【Java手搓RAGFlow】-12- BaoRAGFlow最终项目展示
- [1 引言](#1 引言)
- [2 前端](#2 前端)
-
- [2.1 启动前端](#2.1 启动前端)
- [2.2 前端Login展示](#2.2 前端Login展示)
- [3 后端修改](#3 后端修改)
-
- [3.1 修改SecurityConfig](#3.1 修改SecurityConfig)
- [3.2 修改ChatWebSocketHandler](#3.2 修改ChatWebSocketHandler)
- [3.3 后端启动](#3.3 后端启动)
- [4 功能展示](#4 功能展示)
-
- [4.1 上传文件并解析](#4.1 上传文件并解析)
- [4.2 RAG 流式对话实测](#4.2 RAG 流式对话实测)
-
- [4.2.1 知识库增强对话](#4.2.1 知识库增强对话)
- [4.2.2 非知识库问答](#4.2.2 非知识库问答)
- [5 总结](#5 总结)
1 引言
在之前的系列文章中,我们一步一个脚印,硬核手搓了 RAGFlow 的核心后端架构:从登录注册的安全校验,到文件上传解析的流程,再到Kafka 异步解耦与实时通信。后端的大厦已经落成,现在只差最后一块拼图------前端交互界面。
为了验证我们后端的健壮性并快速落地产品,本次我尝试使用 Cursor 的 Agent 模式,通过自然语言交互,为我们的 Java 后端生成了一套现代化的前端 UI。
本文将展示最终的项目成果,并记录在前后端联调过程中,为了适配前端数据流而进行的后端架构微调。
2 前端
在这个环节,我们没有手写繁琐的 CSS 和 HTML,而是利用 Cursor Agent 根据后端接口文档直接生成 Vue 代码。
生成好后
2.1 启动前端
前端生成完毕后,通过标准的 Node.js 流程启动:
java
npm install
npm dev run 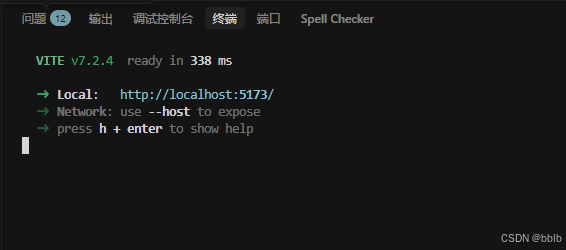
2.2 前端Login展示
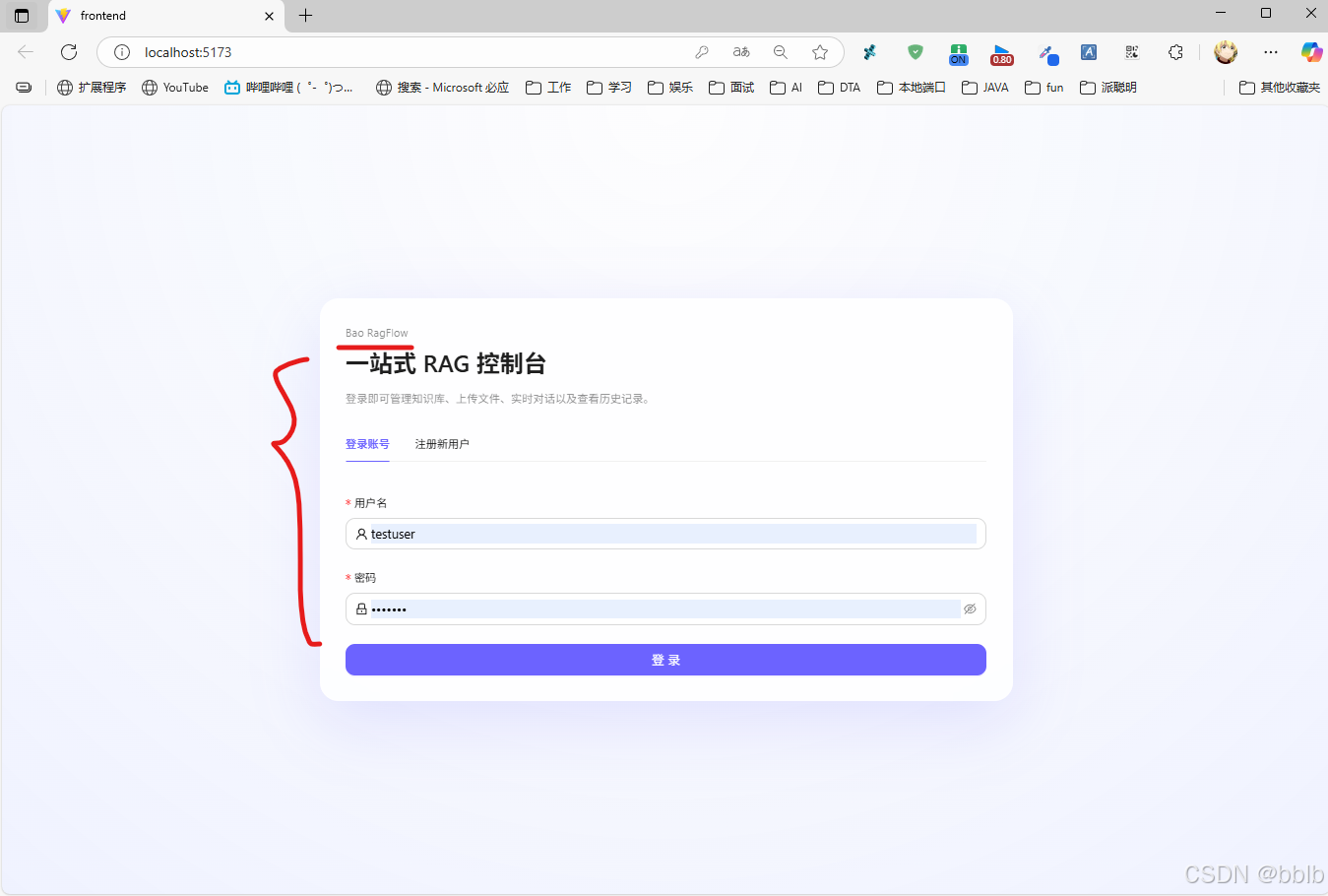
3 后端修改
在前后端联调的过程中,我们发现 Cursor 生成的前端代码虽然美观,但在数据交互格式上与后端存在细微差异。为了提升系统的兼容性和鲁棒性,我们对后端进行了以下关键修改。
cursor自己为了适配前端,也做了许多后端上的修改
3.1 修改SecurityConfig
修改com.alibaba.config.SecurityConfig,添加bean
由于前后端分离部署(前端运行在 Node服务器,后端运行在 Tomcat),跨域资源共享(CORS)是必须解决的问题。我们在 SecurityConfig 中添加了全局 CORS 配置,放行了常用的 HTTP 方法,并允许携带凭证。
java
@Bean
public CorsConfigurationSource corsConfigurationSource() {
CorsConfiguration configuration = new CorsConfiguration();
configuration.setAllowedOriginPatterns(List.of("*"));
configuration.setAllowedMethods(List.of("GET", "POST", "PUT", "DELETE", "PATCH", "OPTIONS"));
configuration.setAllowedHeaders(List.of("*"));
configuration.setAllowCredentials(true);
configuration.setMaxAge(Duration.ofHours(1));
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", configuration);
return source;
}3.2 修改ChatWebSocketHandler
修改com.alibaba.handler.ChatWebSocketHandler#handleTextMessageyi
主要是为了解决 WebSocket 收到的 JSON 里 message/userId 可能不是纯字符串时导致的崩溃。
- 原来用
Map<String, String>直接映射,如果前端传数字或嵌套对象(例如userId: 123),Jackson 会尝试把它硬转换成String,在运行期抛ClassCastException,从而导致整个消息处理失败。 - 改成
Map<String, Object>后,先拿到Object再调用toString()/trim(),就可以兼容数值和字符串输入,并且在缺失时主动给出错误提示,不再因为类型不匹配就断开连接。 - 同时检查空消息和缺失的
userId,把错误以 WebSocket 返回给前端,避免进入业务逻辑后再报错。
所以这是为了增强后端对前端数据格式的容错能力,并显式告知错误原因,而不是让 Handler 直接抛异常。
java
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception {
try {
logger.info("收到消息,会话ID: {}, 消息: {}", session.getId(), message.getPayload());
// 1. 解析消息
Map<String, Object> request = objectMapper.readValue(
message.getPayload(),
Map.class
);
Object messageObj = request.get("message");
String userMessage = messageObj instanceof String ? (String) messageObj :
(messageObj != null ? messageObj.toString() : null);
if (userMessage != null) {
userMessage = userMessage.trim();
}
Object userIdObj = request.get("userId"); // 简化版,实际应该从认证中获取
String userId = userIdObj instanceof String ? (String) userIdObj :
(userIdObj != null ? userIdObj.toString() : null);
if (userMessage == null || userMessage.isEmpty()) {
sendError(session, "消息不能为空");
return;
}
if (userId == null || userId.isEmpty()) {
sendError(session, "用户信息缺失");
return;
}
// 存储用户ID
sessionUserMap.put(session.getId(), userId);
// 2. 处理消息并流式返回
chatHandler.processMessage(userId, userMessage, session);
} catch (Exception e) {
logger.error("处理消息失败", e);
sendError(session, "处理失败: " + e.getMessage());
}
}3.3 后端启动
启动成功后我们的索引会正常创建,可以看到 Elasticsearch 的索引初始化日志正常打印,说明数据库连接与 ORM 映射无误。
4 功能展示
4.1 上传文件并解析
用户在前端上传技术文档,后端通过 Tika组件进行解析,并将文本切片向量化存储。
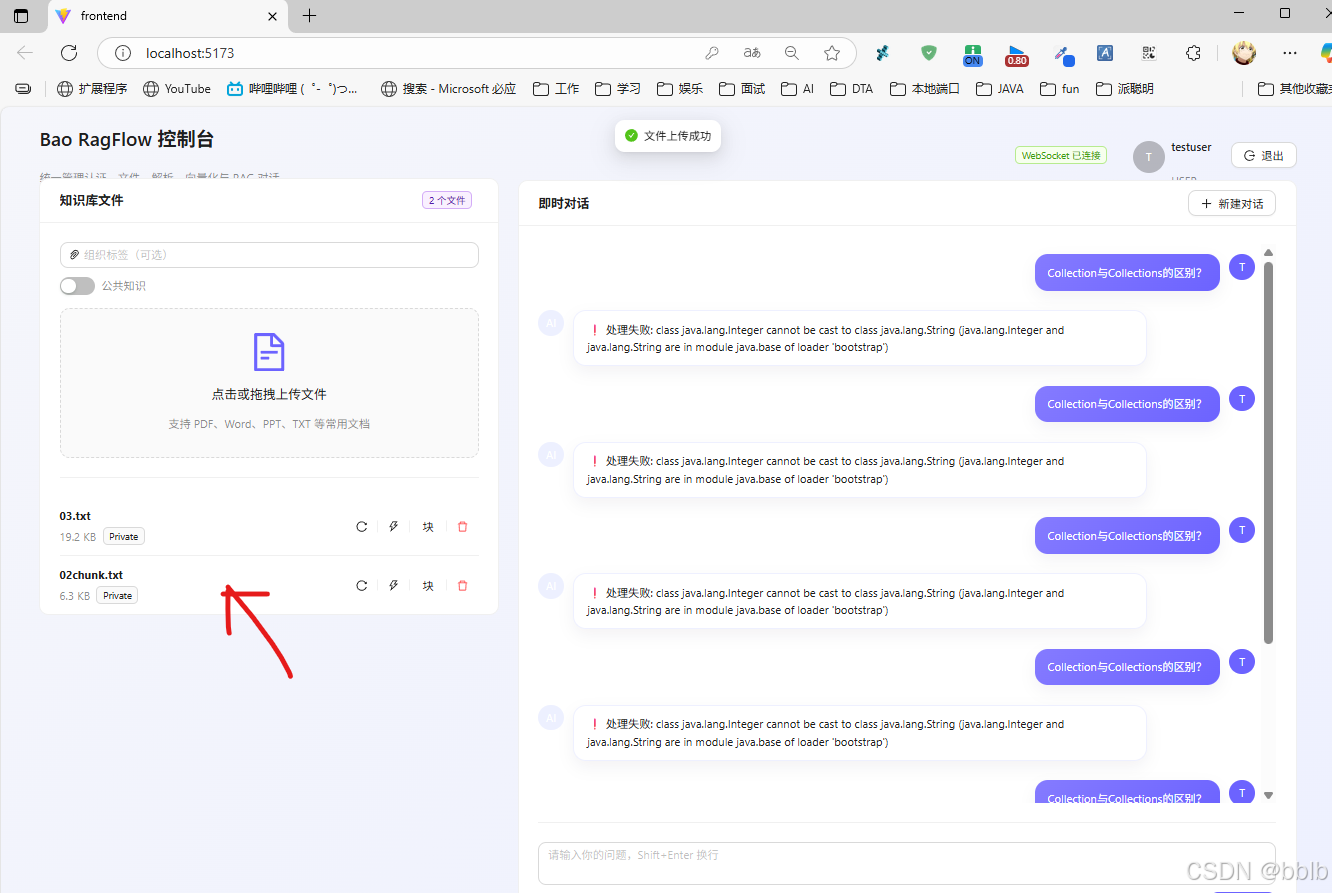
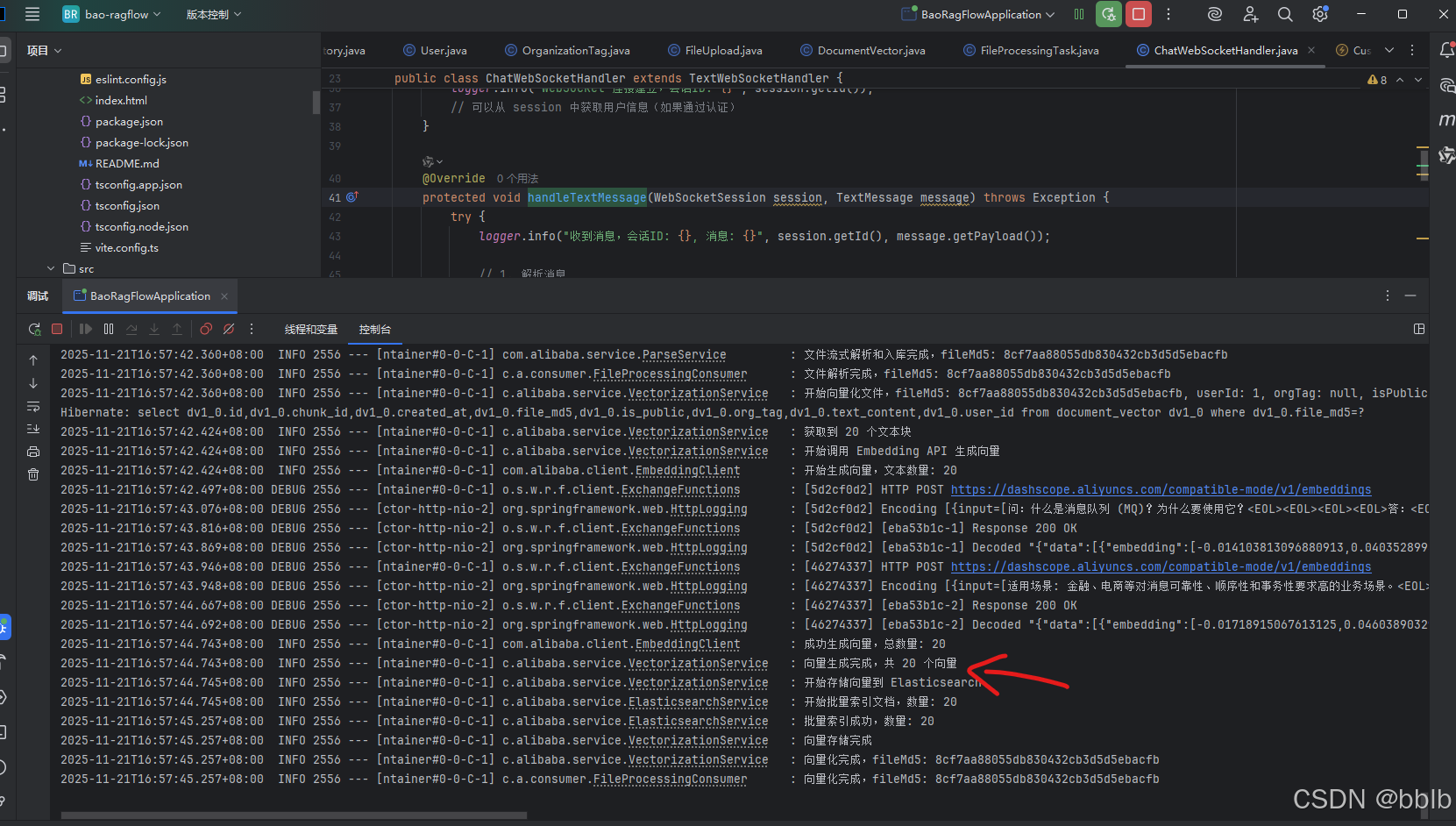
观察后端控制台日志,可以看到文件流被正确接收并触发了对应的任务:
4.2 RAG 流式对话实测
这是系统的核心价值所在:基于检索增强生成的对话。
4.2.1 知识库增强对话
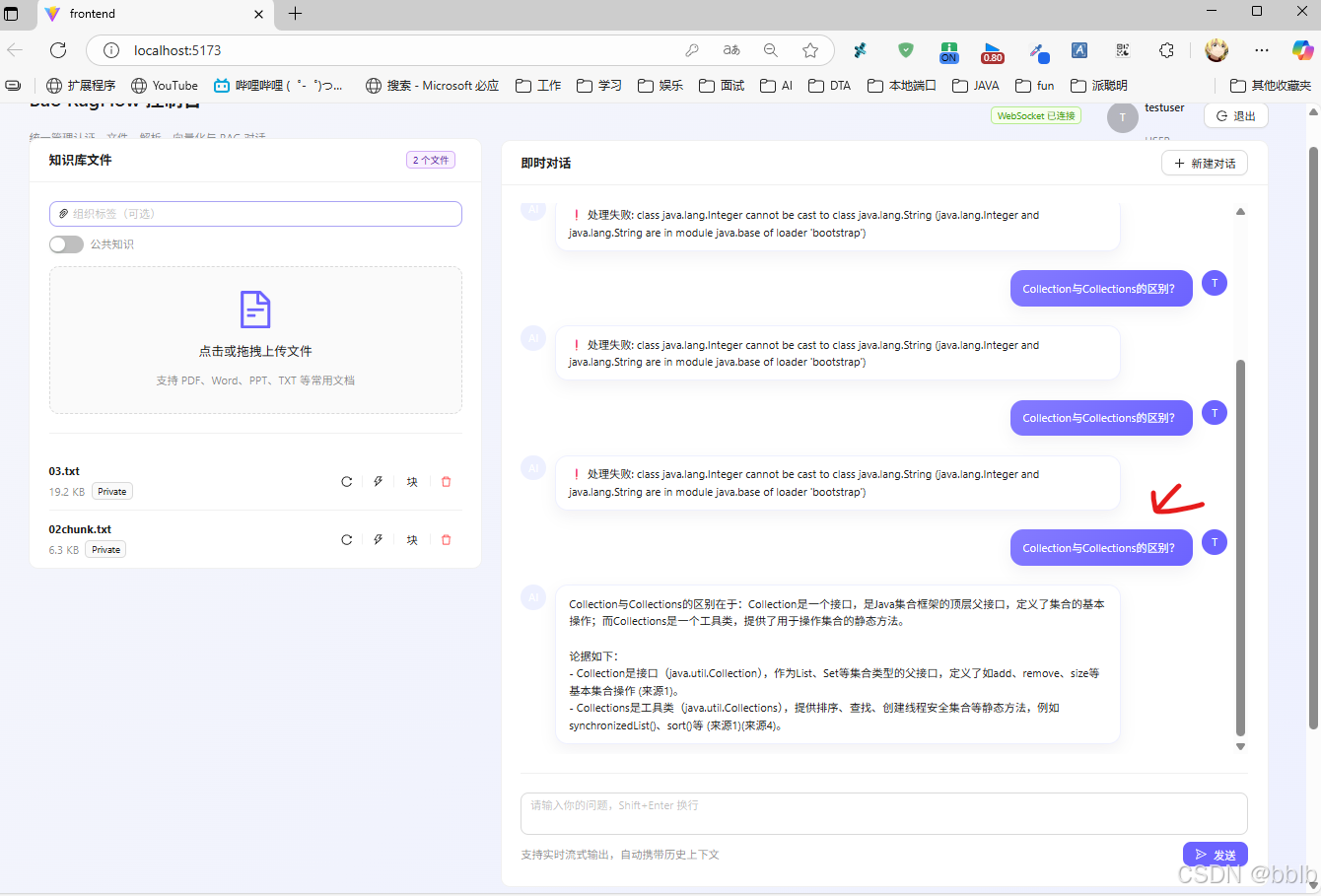
我们向系统提问:"Collection与Collections的区别?"
这是一个典型的 Java 面试题,也是我们上传的文档中包含的内容。
可以看到,AI 并没有胡言乱语,而是精准地引用了知识库中的内容进行回答,且响应速度极快(流式输出)。
4.2.2 非知识库问答
为了验证 Prompt Engineering 的效果,我们询问一个知识库范围外的问题。
系统严格遵守了预设的 System Prompt:"如果知识库中没有相关信息,请告知不知道,不要编造。"
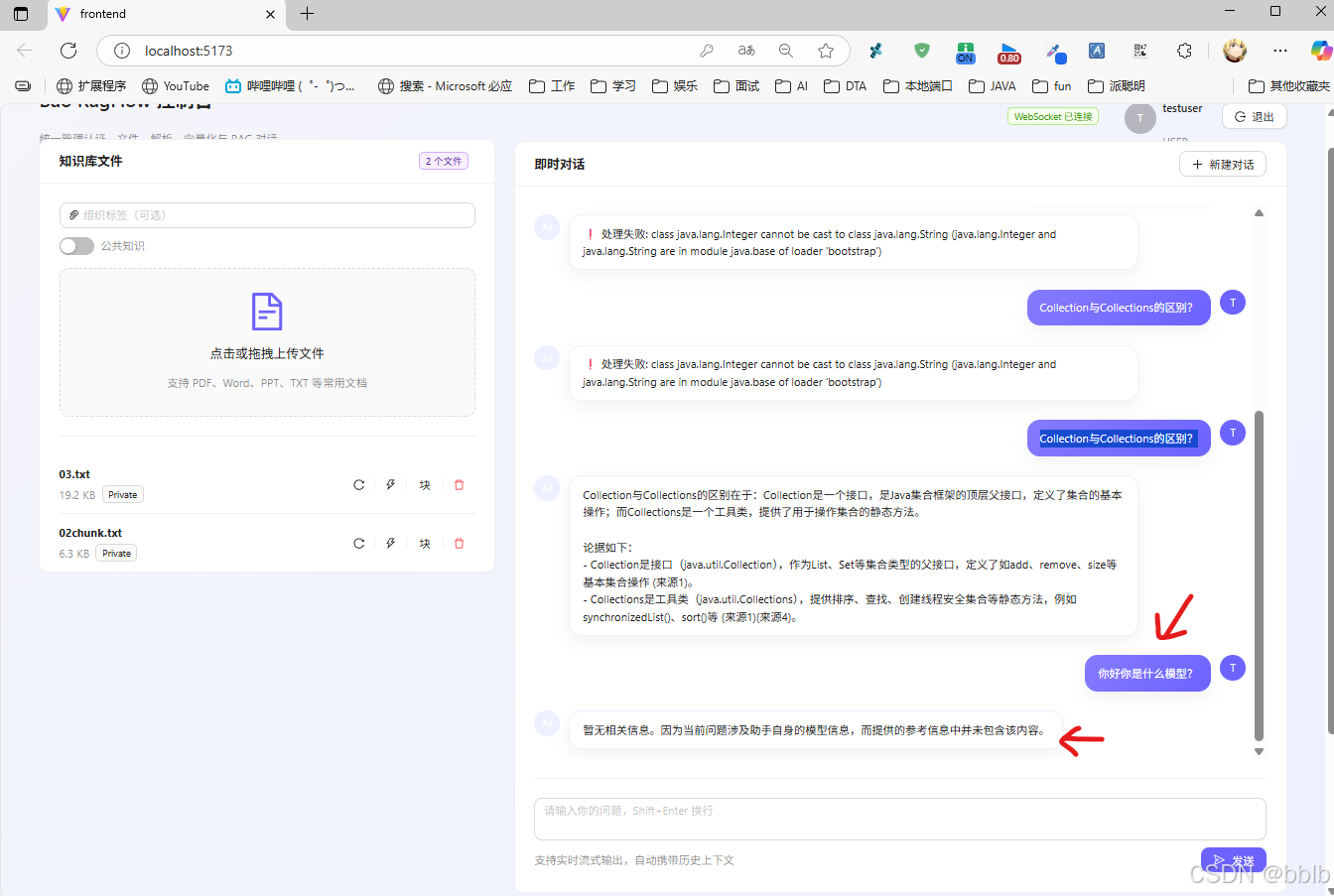
这种严谨的回答机制,对于企业级知识库应用至关重要,有效避免了"AI 幻觉"。
5 总结
至此,【Java手搓RAGFlow】系列教程的主体功能已全部实现。我们从零开始,构建了一个包含Spring Boot、Elasticsearch、Kafka、WebSocket 以及 LLM 接入的完整 RAG 系统。
回顾整个项目:
- 架构层面:实现了计算密集型任务(解析)与IO密集型任务(对话)的解耦。
- 数据层面:打通了非结构化数据到向量数据库的 ETL 链路。
- 交互层面:完成了 WebSocket 全双工流式对话。
BaoRAGFlow 它涵盖了 RAG 应用开发中最核心的痛点与解决方案。希望这一系列文章能为你自己动手实现 AI 应用提供有价值的参考。
我们下一个手搓openManus见!