Spring Ai Alibaba快速入门
文章目录
- [Spring Ai Alibaba快速入门](#Spring Ai Alibaba快速入门)
-
- 一:理论部分
-
- 1:何为SSA
- [2:hello SSA](#2:hello SSA)
- 二:chatModel和chatClient
- 三:格式化输出
- 四:记忆化搜索
- 五:文生图,文生音
- 六:向量数据库和RAG
-
- 1:什么是向量化
- 2:嵌入(embedding)
- 3:向量相似度计算
- 4:向量数据库
- 5:RAG
-
- 5.1:什么是RAG
- 5.2:RAG的核心工作流程
- [5.3:SAA + redis stack + RAG](#5.3:SAA + redis stack + RAG)
- [七:tool calling 和 MCP](#七:tool calling 和 MCP)
-
- [1:tool calling](#1:tool calling)
- 2:MCP
笔记整理自尚硅谷周阳老师的Spring AI Alibaba视频课和Deepseek
一:理论部分
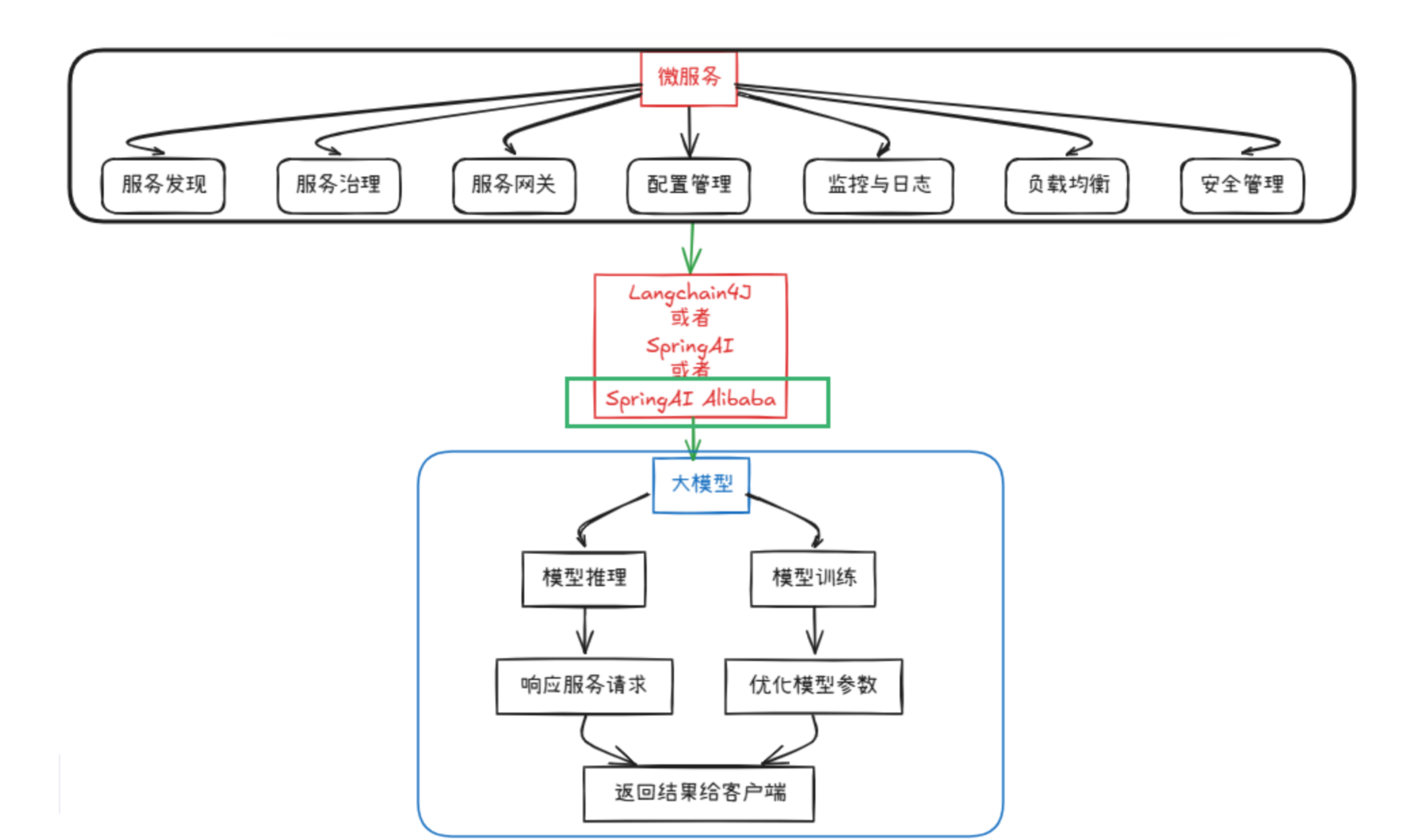
1:何为SSA
1.1:概述SSA
Spring AI Alibaba 是一款以Spring AI为基础,深度集成百炼平台,支持chatbot、工作流、多智能体开发模式的AI框架
Spring AI Alibaba 开源项目基于 Spring AI 构建,是阿里云通义系列模型及服务在 Java AI 应用开发领域的最佳实践,提供高层次的 AI API 抽象与云原生基础设施集成方案和企业级 AI 应用生态集成。
Spring AI Alibaba 基于 Spring AI 构建,因此SAA继承了SpringAI 的所有原子能力抽象并在此基础上扩充丰富了模型、向量存储、记忆、RAG 等核心组件适配,让其能够接入阿里云的 AI 生态。
1.2:阿里巴巴百炼平台
先注册或者登录阿里云
在搜索框搜索 阿里云百炼,进入百炼控制台,进入模型服务之后,点击进入秘钥管理
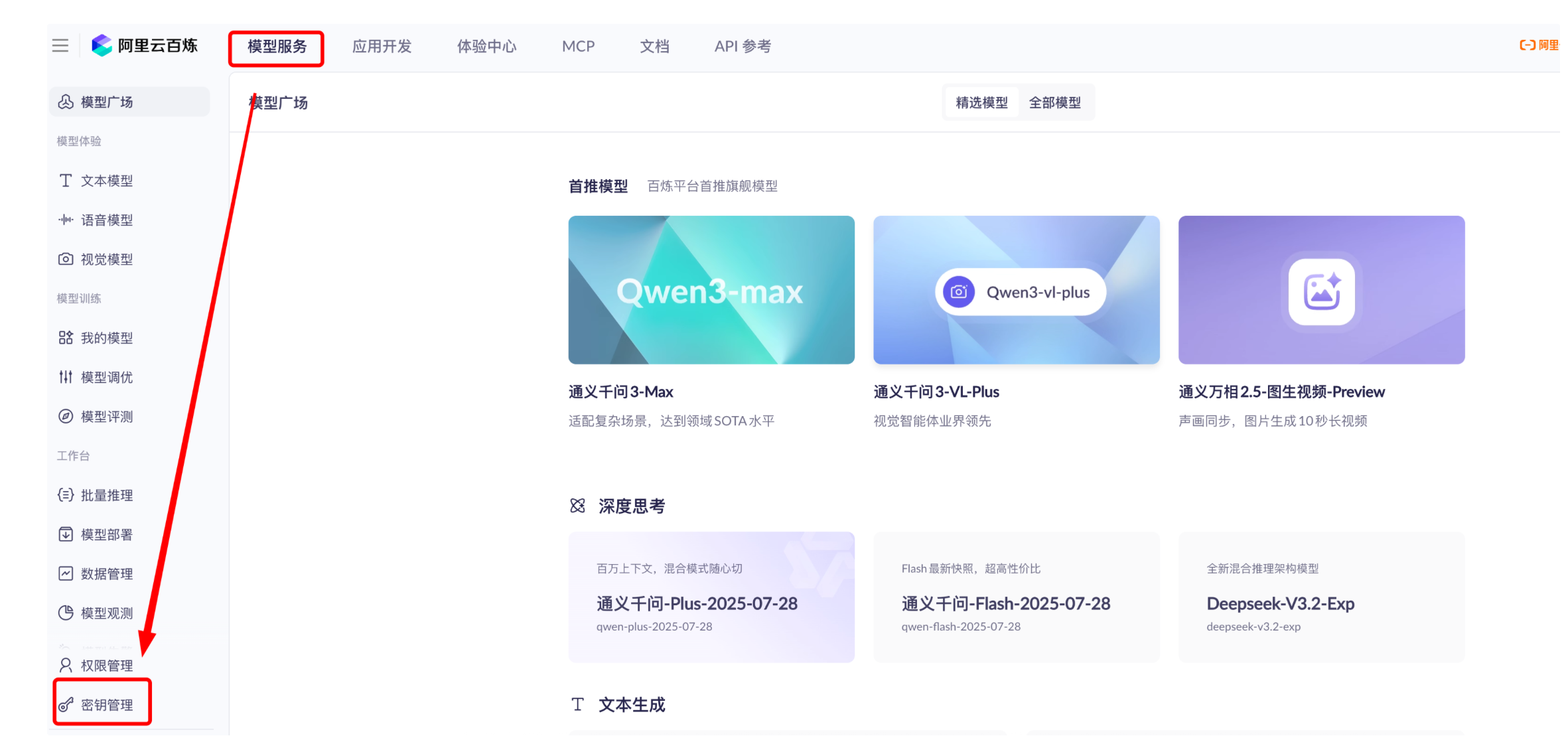
创建你专属的API key,创建之后复制这个API key,后面要用

2:hello SSA
2.1:环境要求和依赖要求
环境要求:JDK17+, Maven3.8+, 有自己的API key
xml
<!-- 在原有的依赖中添加saa和百炼的依赖 -->
<dependencies>
<!-- Spring AI Alibaba Agent Framework -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-agent-framework</artifactId>
<version>1.1.0.0-M4</version>
</dependency>
<!-- DashScope ChatModel 支持(如果使用其他模型,请参考文档选择对应的 starter) -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0-M4</version>
</dependency>
</dependencies>2.2:配置说明
APIkey建议写在配置文件或者环境变量中,最好不要硬编码
yaml
server:
port: 8001 # 服务器端口配置
servlet:
encoding:
enabled: true # 启用编码过滤器
force: true # 强制使用指定编码
charset: UTF-8 # 设置字符编码为UTF-8
spring:
application:
name: ssa-hello-service # 应用服务名称
ai:
dashscope:
api-key: sk-??? # DashScope API密钥
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 # DashScope基础URL
chat:
options:
model: deepseek-v3 # 指定聊天模型2.3:配置类
用于构建DashScopeApi
java
package com.cui.config;
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SaaLLMConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
/**
* 创建DashScopeApi实例
*
* @return DashScopeApi实例
*/
@Bean
public DashScopeApi dashScopeApi() {
return DashScopeApi.builder().apiKey(apiKey).build();
}
}2.4:使用示例
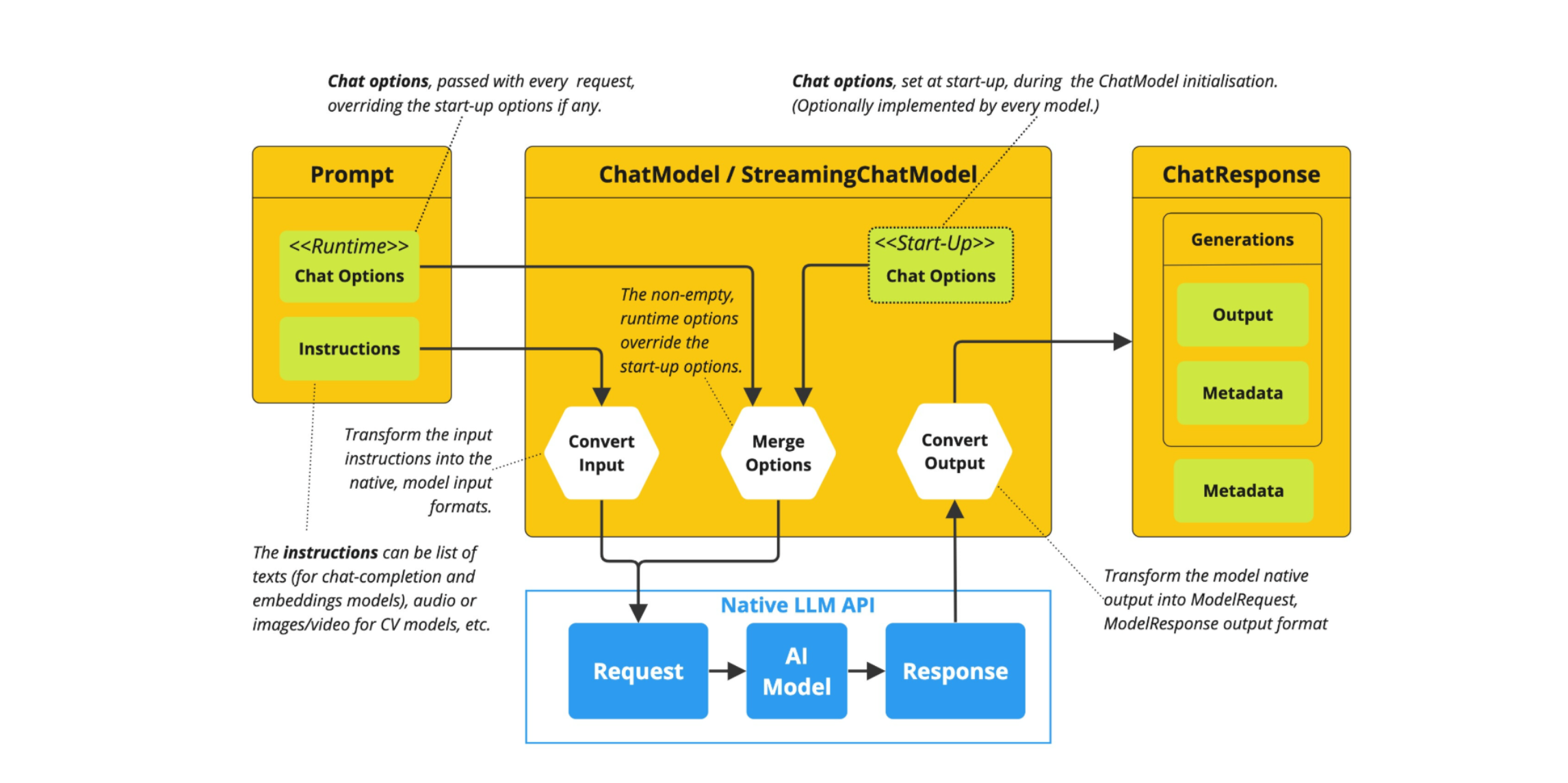
前置知识 - Flux和ChatModel
对话模型(Chat Model)接收一系列消息(Message)作为输入,与模型 LLM 服务进行交互,并接收返回的聊天消息(Chat Message)作为输出。相比于普通的程序输入,模型的输入与输出消息(Message)不止支持纯字符文本,还支持包括语音、图片、视频等作为输入输出。同时,在 Spring AI Alibaba 中,消息中还支持包含不同的角色,帮助底层模型区分来自模型、用户和系统指令等的不同消息。
Spring AI Alibaba 复用了 Spring AI 抽象的 Model API,并与通义系列大模型服务进行适配(如通义千问、通义万相等),目前支持纯文本聊天、文生图、文生语音、语音转文本等。以下是框架定义的几个核心 API:
- ChatModel,文本聊天交互模型,支持纯文本格式作为输入,并将模型的输出以格式化文本形式返回。
- ImageModel,接收用户文本输入,并将模型生成的图片作为输出返回。
- AudioModel,接收用户文本输入,并将模型合成的语音作为输出返回。
ChatModel API 让应用开发者可以非常方便的与 AI 模型进行文本交互,它抽象了应用与模型交互的过程,包括使用 Prompt 作为输入,使用 ChatResponse 作为输出等。ChatModel 的工作原理是接收 Prompt 或部分对话作为输入,将输入发送给后端大模型,模型根据其训练数据和对自然语言的理解生成对话响应,应用程序可以将响应呈现给用户或用于进一步处理。
java
package com.cui.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class HelloController {
@Resource
private ChatModel chatModel;
@GetMapping("/chat")
public String doChat(@RequestParam(name="msg", defaultValue = "你是谁?") String msg) {
return chatModel.call(msg);
}
@GetMapping("/stream")
public Flux doStreamChat(@RequestParam(name="msg", defaultValue = "你是谁?") String msg) {
return chatModel.stream(msg);
}
}
二:chatModel和chatClient
1:官方原话
ChatClient 提供了与 AI 模型通信的 Fluent API,它支持同步和反应式(Reactive)编程模型。
与 ChatModel、Message、ChatMemory 等原子 API 相比,使用 ChatClient 可以将与 LLM 及其他组件交互的复杂性隐藏在背后,因为基于 LLM 的应用程序通常要多个组件协同工作(例如,提示词模板、聊天记忆、LLM Model、输出解析器、RAG 组件:嵌入模型和存储),并且通常涉及多个交互,因此协调它们会让编码变得繁琐。
当然使用 ChatModel 等原子 API 可以为应用程序带来更多的灵活性,成本就是您需要编写大量样板代码。
ChatClient 类似于应用程序开发中的服务层,它为应用程序直接提供 AI 服务,开发者可以使用 ChatClient Fluent API 快速完成一整套 AI 交互流程的组装。
包括一些基础功能,如:
- 定制和组装模型的输入(Prompt)
- 格式化解析模型的输出(Structured Output)
- 调整模型交互参数(ChatOptions)
还支持更多高级功能:
- 聊天记忆(Chat Memory)
- 工具/函数调用(Function Calling)
- RAG
2:核心概括
ChatModel:模型交互层。它代表了对大模型服务(如通义千问)的直接调用,是更底层、更核心的抽象。你用它来发送消息并接收模型的原始响应。
ChatClient:应用构建层。它是一个更高级的、流畅的 API,构建在 ChatModel 之上,旨在简化常见交互模式(如问答、连续对话),并集成 Spring 生态的特性(如函数调用、提示词模板)。
可以把它们的关系理解为:ChatClient 是 ChatModel 的"语法糖"和增强器。
| 特性 | ChatModel | ChatClient |
|---|---|---|
| 抽象层次 | 底层抽象,直接对应模型 API。 | 高层抽象,面向应用开发。 |
| 核心接口 | ChatResponse call(ChatRequest request) String call(String message) |
ChatClient prompt() 返回 PromptCallback |
| 编程模型 | 直接的、命令式的方法调用。 | 流畅接口/DSL,支持链式调用。 |
| 主要用途 | 需要精细控制 请求参数。 直接处理模型的原始响应。 框架底层扩展或集成。 | 快速实现 标准的聊天交互。 使用提示词模板 。 方便的流式响应 。 集成 Spring AI 函数调用。 |
| 易用性 | 相对繁琐,需要手动构建请求对象。 | 非常便捷,几行代码即可完成交互。 |
| 灵活性 | 高,可以访问所有底层选项。 | 中,覆盖大部分常见场景,但对极端特殊配置不友好。 |
| Spring 集成 | 基础 Bean,是 Spring AI 功能的基石。 | 深度集成,无缝使用 ApplicationContext 中的 Bean(如函数调用)。 |
3:前置知识整合
3.1:SSE
3.1.1:流式输出
流式输出(StreamingOutput)
是一种逐步返回大模型生成结果的技术,生成一点返回一点,允许服务器将响应内容
分批次实时传输给客户端,而不是等待全部内容生成完毕后再一次性返回。
这种机制能显著提升用户体验,尤其适用于大模型响应较慢的场景(如生成长文本或复杂推理结果)
3.1.2:SSE和WebSocket
SSE是一种允许服务器主动向客户端推送数据的 Web 技术。
SSE基于标准的 HTTP 协议,因此不需要特殊的协议升级。
- 单向通信:数据流主要是从服务器到客户端。客户端无法通过 SSE 通道向服务器发送数据(除了最初的请求)。
- 基于 HTTP :它完全建立在 HTTP 之上,使用简单的文本格式(通常是
text/event-stream)。这使得它易于理解和调试,并且能天然地绕过很多防火墙和代理的限制。 - 自动重连:SSE 协议内置了重连机制。如果连接断开,浏览器会自动尝试重新连接。
- 轻量级:协议简单,开销小,特别适合用于需要服务器持续更新的场景。
| 特性 | Server-Sent Events | WebSocket |
|---|---|---|
| 通信模式 | 单向 (Server -> Client) | 双向 (Server <-> Client) |
| 协议基础 | HTTP | 独立的 WebSocket 协议 (基于 TCP) |
| 协议开销 | 较低 (每次消息只有 data: 等前缀) |
极低 (有轻量级的帧结构) |
| 使用复杂度 | 非常简单,使用标准 HTTP,客户端 API 直观 | 相对复杂,需要处理协议升级、双向消息管理 |
| 自动重连 | 内置支持 | 需要手动实现 |
| 数据传输格式 | 只能是 文本 (通常使用 JSON) | 文本和二进制数据 |
| 浏览器兼容性 | 良好 (除 IE 外) | 优秀 (包括 IE 10+) |
| 适用场景 | 实时通知、新闻推送、股票行情、日志流、状态更新 | 聊天应用、多人游戏、实时协作编辑、远程控制 |
选择 SSE 当:
- 你的应用场景主要是服务器向客户端推送数据。
- 不需要客户端频繁地向服务器发送数据。
- 你希望实现简单、快速,并且能利用现有的 HTTP 认证和基础设施。
- 典型的例子:
- 社交媒体:在新帖子出现时推送。
- 监控仪表盘:实时更新 CPU 使用率、在线用户数等指标。
- 新闻网站:在重大新闻发生时主动推送给用户。
选择 WebSocket 当:
- 你需要一个真正的、持续的双向对话。
- 客户端也需要频繁地向服务器发送消息。
- 低延迟和高效传输(尤其是二进制数据)至关重要。
- 典型的例子:
- 聊天应用:用户之间实时发送和接收消息。
- 多人在线游戏:玩家动作需要实时同步。
- 协同编辑工具(如 Google Docs):多个用户同时编辑一个文档。
java
package com.example.sse.controller;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import java.io.IOException;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@RestController
@CrossOrigin(origins = "*") // 允许跨域
@RequestMapping("/sse")
public class SseController {
// 存储所有活跃的 SSE 连接
private final CopyOnWriteArrayList<SseEmitter> emitters = new CopyOnWriteArrayList<>();
private final ExecutorService executor = Executors.newCachedThreadPool();
/**
* 客户端连接 SSE 端点
*/
@GetMapping(value = "/connect", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter connect() {
// 设置连接超时时间(0表示永不超时)
SseEmitter emitter = new SseEmitter(0L);
// 将新的连接添加到列表
emitters.add(emitter);
// 设置连接完成和超时的回调
emitter.onCompletion(() -> {
System.out.println("SSE 连接完成");
emitters.remove(emitter);
});
emitter.onTimeout(() -> {
System.out.println("SSE 连接超时");
emitters.remove(emitter);
});
emitter.onError((e) -> {
System.out.println("SSE 连接错误: " + e.getMessage());
emitters.remove(emitter);
});
// 发送欢迎消息
try {
SseEmitter.SseEventBuilder event = SseEmitter.event()
.name("welcome") // 事件名称
.data("连接成功!欢迎使用 SSE 服务。")
.reconnectTime(5000); // 重连时间
emitter.send(event);
} catch (IOException e) {
emitter.completeWithError(e);
}
System.out.println("新的 SSE 连接建立,当前连接数: " + emitters.size());
return emitter;
}
/**
* 向所有客户端广播消息
*/
@PostMapping("/broadcast")
public String broadcast(@RequestParam String message) {
broadcastToAllClients(message);
return "消息已广播: " + message;
}
/**
* 模拟服务器推送定时消息
*/
@PostMapping("/start-timer")
public String startTimer() {
executor.execute(() -> {
try {
for (int i = 1; i <= 10; i++) {
String timerMsg = "定时消息 #" + i + " - 时间: " + java.time.LocalTime.now();
broadcastToAllClients(timerMsg);
Thread.sleep(2000); // 每2秒发送一次
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
return "定时消息已启动";
}
/**
* 向所有连接的客户端广播消息
*/
private void broadcastToAllClients(String message) {
// 记录要移除的失效连接
CopyOnWriteArrayList<SseEmitter> deadEmitters = new CopyOnWriteArrayList<>();
// 向所有活跃连接发送消息
emitters.forEach(emitter -> {
try {
SseEmitter.SseEventBuilder event = SseEmitter.event()
.data(message)
.id(String.valueOf(System.currentTimeMillis())) // 事件ID
.name("message") // 事件类型
.reconnectTime(5000);
emitter.send(event);
System.out.println("消息已发送: " + message);
} catch (IOException e) {
// 发送失败,标记为失效连接
deadEmitters.add(emitter);
System.out.println("发送消息失败,连接已关闭: " + e.getMessage());
}
});
// 清理失效连接
emitters.removeAll(deadEmitters);
deadEmitters.forEach(emitter -> {
emitter.complete();
System.out.println("失效连接已清理");
});
}
/**
* 获取当前连接数
*/
@GetMapping("/stats")
public String getStats() {
return "当前活跃连接数: " + emitters.size();
}
}
html
<script>
class SSEClient {
constructor() {
this.eventSource = null;
this.isConnected = false;
this.reconnectAttempts = 0;
this.maxReconnectAttempts = 5;
}
// 连接 SSE
connect() {
if (this.isConnected) {
this.addMessage('⚠️ 已经连接到服务器', 'system');
return;
}
try {
// 创建 EventSource 连接
this.eventSource = new EventSource('http://localhost:8080/sse/connect');
// 监听通用消息
this.eventSource.onmessage = (event) => {
this.addMessage(`📨 消息: ${event.data}`, 'message');
};
// 监听特定事件类型的消息
this.eventSource.addEventListener('welcome', (event) => {
this.addMessage(`🎉 ${event.data}`, 'system');
});
this.eventSource.addEventListener('message', (event) => {
this.addMessage(`📢 ${event.data}`, 'message');
});
// 连接打开
this.eventSource.onopen = (event) => {
this.isConnected = true;
this.reconnectAttempts = 0;
this.updateUI();
this.addMessage('✅ SSE 连接已建立', 'system');
};
// 连接错误
this.eventSource.onerror = (event) => {
this.addMessage('❌ SSE 连接错误', 'error');
// 如果连接关闭,尝试重连
if (this.eventSource.readyState === EventSource.CLOSED) {
this.handleReconnection();
}
};
} catch (error) {
this.addMessage(`❌ 连接失败: ${error.message}`, 'error');
}
}
// 处理重连逻辑
handleReconnection() {
if (this.reconnectAttempts < this.maxReconnectAttempts) {
this.reconnectAttempts++;
this.addMessage(`🔄 尝试重新连接 (${this.reconnectAttempts}/${this.maxReconnectAttempts})...`, 'system');
setTimeout(() => {
this.disconnect();
this.connect();
}, 3000);
} else {
this.addMessage('💥 重连次数已达上限,请手动重新连接', 'error');
}
}
// 断开连接
disconnect() {
if (this.eventSource) {
this.eventSource.close();
this.eventSource = null;
}
this.isConnected = false;
this.updateUI();
this.addMessage('🔴 SSE 连接已断开', 'system');
}
// 广播消息到服务器
async broadcastMessage(message) {
if (!this.isConnected) {
this.addMessage('⚠️ 请先建立连接', 'error');
return;
}
try {
const response = await fetch('http://localhost:8080/sse/broadcast', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
body: `message=${encodeURIComponent(message)}`
});
const result = await response.text();
this.addMessage(`📤 ${result}`, 'system');
} catch (error) {
this.addMessage(`❌ 发送消息失败: ${error.message}`, 'error');
}
}
// 启动定时消息
async startTimer() {
try {
const response = await fetch('http://localhost:8080/sse/start-timer', {
method: 'POST'
});
const result = await response.text();
this.addMessage(`⏰ ${result}`, 'system');
} catch (error) {
this.addMessage(`❌ 启动定时器失败: ${error.message}`, 'error');
}
}
// 更新 UI 状态
updateUI() {
const statusDiv = document.getElementById('status');
const connectBtn = document.getElementById('connectBtn');
const disconnectBtn = document.getElementById('disconnectBtn');
if (this.isConnected) {
statusDiv.textContent = '🟢 已连接到服务器';
statusDiv.className = 'status connected';
connectBtn.disabled = true;
disconnectBtn.disabled = false;
} else {
statusDiv.textContent = '🔴 未连接';
statusDiv.className = 'status disconnected';
connectBtn.disabled = false;
disconnectBtn.disabled = true;
}
}
// 添加消息到显示区域
addMessage(text, type = 'message') {
const messagesDiv = document.getElementById('messages');
const messageDiv = document.createElement('div');
messageDiv.className = `message ${type}`;
messageDiv.innerHTML = `[${new Date().toLocaleTimeString()}] ${text}`;
messagesDiv.appendChild(messageDiv);
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
}
// 创建全局 SSE 客户端实例
const sseClient = new SSEClient();
// 全局函数供按钮调用
function connectSSE() {
sseClient.connect();
}
function disconnectSSE() {
sseClient.disconnect();
}
function broadcastMessage() {
const messageInput = document.getElementById('messageInput');
const message = messageInput.value.trim();
if (message) {
sseClient.broadcastMessage(message);
messageInput.value = '';
} else {
alert('请输入要广播的消息');
}
}
function startTimer() {
sseClient.startTimer();
}
function clearMessages() {
document.getElementById('messages').innerHTML = '';
}
// 页面加载完成后初始化
document.addEventListener('DOMContentLoaded', function() {
// 支持按 Enter 键发送消息
document.getElementById('messageInput').addEventListener('keypress', function(e) {
if (e.key === 'Enter') {
broadcastMessage();
}
});
});
</script>3.1.3:Flux和Mono
想象一个水龙头流出的水,或者一列正在进站的火车车厢。Flux 就是这样的概念:
- 多个元素:它可以发射多个数据项。
- 异步性:数据的生产和使用是异步的,生产者不必等待消费者。
- 背压:消费者可以告诉生产者"慢一点,我处理不过来了"。
- 生命周期:它有一个明确的开始,然后发射数据,最后以一个完成信号或错误信号结束。
官方定义 :Flux<T> 是一个标准的 Publisher<T>,它可以发射 0 到 N 个元素,然后可选地以一个完成信号或错误信号结束。
创建 Flux 只是定义了数据流,只有订阅时数据才会开始流动。这被称为"冷"流。
| 特性 | Flux | Mono |
|---|---|---|
| 元素数量 | 0, 1, 或 N 个 | 0 或 1 个 |
| 典型场景 | 流、集合、序列 | 单个结果、可选值 |
| 完成信号 | 在最后一个元素后发射 onComplete | 在元素后(如果有)发射 onComplete |
| 操作符 | 支持所有操作符 | 支持大部分操作符,返回类型可能是 Mono |
| 转换 | Flux<T> 可以转换为 Mono<List<T>> |
Mono<T> 可以转换为 Flux<T> |
3.2:提示词Prompt
3.2.1:Prompt提示词
Prompt 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应。
Prompt 最开始只是简单的字符串,随着时间的推移,prompt 逐渐开始包含特定的占位符,例如 AI 模型可以识别的 "USER:"、"SYSTEM:" 等。阿里云通义模型可通过将多个消息字符串分类为不同的角色,然后再由 AI 模型处理,为 prompt 引入了更多结构。每条消息都分配有特定的角色,这些角色对消息进行分类,明确 AI 模型提示的每个部分的上下文和目的。这种结构化方法增强了与 AI 沟通的细微差别和有效性,因为 prompt 的每个部分在交互中都扮演着独特且明确的角色。
3.2.2:prompt四大角色
系统角色(System Role)
指导 AI 的行为和响应方式,设置 AI 如何解释和回复输入的参数或规则。这类似于在发起对话之前向 AI 提供说明。
用户角色(User Role)
代表用户的输入 - 他们向 AI 提出的问题、命令或陈述。这个角色至关重要,因为它构成了 AI 响应的基础。
助手角色(Assistant Role)
AI 对用户输入的响应。这不仅仅是一个答案或反应,它对于保持对话的流畅性至关重要。通过跟踪 AI 之前的响应(其"助手角色"消息),系统可确保连贯且上下文相关的交互。助手消息也可能包含功能工具调用请求信息。它就像 AI 中的一个特殊功能,在需要执行特定功能(例如计算、获取数据或不仅仅是说话)时使用。
工具/功能角色(Tool/Function Role)
工具/功能角色专注于响应工具调用助手消息返回附加信息。
3.2.3:提示词模板
引入占位符(如{占位符变量名})以动态插入内容。
就像短信模版,邮件模板一样...
4:再谈chatClient
4.1:二者如何选择
选择使用
ChatModel当:
- 你需要完全控制 每一次请求的所有参数(例如,为不同问题动态设置
temperature)。 - 你需要访问模型的原始元数据 ,例如本次调用的
promptTokens,completionTokens,totalTokens。 - 你正在开发一个需要与
ChatModel接口对齐的底层库或组件。 - 你做的事情非常特殊,
ChatClient的流畅 API 无法支持。
选择使用
ChatClient当:
- 你要快速构建标准的企业级应用,这是绝大多数场景。
- 你想使用提示词模板来更好地管理提示词。
- 你想方便地使用流式输出来提升用户体验。
- 你计划使用 Spring AI 的函数调用 功能,
ChatClient对其有很好的集成。 - 你希望代码更简洁、更易读。
二者并非是非此即彼的关系,而是相辅相成的关系,ChatModel 提供了强大的基础能力,而 ChatClient 则在此基础上提供了极佳的开发者体验。在实际项目中,你甚至可能会同时使用两者。
4.2:测试一下
基础部分
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 引入 springai alibaba DashScope 模型适配的 Starter -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
yaml
server:
port: 8001 # 服务器端口配置
servlet:
encoding:
enabled: true # 启用编码过滤器
force: true # 强制使用指定编码
charset: UTF-8 # 设置字符编码为UTF-8
spring:
application:
name: ssa-hello-service # 应用服务名称
ai:
dashscope:
api-key: sk-??? # DashScope API密钥
java
package com.cui;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SsaHelloApplication {
public static void main(String[] args) {
SpringApplication.run(SsaHelloApplication.class, args);
}
}配置部分
在resouce/propmttemplate/store_template.txt中
讲一个关于{topic}的故事,并以{output_format}格式输出。
java
package com.cui.config;
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SaaLLMConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
// 模型名称的常量定义
private final String DEEPSEEK_V3_MODEL = "deepseek-v3";
private final String QWEN_MODEL = "qwen-plus";
@Bean(name = "deepseek")
public ChatModel deepSeek()
{
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder()
.apiKey(apiKey)
.build())
.defaultOptions(
DashScopeChatOptions.builder().withModel(DEEPSEEK_V3_MODEL).build()
)
.build();
}
@Bean(name = "qwen")
public ChatModel qwen()
{
return DashScopeChatModel.builder().dashScopeApi(DashScopeApi.builder()
.apiKey(apiKey)
.build())
.defaultOptions(
DashScopeChatOptions.builder()
.withModel(QWEN_MODEL)
.build()
)
.build();
}
@Bean(name = "deepseekChatClient")
public ChatClient deepseekChatClient(@Qualifier("deepseek") ChatModel deepSeek)
{
return ChatClient.builder(deepSeek)
.defaultOptions(ChatOptions.builder()
.model(DEEPSEEK_V3_MODEL)
.build())
.build();
}
@Bean(name = "qwenChatClient")
public ChatClient qwenChatClient(@Qualifier("qwen") ChatModel qwen)
{
return ChatClient.builder(qwen)
.defaultOptions(ChatOptions.builder()
.model(QWEN_MODEL)
.build())
.build();
}
}控制器
java
package com.cui.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.util.List;
import java.util.Map;
/**
* 提示模板控制器
*/
@RestController("/saa/template")
public class PromptTemplateController {
/**
* chat model -> 强大的基础能力提供者
*/
@Resource(name = "deepseek")
private ChatModel deepseekChatModel;
@Resource(name = "qwen")
private ChatModel qwenChatModel;
/**
* chat client -> 可以理解为chat model的语法糖,最好优先使用,不满足需求时,使用chat model
*/
@Resource(name = "deepseekChatClient")
private ChatClient deepseekChatClient;
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
/**
* 获取提示模板
*/
@Value("classpath:/prompttemplate/store-template.txt")
private org.springframework.core.io.Resource storeTemplate;
/**
* 提示模板测试
* 地址 -> http://localhost:8001/saa/template/chat?topic=java&outputFormat=markdown&wordCount=200
*/
@GetMapping("/chat")
public Flux<String> templateChat(String topic, String outputFormat, String wordCount) {
// 声明template
String templateContent = """
讲一个关于{topic}的故事,并以{output_format}的格式输出,字数在{word_count}左右
""";
PromptTemplate template = new PromptTemplate(templateContent);
Prompt prompt = template.create(Map.of(
"topic", topic,
"output_format", outputFormat,
"word_count", wordCount
));
return deepseekChatClient.prompt(prompt).stream().content();
}
/**
* 提示模板测试
* 地址 -> http://localhost:8001/saa/template/chat2?topic=java&outputFormat=html
*/
@GetMapping("/chat2")
public Flux<String> templateChat2(String topic, String outputFormat) {
// 声明模板,使用指定的文件
PromptTemplate template = new PromptTemplate(storeTemplate);
// 创建prompt
Prompt prompt = template.create(Map.of(
"topic", topic,
"output_format", outputFormat
));
return deepseekChatClient.prompt(prompt).stream().content();
}
/**
* 提示词角色 + 模板测试
*/
@GetMapping("/chat3")
public Flux<String> templateChat3(String systemTopic, String userTopic) {
// 系统角色模板
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("""
你是{systemTopic}助手,只回答{systemTopic}其它无可奉告,以HTML格式的结果。
""");
Message sysMessage = systemPromptTemplate.createMessage(Map.of("systemTopic", systemTopic));
// 用户角色模板
PromptTemplate userPromptTemplate = new PromptTemplate("""
解释一下{userTopic}
""");
Message userMessage = userPromptTemplate.createMessage(Map.of("userTopic", userTopic));
// 组合多个message -> prompt
Prompt prompt = new Prompt(sysMessage, userMessage);
// 调用LLM
return deepseekChatClient.prompt(prompt).stream().content();
}
/**
* 提示词角色 + 模板测试
*/
@GetMapping("/chat4")
public String chat4(String question) {
//1 系统消息
SystemMessage systemMessage = new SystemMessage("你是一个Java编程助手,拒绝回答非技术问题。");
//2 用户消息
UserMessage userMessage = new UserMessage(question);
//3 系统消息+用户消息=完整提示词
//Prompt prompt = new Prompt(systemMessage, userMessage);
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
//4 调用LLM
String result = deepseekChatModel.call(prompt).getResult().getOutput().getText();
System.out.println(result);
return result;
}
/**
* 提示词角色 + 模板测试
*/
@GetMapping("/chat5")
public Flux<String> chat5(String question) {
return deepseekChatClient.prompt()
.system("你是一个Java编程助手,拒绝回答非技术问题。")
.user(question)
.stream()
.content();
}
}三:格式化输出
上面的例子中我们的返回结果都是string, 但是有时候我们会想要返回对应的实体类,这个时候就需要结构化输出
格式化输出就是在chatClient中通过entity()进行返回结果的转换
java
package com.cui.controller;
import com.cui.domain.StudentRecord;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.function.Consumer;
/**
* 测试结构体输出
* @author cuihaida
*/
@Slf4j
@RestController
@RequestMapping("/saa/struct")
public class StructOutputController {
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
@GetMapping("/output")
public StudentRecord chat(@RequestParam(name = "name") String name,
@RequestParam(name = "email") String email) {
// prompt() -> 创建提示词构建器
StudentRecord ans = qwenChatClient.prompt()
// user() -> 设置用户的输入
.user(userinfo -> userinfo.text("学号1001,我叫{sname},大学专业计算机科学与技术,邮箱{email}").param("name",name).param("email",email))
// call() -> 调用模型
.call()
// entity() -> 结果转换成实体
.entity(StudentRecord.class);
log.info("结果:{}", ans);
return ans;
}
}四:记忆化搜索
Spring AI Alibaba中的聊天记忆提供了维护 AI 聊天应用程序的对话上下文和历史的机制。
既然可以维护对话的上下文和历史,必然就要用一个数据库存储起来,AI最常用的就是redis
将你的问题存储到redis中,这样大模型就可以维护对话的上下文和历史了
1:基础配置
在原有的基础上加入如下的配置
xml
<!--spring-ai-alibaba memory-redis-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
</dependency>
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>添加对应的配置项,配置redis的地址
yaml
server:
port: 8001 # 服务器端口配置
servlet:
encoding:
enabled: true # 启用编码过滤器
force: true # 强制使用指定编码
charset: UTF-8 # 设置字符编码为UTF-8
spring:
application:
name: ssa-hello-service # 应用服务名称
ai:
dashscope:
api-key: sk-??? # DashScope API密钥
data:
redis:
host: localhost
port: 6379
database: 0
connect-timeout: 3 # 连接超时, 单位秒
timeout: 3 # 读取超时, 单位秒2:配置类
创建redis memory配置类
java
package com.cui.config;
import com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* redis memory 配置类
*/
@Configuration
public class RedisMemoryConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
/**
* 创建redis memory
*
* @return RedisChatMemoryRepository
*/
@Bean
public RedisChatMemoryRepository redisChatMemoryRepository() {
return RedisChatMemoryRepository.builder().host(host).port(port).build();
}
}为chat client指定记忆化搜索的方式
java
package com.cui.config;
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SaaLLMConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
// 模型名称的常量定义
private final String DEEPSEEK_V3_MODEL = "deepseek-v3";
private final String QWEN_MODEL = "qwen-plus";
@Bean(name = "deepseek")
public ChatModel deepSeek()
{
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder()
.apiKey(apiKey)
.build())
.defaultOptions(
DashScopeChatOptions.builder().withModel(DEEPSEEK_V3_MODEL).build()
)
.build();
}
@Bean(name = "qwen")
public ChatModel qwen()
{
return DashScopeChatModel.builder().dashScopeApi(DashScopeApi.builder()
.apiKey(apiKey)
.build())
.defaultOptions(
DashScopeChatOptions.builder()
.withModel(QWEN_MODEL)
.build()
)
.build();
}
/**
* 创建DeepSeek模型的ChatClient Bean
*
* @param deepSeek 注入名为"deepseek"的ChatModel Bean
* @param redisChatMemoryRepository Redis聊天记忆存储库,用于持久化聊天历史
* @return 配置好的ChatClient实例
*/
@Bean(name = "deepseekChatClient")
public ChatClient deepseekChatClient(@Qualifier("deepseek") ChatModel deepSeek,
RedisChatMemoryRepository redisChatMemoryRepository) {
// 构建消息窗口聊天记忆组件,用于管理对话历史
MessageWindowChatMemory windowChatMemory = MessageWindowChatMemory.builder()
// 设置Redis聊天记忆存储库
.chatMemoryRepository(redisChatMemoryRepository)
// 设置最大保存的消息数量为10条
.maxMessages(10)
.build();
// 构建ChatClient实例
return ChatClient.builder(deepSeek)
// 设置默认选项,指定使用DEEPSEEK_V3_MODEL模型
.defaultOptions(ChatOptions.builder().model(DEEPSEEK_V3_MODEL).build())
// 添加默认顾问,使用构建好的消息记忆组件
.defaultAdvisors(MessageChatMemoryAdvisor.builder(windowChatMemory).build())
.build();
}
/**
* 创建Qwen模型的ChatClient Bean
*
* @param qwen 注入名为"qwen"的ChatModel Bean
* @param redisChatMemoryRepository Redis聊天记忆存储库,用于持久化聊天历史
* @return 配置好的ChatClient实例
*/
@Bean(name = "qwenChatClient")
public ChatClient qwenChatClient(@Qualifier("qwen") ChatModel qwen,
RedisChatMemoryRepository redisChatMemoryRepository) {
// 构建消息窗口聊天记忆组件,用于管理对话历史
MessageWindowChatMemory windowChatMemory = MessageWindowChatMemory.builder()
// 设置Redis聊天记忆存储库
.chatMemoryRepository(redisChatMemoryRepository)
// 设置最大保存的消息数量为10条
.maxMessages(10)
.build();
// 构建ChatClient实例
return ChatClient.builder(qwen)
// 设置默认选项,指定使用QWEN_MODEL模型
.defaultOptions(ChatOptions.builder().model(QWEN_MODEL).build())
// 添加默认顾问,使用构建好的消息记忆组件
.defaultAdvisors(MessageChatMemoryAdvisor.builder(windowChatMemory).build())
.build();
}
}3:advisor实现
使用advisor对每一个用户进行区分,从而保证上下文的正确性
java
package com.cui.controller;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import static org.springframework.ai.chat.memory.ChatMemory.CONVERSATION_ID;
@Slf4j
@RestController
@RequestMapping("/saa/memory")
public class ChatMemoryController {
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
/**
* advisors 是 Spring AI 框架中的一个机制,用于为聊天客户端添加额外的行为或配置。
* 具体来说,它允许你在发送请求给 AI 模型之前或之后插入一些逻辑或参数设置
*
* advisors 的主要功能是向 ChatClient 提供一种扩展点(类似于拦截器或者中间件的概念)
* 使得开发者可以在请求处理过程中加入自定义行为。
* 在这段代码中,它的用途是传递与当前对话相关的元数据,例如用户的唯一标识符 (userId)。
*
* 这里使用了 Lambda 表达式来简化代码编写。
* - advisorSpec 是一个 ChatClient.AdvisorSpec 类型的对象,用来指定聊天过程中的各种参数和策略。
* - CONVERSATION_ID 是一个预定义常量,代表"对话 ID",这是 Spring AI 中用于跟踪和管理多个用户之间独立对话的关键属性。
* - 通过 .param(CONVERSATION_ID, userId) 将 userId 作为对话 ID 传入,这样 AI 能够识别不同用户之间的上下文,并维持各自的对话记忆。
*
* 为什么需要这样做?
* - 当你需要支持多用户并发聊天且希望每个用户都有自己的对话历史记录时,就需要区分不同的会话。
* - Redis 或其他持久化存储可以基于这个 CONVERSATION_ID 来保存和恢复特定用户的对话状态。
* - 因此,在这里通过 advisors 设置 CONVERSATION_ID 实际上是为了启用"有状态"的聊天体验 ------ 即让 AI 记住之前的交流内容。
*
* 总结起来,这段代码的作用就是告诉 AI 客户端:"这次提问属于哪个用户?"
* 从而保证回复能够关联到正确的对话上下文之中。
*/
@GetMapping("/memoryTest")
public String memoryTest(String userId, String question) {
return qwenChatClient // 获取配置好的Qwen聊天客户端实例
.prompt(question) // 设置用户输入的消息内容作为提示词
.advisors(advisorSpec -> // 添加顾问(Advisor)配置,使用Lambda表达式简化代码
advisorSpec.param(CONVERSATION_ID, userId)) // 设置对话ID参数,用于标识用户会话
.call() // 执行聊天请求调用
.content(); // 获取并返回AI回复的内容字符串
}
}五:文生图,文生音
1:文生图
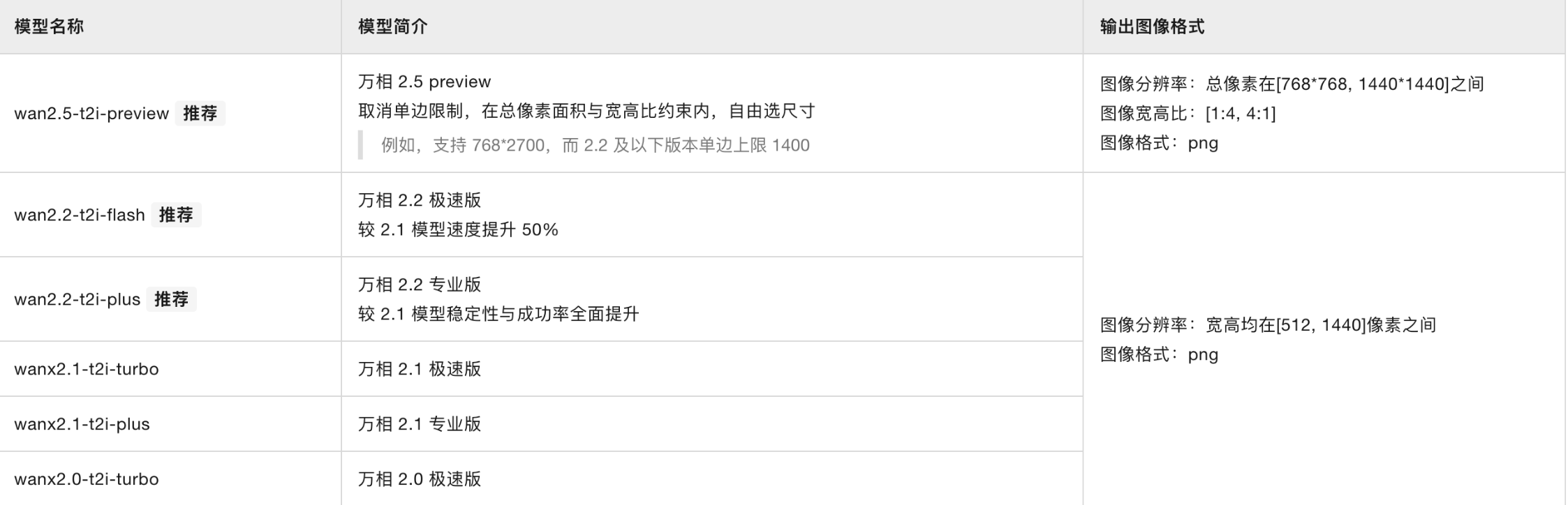
通过文生图API,您可以基于文本描述创造出全新的图像。阿里云百炼提供两大系列模型:
- 通义千问(Qwen-Image): 擅长渲染复杂的中英文文本。
- 通义万相(Wan系列): 用于生成写实图像和摄影级视觉效果。链接
java
package com.cui.controller;
import com.alibaba.cloud.ai.dashscope.image.DashScopeImageOptions;
import jakarta.annotation.Resource;
import org.springframework.ai.image.ImageModel;
import org.springframework.ai.image.ImagePrompt;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/saa/text2image")
public class Text2ImageController {
private static final String IMAGE_MODEL = "wanx2.1-t2i-turbo";
@Resource
private ImageModel imageModel;
@RequestMapping("/text2image")
public String image(@RequestParam(name = "prompt",defaultValue = "刺猬") String prompt) {
// 创建参数, 声明使用的文生图模型是wanx2.1-t2i-turbo
DashScopeImageOptions options = DashScopeImageOptions.builder().withModel(IMAGE_MODEL).build();
// 通过call方法调用模型,传入prompt和模型信息,返回结果(getUrl)
return imageModel.call(new ImagePrompt(prompt, options)).getResult().getOutput().getUrl();
}
}2:文生音

java
package com.cui.controller;
import com.alibaba.cloud.ai.dashscope.audio.DashScopeSpeechSynthesisOptions;
import com.alibaba.cloud.ai.dashscope.audio.synthesis.SpeechSynthesisModel;
import com.alibaba.cloud.ai.dashscope.audio.synthesis.SpeechSynthesisPrompt;
import com.alibaba.cloud.ai.dashscope.audio.synthesis.SpeechSynthesisResponse;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.util.UUID;
@RestController
@RequestMapping("/saa/text2voice")
public class Text2VoiceController {
@Resource
private SpeechSynthesisModel speechSynthesisModel;
// 指定音色模型和音色列表
public static final String BAILIAN_VOICE_MODEL = "cosyvoice-v2";
public static final String BAILIAN_VOICE_TIMBER = "longyingcui";//龙应催
@GetMapping("/t2v/voice")
public String voice(@RequestParam(name = "msg",defaultValue = "温馨提醒,支付宝到账100元请注意查收") String msg) {
// 指定存储的文件路径
String filePath = UUID.randomUUID() + ".mp3";
// 语音参数设置,设置对应的模型和音色
DashScopeSpeechSynthesisOptions options = DashScopeSpeechSynthesisOptions.builder()
.model(BAILIAN_VOICE_MODEL)
.voice(BAILIAN_VOICE_TIMBER)
.build();
//2 调用大模型语音生成对象
SpeechSynthesisResponse response =
speechSynthesisModel.call(new SpeechSynthesisPrompt(msg, options));
//3 字节流语音转换 - getAudio()
ByteBuffer byteBuffer = response.getResult().getOutput().getAudio();
//4 文件生成 -> byteBuffer -> file
try (FileOutputStream fileOutputStream = new FileOutputStream(filePath)) {
fileOutputStream.write(byteBuffer.array());
} catch (Exception e) {
System.out.println(e.getMessage());
}
//5 生成路径OK
return filePath;
}
}六:向量数据库和RAG
1:什么是向量化
因为计算机不理解我们人类的语言,所以向量化就是将非结构化文本(我们说的)转换成为他能够理解处理的一串数值
可以把它想象为一种"翻译":
- 源语言:人类可理解的信息(如单词、句子、图片)。
- 目标语言:计算机(特别是机器学习模型)能够理解和处理的数学表示
这个向量不是随机的数值串,它的关键在于:语义相近或相似的对象,在高维向量空间中的距离也更近。
计算机无法直接理解"国王"、"王后"、"男人"、"女人"这些词汇的含义。但通过向量化:
- "国王"的向量可能被表示为
[0.8, 0.2, 0.1, ...] - "王后"的向量可能被表示为
[0.75, 0.8, 0.05, ...] - "男人"的向量可能被表示为
[0.6, 0.1, 0.9, ...] - "女人"的向量可能被表示为
[0.55, 0.7, 0.85, ...]
可以发现,从"国王"到"王后"的向量变化,与从"男人"到"女人"的向量变化是相似的(例如,在某个维度上数值增加,在另一个维度上数值减少)。这完美地捕捉了"性别"关系。
2:嵌入(embedding)
2.1:文本向量化
早期/基础方法
- One-Hot Encoding:一个词用一个很长的向量表示,向量中只有一位是1,其余是0。维度高、稀疏、无法表示语义关系。
- TF-IDF:基于词频和逆文档频率的统计方法,比One-Hot好,但仍是浅层表示。
现代深度学习方法 - 核心
- Word2Vec:将单词映射为稠密向量,能捕捉"国王 - 男人 + 女人 ≈ 王后"这样的语义关系。
- GloVe:基于全局词频统计的模型。
- BERT及其变体(如sentence-transformers):这是当前的主流和最佳实践。它不是为单个单词生成静态向量,而是根据单词在句子中的上下文生成动态向量。因此,它能更好地理解一词多义和复杂的句法结构。例如,
"我今天要去开户"和"请打开窗户"中的"开"字,BERT会生成完全不同的向量表示。
2.2:图像/多模态向量化
- 使用卷积神经网络(CNN,如ResNet)或视觉Transformer(ViT)等模型,将图像映射到向量空间。
- 多模态模型(如CLIP)可以将图像和文本映射到同一个向量空间,从而实现"以文搜图"或"以图搜文"。
2.3:embedding
Embedding 是一个将高维、离散、非结构化的数据(如文字)映射到低维、连续、稠密的向量空间中的过程 。得到的输出结果就是一个向量(一组数字),这个向量就是嵌入本身。
高维 -> 低维
- 高维:比如用 One-Hot Encoding 表示单词。假设词汇表有5万个词,"国王"这个词会被表示成一个长度为5万的向量,只有一位是1,其他全是0。这非常稀疏、低效。
- 低维 :Embedding 会把这个5万维的"国王"压缩成一个长度为300或768的向量(例如
[0.23, -0.45, 0.89, ..., 0.12])。这个维度虽然依然很高,但相比5万维,已经是非常"低"且"稠密"了。
离散 -> 连续
- 离散:词语是孤立的、符号化的。"国王"和"君主"在计算机看来是两个完全不同的字符串。
- 连续:Embedding 将词语映射到一个连续的数学空间中。"国王"和"君主"的向量值会非常接近,它们之间的"语义空间"是平滑过渡的,你可以找到意义介于两者之间的点。
稠密
- 向量中的每一个数字都承载了信息,没有浪费的0值。每一个维度都可能代表了某种潜在的语义特征(虽然我们人类很难解读这些特征具体是什么)。
作为工程师,你通常不需要自己从零训练一个Embedding模型,而是会调用现有的模型来生成Embedding。
流程如下:
- 输入:你的数据(如一段用户查询:"什么是人工智能?")。
- 调用Embedding模型:通过HTTP请求等方式,调用一个Embedding模型服务(如OpenAI的
text-embedding-3-small、Hugging Face上的开源模型如BGE,或本地部署的sentence-transformers模型)。 - 输出:得到一个
float[]数组。这个数组就是你的文本的"数字指纹"。
| 方面 | 解释 |
|---|---|
| 它是什么? | 一段信息(文本/图像等)的数学表示,一个高维向量。 |
| 它做了什么? | 将人类可理解的信息"翻译"成计算机可处理的数值形式,并保持语义关系。 |
| 为什么需要它? | 让计算机能够理解语义,从而进行语义搜索、推荐、聚类等高级任务。它是大模型应用(如RAG)的基石。 |
| 工程师怎么看它? | 它是一个float[]数组,是数据的"数字指纹",是向量数据库的"燃料"。我们的工作就是生成、存储、检索和计算它。 |
3:向量相似度计算
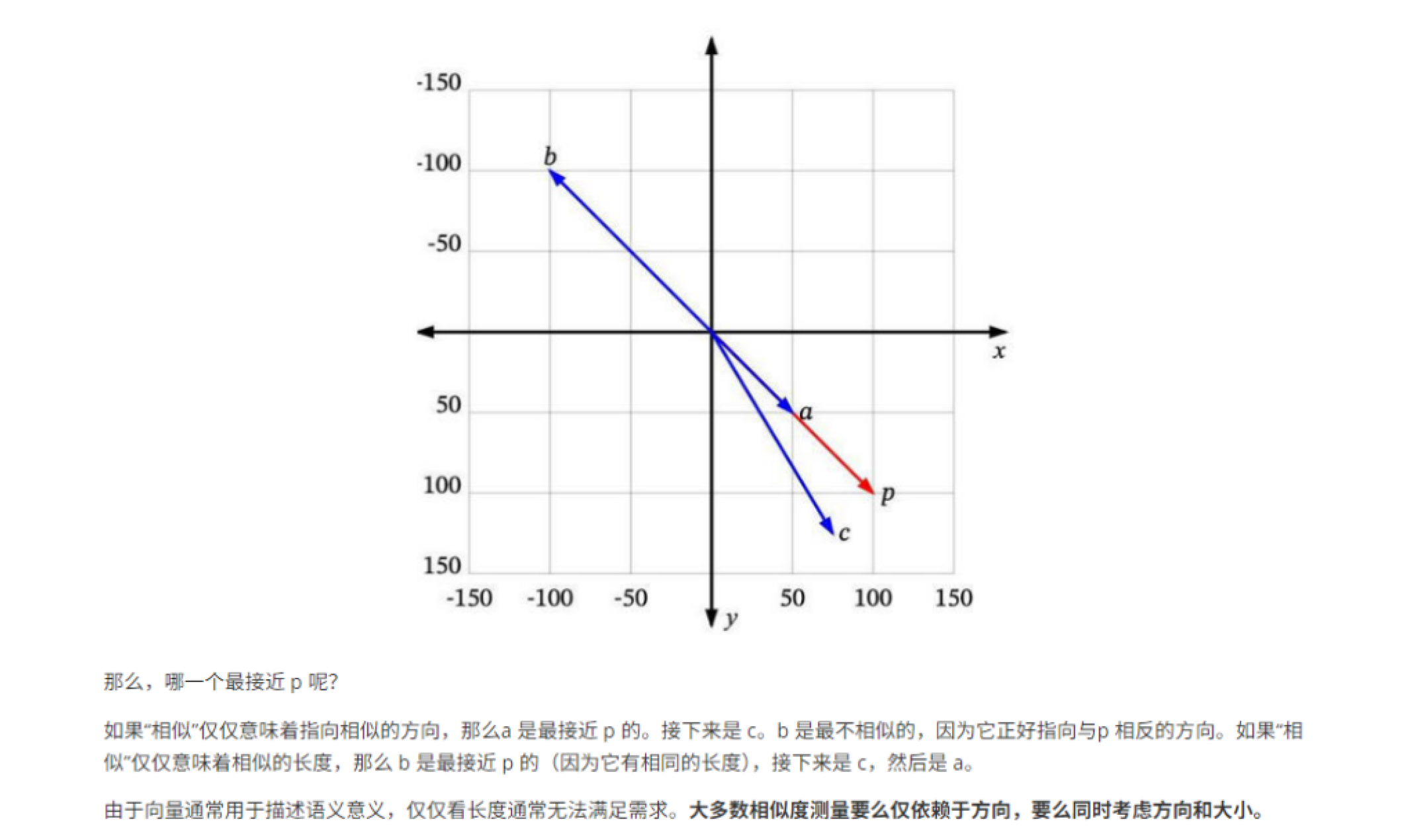
- 余弦相似度 :最常用,衡量的是向量方向上的差异,忽略其大小。范围在-1, 1之间,越接近1越相似。对文本相似度任务尤其有效。
- 欧氏距离:衡量向量空间中的绝对距离。距离越近越相似。
- 点积:计算简单,但其结果受向量模长影响,通常需要先对向量进行归一化。
4:向量数据库
4.1:什么是向量数据库
向量数据库是一种专门为存储、索引和检索高维向量数据而优化的数据库。
它不像传统关系型数据库(如MySQL)那样通过精确匹配来查询,而是通过相似度搜索来找到最接近的向量。
- 向量存储:高效存储海量向量数据。
- 索引:这是向量数据库的灵魂。为了在数十亿向量中快速找到最相似的几个,不能使用暴力循环比较,必须使用高效的近似最近邻(ANN)索引。
- 元数据存储与过滤:除了向量本身,还能存储源数据的元信息(如创建时间、作者、类别等),并支持在相似度搜索的基础上进行元数据过滤。
- CRUD操作:支持向量的增、删、改、查。
4.2:核心原理:ANN索引算法
向量数据库的性能核心在于其索引算法。
- 基于树的索引:KD-Tree:适用于低维空间(<20维),在高维空间中性能会退化到接近暴力搜索("维度灾难")。
- 基于哈希的索引:局部敏感哈希(LSH):核心思想是"让相似的向量以高概率哈希到同一个桶里"。查询时,只需在同一个桶或邻近桶内搜索即可。简单快速,但精度通常不如基于图的方法。
- 基于图的索引(当前主流):HNSW:是目前最流行、综合性能最好的ANN算法之一。
- 原理:它构建了一个分层的图结构。底层包含所有数据点,越往上节点越稀疏。搜索时从顶层开始,找到距离查询点最近的节点,然后逐层向下,像"滑雪跳台"一样,快速逼近目标区域。
- 优点:查询速度快、精度高、支持增量更新。
- 基于量化的索引:产品量化(PQ):将高维向量空间分解为多个低维子空间的笛卡尔积,并对每个子空间进行聚类。这样可以极大地压缩向量表示,减少内存占用,适合超大规模数据集。
Milvus / Zilliz Cloud:开源、功能全面、生态强大,是许多企业的首选。
Pinecone:完全托管的SaaS服务,开箱即用,开发者友好。
Chroma:轻量级、易用,特别适合原型开发和中小项目。
Weaviate:兼具向量搜索和GraphQL查询能力。
Qdrant:用Rust编写,性能优异,API友好。
Elasticsearch / OpenSearch:从8.x版本开始原生支持向量搜索,适合已有ES技术栈的场景。
Pgvector:PostgreSQL的扩展,让你可以在熟悉的PG数据库中直接进行向量运算。对于已经在使用PG且向量规模不大的团队,这是一个非常平滑的过渡方案。
实际的向量数据库(如Milvus, Pinecone)通常会结合多种索引技术,例如使用IVF(倒排文件)进行粗筛,再使用PQ进行细粒度计算。
4.3:redis-stack
redis-stack不仅仅是一个数据库,更是一个强大的多模型实时数据平台
redis-stack是redis公司推出的一体化产品,在开源的redis基础上,集成了多个redis模块,并提供了直观的可视化工具
- Redis (标准版):是一个开源的、内存中的键值存储。它提供了核心的数据结构(String, Hash, List, Set, SortedSet)和基础功能。您通过 Maven 引入的 Jedis/Lettuce 客户端,就是用来与这个标准版通信的。
- Redis Stack:是在 Redis 标准版之上,预先集成了多个官方高级模块的一个发行版。这些模块提供了超越键值存储的强大功能。
4.3.1:redis-stack的组成
redis-core
redis-core是redis-stack的基石,也就是咱们平时用的最基础的redis相关的信息,提供了无与伦比的内存性能、丰富的数据结构(String, List, Set, Hash, ZSet等)以及复制、持久化等核心功能。
redis-json
原生支持 JSON 文档 作为数据类型。
你可以直接存储、读取和修改 JSON 文档中的特定字段,而无需在客户端反序列化整个文档。
使用原生 Redis String 存储 JSON 时,任何小修改都需要GET -> 修改 -> SET,非常低效。
RedisJSON 允许原子性的原地操作。
java
// 存储一个完整的 JSON 文档
jedis.jsonSet("user:1001", "{\"name\":\"Alice\", \"age\":30, \"city\":\"London\", \"hobbies\":[\"coding\", \"hiking\"]}");
// 读取整个文档
Object wholeUser = jedis.jsonGet("user:1001");
System.out.println(wholeUser);
// 输出: {"name":"Alice","age":30,"city":"London","hobbies":["coding","hiking"]}
// 仅读取特定字段
Object userName = jedis.jsonGet("user:1001", Path.of(".name"));
System.out.println(userName); // 输出: "Alice"
// 修改特定字段 (原地更新)
jedis.jsonSet("user:1001", Path.of(".age"), 31);
// 向数组字段添加元素
jedis.jsonArrAppend("user:1001", Path.of(".hobbies"), "gaming");redis-search
一个功能强大的二级索引、查询引擎和全文搜索引擎。
它可以为 Redis 中的数据(包括 Hashes, JSON 文档)创建索引,并执行复杂的查询、过滤、聚合、分页,甚至向量相似度搜索
它打破了 Redis 只能通过 Key 查询的限制,实现了基于字段内容的搜索
java
// 为 Hash 数据创建索引
// 假设我们的 Hash Key 为 `product:XXX`,包含字段 `name`, `price`, `description`
jedis.ftCreate(
// 执行索引的名称
"idx:product",
// 索引的说明,指定索引基于hash结构,并且只为以 `product:` 开头的 Key 建立索引
FTCreateParams.createParams().on(IndexDataType.HASH).prefix("product:"),
// 文本字段,权重更高
TextField.of("name").weight(2.0),
// 标签字段,用于精确分类过滤
TagField.of("category"),
// 数值字段,用于范围查询
NumericField.of("price"),
// 文本字段
TextField.of("description")
);
// 插入一些测试数据
jedis.hset("product:1", Map.of(
"name", "Smartphone",
"category", "electronics",
"price", "999",
"description", "Latest model with advanced camera"
));
jedis.hset("product:2", Map.of(
"name", "Coffee Mug",
"category", "kitchen",
"price", "15",
"description", "A nice mug for your morning coffee"
));
// 执行搜索:查找名称或描述中包含 "coffee" 的商品
SearchResult result = jedis.ftSearch("idx:product", "coffee");
result.getDocuments().forEach(doc -> {
System.out.println("ID: " + doc.getId());
System.out.println("Name: " + doc.get("name"));
System.out.println("Price: " + doc.get("price"));
});
// 执行复杂查询:分类为 electronics 且价格 <= 1000 的商品
String query = "@category:{electronics} @price:[0 1000]";
SearchResult result2 = jedis.ftSearch("idx:product", query);redis bloom
提供一组概率数据结构 ,用于处理大数据流中的成员查询、计数和去重等问题,特点是极其节省内存。
Bloom Filter:高效判断"某元素一定不存在"或"可能存在"于一个集合中。常用于防止缓存穿透。Cuckoo Filter:Bloom Filter 的增强版,支持元素删除。Count-Min Sketch:用于估算数据流的频率(例如,最常搜索的关键词)。Top-K:实时统计流数据中的 Top K 元素(例如,最近一小时的 Top 10 热搜)。
java
// 使用 Lettuce 客户端
StatefulRedisConnection<String, String> connection = ...;
BloomFilterCommands<String, String> bloomCommands = connection.sync();
// 创建一个 Bloom Filter,并初始化
bloomCommands.bfReserve("user:filter", 0.01, 1000L); // 期望容量1000,错误率1%
// 添加元素
bloomCommands.bfAdd("user:filter", "user100");
bloomCommands.bfAdd("user:filter", "user200");
// 检查元素是否存在
Boolean exists = bloomCommands.bfExists("user:filter", "user100");
System.out.println("User100 exists: " + exists); // 输出: true
Boolean notExists = bloomCommands.bfExists("user:filter", "user999");
System.out.println("User999 exists: " + notExists); // 输出: false (可能)
// 应用场景:缓存穿透防护
public String getProduct(String id) {
// 1. 先查 Bloom Filter
if (!bloomCommands.bfExists("product:filter", id)) {
// 一定不存在于数据库,直接返回null,避免访问数据库
return null;
}
// 2. 再查缓存/数据库...
// ...
}Redis-timeSeries
为 Redis 添加了时间序列数据结构,专为处理带时间戳的数据流(如监控指标、传感器数据、股价)优化。
支持按时间范围查询、降采样、聚合(avg, max, min, sum等)和压缩
Redis-insight
Redis 官方提供的图形化管理桌面客户端,可以浏览数据和key,执行命令,查看分析报告等,可以可视化地操作 RedisJSON 文档和 RediSearch 索引,监控慢日志
4.3.2:安装和使用
最方便的方式就是使用docker快速进行安装
shell
# 拉取最新版本的 Redis Stack 镜像
docker pull redis/redis-stack:latest
# 运行 Redis Stack 容器
docker run -d \
--name redis-stack \
-p 6379:6379 \ # Redis 数据库端口
-p 8001:8001 \ # RedisInsight 可视化工具端口
-v redis_data:/data \ # 数据持久化卷
redis/redis-stack:latest
shell
# 检查容器运行状态
docker ps
# 连接到 Redis CLI 测试
docker exec -it redis-stack redis-cli
127.0.0.1:6379> ping
# 应该返回 PONG
5:RAG
5.1:什么是RAG
RAG 的全称是 Retrieval-Augmented Generation,即 检索增强生成。
传统的LLM(基座模型)有如下几个问题:
- 知识滞后: 模型训练数据有截止日期,无法获取最新信息。
- 知识幻觉: 模型可能会"一本正经地胡说八道",生成看似合理但实际错误的内容。
- 缺乏领域特异性: 通用模型对于专业、私有或高度定制化的知识库了解有限。
- 透明度低: 我们无法得知模型生成答案的依据来源。
RAG将信息检索 与文本生成 相结合。在回答用户问题之前,先从外部知识库(如公司文档、数据库、网络搜索)中检索出相关的、权威的信息片段,然后将这些信息作为上下文,连同用户问题一起交给LLM,让LLM基于这些事实依据 来生成答案。
想象一个开卷考试。
- 纯LLM: 闭卷考试。学生只能依靠记忆答题,可能记错、记不清或根本不知道。
- RAG系统: 开卷考试。学生(LLM)可以带着一本指定的参考书(外部知识库)进入考场。当遇到问题时,他先快速在书中查找相关章节(检索),然后组织语言写出答案(生成)。这样答案更准确、更有据可查。
5.2:RAG的核心工作流程
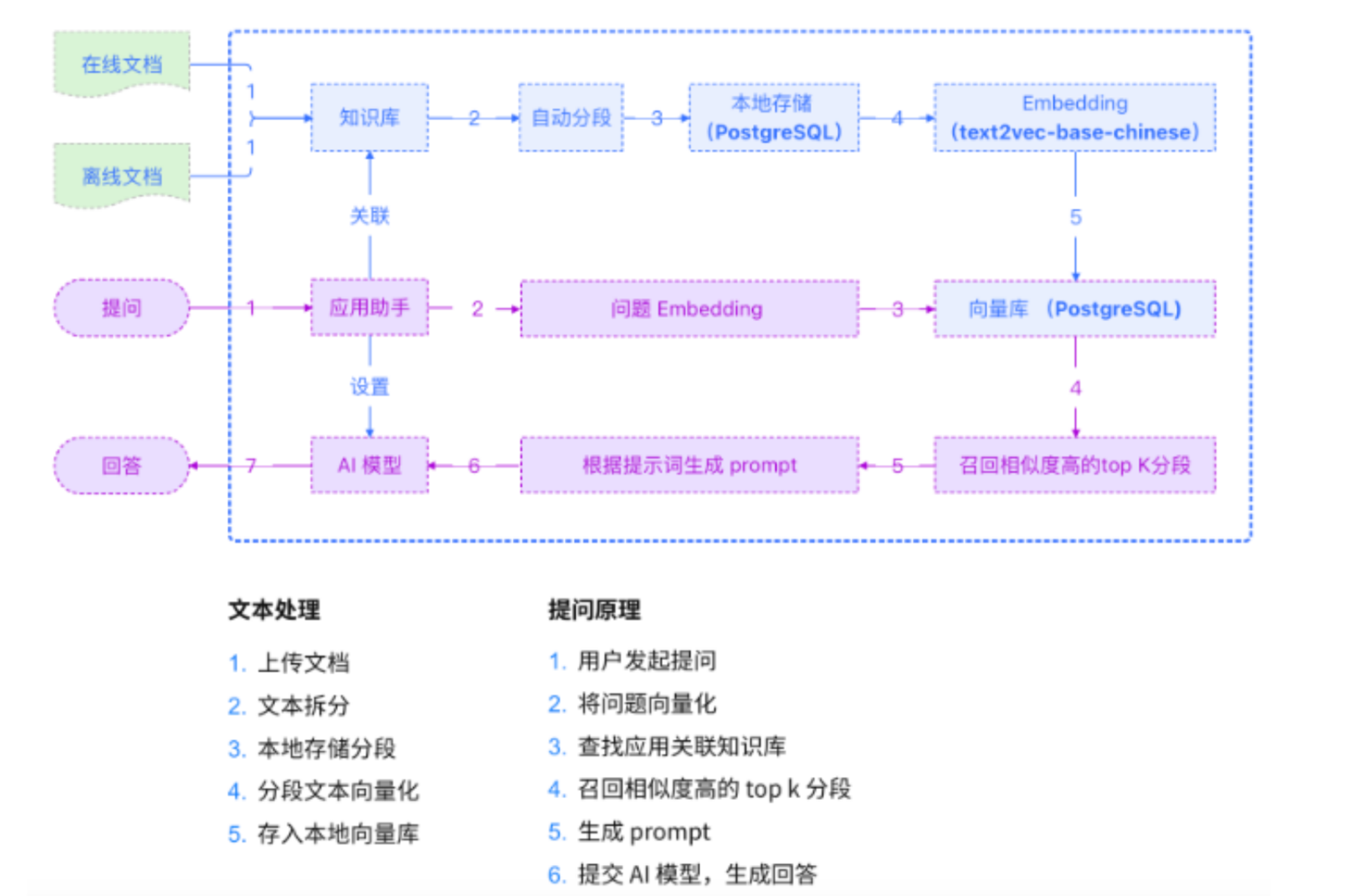
一个典型的RAG流程分为两个主要阶段:数据索引 和 查询/生成。
数据索引(离线进行,预处理)
-
先加载,从各种数据源(PDF, Word, HTML, 数据库等)加载原始文档。Java中可以使用
Apache Tika等库来解析多种文件格式 -
分割:将长文档切分成更小的、有意义的文本块。这是因为LLM有上下文窗口限制,且小文本块更易于精准检索。分割策略(如按段落、按章节、重叠分割)对效果至关重要
-
embedding:使用文本嵌入模型将每个文本块转换为一个高维向量(即Embedding)。这个向量可以理解为该文本块在语义空间中的"数学坐标",语义相近的文本,其向量也相似
-
将文本块和其对应的向量存储到向量数据库中
java
// 伪代码示例:使用简单的按行分割
List<String> documents = Files.readAllLines(Paths.get("knowledge.txt"));
List<TextChunk> chunks = new ArrayList<>();
for (String doc : documents) {
// 更复杂的实现会考虑句子边界、令牌数等
chunks.add(new TextChunk(doc));
}
// 伪代码示例:调用嵌入模型API (例如 OpenAI, Hugging Face, 或本地模型)
EmbeddingModel model = new HuggingFaceEmbeddingModel(); // 例如 all-MiniLM-L6-v2
for (TextChunk chunk : chunks) {
float[] vector = model.embed(chunk.getText());
chunk.setVector(vector);
}查询和生成
- 当用户提出一个问题
Q时,系统使用与阶段一相同的嵌入模型,将问题Q也转换为一个向量V_q。 - 向量数据库中,执行向量相似性搜索(例如,余弦相似度、点积)。寻找与
V_q最相似的Top K个文本块。这些就是系统找到的"证据"或"参考" - 将检索到的Top K个文本块和原始用户问题,组合成一个结构化的提示,交给LLM
- LLM根据这个"增强后"的提示,生成一个内容丰富、有据可依的最终答案。
5.3:SAA + redis stack + RAG
项目结构,依赖和配置
src/main/java/com/example/rag/
├── config/ # 配置类目录
│ └── RagConfiguration.java
├── controller/ # 控制器目录
│ └── RagController.java
├── service/ # 服务层目录
│ ├── DocumentSplitterService.java
│ ├── FileProcessingService.java
│ ├── VectorStoreService.java
│ ├── RagService.java
│ └── DocumentManagementService.java
├── model/ # 数据模型目录
│ └── DocumentChunk.java
├── properties/ # 配置属性目录
│ └── RagProperties.java
└── RagApplication.java # 主应用类
XML
<dependencies>
<!-- Spring Boot Web Starter:提供Web开发能力,比如REST API -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot Data Redis:提供Redis数据库操作能力 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- Spring AI Alibaba DashScope:阿里云通义千问AI的Spring集成 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.0.0-M1</version>
</dependency>
<!-- Spring AI Redis Vector Store:Spring AI的Redis向量存储支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
<version>1.0.0-M1</version>
</dependency>
<!-- Apache Tika:文档解析工具,可以解析PDF、Word、Excel等文件 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>2.9.1</version>
</dependency>
</dependencies>
yaml
# Spring Boot 应用配置
spring:
application:
name: rag-system # 应用名称
# Spring AI Alibaba DashScope 配置
ai:
alibaba:
dashscope:
# API密钥,建议通过环境变量设置,不要硬编码在配置文件中
api-key: ${DASHSCOPE_API_KEY:sk-your-api-key-here}
# 聊天模型配置
chat:
options:
model: qwen-turbo # 使用通义千问Turbo模型
temperature: 0.7 # 创造性:0-1,越小答案越保守
top-p: 0.8 # 核采样:0-1,影响词汇选择
max-tokens: 2000 # 最大输出token数
# 嵌入模型配置
embedding:
options:
model: text-embedding-v1 # 文本嵌入模型
dimensions: 1536 # 向量维度
# Redis向量存储配置
vectorstore:
redis:
index-name: rag-documents # 向量索引名称
prefix: rag:doc: # Redis键前缀
# Redis连接配置
data:
redis:
host: localhost # Redis服务器地址
port: 6379 # Redis端口
database: 0 # Redis数据库编号
password: ${REDIS_PASSWORD:} # Redis密码
timeout: 5000ms # 连接超时时间
lettuce: # Lettuce客户端配置
pool:
max-active: 20 # 最大连接数
max-wait: 5000ms # 最大等待时间
max-idle: 10 # 最大空闲连接
min-idle: 5 # 最小空闲连接
# 文件上传配置
servlet:
multipart:
max-file-size: 10MB # 单个文件最大大小
max-request-size: 50MB # 整个请求最大大小
# 自定义RAG应用配置
app:
rag:
chunk-size: 512 # 文本块大小(字符数)
chunk-overlap: 50 # 块重叠大小(字符数)
top-k: 5 # 向量搜索返回数量
vector-index-name: rag-documents # 向量索引名称
key-prefix: rag:doc: # Redis键前缀
# 日志配置
logging:
level:
com.example.rag: DEBUG # 设置我们应用的日志级别为DEBUG
org.springframework.ai: INFO # Spring AI日志级别
java
// @SpringBootApplication:Spring Boot应用的核心注解,包含以下三个注解:
// @Configuration:标记为配置类
// @EnableAutoConfiguration:启用自动配置 - 依赖中facties中的bean引入
// @ComponentScan:自动扫描当前包及其子包下的组件 - @Component及其衍生注解
@SpringBootApplication
// @EnableConfigurationProperties:启用配置属性绑定
@EnableConfigurationProperties(RagProperties.class)
public class RagApplication {
/**
* 应用主入口方法
* @param args 命令行参数
*/
public static void main(String[] args) {
// 启动Spring Boot应用
SpringApplication.run(RagApplication.class, args);
}
/**
* 配置RestTemplate Bean
* RestTemplate:用于发送HTTP请求的Spring工具类
*/
@Bean
public RestTemplate restTemplate() {
// 创建并返回RestTemplate实例
return new RestTemplate();
}
}配置类 - RagProperties & RagConfiguration & DocumentChunk
java
@Component
@ConfigurationProperties(prefix = "app.rag")
@Data
public class RagProperties {
// 每个文本块的最大大小(字符数)
private int chunkSize = 512;
// 块与块之间的重叠字符数(避免信息丢失)
private int chunkOverlap = 50;
// 每次向量搜索返回的最相关文档数量
private int topK = 5;
// Redis中向量索引的名称
private String vectorIndexName = "rag-documents";
// Redis中存储文档键的前缀
private String keyPrefix = "rag:doc:";
}
java
@Configuration
@EnableConfigurationProperties(RagProperties.class)
public class RagConfiguration {
// VectorStore:向量存储接口,Spring AI的核心接口之一
@Bean
public VectorStore vectorStore(RedisConnectionFactory connectionFactory,
RagProperties ragProperties) {
// 创建Redis向量存储的配置
RedisVectorStoreConfig config = RedisVectorStoreConfig.builder()
.withIndexName(ragProperties.getVectorIndexName()) // 设置索引名称
.withPrefix(ragProperties.getKeyPrefix()) // 设置键前缀
.build(); // 构建配置对象
// 创建并返回Redis向量存储实例
return new RedisVectorStore(config, connectionFactory);
}
// 嵌入客户端Bean - Spring AI Alibaba会自动配置,这里只是演示
@Bean
public EmbeddingClient embeddingClient(AlibabaDashScopeEmbeddingProperties embeddingProperties) {
// 实际上Spring Boot会自动配置这个Bean,这里只是为了展示
return new AlibabaDashScopeEmbeddingClient(embeddingProperties);
}
}
java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DocumentChunk {
// 文档块的唯一标识
private String id;
// 文档块的实际文本内容
private String content;
// 这个块属于哪个文档(文档的唯一标识)
private String documentId;
// 原始文件名
private String fileName;
// 这个块在文档中的位置索引(第几个块)
private Integer chunkIndex;
// 额外的元数据,可以存储任何相关信息
private Map<String, Object> metadata;
// 将我们的DocumentChunk转换为Spring AI的Document对象
public Document toSpringAiDocument() {
// 创建元数据Map
Map<String, Object> docMetadata = new HashMap<>();
// 存储文档ID
docMetadata.put("document_id", documentId);
// 存储文件名
docMetadata.put("file_name", fileName);
// 存储块索引
docMetadata.put("chunk_index", chunkIndex);
// 存储块ID
docMetadata.put("id", id);
// 如果原有metadata不为空,合并进去
if (metadata != null) {
docMetadata.putAll(metadata);
}
// 创建Spring AI的Document对象(内容 + 元数据)
return new Document(content, docMetadata);
}
// 从Spring AI的Document对象转换回我们的DocumentChunk
public static DocumentChunk fromSpringAiDocument(Document document) {
// 获取文档的元数据
Map<String, Object> metadata = document.getMetadata();
// 创建并返回DocumentChunk对象
return new DocumentChunk(
(String) metadata.get("id"), // 从元数据获取id
document.getContent(), // 获取文本内容
(String) metadata.get("document_id"), // 从元数据获取文档ID
(String) metadata.get("file_name"), // 从元数据获取文件名
(Integer) metadata.get("chunk_index"), // 从元数据获取块索引
metadata // 所有元数据
);
}
}各个服务部分
java
@Service
@Slf4j
public class DocumentSplitterService {
// 注入配置属性
private final RagProperties ragProperties;
// 构造函数注入(Spring推荐的方式)
public DocumentSplitterService(RagProperties ragProperties) {
this.ragProperties = ragProperties;
}
/**
* 将长文档分割成多个小文本块
* @param content 文档内容
* @param documentId 文档ID
* @param fileName 文件名
* @return 分割后的文本块列表
*/
public List<DocumentChunk> splitDocument(String content, String documentId, String fileName) {
// 创建空的块列表
List<DocumentChunk> chunks = new ArrayList<>();
// 按空行分割文档为段落(两个换行符之间的内容)
String[] paragraphs = content.split("\\n\\s*\\n");
// 当前正在构建的块的内容列表
List<String> currentChunk = new ArrayList<>();
// 当前块的总字符数
int currentLength = 0;
// 当前块的索引
int chunkIndex = 0;
// 遍历每个段落
for (String paragraph : paragraphs) {
// 去除首尾空格
String trimmedParagraph = paragraph.trim();
// 如果段落为空,跳过
if (trimmedParagraph.isEmpty()) continue;
// 计算当前段落的长度
int paragraphLength = trimmedParagraph.length();
// 如果当前块加上新段落会超过限制,且当前块不为空
if (currentLength + paragraphLength > ragProperties.getChunkSize() && !currentChunk.isEmpty()) {
// 将当前块的内容用两个换行符连接起来
String chunkContent = String.join("\n\n", currentChunk);
// 创建文档块并添加到列表
chunks.add(createChunk(chunkContent, documentId, fileName, chunkIndex++));
// 保留重叠部分:取当前块的最后一部分作为下一个块的开始
int overlapStart = Math.max(0, currentChunk.size() - 1); // 取最后一个段落
currentChunk = new ArrayList<>(currentChunk.subList(overlapStart, currentChunk.size()));
// 重新计算当前长度
currentLength = currentChunk.stream().mapToInt(String::length).sum();
}
// 将当前段落添加到块中
currentChunk.add(trimmedParagraph);
// 更新当前长度
currentLength += paragraphLength;
}
// 处理最后一个块(循环结束后可能还有未保存的内容)
if (!currentChunk.isEmpty()) {
String chunkContent = String.join("\n\n", currentChunk);
chunks.add(createChunk(chunkContent, documentId, fileName, chunkIndex));
}
// 输出日志:文档被分割成了多少个块
log.info("文档 {} 分割为 {} 个块", documentId, chunks.size());
// 返回分割结果
return chunks;
}
/**
* 创建文档块对象
*/
private DocumentChunk createChunk(String content, String documentId, String fileName, int chunkIndex) {
// 生成块的唯一ID:文档ID_chunk_块索引
String chunkId = documentId + "_chunk_" + chunkIndex;
// 创建并返回DocumentChunk对象
return new DocumentChunk(chunkId, content, documentId, fileName, chunkIndex, null);
}
}
java
@Service
@Slf4j
public class FileProcessingService {
/**
* 从各种格式的文件中提取文本内容
* @param file 上传的文件
* @return 提取的文本内容
*/
public String extractTextFromFile(MultipartFile file) {
try {
// 创建Tika对象(文档解析工具)
Tika tika = new Tika();
// 设置最大文本长度限制为10MB
tika.setMaxStringLength(10 * 1024 * 1024);
// 从文件输入流中解析文本内容
return tika.parseToString(file.getInputStream());
} catch (Exception e) {
// 如果解析失败,抛出运行时异常
throw new RuntimeException("文件解析失败: " + e.getMessage(), e);
}
}
/**
* 生成文档的唯一ID
* @param filename 原始文件名
* @return 生成的文档ID
*/
public String generateDocumentId(String filename) {
// 将文件名中的非法字符替换为下划线
String baseName = filename.replaceAll("[^a-zA-Z0-9.-]", "_");
// 在文件名后加上时间戳,确保唯一性
return baseName + "_" + System.currentTimeMillis();
}
}
java
@Service
@Slf4j
public class VectorStoreService {
// Spring AI的向量存储接口
private final VectorStore vectorStore;
// 配置属性
private final RagProperties ragProperties;
// 构造函数注入
public VectorStoreService(VectorStore vectorStore, RagProperties ragProperties) {
this.vectorStore = vectorStore;
this.ragProperties = ragProperties;
}
/**
* 存储文档块到向量数据库
* @param chunks 文档块列表
*/
public void storeDocumentChunks(List<DocumentChunk> chunks) {
try {
// 将我们的DocumentChunk列表转换为Spring AI的Document列表
List<Document> documents = chunks.stream()
.map(DocumentChunk::toSpringAiDocument) // 使用方法引用进行转换
.collect(Collectors.toList()); // 收集为List
// 调用向量存储的add方法存储文档
vectorStore.add(documents);
// 输出成功日志
log.info("成功存储 {} 个文档块到向量数据库", chunks.size());
} catch (Exception e) {
// 输出错误日志
log.error("存储文档块到向量数据库失败", e);
// 抛出运行时异常
throw new RuntimeException("存储失败", e);
}
}
/**
* 相似性搜索(使用默认的topK值)
* @param query 查询文本
* @return 相关的文档块列表
*/
public List<DocumentChunk> similaritySearch(String query) {
// 调用重载方法,使用配置中的默认topK值
return similaritySearch(query, ragProperties.getTopK());
}
/**
* 相似性搜索(指定topK值)
* @param query 查询文本
* @param topK 返回的最相关文档数量
* @return 相关的文档块列表
*/
public List<DocumentChunk> similaritySearch(String query, int topK) {
try {
// 调用向量存储的相似性搜索方法
List<Document> documents = vectorStore.similaritySearch(
// 创建搜索请求:查询文本 + 返回数量
SearchRequest.query(query).withTopK(topK)
);
// 将Spring AI的Document转换回我们的DocumentChunk
return documents.stream()
.map(DocumentChunk::fromSpringAiDocument) // 转换每个Document
.collect(Collectors.toList()); // 收集为List
} catch (Exception e) {
log.error("向量搜索失败", e);
throw new RuntimeException("搜索失败", e);
}
}
/**
* 获取统计信息
* @return 统计信息Map
*/
public Map<String, Object> getStats() {
// 创建统计信息Map
Map<String, Object> stats = new HashMap<>();
// 添加向量存储类型
stats.put("vectorStore", "RedisVectorStore");
// 添加索引名称
stats.put("indexName", ragProperties.getVectorIndexName());
// 返回统计信息
return stats;
}
}
java
// @Service:标记为Spring的服务组件
@Service
// @Slf4j:自动注入日志对象
@Slf4j
public class RagService {
// 向量存储服务,用于搜索相关文档
private final VectorStoreService vectorStoreService;
// Spring AI的聊天客户端,用于调用大模型
private final ChatClient chatClient;
// RAG配置属性
private final RagProperties ragProperties;
// 构造函数注入依赖
public RagService(VectorStoreService vectorStoreService,
ChatClient chatClient,
RagProperties ragProperties) {
this.vectorStoreService = vectorStoreService;
this.chatClient = chatClient;
this.ragProperties = ragProperties;
}
/**
* 回答问题(使用默认配置)
*/
public RagResponse answerQuestion(String question) {
// 调用重载方法,不指定文档过滤
return answerQuestion(question, null);
}
/**
* 回答问题(可以指定文档过滤)
* @param question 用户问题
* @param documentFilter 文档过滤器,只在这个文档中搜索
* @return RAG响应结果
*/
public RagResponse answerQuestion(String question, String documentFilter) {
// 记录开始时间,用于计算性能
long startTime = System.currentTimeMillis();
try {
// 1. 检索相关文档片段 =================================
List<DocumentChunk> relevantChunks;
if (documentFilter != null && !documentFilter.trim().isEmpty()) {
// 如果指定了文档过滤,就在指定文档中搜索
relevantChunks = vectorStoreService.similaritySearchWithFilter(question, documentFilter);
} else {
// 否则在所有文档中搜索
relevantChunks = vectorStoreService.similaritySearch(question);
}
// 记录检索完成时间
long retrievalTime = System.currentTimeMillis();
// 2. 构建上下文和提示 ================================
// 将检索到的文档块组合成上下文文本
String context = buildContext(relevantChunks);
// 调用大模型生成答案
ChatResponse chatResponse = generateAnswer(question, context);
// 记录生成完成时间
long generationTime = System.currentTimeMillis();
// 3. 构建响应对象 ===================================
return RagResponse.builder()
.question(question) // 用户问题
.answer(chatResponse.getResult().getOutput().getContent()) // 模型生成的答案
.contextChunks(relevantChunks) // 使用的参考文档
.retrievalTime(retrievalTime - startTime) // 检索耗时(毫秒)
.generationTime(generationTime - retrievalTime) // 生成耗时(毫秒)
.totalTime(generationTime - startTime) // 总耗时(毫秒)
.sourceCount(relevantChunks.size()) // 使用的文档数量
.documentFilter(documentFilter) // 文档过滤器
.build(); // 构建响应对象
} catch (Exception e) {
// 如果发生异常,记录错误日志
log.error("RAG问答失败", e);
// 抛出业务异常
throw new RuntimeException("问答服务暂时不可用: " + e.getMessage());
}
}
/**
* 构建上下文文本
* @param chunks 相关的文档块列表
* @return 组合后的上下文文本
*/
private String buildContext(List<DocumentChunk> chunks) {
// 如果没有找到相关文档
if (chunks.isEmpty()) {
return "没有找到相关的上下文信息。";
}
// 使用StringBuilder高效拼接字符串
StringBuilder contextBuilder = new StringBuilder();
// 添加上下文说明
contextBuilder.append("请参考以下上下文信息来回答问题:\n\n");
// 遍历所有相关文档块
for (int i = 0; i < chunks.size(); i++) {
// 获取当前文档块
DocumentChunk chunk = chunks.get(i);
// 添加来源标识(序号和文件名)
contextBuilder.append(String.format("【来源%d - %s】\n",
i + 1, chunk.getFileName()));
// 添加文档内容
contextBuilder.append(chunk.getContent());
// 添加块之间的分隔符
contextBuilder.append("\n\n");
}
// 返回构建好的上下文文本
return contextBuilder.toString();
}
/**
* 调用大模型生成答案
* @param question 用户问题
* @param context 上下文信息
* @return 聊天响应
*/
private ChatResponse generateAnswer(String question, String context) {
// 创建提示(Prompt)对象,包含系统指令和用户问题
// 系统消息:设定AI的角色和行为规则
Message systemMessage = new SystemPromptTemplate("""
你是一个专业的AI助手,请根据以下参考上下文来回答问题。
{context}
请遵循以下要求:
1. 答案必须基于上述上下文,不要编造不存在的信息
2. 如果上下文不足以回答问题,请明确说明哪些信息缺失
3. 答案要简洁明了,重点突出
4. 可以适当引用上下文中的关键信息
""").createMessage( // 创建消息对象
Map.of("context", context) // 替换模板中的{context}变量
);
// 用户消息:用户的具体问题
Message userMessage = new UserPromptTemplate("{question}")
.createMessage(Map.of("question", question)); // 替换模板中的{question}变量
// 创建提示对象,包含系统消息和用户消息
Prompt prompt = new Prompt(
Arrays.asList(systemMessage, userMessage) // 消息列表
);
// 调用聊天客户端生成回答
return chatClient.call(prompt);
}
/**
* RAG响应内部类 - 用于封装返回给前端的数据
*/
// @Data:自动生成getter、setter等方法
@Data
// @Builder:提供建造者模式,方便创建对象
@Builder
public static class RagResponse {
private String question; // 用户提出的问题
private String answer; // AI生成的答案
private List<DocumentChunk> contextChunks; // 使用的参考文档块
private Long retrievalTime; // 检索阶段耗时(毫秒)
private Long generationTime; // 生成阶段耗时(毫秒)
private Long totalTime; // 总耗时(毫秒)
private Integer sourceCount; // 使用的文档块数量
private String documentFilter; // 文档过滤器
}
}
java
@Service
@Slf4j
public class DocumentManagementService {
// 文本分割服务
private final DocumentSplitterService splitterService;
// 文件处理服务
private final FileProcessingService fileProcessingService;
// 向量存储服务
private final VectorStoreService vectorStoreService;
// 构造函数注入
public DocumentManagementService(DocumentSplitterService splitterService,
FileProcessingService fileProcessingService,
VectorStoreService vectorStoreService) {
this.splitterService = splitterService;
this.fileProcessingService = fileProcessingService;
this.vectorStoreService = vectorStoreService;
}
/**
* 处理上传的文档
* @param file 上传的文件
* @param customDocumentId 自定义文档ID(可选)
* @return 处理结果
*/
public DocumentProcessResult processDocument(MultipartFile file, String customDocumentId) {
try {
// 1. 提取文本内容 ===================================
// 调用文件处理服务从文件中提取文本
String content = fileProcessingService.extractTextFromFile(file);
// 2. 生成文档ID =====================================
// 如果提供了自定义文档ID就使用,否则自动生成
String documentId = customDocumentId != null ? customDocumentId :
fileProcessingService.generateDocumentId(file.getOriginalFilename());
// 获取原始文件名
String fileName = file.getOriginalFilename();
// 3. 分割文档 =======================================
// 将长文档分割成多个小文本块
List<DocumentChunk> chunks = splitterService.splitDocument(content, documentId, fileName);
// 4. 存储到向量数据库 ================================
// 将文档块转换为向量并存储到Redis
vectorStoreService.storeDocumentChunks(chunks);
// 返回成功结果
return DocumentProcessResult.builder()
.success(true) // 处理成功
.documentId(documentId) // 文档ID
.fileName(fileName) // 文件名
.chunkCount(chunks.size()) // 分割的块数
.message("文档处理成功") // 成功消息
.build(); // 构建结果对象
} catch (Exception e) {
// 如果处理失败,记录错误日志
log.error("文档处理失败", e);
// 返回失败结果
return DocumentProcessResult.builder()
.success(false) // 处理失败
.message("文档处理失败: " + e.getMessage()) // 错误消息
.build();
}
}
/**
* 文档处理结果内部类
*/
@Data
@Builder
public static class DocumentProcessResult {
private boolean success; // 是否处理成功
private String documentId; // 文档ID
private String fileName; // 文件名
private Integer chunkCount; // 分割的块数
private String message; // 处理消息
}
}控制器层
java
// @RestController:标记为RESTful控制器,返回JSON数据
@RestController
// @RequestMapping:设置控制器的基础路径
@RequestMapping("/api/rag")
@Slf4j
public class RagController {
// RAG服务,处理问答逻辑
private final RagService ragService;
// 文档管理服务,处理文档上传
private final DocumentManagementService documentManagementService;
// 向量存储服务,获取统计信息
private final VectorStoreService vectorStoreService;
// 构造函数注入
public RagController(RagService ragService,
DocumentManagementService documentManagementService,
VectorStoreService vectorStoreService) {
this.ragService = ragService;
this.documentManagementService = documentManagementService;
this.vectorStoreService = vectorStoreService;
}
/**
* 处理问答请求
* POST /api/rag/query
*/
// @PostMapping:处理HTTP POST请求
@PostMapping("/query")
// ResponseEntity:封装HTTP响应,包括状态码、头部和主体
// @RequestBody:将请求体中的JSON数据绑定到QueryRequest对象
public ResponseEntity<ApiResponse<RagService.RagResponse>> query(
@RequestBody QueryRequest request) {
try {
// 调用RAG服务回答问题
RagService.RagResponse response = ragService.answerQuestion(
request.getQuestion(), // 用户问题
request.getDocumentFilter() // 文档过滤器
);
// 返回成功响应
return ResponseEntity.ok(ApiResponse.success(response));
} catch (Exception e) {
// 记录错误日志
log.error("查询处理失败", e);
// 返回错误响应(HTTP 400 Bad Request)
return ResponseEntity.badRequest()
.body(ApiResponse.error(e.getMessage()));
}
}
/**
* 处理文档上传请求
* POST /api/rag/upload
*/
@PostMapping("/upload")
// @RequestParam:获取请求参数
public ResponseEntity<ApiResponse<DocumentManagementService.DocumentProcessResult>> uploadDocument(
@RequestParam("file") MultipartFile file, // 文件参数,必须提供
@RequestParam(value = "documentId", required = false) String documentId) { // 文档ID,可选
try {
// 调用文档管理服务处理上传的文件
DocumentManagementService.DocumentProcessResult result =
documentManagementService.processDocument(file, documentId);
// 根据处理结果返回不同的HTTP状态
if (result.isSuccess()) {
// 处理成功,返回200 OK
return ResponseEntity.ok(ApiResponse.success(result));
} else {
// 处理失败,返回400 Bad Request
return ResponseEntity.badRequest()
.body(ApiResponse.error(result.getMessage()));
}
} catch (Exception e) {
// 记录异常日志
log.error("文档上传处理失败", e);
// 返回错误响应
return ResponseEntity.badRequest()
.body(ApiResponse.error("文档处理失败: " + e.getMessage()));
}
}
/**
* 获取系统统计信息
* GET /api/rag/stats
*/
@GetMapping("/stats")
public ResponseEntity<ApiResponse<Map<String, Object>>> getStats() {
try {
// 获取向量存储的统计信息
Map<String, Object> stats = vectorStoreService.getStats();
// 返回成功响应
return ResponseEntity.ok(ApiResponse.success(stats));
} catch (Exception e) {
// 返回错误响应
return ResponseEntity.badRequest()
.body(ApiResponse.error("获取统计信息失败"));
}
}
/**
* 查询请求数据内部类
*/
@Data
public static class QueryRequest {
// @NotBlank:验证注解,确保字符串不为null且不为空
@NotBlank
private String question; // 用户问题
private String documentFilter; // 文档过滤器(可选)
}
/**
* 统一API响应格式内部类
*/
@Data
public static class ApiResponse<T> {
private boolean success; // 是否成功
private String message; // 响应消息
private T data; // 响应数据(泛型)
private long timestamp = System.currentTimeMillis(); // 时间戳
/**
* 创建成功响应
*/
public static <T> ApiResponse<T> success(T data) {
// 创建响应对象
ApiResponse<T> response = new ApiResponse<>();
response.setSuccess(true); // 设置成功状态
response.setMessage("成功"); // 设置成功消息
response.setData(data); // 设置响应数据
return response;
}
/**
* 创建错误响应
*/
public static <T> ApiResponse<T> error(String message) {
ApiResponse<T> response = new ApiResponse<>();
response.setSuccess(false); // 设置失败状态
response.setMessage(message); // 设置错误消息
return response;
}
}
}七:tool calling 和 MCP
1:tool calling
tool calling就是让大语言模型具备调用外部工具的能力。你可以把它想象成给一个博学但"手无缚鸡之力"的学者(LLM)配了一个万能工具箱和一群助手。
- LLM的局限:纯LLM只能处理和生成文本。它知道"查询天气"需要调用API,但它自己无法执行网络请求;它知道"发送邮件"的步骤,但它无法连接SMTP服务器。
- Tool Calling的突破:通过Tool Calling,LLM可以分析用户的请求,判断出需要调用哪个工具,并生成符合该工具要求的结构化参数。然后,由应用程序来真正执行这个工具调用,并将结果返回给LLM,最后由LLM整合信息,生成对用户友好的回复。
Spring AI Alibaba的Tool Calling遵循一个清晰的工作流,其核心是围绕 AiStream 和 ToolCall 等抽象进行的。
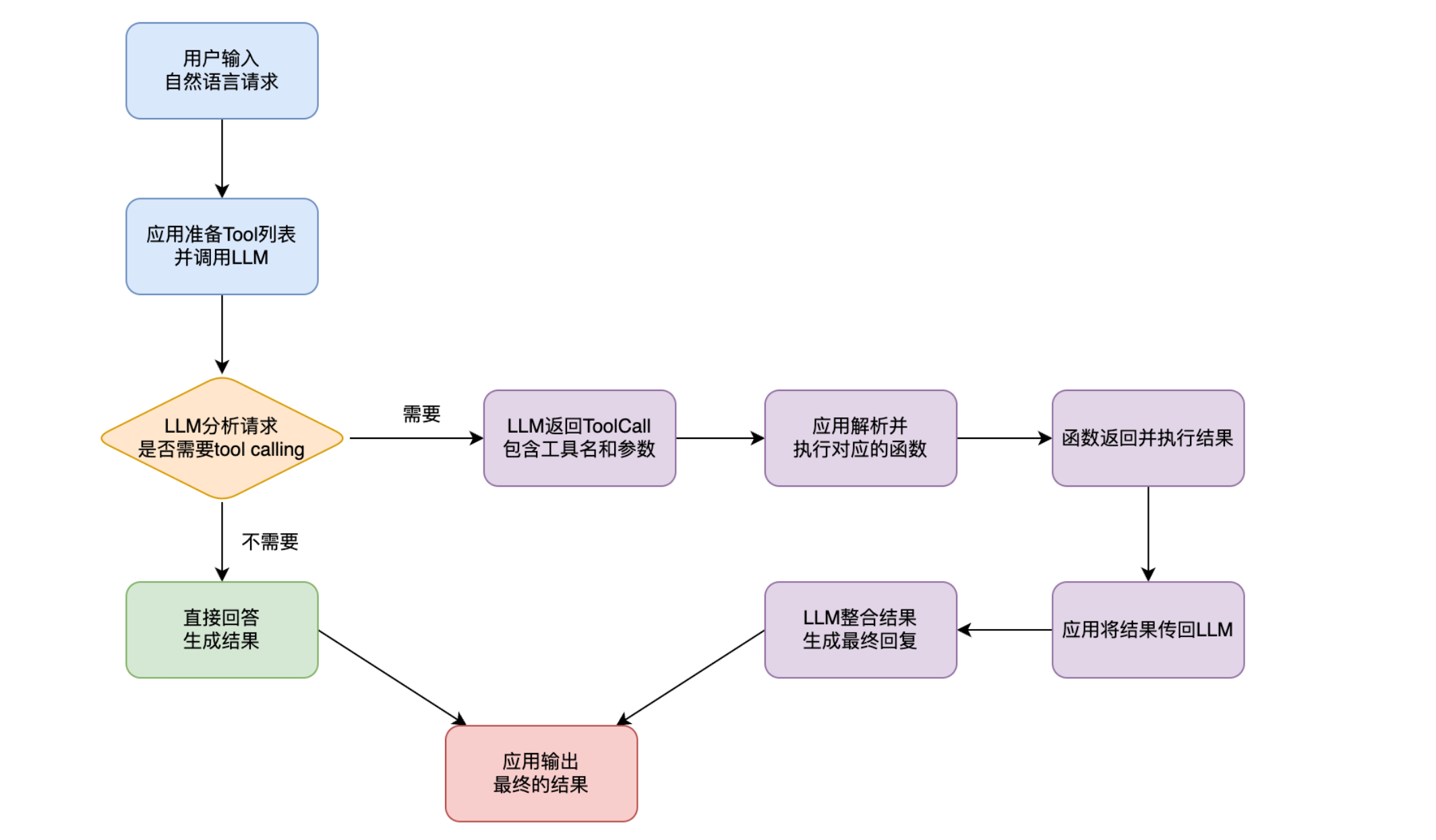
定义tool
java
package com.cui.utils;
import org.springframework.ai.tool.annotation.Tool;
import java.time.LocalDateTime;
public class TimeTool {
/**
* tool call -> 定义tool
*/
@Tool(description = "获取当前时间", returnDirect = false)
public String getCurrentTime() {
return LocalDateTime.now().toString();
}
}
java
package com.cui.utils;
import org.springframework.ai.tool.annotation.Tool;
public class WeatherTool {
/**
* 获取指定城市未来三天的天气预报
*/
@Tool(description = "获取指定城市未来三天的天气预报", returnDirect = false)
public String getWeatherForecast(String city) {
// 模拟返回未来三天的天气数据
StringBuilder forecast = new StringBuilder();
forecast.append(city).append("未来三天天气预报:\n");
forecast.append("第一天: 晴天, 温度 25-30°C\n");
forecast.append("第二天: 多云, 温度 23-28°C\n");
forecast.append("第三天: 小雨, 温度 20-25°C");
return forecast.toString();
}
}注册和调用
java
package com.cui.controller;
import com.cui.utils.TimeTool;
import com.cui.utils.WeatherTool;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.model.tool.ToolCallingChatOptions;
import org.springframework.ai.support.ToolCallbacks;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/saa/tool")
public class ToolCallController {
@Resource(name = "deepseek")
private ChatModel deepseek;
@GetMapping("/nonTool")
public String nonToolTest(@RequestParam(value = "msg", defaultValue = "请问现在几点了") String msg) {
Prompt prompt = new Prompt(msg);
return deepseek.call( prompt ).getResult().getOutput().getText();
}
@GetMapping("/tool_test")
public String toolTest(@RequestParam(value = "msg", defaultValue = "现在几点") String msg) {
// 1.工具注册到工具集合里
ToolCallback[] tools = ToolCallbacks.from(
new TimeTool(), new WeatherTool()
);
// 2.将工具集配置进ChatOptions对象
ChatOptions options = ToolCallingChatOptions.builder().toolCallbacks(tools).build();
// 3.构建提示词
Prompt prompt = new Prompt(msg, options);
// 4.调用大模型
return deepseek.call(prompt).getResult().getOutput().getText();
}
}2:MCP
MCP => MCP 的全称是 Model Context Protocol。这是一个由Anthropic提出的开放协议,旨在标准化LLM与应用/工具之间的交互方式。
在Spring AI Alibaba出现之前,你可能需要为不同的模型(OpenAI, Anthropic, 阿里云等)编写不同的工具调用适配代码,因为它们各自的Function Calling实现略有差异。MCP试图解决这个问题。
你可以将MCP理解为工具调用领域的"JDBC":
- JDBC:为Java应用提供了连接各种数据库(MySQL, PostgreSQL, Oracle)的统一接口。
- MCP:为LLM提供了调用各种后端工具(数据库、文件系统、API)的统一接口。
MCP的核心架构包含两个主要部分:
MCP 客户端:通常是LLM本身或与LLM交互的应用(比如你的Spring AI应用)。它负责发起工具调用请求。
MCP 服务器:提供具体工具实现的服务器。它管理着一组可用的工具(Resources、Tools),并等待客户端的调用。一个MCP服务器可以同时提供多个工具。

百炼的MCP广场
Spring AI项目正在积极地将MCP协议集成到其抽象层中。对于Spring AI Alibaba而言,这意味着:
未来,你可以这样使用工具:
- 连接MCP服务器:你的Spring AI应用(作为MCP客户端)配置连接到一个或多个MCP服务器。例如:
- 一个专门提供数据库操作的
database-mcp-server。 - 一个专门提供公司内部CRM API的
crm-mcp-server。 - 一个专门处理文件的
filesystem-mcp-server。
- 一个专门提供数据库操作的
- 自动工具发现:在启动时,你的Spring应用会自动从这些MCP服务器拉取可用的工具列表。你无需再使用
@Bean来手动注册每个FunctionCallback。 - 透明调用:当用户提问时,Spring AI Alibaba会将所有从MCP服务器发现的工具描述一并发送给LLM。LLM选择工具后,产生的
ToolCall会被Spring AI框架自动路由到对应的MCP服务器执行,并将结果返回。
| 特性 | Tool Calling (Spring AI Alibaba) | MCP (Model Context Protocol) |
|---|---|---|
| 层级 | 框架层实现 | 协议层标准 |
| 范围 | 主要针对单个应用内的工具管理。 | 跨应用、跨语言的工具生态。 |
| 耦合性 | 工具与Spring应用紧密耦合(通过@Bean)。 |
工具与LLM应用完全解耦,通过MCP Server连接。 |
| 灵活性 | 修改工具需要重启应用。 | 可以动态地添加、移除MCP Server,工具热更新。 |
| 当前状态 | 现在即可用,是使用Spring AI Alibaba进行工具调用的主要方式。 | 正在快速集成和发展中,是未来的方向,提供了更高的标准化和扩展性。 |
简单来说:你现在用Spring AI Alibaba的Tool Calling来构建功能强大的AI应用。而MCP是未来的蓝图,它承诺让你的应用能够以更标准、更松散的方式接入一个无限可能的工具世界。
所以,立即上手的是Tool Calling, MCP是未来的宏伟蓝图,代表了工具调用领域的未来趋势。它预示着工具生态的标准化和专业化, 我们应该时刻关注MCP的发展