作为刚接触深度学习的新手,第一次看到 "张量""自动求导""计算图" 这些概念时,我完全是懵的 ------ 这些词到底是什么意思?PyTorch 又该怎么用?后来慢慢发现,其实不用一开始就纠结复杂公式,先把 PyTorch 当成 "带 GPU 加速的计算器" 和 "自动算导数的工具",反而能快速上手。这篇文章就用最通俗的语言,带你一步步搞懂 PyTorch 的核心逻辑,最后还能跑通一个完整的小案例。
一、先搞明白:PyTorch 到底是个啥?
你可以把 PyTorch 理解成两个 "超级工具包" 的结合体,专门解决深度学习里的两大痛点:
-
"GPU 加速的 NumPy"
- 平时用 Python 处理大数组(比如几百张图片的像素数据)时,CPU 计算会很慢。PyTorch 的 "张量(Tensor)" 能直接把计算放到 GPU 上,速度能翻几十倍,相当于给电脑装了个 "计算加速器"。
-
"自动算导数的计算器"
- 深度学习的核心是 "训练模型"------ 不断调整参数让预测更准,这个过程需要算 "导数"(比如 "参数变 1,预测误差变多少")。手动算导数不仅麻烦,遇到矩阵运算时更是会算到崩溃,而 PyTorch 能自动帮你算好,省去 90% 的数学工作量。
简单说:PyTorch 就是为新手设计的 "深度学习工具箱",语法和 Python 几乎一致,不用额外学一套复杂规则,特别适合入门。
二、核心工具 1:Tensor(张量)------ 一个"超级数组"
Tensor 是 PyTorch 里最基础的数据结构,本质就是 "能在 GPU 上跑的数组"。你可以这样理解它的维度:
- 1 维 Tensor = 普通列表(比如
[1,2,3],可表示一组数据) - 2 维 Tensor = Excel 表格(比如 4 行 3 列,可表示 4 个样本,每个样本 3 个特征)
- 3 维 Tensor = 一堆表格(比如 10 张 4 行 3 列的表格,可表示 10 张黑白图片,每张图片 4×3 像素)
新手必学的 5 个 Tensor 操作
先掌握这几个最常用的操作,直接复制代码到 Python 里就能跑通:
1. 创建 Tensor
最常用的两种创建方式:随机值和全 1 / 全 0 值,就像搭积木的 "基础块"。
python
import torch # 先导入PyTorch库
# 1. 创建4行3列的随机值Tensor(类似NumPy的np.random.randn)
random_tensor = torch.randn(4, 3)
print("随机值Tensor:")
print(random_tensor)
# 2. 创建3行3列全为1的Tensor
ones_tensor = torch.ones(3, 3)
print("\n全1 Tensor:")
print(ones_tensor)
# 3. 创建2行2列全为0的Tensor
zeros_tensor = torch.zeros(2, 2)
print("\n全0 Tensor:")
print(zeros_tensor)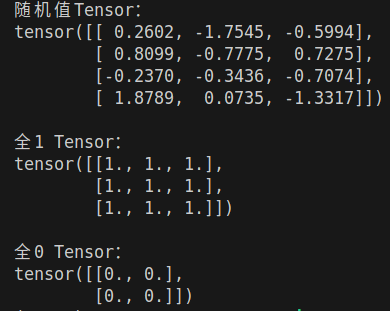
2. 查看 Tensor 的 "基本信息"
拿到一个 Tensor 后,先搞懂它的 "形状""数据类型""在哪个设备(CPU/GPU)上":
python
# 用刚才创建的random_tensor举例
print("Tensor形状(几行几列):", random_tensor.shape) # 也可以用random_tensor.size()
print("Tensor数据类型:", random_tensor.type()) # 比如torch.FloatTensor
print("Tensor维度:", random_tensor.dim()) # 2维(行和列)
print("Tensor总元素数:", random_tensor.numel()) # 4×3=12个元素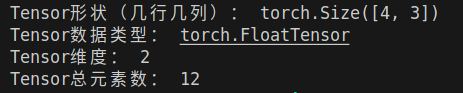
3. CPU 和 GPU 之间迁移
这是 PyTorch 的核心优势!把 Tensor 放到 GPU 上,计算速度会大幅提升:
python
# 先检查电脑有没有GPU(没有也没关系,代码不会报错)
if torch.cuda.is_available():
# 把Tensor放到GPU上
gpu_tensor = random_tensor.cuda()
print("\nGPU上的Tensor:")
print(gpu_tensor)
# 把GPU上的Tensor放回CPU(要转成NumPy必须先放回CPU)
cpu_tensor = gpu_tensor.cpu()
print("\n放回CPU的Tensor:")
print(cpu_tensor)
else:
print("\n没有GPU,继续用CPU计算~")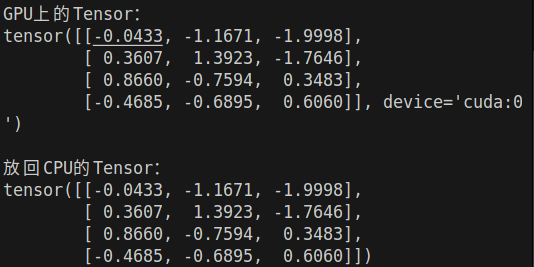
4. Tensor 和 NumPy 互转
有时候需要用 NumPy 的工具处理数据,两者可以无缝切换:
python
import numpy as np # 导入NumPy库
# 1. Tensor转NumPy
tensor_to_np = random_tensor.numpy()
print("\nTensor转NumPy后的类型:", type(tensor_to_np)) # <class 'numpy.ndarray'>
# 2. NumPy转Tensor
np_array = np.random.randn(2, 3) # 创建一个NumPy数组
np_to_tensor = torch.from_numpy(np_array)
print("\nNumPy转Tensor后的类型:", type(np_to_tensor)) # <class 'torch.Tensor'>
5. 常用的数值运算
和 Python 的加减乘除逻辑一样,直接用运算符就行,也可以用torch提供的函数:
(dim表示维度,例如b 是一个 2 维 Tensor ,形状是 (2, 2),可以理解为:
dim=0:代表 第 0 维 → 行(纵向),比如b有 2 行,分别是[1,2]和[3,4];dim=1:代表 第 1 维 → 列(横向),比如b有 2 列,分别是[1,3]和[2,4]。)
python
a = torch.ones(2, 2) # 2×2全1 Tensor
b = torch.tensor([[1,2],[3,4]], dtype=torch.float32) # 2×2的Tensor
# 1. 加法:两种方式都可以
add1 = a + b
add2 = torch.add(a, b)
print("\n加法结果:")
print(add1)
# 2. 乘法(元素对应乘,不是矩阵乘法)
mul1 = a * b
mul2 = torch.mul(a, b)
print("\n元素乘法结果:")
print(mul1)
# 3. 求最大值(dim=1表示按行求最大)
max_value, max_index = torch.max(b, dim=1)
print("\n每行的最大值:", max_value)
print("最大值的位置:", max_index)
# 4. 求和(dim=1表示按行求和)
sum_b = torch.sum(b, dim=1)
print("\n每行的和:", sum_b)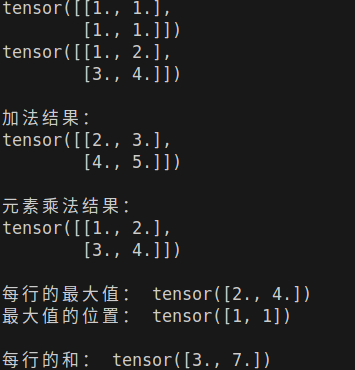
三、核心工具 2:Variable(变量)------ 给 Tensor 装 "记忆功能"
Tensor 只能存数据、算加减乘除,但深度学习需要 "记住每个计算步骤",这样才能后续算导数 ------Variable 就是干这个的:它把 Tensor "包起来",多了 3 个关键属性,相当于给 Tensor 装了 "记忆芯片"。
Variable 的 3 个核心属性
.data:取出 Variable 里面的 Tensor(比如想查看具体数值时用).grad:存储 "导数"(训练时会自动更新,一开始是 0).grad_fn:记录这个 Variable 是怎么来的(比如是 "加法来的" 还是 "乘法来的")
怎么用 Variable?看这个小例子
python
from torch.autograd import Variable # 导入Variable
# 1. 创建Variable:必须指定requires_grad=True才会计算导数
x = Variable(torch.FloatTensor([2]), requires_grad=True) # x=2
y = Variable(torch.FloatTensor([3]), requires_grad=True) # y=3
# 2. 做计算:z = x*2 + y + 5
z = x * 2 + y + 5
# 3. 查看Variable的属性
print("z的值(用.data取Tensor):", z.data) # 结果是2*2+3+5=12
print("z是怎么来的(grad_fn):", z.grad_fn) # 会显示是"加法运算"来的
四、核心功能:自动求导 ------ PyTorch 帮你算导数
这是 PyTorch 最核心的功能之一!不用手动推导公式,一行代码就能算出导数。
先理解:为什么需要求导?
比如你做 "房价预测":x 是 "房子面积",y 是 "预测房价",如果预测值和真实房价差很多,就需要根据 "导数" 调整 x 的权重(比如 "面积每多 1 平米,房价该多涨 1000 还是 2000")------ 导数就是调整的 "方向",决定了参数该变大还是变小。
自动求导的 3 种常见场景
场景 1:对标量求导(最常用)
比如刚才的z = x*2 + y + 5,我们想算 "z 对 x 的导数" 和 "z 对 y 的导数":
python
# 接上面的代码:关键一步------调用backward()求导
z.backward() # 告诉PyTorch"从z开始倒着算导数"
# 查看x和y的导数
print("z对x的导数(x.grad):", x.grad.data) # 结果是2(z对x求导,2的导数是2)
print("z对y的导数(y.grad):", y.grad.data) # 结果是1(z对y求导,y的导数是1)场景 2:对多维 Tensor 求导
如果输出是多维的(比如一个 2×1 的 Tensor),需要给backward()传一个 "权重参数",形状和输出一致:
python
# 创建一个1×2的Variable
m = Variable(torch.FloatTensor([[2, 3]]), requires_grad=True)
n = Variable(torch.zeros(1, 2)) # 空的1×2 Variable
# 计算:n[0,0] = m[0,0]²,n[0,1] = m[0,1]³
n[0, 0] = m[0, 0] ** 2
n[0, 1] = m[0, 1] ** 3
# 多维求导:传一个和n形状一致的权重(这里用全1)
n.backward(torch.ones_like(n)) # torch.ones_like(n)生成1×2的全1 Tensor
# 查看导数:n对m的导数
print("n对m的导数:", m.grad.data) # 结果是[4, 27](2²的导数是4,3³的导数是27)
场景 3:多次求导
如果需要算多次导数,要设置retain_graph=True保留计算图,还要用.zero_()清空之前的梯度(不然梯度会累加):
python
# 创建x
x = Variable(torch.FloatTensor([3]), requires_grad=True)
# 第一次求导
y1 = x ** 2 # y1 = 3²=9
y1.backward(retain_graph=True) # retain_graph=True保留计算图
print("第一次求导(y1对x):", x.grad.data) # 结果是6(3×2)
# 清空梯度
x.grad.data.zero_()
# 第二次求导
y2 = x ** 3 # y2 = 3³=27
y2.backward()
print("第二次求导(y2对x):", x.grad.data) # 结果是27(3²×3)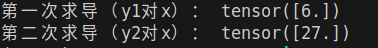
五、为什么 PyTorch 适合新手?因为它是 "动态图"
最后再讲一个 PyTorch 的核心特点:动态图。不用纠结 "图" 是什么,只要记住它的好处就行 ------支持 Python 原生语法,调试超简单。
动态图 vs 静态图(用循环举例)
比如我们想写一个 "循环加 5 次" 的逻辑:
- 静态图框架(比如老版 TensorFlow):需要用专门的
tf.while_loop函数,语法很反直觉; - PyTorch 动态图:直接用 Python 的
while循环,和写普通代码一样。
代码对比:
python
# PyTorch动态图:直接用Python while循环
first_counter = torch.Tensor([0]) # 计数器1,初始值0
second_counter = torch.Tensor([10]) # 计数器2,初始值10
while (first_counter < second_counter)[0]: # [0]是因为Tensor是数组,取第一个元素
first_counter += 2 # 每次加2
second_counter += 1 # 每次加1
print("循环结束后counter1:", first_counter) # 结果是20
print("循环结束后counter2:", second_counter) # 结果是20这种 "写一行算一行" 的逻辑,对新手太友好了 ------ 哪里错了,报错会直接指到哪行,不用在 "定义图" 和 "运行图" 之间来回切换。
六、实战:跑通一个完整流程
最后,我们把前面学的内容串起来,做一个小任务:计算z = (x+2)² + 3,求 x=2 时 z 对 x 的导数(数学结果是 8)。
完整代码如下,复制到 Python 里就能跑通:
python
# 1. 导入需要的库
import torch
from torch.autograd import Variable
# 2. 创建Variable(需要求导)
x = Variable(torch.FloatTensor([2]), requires_grad=True)
# 3. 计算z = (x+2)² + 3
y = x + 2
z = y ** 2 + 3
# 4. 查看z的值
print("z的值:", z.data) # 结果是(2+2)²+3=19
# 5. 自动求导
z.backward()
# 6. 查看x的导数(z对x的导数)
print("z对x的导数:", x.grad.data) # 结果是8,和数学计算一致跑通这段代码,你就已经掌握了 PyTorch 入门的核心逻辑 ------ 后续学深度学习模型(比如线性回归、神经网络),都是基于这些基础操作。
总结
新手入门 PyTorch,不用贪多求全,先掌握这 4 个核心:
- Tensor:处理数据的 "超级数组",需要掌握创建、迁移、基本运算;
- Variable:封装 Tensor,用于构建计算图,记得设
requires_grad=True; - 自动求导:用
backward()算导数,多维求导传权重,多次求导清梯度; - 动态图:支持 Python 原生语法,调试方便,适合快速迭代。
接下来可以尝试更复杂的任务,比如用 Tensor 处理图片数据,或者搭建一个简单的线性回归模型。
