文章目录
一、OpenCV.DNN
OpenCV 的 DNN (Deep Neural Networks,深度神经网络)模块提供了高效的深度学习推理能力,使用户无需依赖完整的深度学习框架,即可在 OpenCV 中直接加载和运行预训练模型,广泛应用于计算机视觉任务。
DNN 模块凭借轻量级、高效性和广泛兼容性,为计算机视觉应用提供了强大的深度学习推理能力,在嵌入式、移动端、工业检测等场景中尤为实用。
1.1、核心功能
- 优势:
- 轻量级:无需额外安装深度学习框架,仅依赖 OpenCV 即可加载和运行模型,简化了集成过程,降低了部署成本。
- 高效推理与多硬件支持:采用高度优化的计算架构,支持多线程和硬件加速,适用于嵌入式设备、移动端和边缘计算场景。同时兼容多种计算后端,包括 CPU(默认)、OpenCL(GPU 加速)、CUDA(NVIDIA GPU 加速)和 OpenVINO(Intel 设备优化),适应不同硬件平台,提高推理性能。
- 易集成:可无缝结合 OpenCV 其他功能,如图像处理、视频分析等,实现从数据预处理到深度学习推理的完整流程。
- 格式兼容性强:支持多种主流深度学习框架的模型格式(Caffe、TensorFlow、Torch、ONNX、YOLO 等),便于迁移已有模型。
- 丰富的应用场景:适用于 目标检测、图像分类、语义分割、人脸识别、姿态估计 等计算机视觉任务。
- 局限性:
仅支持推理,不支持训练:OpenCV DNN 仅用于模型推理,无法直接训练深度学习模型。。需在 TensorFlow、PyTorch、Caffe 等框架中完成训练后,再导出模型进行推理。- 模型转换要求:部分模型需先转换到 OpenCV 兼容格式(如 ONNX),转换过程中可能会遇到运算层支持不全的问题,需手动调整或优化。某些新架构(如 Transformer、Diffusion Models)可能尚未完全支持。
- GPU 加速优化有限:尽管支持 OpenCL 和 CUDA,但相较于专业推理引擎(如 TensorRT、cuDNN),性能优化仍有一定差距,特别是在高并发、低延迟任务场景下。
- 部分新模型兼容性受限:DNN 模块的部分运算层更新可能落后于主流深度学习框架,某些最新模型(如 ViT、Swin Transformer)可能无法直接加载。YOLOv6 及以上版本 需要转换为 ONNX 后才能使用。
- 缺乏自动优化:OpenCV DNN 不具备 TensorRT 等推理引擎的自动图优化、动态批量处理等能力。在大规模模型部署时,可能需要手动优化推理流程,如裁剪无用层、量化模型等,以提高效率。
1.2、支持多框架
OpenCV 的 DNN 模块能够加载来自多种主流深度学习框架的预训练模型,支持多种格式,便于跨平台部署和推理。
- Caffe:
- 支持格式:
.prototxt(网络结构)+.caffemodel(训练权重)- 兼容性:广泛支持,OpenCV 可直接解析 Caffe 模型进行推理。
- TensorFlow:
- 支持格式:
.pb(冻结的计算图)- 兼容性:支持大部分标准 TensorFlow 模型,但部分自定义操作可能需要转换或优化。
- Torch/PyTorch:
- 支持格式:需将 .pt、.pth 转换为 OpenCV 兼容格式(如 ONNX)后才能加载
- ONNX(Open Neural Network Exchange):
- 支持格式:
.onnx- 应用场景:OpenCV 从 4.5 版本起支持 ONNX 格式,ONNX 是一种开放的神经网络交换格式,允许不同框架之间的模型互操作。
- Darknet(YOLO 模型):
- 支持格式:
.cfg(模型结构)+.weights(模型权重)- 应用场景:主要用于 YOLO(You Only Look Once)系列目标检测任务,如 YOLOv3、YOLOv4、YOLOv5 等,但不支持 YOLOv6 及更新版本(建议转换为 ONNX)。
1.3、项目类型
OpenCV 的 DNN 模块可以通过加载预训练的深度学习模型进行多种计算机视觉任务,如:
| 项目类型 | 功能 | 推荐模型 |
|---|---|---|
| 图像分类(Image Classification) | 识别图像中的物体或场景,例如分类常见物体(如猫、狗、车等)。 | GoogLeNet、ResNet、MobileNet |
| 目标检测(Object Detection) | 检测图像或视频流中的目标(如人脸、行人、车辆等),并标记出目标的位置。 | YOLO、SSD、Faster R-CNN |
| 图像分割(Image Segmentation) | 将图像中的不同区域进行分割,通常用于语义分割任务。 | DeepLabv3、ENet |
| 人脸检测与识别(Face Detection & Recognition) | 识别图像中的人脸并进行身份验证。 | OpenCV DNN、Dlib |
| 姿态估计(Pose Estimation) | 估计人体各部位的姿态,用于人体跟踪和动作识别。 | OpenPose、MediaPipe |
| 文字检测与识别(OCR) | EAST、CRNN |
语义分割(DeepLabV3) 有版本限制问题(只支持旧版本),暂不研究
1.4、详细步骤
在 OpenCV 的 DNN 模块中,加载和运行深度学习模型的基本流程如下:
- 加载模型:
cv2.dnn.readNetFromXXX()读取模型文件。支持多种模型格式的加载,如:
- cv2.dnn.readNetFromCaffe(prototxt, model) ------ 适用于 Caffe 模型 (.prototxt 配置文件 + .caffemodel 权重文件)。
- cv2.dnn.readNetFromTensorflow(model, config) ------ 适用于 TensorFlow 模型 (.pb 或 .pbtxt 文件)。
- cv2.dnn.readNetFromONNX(model) ------ 适用于 ONNX 格式的模型 (.onnx 文件)。
- cv2.dnn.readNetFromDarknet(cfg, weights) ------ 适用于 YOLO(Darknet)模型 (.cfg 配置文件 + .weights 权重文件)。
- 预处理输入:使用
cv2.dnn.blobFromImage()将图像转换为适合网络输入的格式(通常是张量)。- 设置输入:
net.setInput(blob)传入数据。- 前向传播:
net.forward()执行前向传播,获取模型的预测结果。对于不同的模型,输出的格式不同:
- 图像分类:通常返回一个 N 类别 的 概率数组。
- 目标检测:返回多个边界框信息(类别、置信度、坐标)。
- 图像分割:返回像素级的类别标签。
- 解析输出:根据任务类型(分类/检测/分割)进行后处理。
二、项目实战
https://github.com/opencv/opencv_extra/tree/4.x/testdata/dnn
2.1、图像分类(GoogleNet)
本项目将使用 OpenCV 的 dnn 模块加载 GoogleNet 预训练模型,并基于 ImageNet 数据集的类别标签对输入图像进行分类。
(1)必需文件
(1)预训练模型下载:
(2)预训练模型基于 ImageNet 数据集(1000 个类别),类别标签可在以下路径下载:
类别标签(synset_words.txt):https://github.com/HoldenCaulfieldRye/caffe/blob/master/data/ilsvrc12/synset_words.txt
BVLC(Berkeley Vision and Learning Center,伯克利视觉与学习中心)是加州大学伯克利分校(UC Berkeley)计算机视觉研究小组的名称。在深度学习领域,BVLC 主要与 Caffe(一个流行的深度学习框架)相关联。BVLC 负责 Caffe 的开发和维护,并提供了一些预训练模型,例如 bvlc_googlenet、bvlc_alexnet 和 bvlc_reference_caffenet 等。
因此,bvlc_googlenet 代表的是由 BVLC 训练和发布的 GoogLeNet 模型,该模型基于 2014 年的 GoogLeNet(Inception v1) 架构,并用于 ImageNet 图像分类任务。
(2)代码复现(图像)

python
import cv2
import numpy as np
# 1. 预训练模型路径
MODEL_PATH = "bvlc_googlenet.caffemodel"
PROTO_PATH = "bvlc_googlenet.prototxt"
LABELS_PATH = "synset_words.txt"
IMAGE_PATH = "beer.png"
# 2. 读取类别标签
with open(LABELS_PATH, "r") as f:
labels = [line.strip() for line in f.readlines()]
# 3. 加载 OpenCV DNN 模型
net = cv2.dnn.readNetFromCaffe(PROTO_PATH, MODEL_PATH)
# 4. 读取并预处理图像
image = cv2.imread(IMAGE_PATH)
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(224, 224),
mean=(104, 117, 123), swapRB=False, crop=False)
# 5. 进行推理
net.setInput(blob)
output = net.forward()
# 6. 获取最可能的类别
class_id = np.argmax(output)
confidence = float(output[0][class_id])
# 7. 输出分类结果
print(f"Predicted: {labels[class_id]} ({confidence * 100:.2f}%)")
# 8. 在图像上显示类别
text = f"{labels[class_id]}: {confidence * 100:.2f}%"
cv2.putText(image, text[10:], (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("Image Classification", image)
cv2.waitKey(0)
cv2.destroyAllWindows()2.2、人脸检测(ResNet)
在本项目中,我们将使用 OpenCV 的 DNN 模块来进行 人脸检测。我们将使用预训练的人脸检测模型,例如 ResNet 或 MobileNet,这类模型可以直接通过 OpenCV DNN 模块加载并使用。
(1)必需文件
(2)代码复现(图像)

python
import cv2
import numpy as np
# 加载 Caffe 模型
prototxt = 'deploy.prototxt'
caffe_model = 'res10_300x300_ssd_iter_140000.caffemodel'
net = cv2.dnn.readNetFromCaffe(prototxt, caffe_model)
# 读取图像
image = cv2.imread('image.jpg')
(h, w) = image.shape[:2]
# 预处理图像并进行推理
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0), swapRB=False, crop=False)
net.setInput(blob)
detections = net.forward()
# 在图像中标出检测到的人脸
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
# 如果检测的置信度高于阈值
if confidence > 0.5:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# 在图像上绘制矩形框
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Face Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()(3)代码复现(视频)
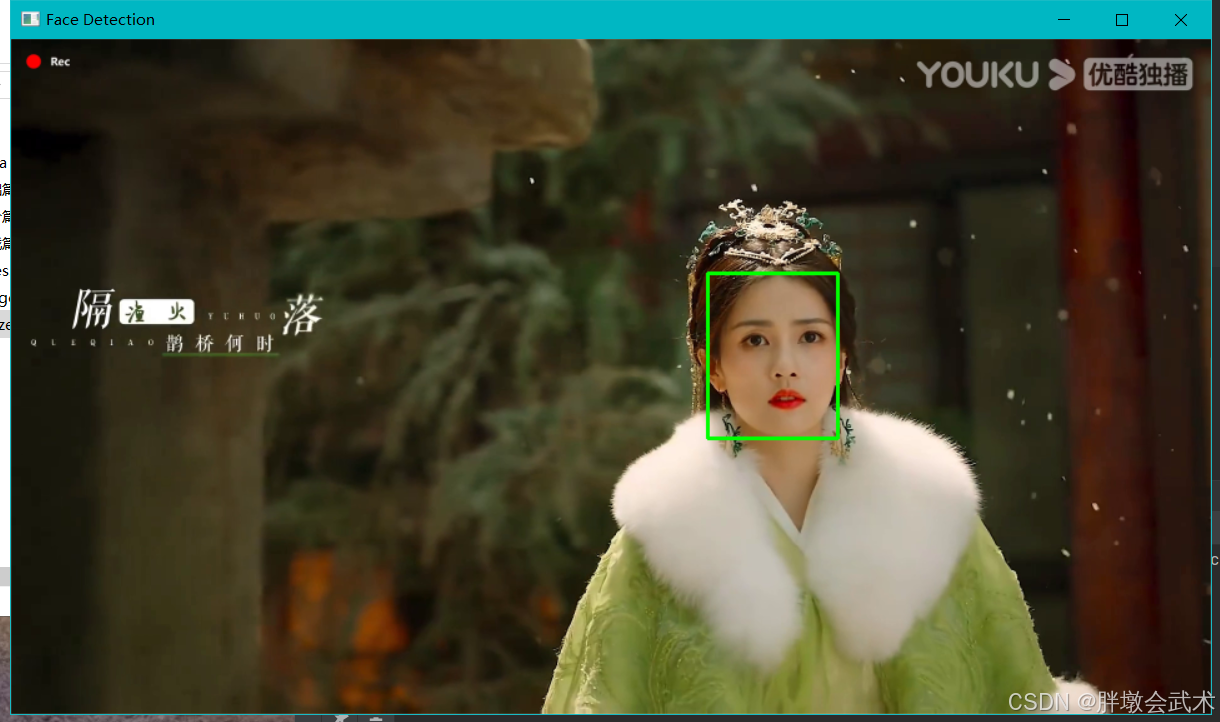
python
import cv2
import numpy as np
# 加载 Caffe 模型
prototxt = 'deploy.prototxt'
caffe_model = 'res10_300x300_ssd_iter_140000.caffemodel'
net = cv2.dnn.readNetFromCaffe(prototxt, caffe_model)
# 打开视频源(0表示默认摄像头)
cap = cv2.VideoCapture(0) # 如果要使用视频文件,可以替换为 'video_file_path.mp4'
while True:
# 读取视频帧
ret, frame = cap.read()
if not ret:
break
# 获取帧的高和宽
(h, w) = frame.shape[:2]
# 预处理图像并进行推理
blob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300), (104.0, 177.0, 123.0), swapRB=False, crop=False)
net.setInput(blob)
detections = net.forward()
# 在帧中标出检测到的人脸
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
# 如果检测的置信度高于阈值
if confidence > 0.5:
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# 在图像上绘制矩形框
cv2.rectangle(frame, (startX, startY), (endX, endY), (0, 255, 0), 2)
# 显示帧
cv2.imshow('Face Detection', frame)
# 按 'q' 键退出视频显示
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放视频流和关闭窗口
cap.release()
cv2.destroyAllWindows()2.3、目标检测(YOLO)
本项目使用 OpenCV 的 dnn 模块加载 YOLOv4 预训练模型,并基于 COCO 数据集的类别标签对输入图像进行目标检测,并可视化检测结果。
(1)必需文件
- (1)预训练模型下载:
- (2)预训练模型基于 COCO 数据集(80 个类别),类别标签可在以下路径下载:
类别标签(coco.names):https://github.com/pjreddie/darknet/blob/master/data/coco.names- (3)使用任意图片进行测试
测试图像(example.jpg):https://upload.wikimedia.org/wikipedia/commons/6/60/Naxos_Taverna.jpg
(2)代码复现(图像)
下载 YOLOv4 模型权重、配置文件和类别标签,放入当前目录。

python
import cv2
import numpy as np
# 1. 设置 YOLO 模型路径
MODEL_CFG = "yolov4.cfg"
MODEL_WEIGHTS = "yolov4.weights"
LABELS_PATH = "coco.names"
IMAGE_PATH = "image.jpg"
# 2. 读取类别标签
with open(LABELS_PATH, "r") as f:
labels = [line.strip() for line in f.readlines()]
# 3. 生成随机颜色用于绘制检测框
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(labels), 3), dtype="uint8")
# 4. 加载 YOLO 模型
net = cv2.dnn.readNetFromDarknet(MODEL_CFG, MODEL_WEIGHTS)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
# 5. 读取输入图像
image = cv2.imread(IMAGE_PATH)
(H, W) = image.shape[:2]
# 6. 获取 YOLO 输出层
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
# 7. 预处理图像
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255.0, size=(416, 416),
swapRB=True, crop=False)
net.setInput(blob)
# 8. 进行目标检测
layer_outputs = net.forward(output_layers)
# 9. 解析检测结果
boxes = []
confidences = []
class_ids = []
for output in layer_outputs:
for detection in output:
scores = detection[5:] # 获取每个类别的置信度
class_id = np.argmax(scores) # 最高分数的类别索引
confidence = scores[class_id] # 最高类别的置信度
if confidence > 0.5: # 设定置信度阈值
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 计算边界框的左上角坐标
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
class_ids.append(class_id)
# 10. 执行非极大值抑制(NMS),去除冗余检测框
indices = cv2.dnn.NMSBoxes(boxes, confidences, score_threshold=0.5, nms_threshold=0.4)
# 11. 绘制检测框
if len(indices) > 0:
for i in indices.flatten():
(x, y, w, h) = boxes[i]
color = [int(c) for c in COLORS[class_ids[i]]]
label = f"{labels[class_ids[i]]}: {confidences[i]:.2f}"
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2)
cv2.putText(image, label, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
0.5, color, 2)
# 12. 显示结果
cv2.namedWindow("YOLO Object Detection", cv2.WINDOW_KEEPRATIO)
cv2.imshow("YOLO Object Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()(3)代码复现(视频)

python
import cv2
import numpy as np
# 1. 设置 YOLO 模型路径
MODEL_CFG = "yolov4.cfg"
MODEL_WEIGHTS = "yolov4.weights"
LABELS_PATH = "coco.names"
VIDEO_PATH = "video.mp4" # 测试视频路径
# 2. 读取类别标签
with open(LABELS_PATH, "r") as f:
labels = [line.strip() for line in f.readlines()]
# 3. 生成随机颜色用于绘制检测框
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(labels), 3), dtype="uint8")
# 4. 加载 YOLO 模型
net = cv2.dnn.readNetFromDarknet(MODEL_CFG, MODEL_WEIGHTS)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
# 5. 读取视频
cap = cv2.VideoCapture(VIDEO_PATH)
if not cap.isOpened():
print("Error: 无法打开视频文件")
exit()
# 6. 获取 YOLO 输出层
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
# 7. 处理视频帧
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break # 视频播放结束
(H, W) = frame.shape[:2]
# 预处理图像
blob = cv2.dnn.blobFromImage(frame, scalefactor=1 / 255.0, size=(416, 416),
swapRB=True, crop=False)
net.setInput(blob)
# 进行目标检测
layer_outputs = net.forward(output_layers)
# 解析检测结果
boxes = []
confidences = []
class_ids = []
for output in layer_outputs:
for detection in output:
scores = detection[5:] # 获取每个类别的置信度
class_id = np.argmax(scores) # 最高分数的类别索引
confidence = scores[class_id] # 最高类别的置信度
if confidence > 0.5: # 设定置信度阈值
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 计算边界框的左上角坐标
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
class_ids.append(class_id)
# 执行非极大值抑制(NMS),去除冗余检测框
indices = cv2.dnn.NMSBoxes(boxes, confidences, score_threshold=0.5, nms_threshold=0.4)
# 绘制检测框
if len(indices) > 0:
for i in indices.flatten():
(x, y, w, h) = boxes[i]
color = [int(c) for c in COLORS[class_ids[i]]]
label = f"{labels[class_ids[i]]}: {confidences[i]:.2f}"
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
cv2.putText(frame, label, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
0.5, color, 2)
# 显示视频
cv2.namedWindow("YOLO Object Detection", cv2.WINDOW_KEEPRATIO)
cv2.imshow("YOLO Object Detection", frame)
if cv2.waitKey(1) & 0xFF == ord("q"): # 按 'q' 退出
break
# 8. 释放资源
cap.release()
cv2.destroyAllWindows()