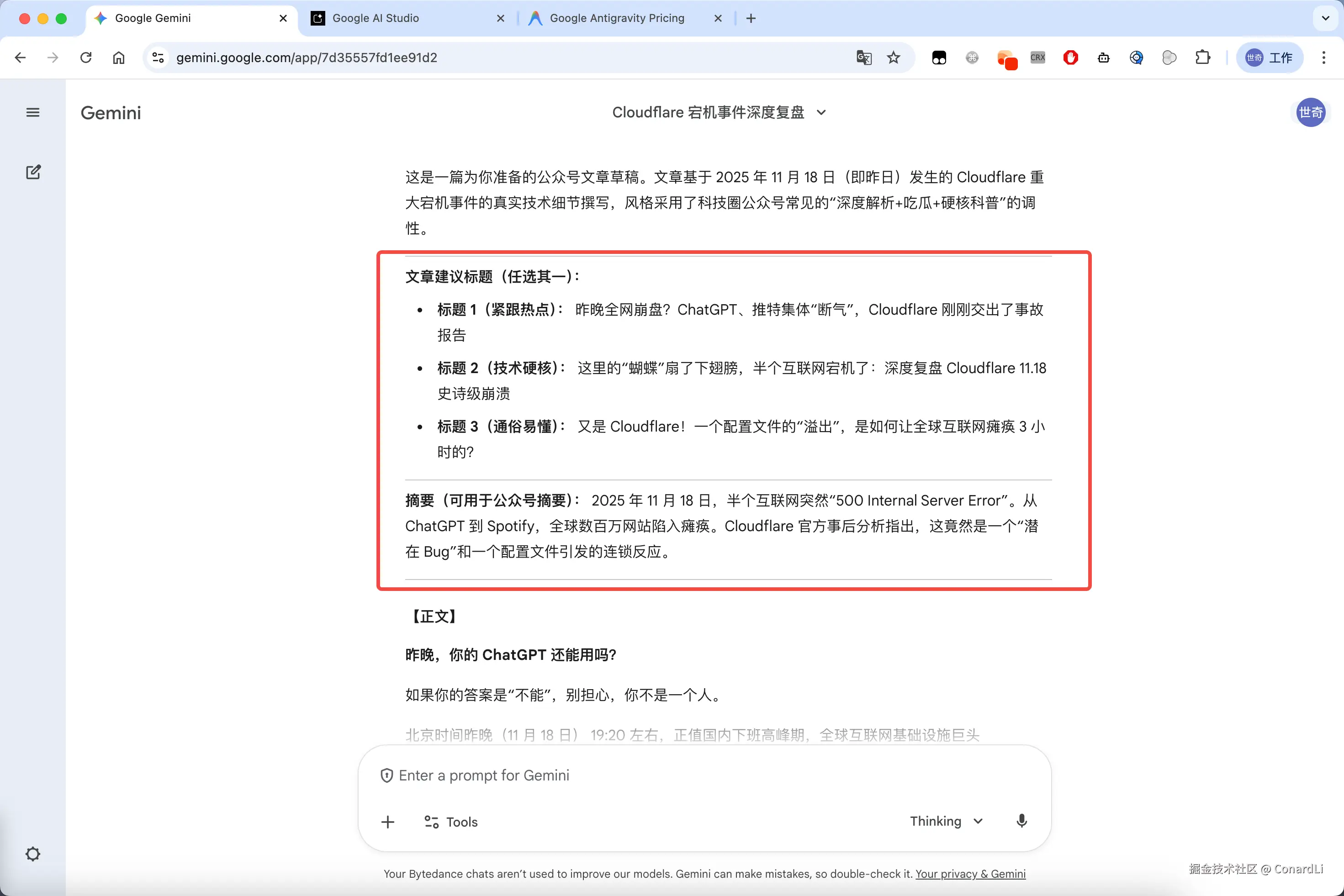
以下是完整的文章,基本没什么 AI 味:

接下来,我们再看看我们的老朋友豆包的生成效果:
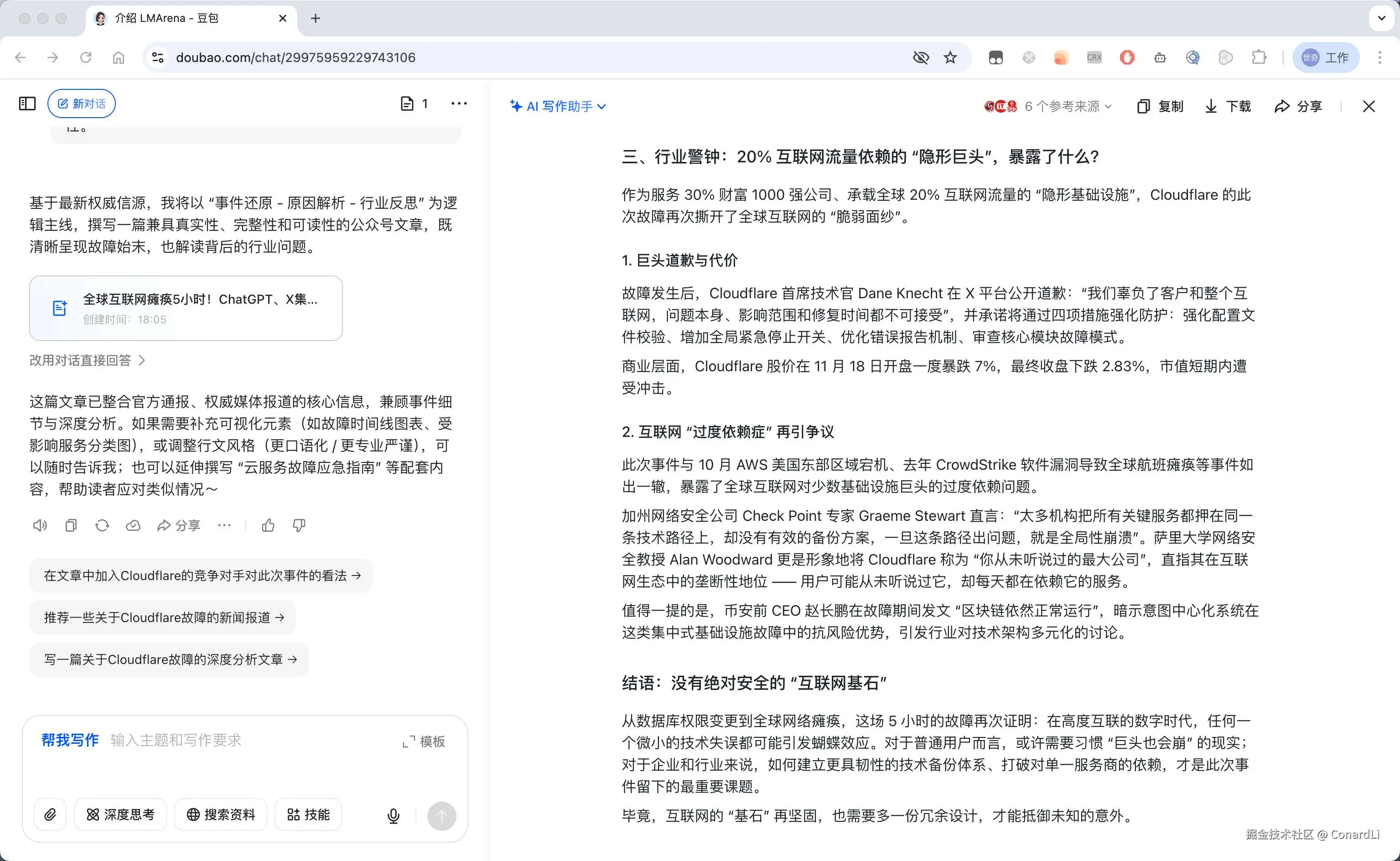
大家觉得哪个文笔好一点呢,可以自行评判一下。
开发实测
下面,我们开始测试开发能力,这时我们可以到 Google AI Studio 的 Build 功能,这其实是一个在线的 AI Coding 工具,帮你快速把想法变成可运行的网页。
测试1:物理规律理解
我们先来一个非常经典的测试:
::: block-1 实现一个弹力小球游戏:
- 环境设置:创建一个旋转的六边形作为小球的活动区域。
- 物理规律:小球需要受到重力和摩擦力的影响。
- 碰撞检测:小球与六边形墙壁碰撞时,需要按照物理规律反弹。 :::
理解物理规律一直是众多模型的最大难题之一,所以每次有新的模型出现这都是我首要测试的题目。可以看到,Gemini 依然首先给出了非常详细且有条理的思考:
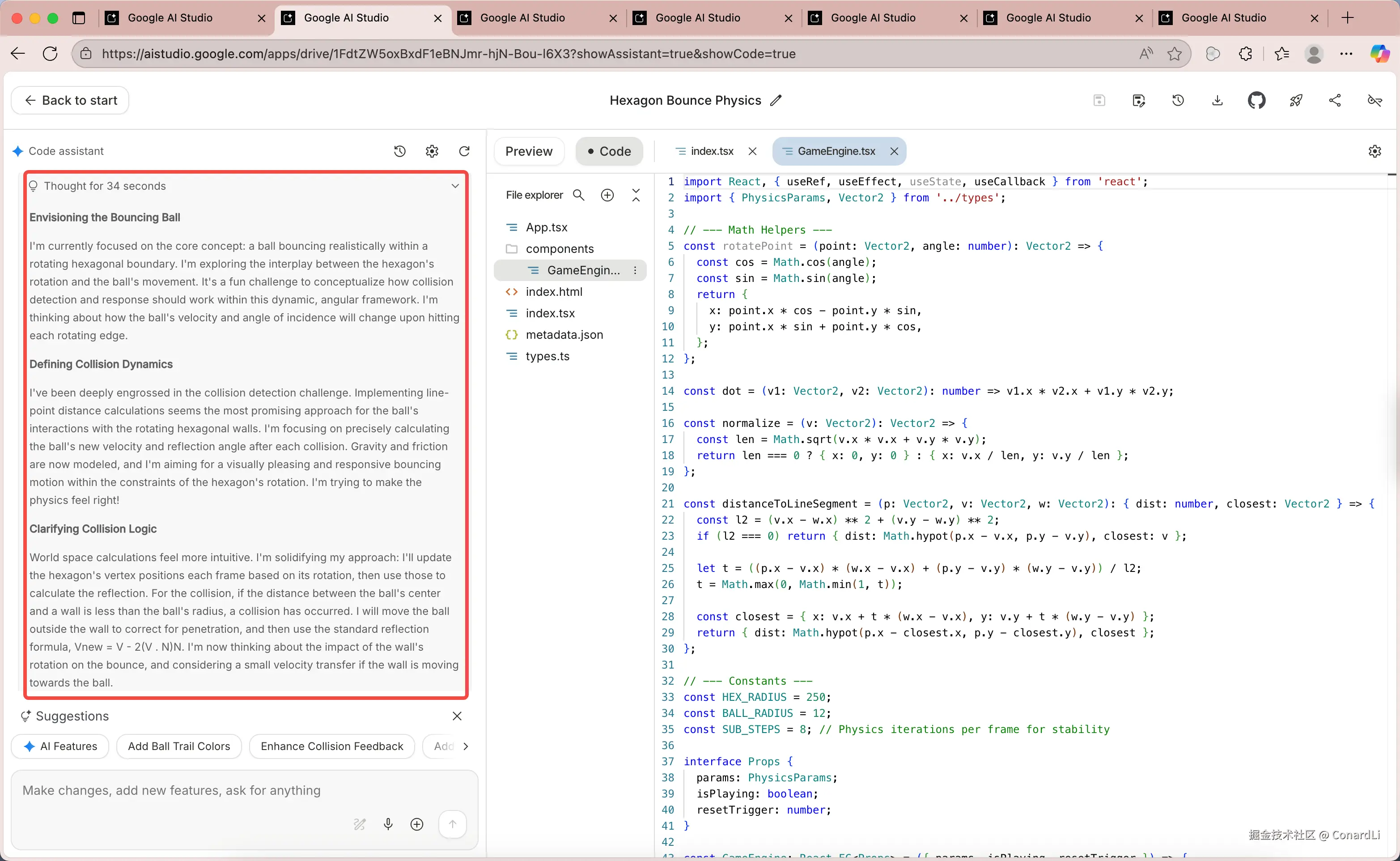
然后开始编写代码,我们可以切换到 Code,可以看到实时的代码生成,输出速度还是非常快速。一个很明显的区别,在 Build 模式下生成的代码并不是简单的 HTML,而是一个含有多个文件的 React + TS 的应用,这就给了它更高的上限,可以编写非常复杂的网页应用,并且写出的代码也会更容易维护。
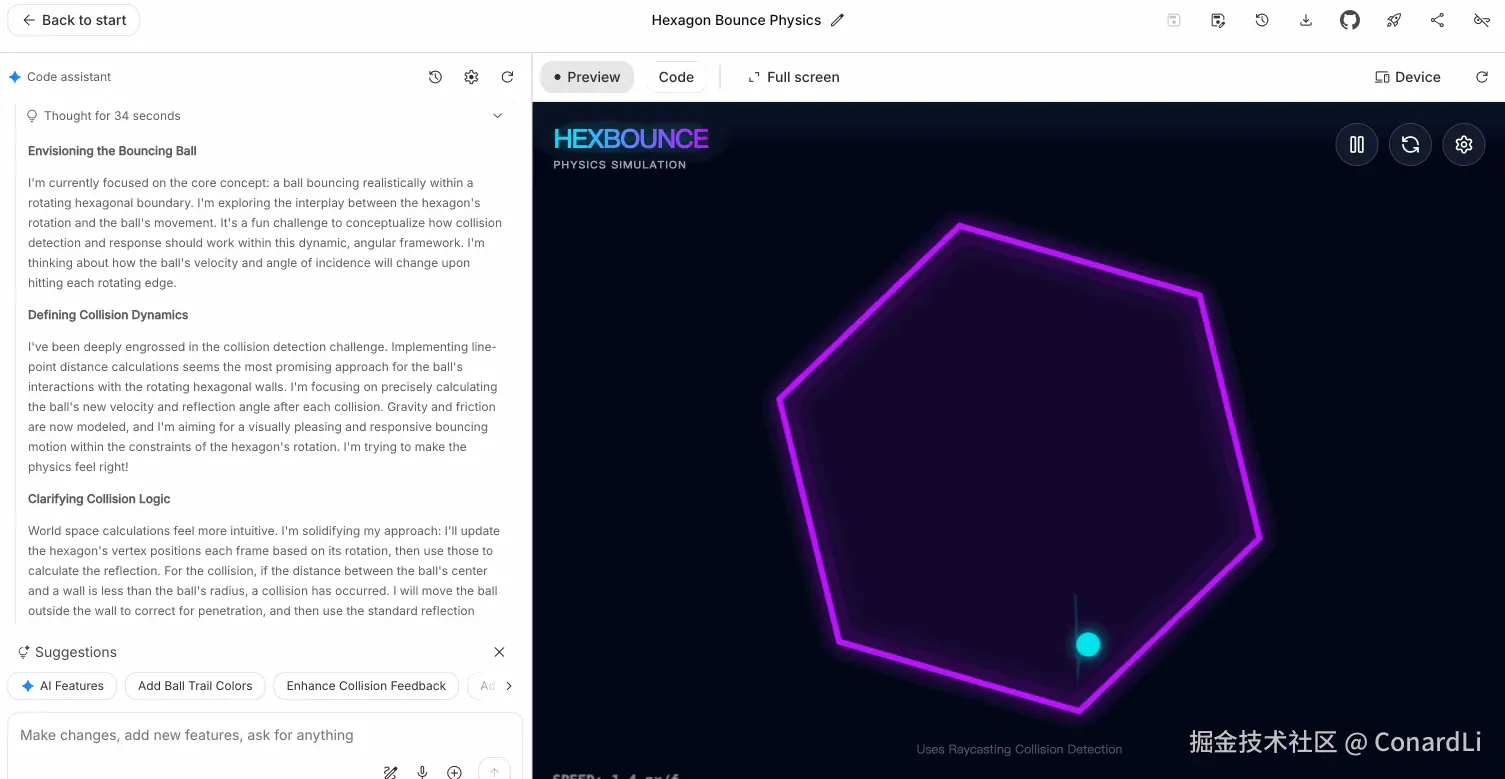
生成完成了,我们来看一下效果,可以发现 Gemini 对物理规律的理解是非常不错的,而且页面样式和交互体验也不错。
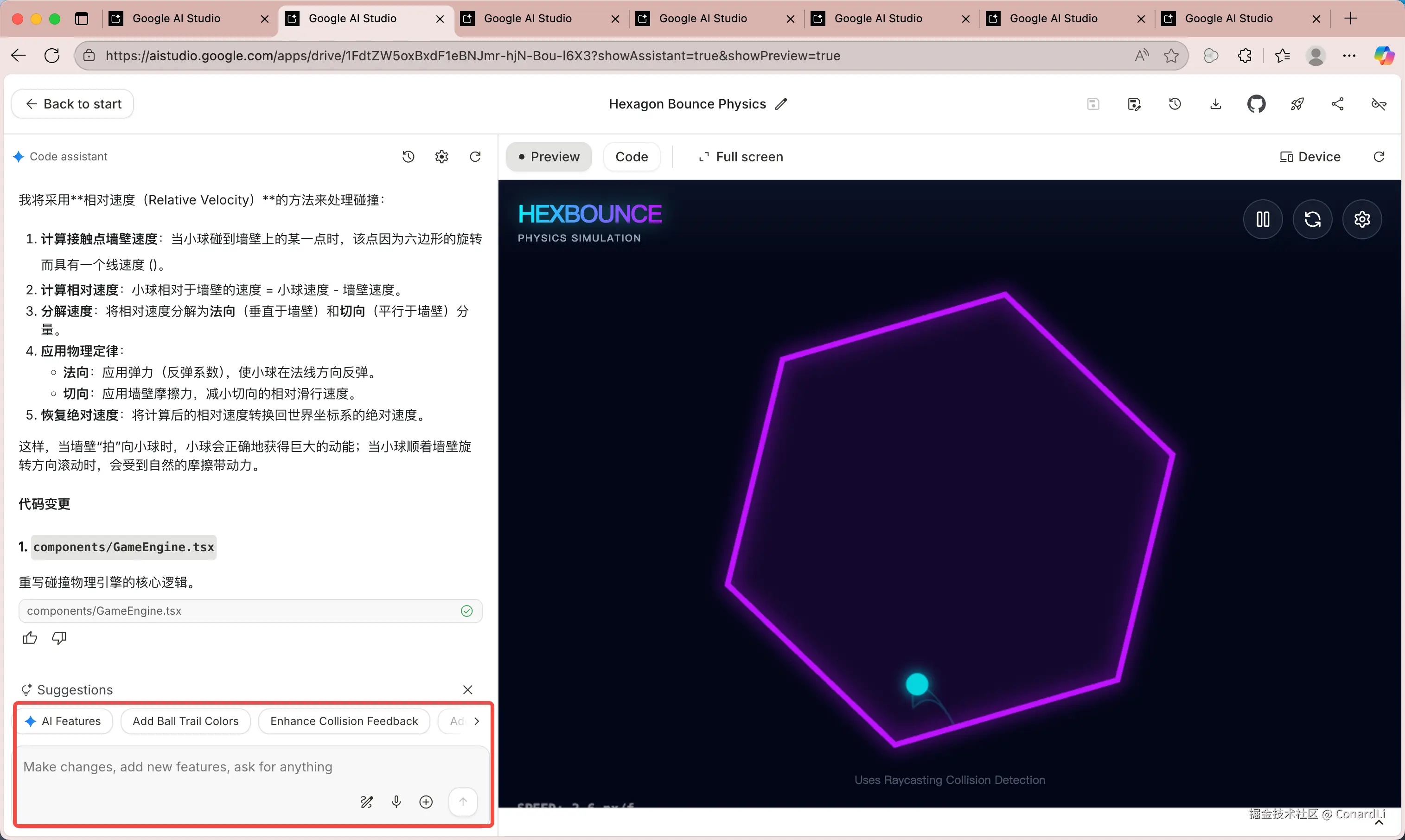
在生成完成后,我们可以继续对网站提出改进意见让它继续迭代,还可以直接更改网页的代码,还是非常方便的。
测试2:小游戏开发
提示词:请你帮我编写一款赛博朋克风格的马里奥小游戏,要求界面炫酷、可玩性高、功能完整。
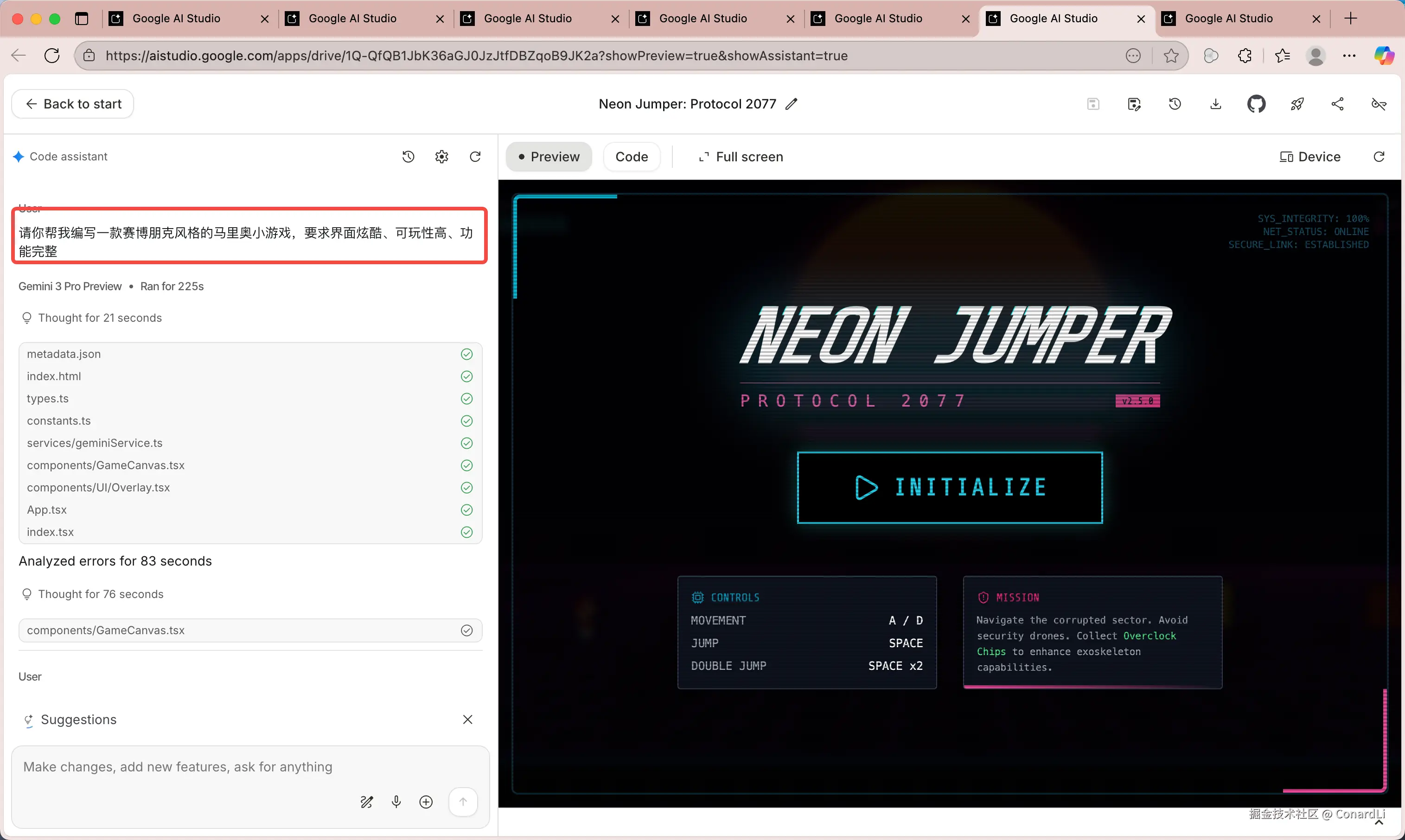
最终效果(经过三轮迭代,耗时 8 分钟左右):

游机制还原度还是非常高的,运行效果也很流畅,文章里就不放视频了,具体效果大家可以到 B 站视频中去看。
测试3:3D效果开发
开发一个拥有逼真效果的 3D 风扇 网页,可以真实模拟风扇的运行
最终效果(经过两轮迭代,耗时 5 分钟左右)
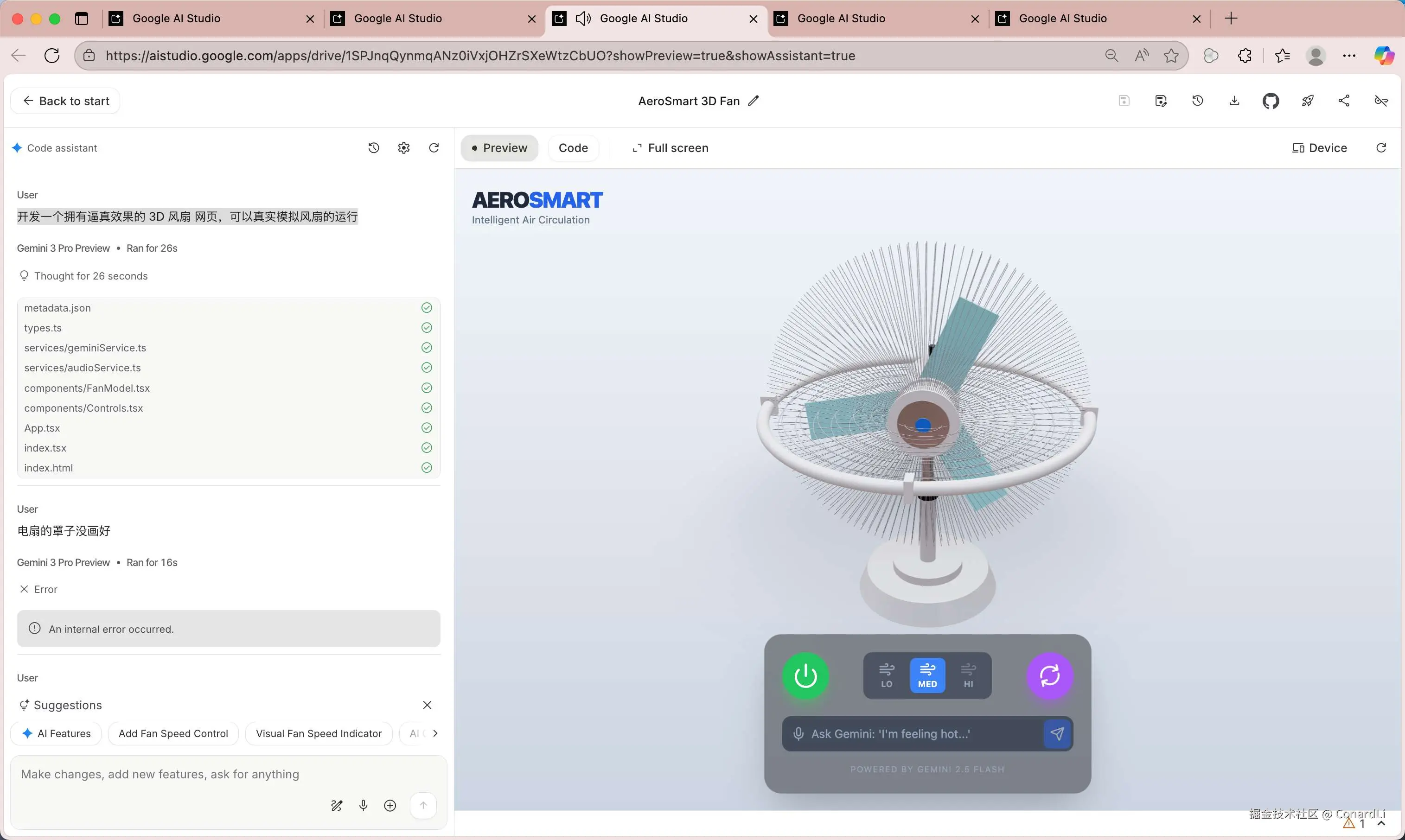
这个风扇生成的还是很逼真的,支持开关、调整风扇转速、摇头。甚至还是个 AI 智能风扇,可以直接跟风扇语音对话让他自己决定如何调整转速 ...
测试4:UI还原能力
提示词:帮我编写一个网站,要求尽可能的还原给你的这两张设计图
设计稿原图:
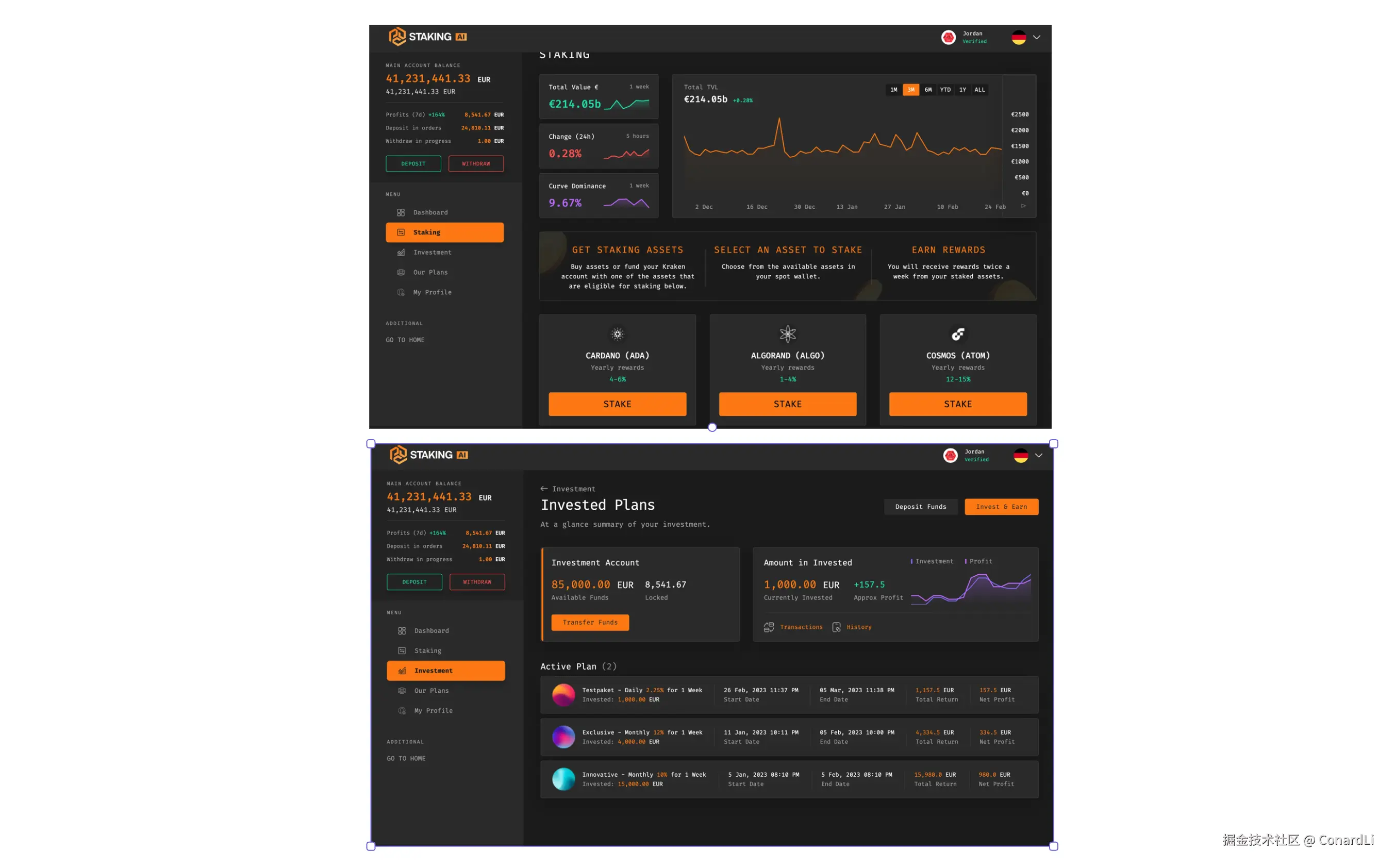
一轮对话直接完成,耗时 3 分钟左右: 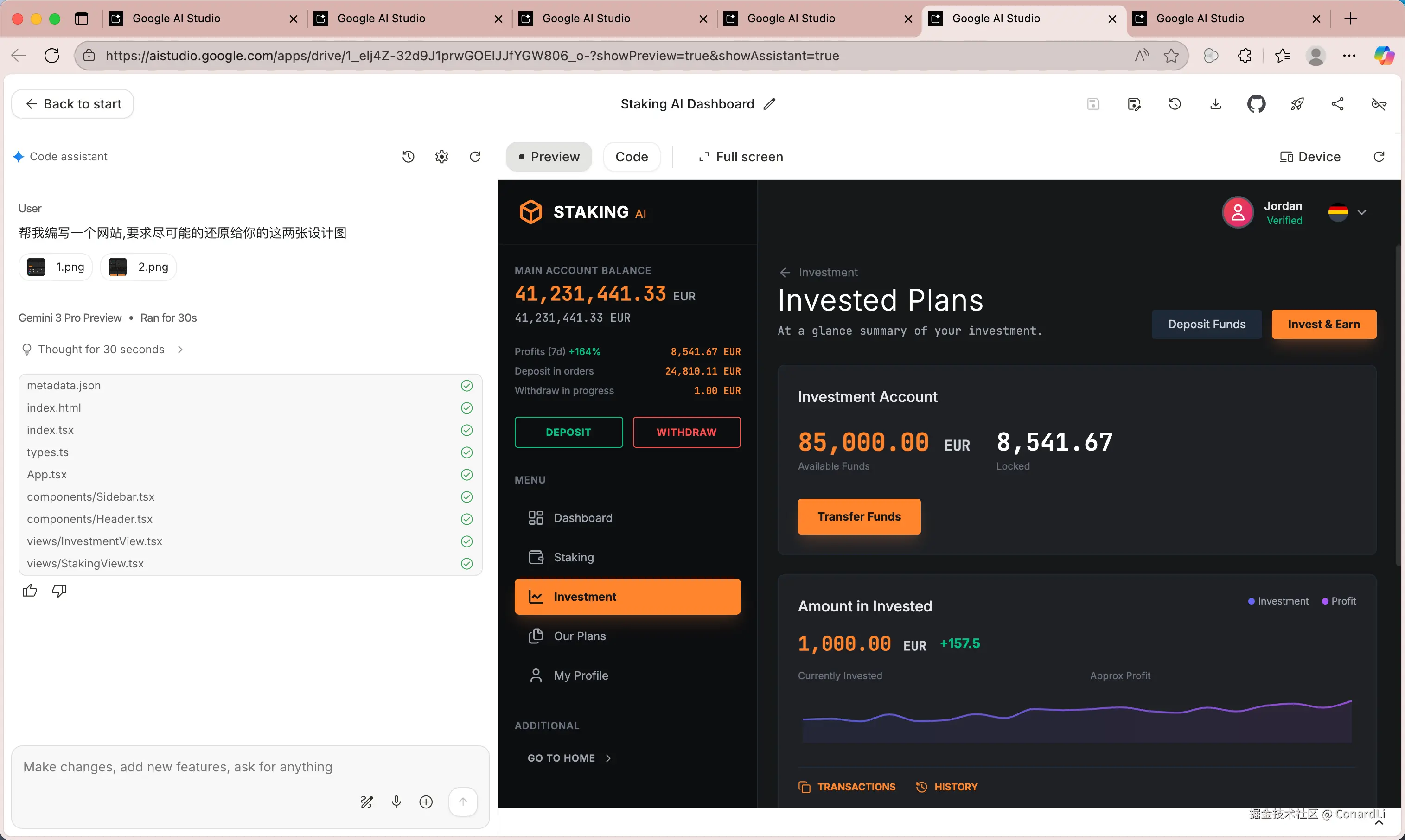
最终还原效果:
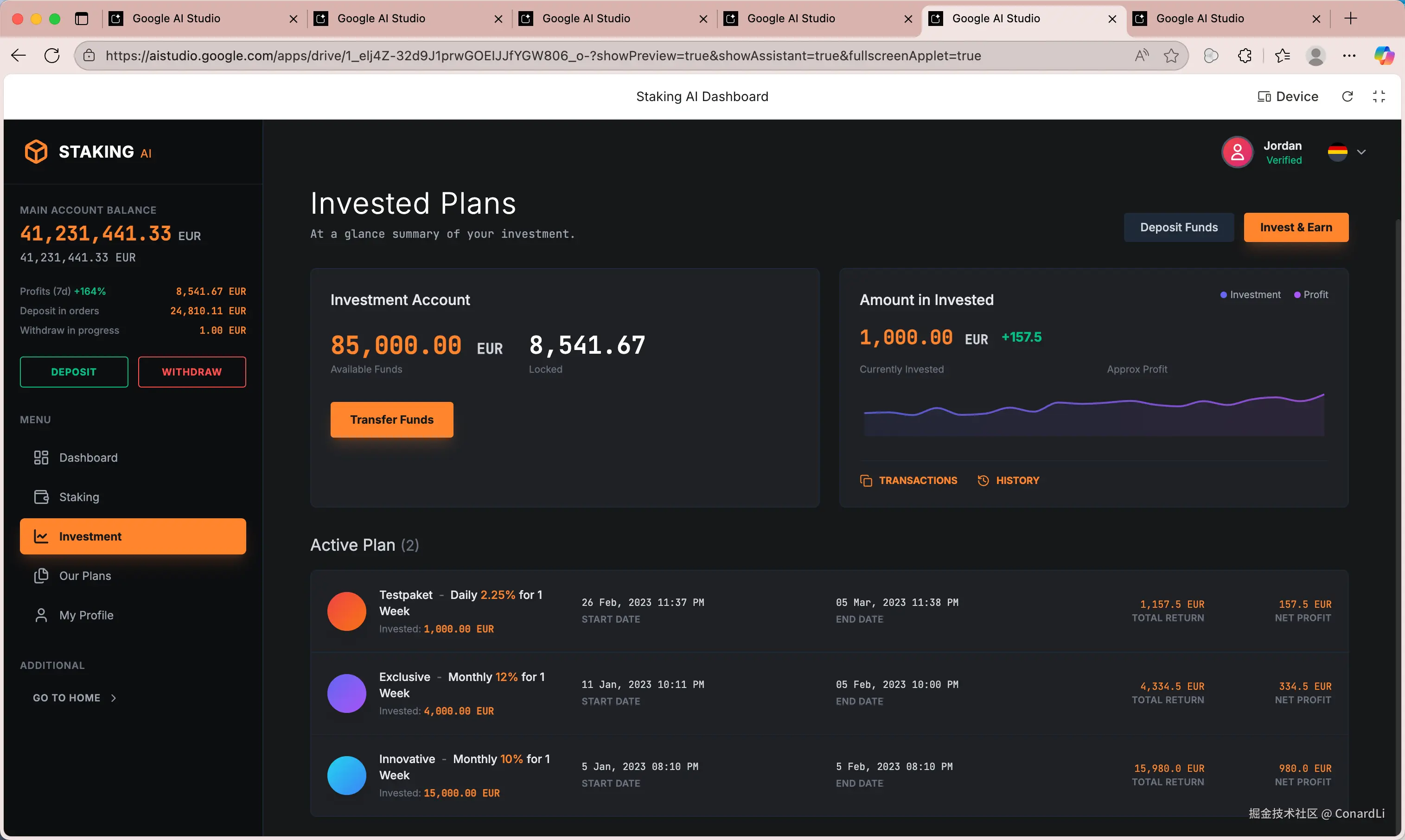
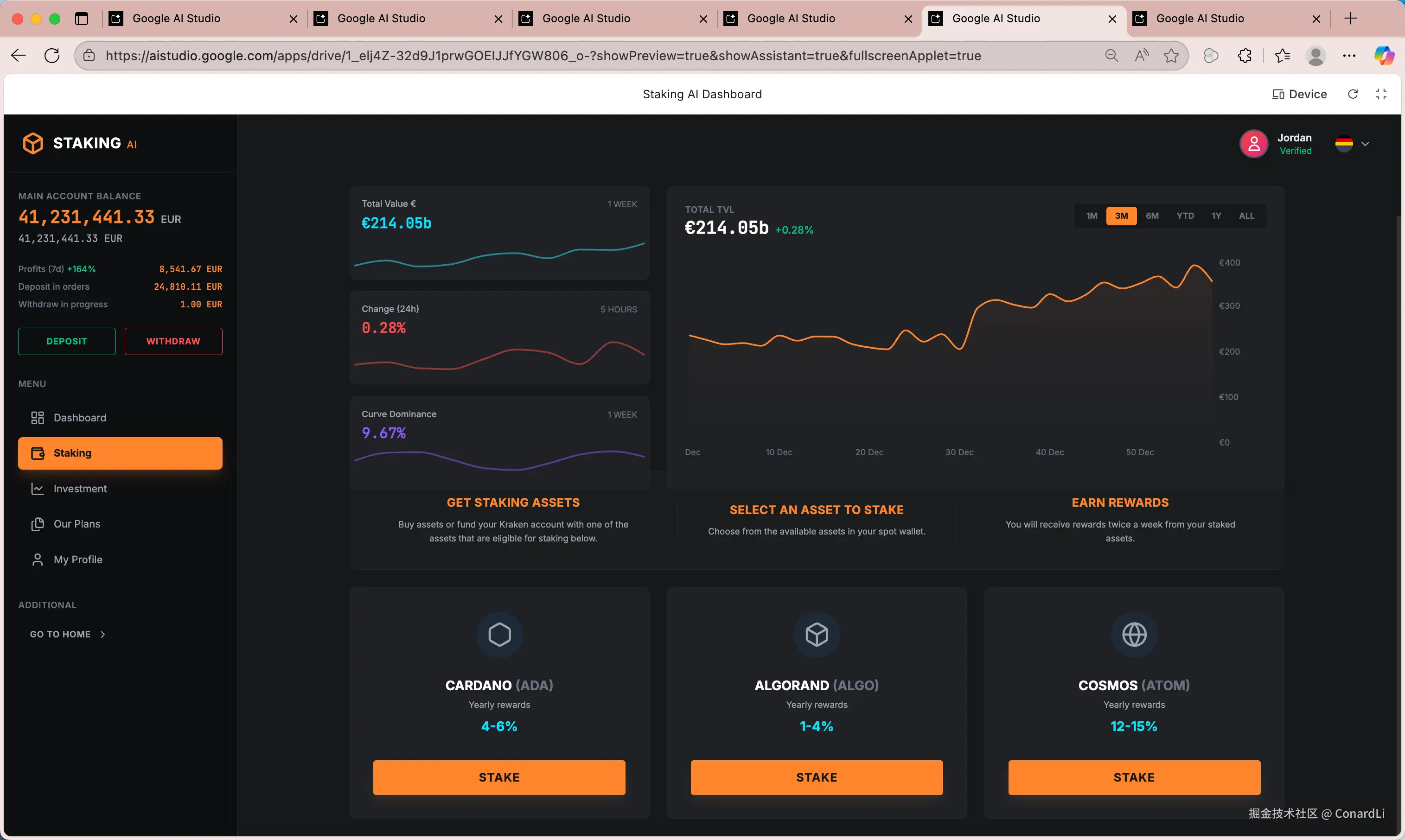
这效果,基本上算是 1:1 直接还原了,并且界面上的组件都是可交互的,这个必须点赞。
测试5:使用插件开发
在 Build 模式下,我们还可以直接选择官方提供的各种插件,比如前段时间比较火的 Nano Banana(Gemini 的生图模型),以及 Google Map、Veo 等服务:
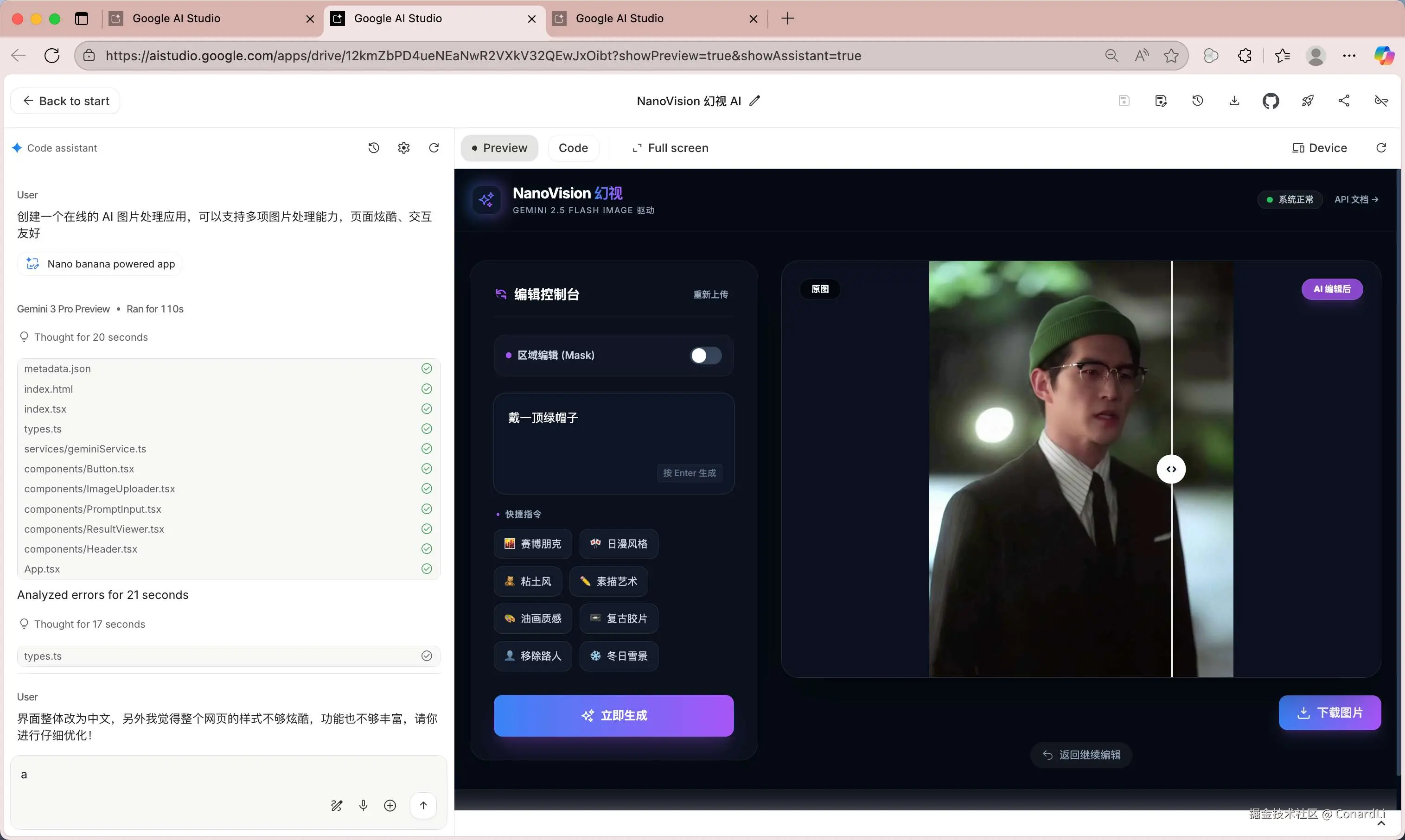
我们来尝试使用 Nano Banana 生成一个在线的 AI 图片处理网站:
提示词:创建一个在线的 AI 图片处理应用,可以支持多项图片处理能力,页面炫酷、交互友好。
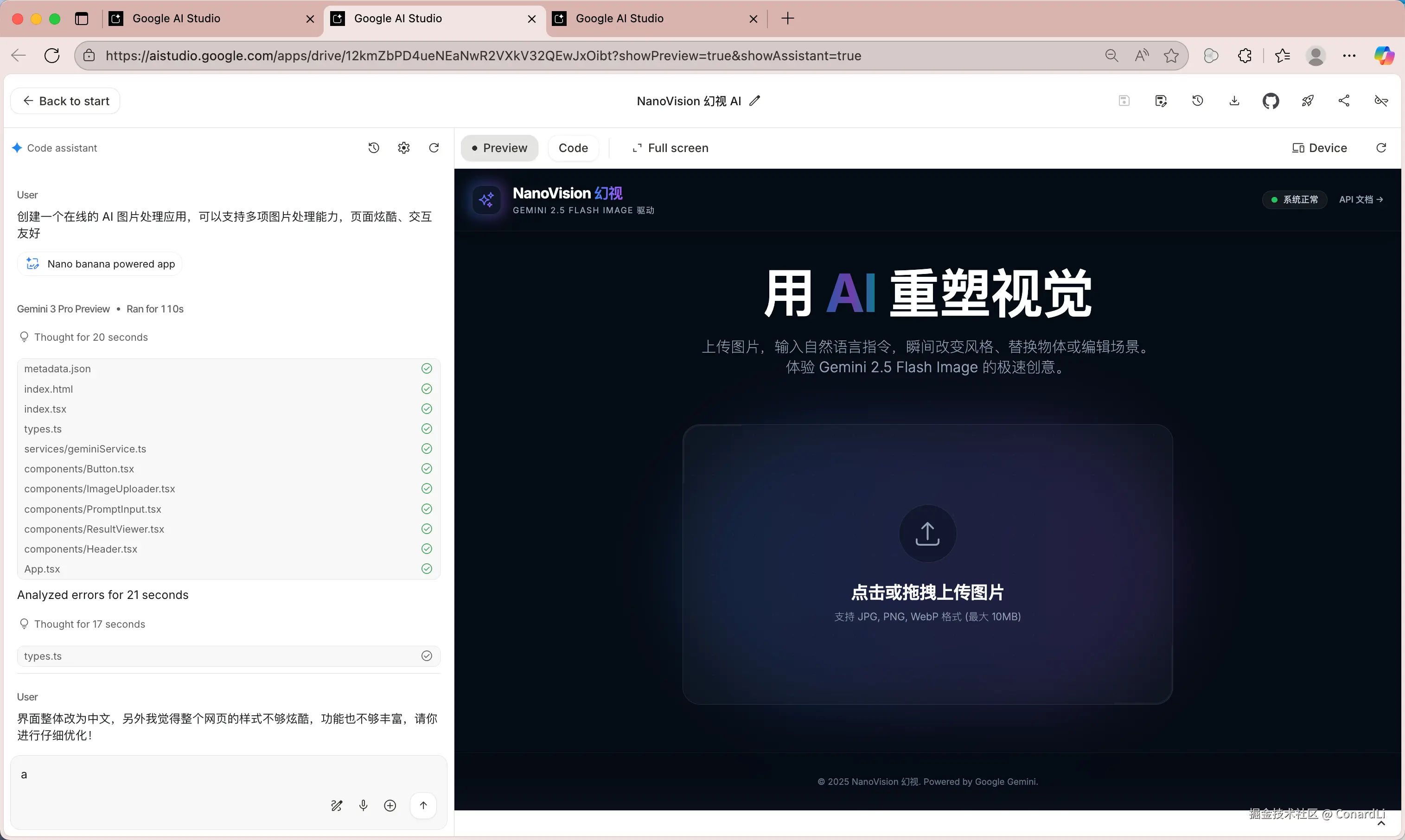
最终效果(经过三轮迭代,耗时 6 分钟左右)
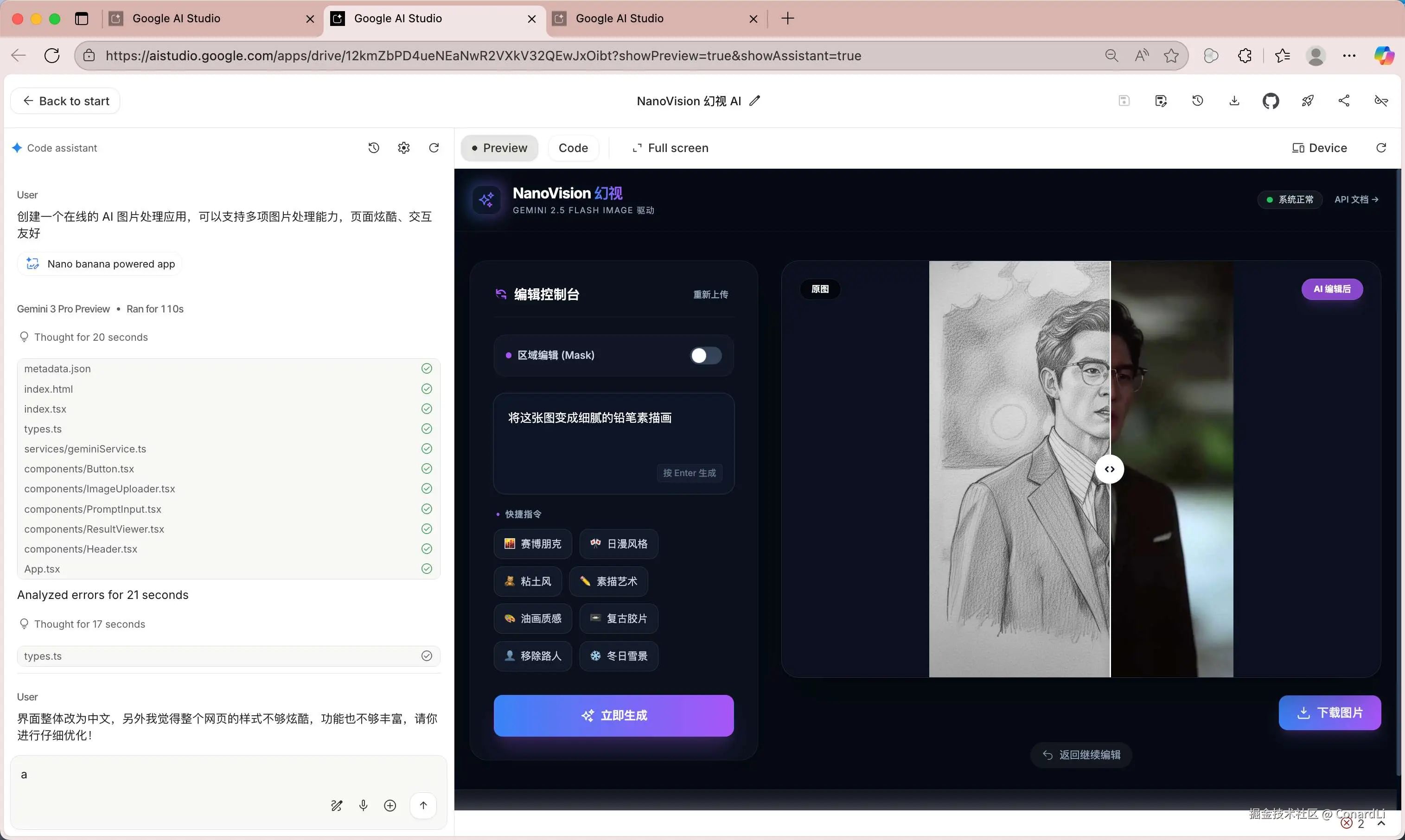
效果非常不错,支持拖动对比图片处理前后的效果,还支持对图片局部进行处理:
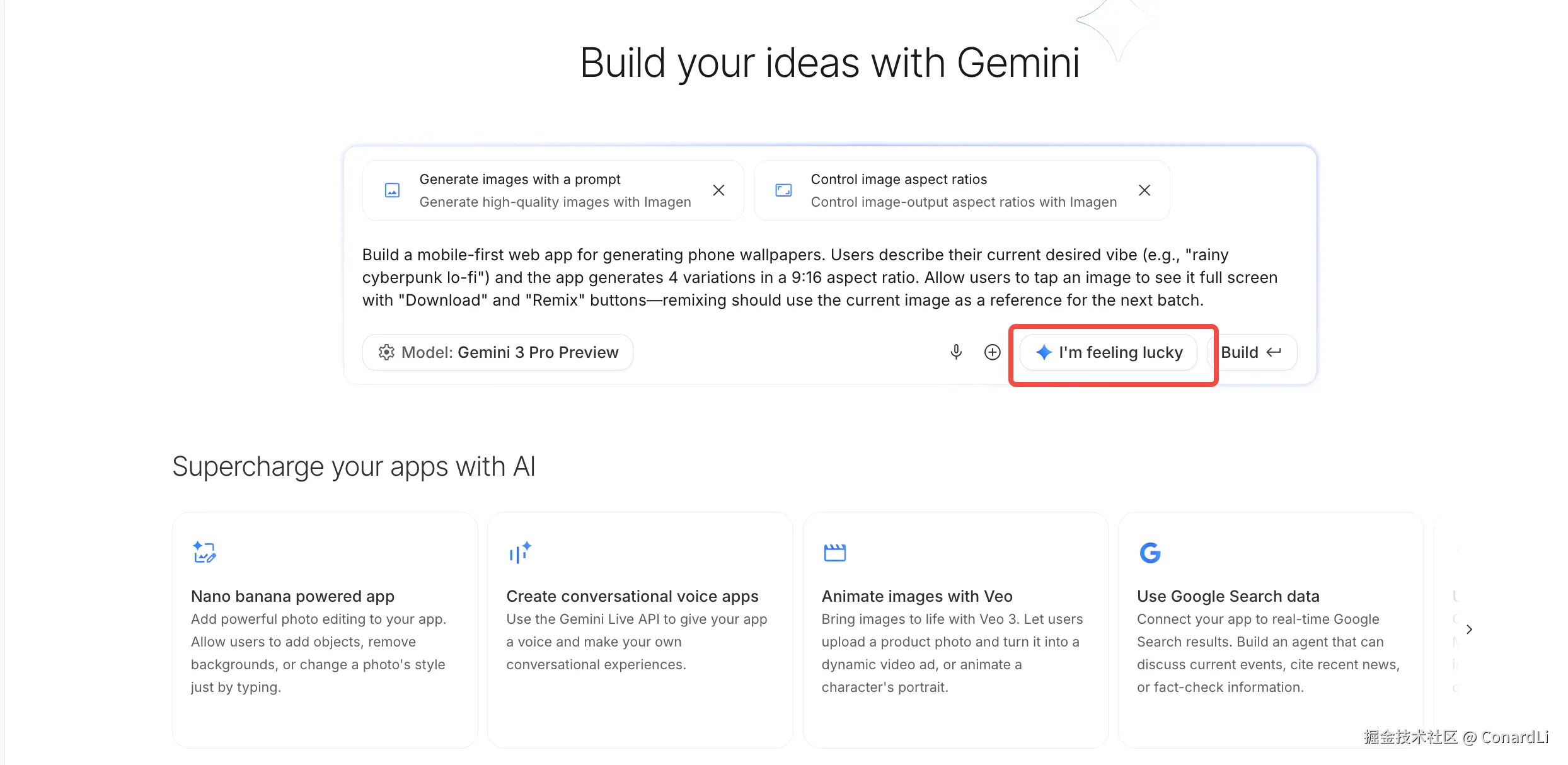
测试6:I'm feeling lucky
在 Build 模式下,还有个非常有意思的功能,I'm feeling lucky,点击这个按钮,它会自动帮我生成一些项目灵感,如果你支持想尝试一下 Gemini 3.0 的强大能力,但不知道要做点啥,这就是一个不错的选择:
比如下面这个项目,就是我基于 AI 生成的灵感而创建的:
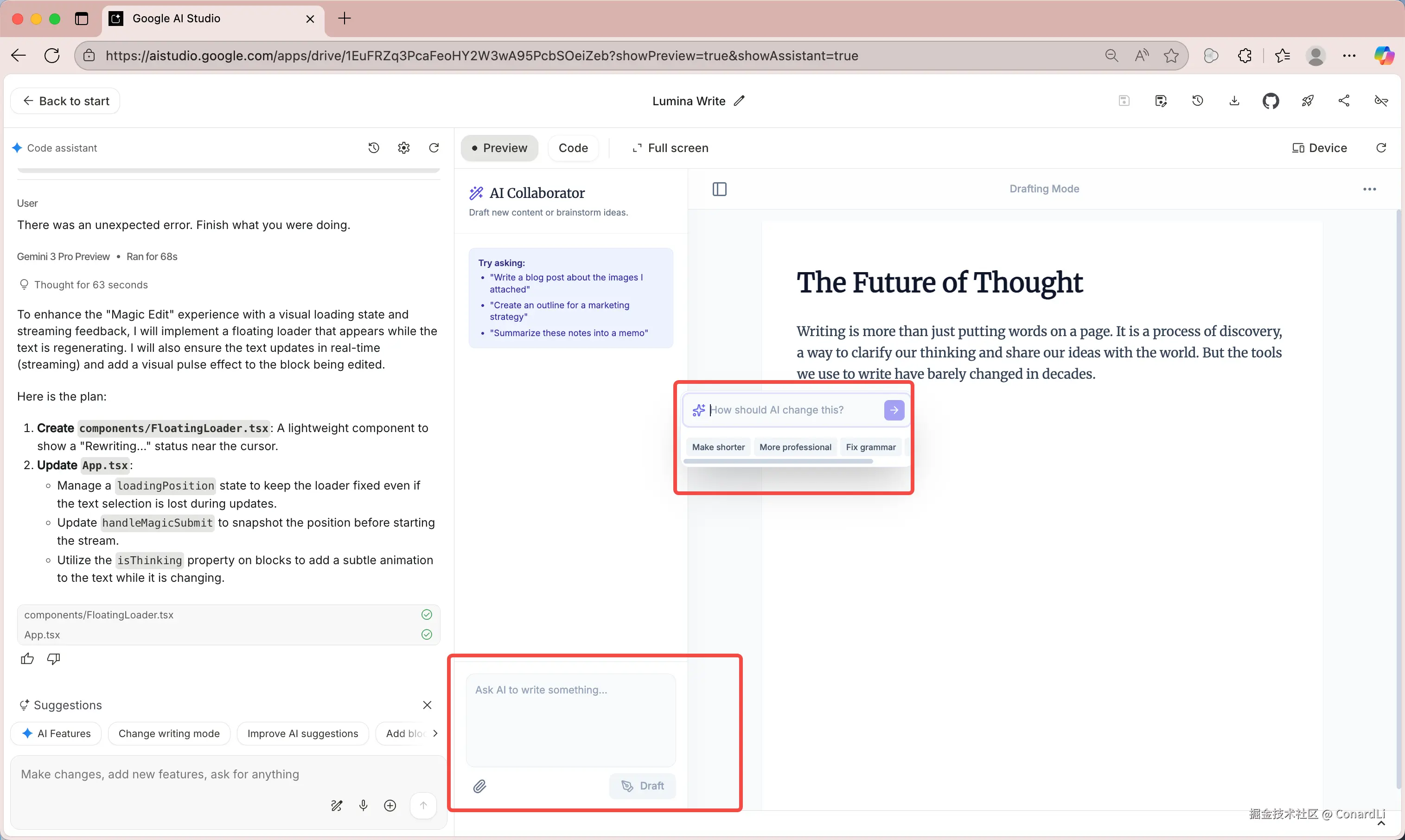
这是一个 AI 写作工具:支持通过输入提示词和文件附件,让 AI 协助创作内容;并要求 AI 对任意段落、句子等进行迭代优化;AI 也会智能主动介入 ------ 当它判断时机合适时,主动提供反馈建议,支持嵌入式修改;
经过这几轮测试我们发现,Gemini 3.0 编写网站的能力确实非常强,不过这也离不开 Build 工具的加持,那脱离了这个工具后究竟效果如何呢,下面我们在本地 AI IDE 环境中来进行测试。
Gemini 3.0 PK Claude Sonnet 4.5
我们让 Gemini 3.0 来 PK 一下目前公认最强的编码模型 Claude Sonnet 4.5 。
为了保证公平的测试环境,我们使用本地的 AI IDE 来进行测试,可让两个模型拥有同样的调度机制和工具。
我们直接用 Google 这次和 Gemini 3.0 一起发布的 Antigravity 编辑器,这是一款直接对标 Cursro、Windsurf 的本地 AI 编辑器,可以直接白嫖 Gemini 3 Pro 和 Claude Sonnet 4.5 。
Antigravity 也是基于 VsCode 二次开发的,使用体验感觉也和 Cursor 差不多:
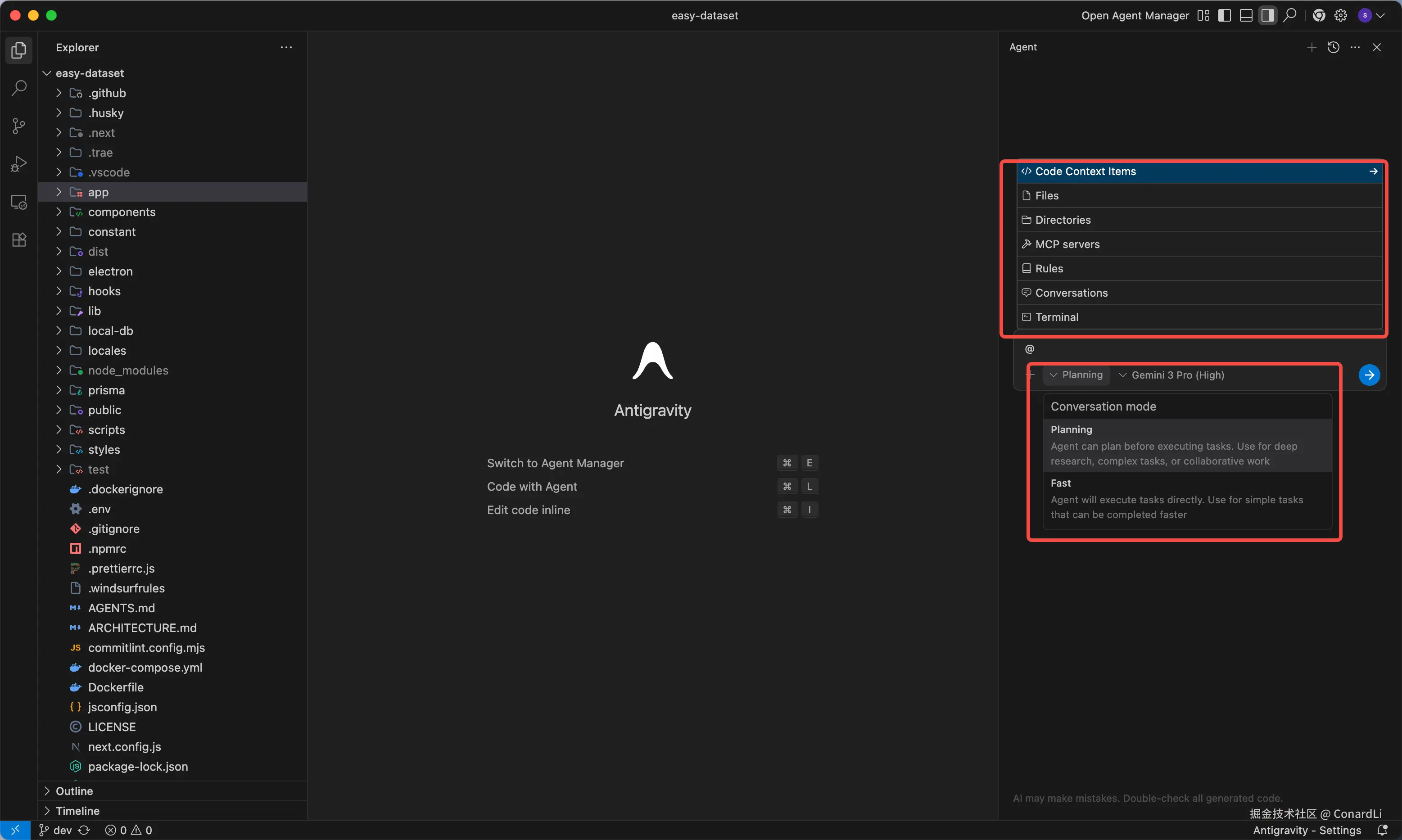
- 输入 @ 可以选择文件、配置
MCP Server、配置Global Rules等功能; Coding Agent可以选择Planning和Fast两种模式
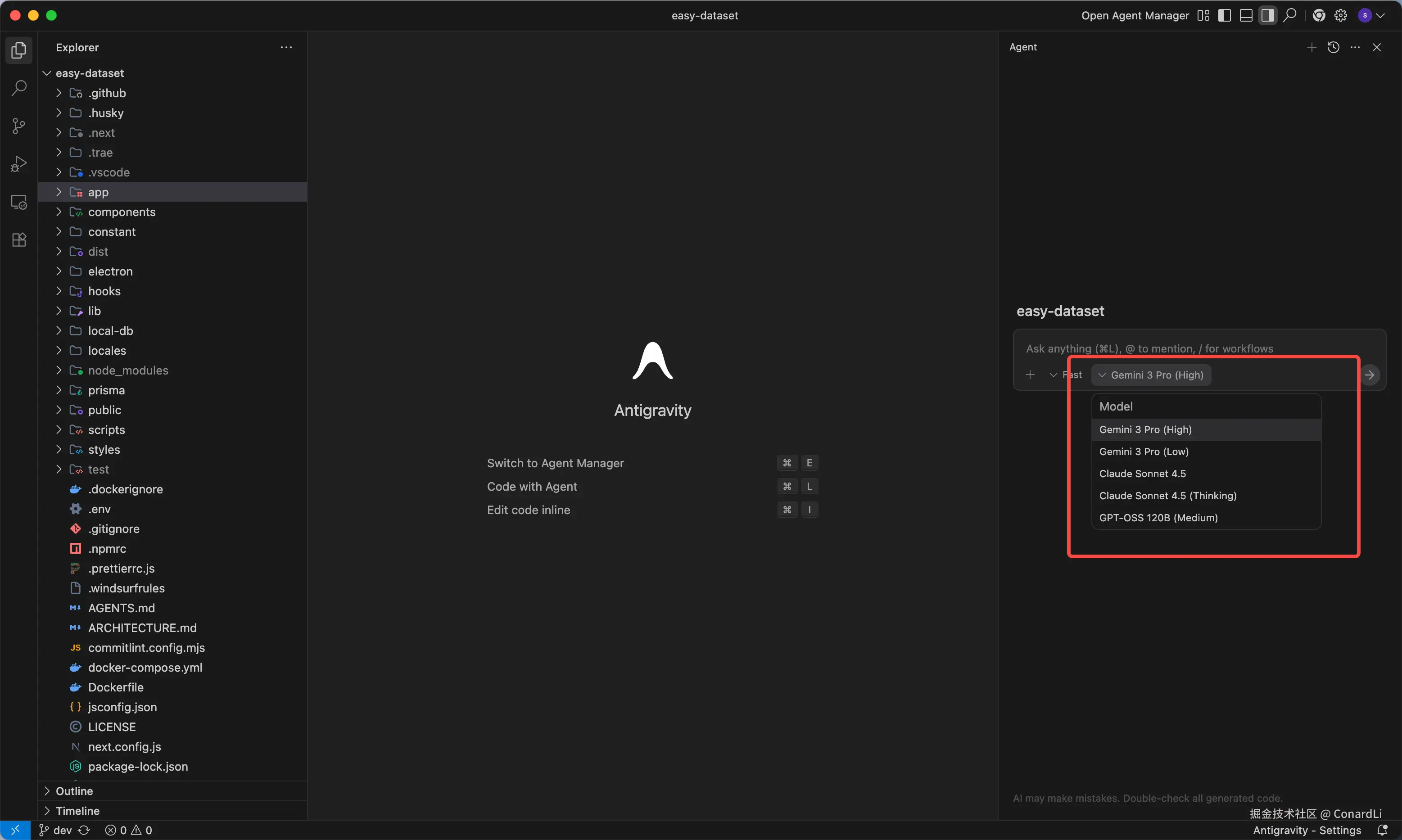
目前支持选择以下五个模型,都是免费的:
- Gemini 3 Pro (High)、Gemini 3 Pro (Low)
- Claude Sonnet 4.5、Claude Sonnet 4.5 (Thinking)
- GPT-OSS 120B (Medium)
题目1:项目理解能力:大型项目优化分析
第一局,我们来测试一下模型的项目理解能力,我们让他对一个大型的项目,进行整体的分析和产出优化建议,我们选择 Easy Dataset 这个项目。
理解当前项目架构,并告诉我本项目还有哪些需要改进的地方?(无需改动代码,先输出结论)
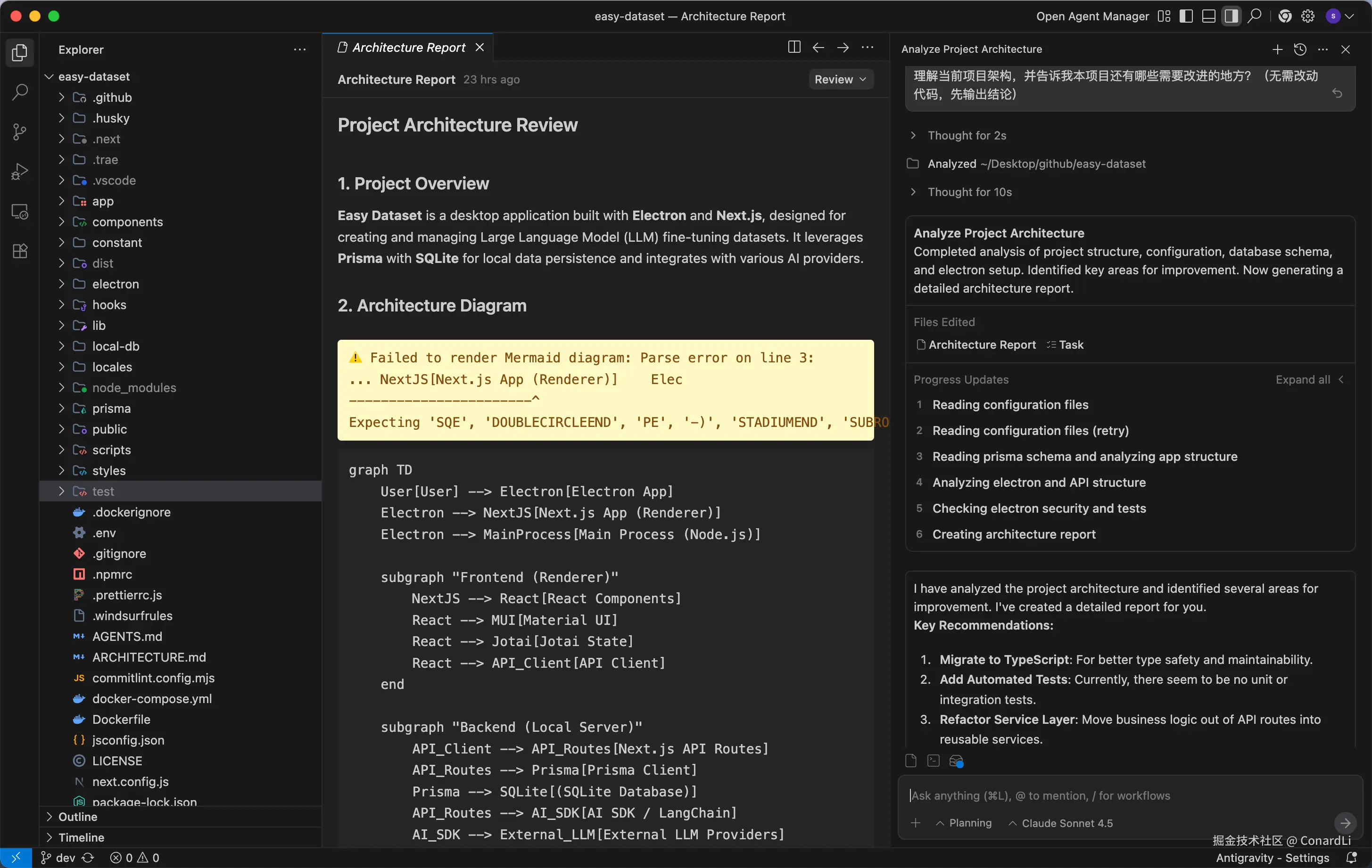
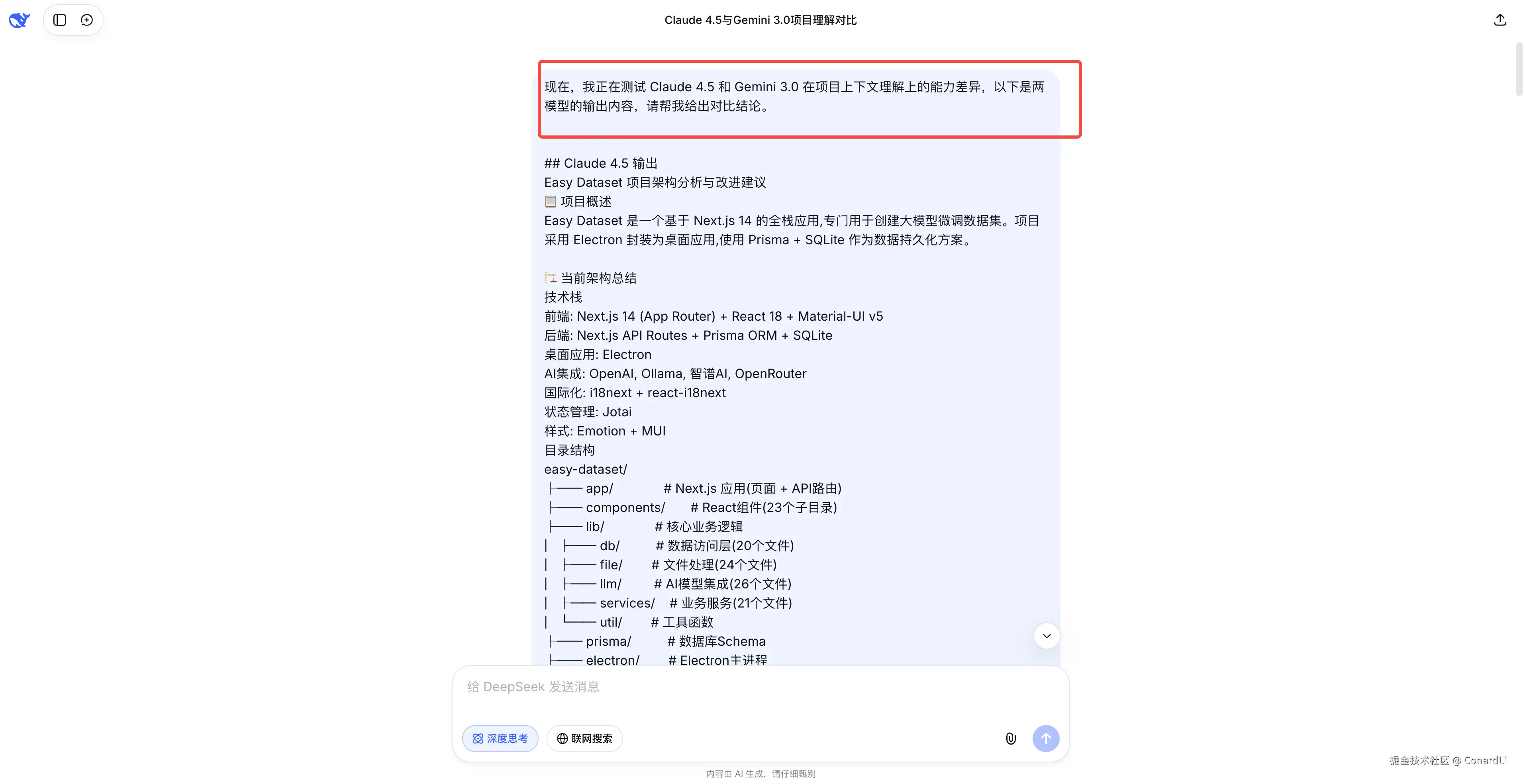
Gemini 3.0
这是 Gemini 3.0 的情况,它先进行了非常全面的分析,然后为最终的结论创作了一个单独的文件,使用英文编写:
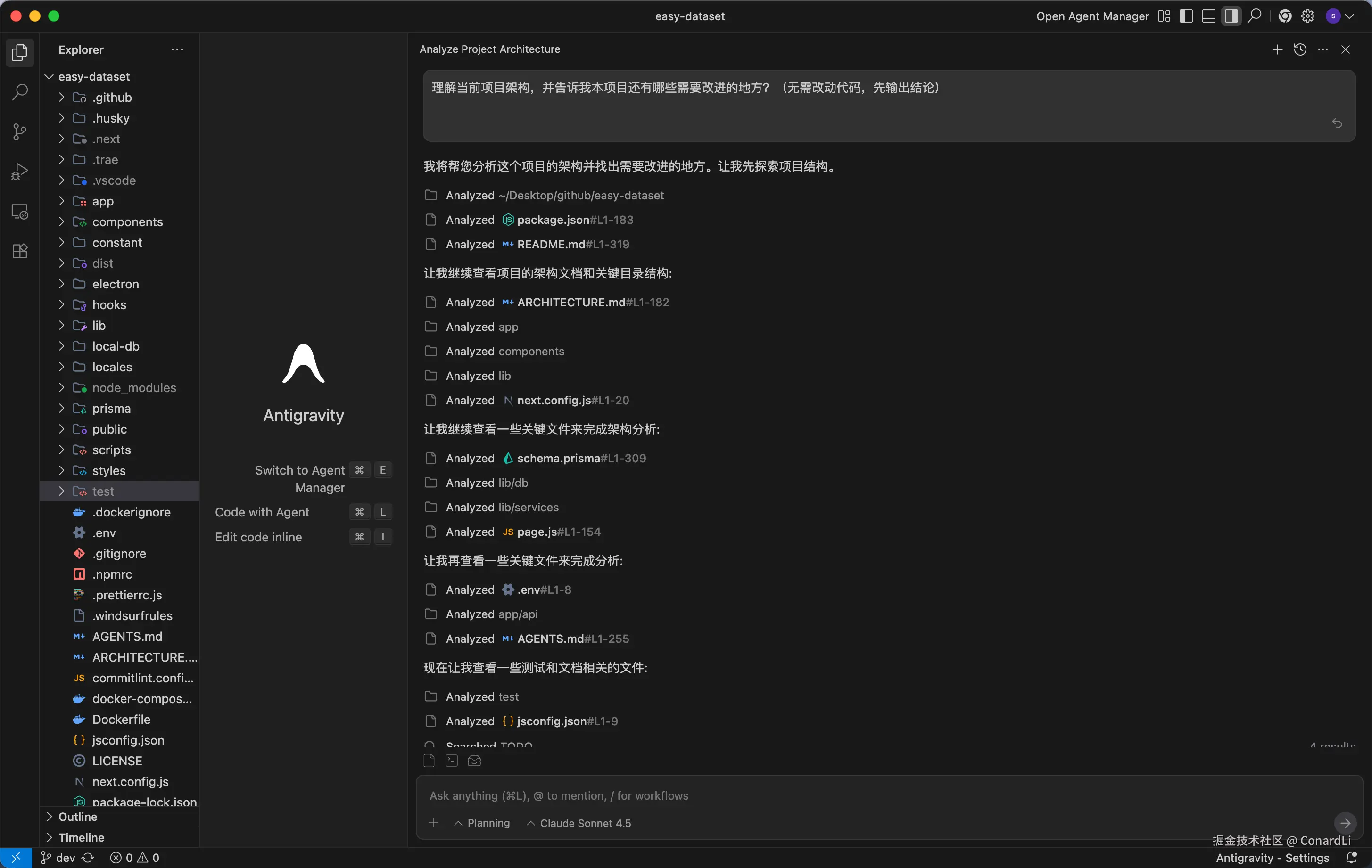
Claude Sonnet 4.5
然后是 Claude 4.5 的分析过程:
最终结论直接输出到了聊天窗口:
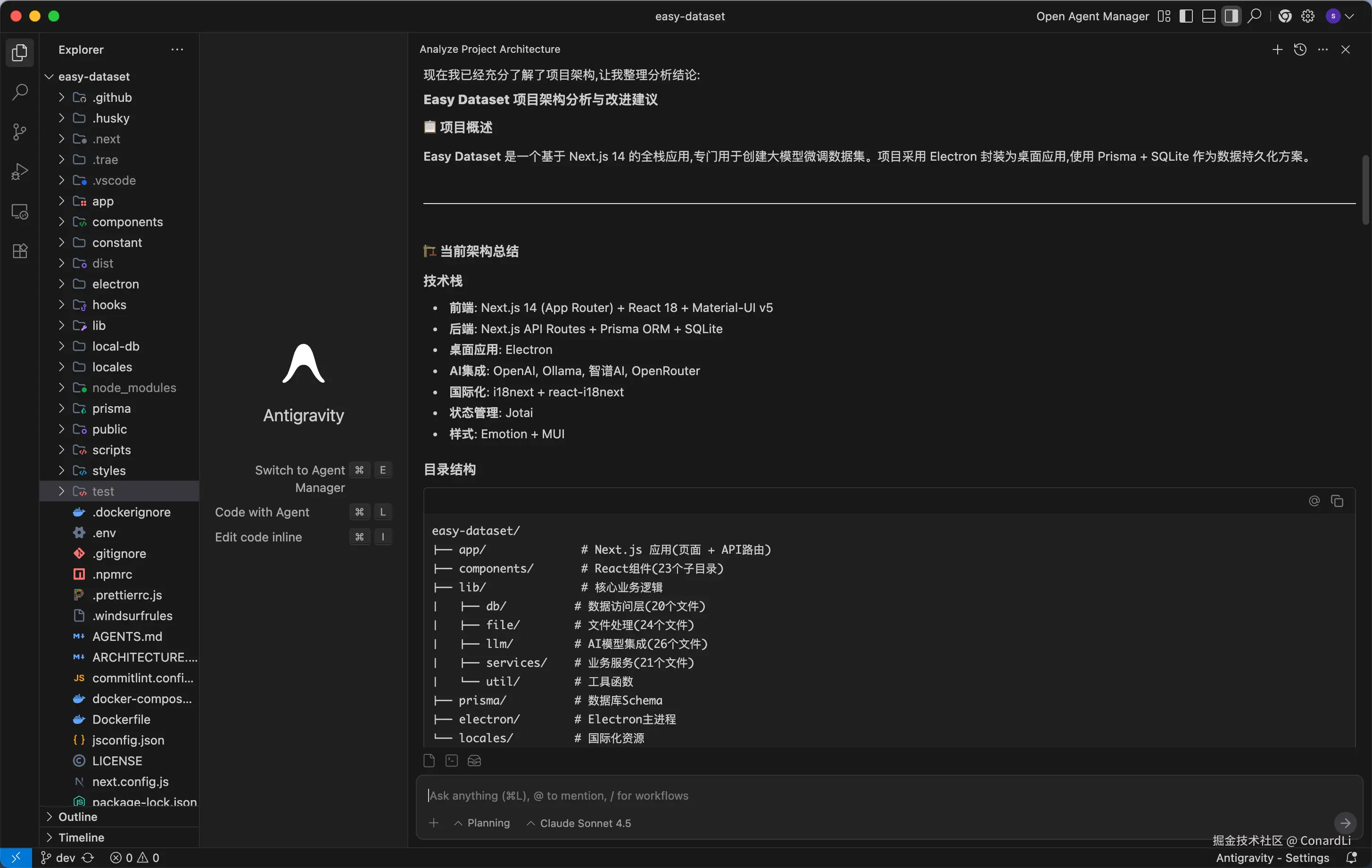
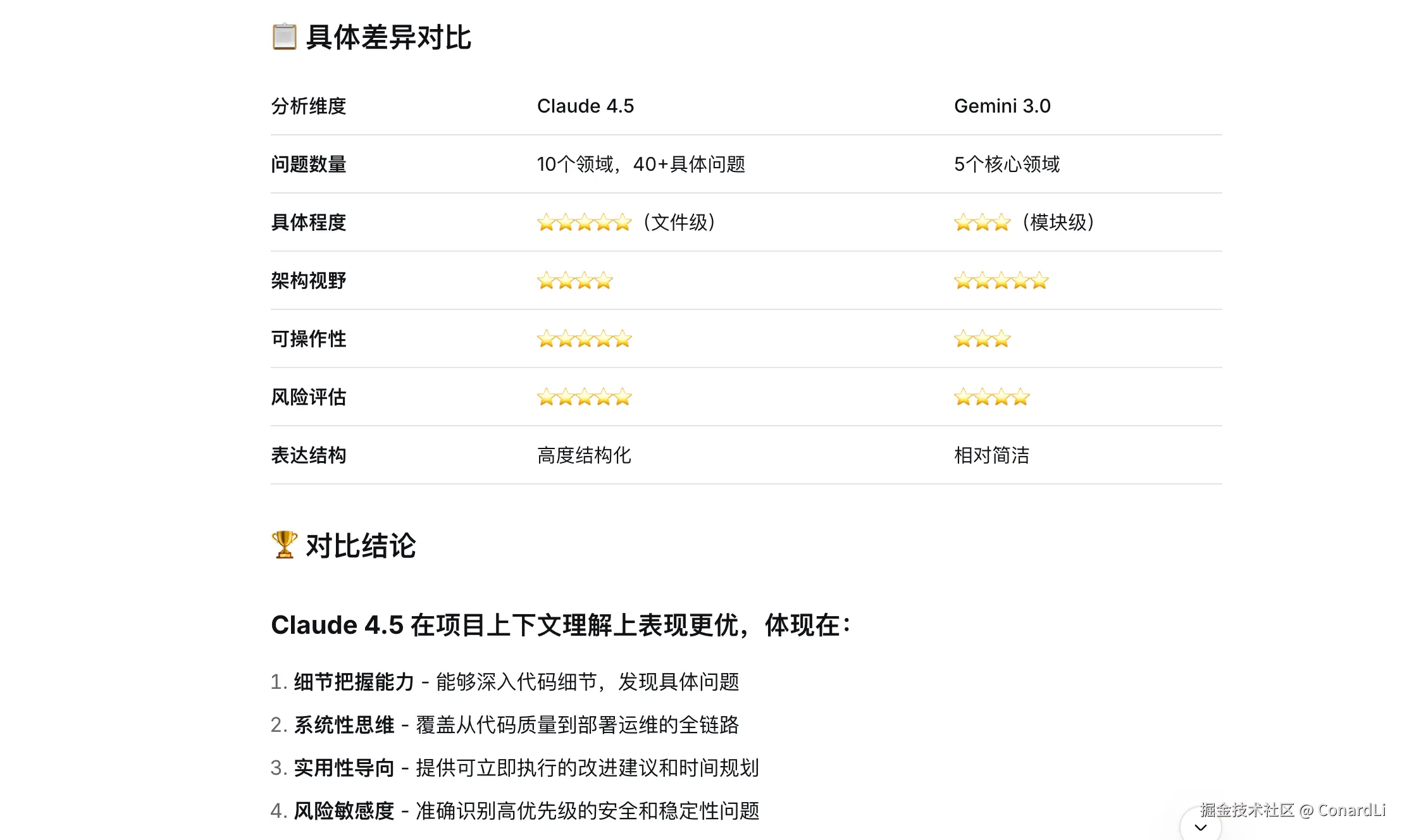
对比结果
凭我个人对这个项目的理解,乍一看还是 Claude 4.5 生成的结果更准确,而且查看的文件也很关键,给出的建议也都是正确的。
为了公平的评判,下面我们有请 DeepSeek 老师来担当裁判:
最终结论,Claude Sonnet 4.5 胜出:
其实这里对 Claude 来讲还稍微有点不公平的,因为 Gemini 3.0 我们使用的是长思考模式,而 Claude 4.5 我们选择的是非思考模型,如果是 Claude 4.5 Thinking 模式,最终效果肯定还要更好一点。
题目2:架构设计能力:全栈项目编写
下面,我们再来测试一下综合的架构设计和编码能力,让它帮我们生成一个完整的全栈项目,既要兼顾某一个具体的技术设计,又要兼顾前后端的协作,需求如下:
设计并实现一个 Node.js 的 JWT 认证中间件,考虑安全性和易用性;设计对应的前端页面、业务接口来演示中间件的调用效果;创建 Readme 文档,并编写此中间件的架构设计、使用方式等。
Gemini 3.0
过程省略(感兴趣可以到视频里去看),直接上结果吧:
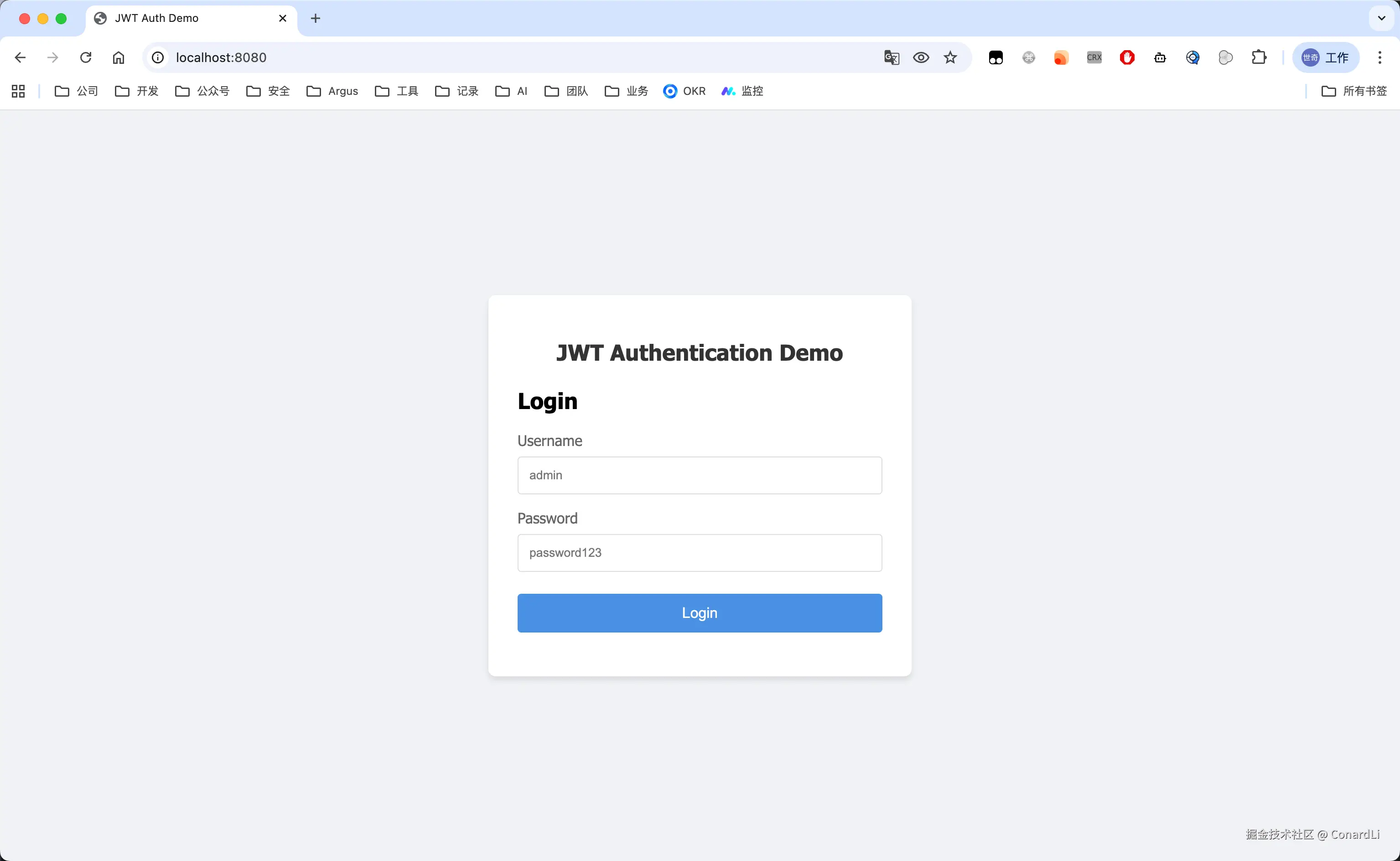
最后只生成了两个页面,一个登录页,一个登录之后的接口验证:
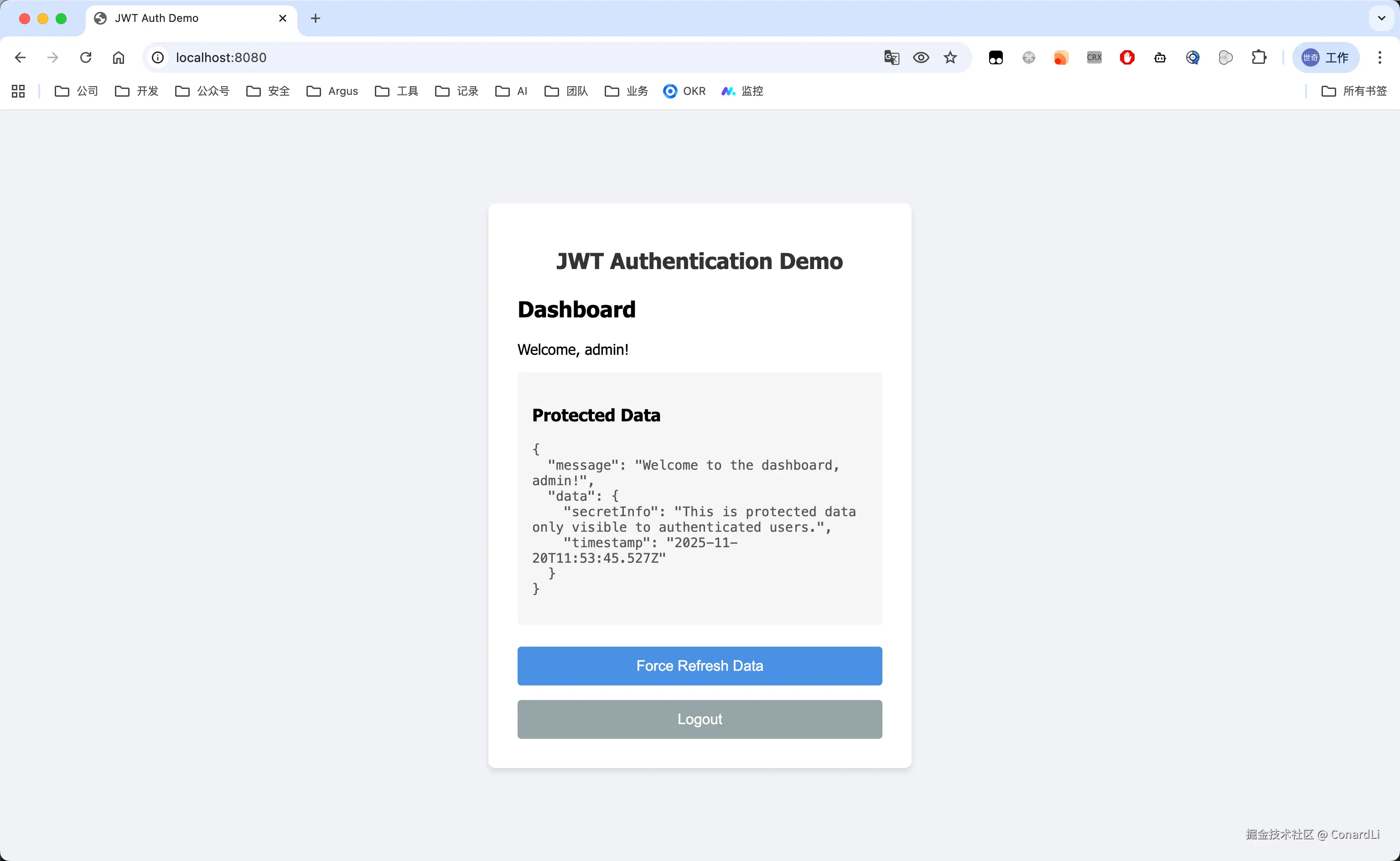
Claude Sonnet 4.5
Claude Sonnet 4.5 的结果明显就要更好一点了:
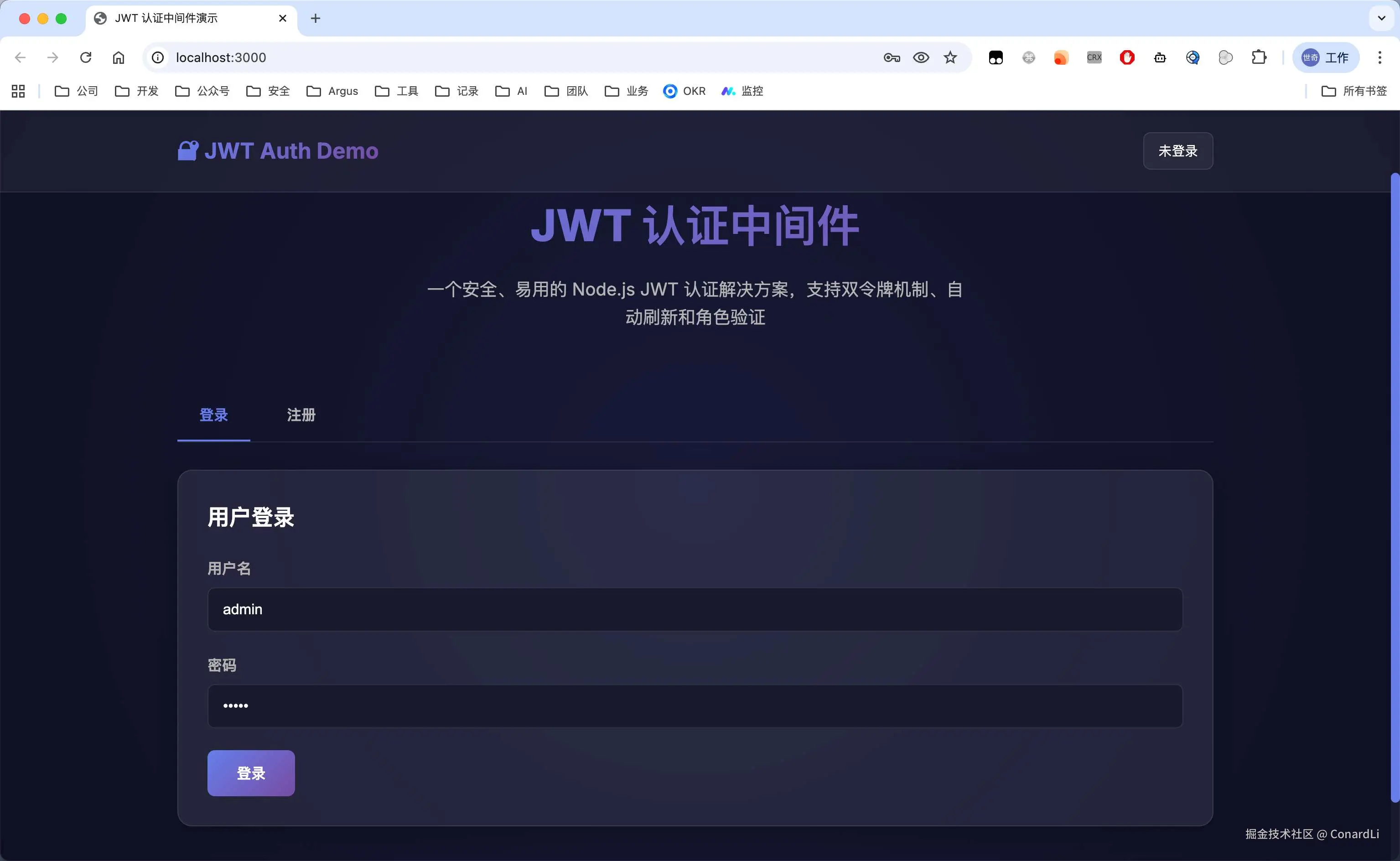
首先包含了完整的注册登录功能,在登录后,可以进行多种维度的接口验证:
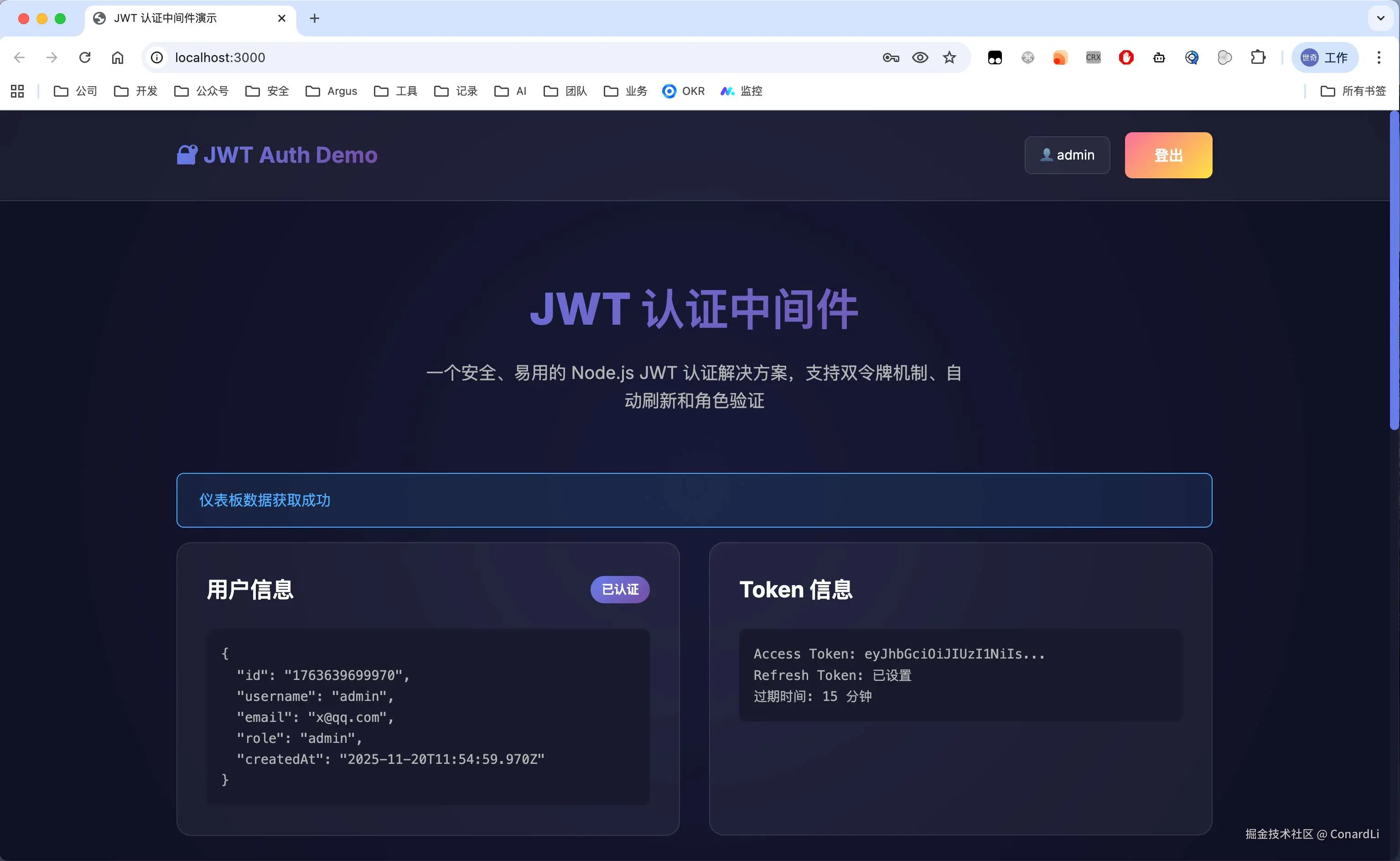
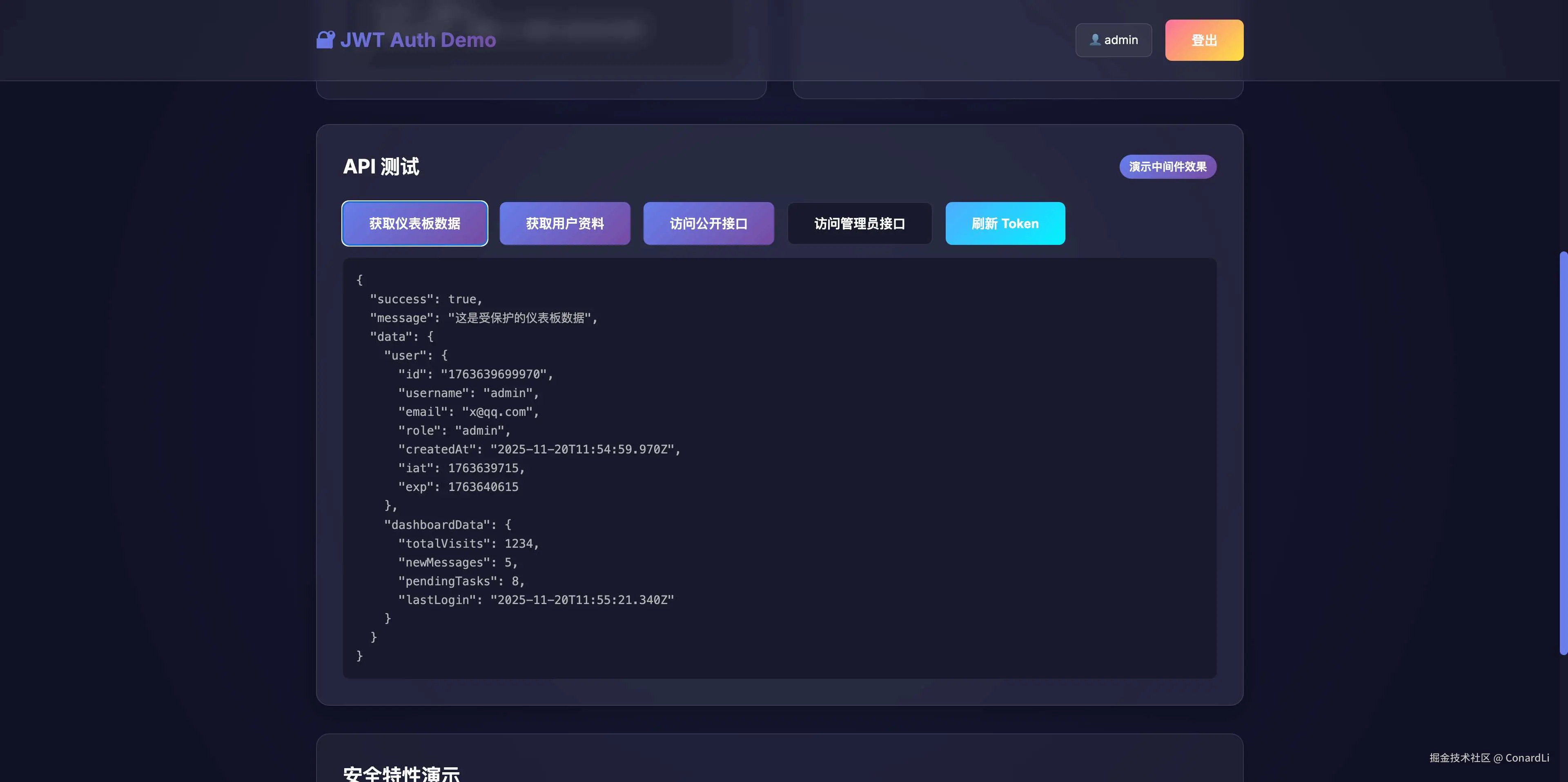
对比结果
为了保证公平,我们还是要看一下代码具体写的怎么样,下面我们还是让 AI 来分析对比下这两个工程的代码:
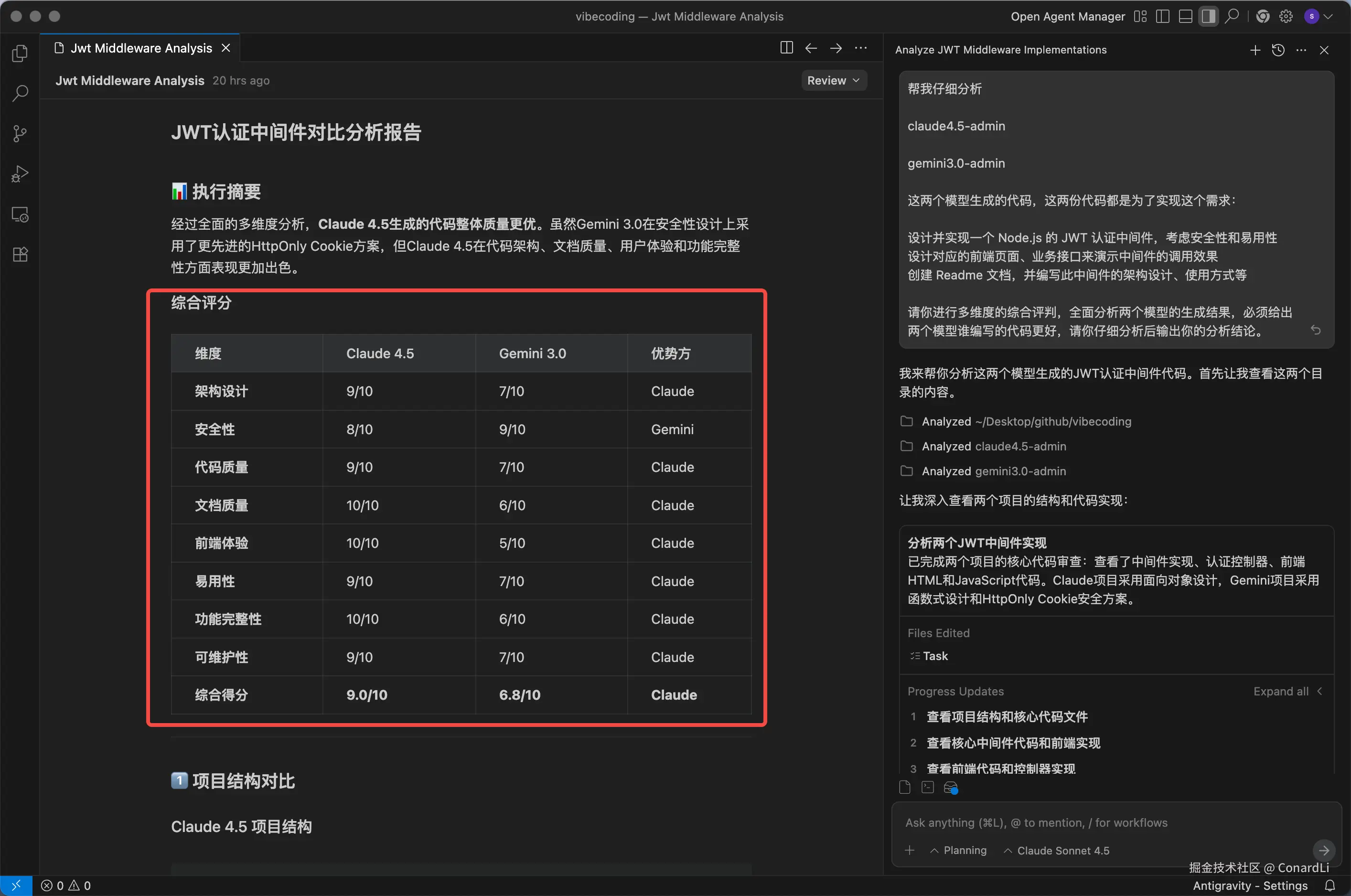
最终对比结论还是 Claude Sonnet 4.5 完胜
题目3:前端编写能力:项目官网编写
第三局,我们偏心一点,来对比一下两者的纯前端编码的能力,因为毕竟是 Gemini 3.0 的实测,都输了也不太好,我们这次让他们从零调研并生成一个 Easy Dataset 的官网。
提示词:请你调研并分析这个项目的主要功能 github.com/ConardLi/ea... ,并为它编写一个企业级的官方网站。
Gemini 3.0
首先看 Gemini 3.0 的生成效果,列出的项目计划是这样的,然后中间中断,手动继续了一次,后使用 tailwindcss 的脚手架模版创建了这个项目,在最后的自动化测试环节也是没有完成的。
最终生成的效果是这样的,审美还是挺在线的,不过内容略显单薄了。
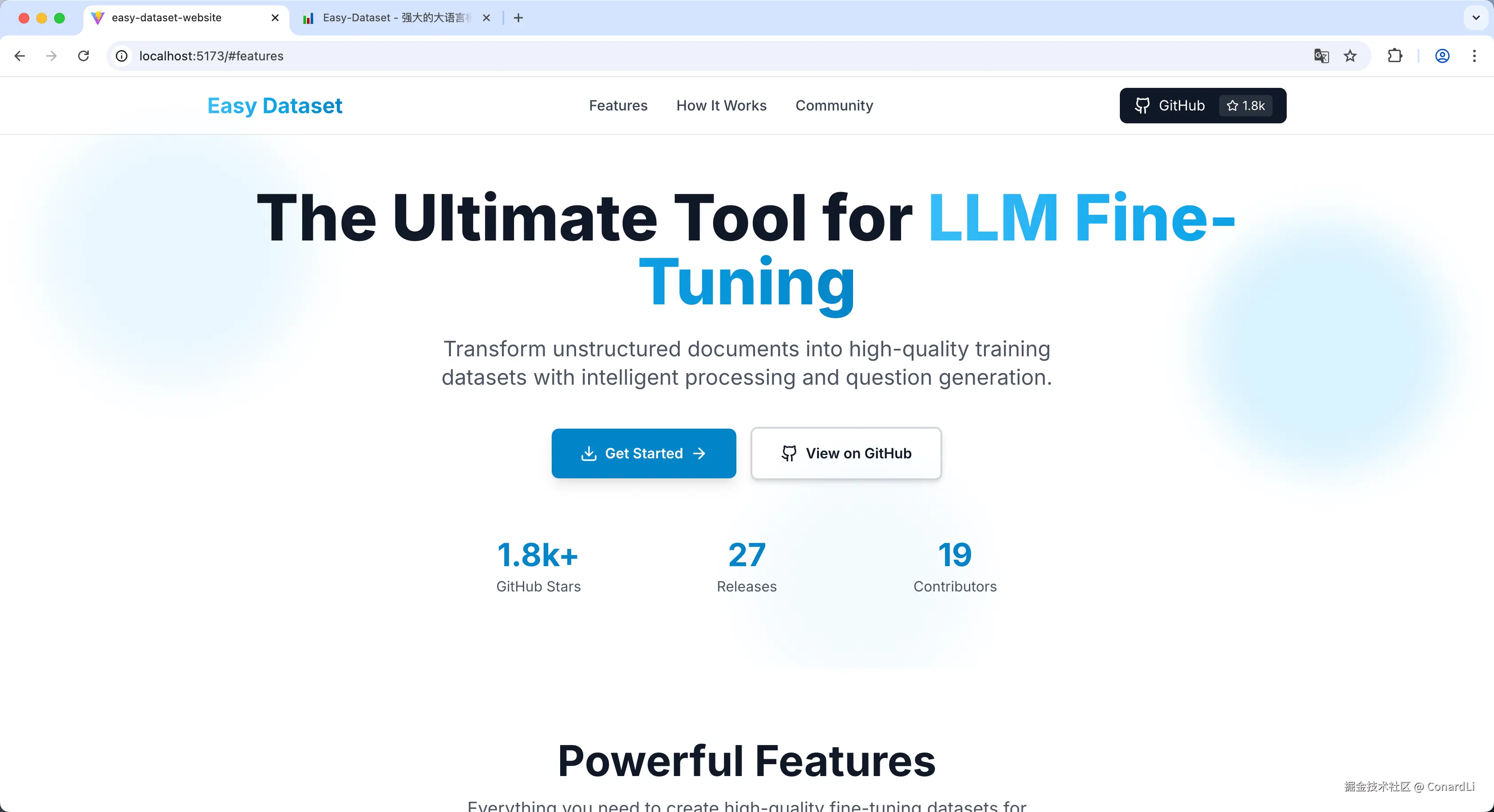
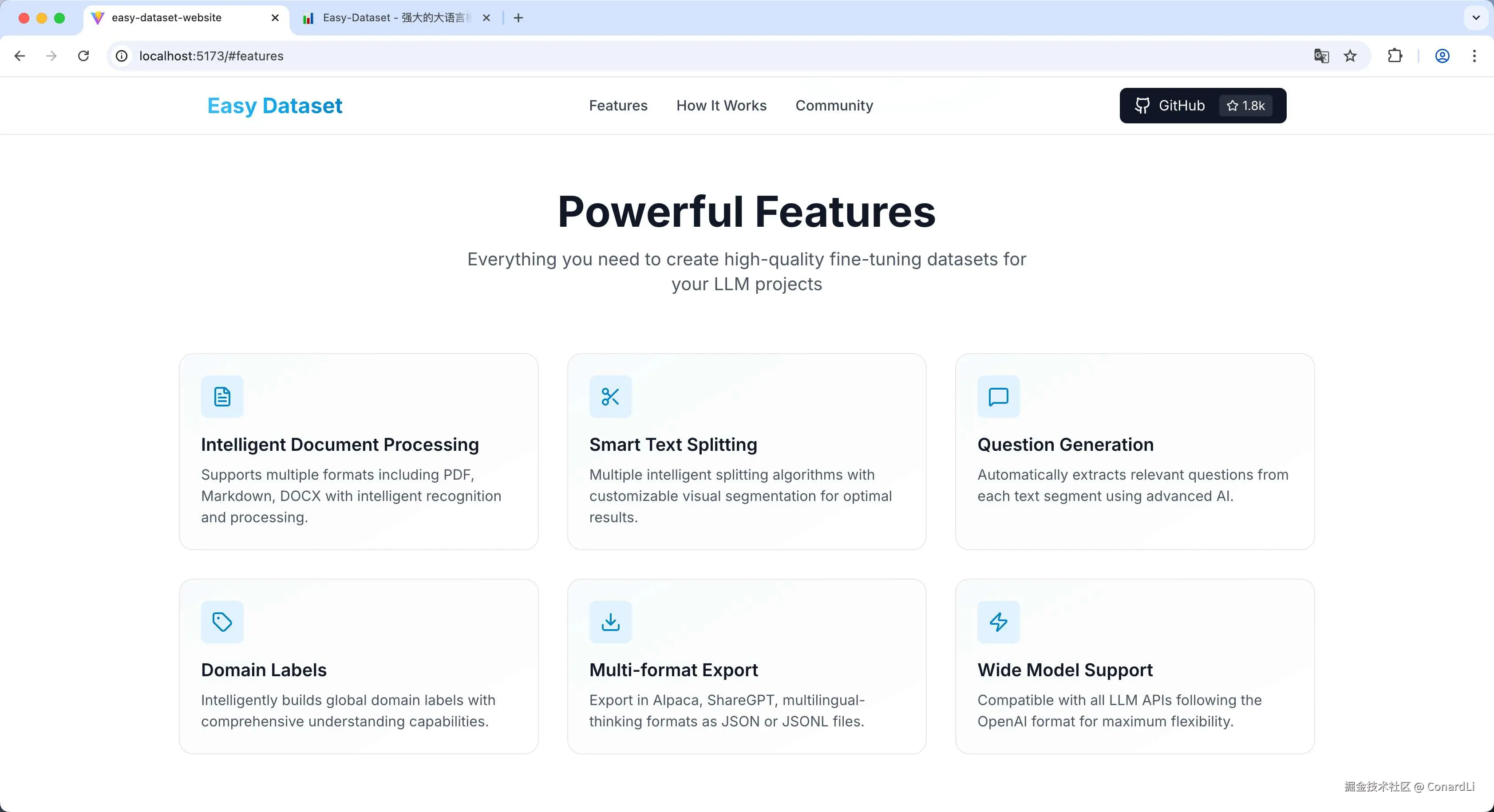
Claude Sonnet 4.5
然后我们来看 Claude 4.5 生成的结果,首先他生成的一份非常详细的开发计划,然后对 Easy Dataset 项目进行了调研,然后产出了一份调研报告后才开始开发。任务是一次就完成了,中间没有任何中断,然后他没有选择使用脚手架,而是从零创建了项目代码,最终也顺利完成了自动化测试。
然后我们来看最终的生成效果,这个看起来在视觉体验上就明显不如 Gemini 3.0 了。
但是,因为前期进行了非常充分的调研,所以网站的内容非常充实,基本上涵盖了所有关键信息。
对比结果
所以这最后一局可以说是各有优劣:
- 视觉体验、项目代码的可维护性 Gemini 3.0 胜出;
- 网站的内容丰富度,整个编写过程的丝滑程度 Claude 4.5 胜出;
所以这一局,我们判定为平局。
总结
最后我们来根据今天的实测结果总结一下结论。
Gemini 3.0 的前端能力确实超标,在小游戏开发,UI 设计稿还原,视觉效果开发这种对审美能力要求极高的需求中更是强的可怕。得益于 Gemini 原生多模态,以及强大的视觉理解能力,让他这种优势进一步放大了出来。
特别是在有了 AI Studio Build 这种工具的加持,让他在从零生成一个 Web 应用这个场景下更是是如虎添翼。另外,在指令遵循,需求理解的能力上,相比上一代的 Gemini 2.5 确实是有了很大幅度的增强。
但是,这足以让前端失业吗?
在实际的开发中,绘制 UI 可能只占很小一部分的工作。说到这,就不得不说我们的前端祖师爷,最近刚靠开发前端工具链融资了 8000 万啊,当之无愧的前端天花板了。

在后面的实战对比中,我们发现,在复杂项目上下文理解,全栈项目的架构设计和编写等实际开发工作中需要考虑的环节上,相比 Claude,Gemini 3.0 还是略逊一筹的,他依然无法撼动 Claude 在 Vibe Coding 领域的的霸主地位。
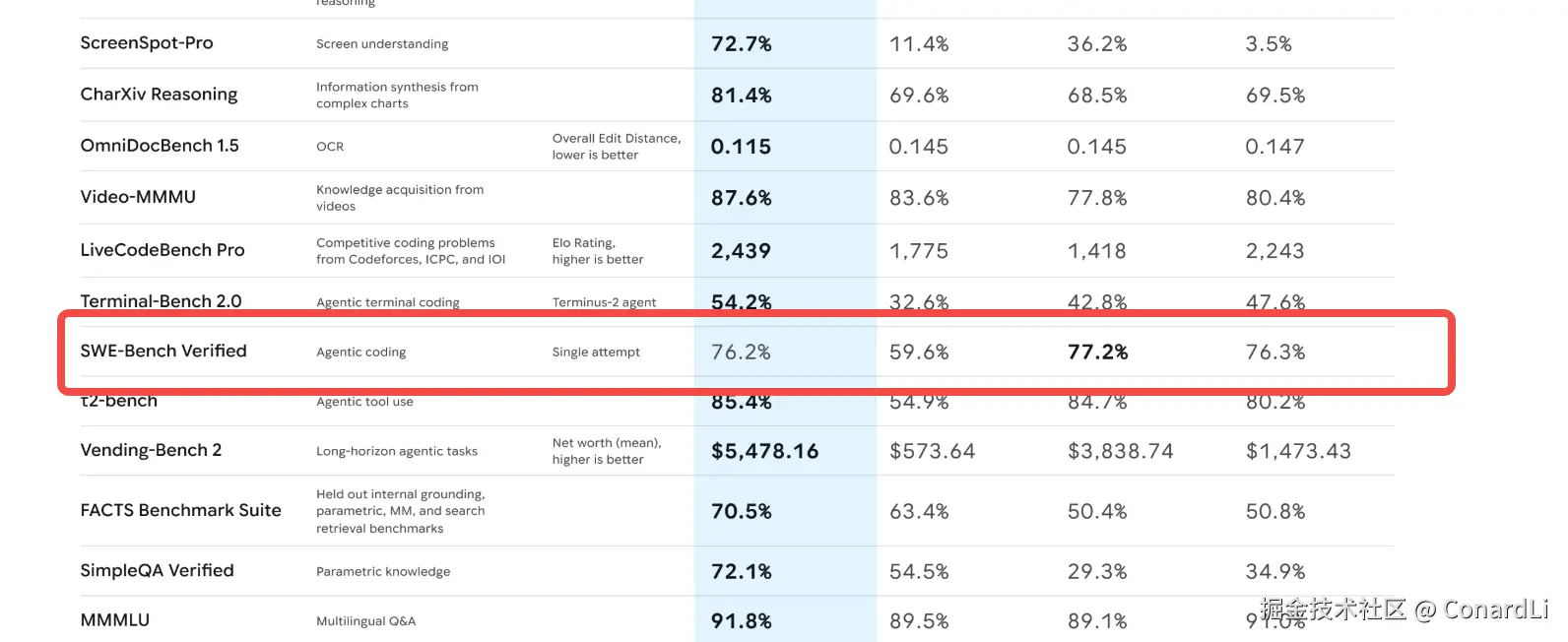
这个其实我们看榜单的 SWE Bentch 就看出来了,这是唯一一个被 Claude超越的指标,这个 Bentch 中包含了大量真实项目开发中要解决的 Issue ,能够衡量模型在真实编程环境中解决问题的能力。

所以这也能体现 Gemini 3.0 在真实的编程工作中并没有带来多大的提升,不过对于完全不会编程的小白来讲,确实可以让你们的想法更快也更好的变成现实了。
所以广大前端程序员不要慌,淘汰的是切图仔,关我前端程序员什么事呢?
不过这是玩笑话,广大程序员们确实应该居安思危了,就算不会在短时间内立刻失业,你们的竞争力确实是在实打实的流失的,其实很多行业也都一样,如果一直是在做简单的重复性工作,那未来被 AI 淘汰已是必然了。
最后
关注《code秘密花园》从此学习 AI 不迷路,相关链接:
- AI 教程完整汇总:rncg5jvpme.feishu.cn/wiki/U9rYwR...
- 相关学习资源汇总在:github.com/ConardLi/ea...
如果本期对你有所帮助,希望得到一个免费的三连,感谢大家支持