文章目录
一、概述
1、简介
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念------Hadoop生态圈。
2、Hadoop 优势
-
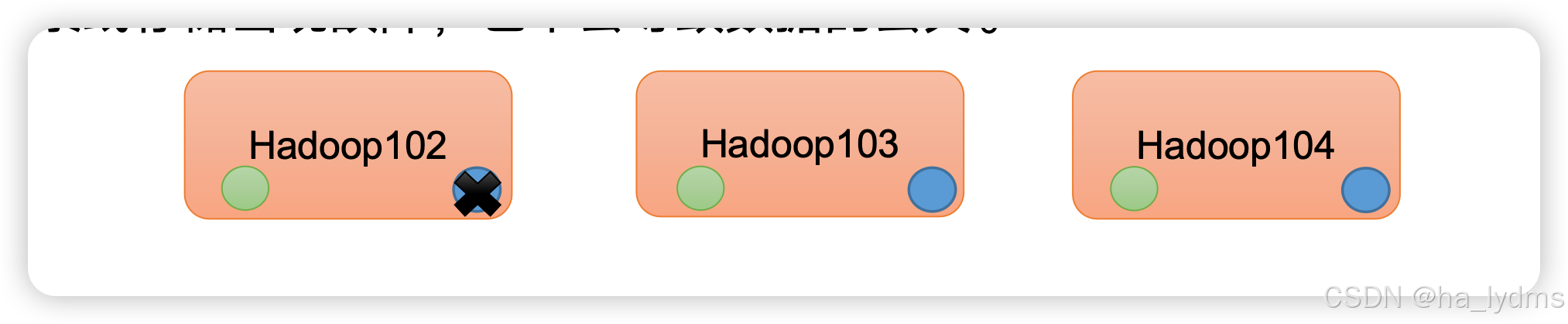
高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
-
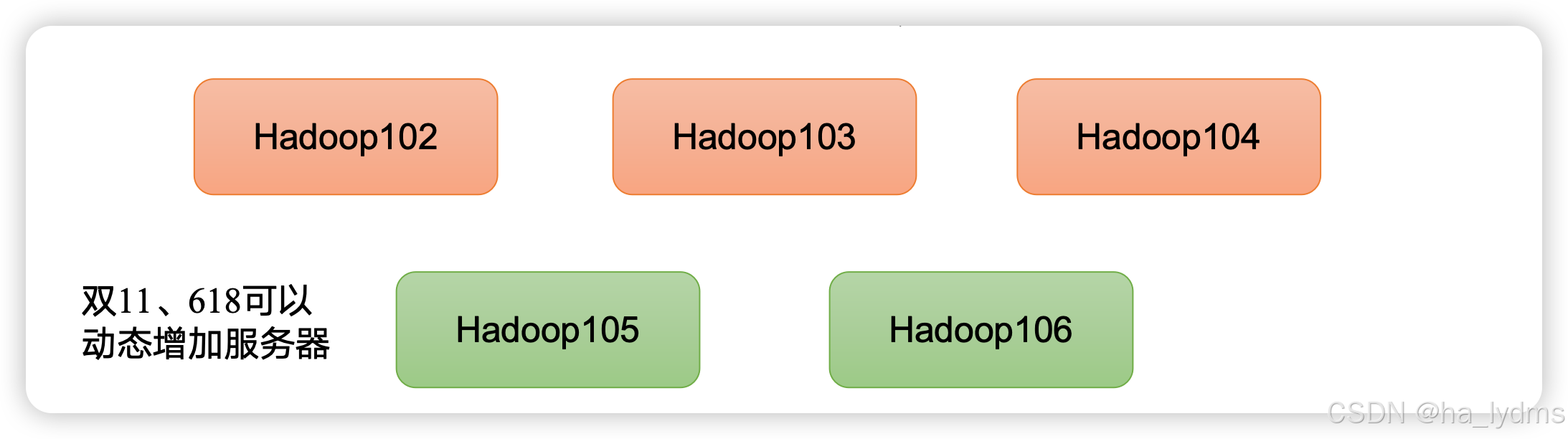
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
-
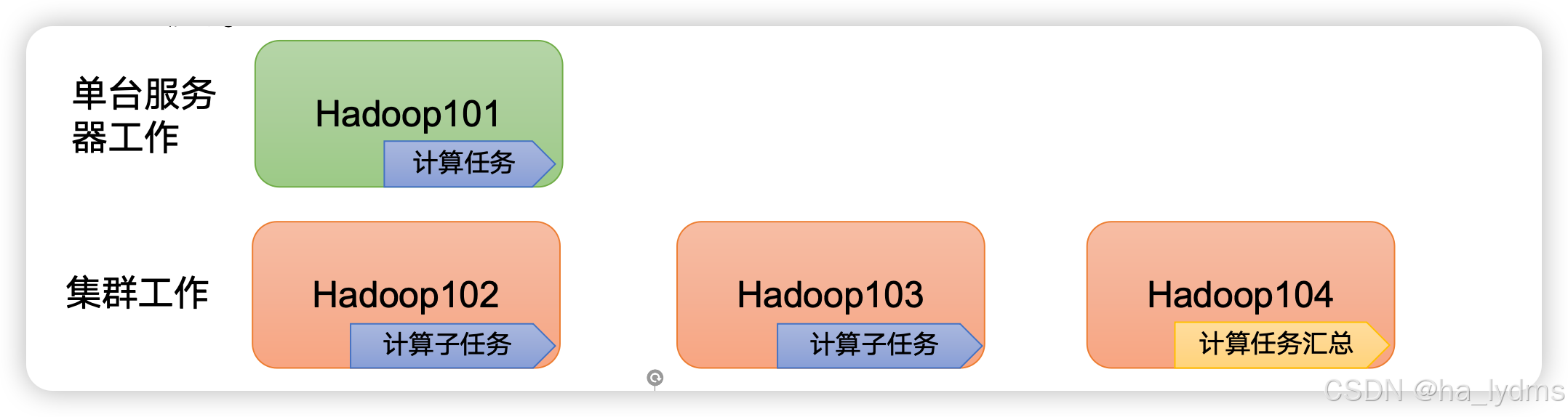
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
 4. 高容错性:能够自动将失败的任务重新分配。
4. 高容错性:能够自动将失败的任务重新分配。
二、架构
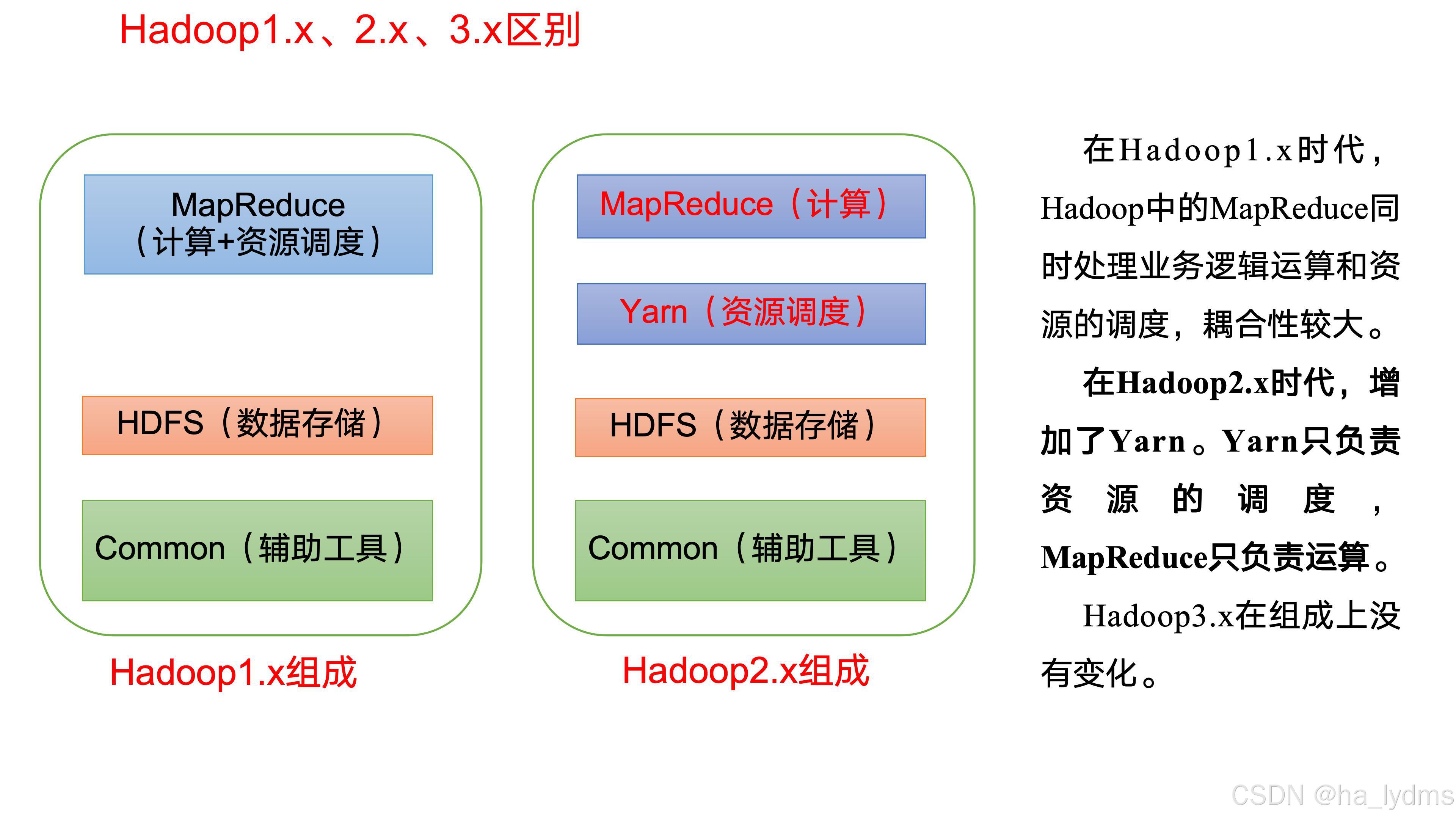
1、Hadoop组成
2、HDFS
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。

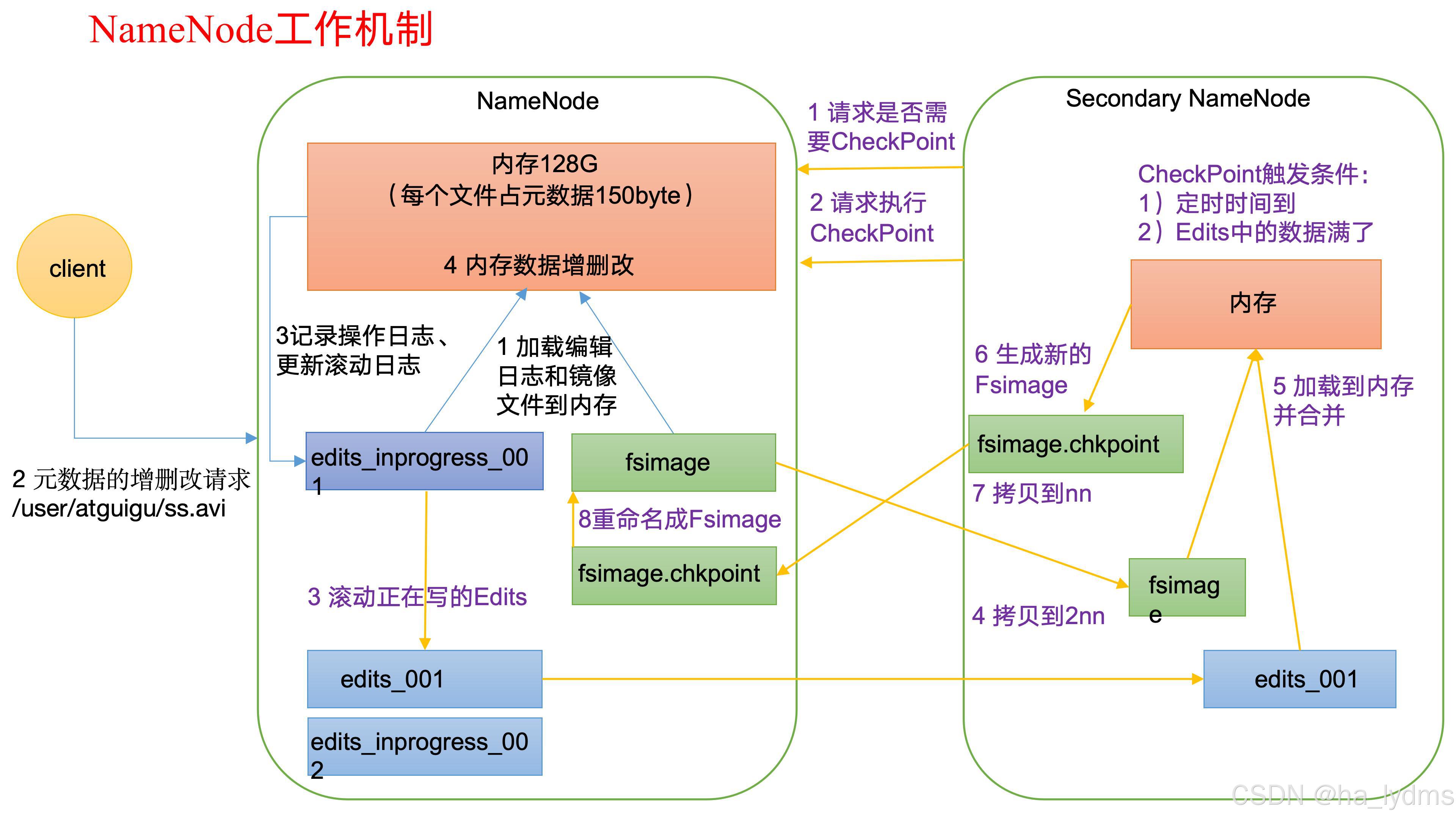
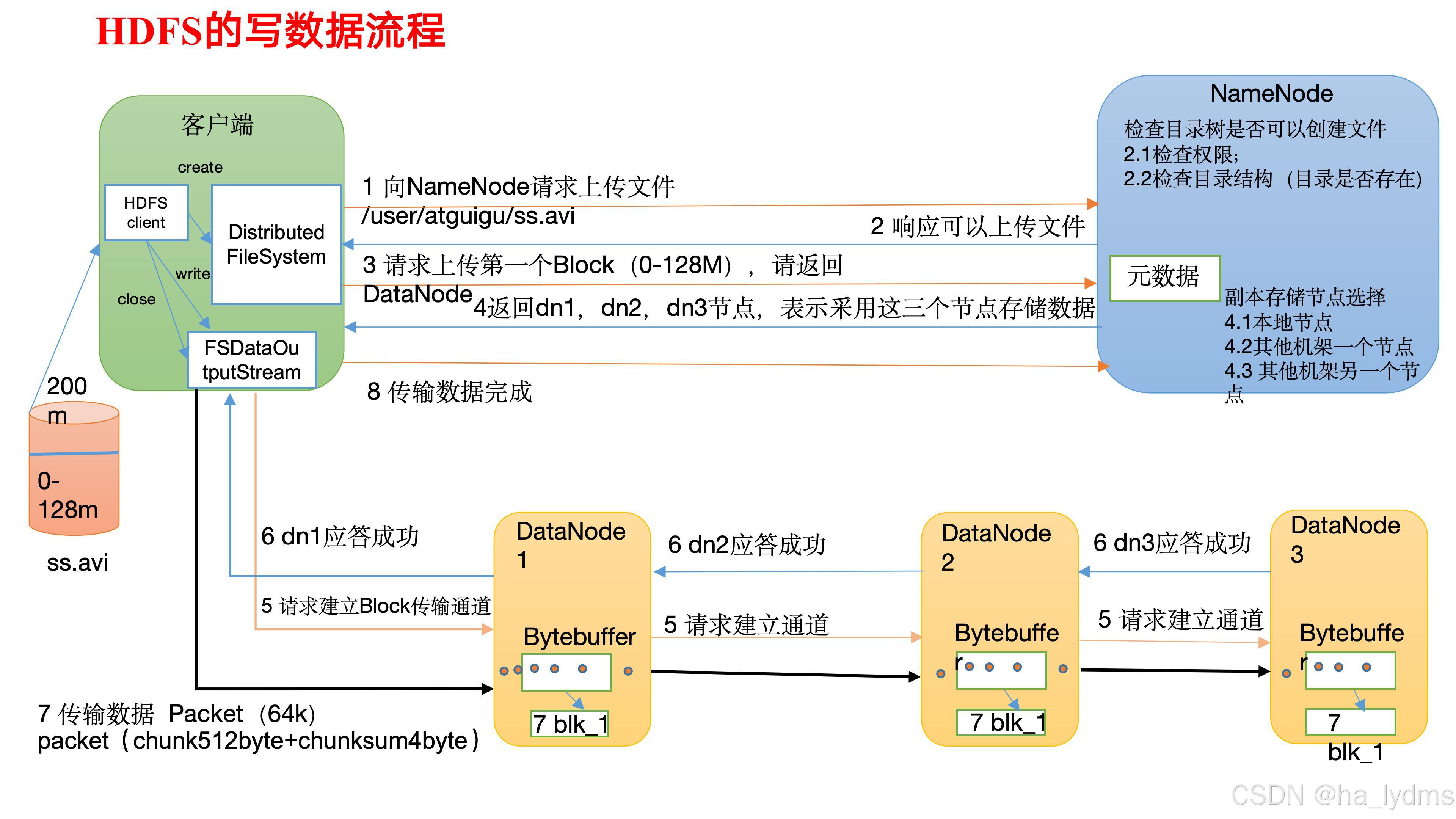
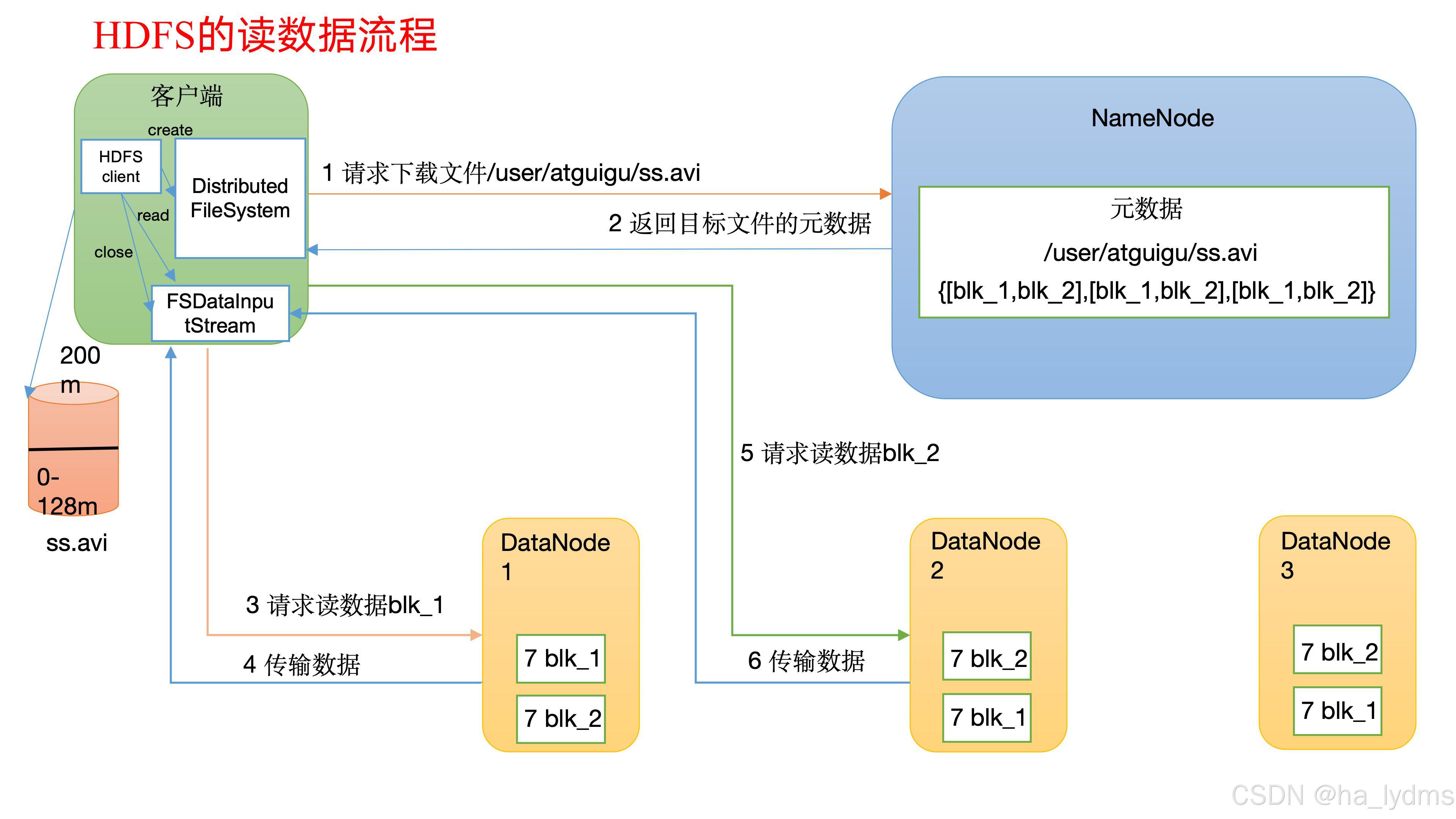
- 1)(nn):就是Master,它是一个主管、管理者。
- (1)管理HDFS的名称空间;
- (2)配置副本策略;
- (3)管理数据块(Block)映射信息;
- (4)处理客户端读写请求。
- 2)DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
- (1)存储实际的数据块;
- (2)执行数据块的读/写操作。
- 3)Client:就是客户端。
- (1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
- (2)与NameNode交互,获取文件的位置信息;
- (3)与DataNode交互,读取或者写入数据;
- (4)Client提供一些命令来管理HDFS,比如NameNode格式化;
- (5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
- 4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
- (1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
- (2)在紧急情况下,可辅助恢复NameNode。
3、YARN
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。
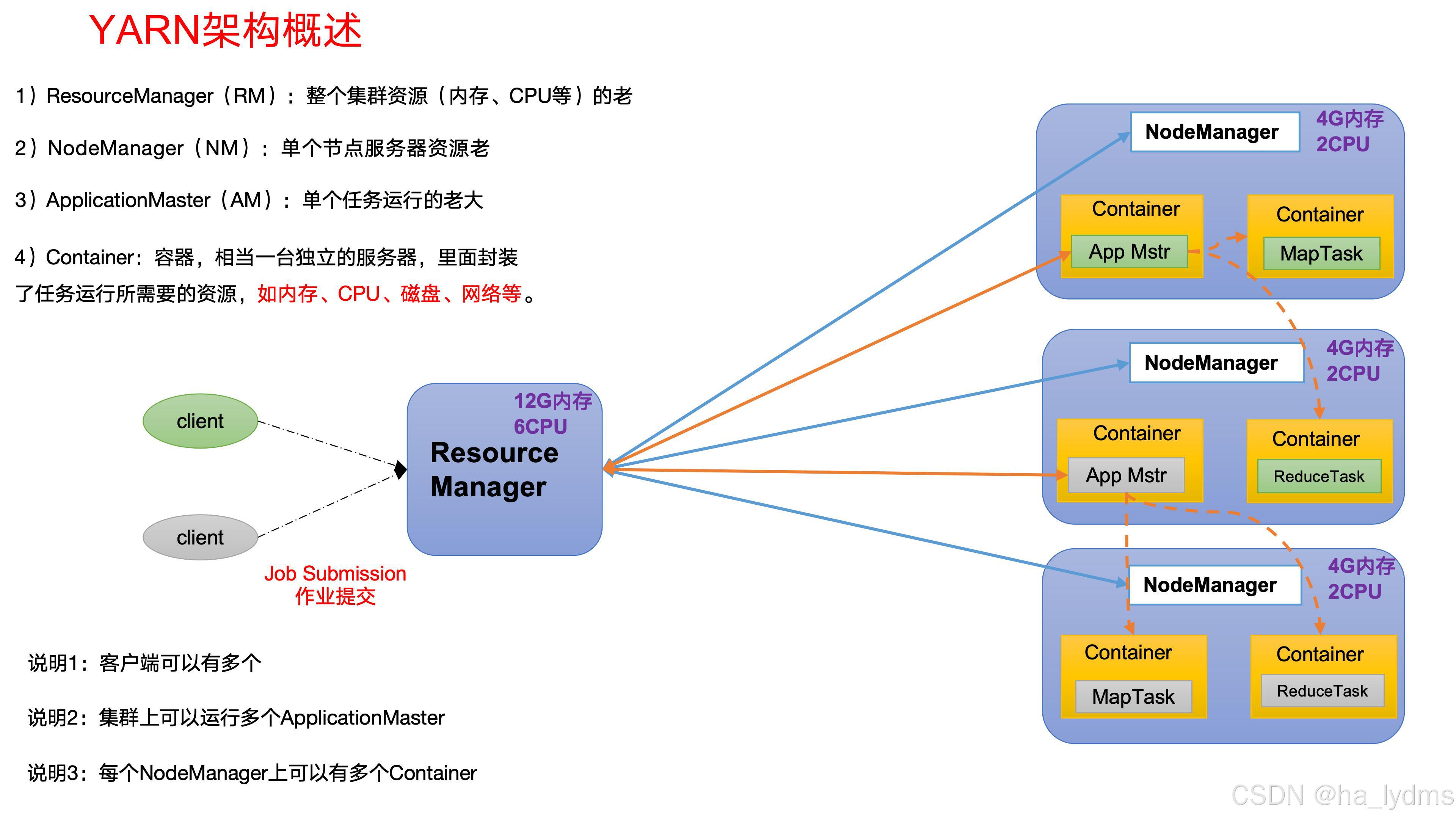
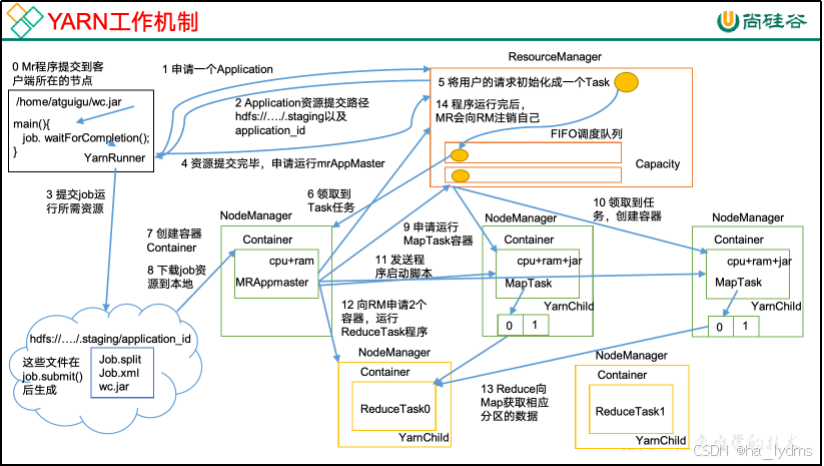
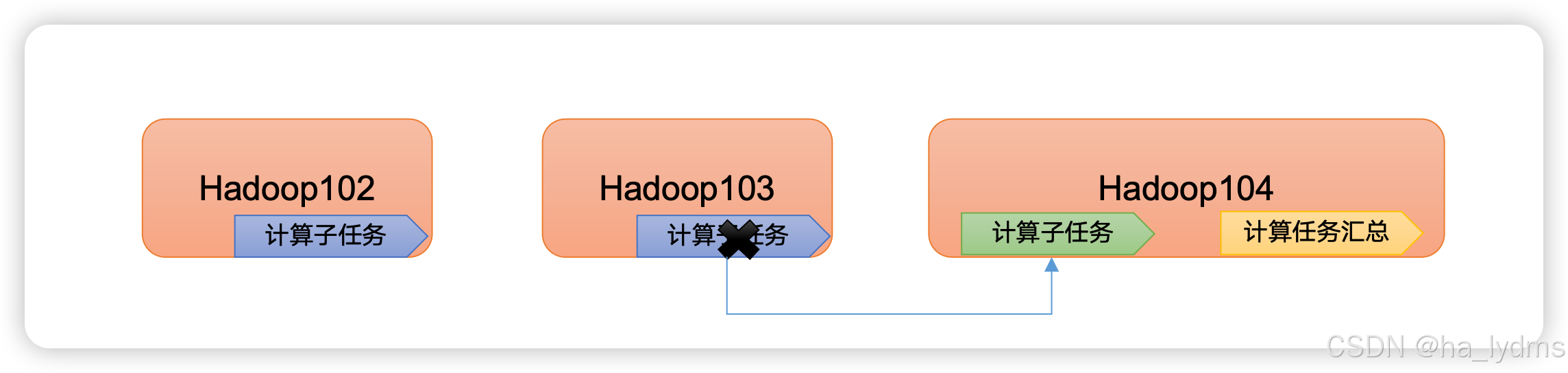
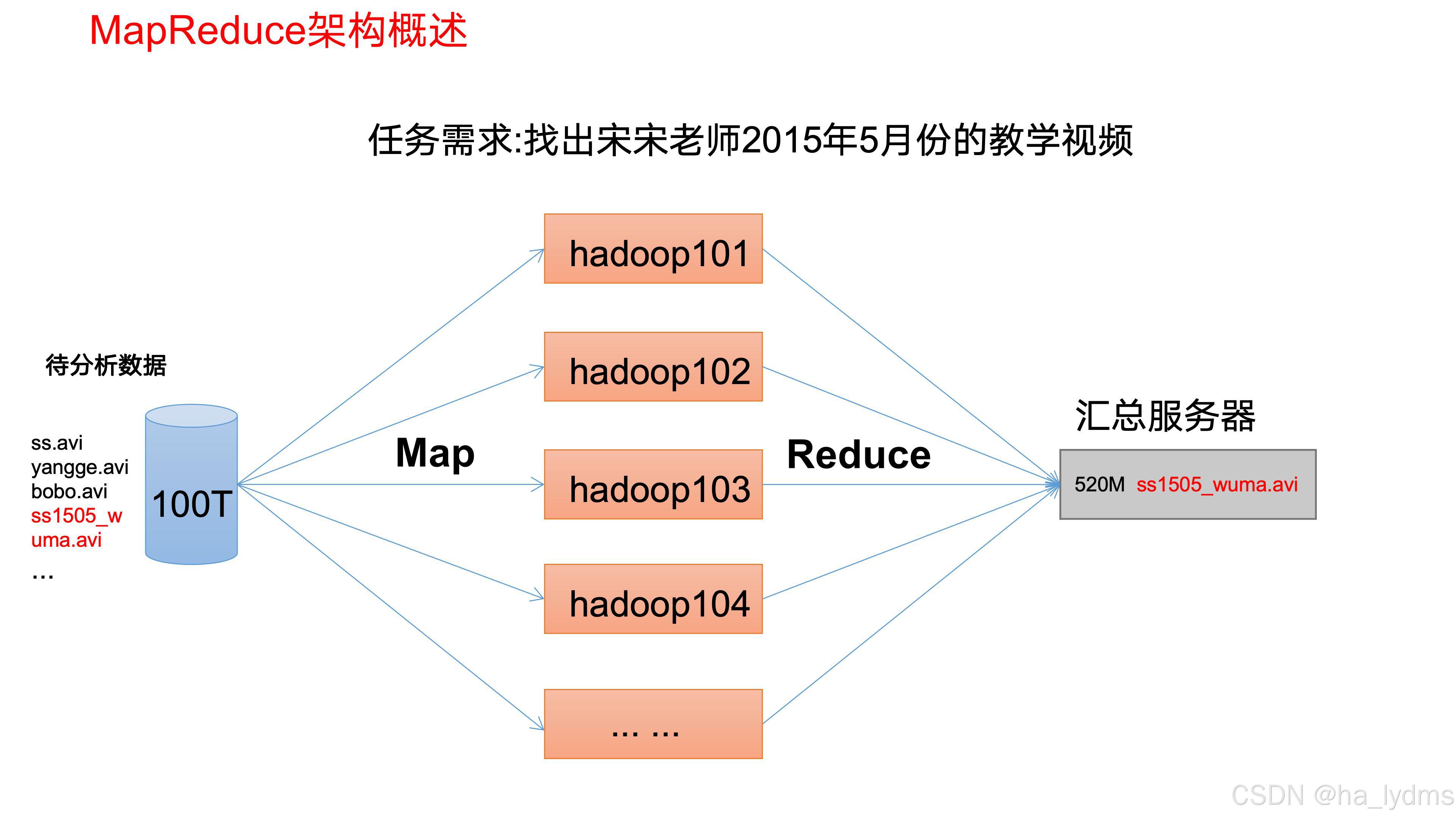
4、MapReduce
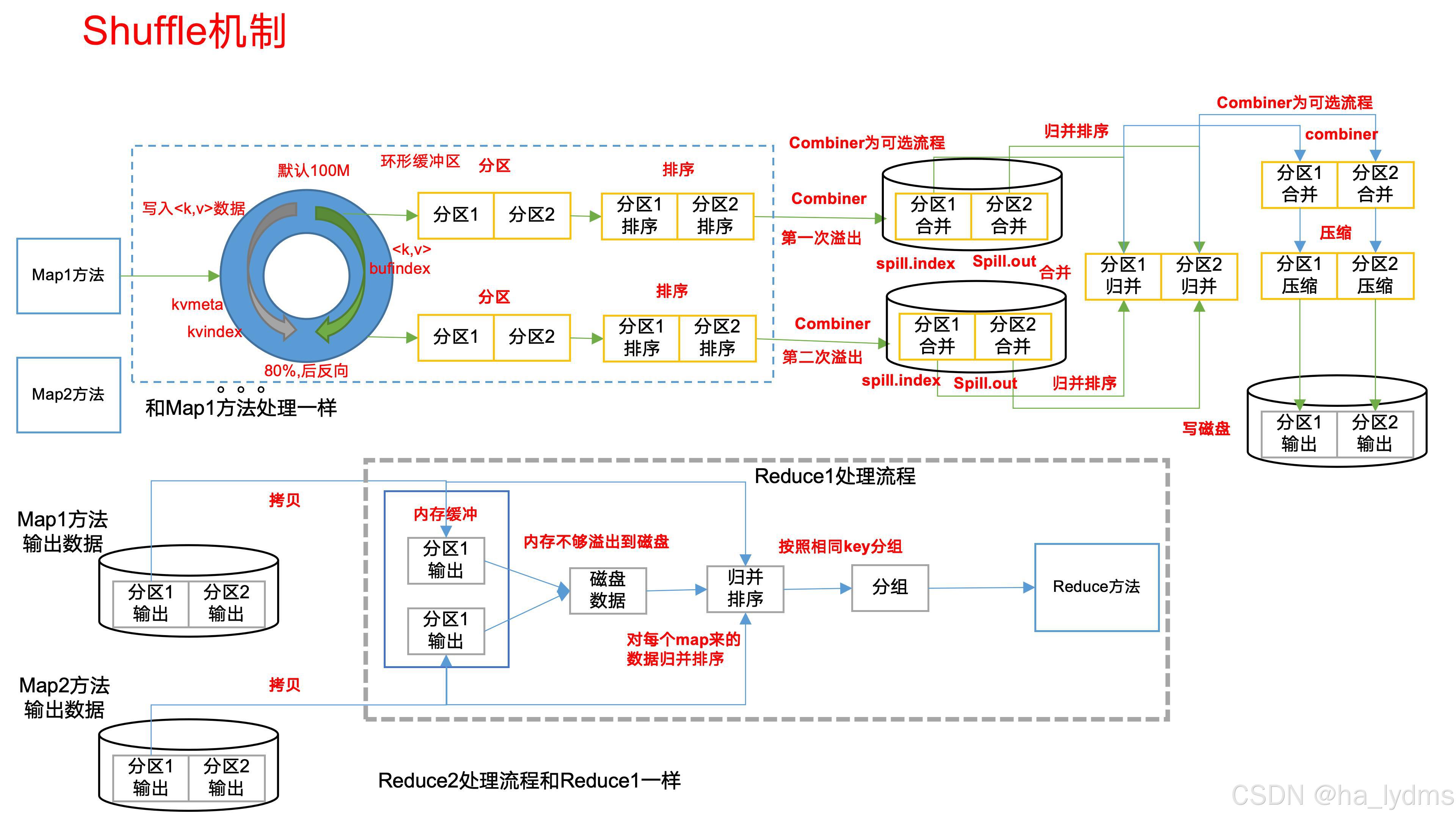
MapReduce将计算过程分为两个阶段:Map和Reduce。
(1)Map阶段并行处理输入数据
(2)Reduce阶段对Map阶段的结果进行汇总
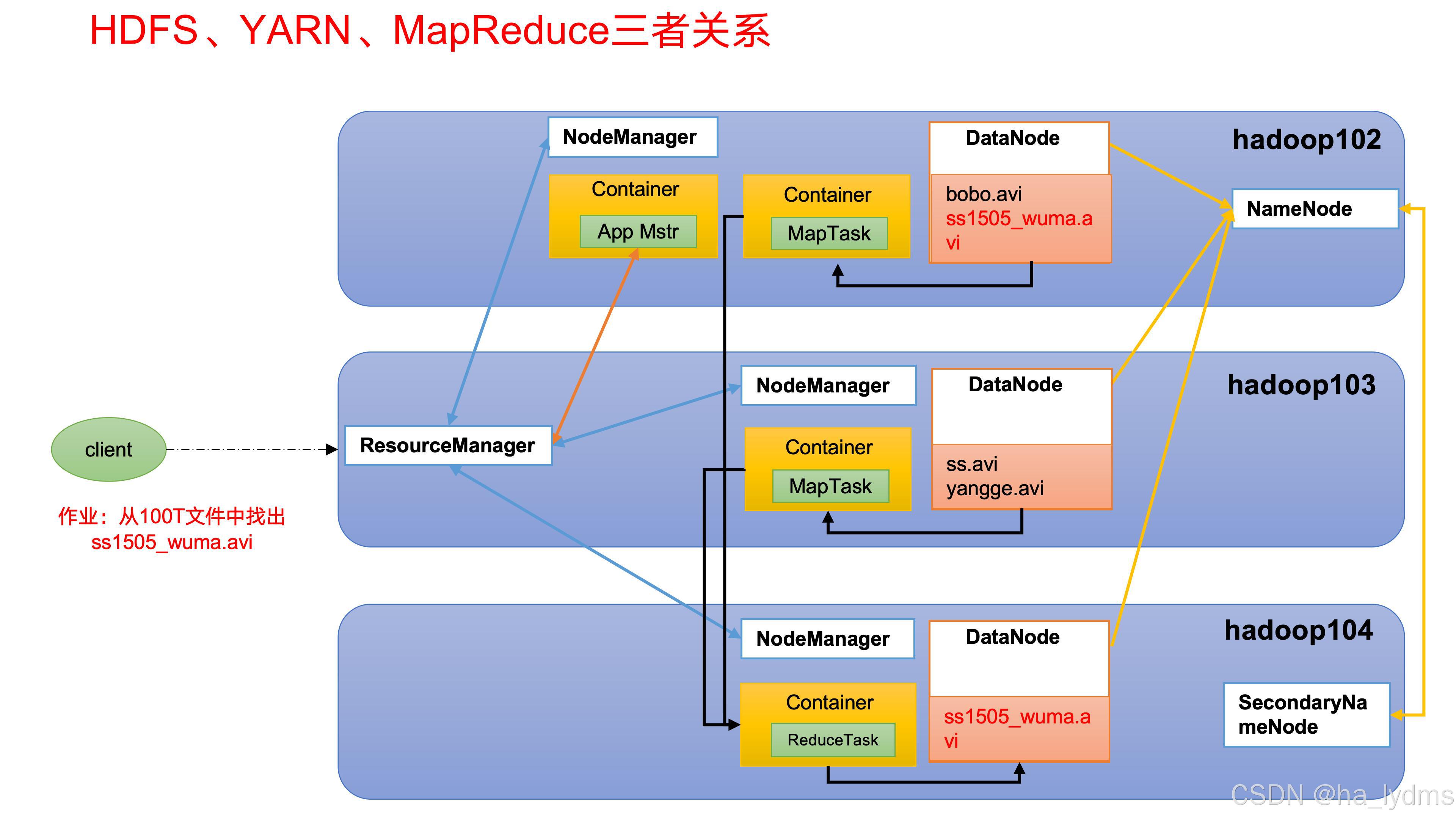
5、HDFS、YARN、MapReduce三者关系
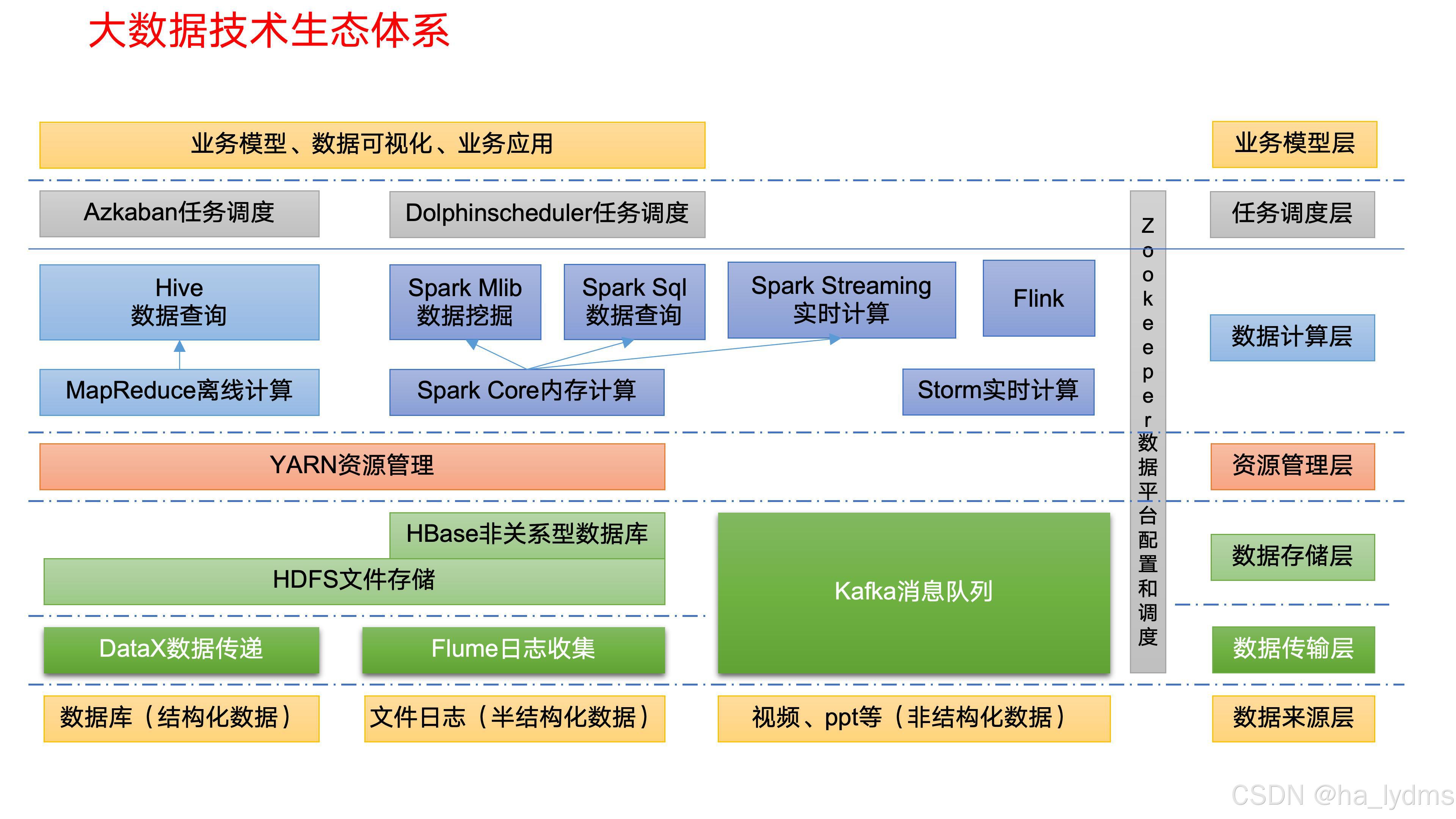
6、大数据技术生态体系