21 Machine Learning Development Process
21.1 Iterative Loop of ML Development
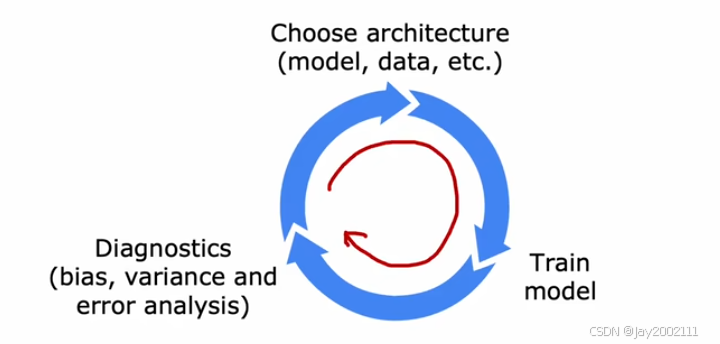
21.2 Error Analysis
对于验证集中失败的case,检测并归纳总结共性的错误原因,优先处理比例大的。
如果验证集较大无法人工检查所有的case,随机抽取其中的一部分进行查看
21.3 Adding Data
数据增强(Data Augmentation):修改已有的训练数据来创建新的训练数据,例如一个字母A的图像,将其旋转、调整大小等
数据合成(Data Synthesis):通常只用于CV,人工合成生成数据,例如文本编辑器生成文本并对截图进行一些扭曲等操作,用于OCR的训练
注:模型效果的提升不仅仅可以通过改变模型设计来实现,往往也可以通过优化训练数据来实现
21.4 Transfer Learning: Using Data from a Different Task
迁移学习
适用场景:自身任务的数据量不足,借用其他类似任务的数据帮助训练
核心思想:除了输出层,借用类似任务的其他层的已训练好的参数,在此基础上用自己的数据的训练优化
两个策略:
- 只训练输出层参数
- 训练所有层参数,但其他层参数的初始值使用类似任务的已训练的参数
策略1一般适用于数据集很小的情况,如果规模稍大一些,通常策略2会更好
注:这种先在大数据集上预训练,叫作有监督预训练(Supervised Pretraining),再在小数据集上进一步调整参数,叫作微调(Fine Tuning)
21.5 Full Cycle of a Machine Learning Project
- 确定任务的Scope
- 收集数据并构建数据集
- 训练模型
- 部署,并持续监控性能
注: - 训练模型的过程中,可以通过错误分析,反过来补充或调整数据集
- 部署的过程中,也可以通过线上的数据和表现,反过来补充和调整数据集,以及优化模型
21.6 Fairness, Bias, and Ethics 公平,偏见,伦理
多元化
在部署前做检查
22 Skewed Datasets 倾斜数据集
22.1 Error Metrics for Skewed Datasets
如果数据集中的正负样本比例失调,这种情况下正确率这个指标并不能很好地反映模型的效果
例如:识别罕见疾病,即使是全预测成0的模型,也能正确率很高
引入概念:准确率Precison ,召回率Recall
| ↓ Predicted Class \ Actual Class → | 1 | 0 |
|---|---|---|
| 1 | True Positive 真阳 | False Positive 假阳 |
| 0 | False Negative 假阴 | True Negative 真阴 |
Precision=True Positiveall predicted positive=True PositiveTrue Positive + False PositiveRecall=True Positiveall actual positive=True PositiveTrue Positive + False Negative\begin{aligned} \text{Precision} &= \frac {\text{True Positive}} {\text{all predicted positive}} &= \frac {\text{True Positive}} {\text{True Positive } + \text{ False Positive}} \\ \text{Recall} &= \frac {\text{True Positive}} {\text{all actual positive}} &= \frac {\text{True Positive}} {\text{True Positive } + \text{ False Negative}} \end{aligned}PrecisionRecall=all predicted positiveTrue Positive=all actual positiveTrue Positive=True Positive + False PositiveTrue Positive=True Positive + False NegativeTrue Positive
Precision反映了预测的所有正例中正确的比例,Recall反映了真正的正例中能预测对的比例。
22.2 Trading off Precision and Recall
阈值的选择:通常用0.5来作为判断的阈值,但如果阈值调大,准确率会上升,召回率会下降,反之亦然
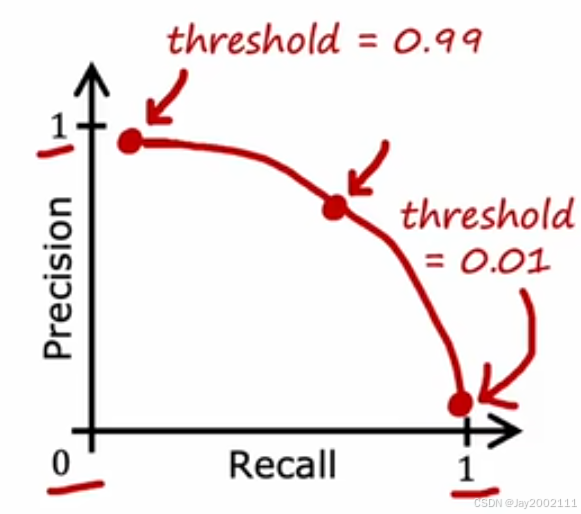
两者之间需要进行权衡
注:选择阈值不能通过交叉验证集来完成
如何量化权衡指标 --> 合二为一,引入 F1 Score (调和平均值 ,更强调两者中较低的值不能过低)
F1 score=112(1Precision+1Recall)=2⋅PRP+RF_1 \space score = \frac {1} {\frac 1 2 (\frac 1 {\text{Precision}} + \frac 1 {\text{Recall}})} = 2 \cdot \frac {PR} {P + R}F1 score=21(Precision1+Recall1)1=2⋅P+RPR