文章目录
- Mutex和RWMutex
-
- Mutex基础用法:解决计数器问题
- [Mutex 的进阶用法](#Mutex 的进阶用法)
- Mutex的TryLock
- [用 Mutex 实现线程安全队列](#用 Mutex 实现线程安全队列)
- RWMutex的用法
- 细节和注意事项
- [Mutex 和 RWMutex如何选择](#Mutex 和 RWMutex如何选择)
- 对比MySQL和Redis的锁
-
- 实际项目中的用法差异
-
- [1. Go内置的锁:进程内goroutine安全](#1. Go内置的锁:进程内goroutine安全)
- [2. MySQL的锁:数据库事务安全](#2. MySQL的锁:数据库事务安全)
- [3. Redis的锁:分布式跨服务安全](#3. Redis的锁:分布式跨服务安全)
- [Go已有锁,为何还需MySQL/Redis 锁?](#Go已有锁,为何还需MySQL/Redis 锁?)
在 Go 语言并发编程中, 处理共享资源竞争 是绕不开的话题。想象一下: 10 个 goroutine 同时给一个计数器加 1,最后结果却不是预期的 10 万 ------ 这就是典型的并发安全问题。针对这个问题,Go语言中有两类锁: Mutex(互斥锁)和 RWMutex(读写锁),这两类锁到底有什么区别,以及具体的应用场景是什么样的?
在Go语言中,当多个 goroutine 同时操作共享资源 (比如全局变量、数据库连接、缓存)时,由于 CPU 调度的随机性,可能导致操作 "交错执行"。比如count++看似简单,实际包含 "读取 - 修改 - 写入" 三个步骤,一旦被打断就会出现数据错误。这里面有几个关键定义:
- 临界区 :需要被保护的共享资源操作代码(比如
count++) - 互斥锁(Mutex):保证临界区同一时间只有一个 goroutine 执行
- 读写锁(RWMutex):区分读操作和写操作,支持多读单写,提升读多写少场景的性能
Mutex和RWMutex
Mutex 是 Go 标准库sync包中的核心原语,是最常用的基础锁,核心就两个方法:Lock()(加锁)和Unlock()(解锁)。
Mutex基础用法:解决计数器问题
先看一个不加锁的例子,实现一个计数器:
go
package main
import (
"fmt"
"sync"
)
func main() {
var count = 0
var wg sync.WaitGroup
wg.Add(10)
// 10个goroutine各加1万次
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 10000; j++ {
count++ // 非原子操作,存在并发安全问题
}
}()
}
wg.Wait()
fmt.Println("结果:", count) // 大概率小于100000
}运行后结果往往小于 10 万,这就是数据竞争导致的问题。用 Mutex 修复只需 3 步:
- 声明 Mutex 变量
- 临界区前加
Lock() - 临界区后加
Unlock()(建议用defer保证释放)
修复后的核心代码:
go
var count = 0
var wg sync.WaitGroup
var mu sync.Mutex // 声明互斥锁
wg.Add(10)
// 10个goroutine各加1万次
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 10000; j++ {
// 加锁保护临界区
mu.Lock()
count++
mu.Unlock()
}
}()
}
wg.Wait()
fmt.Println("加锁实现一个计数器的结果:", count) //稳定输出 100000再次运行,结果稳定为 100000,完美解决并发安全问题。
Mutex 的进阶用法
(1)嵌入结构体
实际开发中,常把 Mutex 嵌入自定义结构体,让锁和资源绑定。
如下示例会启动 100 个 goroutine,每个 goroutine 对计数器进行 1000 次递增操作。通过 sync.WaitGroup 等待所有 goroutine 完成后,打印最终的计数值。
go
// Counter 是一个线程安全的计数器
type Counter struct {
mu sync.Mutex
count uint64
}
// Incr 对计数器进行加1操作
func (c *Counter) Incr() {
c.mu.Lock() //使用了 `sync.Mutex` 进行保护,所以程序是线程安全的
defer c.mu.Unlock()
c.count++
}
// Get 获取当前计数器的值
func (c *Counter) Get() uint64 {
c.mu.Lock() //使用了 `sync.Mutex` 进行保护,所以程序是线程安全的
defer c.mu.Unlock()
return c.count
}
func main() {
// 1. 初始化一个 Counter 实例
var counter Counter
// 2. 使用 sync.WaitGroup 来等待所有 goroutine 完成
var wg sync.WaitGroup
// 3. 定义要启动的 goroutine 数量和每个 goroutine 的迭代次数
const numGoroutines = 100
const iterationsPerGoroutine = 1000
// 4. 启动多个 goroutine 并发地增加计数器
for i := 0; i < numGoroutines; i++ {
// 为每个 goroutine 增加 WaitGroup 的计数
wg.Add(1)
// 启动 goroutine
go func(goroutineID int) {
// 在 goroutine 退出时,将 WaitGroup 的计数减 1
defer wg.Done()
// 每个 goroutine 执行 1000 次递增
for j := 0; j < iterationsPerGoroutine; j++ {
counter.Incr()
}
// 可选:打印每个 goroutine 完成的信息
// fmt.Printf("Goroutine %d finished. Counter is now: %d\n", goroutineID, counter.Get())
}(i) // 注意:这里将循环变量 i 作为参数传入,避免闭包引用问题
}
// 5. 等待所有 goroutine 完成它们的工作
wg.Wait()
// 6. 获取并打印最终的计数器值
finalCount := counter.Get()
fmt.Printf("\n最终的计数器值: %d\n", finalCount)
// 7. 验证结果是否正确
expectedCount := uint64(numGoroutines * iterationsPerGoroutine)
fmt.Printf("验证结果是否正确: %v\n", expectedCount == finalCount)
}由于 Counter 的 Incr 和 Get 方法都使用了 sync.Mutex 进行保护,所以程序是线程安全的。无论你运行多少次,输出结果都应该是:
最终的计数器值: 100000
验证结果是否正确: true
如果你注释掉 Incr 和 Get 方法中的 c.mu.Lock() 和 c.mu.Unlock() 代码,程序就会存在数据竞争 。此时,多个 goroutine 会同时读写 count 变量,导致最终的计数值总是小于预期的 100000,并且每次运行的结果都可能不同。
最终的计数器值: 51517
验证结果是否正确: false
(2)零值可用
Mutex 的零值就是未加锁状态,无需额外初始化,直接声明即可使用:
go
var mu sync.Mutex // 直接使用,无需New
mu.Lock()
// 业务逻辑
mu.Unlock()在 Go 语言中,当你声明一个变量但没有为它赋初始值时,它会被赋予该类型的零值。
- 对于
int,零值是0。 - 对于
string,零值是""。 - 对于
bool,零值是false。
对于 sync.Mutex 这种结构体类型,它的零值是一个合法的、可用的、处于未加锁状态的互斥锁 。这意味着你可以直接声明变量并立即使用它的方法,无需像其他语言或某些 Go 类型那样,需要调用一个 New 函数或进行显式初始化。
sync.Mutex 的结构体定义如下:
go
type Mutex struct {
state int32 //这是一个 32 位整数,用来表示锁的当前状态,比如是否已被锁定、是否有 goroutine 在等待等
sema uint32 //这是一个信号量,用于 goroutine 之间的同步
}当你声明
var mu sync.Mutex时,mu 的 state 字段会被初始化为 0,sema 字段也会被初始化为 0。
Mutex的TryLock
有时候我们不想阻塞等待锁(也就是 非阻塞获取锁),获取不到就直接放弃,这时候可以使用Mutex的TryLock:
定义如下:
go
func (m *Mutex) TryLock() bool {
old := m.state
if old&(mutexLocked|mutexStarving) != 0 {
return false
}
// There may be a goroutine waiting for the mutex, but we are
// running now and can try to grab the mutex before that
// goroutine wakes up.
if !atomic.CompareAndSwapInt32(&m.state, old, old|mutexLocked) {
return false
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return true
}以下案例展示 TryLock 的核心用法:非阻塞地尝试获取锁,获取不到就立即返回。
go
func main() {
var mu sync.Mutex
var wg sync.WaitGroup
// 定义一个尝试获取锁并执行任务的函数
tryTask := func(id int) {
defer wg.Done()
fmt.Printf("Goroutine %d: 尝试获取锁...\n", id)
// 尝试非阻塞地获取锁
if mu.TryLock() {
// 成功获取到锁
fmt.Printf("Goroutine %d: 成功获取锁,开始执行任务...\n", id)
time.Sleep(2 * time.Second) // 模拟任务执行
fmt.Printf("Goroutine %d: 任务执行完毕,释放锁。\n", id)
mu.Unlock() // 释放锁
} else {
// 未能获取到锁
fmt.Printf("Goroutine %d: 获取锁失败,任务被跳过。\n", id)
}
}
wg.Add(2)
go tryTask(1)
go tryTask(2)
wg.Wait()
fmt.Println("所有任务处理完毕。")
}运行效果示例:
Goroutine 2: 尝试获取锁...
Goroutine 2: 成功获取锁,开始执行任务...
Goroutine 1: 尝试获取锁...
Goroutine 1: 获取锁失败,任务被跳过。
Goroutine 2: 任务执行完毕,释放锁。
所有任务处理完毕。
用 Mutex 实现线程安全队列
结合 Mutex 和切片,可以实现简单的线程安全队列:
go
// SafeQueue 一个使用 sync.Mutex 实现的线程安全队列
type SafeQueue struct {
mu sync.Mutex
data []interface{}
}
// 入队: 将一个元素添加到队列尾部
func (q *SafeQueue) Enqueue(item interface{}) {
q.mu.Lock()
defer q.mu.Unlock()
q.data = append(q.data, item)
}
// 出队: 从队列头部移除并返回一个元素; 如果队列为空,返回一个错误
func (q *SafeQueue) Dequeue() interface{} {
q.mu.Lock()
defer q.mu.Unlock()
if len(q.data) == 0 {
return nil
}
item := q.data[0]
q.data = q.data[1:]
return item
}RWMutex的用法
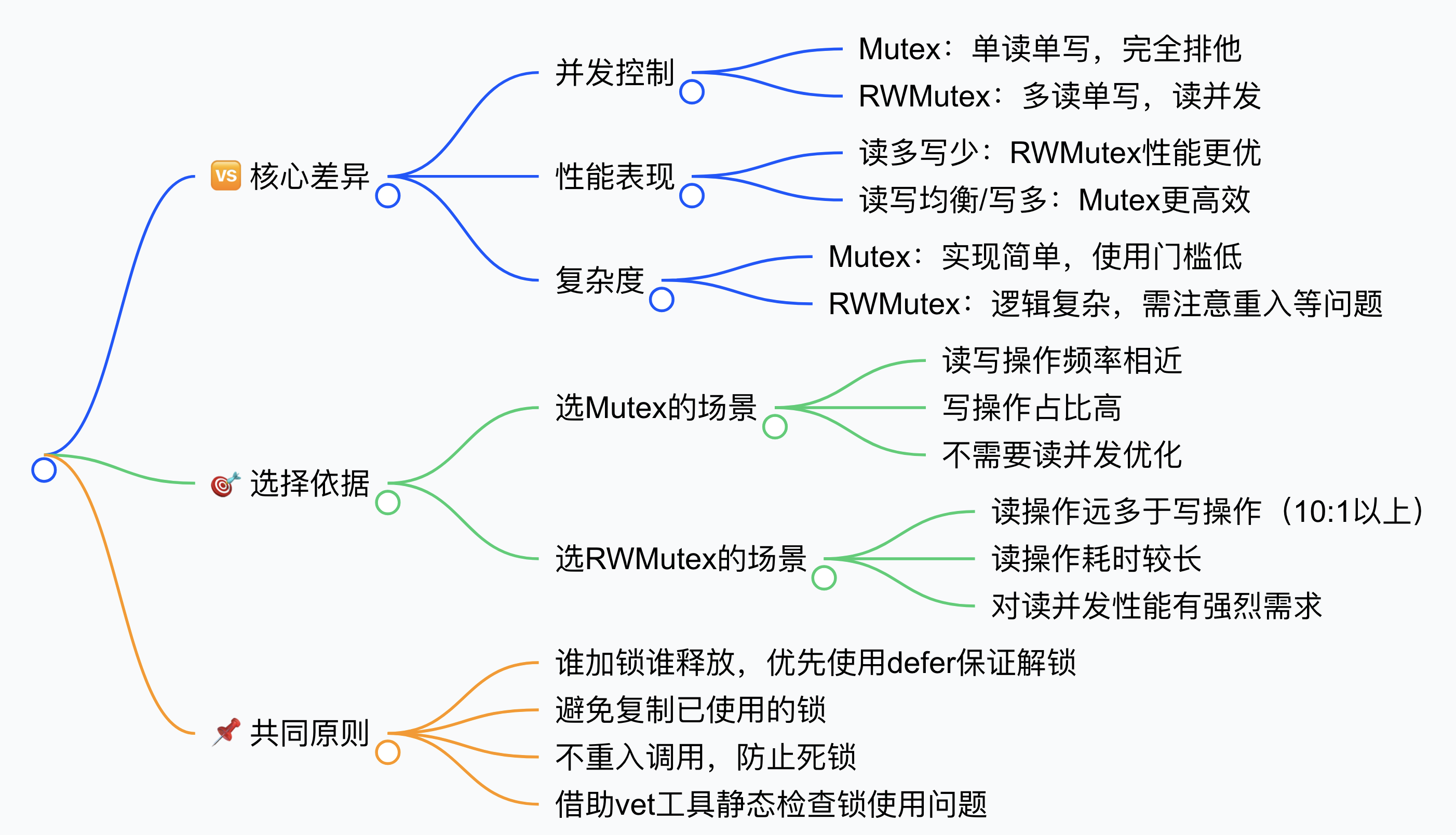
Mutex 不管在读的场景还是写的场景都属于排它锁,在 读多写少的 场景中(比如缓存查询、配置读取)中会浪费性能,因为多个读操作其实可以同时进行。这时候就需要用到 RWMutex 了。
RWMutex 基于 Mutex 实现,它的设计原则是写优先:当有写者等待时,新的读者会被阻塞。
核心字段包括:
w:保护写者竞争的 MutexreaderCount:读者数量(负值表示有写者等待)readerWait:写者等待的读者数量- 两个信号量:用于阻塞和唤醒
核心方法分为读锁和写锁两组:
- 写锁:
Lock() / Unlock()(排他锁,同一时间只能有一个写者) - 读锁:
RLock() / RUnlock()(共享锁,同一时间可以有多个读者)
实战示例:我们来模拟一个简单的电商场景:
- 创建/修改/删除 商品 :这是写操作,需要用写锁保护,因为它会修改共享数据(商品列表)。
- 查询商品信息 :这是读操作,可以用读锁保护,因为它只是读取数据,不会修改。在高并发下,多个用户可以同时查询,不会相互阻塞。
go
// Product 代表一个商品
type Product struct {
ID int
Name string
Price float64
}
// ProductStore 是一个线程安全的商品存储
type ProductStore struct {
rwmu sync.RWMutex
products map[int]Product
}
func NewProductStore() *ProductStore {
return &ProductStore{
products: make(map[int]Product),
}
}
// CreateProduct 创建商品 (写操作)
func (ps *ProductStore) CreateProduct(p Product) {
ps.rwmu.Lock()
defer ps.rwmu.Unlock()
time.Sleep(10 * time.Millisecond) // 模拟数据库延迟
ps.products[p.ID] = p
fmt.Printf("[CREATE] 商品 '%s' (ID: %d) 已上架。\n", p.Name, p.ID)
}
// UpdateProduct 修改商品价格 (写操作)
func (ps *ProductStore) UpdateProduct(id int, newPrice float64) bool {
ps.rwmu.Lock()
defer ps.rwmu.Unlock()
time.Sleep(10 * time.Millisecond) // 模拟数据库延迟
p, exists := ps.products[id]
if !exists {
fmt.Printf("[UPDATE] 商品 ID: %d 不存在,更新失败。\n", id)
return false
}
p.Price = newPrice
ps.products[id] = p
fmt.Printf("[UPDATE] 商品 %s (ID: %d) 价格已更新为: %.2f。\n", p.Name, id, newPrice)
return true
}
// DeleteProduct 删除商品 (写操作)
func (ps *ProductStore) DeleteProduct(id int) bool {
ps.rwmu.Lock()
defer ps.rwmu.Unlock()
time.Sleep(10 * time.Millisecond) // 模拟数据库延迟
if _, exists := ps.products[id]; !exists {
fmt.Printf("[DELETE] 商品 ID: %d 不存在,删除失败。\n", id)
return false
}
delete(ps.products, id)
fmt.Printf("[DELETE] 商品 ID: %d 已下架。\n", id)
return true
}
// GetProduct 查询单个商品 (读操作)
func (ps *ProductStore) GetProduct(id int) (Product, bool) {
ps.rwmu.RLock()
defer ps.rwmu.RUnlock()
time.Sleep(5 * time.Millisecond) // 模拟数据库延迟
p, exists := ps.products[id]
if exists {
fmt.Printf("[QUERY] 用户查询到商品: %s (ID: %d), 价格: %.2f。\n", p.Name, p.ID, p.Price)
} else {
fmt.Printf("[QUERY] 用户查询商品 ID: %d 不存在。\n", id)
}
return p, exists
}
func main() {
store := NewProductStore()
var wg sync.WaitGroup
// 1. 初始创建几个商品
fmt.Println("--- 阶段 1: 初始化商品 ---")
initialProducts := []Product{
{ID: 1, Name: "iPhone17", Price: 7999.0},
{ID: 2, Name: "苹果原装充电器", Price: 825.88},
}
for _, p := range initialProducts {
wg.Add(1)
go func(product Product) {
defer wg.Done()
store.CreateProduct(product)
}(p)
}
wg.Wait()
// 2. 模拟并发操作:查询、更新、删除
fmt.Println("\n--- 阶段 2: 并发操作 ---")
// 模拟多个用户并发查询
for i := 0; i < 5; i++ {
wg.Add(1)
go func() {
defer wg.Done()
store.GetProduct(common.GenerateRandomNumber(1, 2)) // 随机查询商品
}()
}
// 后台管理员更新商品价格
wg.Add(1)
go func() {
defer wg.Done()
time.Sleep(100 * time.Millisecond) // 稍微延迟,确保有查询在进行
store.UpdateProduct(1, 6999.0) // 给 iPhone17 降价
}()
// 另一个管理员删除商品
wg.Add(1)
go func() {
defer wg.Done()
time.Sleep(200 * time.Millisecond) // 再延迟一些
store.DeleteProduct(2) // 删除商品 苹果原装充电器
}()
// 更新和删除后,再进行一些查询,验证结果
wg.Add(2)
go func() {
defer wg.Done()
time.Sleep(300 * time.Millisecond)
store.GetProduct(1) // 应该能查到更新后的价格
}()
go func() {
defer wg.Done()
time.Sleep(300 * time.Millisecond)
store.GetProduct(2) // 应该查询不到,因为已被删除
}()
wg.Wait()
}-
写操作(
CreateProduct) :使用Lock()。当管理员创建商品时,其他所有试图创建或查询商品的操作都会被阻塞,确保了商品数据在写入时的一致性。 -
读操作(
GetProduct) :使用RLock()。多个用户可以同时查询到商品信息,他们的查询操作是并发执行的,不会互相等待。这大大提高了系统在高并发读场景下的吞吐量和响应速度。
运行结果示例:
--- 阶段 1: 初始化商品 ---
CREATE 商品 '苹果原装充电器' (ID: 2) 已上架。
CREATE 商品 'iPhone17' (ID: 1) 已上架。
--- 阶段 2: 并发操作 ---
QUERY 用户查询到商品: 苹果原装充电器 (ID: 2), 价格: 825.88。
QUERY 用户查询到商品: iPhone17 (ID: 1), 价格: 7999.00。
QUERY 用户查询到商品: iPhone17 (ID: 1), 价格: 7999.00。
QUERY 用户查询到商品: 苹果原装充电器 (ID: 2), 价格: 825.88。
QUERY 用户查询到商品: 苹果原装充电器 (ID: 2), 价格: 825.88。
UPDATE 商品 iPhone17 (ID: 1) 价格已更新为: 6999.00。
DELETE 商品 ID: 2 已下架。
QUERY 用户查询商品 ID: 2 不存在。
QUERY 用户查询到商品: iPhone17 (ID: 1), 价格: 6999.00。
细节和注意事项
在使用 Mutex和RWMutex 的时候,需要注意以下细节问题:
1. Lock/Unlock 未成对出现
- 常见场景:if-else 分支中漏写 Unlock,重构时误删 Lock
- 后果:死锁(漏 Unlock)或 panic(漏 Lock 却调用 Unlock)
- 解决方案:始终用
defer mu.Unlock(),紧跟在 Lock 之后
go
// 正确写法
mu.Lock()
defer mu.Unlock() // 确保无论如何都会释放锁
if err != nil {
return err // 无需手动解锁
}
// 业务逻辑2. 复制已使用的锁
Mutex 和 RWMutex 都是有状态的,复制已加锁的实例会导致状态错乱,引发死锁。
错误示例:函数参数按值传递锁。当你将一个包含 Mutex 的结构体(如 Counter)按值传递给函数时,会创建该结构体的一个副本,其中也包括了 Mutex 的状态。这会导致锁的状态错乱,引发潜在的死锁或数据竞争。
go
package main
import (
"sync"
)
// Counter 一个包含互斥锁的计数器结构体
type Counter struct {
mu sync.Mutex
count int
}
// foo 函数按值接收一个 Counter
// 错误:这会复制整个 Counter,包括内部的 mu
func foo(c Counter) {
c.mu.Lock() // 操作的是副本的锁
c.count++
c.mu.Unlock() // 释放的是副本的锁
}
func main() {
var c Counter
// 调用 foo 函数,会发生值拷贝
for i := 0; i < 1000; i++ {
foo(c)
}
// main 函数中的 c 和 foo 函数中的 c 是两个完全独立的实例
// 对 foo 中副本的操作不会影响到 main 中的实例
println(c.count) // 输出:0
}解决方案:通过传递结构体的指针,所有函数调用都将操作同一个结构体实例及其内部的锁,从而保证了并发安全。
go
// foo 函数接收一个 Counter 的指针
// 正确:所有操作都针对同一个 Counter 实例
func foo(c *Counter) {
c.mu.Lock() // 操作的是原始实例的锁
c.count++
c.mu.Unlock() // 释放的是原始实例的锁
}
func main() {
var c Counter
// 调用 foo 函数,传递 c 的地址
for i := 0; i < 1000; i++ {
foo(&c)
}
// main 函数中的 c 和 foo 函数中操作的 c 是同一个实例
// foo 中的操作会正确地修改 main 中 c 的 count 值
println(c.count) // 输出:1000
}3. 重复加锁导致死锁
同一 goroutine 对同一个 sync.Mutex 多次调用 Lock(),会立即导致死锁。因为 Mutex 是互斥锁,当前 goroutine 已经持有锁,再次请求会阻塞自己,且没有其他 goroutine 会释放锁。
go
// 错误示例:重入锁导致死锁
func foo(m *sync.Mutex) {
m.Lock()
bar(m) // 再次加锁,死锁!
m.Unlock()
}
func bar(m *sync.Mutex) {
m.Lock()
// ...
m.Unlock()
}报错信息:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 sync.Mutex.Lock:
4. 释放未加锁的锁
多余的 Unlock 或 RUnlock 会直接 panic,生产环境中一定要避免:
go
// 错误示例:释放未加锁的锁
var mu sync.Mutex
mu.Unlock() // panic: sync: unlock of unlocked mutexMutex 和 RWMutex如何选择
| 特性 | Mutex | RWMutex |
|---|---|---|
| 并发控制 | 单读单写 | 多读单写 |
| 性能(读多写少) | 较低 | 较高 |
| 性能(写多) | 较高 | 较低 |
| 复杂度 | 简单 | 复杂 |
| 适用场景 | 读写均衡、写操作多 | 读操作远多于写操作 |
实际项目中的使用建议:
- 优先使用Mutex:读多写少用 RWMutex,读写均衡用 Mutex。在不确定的场景下,先使用Mutex,后期再根据性能需求考虑RWMutex。
- 锁要精简:尽量减少临界区的代码,只保护必要的部分。
- 使用defer:确保锁一定会被释放,避免忘记Unlock。始终遵循 "谁加锁谁释放",用 defer 保证解锁。
- 避免锁嵌套:复杂的锁依赖关系容易导致死锁,避免复制已使用的锁、重入锁、释放未加锁的锁。
- 监控锁竞争:使用pprof等工具监控锁的竞争情况,及时发现性能瓶颈。
以上示例代码参考:https://gitee.com/rxbook/go-demo-2025/tree/master/demo/mutex
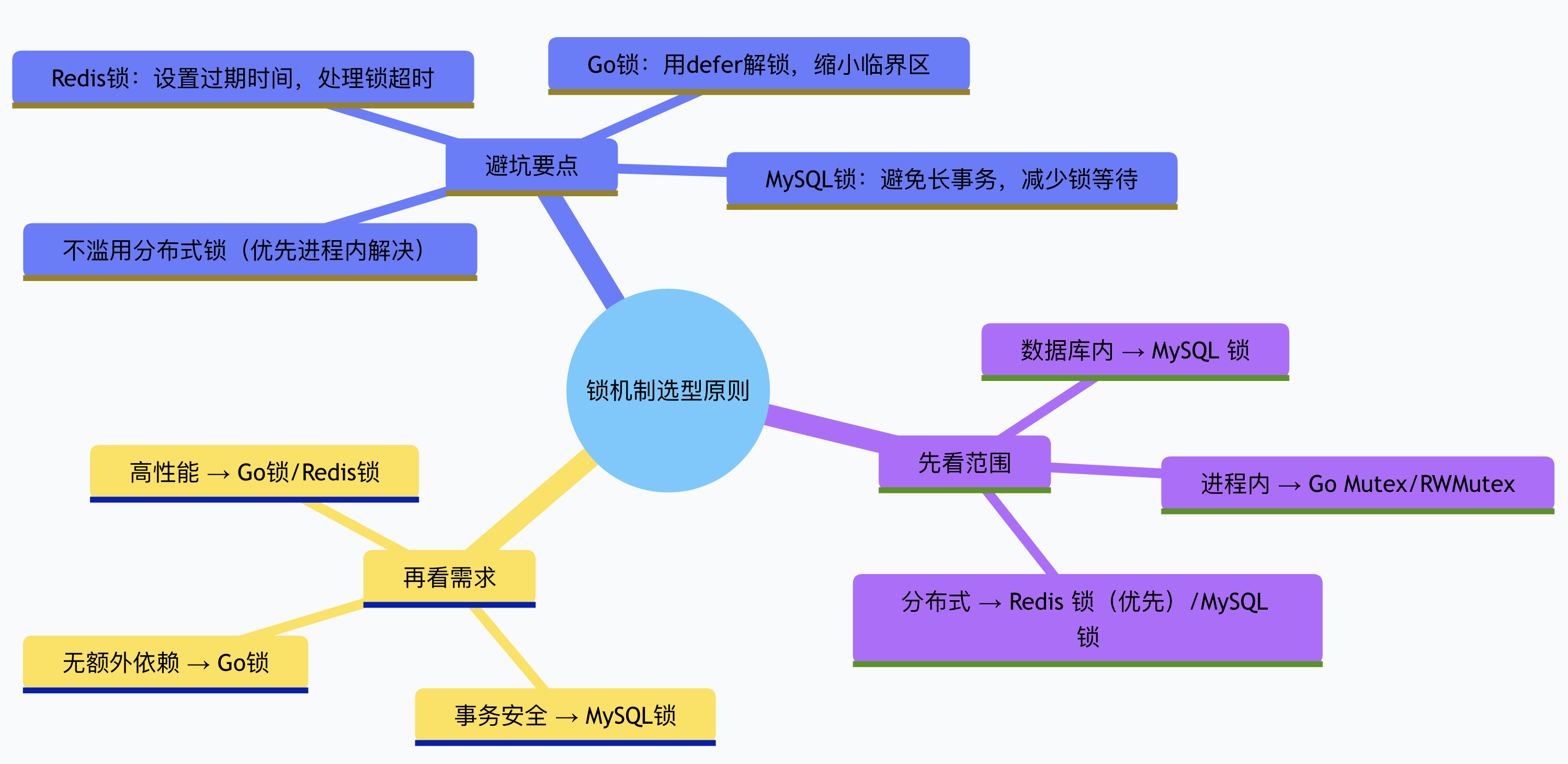
对比MySQL和Redis的锁
我在之前的文章中简单描述过MySQL中锁的基本用法,可以参考以下文章:
这里说到Go语言内置的锁机制了,就再啰嗦两句,对比下。
MySQL 的锁与 Go 锁本质一致,只是面向的共享资源不同:Go 的锁保护内存中的变量 ,解决进程内 goroutine 的并发冲突;MySQL 的锁保护磁盘上的数据行/表,解决多客户端事务的并发冲突;在分布式系统中,MySQL 锁和 Redis 锁又常常用于解决跨服务的数据竞争问题。
那么,既然 Go 已经内置了高效的锁机制,为什么实际项目中还需要依赖 MySQL 或 Redis 锁?
| 对比维度 | Go Mutex/RWMutex | MySQL 锁(表锁/行锁/间隙锁) | Redis 锁(SET NX/Redlock) |
|---|---|---|---|
| 作用范围 | 单进程内的 goroutine 间 | 单 MySQL 实例内的会话 / 事务间 | 分布式系统的跨服务 / 跨机器节点间 |
| 性能开销 | 极低(内存操作,无网络延迟) | 中低(依赖存储引擎,磁盘 IO 影响) | 中(需网络通信,缓存操作高效) |
| 适用场景 | 进程内共享资源(如内存缓存、计数器) | 数据库数据的增删改查(事务安全) | 分布式任务调度、跨服务库存扣减等 |
| 核心优势 | 简单高效、无额外依赖 | 天然支持事务、数据持久化 | 高可用、跨节点、性能优越 |
| 常见问题 | 无法跨进程、无超时自动释放 | 锁等待超时、死锁风险、性能瓶颈 | 网络分区风险、锁超时处理复杂 |
| 解锁保障 | 需手动解锁(defer 必用) | 事务结束自动释放(Commit/Rollback) | 需手动释放或设置过期时间 |
实际项目中的用法差异
1. Go内置的锁:进程内goroutine安全
代码示例:
go
// 进程内线程安全的计数器(用 Mutex 保护临界区)
type Counter struct {
mu sync.Mutex
count int
}
func (c *Counter) Incr() {
c.mu.Lock()
defer c.mu.Unlock() // 确保解锁
c.count++ // 临界区仅保留必要操作
}核心场景:单服务内的内存共享数据(如本地缓存更新、全局计数器),无需跨进程通信。
2. MySQL的锁:数据库事务安全
sql
-- 行锁:更新商品库存(事务内自动加锁,提交后释放)
BEGIN;
SELECT stock FROM product WHERE id=1 FOR UPDATE; -- 悲观行锁,防止并发修改
UPDATE product SET stock=stock-1 WHERE id=1;
COMMIT; -- 事务结束自动解锁核心场景:数据库层面的数据一致性(如订单创建、库存扣减),依赖事务 ACID 特性。
3. Redis的锁:分布式跨服务安全
go
// Redis 分布式锁(基于 SET NX + EX 实现,Go 客户端示例)
func AcquireRedisLock(redisCli *redis.Client, key string, expire int) (bool, error) {
// NX:仅当 key 不存在时设置,EX:自动过期(避免死锁)
return redisCli.SetNX(context.Background(), key, "locked", time.Duration(expire)*time.Second).Result()
}
func ReleaseRedisLock(redisCli *redis.Client, key string) error {
return redisCli.Del(context.Background(), key).Err()
}核心场景:跨服务的资源竞争(如分布式定时任务、多服务共享库存)。
Go已有锁,为何还需MySQL/Redis 锁?
答案的核心是 "作用范围不同" ------ Go 锁解决的是 "进程内" 的并发安全,而 MySQL/Redis 锁解决的是 "跨进程 / 跨服务" 的并发安全,二者无法相互替代,具体分两种情况:
1. 单服务架构:优先用 Go 锁,MySQL 锁按需补充
- 若仅需保护内存中的共享数据 (如本地缓存、全局变量),直接用
Mutex/RWMutex,性能最优且无额外依赖; - 若操作数据库数据(如更新用户余额),需用 MySQL 锁(或事务隔离级别)保障数据一致性,此时 Go 锁无法替代 ------ 因为数据库操作是跨会话的,进程内的 Go 锁无法控制其他进程(或同一进程的不同数据库连接)对数据的修改。
2. 分布式架构:必须用 MySQL/Redis 锁
当系统部署为多服务实例(如微服务集群、多机部署)时,Go 锁完全失效 ------ 因为不同服务实例运行在不同进程(甚至不同机器),进程内的锁无法跨节点同步。此时必须依赖分布式锁:
- 例 1:电商秒杀场景,多服务实例同时扣减同一商品库存,需用 Redis 锁保证不会超卖;
- 例 2:分布式定时任务,需用 Redis 锁避免多个服务实例重复执行同一任务;
- 例 3:跨服务转账,需用 MySQL 锁(或分布式事务)保证资金一致性。
3. 补充:特殊场景的混合使用
- 场景:单服务实例中,既需要操作本地缓存,又需要更新数据库;
- 用法:用 Go 锁保护本地缓存的读写,用 MySQL 锁(或事务)保护数据库操作,二者各司其职。