Apache Hudi 项目总体分析
请关注微信公众号:阿呆-bot
1. 项目结构
Apache Hudi 采用多模块 Maven 架构,主要模块如下:
hudi-master/
├── hudi-common/ # 核心通用功能模块
│ └── src/main/java/org/apache/hudi/common/
│ ├── model/ # 数据模型(HoodieRecord, HoodieKey等)
│ ├── table/ # 表元数据管理
│ └── timeline/ # 时间线管理
├── hudi-client/ # 客户端实现
│ ├── hudi-client-common/ # 客户端通用基类
│ ├── hudi-spark-client/ # Spark客户端
│ ├── hudi-flink-client/ # Flink客户端
│ └── hudi-java-client/ # Java客户端
├── hudi-spark-datasource/ # Spark数据源集成
│ ├── hudi-spark-common/ # Spark通用功能
│ └── hudi-spark3.5.x/ # Spark 3.5版本实现
├── hudi-flink-datasource/ # Flink数据源集成
│ └── hudi-flink1.20.x/ # Flink 1.20版本实现
├── hudi-utilities/ # 工具类和实用程序
├── hudi-sync/ # 元数据目录同步
│ ├── hudi-hive-sync/ # Hive元数据同步
│ └── hudi-sync-common/ # 同步通用功能
├── hudi-io/ # I/O操作和存储格式
├── hudi-cli/ # 命令行工具
│ └── src/main/java/org/apache/hudi/cli/
│ ├── Main.java # CLI入口类
│ └── HoodieCLI.java # CLI核心类
├── hudi-hadoop-common/ # Hadoop通用功能
├── hudi-hadoop-mr/ # MapReduce支持
├── hudi-kafka-connect/ # Kafka连接器
├── hudi-timeline-service/ # 时间线服务
├── hudi-platform-service/ # 平台服务
├── hudi-examples/ # 示例代码
│ ├── hudi-examples-spark/ # Spark示例
│ └── hudi-examples-flink/ # Flink示例
└── packaging/ # 打包模块
├── hudi-spark-bundle/ # Spark bundle
└── hudi-flink-bundle/ # Flink bundle关键文件说明
-
入口类:
hudi-cli/src/main/java/org/apache/hudi/cli/Main.java- CLI工具入口hudi-client/hudi-spark-client/.../SparkRDDWriteClient.java- Spark写入客户端hudi-client/hudi-flink-client/.../HoodieFlinkWriteClient.java- Flink写入客户端
-
核心类:
hudi-common/.../HoodieTableMetaClient.java- 表元数据客户端hudi-common/.../HoodieTimeline.java- 时间线管理hudi-client/.../BaseHoodieWriteClient.java- 写入客户端基类
2. 技术体系架构
Hudi 采用分层架构设计,从下到上分为存储层、核心层、引擎层和应用层:
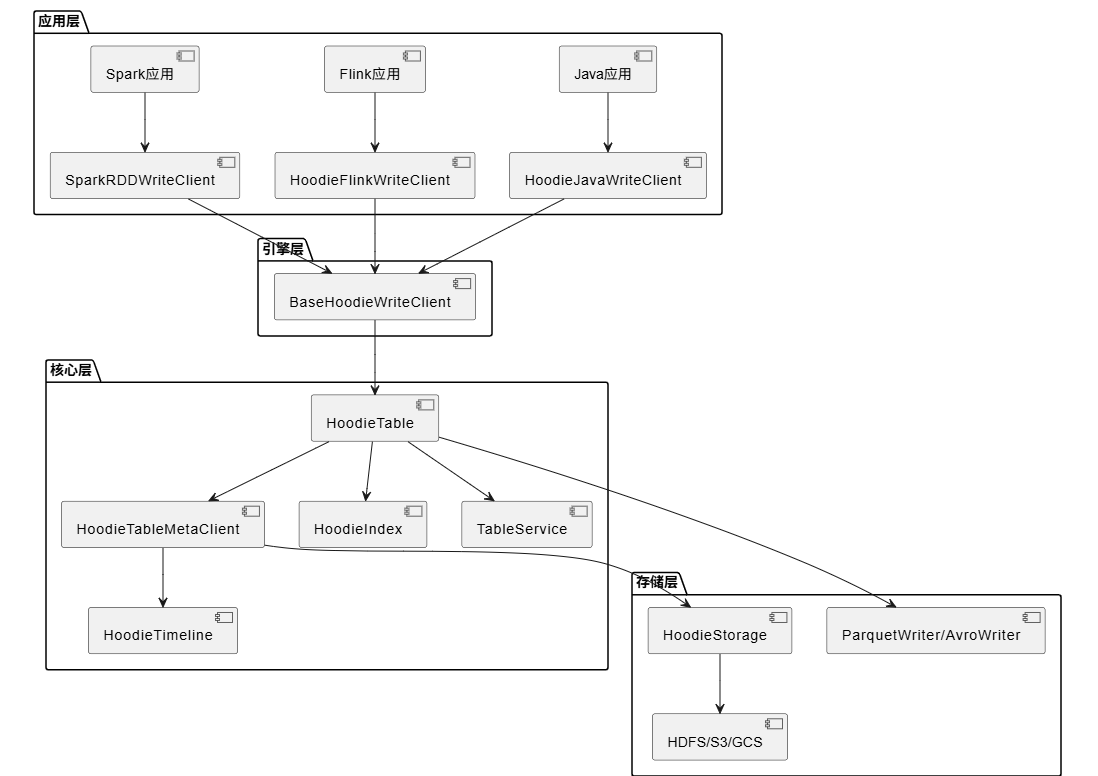
模块间关系
- hudi-common 是核心基础模块,提供数据模型、表元数据、时间线等基础功能
- hudi-client 依赖 hudi-common,提供不同引擎的客户端实现
- hudi-spark-datasource 和 hudi-flink-datasource 分别提供 Spark 和 Flink 的数据源集成
- hudi-sync 负责将 Hudi 表的元数据同步到 Hive、Glue 等元数据目录
- hudi-utilities 提供工具类,如数据导入、清理等
3. 关键场景代码示例
场景1:使用 Spark 写入数据
这是最常用的场景,通过 SparkRDDWriteClient 写入数据到 Hudi 表:
java
// 1. 创建 Spark 上下文
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// 2. 配置 Hudi 写入参数
HoodieWriteConfig cfg = HoodieWriteConfig.newBuilder()
.withPath(tablePath)
.withSchema(schema)
.forTable(tableName)
.withIndexConfig(HoodieIndexConfig.newBuilder()
.withIndexType(HoodieIndex.IndexType.BLOOM).build())
.build();
// 3. 创建写入客户端
SparkRDDWriteClient<HoodieAvroPayload> client =
new SparkRDDWriteClient<>(new HoodieSparkEngineContext(jsc), cfg);
// 4. 开始一个提交
String commitTime = client.startCommit();
// 5. 准备数据并插入
List<HoodieRecord<HoodieAvroPayload>> records = generateRecords();
JavaRDD<HoodieRecord<HoodieAvroPayload>> writeRecords = jsc.parallelize(records);
client.insert(writeRecords, commitTime);
// 6. 更新数据
commitTime = client.startCommit();
List<HoodieRecord<HoodieAvroPayload>> updates = generateUpdates();
writeRecords = jsc.parallelize(updates);
client.upsert(writeRecords, commitTime);场景2:使用 Spark SQL 查询
通过 Spark SQL 直接查询 Hudi 表,非常简单:
scala
// 读取 Hudi 表
val hudiDF = spark.read.format("hudi").load(basePath)
// 查询数据
hudiDF.filter("partition = '2023/01/01'").show()
// 增量查询
val incrementalDF = spark.read.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE.key(), DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME.key(), "20230101000000")
.load(basePath)场景3:表服务操作(压缩、清理)
Hudi 提供了自动化的表服务,比如压缩和清理:
java
// 压缩(Merge-on-Read 表需要)
Option<String> compactionInstant = client.scheduleCompaction(Option.empty());
HoodieWriteMetadata<JavaRDD<WriteStatus>> compactionMetadata =
client.compact(compactionInstant.get());
client.commitCompaction(compactionInstant.get(), compactionMetadata, Option.empty());
// 清理旧文件
client.clean(cleanInstant);4. 入口类和类关系
主要入口类
- HoodieCLI (
hudi-cli) - 命令行工具入口 - SparkRDDWriteClient - Spark 写入客户端
- HoodieFlinkWriteClient - Flink 写入客户端
- HoodieJavaWriteClient - Java 写入客户端
类关系图
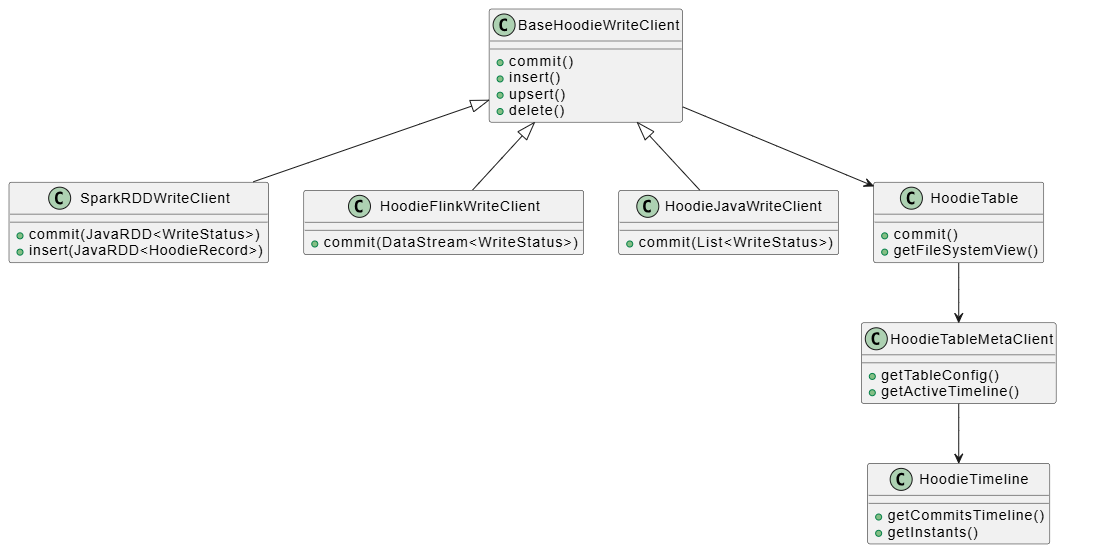
关键类职责
- BaseHoodieWriteClient: 所有写入客户端的基类,定义了通用的写入操作接口
- SparkRDDWriteClient: Spark 引擎的写入客户端,处理 RDD 数据
- HoodieTable: 表的抽象,封装了表的读写操作
- HoodieTableMetaClient: 表元数据管理,负责读取和写入表的元数据
- HoodieTimeline: 时间线管理,记录所有表操作的历史
5. 外部依赖
Hudi 的核心外部依赖包括:
计算引擎
- Apache Spark: 3.3.4, 3.4.3, 3.5.5, 4.0.1 - 主要计算引擎
- Apache Flink: 1.17.1, 1.18.1, 1.19.2, 1.20.1, 2.0.0 - 流处理引擎
存储格式
- Parquet: 1.10.1 - 列式存储格式,用于基础文件
- Avro: 1.11.4 - 行式存储格式,用于增量日志
- ORC: 1.6.0 (Spark), 1.5.6 (Flink) - 列式存储格式
大数据生态
- Hadoop: 2.10.2 - 分布式文件系统支持
- Hive: 2.3.4 - 元数据同步
- Trino: 390 - 查询引擎支持
- Presto: 0.273 - 查询引擎支持
消息队列
- Kafka: 2.0.0 - 流式数据源
- Pulsar: 3.0.2 - 流式数据源
序列化和工具
- Jackson: 2.10.0/2.17.1 - JSON 处理
- Kryo: 4.0.2 - 序列化框架
- RoaringBitmap: 0.9.47 - 位图数据结构
- Caffeine: 2.9.1 - 缓存库
依赖版本选择原因
- Spark/Flink 多版本支持: 为了兼容不同用户环境,支持多个版本
- Parquet/Avro 版本: 与 Hadoop 生态兼容,选择稳定版本
- Java 8 最低支持: 保持向后兼容,支持 Java 8/11/17
6. 工程总结
Apache Hudi 是一个设计精良的数据湖平台,具有以下特点:
架构优势
- 模块化设计: 清晰的模块划分,便于维护和扩展
- 多引擎支持: 同时支持 Spark 和 Flink,满足不同场景需求
- 分层架构: 从存储到应用的分层设计,职责清晰
核心能力
- ACID 事务: 支持原子提交、回滚,保证数据一致性
- 增量处理: 支持增量查询和变更数据捕获,适合实时场景
- 自动表服务: 自动压缩、清理,减少运维成本
- 多种查询类型: 快照查询、增量查询、时间旅行查询等
适用场景
- 实时数据湖: 支持流式写入和实时查询
- 数据仓库: 支持大规模数据存储和查询
- CDC 场景: 支持变更数据捕获和同步
技术亮点
- 时间线机制: 通过时间线管理所有操作历史,支持时间旅行
- 索引系统: 可扩展的索引系统,支持多种索引类型
- 存储优化: 自动管理文件大小和布局,优化查询性能