太棒了!你已经坚持到第4天,这是 R 语言学习中最关键的一天 ------因为从今天起,你将掌握 现代 R 数据处理的核心工具:dplyr!
💡
dplyr是"R语言数据科学"生态(tidyverse)的基石,语法清晰、效率高、代码可读性强,被全球数据分析师广泛使用。
🎯 第4天学习目标
✅ 安装并加载 dplyr
✅ 掌握四大核心函数:
filter():按条件筛选行select():选择特定列mutate():创建新变量(列)arrange():对行排序
✅ 学会用 管道操作符%>%让代码像"流水线"一样流畅
📘 核心概念速览
| 函数 | 作用 | 类比 |
|---|---|---|
filter(df, 条件) |
筛选满足条件的行 | Excel 的"筛选"功能 |
select(df, 列1, 列2) |
选择需要的列 | 隐藏不需要的列 |
mutate(df, 新列 = 表达式) |
增加计算后的新列 | Excel 添加公式列 |
arrange(df, 列名) |
按某列升序排序 | Excel 的"排序" |
🔁 所有操作不会修改原始数据,而是返回一个新数据框(安全!)
💻 第4天完整练习脚本(复制到 RStudio 即可运行)
# ==============================================
# R语言零基础学习 · 第4天练习(修正版)
# ==============================================
# ----------------------------
# Part 1: 安装并加载必要的包
# ----------------------------
# 如果是第一次使用,请取消注释并运行一次
# install.packages(c("dplyr", "tibble"))
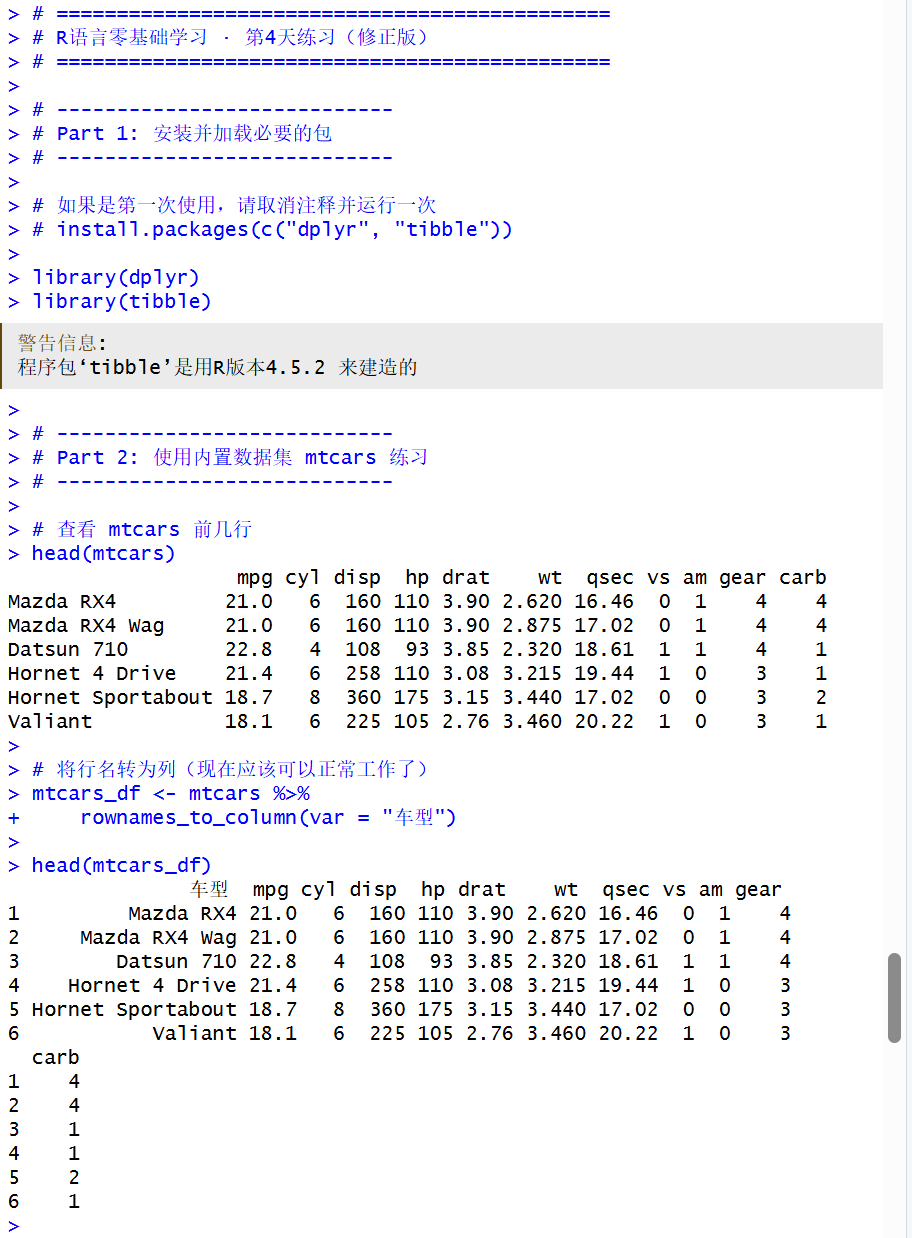
library(dplyr)
library(tibble)
# ----------------------------
# Part 2: 使用内置数据集 mtcars 练习
# ----------------------------
# 查看 mtcars 前几行
head(mtcars)
# 将行名转为列(现在应该可以正常工作了)
mtcars_df <- mtcars %>%
rownames_to_column(var = "车型")
head(mtcars_df)
# ----------------------------
# Part 3: 四大核心函数练习
# ----------------------------
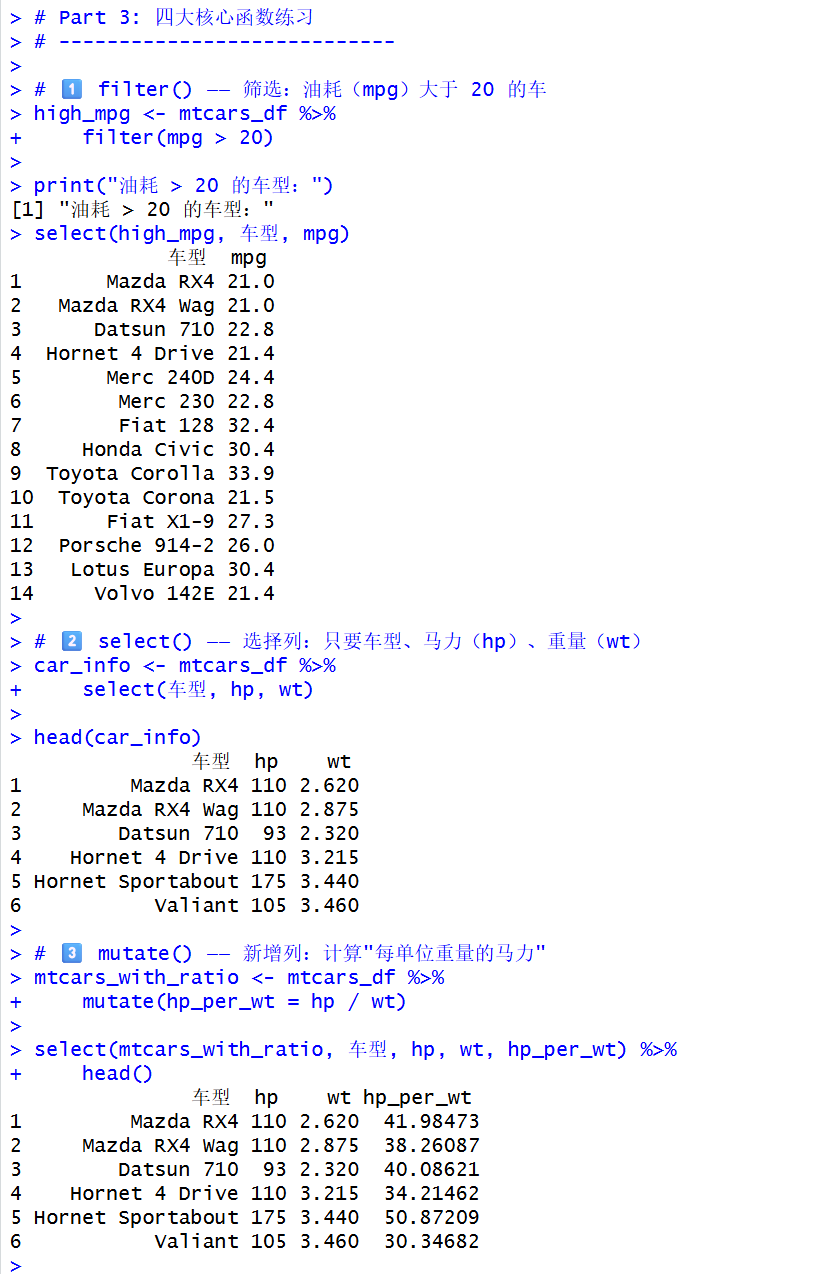
# 1️⃣ filter() ------ 筛选:油耗(mpg)大于 20 的车
high_mpg <- mtcars_df %>%
filter(mpg > 20)
print("油耗 > 20 的车型:")
select(high_mpg, 车型, mpg)
# 2️⃣ select() ------ 选择列:只要车型、马力(hp)、重量(wt)
car_info <- mtcars_df %>%
select(车型, hp, wt)
head(car_info)
# 3️⃣ mutate() ------ 新增列:计算"每单位重量的马力"
mtcars_with_ratio <- mtcars_df %>%
mutate(hp_per_wt = hp / wt)
select(mtcars_with_ratio, 车型, hp, wt, hp_per_wt) %>%
head()
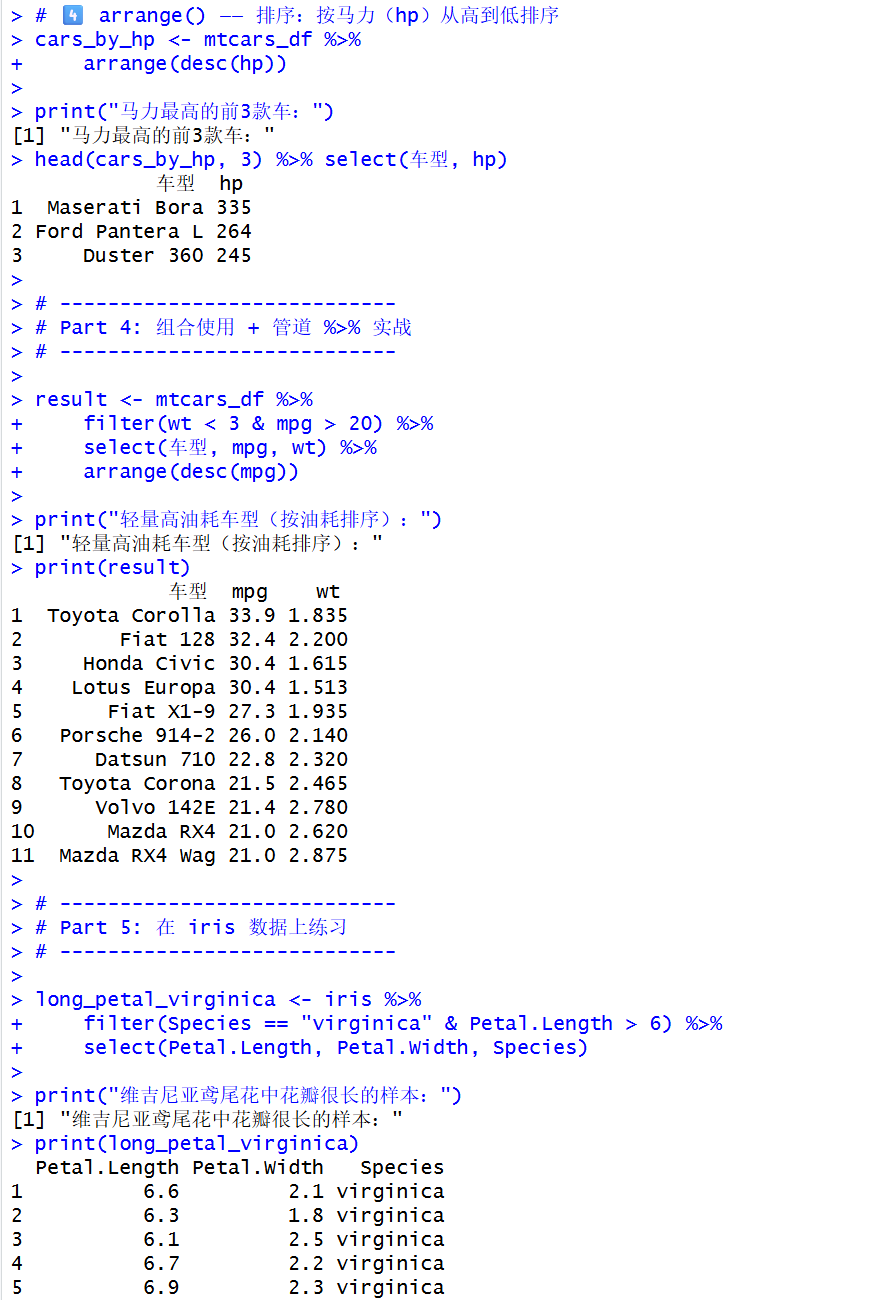
# 4️⃣ arrange() ------ 排序:按马力(hp)从高到低排序
cars_by_hp <- mtcars_df %>%
arrange(desc(hp))
print("马力最高的前3款车:")
head(cars_by_hp, 3) %>% select(车型, hp)
# ----------------------------
# Part 4: 组合使用 + 管道 %>% 实战
# ----------------------------
result <- mtcars_df %>%
filter(wt < 3 & mpg > 20) %>%
select(车型, mpg, wt) %>%
arrange(desc(mpg))
print("轻量高油耗车型(按油耗排序):")
print(result)
# ----------------------------
# Part 5: 在 iris 数据上练习
# ----------------------------
long_petal_virginica <- iris %>%
filter(Species == "virginica" & Petal.Length > 6) %>%
select(Petal.Length, Petal.Width, Species)
print("维吉尼亚鸢尾花中花瓣很长的样本:")
print(long_petal_virginica)
# ----------------------------
# Part 6: 你的小任务(修正版)
# ----------------------------
# 【任务1】在 mtcars 中:
task1_result <- mtcars_df %>%
mutate(cost_per_gallon = 1 / mpg) %>%
filter(cyl == 4) %>%
arrange(cost_per_gallon) %>%
select(车型, mpg, cyl, cost_per_gallon)
print("4缸车中油耗最优(成本最低)的前三名:")
head(task1_result, 3)
# 【任务2】在 iris 中:
setosa_avg <- iris %>%
filter(Species == "setosa") %>%
pull(Petal.Length) %>%
mean()
cat("山鸢尾(setosa)平均花瓣长度:", round(setosa_avg, 2), "\n")
cat("\n🎉 第4天练习完成!\n")
mtcars_df <- mtcars %>% + rownames_to_column(var = "车型")等价于没有管道的写法:mtcars_df <- rownames_to_column(mtcars, var = "车型")
理解
%>%(管道操作符)
作用:把左边的结果传递给右边的函数作为第一个参数
读作:"然后"
mtcars %>% rownames_to_column(var = "车型")
意思是:"取 mtcars 数据集,然后把它的行名转成一列,列名叫做'车型'"
理解
rownames_to_column()函数
功能:将数据框的行名转换为一个新的列
参数:
.data:数据框(通过管道自动传入)
var:新列的名称(这里设为"车型")

🔑 管道操作符 %>% 是什么?
-
读作 "然后"
-
把前一个结果自动传给下一个函数的第一个参数
-
避免嵌套:
❌head(select(filter(mtcars, mpg>20), c(mpg,wt)))
✅🔑 管道操作符 %>% 是什么?
读作 "然后"
把前一个结果自动传给下一个函数的第一个参数
避免嵌套:
❌ head(select(filter(mtcars, mpg>20), c(mpg,wt)))
✅
小技巧:在 RStudio 中输入
%>%可按Ctrl + Shift + M(Windows)或Cmd + Shift + M(Mac)快速输入!
❓ 常见问题
Q:dplyr 和之前学的 subset() 有什么区别?
A:dplyr 更一致、更强大、支持管道,适合复杂操作;subset() 适合简单临时筛选。
Q:为什么有时候列名要加引号,有时候不用?
A:在 dplyr 中,列名直接写,不加引号 (如 mpg),这是它的设计优势!
Q:pull() 是什么?
A:从数据框中提取某一列为向量 ,方便后续计算(如 mean())。
📁 保存建议
- 文件名:
day4_dplyr.R - 和前几天脚本放在一起,形成完整学习路径
🚀 下一步预告(第5天)
📌 第5天:基础可视化(ggplot2 入门)
你将学会用一行代码画出专业级图表:散点图、柱状图、箱线图......