0 介绍
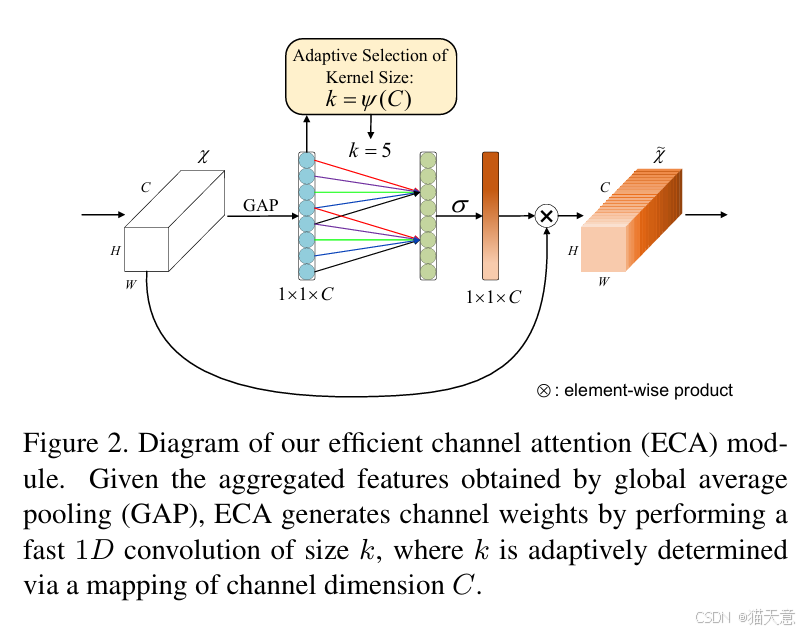
ECA-Net(Efficient Channel Attention for Deep Convolutional Neural Networks)是2020年提出的轻量级通道注意力机制,核心目标是在极低计算与参数开销下提升深度卷积网络的特征表达能力,其设计针对经典通道注意力机制(如SENet)的缺陷优化,核心思想可概括为4点:
- 移除降维操作,保留通道信息完整性
经典SENet通过"降维-激活-升维"的全连接层结构捕获通道依赖,但降维会造成通道特征信息丢失。ECA-Net完全舍弃降维环节,直接在原始通道维度(1×1×C)上处理特征,通过一维卷积实现通道交互,全程保持通道维度不变,避免信息损耗。 - 自适应一维卷积核,捕捉局部通道依赖
ECA-Net认为通道间依赖具有局部性,无需全局交互。其通过指数映射函数自适应确定一维卷积核大小(k=ψ©,C为通道数),通道数越多卷积核越大,适配不同网络层的通道规模,灵活捕获局部通道依赖,且映射无需额外学习参数。 - 轻量化设计,实现高效计算
相比SENet全连接层的O(C²)复杂度,ECA-Net计算仅3步,复杂度为O(C×k),几乎无额外开销:- 对特征图执行全局平均池化,得到1×1×C的通道特征向量;
- 用核大小为k的一维卷积完成局部通道交互;
- Sigmoid归一化生成注意力权重,与原始特征图相乘完成特征重标定。
模块无全连接层,仅一维卷积含少量参数。
- 即插即用的模块化结构
ECA-Net模块结构简洁,可无缝嵌入ResNet、MobileNet等主流网络 的卷积层或残差块中,无需修改网络整体架构,具备极强通用性,可快速迁移至各类视觉任务。
1 代码
py
import torch
import torch.nn as nn
import math
# ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
# https://arxiv.org/abs/1910.03151
class EfficientChannelAttention(nn.Module):
def __init__(self, c, b=1, gamma=2):
super().__init__()
t = int(abs((math.log(c, 2) + b) / gamma)) #
k = t if t % 2 else t + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = nn.Conv1d(1, 1, kernel_size=k, padding=int(k / 2), bias=False)
self.sigmoid = nn.Sigmoid()
# B C H W
def forward(self, x):
out = self.avg_pool(x) # [1, 3, 1, 1]
print(out)
out = self.conv1(out.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) # [1,3,1,1] -> [1,3,1] -> [1,1,3] -> [1,3,1] -> [1,3,1,1]
out = self.sigmoid(out) # [1,3,1,1]
return x * out
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
model = EfficientChannelAttention(3)
print(x.shape)
print(model(x).shape)