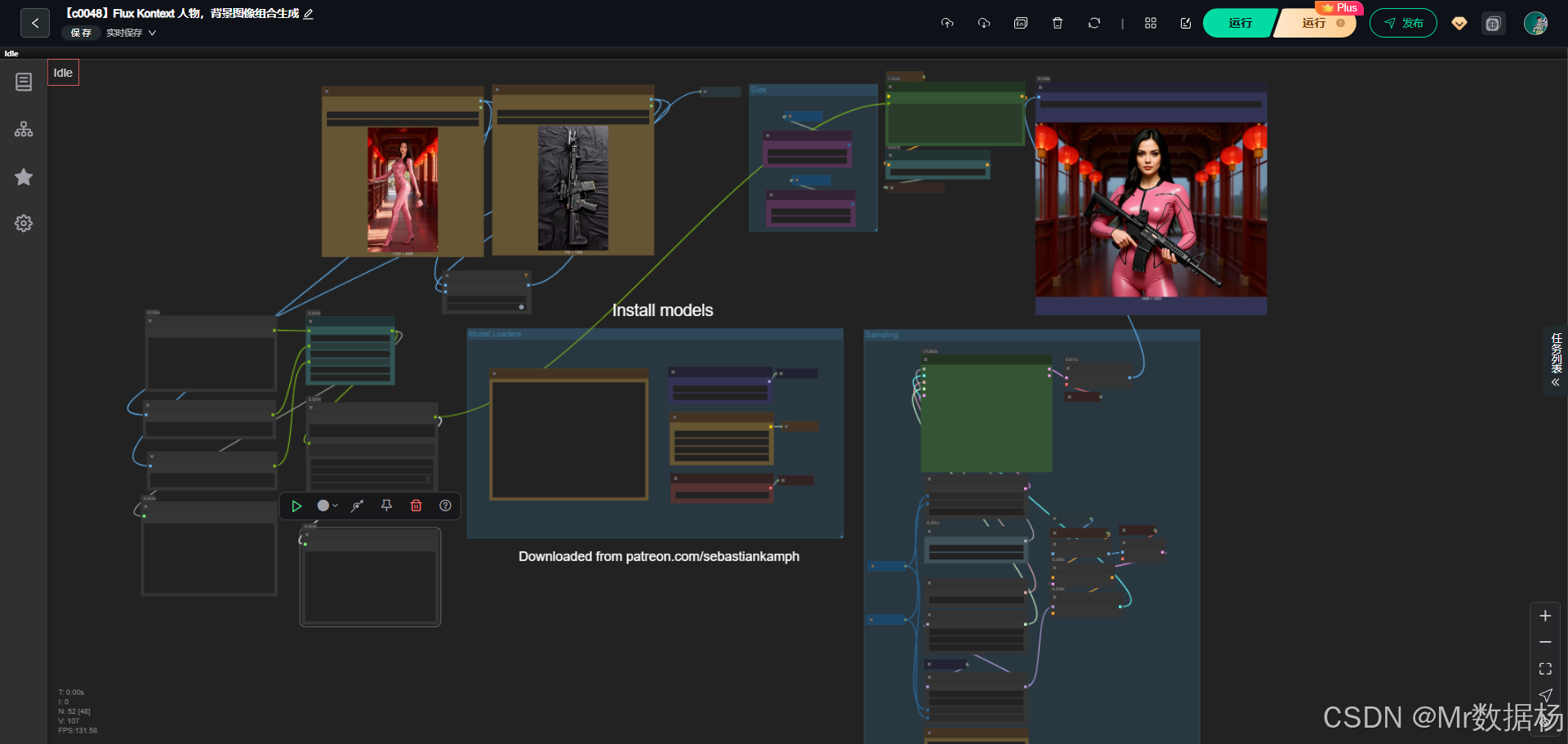
今天展示的案例是一个基于 Flux Kontext 的多图融合 ComfyUI 工作流,整个流程以两张图像为输入,通过拼接、缩放与潜变量处理,再结合 CLIP 文本编码和模型采样机制,实现了图像的多模态融合与重新生成。

该工作流的重点在于将视觉信息和文本条件进行联合建模,从而在保持输入图像核心特征的同时生成符合提示语义的全新图像。结合效果演示,可以直观感受到多源素材在统一模型下的融合能力,为创意设计、影视概念生成和跨领域视觉实验提供了灵活工具。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode 文本语义嵌入生成](#CLIPTextEncode 文本语义嵌入生成)
- [FluxGuidance 文本嵌入调控](#FluxGuidance 文本嵌入调控)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
整个工作流由模型加载、文本条件编码、图像预处理、潜变量生成、噪声注入与采样、解码及最终图像保存等模块组成。核心思想是利用 Flux Kontext 的模型作为基础生成引擎,配合 VAE 编码器/解码器和 CLIP 文本引导,在两张图像拼接形成的输入上施加条件控制,进而生成兼具语义与视觉一致性的图像。
核心模型
工作流中涉及的模型涵盖扩散主模型、文本编码模型和变分自编码器。UNet 模型负责扩散过程的正向与逆向推理,CLIP 编码器通过文本提示引导图像生成,VAE 则负责在像素与潜空间之间实现高效映射。这三类模型相互配合,实现了从输入图像与提示到高质量融合图像的完整链路。
| 模型名称 | 说明 |
|---|---|
| flux1-dev-kontext_fp8_scaled.safetensors | Flux Kontext 核心 UNet 模型,用于扩散采样过程 |
| t5xxl_fp16.safetensors | 文本提示的 T5 编码器,处理自然语言描述 |
| clip_l.safetensors | CLIP-L 模型,用于文本与图像语义对齐 |
| ae.safetensors | VAE 模型,用于图像与潜变量空间之间的双向映射 |
Node节点
节点设计体现了工作流的模块化特点。图像加载节点将两张输入图导入后由 ImageConcanate 节点拼接形成统一输入,再经缩放与 VAE 编码转化为潜变量表示。文本由 CLIPTextEncode 节点结合 DualCLIPLoader 完成条件编码,并通过 FluxGuidance 调整权重。随机噪声和空潜变量作为初始状态输入 SamplerCustomAdvanced,在调度器和引导器的作用下迭代采样,最终经 VAEDecode 解码生成图像,并由 SaveImage 节点输出结果。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 载入输入的两张图像 |
| ImageConcanate | 将两张图像拼接为单一输入 |
| FluxKontextImageScale | 对图像进行缩放处理以适配模型输入 |
| VAEEncode / VAEDecode | 图像与潜变量空间的双向映射 |
| CLIPTextEncode | 将正向提示语编码为条件向量 |
| FluxGuidance | 设置文本条件的引导强度 |
| RandomNoise | 生成扩散采样所需的随机噪声 |
| SamplerCustomAdvanced | 结合噪声、条件与潜变量执行扩散采样 |
| BasicScheduler / KSamplerSelect | 定义采样调度器与采样方式 |
| SaveImage | 输出最终生成的融合图像 |
工作流程
整个工作流的执行顺序体现了从输入到输出的完整生成链路。首先由 LoadImage 节点载入两张独立图像,通过 ImageConcanate 节点将其拼接形成新的输入基底,再经 FluxKontextImageScale 统一图像尺度。随后图像被 VAEEncode 转换为潜变量表示,并与由 CLIPTextEncode 结合 FluxGuidance 得到的文本条件进行交互。与此同时,RandomNoise 和 EmptySD3LatentImage 提供初始潜变量与噪声输入。核心的 SamplerCustomAdvanced 节点在 BasicScheduler 和 KSamplerSelect 的调度下,融合模型采样、噪声去除和条件引导生成新的潜变量结果,之后经 VAEDecode 转换为图像并最终通过 SaveImage 节点输出成品。整个流程环环相扣,既保持了原始图像特征,又结合了提示语义与采样策略,实现了多模态信息的高效融合。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入准备 | 导入两张图像并拼接为统一输入 | LoadImage、ImageConcanate |
| 2 | 图像预处理 | 对拼接后的图像进行缩放,确保与模型输入匹配 | FluxKontextImageScale |
| 3 | 潜变量生成 | 通过 VAE 将图像映射到潜空间 | VAEEncode |
| 4 | 文本条件处理 | 编码提示语并调整引导强度 | CLIPTextEncode、FluxGuidance |
| 5 | 初始状态构建 | 提供噪声与空潜变量作为采样输入 | RandomNoise、EmptySD3LatentImage |
| 6 | 扩散采样 | 结合噪声、潜变量与文本条件进行迭代采样 | SamplerCustomAdvanced、BasicScheduler、KSamplerSelect |
| 7 | 解码与输出 | 将采样结果解码为图像并保存 | VAEDecode、SaveImage |
大模型应用
CLIPTextEncode 文本语义嵌入生成
在 Flux Kontext 人物与背景图像组合生成工作流中,CLIPTextEncode 节点负责将用户提供的正向 Prompt 转换为 CLIP 嵌入,用于指导生成模型在多图像融合条件下生成最终图像。Prompt 的精细描述直接决定人物特征、姿态、背景风格及整体画面布局,是组合生成的语义核心。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Positive Prompt) | The woman is holding the gun in the photo in the sci-fi hatch background on the right | 将正向 Prompt 转化为 CLIP 嵌入,用于控制图像生成的语义、人物特征和背景布局,使生成结果符合用户预期的视觉效果。 |
FluxGuidance 文本嵌入调控
该节点接收 CLIPTextEncode 输出嵌入,通过 CFG 值调节嵌入在生成模型中的影响力,实现语义强化或柔化。Prompt 在此节点主要体现在嵌入权重调节上,确保人物和背景在组合生成时自然融合,细节丰富。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| FluxGuidance | CFG: 2.5 | 调整 CLIP 嵌入在生成模型中的权重,使人物与背景组合生成保持语义准确、细节丰富和风格一致。 |
使用方法
该工作流用于将人物图像与背景图像自然融合生成完整画面。用户提供人物图像和背景图像,通过 ImageConcanate 节点拼接生成组合图,CLIPTextEncode 将正向 Prompt 转化为嵌入,FluxGuidance 调整嵌入权重后输入 UNET 模型进行潜在空间采样,ModelSamplingFlux 与 SamplerCustomAdvanced 控制采样过程,潜在图像经过 VAELoader 和 VAEDecode 解码为最终图像,由 SaveImage 输出。用户可以通过调整 Prompt、素材图或 CFG 值,控制人物与背景的自然融合效果,实现高质量组合生成。
| 注意点 | 说明 | |
|---|---|---|
| 正向 Prompt 描述清晰 | 确保人物姿态、动作和背景特征符合预期 | |
| 素材图清晰 | 提高组合生成效果自然度 | |
| CFG 值合理 | 控制文本嵌入对生成模型的影响,平衡自由度与语义准确性 | |
| 图像拼接顺序合理 | 避免组合元素覆盖或错位 | |
| 模型兼容性 | 确保 UNET 与 FluxKontext 模型匹配,实现风格统一 |
应用场景
该工作流的应用价值在于能够将多张图像进行语义融合并生成符合文本提示的结果,适合在创意设计、视觉实验和跨媒体内容生成中使用。在概念艺术创作时,可以将不同风格的素材拼接,并通过文本控制生成具有统一叙事的画面。在影视前期设计中,可以利用该流程快速合成多元素场景草图,从而加速方案验证。对于学术研究或艺术实验,该工作流也能作为探索多模态融合与条件生成的工具。通过这种方式,既满足了视觉一致性的需求,也提供了高度可控的生成结果。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 创意设计 | 将多张素材融合为统一画面 | 平面设计师、插画师 | 不同风格的元素组合 | 生成具有连贯性的艺术画面 |
| 影视概念 | 快速形成复杂场景草图 | 影视前期设计师 | 多元素环境与角色构图 | 提供视觉化的创意方案 |
| 跨媒体实验 | 探索文本与图像融合的可能性 | 艺术研究者、实验团队 | 跨模态的视觉实验 | 实现语义与视觉的协同控制 |
| 学术研究 | 测试多模态模型的生成能力 | 研究人员 | 条件引导下的样本对比 | 为模型评估提供实验样例 |
| 内容生成 | 自动化合成多来源图像内容 | 新媒体从业者 | 融合后的图像输出 | 提高创作效率与多样性 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用