在计算机视觉领域,目标检测模型通常需要大量带有人工标注的数据集来进行训练,这个过程既耗时又费力。为了解决这个问题,研究者们提出了虚拟监督目标检测(Imaginary Supervised Object Detection, ISOD)这一新方向,即模型在合成的虚拟图像上训练,但在真实的图像上进行测试。然而,现有的虚拟监督方法面临着合成数据质量差、模型容易过拟合合成图像的特定模式以及无法有效处理自动标注带来的噪声等难题。
为了克服这些挑战,本论文提出了一个名为**Cascade HQP-DETR的模型框架,通过高质量数据生成与级联去噪方法提升检测性能。**该方法不仅能够生成场景更丰富、标注更精准的合成数据集,还通过改进模型结构,让其学会关注更具泛化性的物体特征并有效抑制噪声干扰。最终,仅在合成数据集上训练的模型,其性能在真实数据集上超越了众多基准模型,证明了方法的有效性。
另外我整理了计算机视觉入门指南,包含:机器学习数学神书、Python+机器学习+深度学习系列课程、图像处理、目标检测、SCI论文写作技巧、绘图模板等干货资料,感兴趣的自取。
一、论文基本信息

论文标题: High-Quality Proposal Encoding and Cascade Denoising for Imaginary Supervised Object Detection
作者姓名: Zhiyuan Chen, Yuelin Guo, Zitong Huang, Haoyu He, Renhao Lu, Weizhe Zhang
作者单位/机构: 哈尔滨工业大学、鹏城实验室、莫纳什大学
论文链接: https://arxiv.org/pdf/2511.08018
二、主要贡献与创新
- 提出一套高质量合成数据生成流程,推动虚拟监督从弱监督迈向全监督。
- 设计了高质量区域建议引导的查询编码,加速收敛并提升模型的泛化能力。
- 提出级联去噪算法,通过动态调整训练权重,有效缓解伪标签噪声的影响。
- 实现了SOTA性能和高训练效率,仅用12个周期训练便超越了基准模型。
三、研究方法与原理
该论文提出的模型核心思路是:通过高质量的区域建议(proposal)来初始化检测器的查询,并设计一种级联式的去噪机制来应对合成数据中的标签噪声。
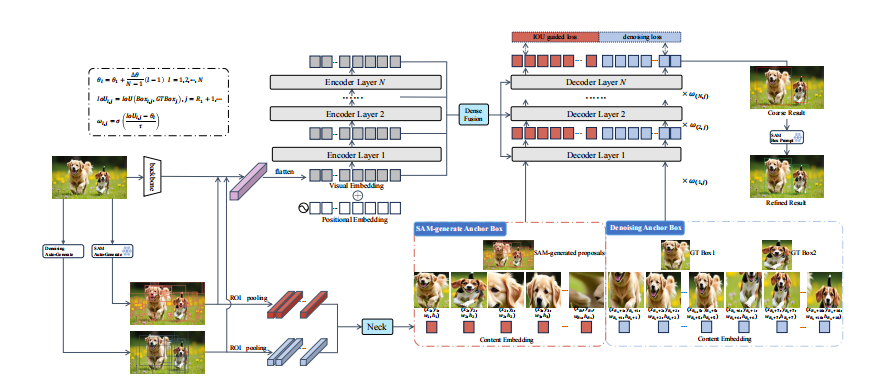
该模型主要由三个创新模块构成:高质量合成数据生成、高质量区域建议引导的查询编码和级联去噪算法。
高质量合成数据生成
为了解决现有虚拟数据质量差的问题,论文首先设计了一个三阶段的自动化数据生成流水线,用以构建FluxVOC和FluxCOCO这两个高质量合成数据集。
- 提示词生成:首先,利用大语言模型LLaMA-3将简单的类别组合(如"一张包含人和狗的照片")丰富为包含生动细节、上下文和合理实例数量的场景描述(如"一张温暖的户外照片,一位年轻女性在洒满阳光的公园里和她的两只金毛犬玩耍")。
- 图像合成:接着,将这些丰富的提示词输入到先进的文生图模型Flux中,生成具有逼真细节和高度多样性的合成图像。
- 自动标注 :最后,利用开放词汇检测器Grounding DINO,根据原始的类别信息自动为合成图像生成精确的边界框标注。这一流程使得虚拟监督目标检测(Object Detection)从仅有图像级标签的弱监督,升级为拥有精确边界框的全监督模式,极大地提升了数据质量。
高质量区域建议(HQP)引导的查询编码
针对传统DETR模型随机初始化查询导致收敛慢和过拟合的问题,论文提出了HQP引导的查询编码机制,为模型提供图像相关的先验知识。这解决了传统方法中"盲目初始化"的弊端。
1. 几何感知的先验信息 :论文使用SAM (Segment Anything Model)来生成高质量、与类别无关的区域建议。这些建议能够准确地覆盖图像中的显著物体,作为几何先验来初始化Transformer 解码器中查询(Query)的锚框位置。具体来说,SAM生成的每个掩码 m i m_i mi 都会被计算其最小外接矩形框 p i = ( x i , y i , w i , h i ) = BBox ( m i ) p_i = (x_i, y_i, w_i, h_i) = \text{BBox}(m_i) pi=(xi,yi,wi,hi)=BBox(mi),这些矩形框就构成了初始的锚框集合。这种方式让模型从一开始就聚焦于图像中可能存在物体的区域,而非在整个图像中漫无目的地搜索。
2. 语义感知的先验信息 :为了补充语义信息,论文进一步从骨干网络 (backbone)的特征图中提取与每个区域建议相对应的特征,用以初始化查询的内容嵌入。具体地,对于骨干网络输出的特征图 F C5 F_{\text{C5}} FC5 和每个区域建议 p i p_i pi,通过区域兴趣池化 (Region of Interest Pooling)操作来提取固定大小的特征块 f roi i f_{\text{roi}i} froii:
f roi i = RoI Pooling ( F C 5 , p i ) f{\text{roi}i} = \text{RoI Pooling}(F{C5}, p_i) froii=RoI Pooling(FC5,pi)
然后,这个特征块会经过一个颈部网络(Neck)投影到解码器所需的维度,生成初始的内容嵌入 c init i = Neck θ ( f roi i ) c_{\text{init}i} = \text{Neck}\theta(f_{\text{roi}_i}) ciniti=Neckθ(froii)。这为每个查询注入了其对应区域的初始语义信息,使其不再是一个随机向量。
通过结合几何和语义先验,HQP编码将解码器的学习任务从全局探索转变为局部优化,极大地简化了学习难度,加速了收敛并引导模型学习更具泛化性的特征。
级联去噪算法
由于自动生成的标签不可避免地含有噪声,直接使用传统的去噪训练方法(如DN-DETR)会导致模型学到错误的模式。为此,论文设计了级联去噪算法,让模型学会在训练中"明辨是非"。
其核心思想是,在解码器的不同层级设置递增的质量门槛,并根据预测质量动态调整训练信号的强度。具体实现如下:
-
动态交并比阈值设计 :为解码器的每一层 l l l(从1到N)设置一个线性递增的交并比 (Intersection over Union, IoU)阈值 θ l \theta_l θl:
θ l = θ 1 + Δ θ N − 1 ( l − 1 ) , l ∈ { 1 , 2 , . . . , N } \theta_l = \theta_1 + \frac{\Delta\theta}{N-1}(l-1), l \in \{1, 2, ..., N\} θl=θ1+N−1Δθ(l−1),l∈{1,2,...,N}在论文中,初始阈值 θ 1 \theta_1 θ1 设为0.3,总增量 Δ θ \Delta\theta Δθ 为0.6,解码器共6层,因此阈值从第一层的0.3逐步增加到最后一层的0.9。
-
查询加权机制 :在训练过程中,对于第 l l l 层的每个去噪查询 j j j,模型会预测一个边界框 Box l , j \text{Box}{l,j} Boxl,j。计算该预测框与其对应的真实标签 GT Box j \text{GT Box}j GT Boxj 的交并比 IoU l , j \text{IoU}{l,j} IoUl,j。然后,通过一个Sigmoid函数计算出一个动态权重 ω l , j \omega{l,j} ωl,j:
ω l , j = σ ( IoU l , j − θ l τ ) \omega_{l,j} = \sigma\left(\frac{\text{IoU}_{l,j} - \theta_l}{\tau}\right) ωl,j=σ(τIoUl,j−θl)其中 τ \tau τ 是一个控制权重曲线陡峭程度的温度系数。这个权重 ω l , j \omega_{l,j} ωl,j 会直接作用于该查询的特征,以调制其对损失函数的贡献。如果一个查询的预测质量远低于当前层的阈值( IoU l , j ≪ θ l \text{IoU}_{l,j} \ll \theta_l IoUl,j≪θl),它的权重将趋近于0,其产生的训练信号就会被抑制。反之,高质量的预测会获得接近1的权重。
这种机制迫使模型在早期层级关注粗略的定位,而在后期层级则专注于精细的边界优化。它鼓励模型去学习物体本身稳定、可靠的视觉特征(如轮廓、边缘),而不是盲目地拟合那些充满噪声的伪标签,从而显著提升了模型的鲁棒性和定位精度。
四、实验设计与结果分析
论文的实验部分设计得非常全面,旨在验证其提出的数据生成流程和模型架构的有效性。实验主要在合成的FluxVOC和FluxCOCO数据集上进行训练,并在真实的PASCAL VOC 2007和MS COCO 2014数据集上进行评测。核心评价指标为平均精度均值(mAP)。
数据集质量评估
为了证明新构建的FluxVOC数据集的优越性,论文首先将其与之前的ImaginaryNet进行了对比。
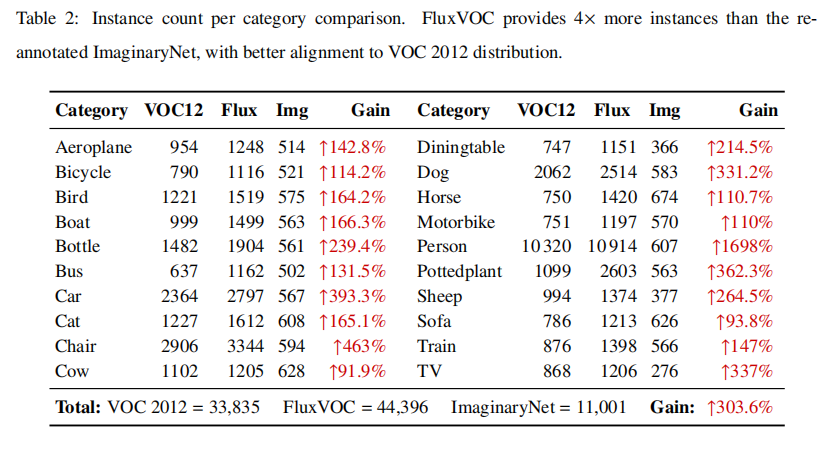
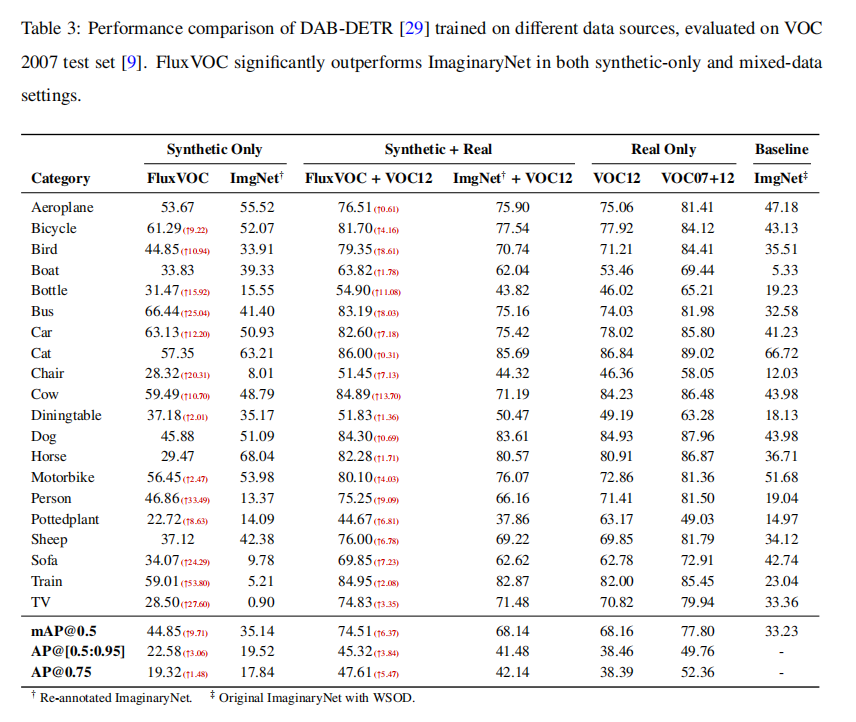
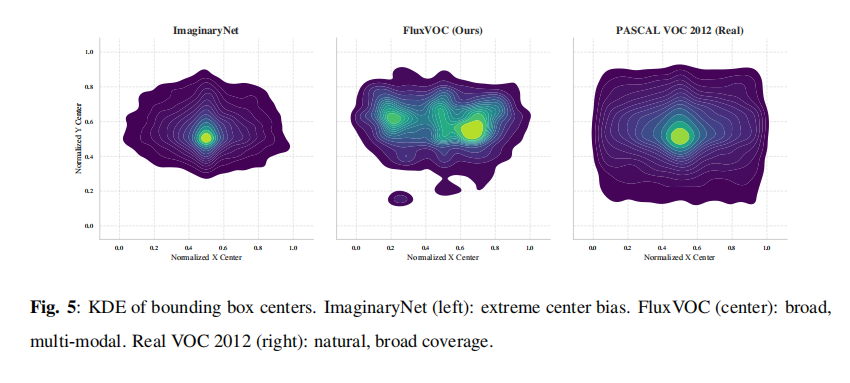
分析表2 和表3 可以发现,FluxVOC在实例数量上是ImaginaryNet的4倍,并且其类别分布更接近真实的VOC 2012数据集。更重要的是,使用相同的检测器在FluxVOC上训练,其性能(44.85% mAP@0.5)远超在ImaginaryNet上训练的结果(35.14% mAP@0.5)。从图5 的空间分布来看,ImaginaryNet的物体位置高度集中在图像中心,而FluxVOC的物体分布则更加广泛和多样,与真实数据的分布更为接近。这表明FluxVOC在数量、分布和视觉质量上都显著优于以往的合成数据集。
对比实验
为了验证Cascade HQP-DETR模型的性能,论文将其与多种主流的DETR变体(如DAB-DETR, DN-DETR, DINO等)在相同的虚拟监督设定下进行了比较。
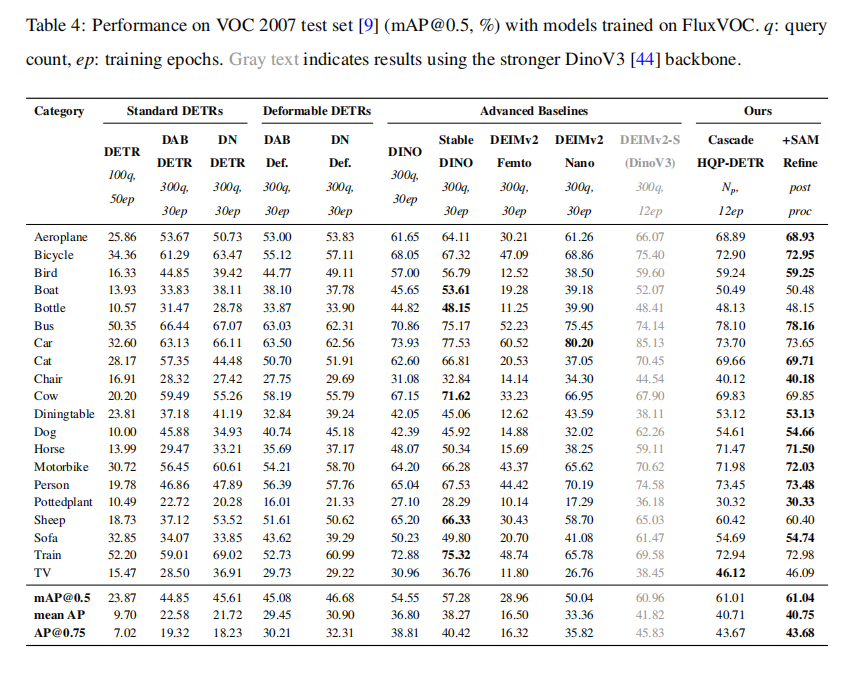
从表4 可以看出,Cascade HQP-DETR仅用12个周期的训练,就在VOC 2007测试集上实现了61.04%的mAP@0.5 ,显著超越了所有基于相同骨干网络(ResNet-50)且训练了30个周期的基准模型。例如,它比强大的基准模型StableDINO(57.28%)高出3.76个百分点。这一结果有力地证明了论文所提出的架构在虚拟监督场景下的卓越性能和训练效率。
可视化对比
为了更直观地展示模型的泛化能力,论文提供了模型在真实的VOC 2007测试集上的检测效果图。

从图7 中可以看到,尽管模型完全没有见过真实的训练图像,但它依然能够在各种复杂场景下准确地检测出物体,例如存在严重遮挡的摩托车手、远距离的小物体(羊群)以及物体密集的餐桌场景。这直观地表明,模型成功地从高质量的合成数据中学到了可迁移的、鲁棒的视觉特征,实现了出色的"虚实结合"泛化能力。
消融实验
为了探究模型各个创新组件的具体贡献,论文进行了一系列详细的消融实验。

通过分析表6,我们可以清晰地看到每个模块的作用。
- 基准模型(DAB-DETR)的性能为44.85% mAP@0.5。
- 单独加入SAM区域建议作为几何先验,性能大幅提升至55.89%(+11.04%),证明了"看对地方"至关重要。
- 在加入几何先验的基础上,再加入RoI特征作为语义先验,性能提升至57.85%(+13.00%),体现了二者的协同效应。
- 最后,将统一的去噪策略替换为级联去噪,性能从59.72%提升至61.01%(+1.29%),证明了该机制在处理伪标签噪声上的有效性。
这些实验数据一步步地验证了论文提出的HQP引导查询编码和级联去噪算法是模型性能提升的关键驱动力。
五、论文结论与评价
总结
这篇论文成功地解决虚拟监督目标检测领域面临的几个核心难题。在理论上,它提出了一套完整且自动化的流程来生成高质量的合成数据,并将虚拟监督学习推向了全监督的新高度。同时,设计的HQP引导查询编码和级联去噪算法,为解决DETR类模型在跨域(从虚拟到现实)应用中的泛化和噪声鲁棒性问题提供了创新的架构方案。在实验上,模型仅依靠合成数据训练,就在真实世界的基准测试中取得了当前最优的性能,并且训练效率远高于此前的模型。这项研究为那些难以获取大规模标注数据的应用领域(如工业质检、罕见病诊断)提供了极具价值的参考,展示了利用合成数据训练高性能检测器的巨大潜力。
优点
- 系统性强:论文提供了一个从数据生成到模型优化的端到端解决方案,完整性和实用性都非常高。
- 创新性突出:HQP引导查询编码巧妙地利用SAM解决了DETR的初始化难题,而级联去噪则为处理噪声伪标签提供了新颖且有效的思路。
- 实验验证充分:详尽的实验不仅证明了方法的优越性,还通过消融研究清晰地剖析了每个组件的贡献,论证扎实有力。
缺点
- 推理开销:在推理阶段需要运行SAM来生成区域建议,这会增加额外的计算开销,可能不适用于对实时性要求极高的场景。
- 领域差距:尽管性能优异,但模型在合成数据上训练后,与在真实数据上训练的模型之间仍然存在一定的性能差距,这表明虚拟与现实之间的"领域鸿沟"依然是待解决的根本挑战。
- 依赖外部模型:数据和模型的性能上限受限于所使用的外部工具(如Flux、Grounding DINO、SAM)的能力,未来需要随着这些基础模型的升级而迭代。
对于这些缺点,未来的研究可以探索如何通过知识蒸馏等技术将SAM的能力迁移到一个轻量级的网络中,以降低推理成本。同时,可以尝试将该框架拓展到更多视觉任务,如语义分割,或在更具挑战性的长尾分布数据集上验证其应用价值。