SpeechProbabilityEstimator在WebRTC噪声抑制系统中是语音检测的核心组件。它通过分析多维度声学特征(LRT似然比、谱平坦度、谱差异),基于贝叶斯概率框架实时估计每个频带的语音存在概率。该算法采用特征加权融合和自适应sigmoid映射,结合先验概率平滑更新,为噪声抑制滤波器提供精确的语音/噪声判别依据。其输出的频带概率直接控制噪声谱估计和增益计算,在保持语音质量的同时实现高效噪声消除,是确保语音清晰度和通信质量的关键技术。
1. 核心功能
语音概率估计器 - 用于估计每个频带的语音存在概率,为噪声抑制提供关键的语音/非语音判断依据。
2. 核心算法原理
数学公式与源码注释
// 核心算法基于贝叶斯框架,结合多个声学特征进行概率估计
// 1. LRT(似然比检验)特征处理
// 公式: indicator0 = 0.5 × (tanh(width_prior × (LRT - LRT_threshold)) + 1)
float indicator0 =
0.5f * (tanh(width_prior * (model.lrt - prior_model.lrt)) + 1.f);
// 2. 谱平坦度特征处理
// 公式: indicator1 = 0.5 × (tanh(width_prior × (threshold - flatness)) + 1)
float indicator1 =
0.5f * (tanh(1.f * width_prior *
(prior_model.flatness_threshold - model.spectral_flatness)) +
1.f);
// 3. 谱差异特征处理
// 公式: indicator2 = 0.5 × (tanh(width_prior × (diff - threshold)) + 1)
float indicator2 =
0.5f * (tanh(width_prior * (model.spectral_diff -
prior_model.template_diff_threshold)) +
1.f);
// 4. 特征加权融合
// 公式: ind_prior = w1×indicator0 + w2×indicator1 + w3×indicator2
float ind_prior = prior_model.lrt_weighting * indicator0 +
prior_model.flatness_weighting * indicator1 +
prior_model.difference_weighting * indicator2;
// 5. 先验概率平滑更新(一阶IIR滤波器)
// 公式: P_prior(t) = P_prior(t-1) + 0.1 × (ind_prior - P_prior(t-1))
prior_speech_prob_ += 0.1f * (ind_prior - prior_speech_prob_);
// 6. 贝叶斯后验概率计算
// 公式: P_speech = 1 / (1 + gain_prior × exp(-avg_log_lrt))
// 其中 gain_prior = (1 - P_prior) / P_prior
float gain_prior = (1.f - prior_speech_prob_) / (prior_speech_prob_ + 0.0001f);
speech_probability_[i] = 1.f / (1.f + gain_prior * inv_lrt[i]);3. 关键数据结构
class SpeechProbabilityEstimator {
private:
SignalModelEstimator signal_model_estimator_; // 信号模型估计器
float prior_speech_prob_ = .5f; // 先验语音概率(初始值0.5)
std::array<float, kFftSizeBy2Plus1> speech_probability_; // 各频带语音概率
};4. 核心方法详解
Update 方法工作流程
void SpeechProbabilityEstimator::Update(
int32_t num_analyzed_frames, // 已分析帧数
rtc::ArrayView<const float, kFftSizeBy2Plus1> prior_snr, // 先验信噪比
rtc::ArrayView<const float, kFftSizeBy2Plus1> post_snr, // 后验信噪比
rtc::ArrayView<const float, kFftSizeBy2Plus1> conservative_noise_spectrum, // 保守噪声谱
rtc::ArrayView<const float, kFftSizeBy2Plus1> signal_spectrum, // 信号谱
float signal_spectral_sum, // 信号谱和
float signal_energy) { // 信号能量5. 设计亮点
-
多特征融合:结合LRT、谱平坦度、谱差异三个互补特征
-
自适应宽度参数:根据语音/非语音区域动态调整sigmoid函数宽度
-
概率平滑:使用一阶IIR滤波器平滑先验概率,避免突变
-
频率精细处理:为每个频带独立计算概率,适应不同频段的声学特性
-
数值稳定性:通过clip操作和epsilon防止除零错误
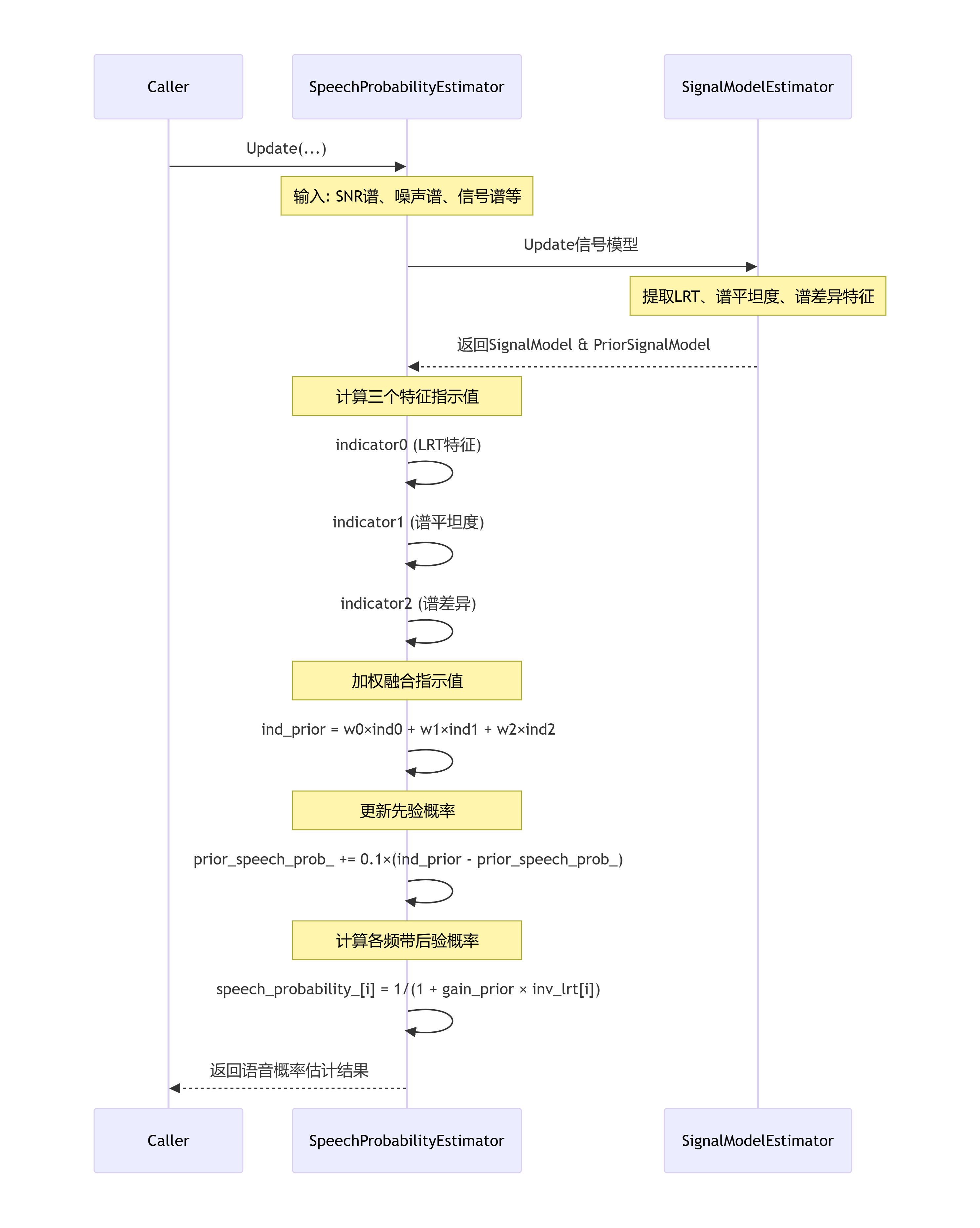
6. 典型工作流程
时序图
流程图
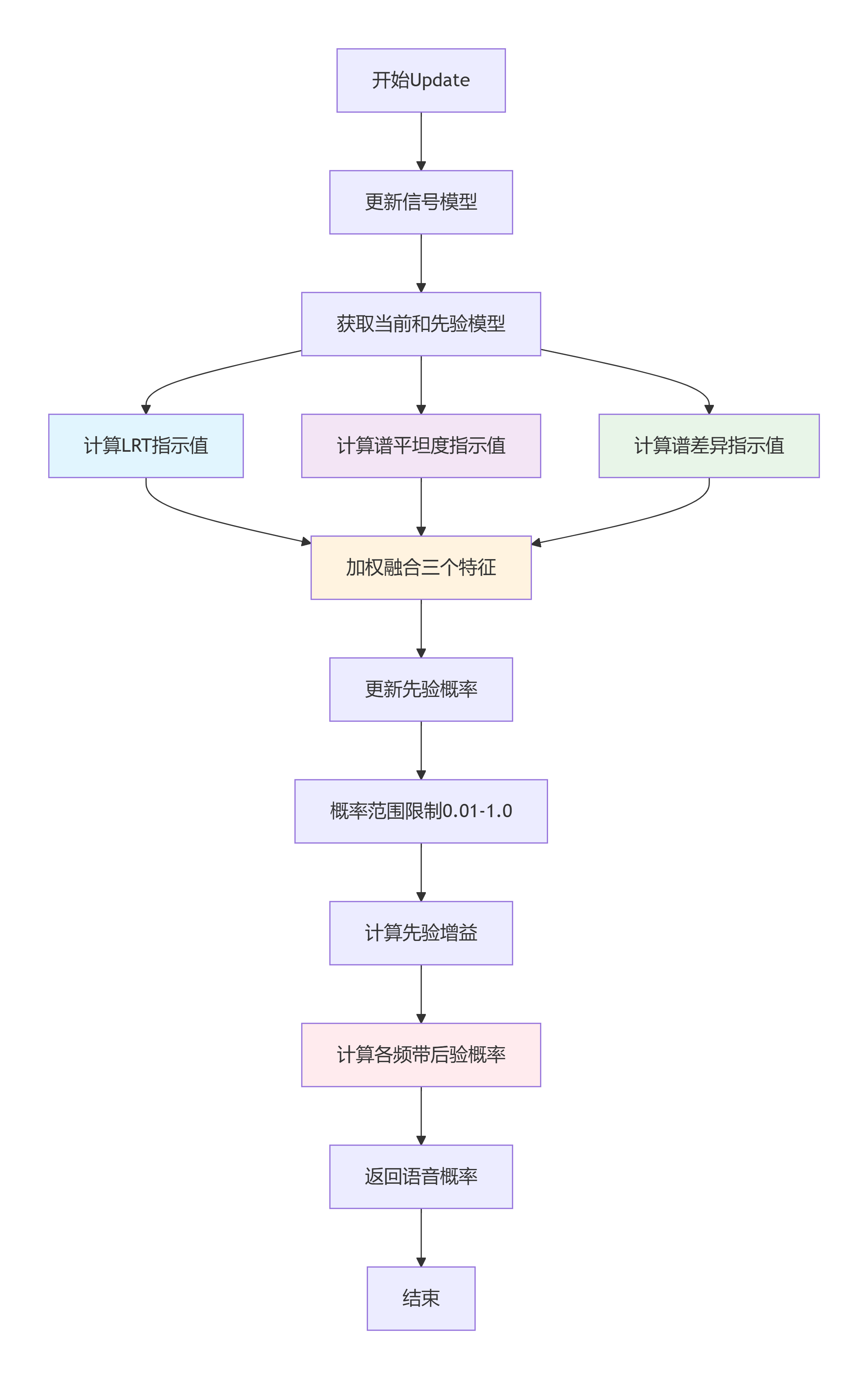
关键步骤说明:
-
模型更新阶段:首先更新底层信号模型,提取当前帧的声学特征
-
特征计算阶段:并行计算三个关键特征的sigmoid映射值
-
决策融合阶段:按预设权重融合三个特征,形成综合判断
-
概率更新阶段:平滑更新先验概率,确保时间连续性
-
频带处理阶段:基于贝叶斯公式计算每个频带的语音存在概率
这种设计确保了算法在各种声学环境下都能稳定工作,为WebRTC的噪声抑制模块提供了可靠的语音/噪声判别基础。