目录

写在前面
我们来看一篇关于大型语言模型的知识蒸馏与数据集蒸馏的综述,主要讲了两大技术:知识蒸馏(KD)和数据集蒸馏(DD)。简单说,KD是让笨重的大模型(老师)把本事教给轻巧的小模型(学生),而DD则是把海量训练数据浓缩成一小瓶"精华液",让训练效率暴增。下面我用大白话展开说说核心内容,并配上原文里的示意图帮你理解。
论文地址:https://arxiv.org/pdf/2504.14772
一、知识蒸馏(KD):让大模型当老师,小模型当学生
知识蒸馏的核心思想是"授人以渔"。比如GPT-4这样的大模型虽然厉害,但部署成本太高,KD就能把它复杂的推理能力"教"给更小的模型。
1.怎么教?软标签与推理过程一起学
传统方法只让学生模仿老师的最终答案(硬标签),但KD让学生学习老师输出的"概率分布"(软标签)。比如老师判断"图片是猫"的置信度是90%,"是狗"是10%,学生不仅要学"猫"这个结果,还要学这种不确定性。

更高级的"理性蒸馏"还会让学生学习老师的思考过程(比如解数学题时的步骤),而不仅是答案。
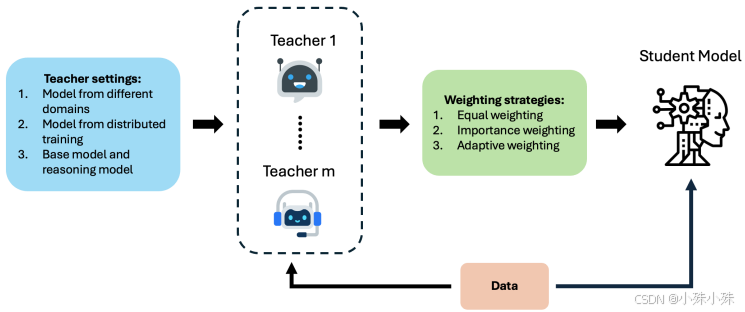
2.多老师合作与自我学习
有些场景会请多个专业老师(比如医疗、法律模型各一个)同时教一个学生,整合不同领域的知识。还有一种"自蒸馏",让模型自己教自己------用深层网络部分教浅层部分,相当于学霸给自己划重点。
二、数据集蒸馏(DD):把万吨数据压缩成一勺精华
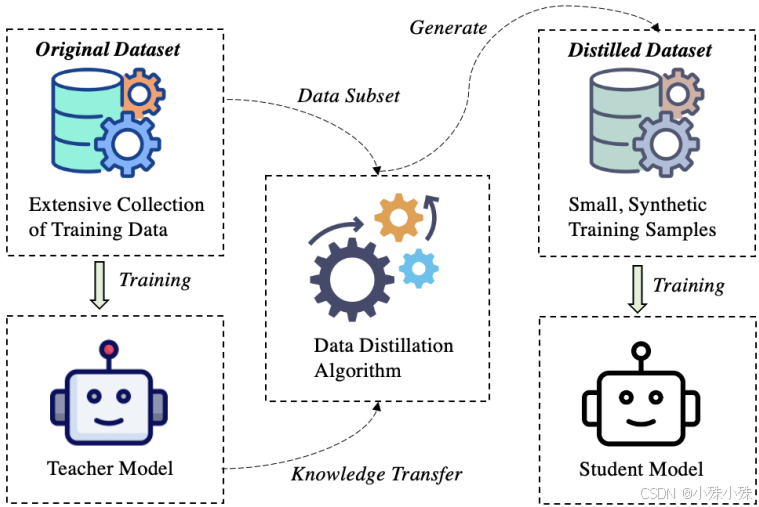
如果原始数据相当于一整座图书馆,DD就是做成一张精华知识卡片。它能将百万级数据压缩到几百条,但训练效果接近原数据集。
1.两种核心方法
**(1)优化法:**通过算法反复调整合成数据,让用小数据训练模型的梯度变化与用大数据时一致。
**(2)生成法:**用AI生成数据(比如GPT合成问答对),替代部分真实数据。
2.智能数据筛选
类似挑重点复习,DD会优先选择多样性强、信息量大的数据。比如用嵌入模型计算文本相似度,去除重复内容;或用困惑度评分过滤低质量文本。
三、KD+DD组合拳:实战中的高效搭配
在医疗、教育等领域,结合两者能大幅降低成本。例如:
**1.医疗诊断:**用DD提炼病历数据,再通过KD让小模型学会大模型的诊断逻辑;
**2.教育评分:**将批改作文的大模型知识蒸馏到轻量模型,快速评估学生作业;
**3.生物信息:**压缩蛋白质数据后,用小模型预测结构,效率提升70%。
四、未来挑战:瘦身不能丢"灵魂"
当前技术仍面临三大难题:
**1.保留深层能力:**小模型容易丢失逻辑链推理等复杂技能;
**2.动态更新难:**老师模型升级后,学生模型可能跟不上;
**3.可靠性风险:**若老师模型有偏见,学生会"学歪",需要增加不确定性校准。
总结来说,这篇论文系统梳理了大语言模型的知识蒸馏(KD)与数据集蒸馏(DD)技术,探讨了如何通过这两种互补的范式来压缩模型规模、提升数据效率,同时保留模型的复杂推理能力和语言多样性,并分析了其集成方法、应用场景以及未来在可持续、资源高效的大型语言模型发展中所面临的挑战与方向。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583