文章目录
- 前言
- 一、listen的第二个参数backlog作用是什么?
- 二、监听套接字中的全连接队列和监听套接字的接收缓冲区是不是一回事儿?
- 三、理解全连接队列(模型角度)
- 四、理解全连接队列(内核角度)
-
- [一次 read 调用的完整穿越之旅](#一次 read 调用的完整穿越之旅)
- 五、倒回来细看源码
-
- [struct socket](#struct socket)
- [struct sock](#struct sock)
- [struct tcp_sock](#struct tcp_sock)
- [struct sk_buff](#struct sk_buff)
- [struct request_sock_queue](#struct request_sock_queue)
- 六、最后再理解三次握手
- 七、最后理解网络通信
- 总结
前言
好了,终于来到了我们TCP的最后一篇啦,我真的保证这是最后一篇了,不会再有新的了,这次我主要就是从源码内核的角度跟大家谈谈 SOCKET网络编程 的本质!
一、listen的第二个参数backlog作用是什么?
答案是 backlog + 1 = TCP全连接队列的容量
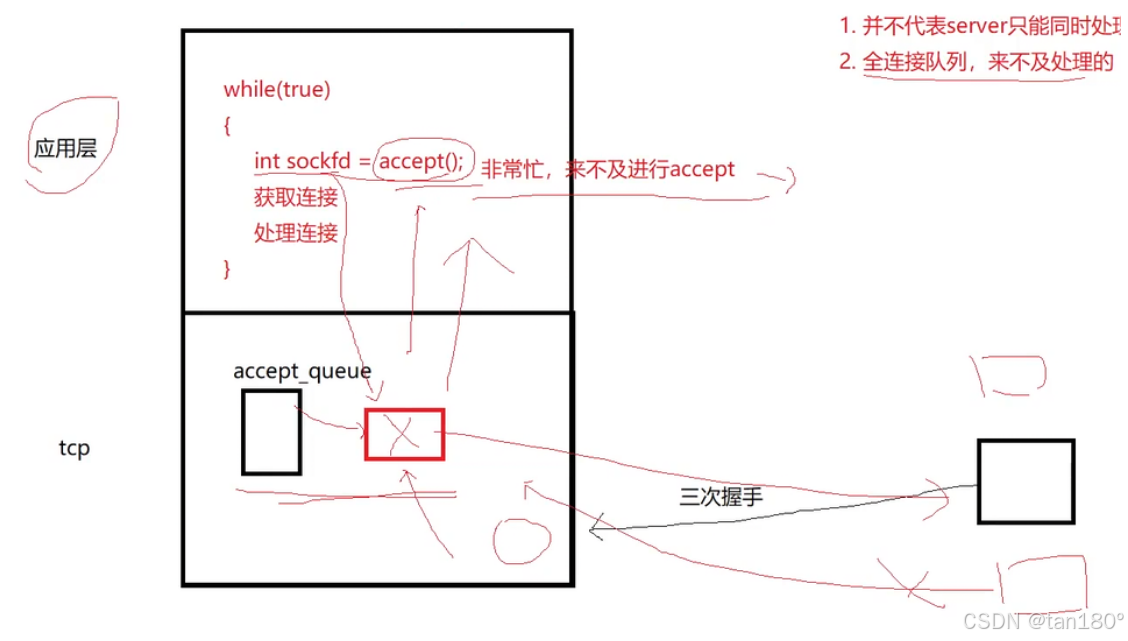
值得注意的是,三次握手建立连接的过程和用户是否 accept 无关 ,在服务器来不及进行 accept 的时候,底层的 TCP listen socket 依然允许用户通过三次握手,成功建立连接,建立好之后,该链接就会被插入到全连接队列中,但是不运行建立太多链接 ---- 当全连接队列中存的链接数量达到上限 backlog + 1 之后,TCP listen socket 就会拒绝来自用户的新 TCP 链接请求了
通过上面的描述我们知道,即使我服务器端不调用 accept 去接受连接,客户端也能与服务器通过三次握手成功建立 TCP 链接,那假如说服务器中的 TCP全连接队列 满了,也就是它的容量达到了 backlog + 1 ,那后面服务器就不能继续建立新链接了,这时候如果有客户端向服务器发起了新的连接请求,服务器会怎么处理呢
这就牵扯到我们的另一个队列------未完成队列(也叫半连接队列)
(1)服务器会先去查看全连接队列有没有满
(2)如果满了,则会进一步查看未完成队列有没有满
如果未完成队列有空间,服务器会正常回应 SYN + ACK,将连接放入未完成队列(这一步不受全连接队列的影响!)
但如果未完成队列也满了(极端情况,比如服务器被 SYN flood 攻击),服务器才会忽略或拒绝新请求
只有当未完成队列也满时,新的 SYN 请求才会被 "丢弃或拒绝"
此时服务器无法再处理新的半连接,才会出现 "忽略 SYN 或发 RST" 的行为
二、监听套接字中的全连接队列和监听套接字的接收缓冲区是不是一回事儿?
当然不是一回事,简单来说就是,接收缓冲区中存放的是对端发来的请求报文,这是客户端发起三次握手的标志。当客户端与服务器完成了三次握手之后,我们才会为这个建立起来的连接创建一个结构体,插入到监听套接字的全连接队列中

如果你还不明白,这里有个图方便你理解这三者之间的关系

三、理解全连接队列(模型角度)
说白了,这玩意儿其实就是一个生产消费者模型。全连接队列就是模型中的缓冲区,应用层(消费者)调用 accept 不断地从全连接队列中获取连接,客户端(生产者)不断的通过三次握手向队列中插入新建立的连接
生产者消费者模型真的蛮多应用的,假如面试这么一问,应该要立刻想起来好多回答
全连接队列的容量上限,是不是服务器处理并发请求能力的上限呢?
其实不是,全连接队列的容量我们经常设置地比较小,可能是10,可能是5,但这并不意味着服务器一次最多只能并发处理5个请求,实际上服务器的并发请求处理能力比这多得多,DS大人给出的答案如下:

既然如此,为什么全连接队列的容量上限不设置大一些呢?
答案是设置大一些,那么这个队列就很长,对于那些还在长队列的末端的请求来说,其所属的用户要等待的时间就非常长,这会给用户造成非常不好的体验感。与其如此还不如在用户请求连接时,直接告诉他我这边儿满了,你先去干会儿别的事情,过一段时间再来找我吧。这样还干脆一点。用户的体验也就没那么糟糕。
四、理解全连接队列(内核角度)
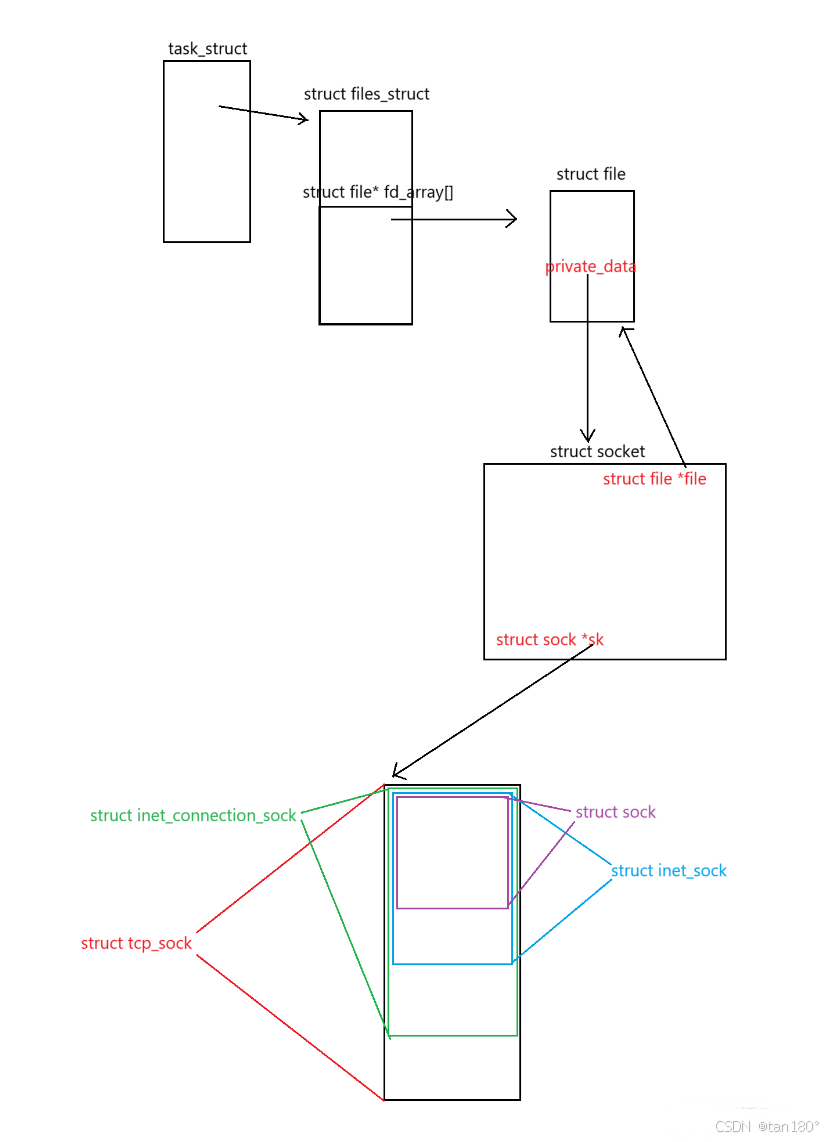
我们都知道。在操作系统看来一切皆文件。而操作系统管理文件的方式。主要是通过 进程PCB(task_struct)中的进程打开文件表(struct files_struct),进程打开文件表中有一个 fd_array 数组 ,里面具体记录了当前进程打开了哪些文件。如果 fd_array 数组中某个元素不为空指针,那它里面存的指针指向的就是一个 struct file类型 的结构体,用来描述一个打开的文件。这个 struct file 中记录的有文件的静态数据(包括 文件元数据,文件inode以及文件操作方法 ),也有文件的动态数据(比如 读写指针、IO缓冲区 这种会随着进程运行状态不断变化的数据)
对于服务器端一个建立好的 TCP链接 来说,他其实最终也会被封装到一个 struct file 类型的结构体中,然后这个结构体的指针会被存放在当前进程文件打开表的 fd_array 中,操作系统通过对这个套接字文件的写操作,最终实现向对端发数据,通过对这个套接字文件的读操作,最终实现接受对端发来的数据
但实际上我们说,我们在程序中通过 read 系统调用 ,对这个套接字文件进行读操作,实际上干的事情仅仅是将数据从套接字文件的接受缓冲区中读取到程序中;我们在程序中通过 write 系统调用 ,对这个套接字文件进行写操作,实际上干的事情仅仅是将数据从用户区写入套接字文件的发送缓冲区(位于内核区)中。那实际上更进一步的工作,比如数据是如何从对端的发送缓冲区发送到我指定套接字文件的接收缓冲区中的,这个过程由操作系统和网络协同自动实现
tcp全连接队列在哪个结构体中?发送缓冲区和接收缓冲区在哪个结构体中?一个tcp连接应该会被描述成一个结构体,这个结构体是什么?
别急,我会从图形和源码的角度将给你听:
我让DS大人生成了一个这样的图示
另外我把生成的文案给复制过来:
生动讲解:一次 read 系统调用的穿越之旅
现在,让我们扮演一个数据包,当服务器应用程序执行 read(fd, buf, size) 时,看看内核如何通过这条链找到我们。
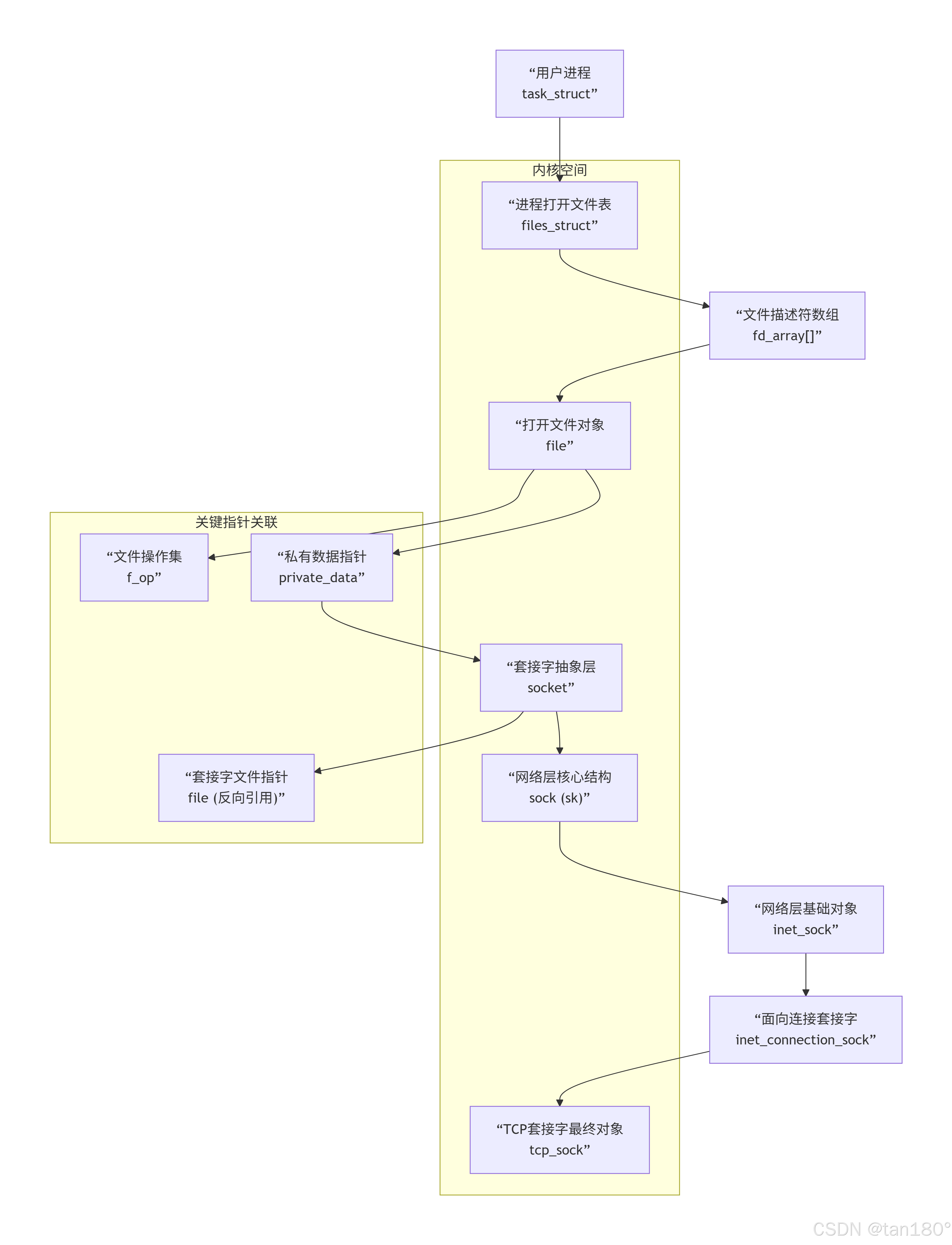
第一站:用户进程 (task_struct)
角色 :整个故事的发起者。好比一家公司的老板(应用程序)下达指令:"从1号渠道(fd )读点东西进来。"
内核定位 :内核通过当前指针可以找到这个进程的 task_struct。这是进程的身份证和总控制台。
第二站:文件表 (files_struct) 与文件描述符 (fd_array\[\])
角色 :老板的秘书处。task_struct 内嵌了一个 files_struct ,它就是公司的文件管理部。
寻址 :秘书处有一个非常重要的文件索引表 (fd_array\[\] )。老板说"1号渠道",秘书就翻开这个表,找到第1项。
收获 :索引表里存的不是文件本身,而是一个"工作单"的地址,这个"工作单"就是 struct file* 。
第三站:打开文件对象 (struct file)
角色 :具体工作单。它描述了一个被打开的文件(或设备、套接字)的动态信息。
关键字段:
f_op :这是工作手册。里面写明了对于这种类型的"文件",具体的"读"、"写"等操作应该怎么做。对于套接字,这里指向的是网络协议栈定义的函数,而不是磁盘操作的函数。
private_data :这是机密附件。它是一个 void * 指针,指向与这个"工作单"相关的、更深层次的专业数据。对于套接字,这里指向的是 struct socket 。
至此,控制权从通用的"文件管理"移交到了专门的"网络部门"。
第四站:套接字抽象层 (struct socket)
角色 :网络事务专员。它是内核为网络操作设计的一个抽象接口。
关键字段:
file :反向链接。指回上面的 struct file 工作单。这样可以从网络部门也能找到对应的文件信息。
sk :核心专家。这是整个链条中最关键的桥梁。它指向 struct sock,从此进入了真正的网络协议栈世界。
第五站及以后:网络协议栈核心 (struct sock -> struct tcp_sock)
从这里开始,是一系列通过结构体继承(C语言中通过内嵌结构体实现 ,可以称得上是C语言的继承风格了)构成的"俄罗斯套娃",体现了面向对象的思想。
struct sock :网络连接总工程师。它是一个通用的网络连接结构,包含了所有网络层(IP)和传输层(TCP/UDP)需要的公共核心状态,比如:
发送/接收缓冲区队列
序列号、确认号
窗口大小
连接状态(ESTABLISHED, TIME_WAIT等)
定时器(重传、保活)
struct inet_sock :IP网络专家。它"继承"了 struct sock,增加了IP层相关的信息,如IP地址、端口号。
struct inet_connection_sock :面向连接专家。它"继承"了 struct inet_sock,增加了面向连接协议(主要是TCP)的公共逻辑,如接受队列、请求队列。
struct tcp_sock :TCP协议大师。这是最终的Boss级结构体。它"继承"了 struct inet_connection_sock,包含了TCP协议所有的私有和精细状态,比如:
拥塞控制状态(snd_cwnd, ssthresh)
丢失恢复状态(快速重传、SACK)
大量的统计信息和优化变量
总结与意义
当 read 调用最终执行到 file->f_op->read 时,它实际上调用的是类似 sock_read 的函数。这个函数会:
通过 file->private_data 找到 struct socket 。
通过 socket->sk 找到 struct sock 。
由于这个连接是 TCP连接 ,内核可以通过容器宏(如 inet_csk , tcp_sk )将 struct sock * 指针安全地向上转换为其真实的类型------struct tcp_sock 。
最终,在这个庞大的 tcp_sock 对象中,找到接收缓冲区,将数据从内核空间拷贝到用户空间。
因此,这一系列结构体的关系,是一个从抽象到具体的"寻宝图"。它使得简单的文件操作接口能够驾驭复杂的网络通信,是 Linux内核 高内聚、低耦合 设计哲学的完美体现。每一个文件描述符背后,都可能关联着一个代表了整个 TCP连接 状态的、极其复杂的"生命体"。
或者我让DS大人再次加工了一下这段话,或许会让你有个更加深刻的理解,估计会让你对 "Linux下一切皆文件" 这段话有一个更加深刻的认识!
一次 read 调用的完整穿越之旅
当服务器进程执行 read(fd, buf, size) 时,一场精妙的内核寻址与数据传递开始了:
-
旅程的起点:找到当前进程的"总部"
通过当前CPU的寄存器或特定的内核数据结构,内核能瞬间定位到当前正在执行的进程的 task_struct 。这就好比GPS直接定位到了公司总部的坐标。这个 task_struct 是进程在内核中的完整化身,是所有操作的起点。
-
获取"通行证":从文件描述符到文件对象
内核沿着 task_struct -> files_struct -> fd_arrayfd 这条路径,找到了对应的 struct file * 。这个 struct file 就是内核颁发的"通行证",它统一代表了所有被打开的资源。在这里,内核完成了第一次,也是至关重要的一次抽象:无论背后是磁盘、管道还是网络套接字,在应用程序看来,它们都是可以通过 read/write 操作的文件。
-
抵达"交叉路口":f_op 与 private_data 的分流
现在,内核站在了 struct file 这个交叉路口。它有两个关键路标:
1、f_op (操作手册):它决定了"读"这个动作的具体实现。对于普通文件,它指向文件系统的函数;对于套接字,它则指向网络协议栈的 sock_read_iter 等函数。这正是C语言实现多态 的核心机制------通过函数指针表,同一接口(read )在不同对象上产生不同行为。
2、private_data (专用通道):这是一个 void * 指针,指向该"文件"特有的数据结构。对于套接字,它指向 struct socket ;对于其他类型,如打开一个普通文件,它可能指向该文件在内存中的 inode 结构;对于设备文件,它可能指向设备驱动定义的私有数据。 至此,通用文件操作正式切换到网络专用路径。
-
深入网络协议栈:从抽象到具体的"降维"
通过 private_data 找到 struct socket (网络事务专员)后,内核立刻通过其 sk 字段抓住了核心------ struct sock *(网络连接总工程师)。由于 TCP连接 的复杂性,一个通用的 struct sock 远不足以描述其全貌。因此,Linux内核采用了C风格的继承 :
struct tcp_sock 内嵌了 struct inet_connection_sock ,后者又内嵌了 struct inet_sock ,最终内嵌了 struct sock 。通过 container_of 这类神奇的容器宏,内核可以将一个 struct sock * 指针"向上转换"为其真实的、更具体的类型 struct tcp_sock *。这完美体现了面向对象的多态思想:将 struct sock * 视为基类指针,而 struct tcp_sock 则是派生类,在需要时能访问到完整的派生类成员。 -
旅程的终点:数据交付
现在,内核终于在这个庞大的、包含了所有TCP状态 (序列号、窗口、拥塞控制、缓冲区等)的 struct tcp_sock 对象中,找到了接收缓冲区。它将数据从这片内核空间拷贝到用户空间的 buf 中,read 系统调用遂告完成,成功返回。
跟普通文件的对比如下:
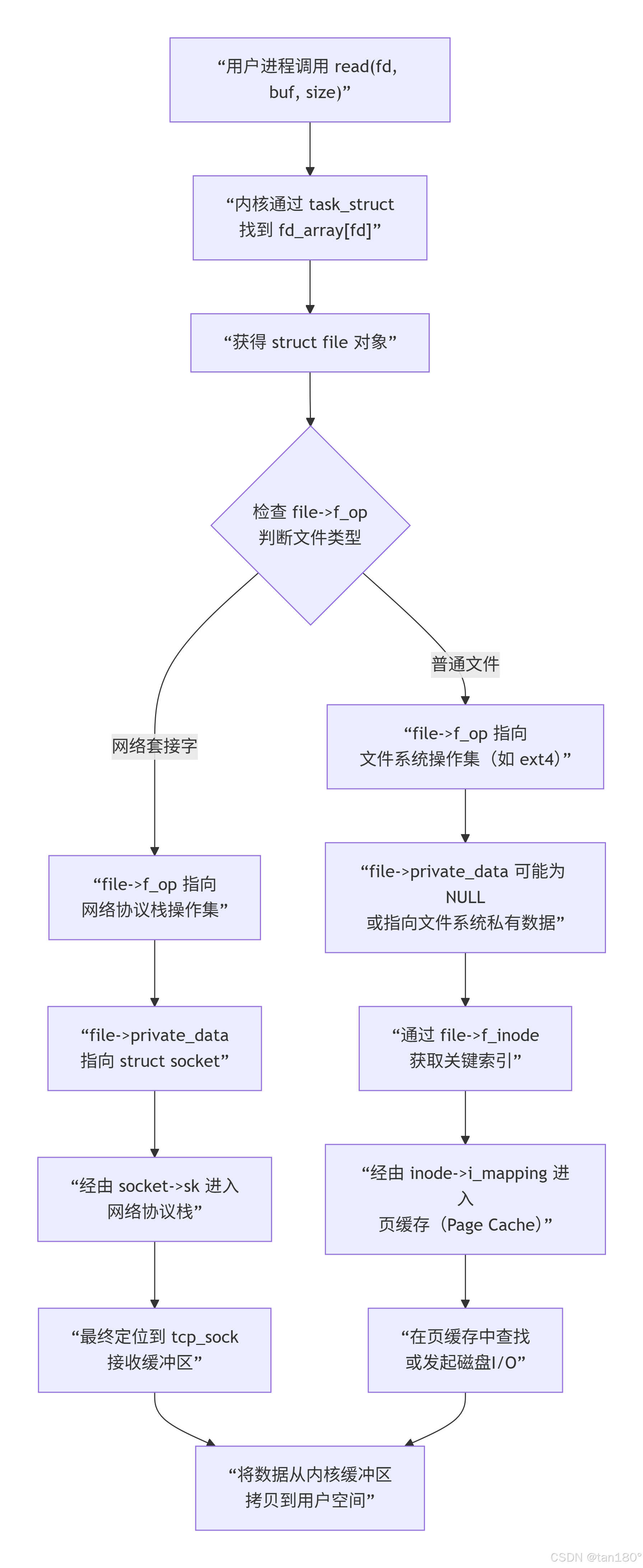
简单来说,读取普通文件,是一次"向内存管理者(页缓存)查询,必要时归档员(文件系统)从仓库(磁盘)调档"的过程;而读取套接字,则是一次"与远程同事(TCP连接)实时通信,从收件箱(接收缓冲区)取件"的过程。 二者在顶层接口上完美統一,却在底层实现上各展神通。
而且你会发现,这个结构体继承体系中,tcp比udp多嵌套了一层,所以才有的面向连接与不面向连接,全差在这一层 struct inet_connection_sock 上面了
哦别忘了还有一个这个结构体 struct sk_buff ,这个就是我们所说的在网络中传输的数据包,贯穿了整个网络协议栈,操作系统也可以通过数据结构将把组织起来来管理

五、倒回来细看源码
struct socket
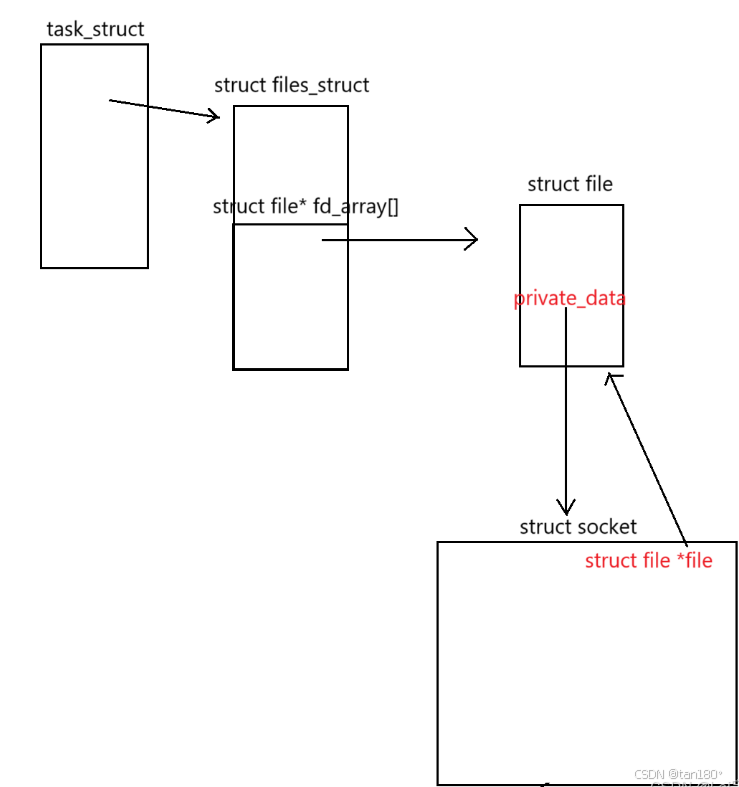
简而言之就 file结构体 中有一个指针叫做 private_data ,类型是void * ,如果这个文件是一个套接字文件,那么这个 file结构体 中的 private_data 就会指向一个 struct socket 结构体
struct socket 主要就是用来描述一个套接字,其中记录了这个套接字的类型、状态、操作方法等关键信息,其中有一个指针叫做 struct file * file ,其指向的就是这个套接字文件的 file结构体 ,没错,它又指回去了,此时我们就已经建立了 struct socket 与 struct file 的双向链接,将套接字信息与其对应的套接字文件 struct file 牢牢地绑定在一起了
c
struct socket
{
socket_state state; // 套接字状态(如 SS_UNCONNECTED, SS_CONNECTED 等)
ktime_t tstamp; // 时间戳(用于 SO_TIMESTAMP 等选项)
struct socket_wq *wq; // 等待队列,用于处理阻塞操作
// 注意看下面一行,就是文件指针,倒指回去文件结构体
struct file *file; // 关联的文件对象(若套接字通过文件描述符访问)
struct sock *sk; // 指向底层传输层的 sock 结构体
const struct proto_ops *ops; // 套接字操作函数集(协议相关)
struct socket_lock *lock; // 用于同步的锁
short type; // 套接字类型(如 SOCK_STREAM, SOCK_DGRAM 等)
unsigned int flags; // 套接字标志(如 SOCK_ASYNC_NOSPACE 等)
struct usock_timers *timers; // 超时定时器(如 SO_RCVTIMEO, SO_SNDTIMEO)
struct fasync_struct *fasync_list; // 异步通知相关链表
struct module *owner; // 模块引用(用于自动卸载)
void *security; // 安全相关数据
struct hlist_node *link; // 用于哈希表的链表节点
struct hlist_node *glue; // 用于协议特定的关联
struct address_space *mm_space; // 内存地址空间(某些协议使用)
};struct sock
在 struct socket 中还有一个非常重要的指针,它的名字是 struct sock * sk; ,指向底层传输层的 sock 结构体。这个 sock结构体 也是用来描述这个套接字的相关信息的,这时候有人就要问了,既然如此,那这个 socket 和 sock 的区别在什么地方呢?主要区别就在于, socket 这个结构体描述的套接字相关信息,是应用层关心的信息,也就是说它是面向用户的!而 sock 这个结构体描述的,则是传输层关心的信息!我们前面问题中提到的发送和接收缓冲区,就存在 sock结构体 中。
c
struct sock
{
/* 基本状态与标识 */
socket_state sk_state; // 传输层状态(如 TCP_ESTABLISHED)
unsigned short sk_type; // 套接字类型(同 struct socket 的 type)
int sk_family; // 地址族(如 AF_INET, AF_INET6)
__u32 sk_flags; // 套接字标志(如 SOCK_FLAG_REUSEADDR)
/* 协议相关核心信息 */
struct proto *sk_prot; // 指向协议操作结构体(如 &tcp_prot, &udp_prot)
struct net *sk_net; // 所属的网络命名空间
struct sock_common __sk_common; // 公共地址信息(源/目的端口、IP 等)
#define sk_local_addr __sk_common.skc_rcv_saddr // 本地 IP 地址
#define sk_remote_addr __sk_common.skc_daddr // 远程 IP 地址
#define sk_local_port __sk_common.skc_num // 本地端口
#define sk_remote_port __sk_common.skc_dport // 远程端口
/* 连接与状态管理 */
struct sock *sk_next; // 哈希表中的下一个套接字
struct hlist_node sk_node; // 用于哈希表的节点
rcu_t sk_rcu; // RCU 机制相关
atomic_t sk_refcnt; // 引用计数
struct socket *sk_socket; // 反向关联的 struct socket
/* 数据缓冲区 */
struct sk_buff_head sk_receive_queue; // 接收缓冲区队列
struct sk_buff_head sk_write_queue; // 发送缓冲区队列
struct sk_buff_head sk_error_queue; // 错误信息队列
unsigned int sk_rcvbuf; // 接收缓冲区大小
unsigned int sk_sndbuf; // 发送缓冲区大小
/* TCP 相关状态(UDP 可能不使用) */
__u32 sk_seq; // 下一个要发送的序列号
__u32 sk_ack; // 已确认的序列号
__u32 sk_window; // 接收窗口大小
__u32 sk_snd_wnd; // 发送窗口大小
__u32 sk_rcv_wnd; // 接收窗口大小
struct tcp_sock *tcp; // TCP 私有数据(仅 TCP 套接字有效)
/* 计时器 */
struct timer_list sk_timer; // 通用计时器
struct timer_list sk_retrans_timer; // 重传计时器(TCP 用)
struct timer_list sk_keepalive_timer;// 保活计时器(TCP 用)
/* 阻塞与同步 */
wait_queue_head_t sk_sleep; // 等待队列(用于阻塞操作)
struct mutex sk_lock; // 互斥锁
spinlock_t sk_callback_lock; // 回调函数锁
/* 其他信息 */
void *sk_user_data; // 用户私有数据
__u32 sk_priority; // 优先级
__s32 sk_err; // 错误码
__u32 sk_mark; // 标记(用于路由等)
};struct tcp_sock
我们知道 传输层TCP 其实要干的事情还是蛮多的,就比如说:
- 端到端连接的建立和维护
- 对应用层下发的大块数据进行分段,将数据提交到应用层之前对其进行重组
- 实现数据的可靠传输(TCP报文段解析机制、序号机制、校验机制、确认应答机制、流量控制与拥塞控制机制)
单纯的 struct sock结构体 肯定干不了那么多的事情,在 Linux 内核中,struct tcp_sock 是 TCP 协议实现的核心数据结构,用于维护一个 TCP 连接的所有状态和相关信息。它包含了连接状态、序号、窗口信息、重传机制、拥塞控制等关键参数,是 TCP 协议各种机制(如可靠传输、流量控制、拥塞控制)的实现基础。struct tcp_sock 的定义如下
c
struct tcp_sock
{
/* 1. 继承自 inet_connection_sock(面向连接的 INET 协议基类)
* 注:这是嵌套继承的核心------tcp_sock 是一种 inet_connection_sock,
* 后者又继承 inet_sock,最终继承 sock(所有套接字通用基类)
*/
struct inet_connection_sock icsk;
/* 2. TCP 序号相关字段(核心:保障数据按序与可靠传输) */
u32 seq; /* 下一个要发送的字节序号(Send Sequence Number) */
u32 end_seq; /* 已发送但未确认的最后一个字节序号(= snd_nxt + 已发送未确认长度) */
u32 snd_nxt; /* 下一个待发送的序号(与 seq 语义一致,部分场景细分使用) */
u32 snd_una; /* 已发送但未被确认的第一个字节序号(Unacknowledged Sequence) */
u32 snd_wnd; /* 对端告知的发送窗口大小(接收方的接收窗口,用于流量控制) */
u32 rcv_nxt; /* 下一个期望接收的字节序号(Receive Next Sequence) */
u32 rcv_wup; /* 接收窗口更新序号(Window Update Sequence,标记窗口需更新的位置) */
u32 rcv_end; /* 接收窗口的末尾序号(= rcv_nxt + rcv_wnd,标记接收窗口边界) */
u32 snd_sml; /* 已发送的最小序号(用于快速重传时的序号判断) */
u32 rcv_tstamp; /* 最后一次接收数据的时间戳(用于计算 RTT、超时等) */
u32 lsndtime; /* 最后一次发送数据的时间戳(用于保活、超时判断) */
u32 last_data_sent; /* 最后一次发送数据的序号(非控制报文) */
u32 last_data_recv; /* 最后一次接收数据的序号(非控制报文) */
/* 3. RTT(往返时间)与重传相关(核心:保障丢包后可靠恢复) */
u32 srtt_us; /* 平滑往返时间(Smoothed RTT),单位:微秒(用于计算 RTO) */
u32 rttvar_us; /* RTT 偏差(RTT Variance),单位:微秒(用于动态调整 RTO) */
u32 rto; /* 重传超时时间(Retransmission Timeout),单位:毫秒(基于 srtt_us 和 rttvar_us 计算) */
u32 rtt_seq; /* 用于测量 RTT 的基准序号(标记当前正在测量 RTT 的数据段序号) */
u32 retrans_stamp; /* 最后一次重传的时间戳(用于重传频率控制) */
u32 retrans_out; /* 当前未被确认的重传段数量(用于拥塞控制判断) */
u32 snd_lost; /* 检测到的丢失段数量(基于重复 ACK 或超时判断) */
u32 high_seq; /* 已发送的最高序号(包括重传段,用于序号范围判断) */
u32 lost_out; /* 已判定丢失但未重传的段数量 */
u32 retransmit_cnt; /* 重传计数器(累计重传次数,用于超时退避) */
u32 undo_marker; /* 序号回滚标记(用于 SACK 机制中恢复丢失的序号范围) */
u32 undo_retrans; /* 序号回滚对应的重传次数 */
/* 4. 拥塞控制相关(核心:避免网络拥塞,控制发送速率) */
u32 ssthresh; /* 慢启动阈值(Slow Start Threshold):超过该值后进入拥塞避免阶段 */
u32 cwnd; /* 拥塞窗口(Congestion Window):发送方基于网络拥塞状态的发送上限 */
u32 cwnd_cnt; /* 拥塞窗口计数器(每发送 cwnd_cnt 个段,cwnd 增长 1,控制增长速率) */
u32 cwnd_clamp; /* 拥塞窗口上限(限制 cwnd 最大取值,避免过度占用带宽) */
u32 snd_cwnd_clamp; /* 发送窗口上限(= min(snd_wnd, cwnd_clamp),综合流量控制与拥塞控制) */
u32 tcp_cwnd_ssthresh; /* 拥塞窗口的慢启动阈值备份(用于 SACK 恢复等场景) */
u32 prior_cwnd; /* 上一次的拥塞窗口大小(用于连接恢复时的cwnd初始化) */
u32 mss_cache; /* 最大分段大小(MSS)缓存(避免重复计算,提升效率) */
u16 advmss; /* 通告的 MSS(Advertised MSS,向对端声明的最大分段大小) */
u8 cwnd_used; /* 拥塞窗口使用标记(用于判断是否充分利用 cwnd) */
u8 cwnd_event; /* 拥塞窗口事件标记(如 CWND_EVENT_LOSE 表示拥塞丢失) */
struct tcp_congestion_ops *cong; /* 当前使用的拥塞控制算法实例(如 Cubic、Reno 等) */
void *cong_priv; /* 拥塞控制算法私有数据(不同算法的自定义参数) */
/* 5. 乱序与数据重组相关(核心:处理乱序到达的数据包) */
struct sk_buff_head out_of_order_queue; /* 乱序接收的数据包队列(缓存序号不连续的段,待补全后重组) */
u32 tcp_gso_segs; /* GSO(Generic Segmentation Offload)分段数量(硬件分段时的段数) */
u32 tcp_gso_size; /* GSO 分段大小(每段的最大字节数) */
u32 tso_segs_goal; /* TSO(TCP Segmentation Offload)目标分段数(优化硬件分段效率) */
u32 tso_size_goal; /* TSO 目标分段大小 */
u32 copied_seq; /* 已复制到应用层的序号(标记用户空间已读取的数据边界) */
u32 rcv_ssthresh; /* 接收窗口的慢启动阈值(用于接收端流量控制) */
u32 rcv_wnd_cnt; /* 接收窗口计数器(控制接收窗口更新频率) */
/* 6. TCP 选项与标志位(核心:协议特性开关与配置) */
unsigned int flags; /* TCP 核心标志位(如 TCP_FLAG_FIN、TCP_FLAG_SYN、TCP_FLAG_SACK_PERM 等) */
u8 num_retrans; /* 累计重传次数(用于判断是否触发连接断开) */
u8 syn_retries; /* SYN 报文重传次数(三次握手阶段的重试次数) */
u8 synack_retries; /* SYN-ACK 报文重传次数(三次握手阶段的重试次数) */
u8 fin_retries; /* FIN 报文重传次数(断开连接阶段的重试次数) */
u8 keepalive_probes; /* 保活探测报文次数(连接保活时的重试次数) */
u32 keepalive_time; /* 保活时间(连接空闲多久后发起保活探测) */
u32 keepalive_intvl; /* 保活探测间隔(两次保活探测的时间差) */
u32 linger2; /* 半关闭状态下的 linger 时间(FIN_WAIT2 阶段的超时时间) */
u16 window_clamp; /* 窗口大小上限(限制对端通告的 snd_wnd 最大取值,避免窗口过大) */
u16 max_window; /* 历史最大接收窗口大小(用于窗口缩放选项) */
u8 window_bits; /* 窗口缩放位数(TCP 窗口缩放选项的偏移量) */
u8 rx_opt; /* 接收端选项标记(如 RX_OPT_SACK、RX_OPT_WSCALE 表示支持 SACK、窗口缩放) */
u8 tx_opt; /* 发送端选项标记(如 TX_OPT_SACK、TX_OPT_WSCALE 表示启用 SACK、窗口缩放) */
/* 7. 定时器相关(核心:控制重传、保活等超时逻辑) */
struct timer_list retrans_timer; /* 重传定时器(超时未确认则重传数据段) */
struct timer_list keepalive_timer; /* 保活定时器(空闲连接时发起保活探测) */
struct timer_list persist_timer; /* 持续定时器(接收窗口为 0 时,定期探测窗口是否恢复) */
struct timer_list delayed_ack_timer; /* 延迟 ACK 定时器(延迟发送 ACK,减少网络开销) */
/* 8. SACK(选择性确认)相关(优化重传效率,仅确认丢失的段) */
struct tcp_sack_block sack_block[TCP_SACK_BLOCKS_MAX]; /* SACK 块数组(记录已接收的乱序段范围) */
u8 sack_blocks; /* 当前有效的 SACK 块数量 */
u8 sack_block_size; /* SACK 块数组大小(默认 TCP_SACK_BLOCKS_MAX=4) */
u8 sack_recv; /* 接收端 SACK 标记(是否支持 SACK 选项) */
u8 sack_enable; /* 发送端 SACK 使能标记(是否启用 SACK 机制) */
u32 sack_left; /* SACK 机制中未确认的最小序号 */
u32 sack_rtt_seq; /* SACK 机制中用于测量 RTT 的序号 */
/* 9. 其他辅助字段 */
u32 tcp_header_len; /* TCP 头部长度(包含选项,单位:字节) */
u32 tso_segs; /* TSO 分段数量(已发送的 TSO 分段数) */
u32 tso_size; /* TSO 分段大小(已发送的 TSO 分段的单段大小) */
u32 mtu_probe_seq; /* MTU 探测序号(用于路径 MTU 发现) */
u32 mtu_probe_size; /* MTU 探测包大小(路径 MTU 发现时的探测包长度) */
u8 mtu_probe_type; /* MTU 探测类型(如 MTU_PROBE_SYN、MTU_PROBE_DATA) */
u8 repair; /* 修复模式标记(用于 TCP 连接修复、调试) */
u32 repair_queue; /* 修复模式下的队列标记(如 REPAIR_QUEUE_SEND、REPAIR_QUEUE_RECV) */
u32 repair_seq; /* 修复模式下的基准序号 */
}; 我又找到了一个图,可能会更加方便的看到它们之间的关系
在 struct sock 结构体中,有专门的字段记录传输层协议类型,我们只需要查一下,就可以知道传输层协议的类型了。知道这个 sock结构体 对应的传输层协议类型之后(假如说传输层采用 TCP 协议),我们经可以将这个 sock 结构体指针强转成 tcp_sock 类型的指针,这样我们就找到记录这个套接字文件完整传输层信息的 tcp_sock 结构体了(因为它们起始地址都是一样的!)
c
struct sock
{
// ... 其他成员
unsigned short sk_protocol; // 传输层协议类型
// ... 其他成员
};struct sk_buff
struct sk_buff 是 "网络数据包的载体",存储实际的报文数据(如 SYN 报文、ACK 报文的字节流)及元信息(协议类型、设备指针等)。它是 "数据的容器",与具体连接的关联是动态的。
一个 TCP 连接(或其他面向连接的协议)在通信过程中会产生多个数据包(如分段的 TCP 报文段、IP数据报)。如果说 tcp_sock 描述的是一个 TCP连接 ,那 struct sk_buff 描述的就是一个 TCP报文段 。相应地,在udp_sock中,struct sk_buff 描述的就是一个 UDP数据报
在 sock结构体 中,收发缓冲区( sock结构体 中的 sk_write_queue 与 sk_receive_queue )其本质就是一个 sk_buff 的队列
c
// 套接字核心结构(简化版)
struct sock
{
// ... 其他大量字段 ...
/* 发送队列:存储待发送的 sk_buff 数据包 */
struct sk_buff_head write_queue;
/* 接收队列:存储已接收、待应用层读取的 sk_buff 数据包 */
struct sk_buff_head receive_queue;
// ... 其他字段(如错误队列、状态标志等)...
};
// 用于管理 sk_buff 链表的队列头结构
struct sk_buff_head
{
struct sk_buff *next; // 队列中第一个 sk_buff
struct sk_buff *prev; // 队列中最后一个 sk_buff
unsigned int qlen; // 队列中 sk_buff 的数量(长度)
spinlock_t lock; // 保护队列操作的自旋锁(并发安全)
};
c
struct sk_buff
{
// 数据缓冲区边界
unsigned char *head; // 缓冲区起始地址
unsigned char *data; // 当前协议层数据起始地址
unsigned char *tail; // 数据末尾地址
unsigned char *end; // 缓冲区结束地址
// 长度信息
unsigned int len; // 当前数据长度(tail - data)
unsigned int data_len;// 数据部分长度(不含协议头)
__u32 truesize;// 整个sk_buff及数据的总大小
// 协议头指针(不同协议层的头部)
struct iphdr *ip_hdr; // IP头部指针(网络层)
struct tcphdr *tcp_hdr; // TCP头部指针(传输层)
struct udphdr *udp_hdr; // UDP头部指针(传输层)
// ... 其他协议头指针
// 网络设备与协议信息
struct net_device *dev; // 接收/发送的网络设备
__be16 protocol;// 上层协议类型(如ETH_P_IP)
__u16 mac_len; // 链路层头部长度
// 内存管理
atomic_t users; // 引用计数
struct sk_buff *next; // 链表指针(用于批量处理)
struct sk_buff *prev; // 双向链表前驱指针
// 控制标记与状态
__u32 mark; // 数据包标记(用于QoS等)
__u8 local_df;// 分片标志
__u8 cloned:1;// 是否为克隆副本
// ... 其他标志位
// 时间与校验和信息
ktime_t tstamp; // 时间戳
__wsum csum; // 校验和
// ... 其他字段
};对于 sk_buff 结构体,说它是贯穿了整个网络协议站,具体内核到底是怎么实现的呢,这里我也直接贴上DeepSeek的解答
你先要明白这四个指针的意义:
- head 和 end:定义了整本书的封面和封底(整个缓冲区的起止)。它们在整个生命周期中基本固定,决定了缓冲区的物理边界。
- data 和 tail:定义了你当前正在阅读的那一页的起始和结束行(当前协议层有效数据的起止)。它们不断移动,标志着我们读到了哪里。

反向封装数据就是移动 data 指针,这么做好处在于:
- 极致的性能:避免了在各层之间来回拷贝数据包 payload 的巨大开销。这是内核网络性能高的关键原因之一。
- 清晰的层次隔离:每一层都只关心 data 和 tail 之间的数据,无需知道其他层的细节,符合网络分层的设计哲学。
- 高效的内存管理:整个数据包(从以太网头到应用数据)在物理内存中是连续存储的,非常适合 DMA 操作和网卡处理。
struct request_sock_queue
全连接队列放在了 inet_connection_sock 下面,而不是 tcp_sock ,因为不只是 tcp 协议才面向连接的
c
// 定义在 include/net/inet_connection_sock.h
struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet;
...
// 这就是接受队列!
struct request_sock_queue icsk_accept_queue;
...
};
// TCP sock 继承自 inet_connection_sock
struct tcp_sock {
/* inet_connection_sock has to be the first member! */
struct inet_connection_sock inet_conn;
...
// TCP 特有的成员在后面
u32 rcv_nxt; /* What we want to receive next */
u32 snd_nxt; /* Next sequence we send */
...
};
c
// 全连接队列的管理结构
struct request_sock_queue
{
struct request_sock *rskq_accept_head; // 队列头部(第一个待accept的连接)
struct request_sock *rskq_accept_tail; // 队列尾部(最后一个待accept的连接)
rwlock_t rskq_lock; // 队列操作锁
int qlen; // 当前队列长度(已完成握手的连接数)
int max_qlen; // 队列最大长度(由listen()的backlog参数设置)
// ... 其他控制字段
};六、最后再理解三次握手
(1)半连接队列阶段(SYN 队列)
首先客户端向服务器发送链接请求,当服务器收到客户端的 SYN 报文时,内核会将该报文封装为 sk_buff,并解析其中的 TCP 头部信息(如源端口、序号等)。内核会为这个连接请求创建一个 request_sock 结构体,记录当前握手状态(如已发送 SYN+ACK),并将其加入 半连接队列(struct request_sock_queue 的 syn_wait_queue)。此时,request_sock 会通过指针关联到对应的 sk_buff(或其解析出的关键信息),用于后续处理该连接的后续报文(如客户端的 ACK)。
(2)全连接队列阶段(Accept 队列)
当服务器收到客户端的最终 ACK 报文(完成三次握手),内核会再次将该 ACK 报文封装为 sk_buff,并根据报文信息(四元组)找到对应的 request_sock。内核会将 request_sock 从半连接队列迁移到 全连接队列(accept_queue),此时 request_sock 已代表一个 "已建立的连接"。
此时,sk_buff(承载 ACK 报文)的使命已完成(驱动连接状态变更),会被内核释放或复用,而 request_sock 则在全连接队列中等待应用层 accept() 调用。
(3)连接建立后
当应用层调用 accept() 后,request_sock 会被转换为一个完整的 struct sock(TCP 连接对象,tcp_sock)。此后:
该连接传输的业务数据会被封装为 sk_buff,并通过 struct sock 的发送 / 接收队列(如 sk_write_queue、sk_receive_queue)与连接对象关联。
此时的 sk_buff 直接与 struct sock 绑定,而非 request_sock(request_sock 已完成使命并被转换)。
七、最后理解网络通信
(1)发送流程(sk_write_queue)
应用层调用 send() 向套接字写入数据。
内核为数据创建 sk_buff,添加 TCP 头(序号、确认号等)、IP 头、链路层头等。
将 sk_buff 加入 sk_write_queue 队列。
TCP 协议栈从队列中取出 sk_buff,根据拥塞控制、滑动窗口等策略发送数据
收到对端 ACK 后,从队列中移除 sk_buff 并释放(若未收到 ACK,会触发重传)。
(2)接收流程(sk_receive_queue)
网络设备收到数据包,封装为 sk_buff 并上传至内核协议栈。
TCP 层对 sk_buff 进行校验(序号、校验和等)、重排(解决乱序)、组装(拼接分段数据)。
处理完成后,将 sk_buff 加入 sk_receive_queue 队列。
应用层调用 recv() 时,内核从队列中取出 sk_buff,将数据复制到用户态缓冲区。
数据被读取后,sk_buff 从队列中移除并释放。
总结
好痛苦,但是我们理解了之后,就不会那么惆怅了,主要是一开始从几个 socket 的函数,当时只是会用,现在还会理解了,就蛮不错的这种感觉