SAM 3: Segment Anything with Concepts
- SAM版本对比
- 一、论文详解
-
- 1、背景与动机
- 2、任务扩展:从PVS走向PCS
-
- [(1)引入【可提示概念分割】(Promptable Concept Segmentation,PCS):文本提示(名词短语 NPs) + 图像示例(正/负)](#(1)引入【可提示概念分割】(Promptable Concept Segmentation,PCS):文本提示(名词短语 NPs) + 图像示例(正/负))
- [3、模型架构:共享【感知编码器】 + 解耦【检测器×跟踪器】](#3、模型架构:共享【感知编码器】 + 解耦【检测器×跟踪器】)
-
- [(1)感知编码器PE(new in SAM3):构建统一语义基座](#(1)感知编码器PE(new in SAM3):构建统一语义基座)
- [(2)检测器Detector(new in SAM3):负责概念识别(是什么)](#(2)检测器Detector(new in SAM3):负责概念识别(是什么))
-
- [(2.1)提示条件化编码机制(Prompt-Conditioned Encoding)](#(2.1)提示条件化编码机制(Prompt-Conditioned Encoding))
- [(2.2)图像示例(image examples):单实例提示 → 多概念提示](#(2.2)图像示例(image examples):单实例提示 → 多概念提示)
- [(2.3)引入存在标记(Presence Token):实现识别与定位解耦](#(2.3)引入存在标记(Presence Token):实现识别与定位解耦)
- (2.4)DETR增强机制
- [(3)跟踪器Tracker(from SAM2):维持时序一致性与实例ID](#(3)跟踪器Tracker(from SAM2):维持时序一致性与实例ID)
- 4、数据引擎:新增【概念标签】约400万条正负例
-
- (1)数据引擎组件
- [(2)数据引擎工作流程 ------ 人机协同 + AI辅助](#(2)数据引擎工作流程 —— 人机协同 + AI辅助)
- [(3)提出【SA-Co概念分割基准】用于评估模型性能 ------ 是现有基准的50倍+](#(3)提出【SA-Co概念分割基准】用于评估模型性能 —— 是现有基准的50倍+)
- 二、3D应用扩展
-
- [1、【SAM 3D Objects】通用物体 3D 重建](#1、【SAM 3D Objects】通用物体 3D 重建)
- [2、【SAM 3D Body】人体 3D 姿态与网格重建](#2、【SAM 3D Body】人体 3D 姿态与网格重建)
- 三、项目实战
SAM版本对比
Sam3 是 Meta 最新一代的通用图像分割模型,相比 SAM/SAM2,在推理速度、交互体验与大规模场景泛化上都有显著提升。
| 功能 | SAM | SAM2 | SAM3 |
|---|---|---|---|
| 自动掩码生成 | ✓ | ✓(更好) | ✓(最强) |
| 单点/框选交互 | ✓ | ✓(快) | ✓(接近实时) |
| 视频跟踪 | × | ✓ | ✓(更稳) |
| 3D-aware | × | × | ✓ |
| 训练数据规模 | SA-1B | SA-1B | 扩展版 SA-1B + 新视觉数据 |
| 推理速度 | 中 | 快 | 更快 |
一、论文详解
- 项目主页: https://ai.meta.com/sam3d/
- 体验地址: https://www.aidemos.meta.com/segment-anything
- 论文地址:
- 代码仓库:
- SAM 概念提示: https://github.com/facebookresearch/sam3
- SAM 3D Objects: https://github.com/facebookresearch/sam-3d-objects
- SAM 3D Body: https://github.com/facebookresearch/sam-3d-body
- MHR: https://github.com/facebookresearch/MHR
| 项目 | 内容 |
|---|---|
| 名称 | Segment Anything Model 3(SAM 3) |
| 模型简介 | 面向开放词汇提示的统一图像与视频分割系统,通过 提示式概念分割(PCS) 接收短名词短语、示例图像或组合,为所有匹配实例生成分割掩码及唯一标识。 |
| 发布背景 | 由 Meta 研究团队于 2025 年 11 月推出,继承 SAM 系列,支持开放词汇分割与图像/视频统一处理。 |
| 模型类型 | 统一视觉理解模型(支持检测、实例分割、语义分割、视频分割/跟踪) |
| 核心创新 | 1. 提示式概念分割(PCS)任务与 SA-Co 基准:提出开放词汇概念分割任务,并建立标准化评测基准。 2. 解耦识别、定位与跟踪架构:共享主干网络,独立检测器与视频跟踪器,引入存在头机制,提高检测与分割精度。 3. 多模态提示融合 :统一支持文本、示例图像、点/框/掩码提示。 4. 实例级分割与身份跟踪:保持视频中实例身份连续。 5. 交互式精修机制 :用户可快速提示修正掩码结果。 6. 可扩展训练数据:新增约 400 万条概念标签(含负样本),覆盖图像与视频场景,提升开放词汇概念理解。 |
| 主要能力 | - 图像分割 :基于任意提示生成高质量掩码。 - 视频实例追踪 :保持实例身份连续,长视频漂移小。 - 开放词汇概念识别 :识别并分割大量概念。 - 交互式分割精修:通过点、框或掩码快速微调结果。 |
| 性能与速度 | - 图像分割精度 :相较 SAM2,在自然场景 PCS 任务中 mIoU 或 AP 提升约 2 倍(需具体指标可补充)。 - 视频跟踪精度 :实例身份保持稳定,长视频中漂移小。 - 推理速度 :在标准 GPU(如 A100)上,单张图像推理延迟 < 200 ms(1024×1024 分辨率)。 |
| 典型应用 | 图像/视频标注、复杂场景分割、多目标实例跟踪、示例驱动概念提取、半自动数据标注流程。 |
| 局限性 | 1. 专业/医疗图像迁移 :原模型在自然场景训练,直接用于医学影像或显微图像精度下降,需要微调或结合专业特征。 2. 遮挡与细粒度结构 :极小、遮挡或复杂纹理对象分割精度低于专用模型。 3. 高分辨率计算开销 :全分辨率图像处理需要大显存,限制边缘或低资源设备部署。 4. 极端概念或长尾样本:开箱性能有限,需定制训练或微调。 |
数据集通常呈现头部-尾部分布:
- 头部(Head):少数高频类别,样本数量多,比如猫、狗、汽车等常见物体。
- 尾部(Tail / 长尾):大量低频类别,样本很少,比如稀有动物、特殊工业零件、罕见医学病变。
在分割或识别任务中,模型通常在头部类别表现良好,但 对长尾类别识别能力弱,因为训练数据不足,模型难以学习到稳定特征。处理方法包括:
- 数据增强:增加长尾类别样本数量或生成合成样本。
- 少样本学习 / 零样本学习:通过迁移学习或提示式学习增强模型对长尾概念的识别。
- 重采样或加权损失:在训练时增加长尾类别样本权重,防止被头部类别主导。
1、背景与动机
在视觉系统中,实现 "发现并分割任意物体" 的能力是多模态人工智能的重要基础,支撑机器人、内容生成、增强现实、数据标注与科学计算等关键应用。
- SAM系列(Kirillov et al., 2023;Ravi et al., 2024)通过提出可提示视觉分割(Promptable Visual Segmentation, PVS),首次将点、框或掩码提示 融入图像与视频分割。但前代方法仍局限于 "分割单个目标" ,无法解决基于概念在输入中发现并分割全部实例的通用任务,例如在视频中识别所有"猫"。
2、任务扩展:从PVS走向PCS
SAM 3在可提示视觉分割(Promptable Visual Segmentation,PVS)基础上,对任务形式进行了进一步抽象与扩展,提出可提示概念分割(Promptable Concept Segmentation, PCS)。该任务用于在图像或视频中检测、分割并追踪所有符合指定概念的对象实例,以实现对开放世界视觉概念的系统化处理。
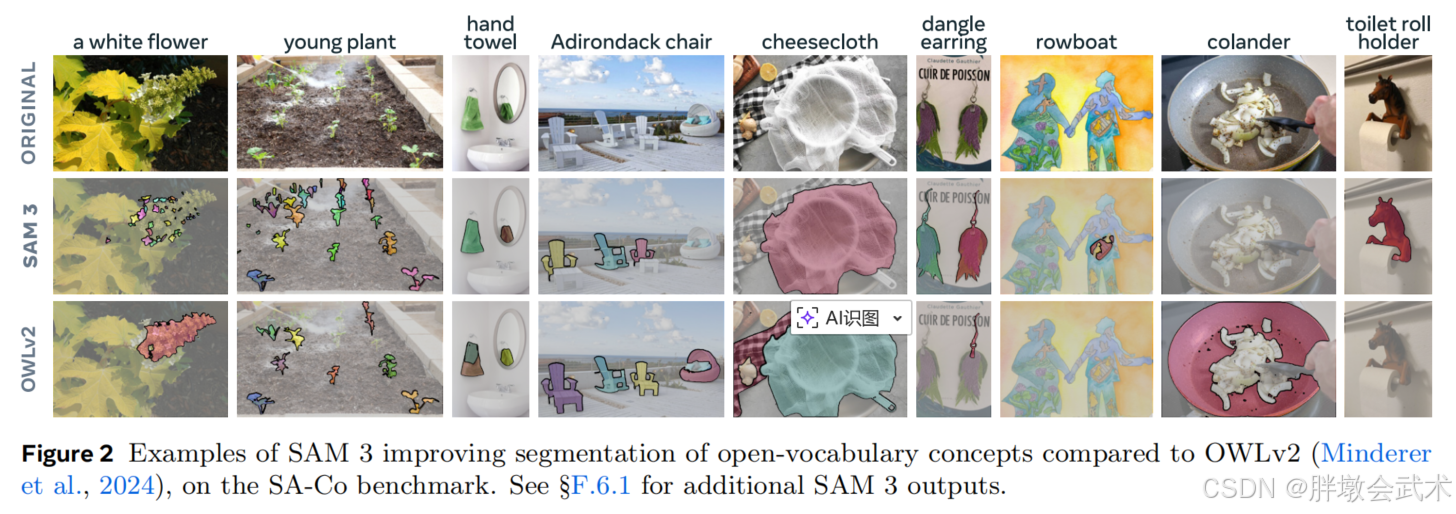
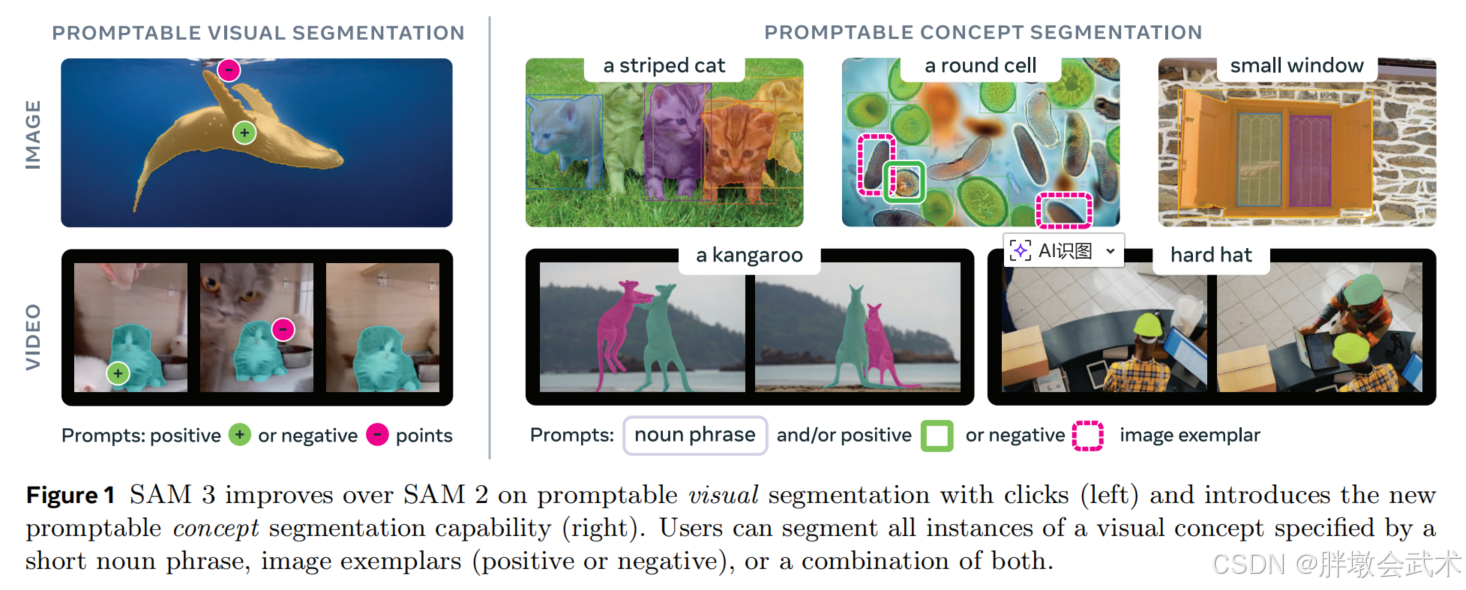
(左)SAM 3较SAM 2,在点击式可提示分割功能上有所改进;
(右)SAM 3引入了可提示概念分割功能,用户可通过简短名词短语、图像示例(正面或负面)或两者的组合来分割指定视觉概念的所有实例。
(1)引入【可提示概念分割】(Promptable Concept Segmentation,PCS):文本提示(名词短语 NPs) + 图像示例(正/负)
任务定义:给定一张图像或一段短视频(≤30秒),模型需在全场景中识别出与指定概念一致的全部对象实例,并生成实例掩码与语义掩码;对于视频任务,还需保持目标身份在跨帧过程中的一致性。
- 输入形式:
文本提示(名词短语 NPs):简短文本由核心名词与可选修饰语构成(如"红苹果""条纹猫")。名词短语提示(若提供)对图像/视频的所有帧具有全局性图像示例(正例/负例):用户可在单帧中提供正例或负例边界框,作为局部约束引导掩码迭代优化(如图3)。图像示例对模型具有补充性,特别适用于稀有概念或模型初识别失败的情形。- 输出形式:
- 对所有匹配概念的对象实例输出
实例掩码 + 语义掩码;- 对视频序列
保持目标身份一致性。- 注意事项:
- SAM 3专注于原子视觉概念 识别,因此文本指令限制为简单名词短语,不涉及长文本或复杂推理。然而,SAM 3可以与多模态大模型(MLLM)组合,用于解析更复杂语义或跨句结构。
- 模型保持完全交互式,允许用户通过增量提示修正歧义并逐步引导模型输出。
(左)初始提示;(右)可选的交互式增强提示
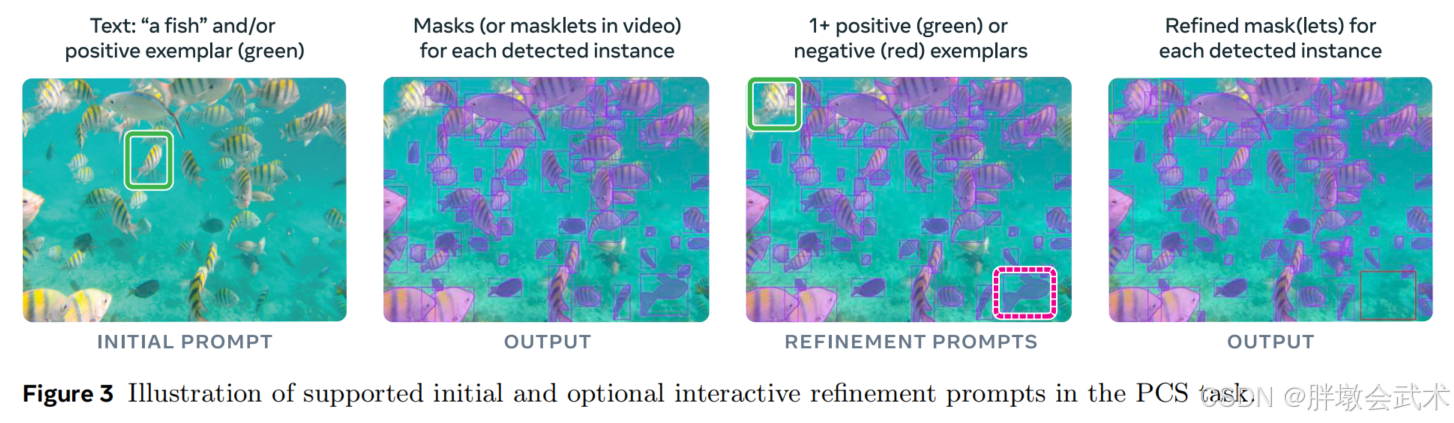
(1.1)引入提示一致性约束PCC
PCS任务要求模型在开放词汇条件下对任意视觉概念进行实例级分割。为避免概念漂移(concept drift)和语义歧义,SAM 3在模型体系中引入提示一致性约束(Prompt Consistency Constraint,PCC),保证所有提示在语义一级上对齐至同一概念空间。
- 1. 约束目标
- 所有提示(文本名词短语 + 图像正负示例)在"概念类别"上保持一致,使模型在不同输入模态间形成稳定的概念映射 。
- 文本提示(NPs) → 提供概念的全局语义锚点
- 图像示例提示 → 在局部区域对概念边界与定义进行实例化细化
- 两者必须指向同一"原子概念"
- 若两类提示存在语义不一致(如文本指向"鱼",示例强调"红色条纹鱼"),模型行为将变得不可定义。因此,当示例对概念区分产生新的语义约束时,需要同步更新文本提示,使其与示例保持一致。
- 2. 约束带来的效果
- 消除跨模态定义差异(semantic mismatch)
- 提升掩码稳定性和跨帧一致性
- 避免示例优化导致的概念收缩(concept shrinkage)或意外泛化(undesired generalization)
- 3. 约束在交互式流程中的作用
- 当模型未能识别长尾实例,或概念在场景中出现频次极低时,图像示例提示具有显著补充价值。此时,提示一致性约束确保示例不会引发概念漂移,而是引导模型对既定概念进行分辨力增强。
(1.2)构建模糊性建模体系
PCS相比PVS具备更高的开放度,其词汇空间允许任何可视名词短语,因此天然包含高维度、不规则的语义模糊性。SAM 3从 "数据→模型→评估" 构建一个完整的模糊性消解系统。
- 模糊性来源:
- 词义多义性:如"鼠标",可能指动物或电脑设备 ------ 模型需要在视觉层面区分同形异义概念。
- 无法具象化的主观语义:如"大、舒适、漂亮" ------ 这些词语缺乏稳定的视觉边界。
- 上下文依赖概念:如"品牌标识""入口" ------ 实例的定义取决于场景功能而非外观形态。
- 对象范围不明确:如"镜子"是否包含镜框、支架?"桌子"是否包含抽屉或装饰物?
- 视觉质量导致的不确定性:遮挡、模糊、运动拖影使边界变得不确定。
- 实例集合模糊:如"堆叠物品"、"人群",应视为多个对象还是单一整体?
- 三层模糊性消解框架:
- ① 数据端:多层级语义控制与一致性增强 ------ 将开放词汇带来的语义模糊最小化,使模型训练过程具备稳定的语义基础。
a.三位专家一致性标注:每个概念实例由三位独立专家标注。采用一致性投票与冲突解析措施,确保视觉定义趋于收敛。b. 精细化标注协议:对容易产生分歧的类别提供明确规范,如:透明与半透明物体的边界定义、复杂结构的主次区分("树干 vs 树冠 vs 整棵树")、人与随身物品的范围划分。c. AI辅助一致性检查:使用微调过的多模态大模型对数据标签进行自动一致性验证,实现数据闭环优化。- ② 模型端:模糊性建模架构 ------ SAM 3 是从"结构"层面对开放世界模糊性进行处理,而非仅依赖数据。核心模块包括:
a. Ambiguity Modeling Module(模糊性建模模块):在概念特征空间中显式建模:概念间的语义重叠区域、概念边界的不确定性区域、低置信度区域的概率分布。通过在训练时注入"不确定性表示(uncertainty embedding)",模型能够对模糊边界做出概率化决策,而非强制单一语义。b. Presence Token(存在标记):解耦"是否存在该对象"与"该对象的几何边界":文本理解层 → 判断概念是否存在、几何预测层 → 对存在的实例进行定位和分割。此结构避免了由于局部几何误差导致的概念识别失败。c. Soft-mask Boundary Modeling:在边界模糊区域引入软标签,使预测保持稳定,不因轻微遮挡或噪声造成抖动。d. 多模态提示融合策略:将文本短语与示例(正例/负例)在统一的概念潜空间中对齐,使示例对概念的细化具有可控影响。- ③ 评估端:引入与人类判断一致的评价策略 ------ PCS的评估相比传统分割任务更接近"语义判断",因此SAM 3在评估体系中引入多个符合人类判断机制的策略。
a. 合理解释集(Acceptable Set):对于语义模糊的概念,允许多个可接受标注被判定为正确,而非单一答案。b. 边界容忍区(Tolerance Band):对边界模糊区域采用柔性度量方法,如:小面积误差不计入、小范围几何漂移不作为错误c. 视频中的跨帧容忍:在跟踪任务中对轻微漂移引入时间维度的容忍度,模拟人类对连续场景的理解。
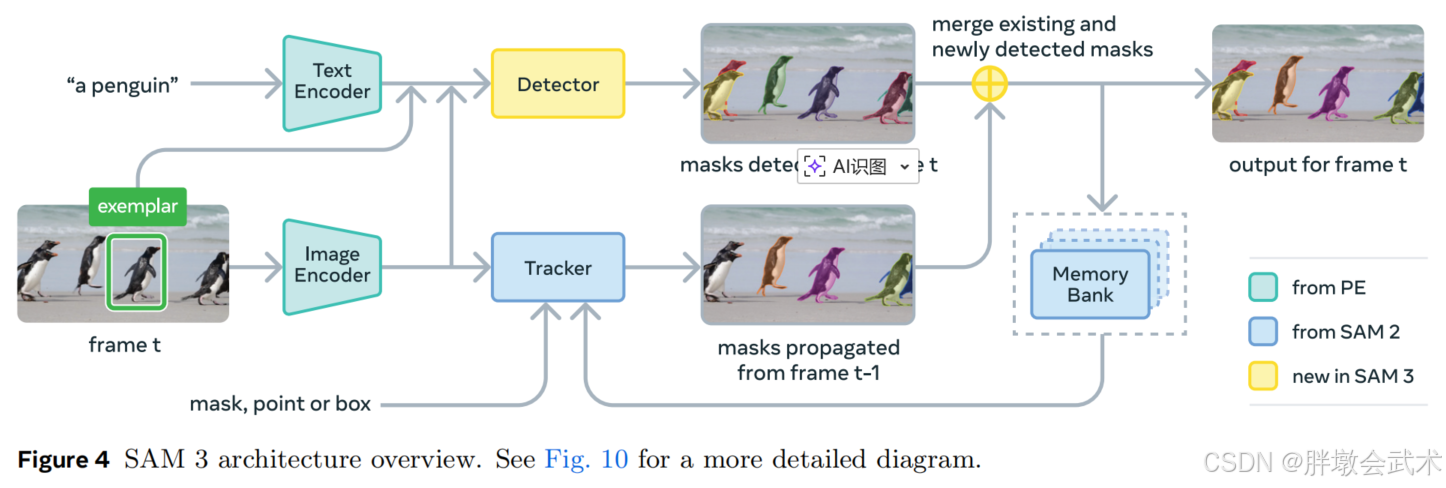
3、模型架构:共享【感知编码器】 + 解耦【检测器×跟踪器】
SAM3在整体设计上实现了检测器(Detector)与跟踪器(Tracker)完全解耦,但二者共享统一的感知编码器PE(Perception Encoder)。这种设计将概念识别与实例身份保持彻底分离,使模型在开放世界场景中保持稳定的空间与时间一致性,同时避免不同子任务间的互相干扰。
核心创新与设计亮点:
共享统一PE:作为视觉--语言对齐的高维语义基座,实现跨帧、跨模态特征一致性。
检测器增强:引入存在标记(Presence Token),实现识别与定位解耦;支持多种提示形式(文本、几何、图像示例)进行开放词汇检测。
图像示例提示升级:从单实例提示扩展为多概念正/负示例,用于开放世界语义消歧。
跟踪器继承并优化SAM2机制:维持跨帧实例ID稳定性,采用双重时间消歧、记忆校正与提示交互,实现视频级一致性。
分阶段训练策略:"检测先行 → 冻结PE → 跟踪训练",保证语义识别与时序跟踪互不干扰。
(1)感知编码器PE:统一语义基座
- PE负责从图像、文本提示、示例掩码等多模态输入中构建一致的表示空间,确保检测器与跟踪器对视觉--语言语义的理解保持对齐。
- 其本质作用是为所有模块提供共享、可跨帧对齐的高维特征表示,使开放词汇条件下的分割成为可能。
(2)检测器:负责语义识别(是什么)
- 根据文本提示、几何提示、示例掩码等输入执行开放词汇检测;
- 输出候选掩码,但不包含实例身份(ID);
- 重点在于概念理解与掩码质量,不介入时序稳定。
(3)跟踪器:负责身份保持(是否为同一实例)
- 利用PE特征执行跨帧匹配与掩码传播;
- 通过记忆库、时间一致性与检测校正实现ID稳定;
- 不负责识别概念,只维持同一对象在视频中的身份连续。
python
输入图像/文本/示例 ──> PE ──> 高维统一特征 ──> 检测器 (概念识别)
└─> 跟踪器 (实例ID维持)
PE 是 检测器和跟踪器共享的语义基座,确保两者语义对齐;
分阶段训练中,PE 在冻结后供跟踪器使用,保证识别与跟踪任务互不干扰。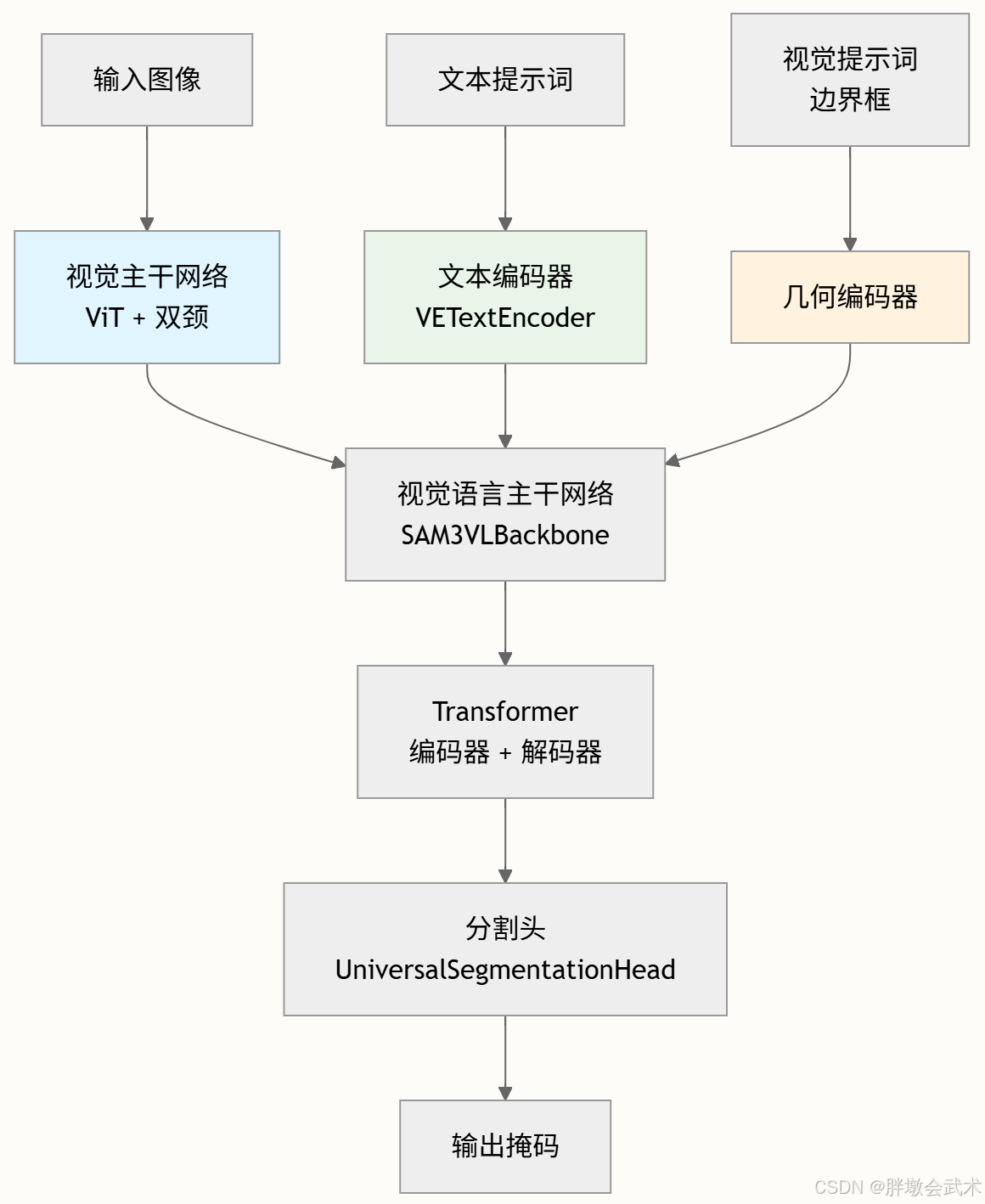
(1)感知编码器PE(new in SAM3):构建统一语义基座
目标:构建一个跨模态、跨帧统一对齐的高维语义表示空间,使图像、文本提示以及示例掩码能够在同一特征坐标系下对齐,保障检测器和跟踪器共享一致的语义基础。
一句话总结:感知编码器(Perception Encoder,PE)是整个 SAM3 的视觉--语言对齐核心,支撑开放世界概念识别与跨帧实例跟踪。
核心目标:
- 多模态对齐:整合图像、文本提示与图像示例特征,实现统一语义空间表示;
- 跨帧一致性:保证视频序列中视觉特征在时间维度上稳定,支持跟踪器实现实例ID连续;
- 开放词汇兼容性:在未见概念或长尾概念条件下,仍能保持概念识别的准确性;
- 子模块共享:为检测器与跟踪器提供可重复使用、可扩展的高维特征,避免重复计算。
- 可扩展示例提示:与图像示例结合,实现概念级消歧、正负示例交互和迭代改进。
输入输出:
- 输入
图像:RGB或多通道图像张量;文本提示:自然语言描述(概念、类别或属性);图像示例/掩码:局部实例正/负示例,提供视觉概念边界。- 输出
高维嵌入特征:
- 跨模态统一表示:图像、文本和示例映射到同一语义空间;
- 跨帧对齐:用于跟踪器记忆编码与掩码传播;
- 检测器友好:可直接输入 DETR 解码器进行开放词汇识别;
- 可扩展性:支持新的提示类型或多概念场景。
PE核心结构与模块:
- 视觉编码器(Vision Encoder)
- Transformer 或卷积 + Transformer 混合结构;
- 提取图像高维语义特征,保持空间分辨率;
- 支持多尺度特征表示,以适应不同大小目标;
- 具备局部感知和全局上下文整合能力。
- 文本编码器(Text Encoder)
- 将自然语言提示映射为语义嵌入;
- 支持长尾、稀有概念语义理解;
- 通过跨模态注意力机制与视觉特征对齐,实现提示语义与图像内容的匹配。
- 示例编码器(Example Encoder)
- 提取图像示例或掩码区域的视觉特征;
- 融入位置编码及正/负标签信息;
- 输出示例提示向量,与文本提示拼接形成统一提示标记;
- 支持概念级消歧及交互式迭代优化。
- 跨模态融合层(Cross-Modal Fusion)
- 将视觉、文本和示例特征投影到统一语义空间;
- 支持与检测器对象查询和跟踪器记忆编码器共享输入;
- 强化语义对齐与提示条件化能力。
- 时间与空间一致性增强模块(Time-Space Consistency)
- 融入时间编码,保证视频序列特征稳定;
- 可选的空间金字塔或多尺度注意力模块,用于尺度鲁棒性和局部--全局信息融合。
(2)检测器Detector(new in SAM3):负责概念识别(是什么)
目标:在开放词汇条件下进行语义识别,输出高质量候选掩码,但不包含实例ID。
检测器承担语义识别与掩码生成任务,不参与实例ID维护。其继承DETR(Deformable Transformer)范式(Carion et al., 2020),但针对开放词汇、多提示融合与语义歧义解决进行了结构升级。
(2.1)提示条件化编码机制(Prompt-Conditioned Encoding)
目标:将各种提示信息与图像特征融合,使 DETR 解码器能够理解具体提示内容,实现跨模态语义锚定,为开放词汇检测提供稳固的概念表示。
提示形式:
- 文本提示:自然语言描述概念、类别或属性
- 几何提示:点或框,提供空间定位信息
- 图像示例:正/负示例区域,用于定义概念边界并支持语义消歧
处理流程:
- 文本提示和图像示例分别由
PE和示例编码器独立编码,生成语义向量;- 所有提示向量被统一转换为
提示标记(prompt tokens);- 提示标记在
融合编码器(Cross-Modal Fusion) 中与图像特征进行 交叉注意力交互;- 融合后的特征输入
类 DETR 解码器,结合可学习对象查询完成跨注意力匹配,生成候选掩码。
核心效果:该机制确保"提示 → 视觉内容"之间的统一语义锚定,为开放词汇检测提供稳固的概念表示。
| 模块 | 核心功能 | 输入 | 输出 | 作用范围 |
|---|---|---|---|---|
| PE(Perception Encoder) | 构建统一语义基座,提供跨模态、跨帧的高维视觉--语言表示 | 图像、文本提示、图像示例/掩码 | 高维嵌入特征(视觉+文本+示例) | 整个模型共享,检测器与跟踪器都使用;跨帧对齐与概念表示基础 |
| 提示条件化编码(Prompt-Conditioned Encoding) | 将提示信息与图像特征融合,使 DETR 解码器能够理解具体的提示内容 | PE输出的图像特征 + 文本提示 + 几何提示(点/框) + 图像示例提示向量 | 融合后的提示条件特征 | 检测器内部机制,用于候选掩码生成;属于"提示到视觉内容"的跨模态匹配过程 |
(2.2)图像示例(image examples):单实例提示 → 多概念提示
目标:将图像示例区域视为一种视觉化的概念提示,由一个局部框与一个二值标签(正/负)构成。与SAM2仅针对单个实例的PVS提示不同,SAM3中的图像示例用于定义概念边界,并检索所有属于该概念的实例。
- 特征构建流程:
- ROI池化提取示例区域视觉特征;
- 融入位置编码与正/负标签嵌入;
- 经小型Transformer处理后,生成示例提示向量;
- 最终与文本提示拼接,形成统一的提示标记,输入检测器进行跨模态匹配。
- 核心价值
正例示例:定义视觉原型:提供目标概念的视觉原型,使模型明确"应该长什么样"。 ------ 用于解决语义歧义(如形状相似的不同物体)。负例示例:限制概念边界:告诉模型"哪些相似对象不属于目标概念"。------ 直接减少假阳性。迭代交互:持续精化概念:用户可根据当前检测结果追加正示例或负示例,实现逐步修正。 ------ 支持交互式细化目标掩码。
一句话总结 :图像示例提示是SAM3开放世界语义消歧的核心机制,将模型从"识别单个目标"升级为"学习一个概念",并通过正负例交互不断精化该概念的检测边界。
(2.3)引入存在标记(Presence Token):实现识别与定位解耦
开放词汇条件下,提示指定的概念可能在图像中完全不存在。如果将"是否存在"与"对象位置"绑定在同一对象查询中,查询会被迫关注全局上下文,从而降低定位精度,并容易在处理否定短语、抽象名词或稀有概念时产生假阳性。
- ① 在整张图中,判断用户提示的概念(如"猫"或"椅子")有没有出现在图像中;
- ② 对象查询仅负责空间定位:若其存在,应在何处;
- 最终得分 = 局部定位得分 × 全局存在得分,从而实现识别与定位的解耦。
该机制显著减少否定短语、抽象名词、稀有概念导致的错误激活。
(2.4)DETR增强机制
为适应开放世界条件,SAM3在检测器中引入多项强化模块:
双监督训练(DAC-DETR,Hu等,2023):提升匹配稳定性;Align损失(Cai等,2024):促使提示嵌入与视觉目标嵌入对齐;Box-Region-Positional Bias(Lin等,2023):强化空间聚焦能力;MaskFormer式掩码头(Cheng等,2021)改进版:生成高质量区域掩码;像素级二分类分割头:辅助提示一致性约束,降低跨提示语义漂移。
(3)跟踪器Tracker(from SAM2):维持时序一致性与实例ID
目标:继承SAM2的视频分割架构,负责保持视频中对象身份ID连续,与检测器形成互补。
① 跟踪流程(单帧传播 × 检测匹配)
给定一个视频序列t与一个提示P,跟踪器按以下流程工作:
t=1(初始化):检测器输出首帧的所有相关掩码{M₁},作为跟踪的起点。t>1(时序更新):
每帧执行三步:
- 传播(Propagation) :跟踪器根据
上一帧掩码 Mₜ₋₁执行 SAM2 风格的单帧掩码传播,生成预测掩码 M̂ₜ;- 检测(Detection) :检测器在当前帧输出新的
潜在实例 Oₜ;- 匹配与融合(Association) :
- 通过 IoU 基准函数将
M̂ₜ 与 Oₜ 关联,形成最终掩码集合 Mₜ;- 未匹配的新检测实例将初始化为新的 "小掩码" 轨迹。
结果:即便存在遮挡、移动或视角剧烈变化,跟踪器仍能维持实例ID的连续性。
② 跟踪器训练策略(检测与跟踪彻底解耦)
SAM3采用分阶段训练,确保语义识别与时空跟踪互不干扰:
- 感知编码器(PE)预训练
- 检测器预训练
- 检测器微调
- 冻结共享的PE,再使用SAM2流程训练跟踪器(包括提示编码器、掩码解码器、记忆编码器、记忆库)
关键组件简介:
掩码解码器:是编码器隐藏状态与输出token之间的双向转换器。为处理歧义,为每帧中每个被追踪对象预测三个输出掩码及其置信度,并选择置信度最高的输出作为当前帧的预测掩码。记忆编码器:是一种Transform结构,其在当前帧的视觉特征上具有自注意力机制,并将视觉特征与记忆库中的空间记忆特征进行交叉注意力。记忆库:使用过去帧和条件帧(对象首次检测或用户提示的帧)的特征对对象的外观进行编码。该策略确保检测器专注语义识别,跟踪器专注时空一致性,避免两个任务互相干扰。
③ 模糊与遮挡处理(双重时间消歧机制)
在遮挡、拥挤或传播误差累积的场景中,跟踪器可能产生歧义预测。SAM3通过两类时间约束稳定轨迹:
时间一致性评分,抑制低置信度轨迹:对每条轨迹计算掩码检测分数,即统计其在时间窗口内与检测器结果持续匹配的稳定性。低分轨迹将被抑制,避免短暂噪声或误匹配进入最终结果。检测矫正机制,高置信度更新结果:周期性使用高置信度检测掩码Oₜ替换传播结果M̂ₜ,重置跟踪器状态,防止记忆库漂移,确保外观参考始终保持更新和可信。④ 基于视觉提示的实例细化(保留SAM2的交互能力)
在生成初始掩码或小掩码后,支持通过正负点击以细化实例边界:
- 用户点击经提示编码器编码;
- 编码提示输入掩码解码器,输出调整后的改进掩膜;
- 改进掩膜将在整个视频中重新传播,实现全局一致的细化效果。
⑤ (推理过程)歧义处理:多候选掩码输出
总结一句话:跟踪器通过 "掩码传播---检测匹配---记忆校正" 构建稳健的时序一致性,是SAM3实现从单帧检测向多帧理解扩展的核心基础;解耦训练策略则确保语义识别与身份维持互不干扰,实现整体系统的稳定与可靠。
4、数据引擎:新增【概念标签】约400万条正负例
为了支持SAM 3在开放概念分割(PCS)上的性能提升,我们构建了一个大规模人机协同数据引擎,实现多模态、多领域、高质量的训练数据生成。我们在数据引擎设计上实现三大创新:
媒体策展:拓展传统同质化网络资源,覆盖更多视觉媒体域,确保概念多样性与场景广度。标签策展:利用本体论和多模态大模型生成名词短语(NP)及困难否定标签,提高标签覆盖与标注难度。标签验证:微调多模态大模型为"AI验证器",实现掩码质量与覆盖范围的双重审核;人工标注集中修正高难度错误案例,实现人机双重质量控制。
(1)数据引擎组件
媒体输入(如:图像或视频)先通过整理后的本体论(Ontology)从海量数据池中筛选。AI模型生成描述视觉概念的名词短语(NPs),并由SAM 3等模型为每个NP生成候选实例掩码。掩码随后经过两步验证:
掩码验证阶段(Mask Verification,MV):标注者根据掩码质量及其与NP的相关性进行接受或拒绝。穷尽性验证阶段(Exhaustivity Verification,EV):标注者检查输入数据中是否覆盖该NP的所有实例。
- 未通过EV的媒体-NP配对进入人工修正阶段,标注者可使用浏览器工具对掩码进行添加、删除或编辑,或对难以分离的小型物体使用"群组掩码"。缺乏依据或存在歧义的短语可以被拒绝,从而保证掩码质量与标注完整性。
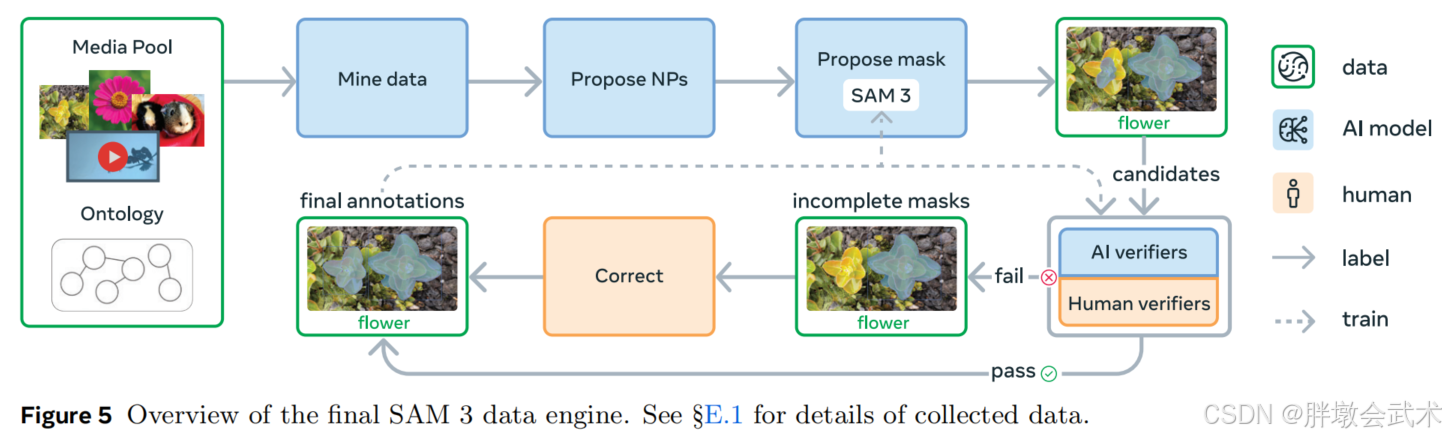
(2)数据引擎工作流程 ------ 人机协同 + AI辅助
SAM 3的数据引擎通过人机协同 + AI辅助迭代生成大规模高质量标注数据,分为四个阶段:
- 阶段一:人工验证
- 随机抽取图像及NP候选,使用SAM 2生成初始掩码提案,并结合开放词汇检测器提示;
- 人工完成掩码验证(MV)和穷尽性验证(EV);
- 收集430万图像-NP配对作为初始SA-Co/HQ数据集,为SAM 3训练提供基础。
- 阶段二:人工 + AI验证
- 利用阶段一结果微调AI验证器(如Llama 3.2),自动执行MV和EV任务,人工集中处理最具挑战案例;
- SAM 3迭代训练6次,AI验证器迭代优化,阶段二新增1.22亿图像及NP配对,大幅提升数据规模与标注效率。
- 阶段三:规模扩展与领域拓展
- 挖掘复杂样本,覆盖15个新视觉-文本领域;
- 利用图像alt-text及Wikidata本体扩展概念至长尾细粒度;
- SAM 3训练7次,AI验证器训练3次,新增1950万图像及NP配对。
- 阶段四:视频标注
- 扩展至视频领域,通过SAM 3生成时空掩码(masklets),去重冗余掩码后形成SA-Co/video;
- 优先标注拥挤或跟踪失败片段,集中人工处理高风险标注;
- 最终收集5.25万段视频、46.7万张高质量时空掩码。
(3)提出【SA-Co概念分割基准】用于评估模型性能 ------ 是现有基准的50倍+
最终数据集包括:
真实数据:400万独特短语、5200万高质量掩码合成数据:3800万短语、14亿合成掩码此外,
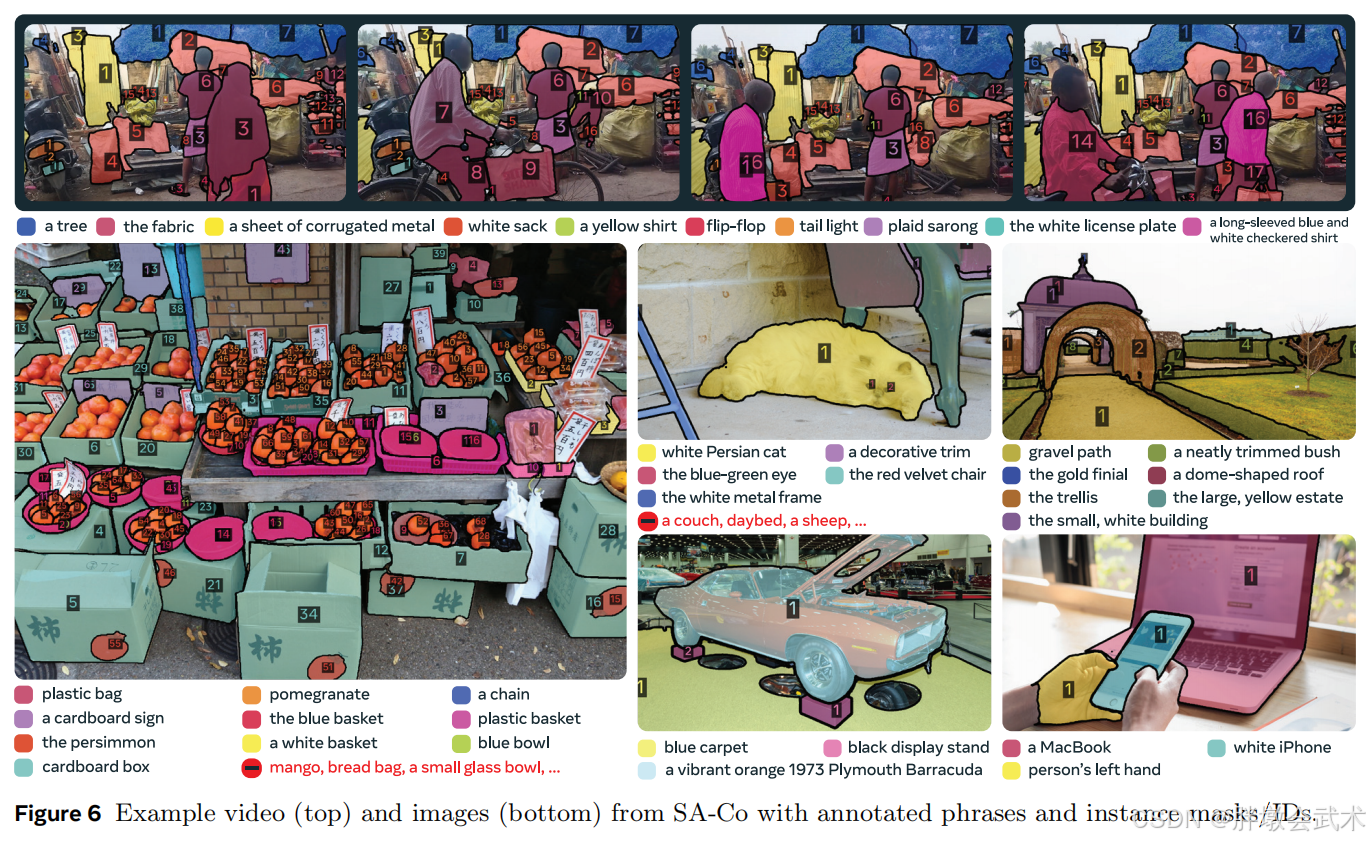
构建了概念任意分割基准 SA-Co,覆盖12万图像与1700视频,共20.7万个独特概念,规模是现有基准的50倍以上。
概念分割基准,用于评估模型在开放词汇分割任务中的性能。
Segment Anything with Concepts (SA-Co) Dataset:示例视频(上)与图像(下),包含标注短语及实例掩码/ID。
训练数据
SA-Co为PCS任务构建了大规模图像与视频训练集,包括三个图像子集:
SA-Co/HQ:数据引擎第1-4阶段收集的高质量图像,标注520万张图像、400万个独特自然点(NPs);SA-Co/SYN:通过数据引擎第3阶段自主生成的合成图像数据,无需人工标注;SA-Co/EXT:整合15个外部实例掩码数据集,通过本体管道补充硬样本负样本。此外,SA-Co/video包含5.25万段视频、2.48万条独特自然点,总计13.4万对视频-NP配对,平均每段视频84.1帧,帧率6 fps。 详细统计及概念分布参见§E.1。
基准测试集(Benchmark)
- 规模: 12.1万张图像/视频,20.7万条独特短语,300万+负样本对。
- 分组:
Gold:七个领域,每组图像-NP由三位标注者完成;Silver:十个领域,每组图像-NP由一位标注者完成;Bronze/Bio:基于九个现有数据集,掩码由现成标注或SAM 2生成;VEval:视频评测,三领域,每组视频-NP由一位标注者完成。示例标注见图6,详细统计表见表28。评估指标
- 定位:正样本微F1(pmF1),针对至少包含一个真实掩码的媒体-NP对;
- 分类:图像级马修斯相关系数(IL_MCC),衡量二元预测("物体是否存在");
- 综合指标:分类门控F1(cgF1)= 100 × pmF1 × IL_MCC,仅考虑置信度>0.5的预测,确保实际应用可用性。
歧义处理
- 在SA-Co/Gold中,每个NP收集三份标注;
- 通过与所有真实值比对选择最佳分数评估预测准确率,减少歧义影响。
二、3D应用扩展
SAM3 系列通过统一的核心技术与多维应用场景,覆盖从二维开放词汇分割到三维物体与人体重建的全流程视觉理解。三篇论文的关系如下:
| 层级 | 模块/论文 | 核心内容 | 输入 | 输出 | 依赖关系 |
|---|---|---|---|---|---|
| 基础 | SAM 概念提示 | 开放词汇分割与概念消歧 | 图像 + 文本/几何/图像示例 | 候选掩码 | PE + 检测器 + 跟踪器 |
| 应用 | SAM 3D Objects | 通用物体 3D 重建 | 图像 + 2D掩码 | 3D 网格/姿态 | 基于 SAM 概念提示掩码 |
| 应用 | SAM 3D Body | 人体 3D 姿态和网格 | 图像 + 2D掩码/关键点 | 3D 人体网格 | 基于 SAM 概念提示掩码 + 交互式提示 |
总结关系:
- SAM 概念提示是 SAM3 的核心技术,提供开放词汇分割能力和概念消歧机制,是所有应用模块的基础。
- SAM 3D Objects和SAM 3D Body均基于概念提示生成的二维掩码,进行三维推理和特化建模。
- 三维模块本质上是概念提示的延伸,将二维视觉理解提升至三维空间,为物体与人体分析提供可交互、高精度的三维表示。
1、【SAM 3D Objects】通用物体 3D 重建
核心目标:从单张或多张图片生成物体的高精度 3D 重建与空间姿态估计,支持虚拟场景中物体的精细形状、纹理和布局理解。
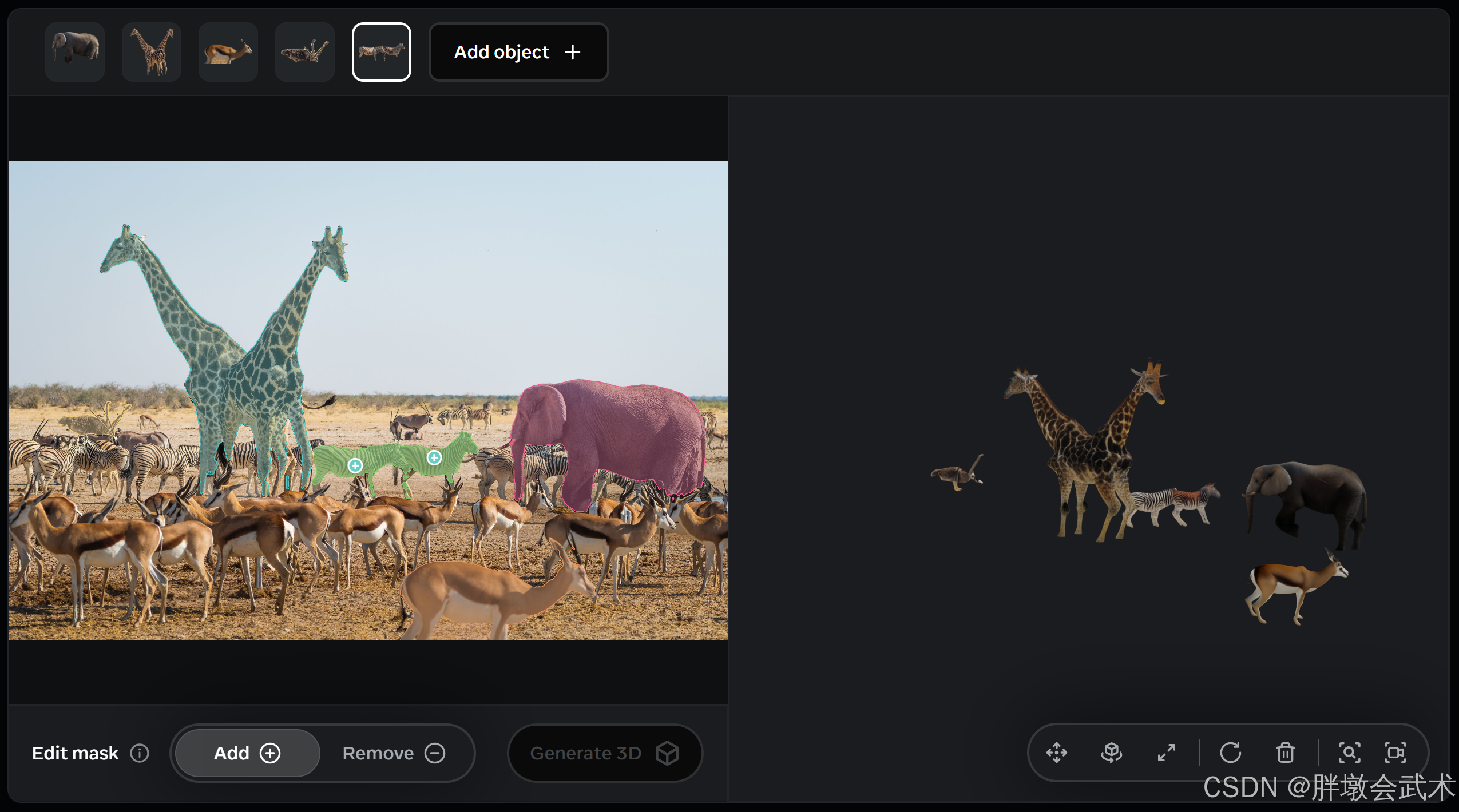
输入:图像(RGB 或多通道)、SAM3 概念提示生成的 2D 分割掩码
输出:高精度 3D 网格模型、纹理映射与姿态信息
核心架构
2D 到 3D 投影模块:将 SAM3 检测器输出的二维掩码作为空间约束;提取物体轮廓、边界和局部特征,用于 3D 重建网格解码器:基于 Transformer 或图卷积网络 (GCN)、支持多视角融合或单视角预测姿态估计模块:输出物体空间姿态(旋转、平移)、可与场景几何关系耦合,支持虚拟场景摆放纹理重建模块:利用图像特征映射纹理到生成网格、保持高分辨率细节核心亮点
- 稳健重建:支持遮挡、复杂背景和视角变化
- 姿态预测:输出空间位姿,实现场景级布局
- 开放应用:虚拟现实、数字孪生、机器人感知
与 SAM3 的关系
- 完全依赖 SAM 概念提示 提供的高质量 2D 掩码
- 将二维语义理解扩展至三维空间,实现从视觉识别到物体重建的无缝衔接
2、【SAM 3D Body】人体 3D 姿态与网格重建
核心目标:从单张图片或视频帧中恢复人体精确的三维姿态和形态,支持复杂场景和交互式控制。

- 输入
- 图像(RGB / 高分辨率多输入)
- SAM3 概念提示生成的 2D 人体掩码
- 可选提示:2D 关键点、分割掩码(Promptable 输入)
- 输出
- 3D 人体网格(MHR 格式)
- 骨骼结构与软组织形态分离
- 可编辑的姿态和局部网格细节
- 核心架构
PE 特征输入
- 利用 SAM3 Perception Encoder 提取跨模态、高维特征
- 提供人体局部与全局语义基础
提示条件化解码
- 将用户提示(掩码/关键点)与图像特征融合
- 实现可交互的三维预测
MHR 网格解码器
- Meta Momentum Human Rig 分离骨骼与软组织
- 支持高分辨率网格生成与姿态控制
多步细化训练
- 大规模数据(约 800 万图像)+ 提示引导
- 多步迭代优化姿态和网格细节
姿态与网格融合
- 融合局部与全局人体特征
- 输出可直接应用于动画、虚拟试衣或运动分析
- 核心亮点
- Promptable 设计:通过分割掩码或关键点可动态控制预测
- 高精度捕捉:细致保留人体各部位特征
- 交互式控制:用户可逐步修正或细化姿态与形态
- 可解释性增强:骨骼和软组织分离,便于后续应用
- 与 SAM3 的关系
- 基于 SAM3 概念提示与 PE 特征提供的 2D 语义基础
- 属于三维重建的特殊子类(人体特化版本)
- 将二维分割能力扩展至三维人体分析,实现精准姿态恢复与网格重建
三、项目实战
【PyTorch项目实战】SAM(Segment Anything Model)
1、环境配置
与SAM github官网教程一致:https://github.com/facebookresearch/sam3
python
# 创建专用的 conda 环境
conda create -n sam3 python=3.12 -y
conda activate sam3
# 安装支持 CUDA 的 PyTorch
pip install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# 安装支持 CPU 的 PyTorch(清华园镜像安装)
pip install torch==2.7.0 torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
########################################################
# 克隆并安装SAM3
cd D:/ # 切换到存放目录
git clone https://github.com/facebookresearch/sam3.git
cd sam3 # 切换当项目路径
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装示例所需的额外依赖:for example notebooks or development
pip install -e ".[notebooks]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -e ".[train,dev]"
pip install iopath triton2、模型下载(目前SAM3是受限访问,默认不对任何人开放)
- 官方 GitHub 代码仓库(含源码):facebookresearch / sam3
- 模型权重与 checkpoint:托管在 Hugging Face(repo 名称 facebook/sam3)中
需要注意的 访问控制 / Gated Repo 问题:SAM 3 的 checkpoint 仓库目前是受限访问(gated repo),默认不对所有人开放。若未获得授权,则会出现 HTTP 403 / 权限拒绝。
因此,下载流程一般为:
- 登录 Hugging Face 账号。
- 在页面 facebook/sam3 上点击 Request Access,提交申请。
- 等待官方批准(通常数小时到数天不等)。
- 批准后,通过 transformers、sam3 库或命令行客户端下载模型权重。
SAM 3本地部署教程:支持文本提示分割,400万概念、30毫秒响应
模型下载:这里推荐转到魔塔社区官网下载模型文件:sam3 · 模型库
3、图像分割
(1)函数详解
| 函数 / 方法 | 所属组件 | 主要用途 | 关键参数 | 返回值 / 说明 |
|---|---|---|---|---|
build_sam3_image_model(checkpoint=None) |
模型构建 | 构建 SAM3 图像分割模型,可选择加载 checkpoint | checkpoint:字符串,可选,模型权重路径 |
返回已构建的 SAM3 图像模型 |
Sam3Processor(model) |
Sam3Processor | 构建分割处理器,将模型封装为高阶接口 | model:SAM3 模型对象 |
返回处理器实例,用于后续图像分割 |
processor.set_image(image, device=None) |
Sam3Processor | 设置输入图像,初始化推理状态 | image:PIL.Image 或 ndarray device:可选,cuda/cpu |
返回推理状态 state,用于后续提示输入 |
processor.set_text_prompt(state, prompt, device=None) |
Sam3Processor | 文本提示分割 | state:推理状态 prompt:字符串,文本描述对象 device:可选 |
更新后的推理状态,可用于 processor.forward(state) 获取 mask |
processor.add_geometric_prompt(state, points=None, boxes=None, masks=None, device=None) |
Sam3Processor | 几何提示分割(点、框、掩码) | state:推理状态 points:前景/背景点列表 boxes:边界框列表 masks:初始掩码列表 device:可选 |
更新后的推理状态 |
processor.set_image_prompt(state, prompt, device=None) |
Sam3Processor | 图像示例提示分割 | state:推理状态 prompt:PIL.Image,示例图像 device:可选 |
更新后的推理状态 |
processor.forward(state) |
Sam3Processor | 执行实际分割推理 | state:推理状态 |
返回 dict,包含 masks(掩码列表)、boxes(边界框列表)、scores(置信度) |
processor.forward_multi_prompt(state, text=None, image=None, points=None, boxes=None, masks=None, device=None) |
Sam3Processor | 多模态联合提示分割(文本+示例图+几何提示) | state:推理状态 text:文本提示 image:图像示例 points/boxes/masks:几何提示 device:可选 |
返回与 forward 类似的分割结果字典 |
processor.forward_auto(state) |
Sam3Processor(部分实现可能自定义) | 全自动/全景分割(无提示) | state:推理状态 |
返回全自动分割结果字典(masks、boxes、scores) |
(2)分割方式:概念分割(文本+示例) + 点/框/掩码 + 全景分割
- SAM3 官方并未提供像 SAM1 的
自动分割器AutomaticMaskGenerator那样的全自动全景分割 API。- SAM3 的核心定位是
提示式概念分割(PCS),强调通过提示分割,包括:文本、示例图像、点/框/mask、视频中的持续跟踪。但 SAM3 的模型结构本身具备所有实例分割 (instance segmentation + semantic segmentation → panoptic)能力,只是官方没有提供直接的"Auto Segment Everything"接口。
python
import torch
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
def sam3_universal_segmentation(
image_path,
text_prompt=None,
example_image_path=None,
checkpoint=None,
visualize=True,
):
"""
SAM3通用分割函数:
- 文本提示分割
- 图像示例分割
- 全自动全景分割(无提示时自动启用)
参数:
image_path - 待处理图像
text_prompt - 文本提示(可选)
example_image_path - 示例图像提示(可选)
checkpoint - SAM3模型权重(可选)
visualize - 是否进行可视化
返回:
masks, boxes, scores
"""
# ------------------
# 自动选择设备
# ------------------
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"[Device] {device}")
# ------------------
# 构建或加载模型
# ------------------
try:
if checkpoint:
model = build_sam3_image_model(checkpoint=checkpoint)
print(f"[Model] Loaded checkpoint: {checkpoint}")
else:
raise ValueError
except Exception:
model = build_sam3_image_model()
print("[Model] Loaded default SAM3")
model.to(device)
processor = Sam3Processor(model)
# ------------------
# 读取图像
# ------------------
image = Image.open(image_path).convert("RGB")
state = processor.set_image(image, device=device)
# 如果没有文本提示和示例图像提示
if (text_prompt is None) and (example_image_path is None):
print("[Mode] No prompt provided. Running full automatic panoptic segmentation...")
output = processor.forward(state) # 直接 forward 即可
else:
# 文本提示
if text_prompt:
state = processor.set_text_prompt(state=state, prompt=text_prompt, device=device)
print(f"[Prompt] Text prompt applied: {text_prompt}")
# 示例图像提示
if example_image_path:
example_img = Image.open(example_image_path).convert("RGB")
state = processor.set_image_prompt(state=state, prompt=example_img, device=device)
print(f"[Prompt] Image example applied: {example_image_path}")
output = processor.forward(state)
# ------------------
# 推理
# ------------------
output = processor.forward(state)
masks = output["masks"]
boxes = output["boxes"]
scores = output["scores"]
print(f"[Result] {len(masks)} objects detected.")
# ------------------
# 可视化
# ------------------
if visualize:
plt.figure(figsize=(10, 10))
plt.imshow(image)
ax = plt.gca()
plt.axis("off")
for mask, box in zip(masks, boxes):
m = mask.cpu().numpy()
color = np.random.rand(3)
h, w = m.shape
overlay = np.zeros((h, w, 3))
for i in range(3):
overlay[:, :, i] = color[i]
ax.imshow(np.dstack((overlay, m * 0.6)))
x0, y0, x1, y1 = box
rect = plt.Rectangle((x0, y0), x1 - x0, y1 - y0, fill=False, edgecolor="red", linewidth=2)
ax.add_patch(rect)
plt.show()
return masks, boxes, scores
"""
函数将按照以下优先级自动执行:
1. 若提供文本提示 → 文本提示分割
2. 若提供图像示例 → 图像示例提示分割
3. 若两者都提供 → 联合提示分割(精度最高)
4. 若无任何提示 → 进入全自动全景分割模式
"""
if __name__ == "__main__":
image_path = "path/to/your/image.jpg"
text_prompt = "A cat sitting on a sofa"
example_image_path = None # "path/to/your/example_image.jpg"
checkpoint = None # "path/to/your/sam3_checkpoint.pth"
sam3_universal_segmentation(
image_path=image_path,
text_prompt=text_prompt,
example_image_path=example_image_path,
checkpoint=checkpoint,
visualize=True,
)4、视频分割
(1)函数详解
| 函数 / 方法 | 所属组件 | 主要用途 | 关键参数 | 返回值 / 说明 | ||
|---|---|---|---|---|---|---|
build_sam3_video_predictor(checkpoint=None) |
模型构建 | 构建 SAM3 视频分割预测器,可加载 checkpoint | checkpoint:可选,权重路径 |
返回视频预测器对象 | ||
video_predictor.handle_request(request) |
视频预测器 | 执行视频分割任务(包含开始会话、添加提示、推理等) | request:字典,包括操作类型和参数,例如: type: `"start_session" |
"add_prompt" | "forward"<br>resource_path: 视频路径或帧目录<br>frame_index: 帧索引<br>text/image/points/boxes/masks`: 提示信息 |
返回字典,包含每帧的 masks、boxes、scores 及实例 ID |
video_predictor.start_session(video_path) |
视频预测器 | 初始化视频会话 | video_path:MP4 文件路径或 JPEG 文件夹 |
返回 session_id |
||
video_predictor.add_prompt(session_id, frame_index, text=None, image=None, points=None, boxes=None, masks=None) |
视频预测器 | 在指定帧添加提示(文本/图像/几何) | 同上 | 更新会话状态,返回当前帧分割结果 | ||
video_predictor.forward(session_id, frame_index=None) |
视频预测器 | 推理指定帧或整个视频 | session_id:会话 ID frame_index:可选,单帧索引,不指定则推理整个视频 |
返回分割结果字典,包含 masks、boxes、scores 和 instance_ids |
||
video_predictor.forward_auto(session_id) |
视频预测器 | 全自动视频分割(无提示) | session_id:会话 ID |
返回全自动分割结果字典,包含每帧 mask、box、score 和 instance ID |
(2)分割方式:概念分割(文本+示例) + 点/框/掩码 + 全景分割
python
import torch
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import cv2
from sam3.model_builder import build_sam3_video_predictor
# ===========================
# 可视化函数
# ===========================
def draw_mask(mask, ax, color=None, alpha=0.6):
"""在 matplotlib 上叠加 mask"""
if isinstance(mask, torch.Tensor):
mask = mask.cpu().numpy()
if color is None:
color = np.random.rand(3)
h, w = mask.shape
mask_img = np.zeros((h, w, 3))
for i in range(3):
mask_img[:, :, i] = color[i]
ax.imshow(np.dstack((mask_img, mask * alpha)))
def draw_box(box, ax, color="red", lw=2):
"""在 matplotlib 上绘制边界框"""
x0, y0, x1, y1 = box
w, h = x1 - x0, y1 - y0
ax.add_patch(plt.Rectangle((x0, y0), w, h, fill=False, edgecolor=color, linewidth=lw))
def visualize_frame(frame_image, masks, boxes):
"""整合 mask 和 box 可视化"""
plt.figure(figsize=(10, 10))
plt.imshow(frame_image)
ax = plt.gca()
plt.axis("off")
for mask, box in zip(masks, boxes):
draw_mask(mask, ax)
draw_box(box, ax)
plt.show()
# ===========================
# 视频分割函数
# ===========================
def sam3_video_segment(
video_path,
text_prompt=None,
image_prompt=None,
points_prompt=None,
boxes_prompt=None,
masks_prompt=None,
full_auto=False,
visualize=True
):
"""
SAM3 视频分割(支持文本/示例图/几何提示 + 全自动分割)
参数:
video_path (str) : MP4 文件路径或帧文件夹
text_prompt (str) : 文本描述
image_prompt (PIL.Image.Image) : 示例图像
points_prompt (list of tuples) : [(x, y, is_foreground)]
boxes_prompt (list of list) : [[x0, y0, x1, y1], ...]
masks_prompt (list of np.array or torch.Tensor) : 初始掩码
full_auto (bool) : 是否全自动(零提示)
visualize (bool) : 是否可视化每帧
返回:
list : 每帧的分割结果,包含 masks, boxes, scores, instance_ids
"""
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# 构建视频预测器
predictor = build_sam3_video_predictor()
# 初始化视频会话
response = predictor.handle_request({
"type": "start_session",
"resource_path": video_path
})
session_id = response["session_id"]
print(f"会话 ID: {session_id}")
# 添加提示(若非全自动模式)
if not full_auto:
request_dict = {
"type": "add_prompt",
"session_id": session_id,
"frame_index": 0
}
if text_prompt: request_dict["text"] = text_prompt
if image_prompt: request_dict["image"] = image_prompt
if points_prompt: request_dict["points"] = points_prompt
if boxes_prompt: request_dict["boxes"] = boxes_prompt
if masks_prompt: request_dict["masks"] = masks_prompt
predictor.handle_request(request_dict)
print(f"已添加提示到帧 0")
# 推理视频
response = predictor.handle_request({
"type": "forward",
"session_id": session_id
})
results = response["outputs"]
print(f"视频帧数: {len(results)}")
# 视频逐帧可视化
if visualize:
cap = cv2.VideoCapture(video_path)
frame_idx = 0
while True:
ret, frame = cap.read()
if not ret or frame_idx >= len(results):
break
frame_image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
frame_res = results[frame_idx]
masks = frame_res["masks"]
boxes = frame_res["boxes"]
print(f"帧 {frame_idx}: {len(masks)} 个对象")
visualize_frame(frame_image, masks, boxes)
frame_idx += 1
cap.release()
return results
if __name__ == "__main__":
video_path = "video.mp4"
text_prompt = "a person riding a bike"
image_prompt = Image.open("example.jpg").convert("RGB") # 可选示例图
results = sam3_video_segment(
video_path=video_path,
text_prompt=text_prompt,
image_prompt=image_prompt,
full_auto=False,
visualize=True
)