摘要
本文主要介绍了 JanusGraph 图数据库系统。阐述了其特点、优势、劣势以及与其他数据库的对比。还列举了影响其性能的关键因素,如后端数据库选择、索引设计等,并提供了企业使用 JanusGraph 的真实案例,如支付公司风控、银行反欺诈等场景,展示了其在不同场景下的数据量、查询延迟等指标。
1. JanusGraph图数据简介
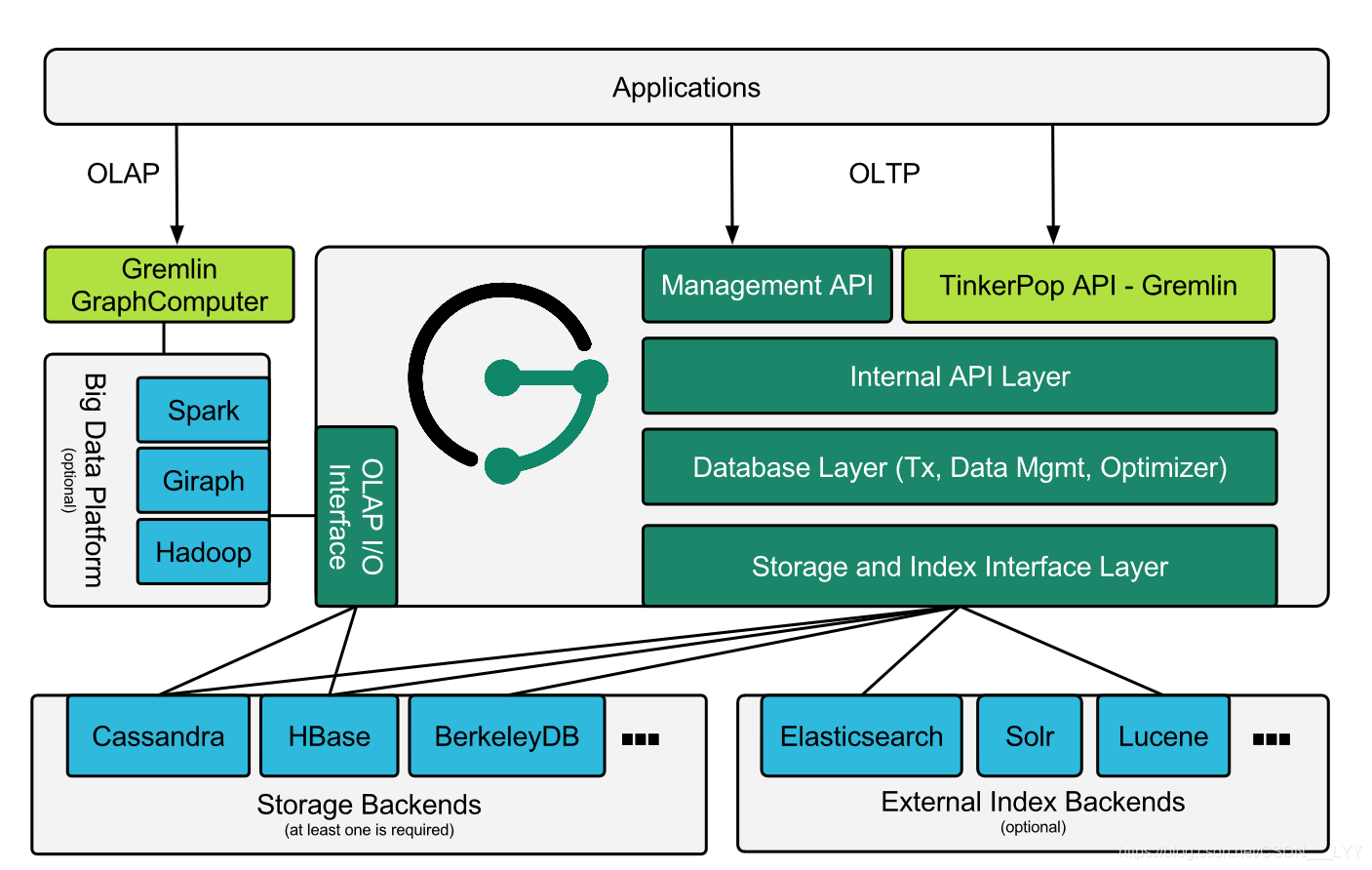
1.1. JanusGraph图数据库特点
JanusGraph 是一个分布式、可扩展的开源图数据库(Graph Database) ,用于存储和查询高度关联的数据(图结构:点+边)。它不是一个单机数据库,而是一个 分布式图引擎,底层依赖其他存储系统。
|------|-----------------------------------------------------|
| 类别 | 描述 |
| 数据模型 | 属性图(Property Graph):顶点(Vertex)、边(Edge)、属性(Property) |
| 查询语言 | Gremlin(Apache TinkerPop) |
| 架构定位 | 图数据库计算层(存储层可插拔) |
| 适用场景 | 知识图谱、风控关系网络、反欺诈、多跳关联查询、推荐等 |
1.2. JanusGraph使用场景(金融风控非常常用)
1.2.1. 风控 & 反欺诈图分析
- 多设备登录识别
- 人机异常身份识别
- 多手机号/银行卡聚合关系
- 企业关联(法人 → 董监高 → 投资链)
1.2.2. 知识图谱
- 信贷企业画像
- 支付风险图谱
- 用户关系网络图谱
1.2.3. 推荐系统 / 社交关系
- 用户关系推荐
- 关注网络分析
1.3. JanusGraph是"可插拔分布式图数据库"
JanusGraph 本质上是一个 图数据库逻辑层,底层存储可以自由选择:
- 可插拔存储后端 (支持分布式)
|-----------|---------------------|
| 类别 | 存储系统 |
| 分布式 KV 存储 | Cassandra、HBase |
| 高性能 KV | ScyllaDB |
| 内存存储(仅测试) | BerkeleyDB |
- 可插拔索引系统
|-----------|---------------------------|
| 用途 | 系统 |
| 全文搜索 / 排序 | Elasticsearch、Solr、Lucene |
| 精准索引 | 内建索引或 Elastic |
JanusGraph = 图结构 + 分布式 KV + 搜索引擎。因此它能轻松扩容、存超大规模图数据(几十亿节点、边)。
1.4. 🔥 JanusGraph 的优势
1.4.1. 1️⃣ 超大规模图计算能力(最核心)
关系型数据库、Neo4j 单机版无法处理上 10 亿级 的节点和边。
但 JanusGraph 能做到:
- 分布式存储(Cassandra/HBase)
- 数据水平扩容(scale out)
- 图遍历支持多跳(multi-hop)
非常适合 反欺诈网络、资金路径图、企业关联图。
1.4.2. 2️⃣ 高可用、分布式
底层使用 Cassandra/HBase,你自动获得:
- 副本数
- 多机房容灾
- CAP 策略保证
- 横向扩容
Neo4j 要实现分布式扩展 → 需要收费的 *Neo4j Fabric / Enterprise,*JanusGraph → 完全开源。
1.4.3. 3️⃣ 与大数据生态兼容
你可以直接和 Hadoop / Spark / Kafka 集成,例如:
- Spark 图计算(GraphX)
- 实时流式写入(Kafka → JanusGraph)
- HBase/Cassandra 的备份能力
适合你当前关注的 知识图谱 + 风控大数据系统。
1.5. ⚠️ JanusGraph 的缺点
1.5.1. 1️⃣ 写入延迟比单机数据库大
因为底层是分布式系统(Cassandra/HBase):
- 单条写延迟比 Neo4j 高
- 大批量写需要调优(写入吞吐 OK)
适合"读多写少"场景。
1.5.2. 2️⃣ 部署、运维复杂
你需要维护:
- JanusGraph 服务
- Cassandra 或 HBase 集群
- Elasticsearch/Solr
- TinkerPop Gremlin Server
比 Neo4j 单机安装复杂很多。
1.5.3. 3️⃣ 社区活跃度不如 Neo4j
- 功能成熟度可以,但商业支持较弱。
- 最适合有大数据经验的团队(你目前风控方向非常契合)。
1.5.4. 4️⃣ 不支持纯事务(依赖存储后端)
支持 ACID 事务,但强一致性依赖后端存储(Cassandra 默认 AP)。若你需要严格 ACID、强一致 → Neo4j 更合适。
1.6. JanusGraphvs其他数据库对比
1.6.1. JanusGraph vs Neo4j(图数据库)
|-----|-----------------------|-------------------|
| 角度 | JanusGraph | Neo4j |
| 架构 | 分布式 | 单机(集群要付费) |
| 扩展性 | 水平扩展(HBase/Cassandra) | 受限(Fabric 写入不分布式) |
| 成本 | 免费开源 | 企业版要收费 |
| 性能 | 多跳查询强,但写入稍慢 | 单机性能最好 |
| 运维 | 难度高 | 简单 |
总结:大规模图(>10 亿边)选 JanusGraph;中小规模选 Neo4j。
1.6.2. JanusGraph vs 关系型数据库(MySQL/PostgreSQL)
|------|--------------|------------|
| 角度 | JanusGraph | MySQL |
| 数据模型 | 图结构,多跳关联快 | 表结构,多表关联慢 |
| 关系查询 | n-hop 多跳,毫秒级 | join 多跳性能差 |
| 扩展性 | 分布式 | 主从复制,扩展有限 |
| 应用场景 | 反欺诈、推荐、知识图谱 | 业务系统、交易系统 |
1.6.3. JanusGraph vs NoSQL(Redis/MongoDB)
|--------|------------|-------------|
| 角度 | JanusGraph | Redis/Mongo |
| 存储模型 | 图 | KV / 文档 |
| 多跳关系查询 | 强 | 弱 |
| 扩展性 | 强 | 强 |
| 适用 | 关联网络 | 普通查询存储 |
Redis/Mongo 做图查询性能远不如 JanusGraph。
1.6.4. JanusGraph 写入性能指标(真实可参考)
- 顶点写入吞吐(Vertices Write Throughput)
|-------|--------------|----------------|-----------|
| 集群规模 | Cassandra 容量 | 顶点写入 TPS | 延迟(p99) |
| 单机 | 1 节点 | 5k -- 15k | 10--25 ms |
| 3 节点 | RF=3 | 20k -- 40k | 15--30 ms |
| 6 节点 | RF=3 | 40k -- 80k | 20--40 ms |
| 12 节点 | RF=3 | 100k+ | 20--50 ms |
- 边写入吞吐(Edges Write Throughput)
边写入成本比节点高(需要两方向存储)。
|-------|------------|-----------|
| 集群 | 边写入 TPS | 延迟(p99) |
| 单机 | 3k -- 10k | 15--30 ms |
| 3 节点 | 10k -- 25k | 20--40 ms |
| 6 节点 | 20k -- 40k | 25--45 ms |
| 12 节点 | 50k -- 70k | 25--60 ms |
真实系统中:边数量往往是点的 3~10 倍 → 边写入是瓶颈。
- 批量写 Bulk Load
Bulk Load(使用 Hadoop Bulk Loader / Spark)效率更高:
|----------------|------------------|
| 方式 | 指标 |
| Bulk Load(百万级) | 20--50 万 / 秒 |
| Bulk Load(十亿级) | 每小时 1 亿+ |
Bulk Load 会跳过 JanusGraph 事务层,直接写到底层 Cassandra/HBase。
1.6.5. JanusGraph 查询性能指标(真实可参考)
JanusGraph 最大优势是多跳查询、多关系图遍历。我们按查询类型给指标。
- 点查(vertex by id)
JanusGraph → O(1) 查询
|----------|----------------|-----------------------------------|
| 查询类型 | TPS | p99 延迟 |
| 点查(id 查) | 10k -- 50k | 1--5 ms (内存命中) 10--20 ms(跨节点) |
非常快,和 Redis 程度类似。
- 1-hop 邻居查询(最常见)
风控最常用:例如 "手机号 → 关联设备列表"
|---------------|-----------|
| 节点度数 | 查询时间 |
| 10--100 条边 | < 5 ms |
| 100--1000 条边 | 5--20 ms |
| 1000--5000 条边 | 20--50 ms |
如果加二级索引 + Elasticsearch,性能更稳。
- N-hop 查询(多跳查询,图数据库核心能力)
风控常用:A → 设备 → B → 账户 → C(多达 3~5 hops)
|-------|-------------|
| 跳数 | 指标(典型) |
| 2-hop | 5--30 ms |
| 3-hop | 20--50 ms |
| 4-hop | 50--150 ms |
| 5-hop | 100--300 ms |
在 Neo4j 单机情况下 3--4 hop 会明显变慢但 JanusGraph 分布式可维持较稳定性能
- 路径查询(最短路径 shortestPath)
|-----------|-----------|-------------|
| 图规模 | median | p99 |
| 小规模图(百万级) | 5--30 ms | 50--200 ms |
| 大图(十亿级) | 20--80 ms | 100--300 ms |
- 子图抽取(subgraph)
例如:"取某用户 5 层以内的关系图"
|-----------|--------------|
| 子图大小 | 查询耗时 |
| 1000 节点子图 | 20--100 ms |
| 1 万节点子图 | 100--300 ms |
| 10 万节点子图 | 300--1000 ms |
超 10w 节点通常建议用 Spark GraphX 或 GraphFrames。
- Adjacency List(邻接列表)查询
图数据库最强项:
|--------|----------|
| 查询 | 延迟 |
| 获取所有出边 | 1--5 ms |
| 获取所有入边 | 3--7 ms |
| 带过滤的出边 | 5--20 ms |
- 全文检索(Elasticsearch 后端)
用于:名称搜索、模糊搜索、属性条件过滤
|---------|--------------|
| 指标 | 数值 |
| 每秒索引查询量 | 100--500 QPS |
| 延迟 | 10--40 ms |
比 Neo4j 自带索引更强。
1.7. 影响 JanusGraph 性能的关键因素(非常重要)
1.7.1. 后端数据库的选择
|-----------|----------------|-----------|
| 后端 | 特性 | 性能 |
| Cassandra | 高写入、低延迟、EC 分区 | 推荐,最高 |
| HBase | 强一致性、读较慢 | 次之 |
| ScyllaDB | 类 Cassandra,更快 | 最好但商业版较贵 |
你是金融风控 → 推荐 Cassandra / ScyllaDB
1.7.2. 索引设计(影响 10x 以上性能)
- JanusGraph composite index(精确索引)
- Elasticsearch(全文索引)
- Mixed Index(混合索引)
没有索引查询会非常慢!
1.7.3. 查询模式
- 不要查询"全图"
- 控制遍历深度(2--3 hop 最常用)
- 控制节点度(避免超级节点)
1.7.4. 集群规模
集群越大吞吐越高,但延迟不会无限降低。
1.8. JanusGraph典型真实案例(企业提供的指标)
|--------------|-----------------|-------------------|--------------------|
| 企业 | 数据量 | 查询延迟 | 备注 |
| 支付公司(风控) | 20 亿边 | 2-hop 15ms | Cassandra + ES |
| 银行(反欺诈) | 8 亿节点、40 亿边 | 3-hop < 80ms | HBase 后端 |
| 电商 | 5 亿边 | 点查 <10ms | 用户行为图 |
| 物流风险图谱 | 10 亿关系 | 批量写 20 万条/秒 | Bulk Loader |