北航、北大、中关村实验室联合团队在ACL 2025上提出了词汇多样性感知的RAG方法(DRAG),通过细粒度相关性评估和高风险token校准,让RAG在复杂查询场景下性能实现质的飞跃,尤其在HotpotQA数据集上准确率提升10.6%!

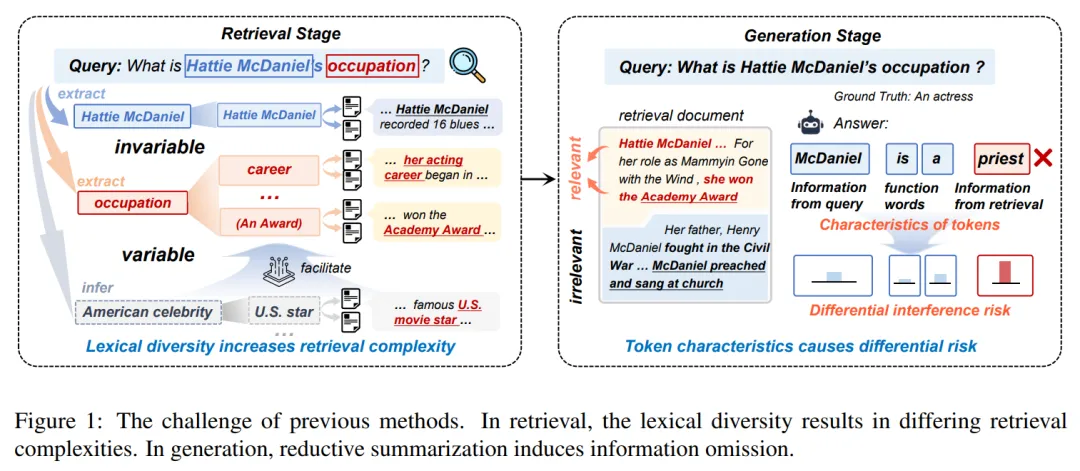
在大语言模型(LLMs)席卷各个领域的今天,检索增强生成(RAG)已成为解决模型事实幻觉、信息过时的核心方案。但你是否发现,当查询表述存在多种词汇变化时,RAG的检索准确性会大幅下降?比如查询"职业"时,文档中可能用"专业""演员"甚至"奥斯卡奖项"等间接表述,传统RAG很难精准匹配这些相关信息。
针对这一痛点,北航、北大、中关村实验室联合团队在ACL 2025上提出了词汇多样性感知的RAG方法(DRAG),通过细粒度相关性评估和高风险token校准,让RAG在复杂查询场景下性能实现质的飞跃,尤其在HotpotQA数据集上准确率提升10.6%!
论文地址:https://aclanthology.org/2025.acl-long.1346.pdf
项目地址:https://github.com/Zhange21/DRAG
01、RAG的核心痛点:被忽视的词汇多样性
RAG的核心逻辑是"检索相关文档+增强生成",但传统方法存在两个关键缺陷:
检索相关性太粗糙
现有RAG大多用单一标准判断文档相关性,忽略了查询中不同成分的词汇多样性差异:
- 固定成分:如专有名词"Hattie McDaniel",表达方式固定,易判断相关性;
- 可变成分:如"occupation"(职业),可表述为"profession""actress"(演员)等,判断难度大;
- 补充成分:如与"Hattie McDaniel的职业"相关的"美国名人",未明确出现在查询中但能辅助检索。
这种差异导致传统RAG要么误判部分相似文档为高相关,要么遗漏表达方式不同的真正相关文档。
生成校准无差别
检索文档中难免混入无关噪声,而不同token受噪声影响程度不同:
- 核心实体token(如职业名称、人名):直接从检索内容提取,易受噪声干扰;
- 辅助token(如连词、代词):受影响极小或无语义价值。
传统方法要么不校准,要么对所有token无差别校准,既影响生成质量又增加计算开销。
02、DRAG的创新方案:双模块破解难题
DRAG通过"多样性敏感相关性分析器(Diversity-Sensitive Relevance Analyzer,DRA) "和"风险引导的稀疏校准(Risk-guided Sparse Calibration,RSC)"两个核心模块,分别解决检索和生成阶段的问题,整体框架如下:
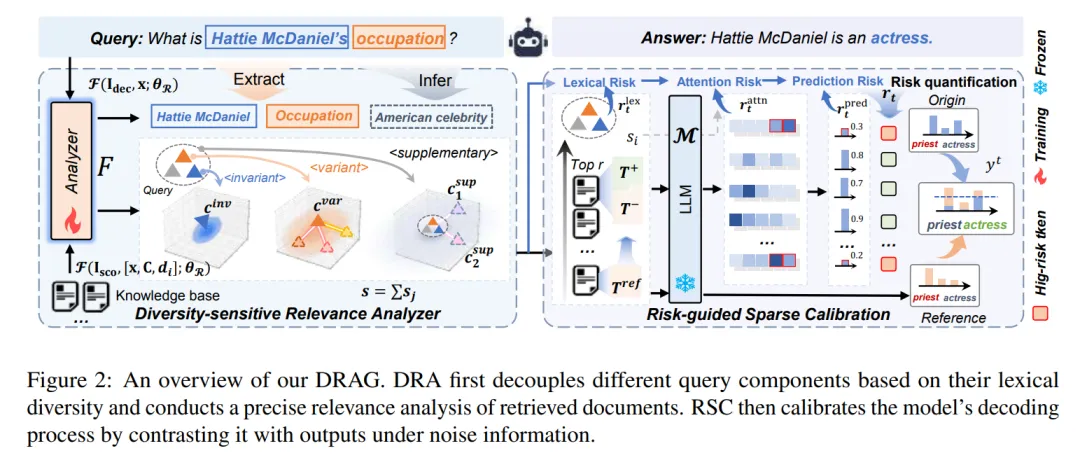
模块1:DRA------让检索懂"词汇差异"
DRA的核心是"按词汇多样性拆分查询,差异化评估相关性",具体分为两步:
1. 查询解耦:三类成分精准划分
将查询拆分为三种属性的成分,适配不同词汇多样性:
- 固定成分(Invariant):无词汇多样性、直接从查询中提取的成分。如"Portland"(地名),表达方式固定,需文档明确提及;
- 可变成分(Variant):具有词汇多样性、直接从查询中提取的成分。如"capital"(首府),可替换为"administrative center"(行政中心);
- 补充成分(Supplementary):未在查询中明确提及,但可通过合理推断补充以辅助相关性评估的成分(非必需),且具有显著词汇多样性。如"州或国家",未明确出现但辅助判断"Portland的首府归属"。
基于上述属性定义,训练DRA模块,将查询分解:
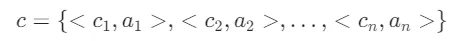
并为每个组件 c_j 分配属性a_j,该过程可表示为:
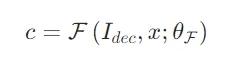
2. 细粒度评估:不同成分不同标准
为精准评估每个成分与检索文档的相关性,进一步针对不同属性的成分制定细粒度评估:
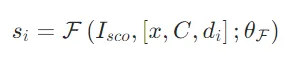
评估标准:
- 固定成分:严格二元评分(1=明确提及,0=未提及);
- 可变/补充成分:灵活连续评分(0-1分,衡量语义关联度);
- 加权求和:在获得各组件得分后,通过加权求和计算文档d_i与查询 x 的整体相关性得分:
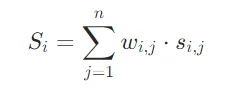
固定成分权重最高(1.0),可变成分(α)和补充成分(β)权重介于0-1之间,最终筛选Top-r高相关文档。3. DRA 模块训练:轻量化适配,数据驱动
基础模型选择:采用小型开源模型 Qwen-0.5B 作为基础模型,避免高额计算开销,适配轻量化部署需求;
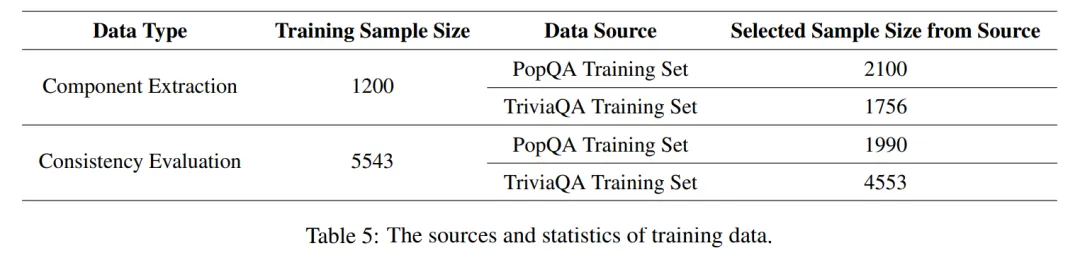
训练数据构建 :两类数据驱动训练 ------① 1200 条查询分解数据 (输入查询 + 指令,输出 "组件 - 属性" 对,基于 GPT-4 生成并人工验证);② 5543 条相关性评估数据(输入查询 + 组件 + 检索文档,输出组件得分及解释,覆盖高 / 中 / 低相关场景);
训练目标与损失:以 "精准拆分组件" 和 "准确评估相关性" 为目标,采用交叉熵损失进行监督微调,确保模块能稳定识别不同词汇多样性的查询组件,并输出合理评分。
模块2:RSC------精准校准高风险token
为解决检索文档中无关信息对预测生成token的差异化干扰问题,RSC通过"无关风险"量化无关噪声对每个生成token的影响,并对高风险token的解码过程进行稀疏调整------在减轻细粒度噪声干扰的同时,保持极低的计算开销。
1. 无关风险量化:三维度综合判断
计算每个生成token的"无关风险",识别高风险token,具体分为以下三个维度:
- 词汇风险:查询成分多样性越高,风险越大
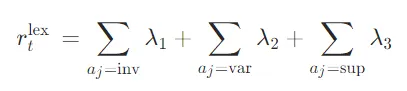
- 注意力风险:对低相关文档的注意力占比越高,风险越大
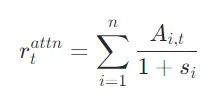
- 预测风险:模型生成置信度越低,风险越大
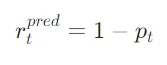
最终,通过融合上述三个维度,得到tokenyty_tyt的综合无关风险:
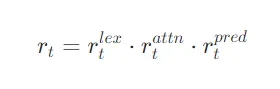
2. 稀疏校准:只改该改的token
基于量化的无关风险,RSC通过将高风险token的输出分布与"无关文本条件下的生成分布"对比,对高风险token进行稀疏校正,从而减轻噪声干扰。
- 构建参考噪声:选取DRA评估的最低相关文档,模拟真实无关噪声
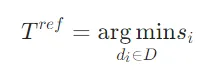
- 阈值筛选:仅对风险≥δ的高风险token进行校准
- 分布调整:用噪声文档的生成分布校正高风险token的解码过程,抵消无关干扰
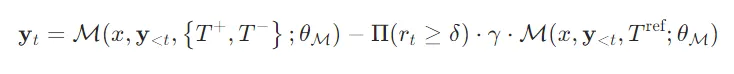
DRAG完整推理流程
- 检索阶段:DRA拆分查询成分→差异化评估文档相关性→筛选Top-r相关文档+最低相关噪声文档;
- 生成阶段:逐token计算无关风险→高风险token用噪声文档校准→低风险token直接生成→输出最终结果。

03、实验结果:多任务全面领先
DRAG在短文本生成、长文本生成、多跳问答三大任务中,均显著优于传统RAG方法:
主要结果:全任务显著领先,性能突破明显
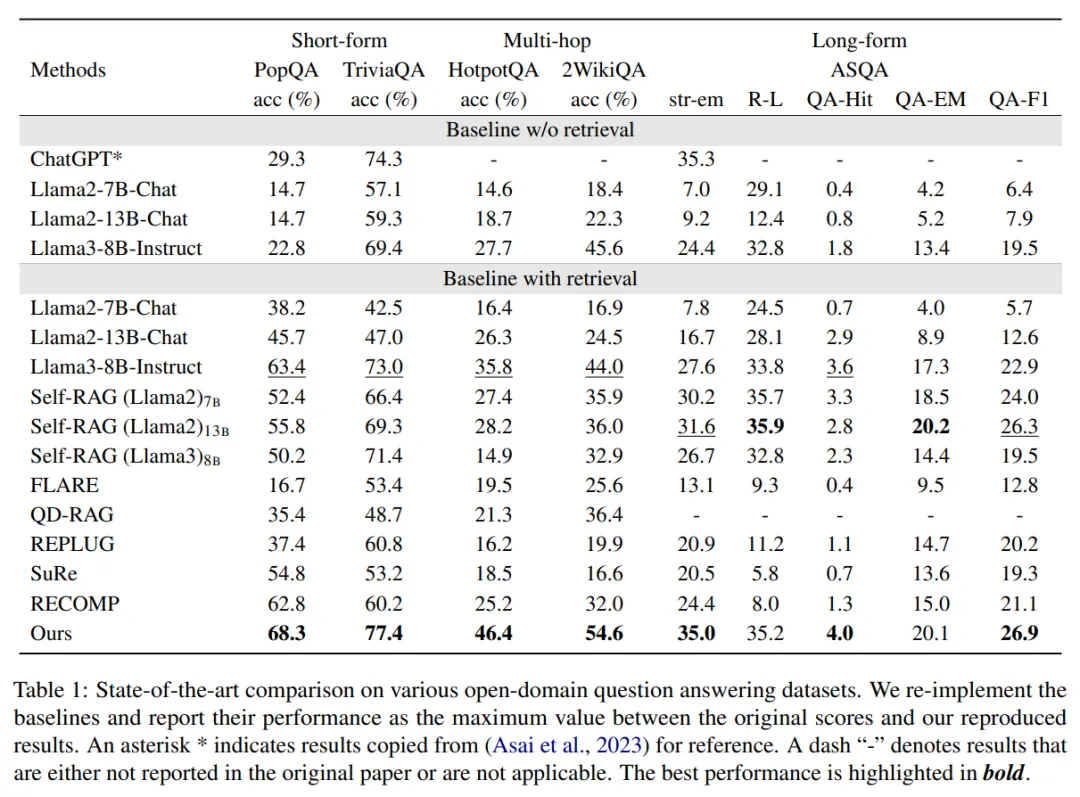
实验结果显示,DRAG在所有任务中均表现出优于基准方法的性能,尤其在多跳问答和短文本生成任务中实现大幅提升,具体如下:
vs 无检索基准:检索增强价值凸显
DRAG通过引入外部检索与精细化处理,显著超越了仅依赖参数知识的LLM:
- 在PopQA数据集上,DRAG准确率达到68.3%,较无检索的Llama3-8B-Instruct(22.8%)提升45.5%,充分证明了"精准检索+有效利用"的核心价值;
- 在TriviaQA数据集上,DRAG准确率77.4%,较无检索基准(69.4%)提升8%,即使是本身事实性较强的LLM,也能通过DRAG进一步弥补知识缺口与表达差异带来的误差;
- 多跳任务中,HotpotQA准确率从27.7%提升至46.4%,2WikiMultiHopQA从45.6%提升至54.6%,验证了DRAG在复杂推理场景下的检索增强能力。
vs 有检索基准与先进RAG方法:精细化处理见效
与传统RAG及先进方案相比,DRAG的词汇多样性感知机制带来了显著优势:
- 短文本生成任务 :
PopQA数据集:DRAG准确率68.3%,较次优的RECOMP(62.8%)提升4.9%;
TriviaQA数据集:DRAG准确率77.4%,较次优的Llama3-8B-Instruct(73.0%)提升4.4%;
关键原因:DRA模块通过差异化评估,避免了"同义表达文档被遗漏""部分相似文档误判"的问题,从源头提升了检索质量,案例对比如下:

- 多跳问答任务 :
HotpotQA与2WikiMultiHopQA数据集上,DRAG准确率均提升10.6%,是所有对比方法中提升最显著的;
核心优势:多跳任务的查询成分更复杂,词汇多样性带来的检索难度更高,DRAG的细粒度组件分解与相关性评估能精准串联多步推理所需的文档,而传统RAG往往因单一评估标准遗漏关键中间文档。 - 长文本生成任务 :
ASQA数据集上,DRAG的str-em指标达到35.0(最优),QA-Hit、QA-F1分别为35.2、26.9,均优于其他对比方法;
虽在QA-EM(4.0)上略有差距,但整体综合性能领先,证明DRAG在长文本生成中既能保证信息全面性,又能维持与标准答案的语义对齐,避免因词汇表达差异导致的信息偏差。
消融实验:拆解核心模块,验证关键贡献
为明确DRA(多样性敏感相关性分析器)与RSC(风险引导的稀疏校准)的具体作用,团队进行了模块消融与超参数敏感性分析,结果如下:
模块消融:双模块协同发力,缺一不可
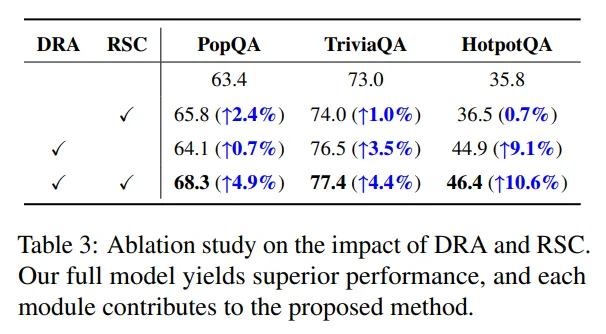
- 仅DRA模块:HotpotQA准确率提升3.1%,证明差异化相关性评估能有效筛选高相关文档,解决"检索不准"问题;
- 仅RSC模块:PopQA准确率提升0.7%,HotpotQA提升9.1%,说明风险校准能有效抵消无关噪声干扰,尤其在多跳任务中,噪声对核心推理的影响更显著,RSC的作用更突出;
- 双模块结合:性能实现"1+1>2"的提升,证明DRA的"精准检索"与RSC的"精准校准"形成协同,从检索到生成全流程优化,是DRAG性能领先的核心原因。
超参数敏感性:关键参数影响规律明确
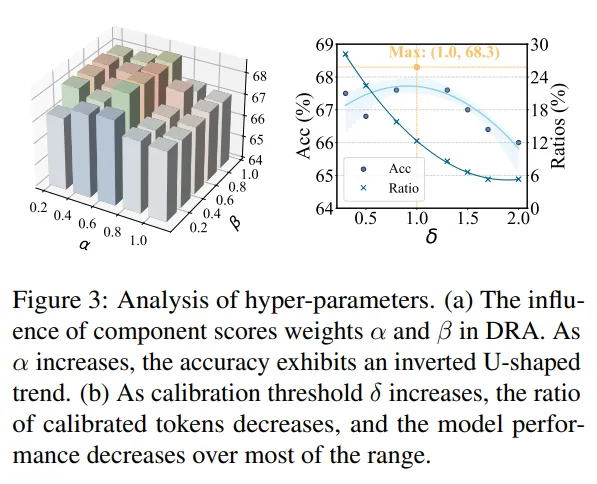
- DRA模块的组件权重(α、β) :
α(可变组件权重):对性能影响更显著,随着α增大,模型准确率呈"倒U型"趋势------α过小会忽视可变组件的词汇多样性,α过大则会引入过多噪声;
β(补充组件权重):影响相对温和,因补充组件是非必需的辅助信息,过度加权反而会稀释核心组件的相关性信号;
最优取值:α=0.8,β=0.5,既充分重视可变组件的表达差异,又不过度依赖补充组件。 - RSC模块的校正阈值(δ) :
随着δ增大,被校准的高风险token比例逐渐减少,模型性能整体呈下降趋势;
δ较小时(如δ=0.3),校准覆盖的token过多,可能误校正低风险token,导致生成流畅度下降;
δ较大时(如δ=0.7),仅校准极少数token,无法充分抵消噪声干扰;
最优取值:δ=0.5,能精准覆盖"真正受噪声影响的高风险token",在去噪与流畅度之间达到平衡。
深度分析:计算开销与模型兼容性双优
生成阶段计算开销:稀疏校准高效节能
对比DRAG与其他解码优化类RAG方法(如CAD)、全token校准策略的计算开销:
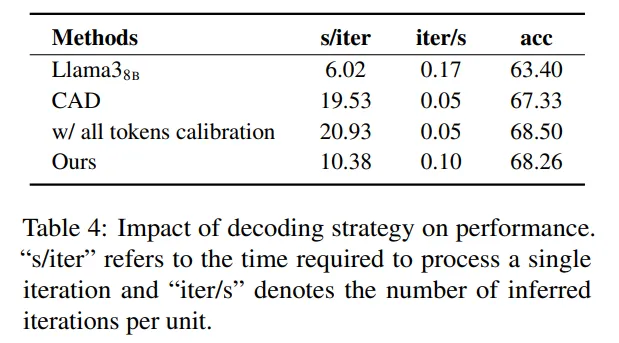
结果显示,所提方法在生成阶段引入的计算开销远低于其他基于解码的 RAG 方法,且与基础模型相比,计算开销仅略有增加,但性能提升显著。
不同大语言模型的兼容性:泛化能力强
在Llama2-7B-Chat、Llama2-13B-Chat、Llama3-8B-Instruct、Alpaca-7B、Mistral-7B等5种主流开源模型上验证DRAG的适配性:
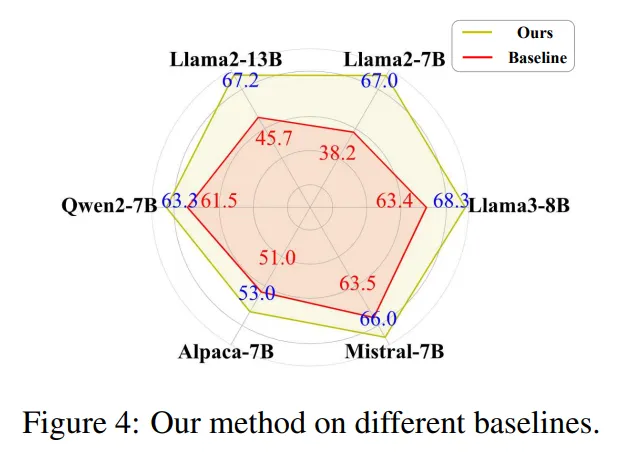
- DRAG在所有测试模型上均实现性能提升,无明显兼容性问题;
- 对基础性能较弱的模型提升更显著:如Llama2-7B-Chat的准确率从38.2%提升至67.0%,提升幅度达28.8%;
- 对高性能模型仍有稳定提升:Llama3-8B-Instruct从63.4%提升至68.3%,证明DRAG的核心机制(词汇多样性感知+稀疏校准)能有效弥补不同模型在"文档相关性评估"与"噪声抵抗"方面的共性短板。
04、总结
DRAG(Lexical Diversity-aware RAG)的核心突破,在于跳出传统RAG"单一标准检索+无差别生成"的局限,针对性解决"查询词汇多样性"这一关键痛点------通过DRA(多样性敏感相关性分析器) 聚焦检索侧优化,按查询组件的词汇多样性属性(固定/可变/补充)制定差异化评估标准,精准筛选出真正相关的文档,从源头避免因表达差异导致的"漏检"或"误检";再通过RSC(风险引导的稀疏校准) 聚焦生成侧优化,量化每个token的无关风险,仅对受噪声干扰的高风险token进行校准,在保证生成准确性的同时控制计算开销。这种"检索-生成"全流程的协同优化思路,为RAG性能提升提供了更贴合真实查询场景的新方向。
落地思考
从落地价值来看,DRAG具备"轻量化"与"场景适配灵活性"的双重优势:一方面,其核心的DRA模块仅需基于Qwen-0.5B等小型开源模型,用6743条训练数据即可完成微调,无需大规模算力支撑,轻量化特性显著;另一方面,项目已完全开源,开发者可直接基于现有框架快速部署,或结合自身场景二次开发------尤其适合需要提升复杂查询下RAG检索精度的技术团队,即使是资源有限的场景也能高效落地。
需特别注意的是,DRAG的两大模块在场景适配性上存在差异:
- DRA模块(检索侧):适配范围更广,无论是开源模型还是闭源模型场景,均能借鉴其"按词汇多样性拆分查询、差异化评估文档"的核心思路------例如在调用闭源模型API时,可先通过独立部署的DRA模块预处理检索文档,筛选出高相关内容后再输入闭源模型,间接提升检索增强效果;
- RSC模块(生成侧):受限于技术依赖,仅能适配开源模型------其风险量化(如注意力风险需获取模型对文档的注意力分数、预测风险需获取token的预测概率)依赖模型底层输出,而闭源模型通常不对外开放此类信息,因此无法直接应用,仅能在开源模型生态中发挥生成侧优化价值。
使用场景
从适用场景来看,DRAG在"检索精准度优先"的任务中表现突出,具体可覆盖三类核心场景:
- 开放域问答:如百科知识查询、事实性问答(如"某人物的职业""某事件的时间"),DRA能精准处理查询中专有名词、同义表达等词汇差异,避免传统RAG的检索偏差;若基于开源模型,还可搭配RSC进一步降低生成噪声,提升答案准确性;
- 多跳问答:需串联多个文档信息的复杂推理任务(如 "某电影导演的母亲是谁"),DRA 可拆分查询中的多步推理组件,精准匹配所需的相关文档,RSC 则保障核心推理 token 不受无关信息干扰;
- 垂直领域应用:如法律条款检索(需匹配"合同纠纷""违约责任"等专业术语的多样表述)、医疗知识问答(需关联"病症-症状-治疗方案"的语义关联),此类场景中,DRA的"组件拆分+差异化评估"思路可直接复用(需补充领域专属训练数据适配专业词汇);若采用开源模型构建专属系统,RSC还能进一步优化专业内容的生成质量,避免无关信息干扰核心结论。
对于多跳问答的进一步思考
DRA本质是"一轮检索+多成分并行评估",核心解决"单步检索的词汇多样性偏差",无法独立完成多跳任务的逻辑串联。因此,在多跳场景中,可将DRA作为"检索增强插件"融入多轮推理框架:由多轮框架负责拆分查询、串联推理逻辑(如生成子查询、验证中间结果),DRA则为每一步子查询优化检索精度,确保每轮推理都能获取高质量文档;若基于开源模型,再搭配RSC校准每一步的生成风险,理论上可同时提升多跳任务的"检索准确性"与"推理连贯性"。而在闭源模型场景下,即使无法应用RSC,仅通过DRA优化检索环节,也能为多轮推理提供更可靠的信息支撑,间接改善多跳问答效果。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。