深度学习与大模型之间的关系
大模型和深度学习的本质关联------二者不是"替代关系",而是"子集与父集、进阶与基础"的关系,核心逻辑可概括为:大模型是深度学习在"海量数据+复杂架构"下的极致产物,深度学习是大模型的技术底座。
- 深度学习(Deep Learning, DL):人工智能的一个分支,核心是"用多层神经网络自动学习数据特征",无需手动设计特征,是相对"传统机器学习"的技术升级。范围涵盖CNN(图像)、RNN(序列)、Transformer(通用)等所有神经网络模型。
- 大模型(Large Language Model/Foundation Model):深度学习的"超级升级版",特指"参数量亿级以上、基于海量数据预训练、能适配多任务"的模型。典型代表包括LLM(GPT、BERT)、CV大模型(SAM、ViT)、多模态大模型(GPT-4V)。
- 传统模型(Traditional ML):指深度学习之前的机器学习算法,核心是"手动提取特征+简单模型映射",比如线性回归、决策树、SVM、随机森林等。
三者的包含关系清晰明了:传统模型 ⊂ 机器学习 ⊃ 深度学习 ⊃ 大模型。
很多人误以为"大模型=深度学习",但二者的技术边界、适用场景、学习门槛完全不同,用表格直观对比:大模型≠深度学习,深度学习≠大模型
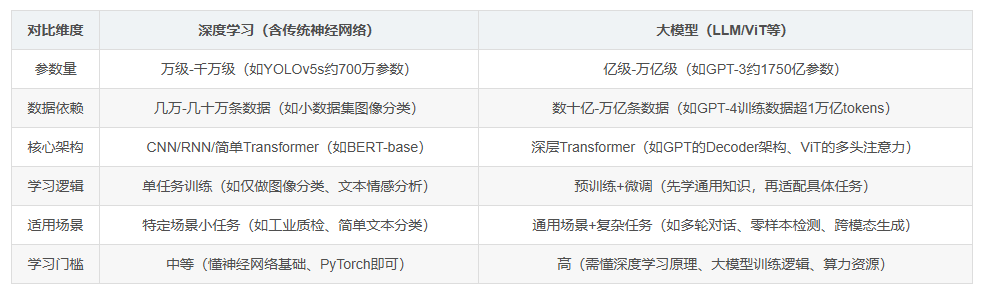
大模型没有脱离深度学习的核心逻辑,而是在其基础上做了"规模升级"和"范式创新":
继承的核心逻辑:
- 特征自动学习:延续深度学习"端到端"优势,无需手动设计特征(如LLM自动学习文本语义,ViT自动学习图像特征);
- 神经网络底座:本质仍是"多层神经元连接",依赖深度学习的反向传播、梯度下降、激活函数等核心技术;
- 损失函数思想:沿用交叉熵损失、MSE损失等基础逻辑,仅在具体任务中做适配(如LLM用自回归语言建模损失)。
突破的关键创新:
- 架构规模化:将Transformer等深度学习架构"深层化、宽层化",参数量从千万级提升到万亿级;
- 数据规模化:从"十万级标注数据"升级到"万亿级无标注数据",通过预训练学习通用知识;
- 任务泛化性:从"单任务模型"升级为"多任务通用模型",支持零样本/少样本学习(如用GPT-4直接做翻译、摘要,无需单独训练)。
常用深度学习框架
参考链接:https://cloud.tencent.com/developer/techpedia/1757
深度学习框架是帮助使用者进行深度学习的工具,它的出现降低了深度学习入门的门槛,你不需要从复杂的神经网络开始编代码,就可以根据需要使用现有的模型。它是一种软件工具,用于支持和简化深度学习算法的设计、训练和部署。深度学习框架提供了一组API和工具,可以方便地定义和训练神经网络模型,并在不同的硬件上进行优化和部署。
深度学习框架通常包括以下几个部分:
- 前端API:用于定义和配置神经网络模型的结构和参数,例如层、激活函数、优化器等。
- 计算引擎:用于执行神经网络模型的前向传播和反向传播算法,并进行梯度计算和参数更新。
- 数据管理和预处理:用于加载和处理训练数据和测试数据,并进行数据增强和批量处理等操作。
- 硬件加速和分布式计算:用于在多个GPU或分布式系统上进行高效的并行计算和训练。
深度学习框架的主要功能:
- 神经网络的定义和配置:深度学习框架提供了一组API和工具,可以方便地定义和配置神经网络模型的结构和参数,例如层、激活函数、优化器等。
- 训练和优化:深度学习框架提供了计算引擎,可以执行神经网络模型的前向传播和反向传播算法,并进行梯度计算和参数更新,从而实现模型的训练和优化。
- 数据管理和预处理:深度学习框架提供了数据管理和预处理工具,可以加载和处理训练数据和测试数据,并进行数据增强和批量处理等操作,从而提高模型的鲁棒性和泛化性能。大数据支持:深度学习框架可以在大规模数据集上进行训练,从而提高模型的精度和泛化能力。
- 硬件加速和分布式计算:深度学习框架支持在多个GPU或分布式系统上进行高效的并行计算和训练,从而加速模型的训练和优化过程。
- 模型的部署和推理:深度学习框架支持将训练好的模型部署到不同的硬件平台上,并进行推理和预测,从而实现模型的应用。
各种开源深度学习框架也层出不穷,其中包括PyTorch、TensorFlow、Caffe、Keras、Torch7、MXNet、CNTK、Leaf、Theano、DeepLearning4、Lasagne、Neon等等。不同框架之间的"好与坏",没有一个统一的标准。
TensorFlow
- 由Google Brain开发的开源深度学习框架,使用C++语言编写,支持多种语言接口(如Python、JavaScript、C ++、Java、Go、C#、Julia和R等多种编程语言等),支持多种硬件平台,包括CPU、GPU和TPU等。还可以在iOS和Android等移动平台上运行模型。
- TensorFlow使用静态计算图进行操作。也就是说,我们需要先定义图形,然后运行计算,如果我们需要对架构进行更改,则需要重新训练模型。选择这样的方法是为了提高效率,但是许多现代神经网络工具已经能够在学习过程中改进,并且不会显著降低学习速度。在这方面,TensorFlow的主要竞争对手是PyTorch。
- RStudio提供了R与TensorFlow的API接口,RStudio官网及GitHub上也提供了TensorFlow扩展包的学习资料。
https://tensorflow.rstudio.com/tensorflow/
https://github.com/rstudio/tensorflow - GitHub源码地址:https://github.com/tensorflow/tensorflow
PyTorch
- 由Facebook AI Research开发的开源深度学习框架,支持动态图和静态图两种计算图模式,具有灵活性和易用性等优点。前身是Torch,但使用Python重新编写。
- PyTroch主要提供以下两种核心功能:
- 支持GPU加速的张量计算;
- 方便优化模型的自动微分机制。
- PyTorch的主要优点如下。
- 简洁易懂:PyTorch的API设计相当简洁一致,基本上是tensor、autograd、nn三级封装,学习起来非常容易。
- 便于调试:PyTorch采用动态图,可以像普通Python代码一样进行调试。不同于TensorFlow,PyTorch的报错说明通常很容易看懂。
- 强大高效:PyTorch提供了非常丰富的模型组件,可以快速实现想法。
- 支持的语言:C/C++/Python
- GitHub源码地址:https://github.com/pytorch/pytorch
Caffe
- 由加州大学伯克利分校(BVLC)开发的开源深度学习框架,专门用于图像分类和目标检测等任务,具有高效性和易用性等特点。
- Caffe的全称是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,对卷积网络支持较好,核心语言是C++,它支持命令行、Python和MATLAB接口,既可以在CPU上运行,也可以在GPU上运行。
- Caffe的基本特性如下。
- 以C++/CUDA/Python代码为主,速度快,性能高。
- 工厂设计模式,代码结构清晰,可读性和可拓展性强。
- 支持命令行、Python和Matlab接口,使用方便。
- CPU和GPU之间切换方便,多GPU训练方便。
- 工具丰富,社区活跃。
- 同时,Caffe的缺点也比较明显,主要包括如下几点。
- 源代码修改门槛较高,需要实现正向/反向传播。
- 不支持自动求导。
- 不支持模型级并行,只支持数据级并行。
- 不适合非图像任务。
- GitHub源码地址:https://github.com/BVLC/caffe
Keras
- 由François Chollet开发的高级深度学习框架,提供了简单易用的API,可以快速搭建和训练神经网络模型。Keras是一个高层神经网络API,由纯Python编写而成并使用TensorFlow、Theano及CNTK作为后端。严格意义上讲,Keras并不能称为一个深度学习框架,它更像一个深度学习接口,它构建于第三方框架之上。入门最简单,但是不够灵活,使用受限。对于常见应用,使用Keras开发效率高,但运行效率可能不如底层框架。RStudio提供了R与Keras的API接口,RStudio的官网及GitHub上也提供了Keras扩展包的学习资料。
https://tensorflow.rstudio.com/keras/
https://github.com/rstudio/keras - GitHub源码地址:https://github.com/keras-team/keras
MXNet
- 主要作者是李沐,由亚马逊开发的开源深度学习框架,具有高效性和可扩展性等特点,支持多种编程语言和硬件平台。具有很好的分布式支持,性能出色,占用显存低。MXNet以其超强的分布式支持,明显的内存、显存优化为人所称道。可以运行在CPU、GPU、集群、服务器、台式机或者移动设备上。开发语言接口丰富(包括Python、C++、R、Matlab、Scala、JavaScript等),但教程不够完善。
- GitHub源码地址:https://github.com/apache/incubator-mxnet
Theano
- Theano最初诞生于蒙特利尔大学 LISA 实验室,于2008年开始开发,是第一个有较大影响力的Python深度学习框架。具有高效性和可移植性等特点,支持GPU加速和自动求导等功能。核心是一个数学表达式的编译器,能将结构转化为高效代码在CPU或GPU上运行。为深度学习中处理大型神经网络算法的计算而设计,但目前已停止维护。
- GitHub源码地址:https://github.com/Theano/Theano
PaddlePaddle
- 百度研发的开源开放深度学习平台,是国内最早开源且功能完备的深度学习平台。有最全面的官方支持的工业级应用模型,涵盖多个领域。支持稠密参数和稀疏参数场景的超大规模深度学习并行训练,具有强大的多端部署能力。
- 支持的语言:C++/Python
- GitHub源码地址:https://github.com/PaddlePaddle/Paddle/
Deeplearning4j
- DeepLearning4J(简称DL4J)是基于Java及JVM语言的开源深度学习框架,支持受限玻尔兹曼机、卷积神经网络(CNN)、循环神经网络(RNN)等算法,通过ND4J库实现CUDA内核调用,集成Hadoop、Spark,支持大规模数据训练 ,兼容GPU加速和分布式计算,适用于金融、工业、推荐系统等领域。
- 支持的语言:Java/Scala等
- GitHub源码地址:https://github.com/eclipse/deeplearning4j