
【往期数据结构回顾】:
/-----------初阶数据结构-----------/
栈和队列实现目录:
[1. 栈](#1. 栈)
[2. 队列](#2. 队列)
[1. 数组实现(顺序栈)](#1. 数组实现(顺序栈))
[2. 链表实现(链栈)](#2. 链表实现(链栈))
在数据结构的学习中,栈和队列是绕不开的基础线性结构。它们本质上都是对数组或链表的"规则化封装"------通过限制数据的存取方式,满足不同场景的需求。栈遵循"先进后出(LIFO)",像弹匣一样只能从顶端操作;队列遵循"先进先出(FIFO)",像排队办事一样有序流转。
一、概念:两种"秩序"的本质区别
栈和队列的核心差异在于数据操作的顺序规则,这一规则直接决定了它们的应用场景和实现逻辑。
1. 栈
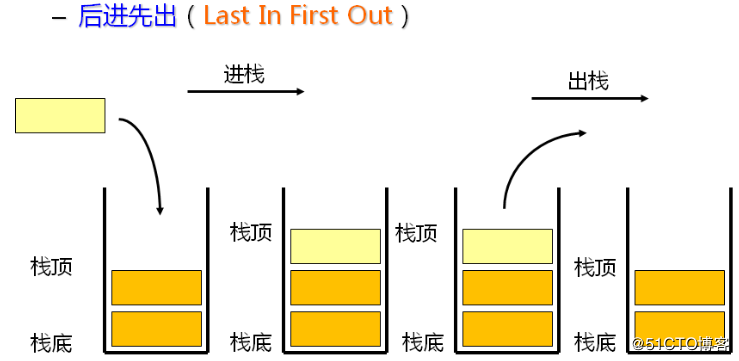
栈(Stack)遵循后进先出(Last In First Out, LIFO) 原则,就像我们日常叠放的盘子------最后放上去的盘子,必须最先拿下来。这种结构对数据操作施加了严格限制:所有插入和删除操作都只能在栈的顶端(栈顶)完成,不支持随机访问中间元素。
生活中的"撤销操作"、程序中的函数调用栈,都是栈结构的典型体现:最新的操作或调用始终处于"栈顶",需要时优先被处理。
2. 队列
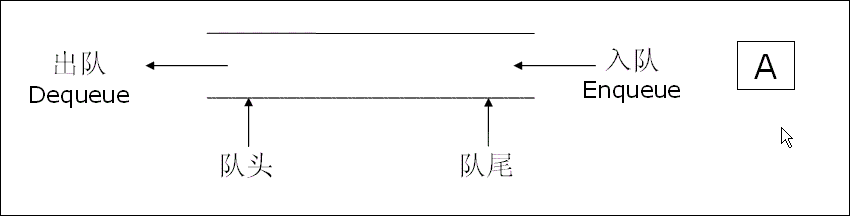
队列(Queue)遵循先进先出(First In First Out, FIFO) 原则,类似银行柜台前排队的人群------最先排队的人,最先办理业务。与栈不同,队列的操作分为两端:只能在队列的尾部(队尾)插入元素,在队列的头部(队头)删除元素,同样不支持随机访问。
操作系统的进程调度、打印机的任务队列,都依赖队列的"顺序处理"特性,确保任务按提交顺序公平执行。
二、栈的实现
栈的实现有两种经典方案:数组实现(顺序栈)和链表实现(链栈)。两者各有优劣,需根据实际场景选择------数组实现效率高但需预分配空间,链表实现动态扩容但有指针开销。
1. 数组实现(顺序栈)
数组实现的核心是用一个数组(定长的静态栈的结构,实际中一般不实用,所以我们只实现支持动态增长的栈 )存储元素,并通过一个"栈顶指针"(通常是整数索引)标记栈顶位置。初始时栈顶指针为-1或者0(表示栈空),如果是-1代表top始终指向栈顶元素,如果是0表示top始终指向栈顶元素的下一个位置,压栈时指针加1,弹栈时指针减1。
由于这两个数据结构的实现都很简单,我就不分开实现接口了,具体的我在代码里注释
cpp
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
// 栈存储的数据类型
typedef int STDataType;
// 栈(基于动态数组实现)
typedef struct stack
{
STDataType* a; // 动态数组,存储栈元素
int top; // 栈顶指针:指向栈顶元素的下一个位置
int capacity; // 当前栈的最大容量
}stack;
// 栈的初始化
void STInit(stack* ps)
{
// 避免对空指针进行解引用
assert(ps);
// 为数组开辟初始容量(4个元素)的空间
ps->a =(STDataType* ) malloc(sizeof(STDataType)*4);
// 内存开辟失败时,打印错误并返回
if (ps->a == NULL)
{
perror("malloc");
return;
}
ps->capacity = 4; // 初始化栈容量为4
ps->top = 0; // 初始时栈空,top指向栈顶下一个位置
//ps->top = -1;// 若需改为"指向栈顶元素",可启用此注释
}
// 栈的销毁
void STDestroy(stack* ps)
{
assert(ps); // 避免空指针操作
free(ps->a); // 释放动态数组的内存
ps->a = NULL; // 指针置空,防止野指针
ps->capacity = 0; // 容量重置为0
ps->top = 0; // top重置为初始状态
}
// 入栈(压栈)
void STPush(stack* ps, STDataType x)
{
// 避免空指针操作
assert(ps);
// 检查栈是否已满,满则扩容为原容量的2倍
if (ps->capacity == ps->top)
{
STDataType* tmp =(STDataType*)realloc(ps->a, sizeof(STDataType)*2*ps->capacity );
// 扩容失败时,打印错误并返回
if (tmp == NULL)
{
perror("realloc");
return;
}
ps->a = tmp; // 更新数组指针
ps->capacity = ps->capacity * 2; // 更新容量
}
ps->a[ps->top++] = x; // 元素存入当前top位置,随后top后移
}
// 出栈(弹栈)
void STPop(stack* ps)
{
assert(ps); // 避免空指针操作
assert(!STEmpty(ps)); // 栈空时禁止出栈
ps->top--; // top前移,实现出栈(逻辑删除)
}
// 获取栈中有效元素个数
int STSize(stack* ps)
{
assert(ps); // 避免空指针操作
return ps->top; // top的值等于元素个数(因top指向栈顶下一个位置)
}
// 判断栈是否为空
bool STEmpty(stack* ps)
{
assert(ps); // 避免空指针操作
return ps->top == 0;// top为0时栈空
}
// 获取栈顶元素
STDataType STTop(stack* ps)
{
assert(ps); // 避免空指针操作
assert(!STEmpty(ps)); // 栈空时无栈顶元素
return ps->a[ps->top - 1]; // 栈顶元素在top-1位置
}【顺序栈优缺点】
优点:
- 内存连续,缓存友好,访问速度快;
- 核心操作(入 / 出栈、查栈顶)均为 O (1);
缺点:
- 扩容依赖连续内存空间,异地扩容需拷贝数据,存在瞬时时间开销(原地扩容无此消耗);
- 扩容后若实际元素远少于容量(如容量 100 仅用 55 个),易造成闲置内存浪费。
2. 链表实现(链栈)
链表实现的核心是用链表节点存储元素,以链表的头部作为栈顶(便于插入和删除)。无需预分配空间,元素个数可动态增减,从根本上避免了栈溢出问题。
cpp
// 链栈的定义
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include<assert.h>
// 链表节点结构
typedef struct StackNode
{
int data; // 节点存储的数据
struct StackNode *next; // 指向下一个节点的指针(链表特性)
} StackNode;
// 链栈结构:通过栈顶指针和大小维护整个栈
typedef struct
{
StackNode *top; // 栈顶指针(链栈核心:所有操作围绕栈顶),NULL表示栈空
int size; // 栈的元素个数(快速获取大小,避免遍历)
} LinkStack;
// 1. 初始化栈:将栈置为空状态
void StackInit(LinkStack *stack)
{
stack->top = NULL; // 栈顶置空表示空栈
stack->size = 0; // 大小初始化为0
}
// 2. 压栈操作(链表头插法):新节点成为新栈顶
bool StackPush(LinkStack *stack, int value)
{
assert(stack); // 防止传入空指针
// 创建新节点并分配内存
StackNode *newNode = (StackNode *)malloc(sizeof(StackNode));
if (newNode == NULL) // 内存分配失败处理
{
printf("内存分配失败,压栈失败!\n");
return false;
}
// 新节点数据赋值
newNode->data = value;
// 关键:新节点指向原栈顶(头插法核心)
newNode->next = stack->top;
// 栈顶指针更新为新节点
stack->top = newNode;
stack->size++; // 元素个数+1
return true;
}
// 3. 弹栈操作(链表头删法):移除栈顶节点
bool StackPop(LinkStack *stack)
{
// 空栈判断(栈顶为NULL则无法弹栈)
if (stack->top == NULL)
{
printf("栈为空,弹栈失败!\n");
return false;
}
// 保存原栈顶的下一个节点(防止链表断裂)
StackNode* next = stack->top->next;
// 释放原栈顶节点内存
free(stack->top);
// 栈顶指针更新为原栈顶的下一个节点
stack->top = next;
stack->size--; // 元素个数-1
return true;
}
// 4. 查看栈顶元素:仅读取不修改栈
bool StackPeek(LinkStack *stack, int *value)
{
// 空栈判断
if (stack->top == NULL)
{
printf("栈为空,无栈顶元素!\n");
return false;
}
// 通过指针输出栈顶数据
*value = stack->top->data;
return true;
}
// 5. 判断栈是否为空:通过栈顶指针直接判断
bool StackIsEmpty(LinkStack *stack)
{
return stack->top == NULL; // 栈顶为NULL即空栈
}
// 6. 获取栈的大小:直接返回维护的size(O(1)效率)
int StackGetSize(LinkStack *stack)
{
return stack->size;
}
// 销毁栈:释放所有节点内存(避免内存泄漏)
void StackDestroy(LinkStack *stack)
{
StackNode *temp; // 临时指针保存待释放节点
// 循环删除栈顶节点,直到栈空
while (stack->top != NULL)
{
temp = stack->top; // 保存当前栈顶节点
stack->top = temp->next; // 栈顶后移
free(temp); // 释放当前节点
}
stack->size = 0; // 大小重置为0
}【链式栈优缺点】
优点:
- 压栈 / 出栈仅需修改节点指针指向(链表头插 / 头删),无需移动大量元素(数组栈扩容时可能需要拷贝数据)。
- 无需扩容 / 溢出风险:内存动态分配(每个节点独立申请),只要系统有空闲内存就能持续压栈,不存在数组栈的扩容操作或容量限制
缺点:
- 存在指针空间开销 :每个节点需额外存储
next指针(比如 int 型数据占 4 字节,指针占 8 字节时,额外开销达 2 倍),内存利用率低于数组栈。- 缓存利用率低:节点内存分散存储,CPU 缓存命中率远低于数组栈的连续内存布局,访问效率受影响。
- 实际操作效率略低 :压栈需动态分配节点(
malloc)、出栈需释放节点(free),比数组栈的 "直接读写内存" 多了调用开销
三、队列的实现
队列的实现同样有数组和链表两种方式。数组实现时,普通队列会出现"假溢出"问题------队尾已满但队头有空闲空间,因此实际中更常用循环队列;链表实现则通过头尾指针轻松完成两端操作。
**假溢出:**普通数组队列里,队尾已经到数组末尾没法再存,但队头因为出队空了不少位置 ------ 看着像满了,其实还有空间能用,就是普通队列用不了这些空位置。
1、循环队列
循环队列的核心是利用"取模运算"让数组首尾相连,形成逻辑上的环形空间。通过两个指针(front指向队头,rear指向队尾的下一个位置)控制操作,同时可引入size变量记录元素个数,capacity变量记录容量大小,这种方式能让判空和判满逻辑更直观------判空条件为size == 0,判满条件为size == capacity,无需通过指针关系间接判断,也避免了预留空间的问题。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// 动态循环队列结构体
typedef struct
{
int* data; // 存储队列元素的数组
int front; // 队头指针(指向队头元素)
int rear; // 队尾指针(指向队尾元素的下一个位置)
int capacity; // 当前队列容量
int size; // 当前队列元素个数
}CircularQueue;
// 初始化队列
CircularQueue* queueInit(CircularQueue* queue)
{
// 为队列数据分配初始内存(4个int大小)
queue->data = (int*)malloc(sizeof(int) * 4);
if (queue->data == NULL)
{
perror("Failed to allocate memory for queue data");
exit(1); // 内存分配失败则终止程序
}
queue->front = 0; // 队头指针:指向队列第一个元素的位置
queue->rear = 0; // 队尾指针:指向队列最后一个元素的下一个位置(便于入队操作)
queue->capacity = 4; // 队列初始容量(最多可存储4个元素)
queue->size = 0; // 当前队列中的元素个数(初始为空)
return queue;
}
// 扩容
void expandQueue(CircularQueue* queue)
{
if (queue == NULL)
return;
// 2倍扩容
int* tmp = realloc(queue->data, sizeof(int) * queue->capacity * 2);
if (tmp == NULL)
{
perror("realloc");
exit(1); // 扩容失败则终止程序
}
queue->data = tmp; // 更新数据指针到新内存地址
// 关键逻辑:处理环形队列的"折回"情况
// 当首尾重合(队列满)时,
// 扩容后队尾指针需偏移原容量大小,避免新数据覆盖旧数据
queue->rear += queue->capacity; // 队尾指针移到新内存区域的对应位置
queue->capacity *= 2; // 更新队列容量为翻倍后的值
}
// 判断队列是否为空:通过元素个数size是否为0判断(比指针比较更直观)
bool isEmpty(CircularQueue* queue)
{
return queue->size == 0;
}
// 判断队列是否已满:元素个数等于队列容量时即为满
bool isFull(CircularQueue* queue)
{
return queue->size == queue->capacity;
}
// 入队操作:将元素添加到队尾,队列满时自动扩容
// 参数queue为队列指针,value为要入队的元素值,成功返回true,失败返回false
bool enqueue(CircularQueue* queue, int value)
{
if (queue == NULL)
return false; // 空指针保护
// 队列满时触发扩容(容量翻倍)
if (isFull(queue))
{
expandQueue(queue);
}
queue->data[queue->rear] = value; // 将元素存入队尾指针指向的位置
// 队尾指针循环后移:取模运算实现环形结构,指针到数组末尾后回到开头
queue->rear = (queue->rear + 1) % queue->capacity;
queue->size++; // 元素个数加1
return true;
}
// 出队操作:移除队头元素(仅修改指针,不清理数据)
// 队列为空时直接终止程序(也可根据需求改为返回错误码)
void dequeue(CircularQueue* queue)
{
if (queue == NULL || isEmpty(queue))
{
printf("Dequeue error: queue is NULL or empty\n");
exit(1); // 空队列出队属于非法操作,终止程序
}
// 队头指针循环后移:指向下一个元素,实现队头元素的"移除"
queue->front = (queue->front + 1) % queue->capacity;
queue->size--; // 元素个数减1
}
// 获取队头元素值:返回当前队头指针指向的元素
// 队列为空时终止程序
int getFront(CircularQueue* queue)
{
if (queue == NULL || isEmpty(queue))
{
printf("Queue is empty\n");
exit(1);
}
return queue->data[queue->front]; // 直接返回队头指针指向的元素
}
// 获取队列当前元素个数:直接返回size成员
int getSize(CircularQueue* queue)
{
return queue->size;
}
// 销毁队列:释放数据内存并重置所有成员,防止内存泄漏和野指针
void queueDestroy(CircularQueue* queue)
{
if (queue != NULL)
{
free(queue->data); // 释放数据数组的内存
queue->data = NULL; // 将指针置空,避免野指针访问
queue->capacity = 0; // 重置容量为0
queue->front = -1; // 重置队头指针(非0值标记已销毁)
queue->rear = 0; // 重置队尾指针
queue->size = 0; // 重置元素个数
}
}
// 打印队列所有元素:从队头开始遍历,按顺序输出所有元素
// 处理环形结构,确保遍历顺序正确
void printQueue(CircularQueue* queue)
{
if (isEmpty(queue))
{
printf("Queue is empty\n");
return;
}
printf("Queue elements: ");
// 遍历逻辑:从队头指针开始,依次取size个元素
// (queue->front + i) % queue->capacity:实现环形遍历,
// 即使队头不在数组开头,也能按顺序访问所有元素
for (int i = 0; i < queue->size; i++)
{
printf("%d ", queue->data[(queue->front + i) % queue->capacity]);
}
printf("\n");
}循环队列解决了普通数组队列的"假溢出"问题,空间利用率高且核心操作时间复杂度均为O(1),但固定容量实现存在溢出风险,动态扩容时需处理元素拷贝,且相比链队列多了数组容量管理的成本。
2、链式队列
链队列的核心是用链表存储元素,维护两个指针:front指向队头节点,rear指向队尾节点。入队时在rear后插入新节点,出队时删除front指向的节点,操作简洁且无容量限制。
cpp
#include<stdlib.h>
#include<assert.h>
#include<stdio.h>
typedef int QDataType;
// 链式结构:表示队列
typedef struct QListNode
{
struct QListNode* _pNext;
QDataType _data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode * _front;
QNode* _rear;
int size;
}Queue;
// 初始化队列:将队头、队尾指针置空,有效元素个数置0
void QueueInit(Queue* q)
{
assert(q); // 防止传入空指针
q->_front = q->_rear = NULL; // 空队列时头尾指针均指向NULL
q->size = 0; // 初始元素个数为0
}
// 队尾入队列:创建新节点,处理空队列/非空队列两种情况
void QueuePush(Queue* q, QDataType data)
{
assert(q);
// 1. 创建新节点并初始化
QNode* newNode = (QNode*)malloc(sizeof(QNode));
if (newNode == NULL) // 内存分配失败处理
{
perror("malloc fail\n");
return;
}
newNode->_data = data;
newNode->_pNext = NULL; // 新节点作为队尾,next置空
// 2. 处理空队列(首次入队)
if (q->_front == NULL)
{
assert(q->_rear == NULL); // 空队列时头尾指针必须同时为空
q->_front = q->_rear = newNode; // 头尾指针都指向新节点
}
// 3. 处理非空队列(正常入队)
else
{
q->_rear->_pNext = newNode; // 原队尾节点指向新节点
q->_rear = newNode; // 更新队尾指针为新节点
}
q->size++; // 有效元素个数+1
}
// 队头出队列:处理单个节点/多个节点两种情况,避免野指针
void QueuePop(Queue* q)
{
assert(q);
assert(!QueueEmpty(q)); // 防止空队列出队
// 1. 处理队列中只有一个节点的情况
if (q->_front->_pNext == NULL)
{
free(q->_front); // 释放唯一节点
q->_front = q->_rear = NULL; // 重置头尾指针为空
}
// 2. 处理队列中有多个节点的情况
else
{
QNode* next = q->_front->_pNext; // 保存队头的下一个节点
free(q->_front); // 释放队头节点
q->_front = next; // 更新队头指针为下一个节点
}
q->size--; // 有效元素个数-1
}
// 获取队列头部元素:直接返回队头节点的数据
QDataType QueueFront(Queue* q)
{
assert(q);
assert(!QueueEmpty(q)); // 空队列无头部元素
return q->_front->_data;
}
// 获取队列队尾元素:直接返回队尾节点的数据
QDataType QueueBack(Queue* q)
{
assert(q);
assert(!QueueEmpty(q)); // 空队列无尾部元素
return q->_rear->_data;
}
// 获取队列中有效元素个数:直接返回size成员
int QueueSize(Queue* q)
{
assert(q);
return q->size;
}
// 检测队列是否为空:通过size是否为0判断(也可通过_front是否为NULL)
int QueueEmpty(Queue* q)
{
assert(q);
return q->size == 0;
}
// 销毁队列:遍历释放所有节点,重置指针和size
void QueueDestroy(Queue* q)
{
assert(q);
QNode* cur = q->_front; // 从队头开始遍历
while (cur) // 遍历所有节点
{
QNode* next = cur->_pNext; // 保存下一个节点(防止释放后找不到)
free(cur); // 释放当前节点
cur = next; // 移动到下一个节点
}
q->_front = q->_rear = NULL; // 重置头尾指针
q->size = 0; // 重置元素个数
}链队列的优点是动态扩容,无需处理溢出问题;缺点是节点指针带来额外空间开销,适合元素个数不确定的场景。
四、总结
栈和队列是数据结构的"入门基石",它们的核心价值并非复杂的结构,而是通过限制操作顺序,为问题提供清晰、高效的解决思路:
栈的LIFO特性,适合处理"需要回溯"或"逆序处理"的场景,所有操作聚焦栈顶,时间复杂度均为O(1)。
队列的FIFO特性,适合处理"需要顺序执行"或"分层遍历"的场景,两端操作同样保证O(1)的高效性能。
实现选择上,数组实现高效紧凑,链表实现动态灵活,需根据实际需求(容量确定性、空间开销)权衡。
理解栈和队列的本质,不仅能解决算法问题,更能在程序设计中建立"秩序化"的思维,让数据操作更可控、更高效。
