软件体系结构设计的一个核心目标是重复的体系结构模式,即达到体系结构级的软件重用。
也就是说,在不同的软件系统中,使用同一体系结构。基于这个目标,主要任务是研究和实践软件体系结构风格和类型问题。
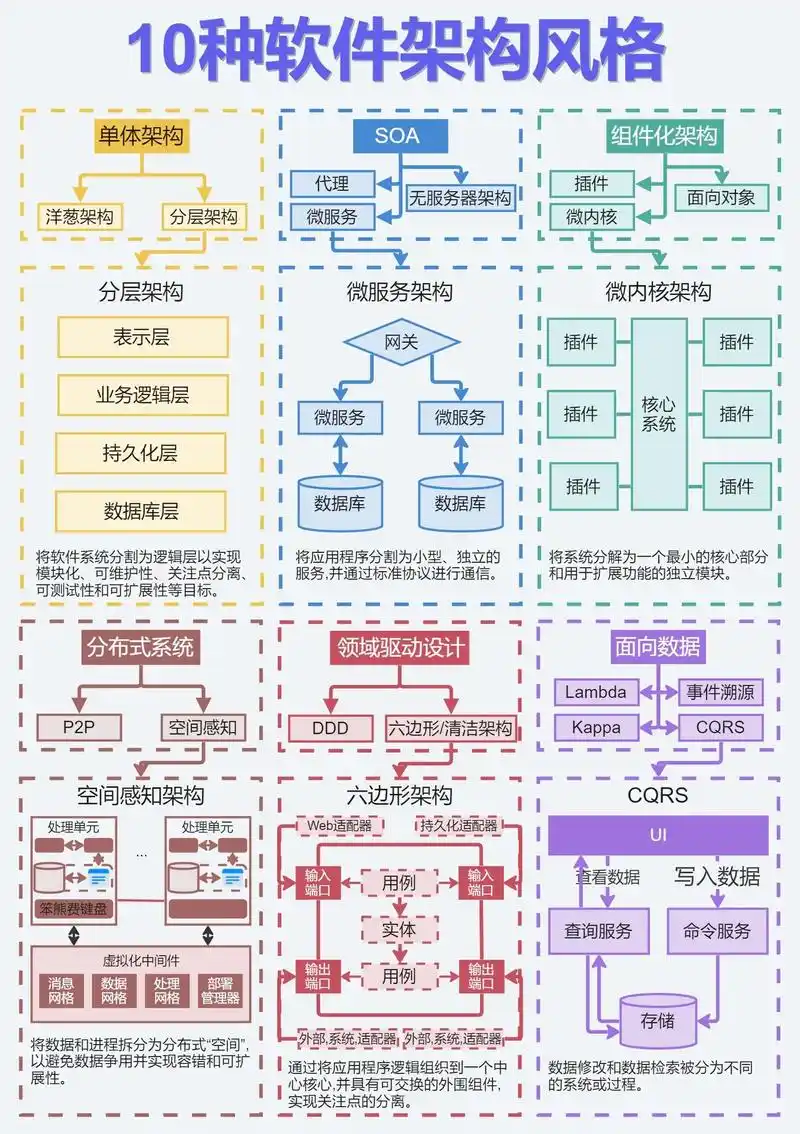
一、 软件架构风格概述
软件架构风格是描述某一特定应用领域中系统组织方式的惯用模式。
例如,建筑有中式风格、美式风格、日式风格等。
架构风格定义了一个系统家族,即一个架构定义一个词汇表和一组约束。词汇表中包含一些构件和连接件类型,而这组约束指出系统是如何将这些构件和连接件组合起来的。
核心定义:架构风格是某一应用领域中,系统组织方式的"惯用模式"。它包含两部分:
- 词汇表:明确系统的"构件类型"(如模块、子系统)和"连接件类型"(如数据管道、函数调用)。
- 约束规则:规定构件与连接件的组合方式(如数据单向流动、分层调用不跨层)。
词汇表中包含一些构件和连接件类型,而这组约束指出系统是如何将这些构件和连接件组合起来的。
软件架构风格反映了领域中众多系统所共有的结构和语义特性,并指导如何将各个模块和子系统有效地组织成一个完整的系统。
核心价值:
- 实现"架构级重用":同一风格可复用在不同系统(如分层架构可用于电商、政务系统)。
- 降低设计复杂度:提供成熟的组织框架,避免从零设计系统结构。
- 选择灵活:需结合项目需求(如性能、耦合度)选择,无"万能风格"。
对软件体系结构风格的研究和实践促进对设计的重用,一些经过实践证实的解决方案也可以可靠地用于解决新的问题。
例如,如果某人把系统描述为"客户/服务器"模式,则不必给出设计细节,人们立刻就会明白系统是如何组织和工作的。
信息系统架构设计的一个核心问题是能否使用重复的信息系统架构模式,即能否达到架构级别的软件重用。也就是说,能否在不同的软件系统中,使用同一架构。
按这种方式理解,信息系统架构风格定义了用于描述系统的术语表和一组指导构建系统的规则。信息系统架构风格为大粒度的软件重用提供了可能。
然而,对于应用架构风格来说,由于视点的不同,架构设计师有很大的选择余地。要为系统选择或设计某一个架构风格,必须根据特定项目的具体特点,进行分析比较后再确定,架构风格的使用几乎完全是特定的。
信息系统架构风格通常也遵循通用的架构风格 :
- (1)数据流风格:批处理序列;管道/过滤器。
- (2)调用/返回风格:主程序/子程序;面向对象风格;层次结构。
- (3)独立构件风格:进程通信;事件系统。
- (4)虚拟机风格:解释器;基于规则的系统。
- (5)仓库风格:数据库系统;超文本系统;黑板系统。
下面详细介绍每类风格均包含"核心特点+具体案例+补充说明",明确其"词汇表(构件/连接件)"和"约束规则":
二、数据流风格
数据流体系结构是一种计算机体系结构,直接与传统的冯·诺依曼体系结构或控制流体系结构进行了对比。
数据流体系结构没有概念上的程序计数器:指令的可执行性和执行仅基于指令输入参数的可用性来确定,因此,指令执行的顺序是不可预测的,即行为是不确定的。数据流体系结构风格主要包括批处理风格和管道-过滤器风格。
核心特点:系统由"数据处理单元"和"数据传输通道"组成,数据按固定路径单向流动,构件无状态(不存储中间数据)。
(一)批处理风格
在批处理风格的软件体系结构中,每个处理步骤是一个单独的程序,每一步必须在前一步结束后才能开始,并且数据必须是完整的,以整体的方式传递。
它的基本构件是独立的应用程序,连接件是某种类型的媒介。
连接件定义了相应的数据流图,表达拓扑结构。

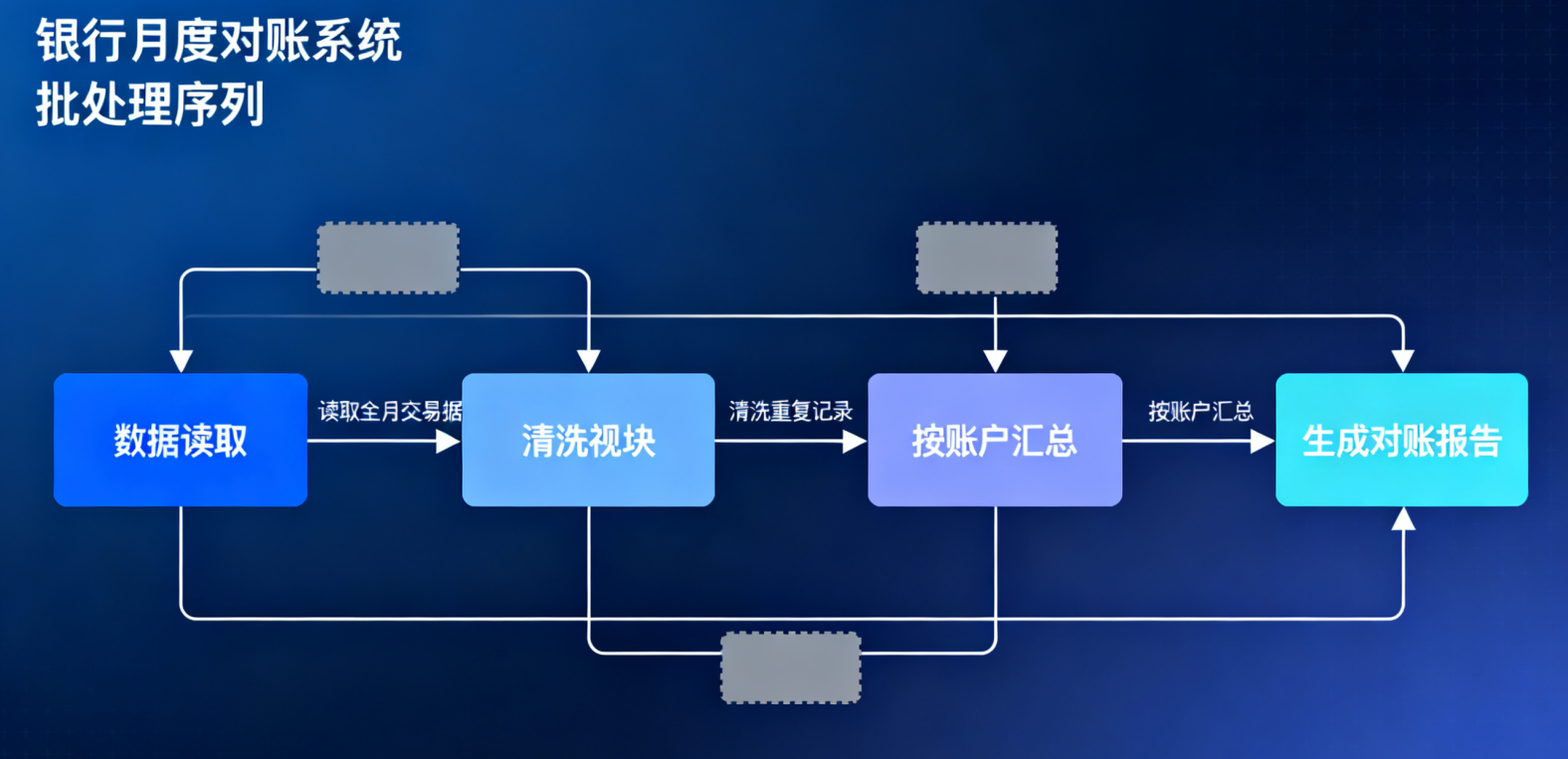
1. 案例
银行月度对账系统。流程为"读取全月交易数据→清洗重复记录→按账户汇总→生成对账报告",数据批量输入、批量处理、批量输出。
补充说明:构件是"数据读取模块、清洗模块、汇总模块、报告生成模块",连接件是"临时数据文件";约束是"必须完成前一步才能开始后一步,数据不可回溯"。
2.特点
无论属于哪个领域,典型的批处理序列程序通常都具有以下特点:
-
自动化: 无需人工干预,按计划(如 cron job)或事件触发(如文件到达)自动运行。
-
处理量大: 面向大量数据项或复杂计算任务。
-
顺序性: 任务步骤有明确的先后顺序,前一步的输出可能是后一步的输入。
-
高可靠性: 需要具备错误处理和日志记录能力,以便在长时间运行中排查问题。
-
资源敏感: 通常会消耗大量 CPU、内存或 I/O 资源,因此常被安排在系统负载较低的时段(如夜间)执行。
3.典型批处理序列程序
| 类别 | 程序名称 | 主要用途 | 特点 |
|---|---|---|---|
| 操作系统脚本 | Windows Batch (.bat) | Windows系统自动化、文件管理、软件部署。 | 内置于Windows,语法简单,与Windows系统紧密集成。 |
| Windows PowerShell (.ps1) | 系统配置、自动化管理、处理对象而不仅是文本。 | 功能强大,面向对象,可以管理几乎所有Windows组件。 | |
| Shell Script (.sh) | Unix/Linux/macOS系统管理、软件安装、日志分析。 | 灵活高效,拥有海量的命令行工具(如 grep, awk, sed)支持。 | |
| 数据处理与ETL | Apache Spark | 大规模数据清洗、转换、分析和机器学习。 | 分布式计算,内存处理,速度极快,适合海量数据批处理。 |
| Apache Flink | 流处理和批处理,尤其擅长有状态的计算。 | 高吞吐、低延迟,统一了流和批的处理模型。 | |
| Informatica / Talend | 企业级数据提取、转换、加载。 | 图形化界面,功能全面,支持复杂的数据集成任务。 | |
| 媒体处理 | FFmpeg | 视频/音频格式转换、剪辑、压缩、截图等。 | 命令行工具,支持几乎所有媒体格式,是众多视频软件的后端核心。 |
| ImageMagick | 批量图片格式转换、调整大小、添加水印、特效等。 | 功能极其丰富的命令行图片处理工具集。 | |
| 科学计算与模拟 | MATLAB / GNU Octave | 数值计算、算法开发、数据分析和仿真。 | 提供完整的数学函数库和编程环境,常用于工程和科研领域。 |
| Python (with NumPy/Pandas) | 数据分析、机器学习、科学计算、自动化脚本。 | 语法简洁,拥有庞大的科学计算库生态系统,通用性强。 | |
| 编译与构建 | Make | 自动化软件编译和构建过程。 | 通过 Makefile 定义源文件之间的依赖关系,只编译变更的部分。 |
| GCC / Clang | 将源代码(如C/C++)编译成可执行程序。 | 编译器本身,通常被 Make 或构建系统调用以进行批处理编译。 |
|
| 打印与文档 | 打印队列处理程序 | 管理打印任务,按顺序将文档发送到打印机。 | 操作系统核心组件,是典型的"先进先出"批处理系统。 |
| Adobe Acrobat Distiller | 将PostScript文件批量转换为PDF文件。 | 专业且经典的文档格式批处理转换工具。 |
(二)管道-过滤器风格
当数据源源不断地产生,系统就需要对这些数据进行若干处理(分析、计算、转换等)。现有的解决方案是把系统分解为几个序贯的处理步骤,这些步骤之间通过数据流连接,一个步骤的输出是另一个步骤的输入。
每个处理步骤由一个过滤器 (Filter) 实现,处理步骤之间的数据传输由管道 (Pipe) 负责。每个处理步骤(过滤器)都有一组输入和输出,过滤器从管道中读取输入的数据流,经过内部处理,然后产生输出数据流并写入管道中。
因此,管道-过滤器风格(见图)的基本构件是过滤器,连接件是数据流传输管道,将一个过滤器的输出传到另一过滤器的输入。

1.案例
日志分析系统。流程为"日志采集→解析字段→过滤无效日志→统计访问量→存储结果",每个环节独立处理,数据通过"管道"传递。
补充说明:构件是"过滤器"(解析、过滤、统计),连接件是"管道"(数据流转通道);约束是"数据单向流动,过滤器仅依赖输入数据,不共享状态",适合实时数据处理。

2.特点
典型的管道/过滤器风格的程序如下:
| 特征 | 说明 |
|---|---|
| 数据流 | 数据以流的形式在处理单元间传递 |
| 增量处理 | 过滤器在接收到部分数据时即可开始处理 |
| 并发性 | 多个过滤器可以并行执行,形成处理流水线 |
| 连接方式 | 通过管道(内存缓冲区)连接各个过滤器 |
| 独立性 | 每个过滤器是独立的处理单元,职责单一 |
| 组合性 | 过滤器可以灵活组合,构建复杂处理流程 |
3.典型管道-过滤器架构风格程序
管道/过滤器架构风格 - 典型程序示例:
| 类别 | 典型程序/系统 | 具体示例 | 架构特点 |
|---|---|---|---|
| Unix/Linux命令行 | grep, sort, uniq, awk, sed 等 |
`grep "error" app.log | sort |
| 实时数据处理 | Apache Kafka Streams | 用户点击流处理:事件采集 → 过滤清洗 → 会话聚合 → 异常检测 → 结果存储 | - Kafka主题作为管道 - 无界数据流处理 - 拓扑结构 |
| 流计算框架 | Apache Flink / Apache Storm | Source → Map/Filter → Window Aggregation → Sink | - 专门的流处理引擎 - 低延迟实时计算 - 有向无环图 |
| 编译器系统 | 传统编译器 | 源代码 → 词法分析 → 语法分析 → 语义分析 → 代码生成 | - 阶段化处理流水线 - 中间表示(IR)传递 - 逻辑上的管道 |
| 音视频处理 | FFmpeg | ffmpeg -i input.mp4 -vf "scale=640:480,drawtext=text='Hello'" output.mp4 |
- 滤镜图概念 - 音视频帧流处理 - 复杂的过滤器链 |
| 图像处理 | ImageMagick | convert input.jpg -resize 50% -blur 0x2 output.jpg |
- 多个操作串联 - 图像数据流传递 - 命令链式调用 |
| 信号处理 | 音频效果链 | 音频输入 → 降噪 → 均衡 → 混响 → 输出 | - 实时信号处理 - 样本级流水线 - 低延迟要求 |
| 金融数据处理 | 实时行情处理 | 行情源 → 校验 → 计算指标 → 生成信号 → 风控 | - 高吞吐数据流 - 逐笔数据处理 - 严格时序要求 |
三、调用/返回风格
调用/返回风格是指在系统中采用了调用与返回机制。利用调用-返回实际上是一种分而治之的策略,其主要思想是将一个复杂的大系统分解为若干子系统,以便降低复杂度,并且增加可修改性。
程序从其执行起点开始执行该构件的代码,程序执行结束,将控制返回给程序调用构件。调用/返回体系结构风格主要包括主程序/子程序风格、面向对象风格、层次型风格以及客户端/服务器风格。
核心特点:系统由"主模块"和"被调用模块"组成,通过"函数调用、接口调用"实现交互,调用方需等待被调用方返回结果后再继续执行。
(一)主程序/子程序风格
主程序/子程序风格一般采用单线程控制,把问题划分为若干处理步骤,构件即为主程序和子程序。
子程序通常可合成为模块。过程调用作为交互机制,即充当连接件。调用关系具有层次性,其语义逻辑表现为子程序的正确性取决于它调用的子程序的正确性。
1. 案例
简单计算软件。主程序接收用户输入的"数字+运算类型",调用"加法子程序""乘法子程序",子程序执行后返回结果,主程序展示最终答案。
补充说明:构件是"主程序"和"子程序",连接件是"函数调用";约束是"主程序主导流程,子程序仅响应调用,无独立执行逻辑",适合简单、流程固定的系统。
假设有一个简单的计算器程序,它可以执行加法、减法、乘法和除法。这个程序可以采用主程序/子程序风格来设计:
python
def add(a, b):
return a + b
def subtract(a, b):
return a - b
def multiply(a, b):
return a * b
def divide(a, b):
if b == 0:
raise ValueError("Cannot divide by zero")
return a / b
def main():
while True:
print("Options:")
print("Enter 'add' to add two numbers")
print("Enter 'subtract' to subtract two numbers")
print("Enter 'multiply' to multiply two numbers")
print("Enter 'divide' to divide two numbers")
print("Enter 'quit' to end the program")
user_input = input(": ")
if user_input == "quit":
break
elif user_input in ('add', 'subtract', 'multiply', 'divide'):
num1 = float(input("Enter first number: "))
num2 = float(input("Enter second number: "))
if user_input == "add":
result = add(num1, num2)
elif user_input == "subtract":
result = subtract(num1, num2)
elif user_input == "multiply":
result = multiply(num1, num2)
elif user_input == "divide":
try:
result = divide(num1, num2)
except ValueError as e:
print(e)
continue
print("Result:", result)
else:
print("Unknown command")
if __name__ == "__main__":
main()在这个例子中,main 函数是主程序,它负责用户交互和程序的总体控制。add、subtract、multiply 和 divide 是子程序,它们分别实现了具体的数学运算。这种结构使得程序易于理解、维护和扩展。
2.特点
主程序/子程序风格的主要特点:
- 清晰的入口点:主程序作为整个应用的起点,负责初始化环境、配置资源、启动程序的主要逻辑等。主程序通常包含对各个子程序的调用,以完成具体的功能。
- 模块化:子程序是独立的单元,每个子程序负责完成特定的任务。每个子程序具有明确的输入和输出,这有助于降低各部分之间的耦合度,提高代码的可重用性。
- 层次结构:程序的逻辑按照功能进行分层,每一层可以调用更低层的子程序来完成更具体的任务。这种层次结构有助于管理和理解复杂的系统。
- 局部化错误处理:错误处理通常在子程序内部进行,这样可以将错误的影响限制在局部范围内,避免影响到其他部分的执行。子程序可以捕获并处理异常,或者将异常向上层传递。
- 参数传递:子程序之间通过参数传递数据,这包括输入参数和输出参数。参数传递机制确保了数据的一致性和安全性。
- 状态管理:子程序可以访问全局变量或共享数据结构,但通常建议尽量减少全局状态的使用,以避免副作用和难以追踪的错误。使用局部变量和参数传递来管理状态,可以提高程序的可预测性和可靠性。
- 可测试性:每个子程序都可以单独测试,这使得单元测试变得更加容易。通过隔离子程序,可以更容易地验证每个组件的功能是否正确。
- 可扩展性:新的功能可以通过添加新的子程序来实现,而不需要修改现有的代码。这种设计有利于系统的长期维护和发展。
- 可读性:由于每个子程序都专注于解决一个小问题,因此代码更加简洁明了。高级别的抽象有助于读者快速理解程序的整体结构和工作原理。
3.典型程序
以下是一些典型的主程序/子程序风格的程序示例。主程序/子程序风格是一种传统的调用/返回风格,其中主程序作为入口点,调用多个子程序(如函数或过程)来完成任务。这种风格常见于过程式编程语言(如C、Pascal)编写的应用程序。
| 程序名称 | 描述 |
|---|---|
| 简单计算器 | 主程序接收用户输入(如数字和运算符),调用子程序执行加、减、乘、除等算术运算,并输出结果。 |
| 文件复制工具 | 主程序调用子程序读取源文件内容,然后调用另一个子程序将内容写入目标文件,实现文件复制功能。 |
| 学生成绩管理系统 | 主程序调用子程序添加学生记录、计算平均成绩、生成成绩报告等,控制流从主程序开始并返回。 |
| 银行账户管理程序 | 主程序调用子程序处理存款、取款、查询余额等操作,每个操作由独立的子程序实现。 |
| 文本分析工具 | 主程序调用子程序统计文本中的字符数、单词数和行数,每个统计任务由特定子程序完成。 |
这些示例展示了主程序/子程序风格的基本特点:模块化、可重用性和清晰的控制流。
(二)面向对象风格
抽象数据类型概念对软件系统有着重要作用,目前软件界已普遍转向使用面向对象系统。
这种风格建立在数据抽象和面向对象的基础上,数据的表示方法和它们的相应操作封装在一个抽象数据类型或对象中。这种风格的构件是对象,或者说是抽象数据类型的实例(见图)。

1.案例
电商系统的 "商品管理模块"。定义 "商品类"(含属性:名称、价格;方法:查询、更新)、"订单类"(含属性:订单号、商品列表;方法:创建、支付),类通过 "对象实例调用方法" 交互。
补充说明:构件是 "类 / 对象",连接件是 "方法调用";约束是 "封装属性和方法,通过接口交互,低耦合、高内聚",是目前最常用的风格之一。
以下是一个简单的 Java 示例,展示了面向对象风格的特点:
java
// 定义一个抽象类 Animal
abstract class Animal {
private String name;
public Animal(String name) {
this.name = name;
}
public String getName() {
return name;
}
// 抽象方法,由子类实现
public abstract void makeSound();
}
// 定义一个接口 Flyable
interface Flyable {
void fly();
}
// 定义一个子类 Dog,继承自 Animal
class Dog extends Animal {
public Dog(String name) {
super(name);
}
@Override
public void makeSound() {
System.out.println(getName() + " says Woof!");
}
}
// 定义一个子类 Bird,继承自 Animal 并实现 Flyable 接口
class Bird extends Animal implements Flyable {
public Bird(String name) {
super(name);
}
@Override
public void makeSound() {
System.out.println(getName() + " says Chirp!");
}
@Override
public void fly() {
System.out.println(getName() + " is flying.");
}
}面向对象风格(Object-Oriented Style)是一种广泛使用的软件架构模式,它强调将数据和行为封装在一起,形成独立的对象。这种风格的核心概念包括类、对象、继承、多态和封装。
2.特点
以下是面向对象风格程序的主要特点:
(1) 封装(Encapsulation)
定义:封装是指将数据(属性)和操作数据的方法(行为)绑定在一起,形成一个独立的单元,即对象。
优点:
隐藏内部实现:外部无法直接访问对象的内部数据,只能通过公共方法(接口)进行访问,提高了数据的安全性和完整性。
模块化:每个对象都是一个独立的模块,可以独立开发、测试和维护。
(2)继承(Inheritance)
定义:继承允许一个类(子类)继承另一个类(父类)的属性和方法,从而实现代码的复用。
优点:
代码复用:子类可以直接使用父类的属性和方法,减少了重复代码。
层次结构:通过继承可以构建类的层次结构,使代码更加有组织和条理。
(3)多态(Polymorphism)
定义:多态是指同一个方法名在不同的上下文中有不同的实现。
优点:
灵活性:子类可以覆盖或扩展父类的方法,提供不同的实现。
可扩展性:新增加的子类可以无缝地融入现有的系统,而不需要修改现有代码。
(4)抽象(Abstraction)
定义:抽象是指将复杂的现实世界问题简化为计算机可以处理的模型。
优点:
简化复杂性:通过抽象,可以忽略不必要的细节,只关注核心问题。
提高可读性:抽象类和接口可以帮助开发者更好地理解系统的结构和功能。
(5)消息传递(Message Passing)
定义:对象之间通过发送消息来通信,调用其他对象的方法。
优点:
解耦:对象之间通过消息传递进行交互,降低了对象之间的耦合度。
动态性:消息传递机制使得对象可以在运行时动态地决定如何响应消息。
(6)类和对象
类:类是对象的模板,定义了对象的属性和方法。
对象:对象是类的实例,具有具体的属性值和行为。
(7)组合(Composition)
定义:组合是指一个类包含另一个类的对象作为其成员。
优点:
灵活性:组合关系比继承关系更灵活,可以根据需要动态地创建和销毁对象。
代码复用:通过组合,可以复用现有的类,而不必依赖于继承。
(8) 接口(Interface)
定义:接口定义了一组方法的签名,但不提供具体的实现。
优点:
规范:接口定义了类的行为规范,确保实现类遵循特定的契约。
多实现:一个类可以实现多个接口,从而具备多种行为。
3.典型程序
以下是典型的面向对象风格程序示例。面向对象编程(OOP)以对象为核心,通过类、对象、继承、封装和多态等概念组织代码。
| 程序名称 | 描述 | 主要类和对象 |
|---|---|---|
| 银行账户管理系统 | 模拟银行账户操作,支持开户、存款、取款、转账等功能 | BankAccount(账户)、Customer(客户)、Bank(银行)、Transaction(交易) |
| 电子商务系统 | 在线购物平台,处理商品浏览、购物车、订单、支付等 | Product(商品)、ShoppingCart(购物车)、Order(订单)、Customer(客户)、Payment(支付) |
| 学校管理系统 | 管理学生、教师、课程、成绩等教育相关数据 | Student(学生)、Teacher(教师)、Course(课程)、Grade(成绩)、Department(系部) |
| 图形用户界面应用 | 桌面应用如计算器、文本编辑器等,使用GUI组件 | Window(窗口)、Button(按钮)、TextField(文本框)、Menu(菜单) |
| 游戏角色系统 | 角色扮演游戏中的角色管理,包括属性、技能、装备等 | Character(角色)、Weapon(武器)、Armor(护甲)、Skill(技能)、Inventory(背包) |
| 车辆租赁系统 | 汽车租赁管理,处理车辆信息、客户租赁、费用计算等 | Vehicle(车辆)、Car(汽车)、Customer(客户)、Rental(租赁)、Invoice(发票) |
| 社交媒体平台 | 社交网络应用,管理用户、帖子、评论、好友关系等 | User(用户)、Post(帖子)、Comment(评论)、FriendRequest(好友请求) |
| 图书馆管理系统 | 图书借阅管理,处理图书信息、借阅记录、读者信息等 | Book(图书)、Reader(读者)、BorrowRecord(借阅记录)、Library(图书馆) |
| 员工薪资系统 | 企业管理员工信息、计算薪资、管理部门等 | Employee(员工)、Manager(经理)、Department(部门)、Payroll(薪资) |
| 在线订餐系统 | 外卖订餐平台,处理餐厅、菜单、订单、配送等 | Restaurant(餐厅)、Menu(菜单)、Order(订单)、DeliveryPerson(配送员) |
这些示例展示了面向对象编程如何通过模拟现实世界实体来构建复杂系统,提高代码的可维护性、可扩展性和重用性。
(三)层次型风格
层次系统(见图)组成一个层次结构,每一层为上层提供服务,并作为下层的客户。

在一些层次系统中,除了一些精心挑选的输出函数外,内部的层接口只对相邻的层可见。这样的系统中构件在层上实现了虚拟机。
连接件由通过决定层间如何交互的协议来定义,拓扑约束包括对相邻层间交互的约束。由于每一层最多只影响两层,同时只要给相邻层提供相同的接口,允许每层用不同的方法实现,这同样为软件重用提供了强大的支持。
1.案例
经典三层架构(表现层→业务层→数据层)。表现层(前端页面)接收用户请求,调用业务层(订单逻辑、权限校验),业务层再调用数据层(数据库增删改查),每层仅与相邻层交互。
补充说明:构件是 "表现层、业务层、数据层",连接件是 "接口调用";约束是 "禁止跨层调用,每层职责单一",适合复杂业务系统,便于维护和扩展。
以下是一个简单的三层架构示例,展示了一个典型的 Web 应用程序的结构:
java
// 表示层: UserController 负责处理用户的请求,调用 UserService 获取用户列表,并将结果传递给视图。
@Controller
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/users")
public String listUsers(Model model) {
List<User> users = userService.getAllUsers();
model.addAttribute("users", users);
return "userList";
}
}
// 业务逻辑层:UserService 负责核心业务逻辑,例如获取所有用户。它依赖于 UserRepository 来访问数据库。
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> getAllUsers() {
return userRepository.findAll();
}
}
// 数据访问层:UserRepository 是一个接口,继承自 JpaRepository,提供了基本的 CRUD 操作。实际的数据库操作由 Spring Data JPA 自动实现。
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}层次型风格(Layered Architecture)是一种常见的软件架构模式,它将应用程序划分为多个层次,每个层次负责特定的功能,并且层次之间有明确的依赖关系。这种架构模式的优点在于能够清晰地分离关注点,提高系统的可维护性和可扩展性。
2.特点
以下是层次型风格的主要特点:
(1)分层结构
定义:应用程序被划分为多个层次,每个层次负责特定的功能。
典型层次:
表示层(Presentation Layer):负责用户界面和用户交互。
业务逻辑层(Business Logic Layer):负责核心业务逻辑和规则。
数据访问层(Data Access Layer):负责数据的存储和检索。
(2)单向依赖
定义:高层依赖于低层,但低层不依赖于高层。
优点:
解耦:层次之间的单向依赖减少了模块间的耦合,使得每个层次可以独立开发、测试和维护。
可替换性:某个层次的实现可以被替换,而不会影响其他层次。
(3)职责分离
定义:每个层次有明确的职责,专注于特定的功能。
优点:
可维护性:每个层次的代码更加简洁和专注,便于理解和维护。
可扩展性:新增功能时,可以集中在特定的层次中进行开发,而不会影响其他层次。
(4)数据流动
定义:数据从上层向下层传递,处理结果从下层向上层返回。
优点:
清晰的数据流:数据流动路径明确,便于跟踪和调试。
一致性:数据在各层之间的一致性更容易保证。
(5)模块化
定义:每个层次可以被视为一个独立的模块,具有明确的接口。
优点:
重用性:模块化的层次可以被其他项目重用。
可测试性:每个层次可以独立进行单元测试,提高测试的覆盖率和效率。
(6)可配置性
定义:层次之间的依赖关系可以通过配置文件或依赖注入框架进行管理。
优点:
灵活性:可以通过配置文件或依赖注入框架轻松更改层次之间的依赖关系。
可插拔性:不同的实现可以插拔,便于系统升级和维护。
(7)性能考虑
定义:层次型架构可能会引入额外的开销,因为数据需要在多个层次之间传递。
优化:
缓存:在适当的位置使用缓存可以减少数据的重复处理。
异步处理:对于耗时的操作,可以使用异步处理机制。
3.典型程序
以下是典型的层次结构风格的程序示例。层次结构风格是一种调用/返回风格,系统被组织成一系列层次,每一层为其上层提供服务,并使用其下层提供的服务。
| 程序名称 | 描述 | 层次结构 |
|---|---|---|
| 操作系统内核 | 如Linux/Windows内核,提供硬件抽象和系统服务 | 硬件层 → 内核层 → 系统调用接口 → 用户空间应用 |
| 网络协议栈 | TCP/IP协议实现,处理网络通信 | 物理层 → 数据链路层 → 网络层 → 传输层 → 应用层 |
| 数据库管理系统 | 如MySQL/Oracle,管理数据存储和检索 | 存储引擎层 → 查询处理层 → 事务管理层 → SQL接口层 → 客户端接口 |
| Web应用框架 | 如Django/Spring MVC,构建Web应用 | 表示层(UI) → 业务逻辑层 → 数据访问层 → 数据库层 |
| 编译器设计 | 如GCC/LLVM,将源代码转换为目标代码 | 词法分析 → 语法分析 → 语义分析 → 中间代码生成 → 代码优化 → 目标代码生成 |
| 图形用户界面框架 | 如Qt/Java Swing,创建桌面应用 | 应用程序层 → 窗口管理层 → 图形原语层 → 设备驱动层 → 显示硬件 |
| 企业应用架构 | 大型业务系统,如ERP/CRM | 表示层 → 应用层 → 领域层 → 基础设施层 |
| 虚拟化系统 | 如VMware/Docker,提供资源隔离 | 应用程序 → 客户OS → 虚拟化层 → 主机OS → 硬件 |
| 嵌入式系统 | 如汽车控制系统、物联网设备 | 应用层 → 中间件层 → 操作系统层 → 硬件抽象层 → 硬件 |
| 移动应用架构 | iOS/Android应用开发 | UI层 → 业务逻辑层 → 数据层 → 网络层 → 本地存储 |
这种架构风格特别适合需要清晰分离关注点、易于测试和维护的大型复杂系统。
(四)客户端/服务器风格
C/S (客户端/服务器)软件体系结构是基于资源不对等,且为实现共享而提出的,在20世纪90年代逐渐成熟起来。
两层 C/S 体系结构有3个主要组成部分:数据库服务器、客户应用程序和网络。服务器(后台)负责数据管理,客户机(前台)完成与用户的交互任务,称为"胖客户机,瘦服务器"。

与两层C/S 结构相比,三层C/S结构(见图)增加了一个应用服务器。整个应用逻辑驻留在应用服务器上,只有表示层存在于客户机上,故称为"瘦客户机"。应用功能分为表示层、功能层和数据层三层。表示层是应用的用户接口部分,通常使用图形用户界面;功能层是应用的主体,实现具体的业务处理逻辑;数据层是数据库管理系统。以上三层逻辑上独立。

1.案例
微信 PC 端(客户端)发送消息。客户端将消息通过 TCP 协议发送给微信后台服务器,服务器接收后转发给接收方,再返回 "发送成功" 响应,客户端才会显示 "已发送"------ 符合调用 / 返回的闭环逻辑。
补充说明:构件是客户端(如桌面 APP、浏览器端)、服务器(如后端服务、数据库服务器),
连接件是网络协议(如 TCP/IP、HTTP、JDBC),本质是 "跨进程的调用通道"(替代单机场景的函数调用)。
架构变体:
| 变体类型 | 描述 | 典型应用 |
|---|---|---|
| 两层架构 | 客户端直接连接数据库服务器 | 传统的桌面数据库应用 |
| 三层架构 | 客户端 → 应用服务器 → 数据库服务器 | 现代企业应用系统 |
| 多层架构 | 添加更多中间层,如Web服务器、缓存层等 | 大型电商网站、社交平台 |
| 胖客户端 | 客户端承担较多业务逻辑处理 | 复杂桌面应用、图形设计软件 |
| 瘦客户端 | 客户端主要负责界面展示 | 基于Web的应用、终端服务 |
2.特点概述
客户端/服务器(Client/Server,C/S)架构是一种分布式计算模型,将应用程序分为两个独立的部分:
| 特点 | 描述 |
|---|---|
| 职责分离 | 客户端负责用户界面和表示逻辑,服务器负责数据处理和业务逻辑 |
| 集中化管理 | 数据和服务集中在服务器端,便于管理和维护 |
| 网络通信 | 客户端和服务器通过网络协议进行通信 |
| 可扩展性 | 服务器可以服务多个客户端,支持系统扩展 |
| 资源共享 | 多个客户端可以共享服务器提供的资源和服务 |
| 位置透明性 | 客户端无需知道服务器的物理位置 |
| 安全性 | 可以在服务器端实现统一的安全控制和数据保护 |
3.典型的客户端/服务器风格程序
| 程序名称 | 描述 | 客户端角色 | 服务器角色 |
|---|---|---|---|
| 数据库管理系统 | 如MySQL客户端/服务器 | 发送SQL查询,接收和显示结果 | 处理查询,管理数据存储,返回结果集 |
| 电子邮件系统 | 如Outlook/Exchange | 撰写、发送、接收邮件,管理本地邮箱 | 存储邮件,路由转发,用户认证 |
| 文件共享系统 | 如FTP客户端/服务器 | 浏览远程目录,上传下载文件 | 管理文件系统,控制访问权限 |
| Web浏览器/服务器 | 浏览器/Web服务器 | 渲染页面,处理用户交互,发送HTTP请求 | 处理请求,生成动态内容,返回HTML页面 |
| 远程桌面系统 | 如Windows远程桌面 | 显示远程界面,发送键盘鼠标输入 | 运行实际应用程序,发送屏幕更新 |
| 即时通讯系统 | 如QQ/微信客户端 | 显示联系人列表,收发消息,文件传输 | 用户状态管理,消息路由,存储转发 |
| 网络游戏 | 多人在线游戏 | 渲染游戏画面,处理本地输入 | 游戏逻辑处理,玩家状态同步,反作弊 |
| 银行ATM系统 | 自动取款机网络 | 接受用户操作,显示界面,吐钞 | 账户验证,交易处理,余额更新 |
| 视频流媒体 | 如Netflix客户端 | 解码视频,提供播放控制界面 | 存储视频文件,处理流媒体传输 |
| 云存储服务 | 如Dropbox客户端 | 同步本地文件夹,文件预览 | 存储用户文件,版本管理,跨设备同步 |
四、独立构件风格
独立构件风格主要强调系统中的每个构件都是相对独立的个体,它们之间不直接通信,以降低耦合度,提升灵活性。独立构件风格主要包括进程通信和事件系统风格。
(一)进程通信风格
在进程通信结构体系结构风格中,构件是独立的过程,连接件是消息传递。这种风格的特点是构件通常是命名过程,消息传递的方式可以是点到点、异步或同步方式及远程过程调用等。
1.案例
分布式系统的 "订单系统" 与 "库存系统"。订单系统完成支付后,通过 "TCP/IP 协议" 向库存系统发送 "扣减库存" 请求,两个系统是独立进程,通过网络通信交互。
补充说明:构件是 "独立进程 / 系统",连接件是 "网络协议(TCP/IP、UDP)";约束是 "构件独立部署,通信需遵循统一协议",适合分布式场景。
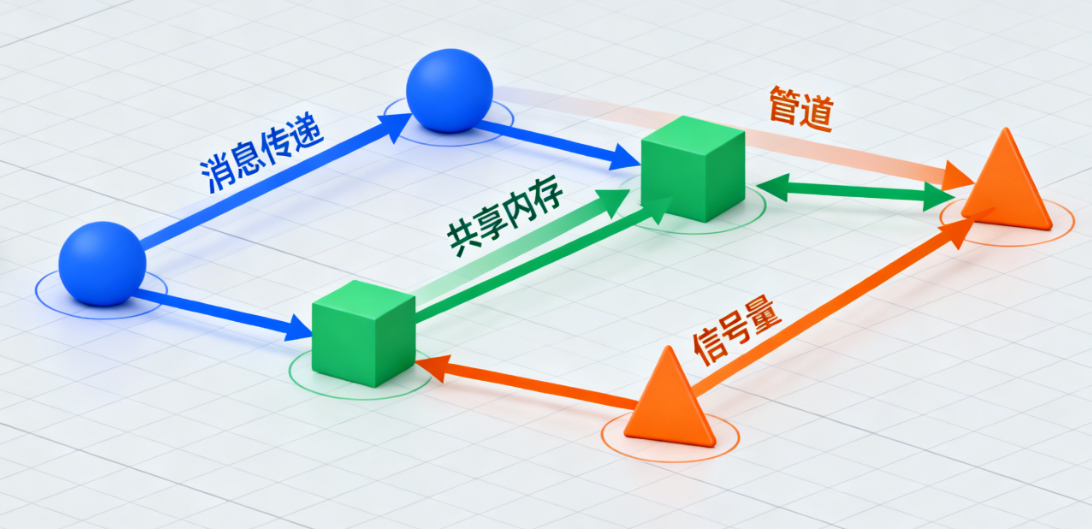
通信模式分类:
| 通信模式 | 描述 | 典型技术 |
|---|---|---|
| 一对一同步 | 客户端等待服务器响应 | HTTP请求-响应,RPC调用 |
| 一对一异步 | 客户端不阻塞等待响应 | 消息队列,异步RPC |
| 一对多发布订阅 | 消息生产者向多个消费者广播 | Redis Pub/Sub,Kafka主题 |
| 多对多 | 多个进程相互通信 | P2P网络,gossip协议 |
| 流水线 | 数据通过一系列处理进程流动 | Unix管道,流处理拓扑 |
通信机制:
| 机制类型 | 描述 | 适用场景 |
|---|---|---|
| 管道(Pipes) | 单向字节流,通常用于父子进程 | 命令行工具链 |
| 消息队列 | 异步、持久化的消息传递 | 微服务通信,任务队列 |
| 套接字(Sockets) | 网络通信端点 | 跨网络进程通信 |
| RPC(远程过程调用) | 像调用本地函数一样调用远程服务 | 分布式系统服务调用 |
| 共享文件 | 通过文件系统进行数据交换 | 批处理系统,日志处理 |
优势:
- 更好的故障隔离和系统稳定性
- 便于分布式部署和扩展
- 技术栈灵活性(不同进程可用不同语言开发)
- 支持增量更新和部署
挑战:
- 通信开销和延迟
- 分布式系统复杂性(网络分区、一致性等)
- 调试和监控难度增加
- 需要处理进程间协调和同步
2.特点
进程通信(Process Communication)架构风格属于独立构件风格,其核心特点是系统中的各个构件是独立的进程,它们通过消息传递机制进行通信和协作。
| 特点 | 描述 |
|---|---|
| 进程独立性 | 每个构件作为独立的进程运行,有自己的地址空间和执行环境 |
| 消息传递 | 进程间通过消息进行通信,而非共享内存 |
| 松耦合 | 进程之间相互独立,通过定义良好的接口进行交互 |
| 并发性 | 多个进程可以并行执行,提高系统吞吐量 |
| 位置透明 | 通信进程可以在同一主机或分布式环境中的不同节点 |
| 错误隔离 | 单个进程的故障不会直接导致整个系统崩溃 |
| 可扩展性 | 可以通过增加更多进程实例来扩展系统能力 |
3.典型的进程通信风格程序
| 程序名称 | 描述 | 通信机制 | 进程角色 |
|---|---|---|---|
| 微服务架构系统 | 如Netflix、Uber的后端系统 | HTTP/REST, gRPC, 消息队列 | 每个微服务作为独立进程,通过API通信 |
| 消息队列系统 | 如RabbitMQ、Kafka应用 | AMQP, MQTT, 自定义协议 | 生产者进程发送消息,消费者进程接收处理 |
| 分布式计算系统 | 如Hadoop、Spark集群 | RPC, 自定义网络协议 | Master进程协调,Worker进程执行计算任务 |
| 数据库复制系统 | 如MySQL主从复制 | 二进制日志传输,复制协议 | 主数据库进程发送变更,从数据库进程应用变更 |
| 容器编排平台 | 如Kubernetes集群 | etcd, API Server, 网络插件 | 控制平面进程与管理平面进程协同工作 |
| 实时数据处理 | 如Flink、Storm流处理 | 网络套接字,消息总线 | 数据源进程、处理进程、输出进程形成流水线 |
| 邮件传输系统 | 如Sendmail、Postfix | SMTP协议 | MTA进程间通过SMTP中继邮件 |
| 分布式缓存 | 如Redis集群、Memcached | gossip协议, 集群总线 | 节点进程间同步数据和管理集群状态 |
| 文件同步工具 | 如rsync、BitTorrent | 自定义同步协议,P2P协议 | 客户端进程与服务器进程或对等节点进程通信 |
| 服务网格 | 如Istio、Linkerd | Envoy代理间通信 | Sidecar代理进程拦截和处理服务间通信 |
这种架构风格特别适合需要高可用性、可扩展性和容错性的分布式系统,是现代云计算和微服务架构的基础。
(二)事件系统风格
事件系统风格基于事件的隐式调用风格的思想是构件不直接调用一个过程,而是触发或广播一个或多个事件。系统中的其他构件中的过程在一个或多个事件中注册,当一个事件被触发,系统自动调用在这个事件中注册的所有过程,这样,一个事件的触发就导致了另一模块中的过程的调用。
从架构上说,这种风格的构件是一些模块,这些模块既可以是一些过程,又可以是一些事件的集合。过程可以用通用的方式调用,也可以在系统事件中注册一些过程,当发生这些事件时,过程被调用。
基于事件的隐式调用风格的主要特点是事件的触发者并不知道哪些构件会被这些事件影响。
这使得不能假定构件的处理顺序,甚至不知道哪些过程会被调用,因此,许多隐式调用的系统也包含显式调用作为构件交互的补充形式。
支持基于事件的隐式调用的应用系统很多。例如,在编程环境中用于集成各种工具,在数据库管理系统中确保数据的一致性约束,在用户界面系统中管理数据,以及在编辑器中支持语法检查。例如在某系统中,编辑器和变量监视器可以登记相应Debugger的断点事件。
当Debugger 在断点处停下时,它声明该事件,由系统自动调用处理程序,如编辑器可以卷屏(返回)到断点,变量监视器刷新变量数值。而Debugger本身只声明事件,并不关心哪些过程会启动,也不关心这些过程做什么处理。

1.案例
电商 "下单支付成功" 触发多模块联动。支付系统发送 "支付成功事件",订单系统监听后更新订单状态、物流系统监听后创建物流单、积分系统监听后增加用户积分。
补充说明:构件是 "支付系统、订单系统、物流系统",连接件是 "事件总线";约束是 "构件通过订阅 / 发布事件交互,无需知晓对方存在",适合需求多变、模块较多的系统。
事件处理模式:
| 模式类型 | 描述 | 适用场景 |
|---|---|---|
| 简单事件处理 | 直接的事件-响应映射 | GUI交互,简单业务逻辑 |
| 复杂事件处理(CEP) | 检测事件流中的模式 | 金融交易监控,欺诈检测 |
| 事件溯源 | 使用事件序列作为唯一事实来源 | 审计要求高的系统,领域驱动设计 |
| 事件编排 | 通过事件协调多个服务 | 微服务架构中的业务流程 |
| 事件通知 | 简单的事件广播 | 系统状态变更通知 |
事件系统组件:
| 组件 | 功能 | 示例 |
|---|---|---|
| 事件发布者 | 产生和发布事件 | 用户界面控件,领域实体 |
| 事件订阅者 | 注册并处理特定类型事件 | 业务逻辑处理器,通知服务 |
| 事件总线/中介 | 路由和分发事件 | MessageBroker,EventEmitter |
| 事件存储 | 持久化事件序列 | EventStore,数据库事件表 |
| 事件处理器 | 执行具体的事件处理逻辑 | 业务服务,工作流步骤 |
通信机制:
| 机制 | 描述 | 技术实现 |
|---|---|---|
| 内存事件总线 | 进程内事件分发 | Node.js EventEmitter,C# event |
| 消息队列 | 跨进程异步事件传递 | RabbitMQ,Apache Kafka |
| WebHook | HTTP回调的事件通知 | REST API 回调 |
| WebSocket | 全双工实时事件推送 | Socket.IO,SignalR |
| 服务网格 | 服务间事件通信 | Istio,Linkerd |
优势:
- 极高的组件解耦和独立性
- 更好的可扩展性和可维护性
- 支持实时响应和复杂业务流程
- 便于实现横切关注点(日志、监控等)
挑战:
- 系统流程难以跟踪和调试
- 事件顺序和一致性管理复杂
- 可能产生事件循环或级联故障
- 需要处理事件丢失和重复投递
2.特点概述
事件系统(Event System)架构风格属于独立构件风格,其核心特点是系统中的组件通过产生、发布、订阅和处理事件来进行异步通信,实现松耦合的交互。
| 特点 | 描述 |
|---|---|
| 事件驱动 | 系统行为由事件触发,而不是传统的请求-响应模式 |
| 发布-订阅模式 | 组件发布事件,零个或多个订阅者异步接收和处理事件 |
| 解耦性 | 事件生产者不知道事件消费者的存在,实现完全解耦 |
| 异步通信 | 事件处理通常是异步的,提高系统响应性和吞吐量 |
| 动态响应 | 可以动态添加或移除事件处理程序,无需修改事件源 |
| 事件溯源 | 通过记录事件序列可以重建系统状态,支持审计和回放 |
| 可扩展性 | 新功能可以通过订阅现有事件轻松添加 |
3.典型的事件系统风格程序
| 程序名称 | 描述 | 事件类型 | 架构特点 |
|---|---|---|---|
| 图形用户界面框架 | 如Windows Forms、Web前端 | 点击事件、键盘事件、鼠标移动 | 事件监听器注册,事件循环分发 |
| 消息中间件系统 | 如RabbitMQ、Apache Kafka | 消息到达事件、消费确认事件 | 发布-订阅模式,主题/队列管理 |
| 微服务事件总线 | 如Spring Cloud Stream、Axon | 领域事件、集成事件 | 服务间异步通信,事件溯源 |
| 实时数据处理平台 | 如Apache Flink、Apache Storm | 数据流事件、窗口事件 | 流处理拓扑,复杂事件处理 |
| 游戏引擎系统 | 如Unity、Unreal Engine | 碰撞事件、动画事件、输入事件 | 事件管理器,脚本回调系统 |
| 物联网平台 | 如AWS IoT、Azure IoT Hub | 设备遥测事件、状态变更事件 | 设备到云事件流,规则引擎 |
| 工作流引擎 | 如Camunda、Activiti | 任务完成事件、流程实例事件 | BPMN事件网关,流程监听器 |
| 电商订单系统 | 在线零售平台 | 订单创建、支付成功、库存更新 | 领域事件驱动,最终一致性 |
| 监控告警系统 | 如Prometheus、Zabbix | 指标阈值事件、服务下线事件 | 事件采集、过滤、分发管道 |
| 社交网络推送 | 如Facebook、Twitter | 新帖子事件、点赞事件、关注事件 | 实时推送,粉丝订阅模式 |
事件系统架构特别适合需要高响应性、松耦合和复杂业务逻辑的现代分布式系统,是微服务架构和实时应用的核心模式。
五、以数据为中心的风格
以数据为中心的体系结构风格主要包括仓库体系结构风格和黑板体系结构风格。
(一)仓库风格
仓 库 (Repository) 是存储和维护数据的中心场所。
在仓库风格(见图)中,有两种不同的构件:中央数据结构说明当前数据的状态以及一组对中央数据进行操作的独立构件,仓库与独立构件间的相互作用在系统中会有大的变化。
这种风格的连接件即为仓库与独立构件之间的交互。

1.案例
企业 CRM 系统。销售模块、客服模块、财务模块均通过 "集中式数据库" 共享客户数据(如客户信息、跟进记录),各模块仅对数据库进行增删改查,模块间不直接交互。
补充说明:构件是 "销售模块、客服模块",连接件是 "数据库";约束是 "数据统一存储,模块通过标准化 SQL 访问,保证数据一致性",适合数据密集型系统。
仓库风格变体:
| 变体类型 | 描述 | 典型应用 |
|---|---|---|
| 数据库系统 | 结构化数据存储,支持复杂查询 | 企业信息系统、Web应用后端 |
| 超文本系统 | 通过链接连接的信息节点网络 | 静态网站、帮助文档系统 |
| 黑板系统 | 多个知识源协作解决问题的共享工作区 | 语音识别、信号处理、专家系统 |
| 数据湖 | 存储原始各种格式数据的存储库 | 大数据分析、数据科学平台 |
| 知识图谱 | 实体和关系的语义网络 | 智能搜索、推荐系统 |
架构组件:
| 组件 | 功能 | 示例 |
|---|---|---|
| 中央数据仓库 | 存储和管理所有共享数据 | 数据库、文件系统、内存数据结构 |
| 数据生产者 | 向仓库添加或更新数据 | 用户输入模块、数据采集器、传感器 |
| 数据消费者 | 从仓库读取和使用数据 | 查询处理器、报表生成器、分析工具 |
| 仓库管理器 | 管理数据访问、一致性和完整性 | 数据库管理系统、版本控制核心 |
| 数据转换器 | 在数据存储和使用间进行格式转换 | ORM映射、数据序列化工具 |
数据访问模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| 查询-响应 | 客户端查询数据,仓库返回结果 | 数据库查询、信息检索 |
| 发布-订阅 | 组件订阅数据变化通知 | 实时数据监控、配置更新 |
| 事务处理 | 保证数据操作的原子性和一致性 | 金融交易、库存管理 |
| 批量处理 | 大量数据的批量读写操作 | 数据迁移、报表生成 |
| 流式访问 | 连续的数据流读写 | 日志处理、实时分析 |
优势:
- 数据集中管理,便于维护一致性
- 组件松耦合,易于独立开发和测试
- 支持数据持久化和历史追踪
- 便于实现数据共享和协作
挑战:
- 中央仓库可能成为性能和可扩展性瓶颈
- 单点故障风险
- 数据模型变更影响所有组件
- 需要处理并发访问和锁竞争
2.特点概述
仓库(Repository)架构风格以中央数据存储为核心,组件通过共享的数据仓库进行交互,而不是直接相互通信。
| 特点 | 描述 |
|---|---|
| 中心数据存储 | 系统围绕一个中央数据仓库构建,所有数据集中管理 |
| 数据共享 | 多个组件共享和访问同一数据存储 |
| 组件独立性 | 组件之间不直接通信,通过仓库进行数据交换 |
| 数据驱动 | 系统行为主要由数据状态变化驱动 |
| 持久化存储 | 数据通常被持久化保存,支持长期使用 |
| 统一接口 | 提供统一的数据访问和管理接口 |
| 数据一致性 | 中心存储有助于维护数据的一致性和完整性 |
3.典型的仓库风格程序
| 程序名称 | 描述 | 仓库类型 | 组件角色 |
|---|---|---|---|
| 数据库管理系统 | 如Oracle、MySQL等关系数据库 | 关系数据库 | 客户端应用通过SQL访问共享数据库 |
| 版本控制系统 | 如Git、SVN代码管理系统 | 代码仓库 | 开发者提交和获取代码,仓库管理版本历史 |
| 数字资产管理系统 | 企业内容管理、数字图书馆 | 数字资产库 | 用户上传、检索多媒体资源,系统管理元数据 |
| 编译器系统 | 如传统编译器的符号表管理 | 符号表仓库 | 词法分析、语法分析、语义分析共享符号表 |
| 集成开发环境 | 如Eclipse、Visual Studio IDE | 项目模型仓库 | 编辑器、调试器、构建工具共享项目信息 |
| 超文本系统 | 如早期静态网站、知识库 | 超文本链接库 | 页面通过链接相互关联,形成信息网络 |
| 黑板系统 | 人工智能问题求解系统 | 共享问题求解空间 | 知识源独立工作,通过黑板交换信息 |
| 配置管理系统 | 如Apache ZooKeeper、etcd | 配置信息仓库 | 分布式系统组件从中心配置库读取配置 |
| 数据仓库系统 | 商业智能和分析平台 | 企业数据仓库 | ETL工具、报表工具、分析工具共享数据 |
| 知识库系统 | 专家系统、语义网应用 | 知识图谱仓库 | 推理引擎、查询接口共享知识库 |
仓库架构风格特别适合数据密集型应用,其中数据的完整性、一致性和共享性比组件间的直接交互更为重要。这种风格在需要强数据管理和协作的系统中有广泛应用。
(二)超文本系统
1.案例
维基百科。所有词条以 "超文本" 形式存储在服务器(仓库),用户通过 "链接" 跳转访问不同词条,词条内容统一管理、共享访问。
补充说明:构件是 "词条页面",连接件是 "超链接";约束是 "内容以超文本格式存储,支持非线性访问",适合信息关联紧密、需灵活跳转的场景。
超文本系统组件:
| 组件 | 功能 | 示例 |
|---|---|---|
| 节点 | 信息的基本单元,包含内容 | 网页、文档、多媒体文件 |
| 链接 | 节点间的连接关系 | 超链接、锚点、引用 |
| 导航器 | 提供浏览和导航界面 | 浏览器、阅读器、查看器 |
| 存储系统 | 管理节点和链接的存储 | 文件系统、数据库、CDN |
| 索引引擎 | 支持内容检索和发现 | 搜索引擎、标签系统 |
| 创作工具 | 创建和编辑超文本内容 | 网页编辑器、Wiki系统 |
链接类型:
| 链接类型 | 描述 | 示例 |
|---|---|---|
| 结构链接 | 反映内容组织结构 | 目录链接、前后页导航 |
| 引用链接 | 指向相关或补充信息 | 脚注、参考文献 |
| 关联链接 | 基于语义关系的连接 | 相关概念、相似内容 |
| 功能链接 | 触发特定操作或功能 | 下载链接、表单提交 |
| 外部链接 | 指向不同系统的资源 | 跨网站链接、API调用 |
导航模式:
| 导航模式 | 描述 | 适用场景 |
|---|---|---|
| 层次导航 | 树状结构,从上到下浏览 | 网站菜单、文件目录 |
| 网络导航 | 任意节点间跳转 | 知识库、参考文档 |
| 序列导航 | 线性顺序浏览 | 教程、故事叙述 |
| 搜索导航 | 通过关键词直接定位 | 大型网站、数据库 |
| 标签导航 | 基于分类标签过滤 | 博客、产品目录 |
优势:
- 支持符合人类思维的联想式信息获取
- 提供个性化的学习和探索路径
- 便于建立知识间的关联和上下文
- 支持大规模信息的组织和访问
挑战:
- 用户容易在复杂链接网络中迷失方向
- 维护链接完整性困难(如链接失效)
- 信息结构可能变得复杂和混乱
- 需要平衡自由探索和引导性导航
2.特点概述
超文本系统(Hypertext Systems)属于仓库风格,其核心特点是通过非线性、互链接的信息节点组织内容,用户可以通过链接在不同信息单元之间自由导航。
| 特点 | 描述 |
|---|---|
| 非线性结构 | 信息通过链接形成网络状结构,而非传统的线性顺序 |
| 节点与链接 | 内容被分解为独立节点,通过超链接相互关联 |
| 用户主导导航 | 用户通过点击链接自主选择浏览路径 |
| 多媒体集成 | 支持文本、图像、音频、视频等多种媒体类型 |
| 跨文档引用 | 允许在不同文档间建立关联和引用 |
| 分层组织 | 支持信息的分层和分类浏览 |
| 交互性 | 用户可以与内容进行交互,主动探索信息空间 |
3.典型的超文本系统程序
| 程序名称 | 描述 | 超文本特性 | 技术实现 |
|---|---|---|---|
| 万维网(WWW) | 全球信息网,最大的超文本系统 | 网页间超链接、URL寻址、多媒体内容 | HTTP、HTML、浏览器 |
| 维基百科 | 在线协作百科全书 | 词条间交叉引用、分类导航、内部链接 | Wiki引擎、数据库存储 |
| 帮助文档系统 | 如Microsoft Help、Apple Help | 主题跳转、索引搜索、相关链接 | CHM、Help Viewer |
| 数字图书馆 | 如Project Gutenberg、学术数据库 | 文献引用、相关阅读、主题关联 | 数字资源管理、元数据 |
| 知识管理系统 | 企业知识库、Confluence | 文档链接、知识图谱、标签关联 | 企业Wiki、搜索索引 |
| 在线教育平台 | 如可汗学院、Coursera | 课程模块跳转、参考资料链接 | LMS、内容管理系统 |
| 交互式小说 | 非线性叙事作品 | 分支剧情、多结局、读者选择 | 超文本创作工具 |
| 产品文档 | 如API文档、技术手册 | 代码示例链接、相关概念跳转 | 静态站点生成器 |
| 数字博物馆 | 在线展览和文化资源 | 展品关联、时间线导航、多媒体解说 | 数字资产管理系统 |
| 个人知识库 | 如Obsidian、Roam Research | 双向链接、知识图谱可视化 | 图数据库、Markdown |
| 电子商务网站 | 如Amazon产品页面 | 相关产品推荐、分类浏览、用户评论 | 推荐算法、分类系统 |
| 社交媒体平台 | 如微博、Twitter | 话题标签、用户提及、内容分享 | 社交图谱、消息流 |
超文本系统架构特别适合需要建立丰富关联、支持探索式学习、内容间存在复杂关系的应用场景,是现代信息管理和知识传播的基础架构。
(三)黑板风格
黑板体系结构风格适用于解决复杂的非结构化的问题,能在求解过程中综合运用多种不同知识源,使得问题的表达、组织和求解变得比较容易。黑板系统是一种问题求解模型,是组织推理步骤、控制状态数据和问题求解之领域知识的概念框架。它将问题的解空间组织成一个或多个应用相关的分级结构。分级结构的每一层信息由一个唯一的词汇来描述,它代表了问题的部分解。
领域相关的知识被分成独立的知识模块,它将某一层次中的信息转换成同层或相邻层的信息。各种应用通过不同知识表达方法、推理框架和控制机制的组合来实现。
影响黑板系统设计的最大因素是应用问题本身的特性,但是支撑应用程序的黑板体系结构有许多相似的特征和构件。

对于特定应用问题,黑板系统可通过选取各种黑板、知识源和控制模块的构件来设计,也可以利用预先定制的黑板体系结构的编程环境。黑板系统的传统应用是信号处理领域,如语音识别和模式识别。另一应用是松耦合代理数据共享存取。
1.案例
语音识别系统。系统包含 "语音采集模块、特征提取模块、语法分析模块、结果输出模块",所有模块共享 "黑板"(数据仓库),采集模块将语音数据写入黑板,其他模块依次读取并处理,最终输出识别结果。
补充说明:构件是 "各处理模块",连接件是 "黑板";约束是 "模块按预设规则读取 / 写入黑板数据,无直接依赖",适合复杂问题的分步求解(如人工智能、数据分析)。
黑板系统组件:
| 组件 | 功能 | 示例 |
|---|---|---|
| 黑板 | 共享的全局数据存储,包含问题求解的当前状态 | 分层数据结构、假设网络、解决方案空间 |
| 知识源 | 独立的专家模块,具有特定领域的专业知识 | 信号处理算法、语法分析器、推理引擎 |
| 控制器 | 调度知识源执行的机制,基于当前黑板状态 | 机会主义调度、事件驱动、优先级队列 |
| 知识源触发器 | 监控黑板状态并激活相关知识源的条件 | 模式匹配规则、状态变化检测 |
问题求解过程:
| 阶段 | 描述 | 黑板状态变化 |
|---|---|---|
| 数据输入 | 原始数据被放置到黑板上 | 问题陈述、输入数据 |
| 假设生成 | 知识源基于当前数据生成初步假设 | 候选解决方案、部分解 |
| 假设精化 | 知识源验证、修正和扩展已有假设 | 假设评分、置信度更新 |
| 解决方案收敛 | 通过迭代改进达到可接受的解决方案 | 最终答案、完整解 |
控制策略:
| 策略类型 | 描述 | 适用场景 |
|---|---|---|
| 机会主义调度 | 选择在当前状态下最有希望取得进展的知识源 | 不确定性问题求解 |
| 事件驱动 | 响应黑板上的特定变化或事件 | 实时系统、流处理 |
| 优先级调度 | 基于知识源优先级和问题紧急程度 | 资源受限环境 |
| 议程机制 | 维护待执行的知识源动作队列 | 复杂决策过程 |
优势:
- 能够解决没有确定性算法的问题
- 支持多专家领域的协作
- 具有很好的可扩展性和灵活性
- 能够处理不完整和不确定的信息
- 支持增量式问题求解和学习
挑战:
- 系统行为难以预测和调试
- 控制策略设计复杂
- 可能产生组合爆炸问题
- 知识源之间的交互难以管理
- 性能优化困难
2.特点概述
黑板(Blackboard)架构风格是一种特殊的仓库风格,多个独立的专家系统(知识源)通过共享的"黑板"数据结构协作解决复杂问题,其中没有中央控制机制。
| 特点 | 描述 |
|---|---|
| 共享工作区 | 所有组件通过共享的"黑板"数据结构进行通信和协作 |
| 知识源独立性 | 各个知识源相互独立,不了解彼此的存在 |
| 机会主义推理 | 系统根据当前黑板状态动态选择最合适的知识源执行 |
| 增量问题求解 | 解决方案通过知识源的逐步贡献逐步完善 |
| 无中央控制 | 控制决策基于黑板当前状态,而非预定义流程 |
| 假设验证 | 知识源在黑板上提出和验证假设,逐步逼近解决方案 |
| 灵活协作 | 不同专家系统以松散耦合方式协作解决单一复杂问题 |
3.典型的黑板风格程序
| 程序名称 | 描述 | 知识源角色 | 黑板内容 |
|---|---|---|---|
| 语音识别系统 | 如早期HARPY、HEARSAY-II系统 | 声学分析、词汇匹配、语法分析、语义分析 | 原始音频、音素序列、候选词汇、句子假设 |
| 图像识别系统 | 计算机视觉和模式识别 | 边缘检测、形状分析、特征提取、对象识别 | 原始像素、边缘图、形状特征、对象假设 |
| 信号处理系统 | 雷达、声纳信号分析 | 信号滤波、特征提取、模式分类、目标跟踪 | 原始信号、特征向量、分类结果、跟踪轨迹 |
| 医疗诊断系统 | 如医学专家诊断系统 | 症状分析、疾病推理、治疗方案生成 | 患者数据、症状集合、疾病假设、诊断结论 |
| 自然语言理解 | 文本理解和语义分析 | 词法分析、句法分析、语义角色标注、推理 | 原始文本、词性标注、语法树、语义表示 |
| 车辆自动驾驶 | 环境感知和决策系统 | 传感器融合、路径规划、障碍物检测、控制决策 | 传感器数据、环境模型、可行路径、控制命令 |
| 网络安全监控 | 入侵检测和威胁分析 | 日志分析、行为检测、模式匹配、风险评估 | 网络流量、异常事件、攻击模式、威胁等级 |
| 工业故障诊断 | 设备监控和故障预测 | 振动分析、温度监控、性能评估、故障推理 | 传感器读数、特征指标、故障假设、维护建议 |
| 蛋白质结构预测 | 生物信息学分析 | 序列分析、结构比对、能量计算、构象搜索 | 氨基酸序列、结构模板、候选构象、能量评分 |
| 游戏AI决策 | 复杂游戏角色行为 | 环境感知、策略评估、动作选择、风险评估 | 游戏状态、可行动作、效用评估、决策序列 |
黑板架构特别适合那些需要多个专业领域知识协作、问题空间复杂且没有确定性解决方案的智能系统,是人工智能和复杂决策系统的重要架构模式。
六、虚拟机风格
虚拟机体系结构风格的基本思想是人为构建一个运行环境,在这个环境之上,可以解析与运行自定义的一些语言,这样来增加架构的灵活性。虚拟机体系结构风格主要包括解释器风格和规则系统风格。
(一)解释器风格
一个解释器通常包括完成解释工作的解释引擎,一个包含将被解释的代码的存储区,一个记录解释引擎当前工作状态的数据结构,以及一个记录源代码被解释执行进度的数据结构。
具有解释器风格的软件中含有一个虚拟机,可以仿真硬件的执行过程和一些关键应用。解释器通常被用来建立一种虚拟机以弥合程序语义与硬件语义之间的差异。其缺点是执行效率较低。典型的例子是专家系统。

1.案例
Python 脚本执行器。开发者编写 Python 脚本(业务逻辑),Python 解释器(虚拟机)将脚本翻译成机器语言执行,无需编译成二进制文件。
补充说明:构件是 "脚本(业务逻辑)" 和 "解释器(虚拟机)",连接件是 "脚本语法规则";约束是 "脚本需遵循解释器的语法规范",适合快速迭代、逻辑多变的场景。
解释器架构组件:
| 组件 | 功能 | 示例 |
|---|---|---|
| 词法分析器 | 将源代码分解为词法单元 | 标识符、关键字、运算符识别 |
| 语法分析器 | 构建抽象语法树 | 语法规则验证、AST构建 |
| 语义分析器 | 检查语义正确性 | 类型检查、作用域分析 |
| 解释引擎 | 执行中间表示 | 字节码解释、树遍历执行 |
| 运行时环境 | 管理执行状态 | 变量存储、内存管理、异常处理 |
| 标准库 | 提供内置函数和类 | 系统函数、基础类库 |
解释器工作流程:
源代码 → 词法分析 → 语法分析 → 语义分析 → 中间表示 → 解释执行 → 结果输出解释器类型:
| 类型 | 描述 | 典型实现 |
|---|---|---|
| 抽象语法树解释器 | 直接遍历和执行AST节点 | 早期Lisp解释器、简单计算器 |
| 字节码解释器 | 将源码编译为字节码后解释执行 | Python、Java虚拟机 |
| 即时编译解释器 | 在运行时编译为本地代码 | V8 JavaScript引擎、PyPy |
| 基于规则的解释器 | 执行规则集合和模式匹配 | 专家系统、业务规则引擎 |
| 数据流解释器 | 基于数据依赖关系执行 | 可视化编程语言、ETL工具 |
执行模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| 纯解释执行 | 直接分析源码并执行 | 简单脚本语言、配置解析 |
| 编译+解释 | 先编译为中间代码再解释 | 大多数现代解释型语言 |
| 即时编译 | 运行时编译为机器码执行 | 高性能JavaScript、Python |
| 增量编译 | 按需编译和执行代码块 | 交互式开发环境 |
优势:
- 平台无关性,一次编写到处运行
- 动态性和灵活性,支持运行时代码生成
- 更好的错误检查和调试支持
- 适合快速原型开发和脚本任务
挑战:
- 执行性能通常低于编译型语言
- 内存消耗较大
- 隐藏底层细节,可能影响系统级优化
- 部署依赖运行时环境
2.特点概述
解释器(Interpreter)架构风格属于虚拟机风格,其核心特点是提供一个执行环境来解释和执行用特定语言或领域特定语言编写的程序或表达式。
| 特点 | 描述 |
|---|---|
| 语言解释 | 能够解析和执行特定语言或DSL的代码 |
| 运行时环境 | 提供执行代码所需的虚拟机和环境状态 |
| 抽象语法树 | 将源代码转换为中间表示(如AST)进行解释 |
| 动态执行 | 支持运行时代码解析和执行 |
| 领域特定 | 通常针对特定领域设计专用语言和解释器 |
| 符号处理 | 能够处理符号计算和动态绑定 |
| 可扩展性 | 允许用户通过编写新代码扩展系统行为 |
3.典型的解释器风格程序
| 程序名称 | 描述 | 解释的语言/规则 | 核心组件 |
|---|---|---|---|
| Python解释器 | CPython执行环境 | Python语言 | 词法分析器、语法分析器、字节码解释器、对象系统 |
| JavaScript引擎 | 如V8、SpiderMonkey | JavaScript语言 | JIT编译器、垃圾回收器、运行时环境 |
| 正则表达式引擎 | 如PCRE、RE2库 | 正则表达式语法 | 模式编译器、状态机执行器 |
| 数据库查询解释器 | SQL执行引擎 | SQL查询语言 | 查询解析器、优化器、执行引擎 |
| 规则引擎系统 | 如Drools、CLIPS | 业务规则语言 | 规则匹配器、推理引擎、工作内存 |
| 模板引擎 | 如Jinja2、Thymeleaf | 模板语言 | 模板解析器、上下文处理器、渲染器 |
| 计算器程序 | 科学计算器 | 数学表达式 | 表达式解析器、符号计算器 |
| 配置脚本解释器 | 如Apache配置 | 配置DSL | 配置解析器、设置应用器 |
| 游戏脚本引擎 | 如Lua脚本引擎 | 游戏脚本语言 | 脚本虚拟机、API绑定、事件系统 |
| 工作流引擎 | 如Activiti、Camunda | BPMN工作流语言 | 流程解析器、状态机、任务执行器 |
| 标记语言处理器 | 如Markdown解析器 | Markdown语法 | 标记解析器、HTML生成器 |
| 领域特定语言 | 如MATLAB、R语言 | 特定领域语法 | 领域函数库、交互式环境 |
解释器架构风格特别适合需要高度灵活性、快速迭代和跨平台兼容性的应用场景,是现代脚本语言、领域特定语言和配置系统的核心技术基础。
(二)规则系统风格
基于规则的系统(见图)包括规则集、规则解释器、规则/数据选择器及工作内存。

1.案例
保险理赔审核系统。预设理赔规则(如 "医疗费用> 5000 元需人工审核""意外身故赔付保额 100%"),系统接收理赔申请后,通过规则引擎(虚拟机)匹配规则并执行审核结果。
补充说明:构件是 "规则库、规则引擎、理赔申请模块",连接件是 "规则匹配逻辑";约束是 "规则需标准化定义,引擎按固定顺序匹配",适合规则明确且频繁变更的系统。
系统架构组件:
| 组件 | 功能 | 示例 |
|---|---|---|
| 规则库 | 存储所有业务规则和领域知识 | IF-THEN规则集合、决策表 |
| 工作内存 | 存储当前事实和系统状态 | 事实对象、临时数据 |
| 推理引擎 | 执行规则匹配和推理过程 | Rete算法、前向链、后向链 |
| 规则编辑器 | 提供规则创建和管理的界面 | 可视化规则设计器 |
| 事实管理器 | 管理事实的插入、修改和删除 | 对象管理器、事件处理器 |
规则执行周期:
事实插入 → 模式匹配 → 冲突集生成 → 冲突解决 → 规则执行 → 事实更新推理策略:
| 策略类型 | 描述 | 适用场景 |
|---|---|---|
| 前向链推理 | 从已知事实出发推导新结论 | 数据驱动系统、监控系统 |
| 后向链推理 | 从目标假设出发寻找支持证据 | 诊断系统、查询系统 |
| 混合推理 | 结合前向和后向链推理 | 复杂决策支持系统 |
| 确定性推理 | 基于布尔逻辑的精确推理 | 业务规则执行 |
| 不确定性推理 | 处理概率和置信度 | 专家诊断系统 |
规则模式类型:
| 规则类型 | 描述 | 示例 |
|---|---|---|
| 产生式规则 | IF条件THEN动作 | IF温度>30 THEN开启空调 |
| 决策表 | 多条件多结果的表格形式 | 保险保费计算表 |
| 决策树 | 树状结构的分类规则 | 客户分类树 |
| 业务规则 | 自然语言风格的业务策略 | "黄金客户享受9折优惠" |
| 约束规则 | 系统必须满足的条件 | "库存数量不能为负数" |
优势:
- 知识表示直观,易于领域专家理解
- 规则之间相对独立,便于维护和更新
- 系统行为可解释,推理过程透明
- 支持增量式知识积累
- 规则重用性高
挑战:
- 规则冲突解决复杂
- 大规模规则库性能可能下降
- 规则间隐式依赖难以管理
- 需要处理规则循环和递归
- 规则一致性验证困难
2.特点概述
基于规则的系统(Rule-based Systems)属于虚拟机风格,其核心特点是使用一组预定义的规则来表示领域知识,并通过推理引擎来执行这些规则解决问题。
| 特点 | 描述 |
|---|---|
| 规则表示 | 知识以"条件-动作"规则的形式存储(IF-THEN格式) |
| 声明式编程 | 关注"做什么"而非"如何做",规则描述逻辑而非流程 |
| 知识库与推理引擎分离 | 规则存储与规则执行机制分离 |
| 模式匹配驱动 | 系统通过匹配事实和规则条件来触发相应动作 |
| 可解释性 | 推理过程相对透明,便于理解和调试 |
| 易于维护 | 通过添加/修改规则即可更新系统行为 |
| 不确定性 | 多个规则可能同时满足条件,需要冲突解决策略 |
3.典型的基于规则系统程序
| 程序名称 | 描述 | 规则类型 | 推理机制 |
|---|---|---|---|
| 专家系统 | 如MYCIN医疗诊断系统 | 诊断规则、治疗建议 | 前向链推理、置信度计算 |
| 业务规则管理系统 | 如Drools、IBM ODM | 业务策略、合规规则 | Rete算法、规则流 |
| 信用卡欺诈检测 | 实时交易监控系统 | 欺诈模式规则、风险评估 | 复杂事件处理、实时推理 |
| 网络入侵检测系统 | 如Snort、Suricata | 攻击特征规则、异常检测 | 模式匹配、状态跟踪 |
| 智能客服聊天机器人 | 自动问答系统 | 问答规则、对话流程 | 模式匹配、上下文推理 |
| 工业控制系统 | 如PLC程序、自动化系统 | 控制逻辑、安全规则 | 顺序执行、事件响应 |
| 保险理赔系统 | 自动理赔处理 | 理赔策略、风险评估 | 规则优先级、工作流集成 |
| 税收计算系统 | 自动税务处理 | 税法规则、减免条件 | 确定性推理、计算规则 |
| 游戏AI系统 | NPC行为决策 | 行为规则、环境响应 | 实时推理、优先级调度 |
| 质量检测系统 | 产品缺陷检测 | 质量标准、缺陷模式 | 视觉规则、测量规则 |
| 配置验证系统 | 系统配置检查 | 最佳实践、安全策略 | 配置扫描、合规检查 |
| 智能家居控制 | 自动化场景执行 | 场景规则、设备联动 | 事件触发、状态条件 |
基于规则的系统特别适合那些领域知识可以明确表示为规则、业务逻辑频繁变化、需要透明决策过程的场景,是业务规则管理和专家系统的重要技术基础。