神经网络类算法
-
前馈神经网络(FFNN):基础结构,信息单向流动,适用于简单任务如手写数字识别 。
-
卷积神经网络(CNN):专为网格数据设计,通过卷积核和池化操作处理图像、音频等数据,广泛应用于图像分类、目标检测 。
-
循环神经网络(RNN):处理序列数据,但存在梯度消失问题,变体如LSTM和GRU改进了长期依赖处理能力 。
循环神经网络(RNN)
参考链接:https://blog.csdn.net/xiaoyingxixi1989/article/details/151627962
循环神经网络(Recurrent Neural Network,RNN)是专门为处理序列数据而设计的神经网络,它的结构中存在隐藏层的自连接,这使得它能够保存和利用过去的信息来处理当前的输入,就像一个人在做事时会参考自己以往的经验。在处理文本时,RNN 可以依次读取每个单词,并根据之前读取的单词信息来理解当前单词的含义,从而更好地处理整个文本;在时间序列分析中,它能够根据过去的时间序列数据预测未来的趋势,如预测股票价格的走势。
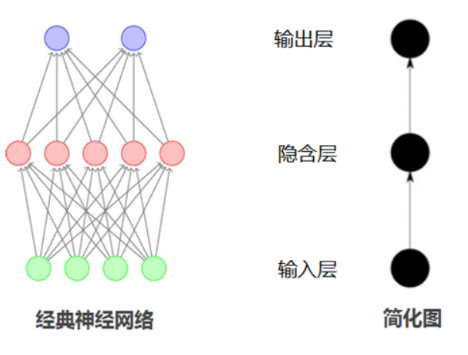
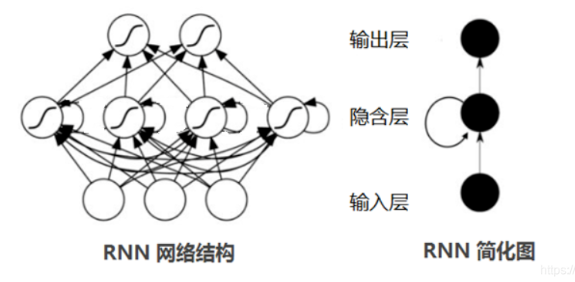
然而,RNN 在处理长序列数据时,会遇到梯度消失或梯度爆炸的问题。梯度消失使得模型难以学习到长期的依赖关系,就像随着时间的推移,过去的经验对当前的决策影响越来越小;梯度爆炸则可能导致模型训练不稳定。为了解决这些问题,长短期记忆网络(Long Short - Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)应运而生。LSTM 通过引入遗忘门、输入门和输出门,实现了对信息的选择性记忆和遗忘。遗忘门决定保留或丢弃上一时刻隐藏状态中的信息;输入门控制新信息的输入;输出门确定当前时刻的输出,这使得它能够有效地处理长序列数据,记住重要的信息。GRU 则是对 LSTM 的简化,它合并了遗忘门和输入门,形成更新门,同时将输出门改为重置门,在保持一定性能的同时,减少了计算量,提高了训练效率 。
RNN 及其变体在自然语言处理和时间序列分析中有着广泛的应用。在自然语言处理中,机器翻译、文本生成、情感分析等任务都离不开它们;在时间序列分析中,除了股票价格预测,还可以用于气象数据预测、电力负荷预测等,为相关领域的决策提供重要支持。
RNN基本结构
参考链接:https://blog.csdn.net/xiaoyingxixi1989/article/details/151690012
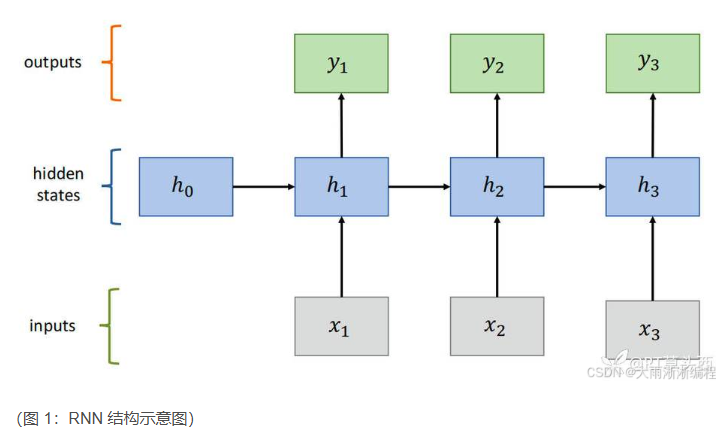
循环神经网络主要由输入层、隐藏层和输出层构成 ,其结构如图 1 所示。与传统神经网络不同的是,隐藏层之间存在连接,这是 RNN 的关键所在。在处理序列数据时,每个时间步(可以理解为序列中的每个位置,比如文本中的每个单词,时间序列中的每个时间点),输入层接收当前时刻的输入,同时隐藏层会接收上一个时间步的隐藏状态。隐藏层根据这两个输入进行计算,得到当前时间步的隐藏状态 ,这个隐藏状态不仅包含了当前输入的信息,还融合了之前时间步的信息,就像我们在阅读文章时,每读到一个新的句子,都会结合之前读过的内容来理解一样。之后,隐藏状态被传递到输出层,生成当前时间步的输出。
这种结构设计使得 RNN 能够处理任意长度的序列数据,并且可以将时刻以前的信息保留下来,使得模型具有更好的表达能力。同时,RNN 还有一个优点,就是参数共享,也就是在每一个时间步中,我们计算中间输出和标签输出时使用的都是同一组权重参数,这使得网络中需要训练的参数量大大减少,节省了大量计算开销 。
反向传播与梯度问题
在训练 RNN 时,我们需要通过反向传播算法来调整网络的参数,使得网络的预测结果与真实标签之间的误差最小。反向传播算法的基本思想是利用链式法则,从输出层开始,将误差反向传播到每一层,计算出每一个权重和偏置的梯度,然后根据梯度来更新参数 。然而,RNN 在反向传播过程中会遇到梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)的问题。这两个问题都与梯度在时间步上的传播有关。
梯度消失问题:
在 RNN 中,梯度在反向传播时,会随着时间步的回溯不断地乘以权重矩阵和激活函数的导数。当权重矩阵的某些元素绝对值小于 1,且经过多个时间步的连乘后,梯度会变得越来越小,趋近于 0。这就导致在更新前面时间步的参数时,梯度几乎不起作用,网络无法有效地学习到长距离的依赖关系 。例如,在处理一个很长的文本时,前面单词的信息在反向传播过程中可能会因为梯度消失而无法有效地影响后面的参数更新,使得模型对文本开头部分的信息 "遗忘"。
梯度爆炸问题:
当权重矩阵的某些元素绝对值大于 1 时,经过多个时间步的连乘,梯度会变得越来越大,导致参数更新时变化过于剧烈,使得网络训练不稳定,甚至无法收敛 。这就好比一辆汽车在行驶过程中,油门突然踩得过大,车子就会失控。
长短期记忆网络(LSTM)
长短期记忆网络(Long Short-Term Memory,LSTM)是为了解决 RNN 长期依赖问题而诞生的。在 RNN 中,由于梯度消失或梯度爆炸的问题,模型很难学习到序列中相隔较远的信息之间的依赖关系 。而 LSTM 通过引入门控机制和细胞状态,成功地解决了这一难题。
长LSTM 的核心结构包括遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)和细胞状态(Cell State)。
- 遗忘门决定从细胞状态中丢弃哪些信息,它通过一个 sigmoid 函数生成一个 0 到 1 之间的值,表示每个状态值的保留程度。
- 输入门决定当前时刻新输入信息哪些部分应被添加到细胞状态中。它由两部分构成:一个 sigmoid 层决定哪些值将被更新,一个 tanh 层生成新的候选值向量。
- 细胞状态就像一个传送带,贯穿 LSTM 单元的整个链条,它可以在序列的处理过程中长时间地保存和传递信息,并且能够选择性地更新和遗忘信息,从而实现对长期依赖的建模 。细胞状态的更新是通过遗忘门的输出和输入门的输出相加得到的,这样可以确保网络能够记住重要的长期信息,并遗忘不相关的信息 。
- 输出门决定记忆单元状态的哪一部分将被输出到隐藏状态。它通过一个 sigmoid 层决定哪些单元状态将被输出,然后通过 tanh 层生成输出状态的候选值,最后将这两部分结合起来形成最终的输出 。
门控循环单元(GRU)
门控循环单元(Gated Recurrent Unit,GRU)是 LSTM 的简化版本,它在 2014 年被提出 。GRU 同样是为了解决 RNN 的长期依赖问题,通过引入门控机制来控制信息的流动,从而减少梯度消失和梯度爆炸的问题 。
GRU 主要包含两个门:更新门(Update Gate)和重置门(Reset Gate) 。
- 更新门决定了当前时间步的隐藏状态需要保留多少前一个时间步的信息,其输出值介于 0 和 1 之间,值越大表示保留的过去信息越多,值越小则意味着更多地依赖于当前输入的信息 。
- 重置门决定了如何将新的输入信息与前面的记忆相结合,类似于 LSTM 的遗忘门,但工作方式稍有不同 。当重置门接近 0 时,意味着忽略过去的隐藏状态,更多地关注当前输入;当重置门接近 1 时,表示完全考虑过去的状态 。在处理一段对话时,如果重置门的值较低,那么在回答当前问题时,模型会较少参考之前的对话内容,更侧重于当前问题的信息;如果重置门的值较高,模型则会综合考虑整个对话的上下文来回答问题。
循环神经网络的应用场景
- 文本分析与生成
- 自然语言处理
RNN可用于词性标注、命名实体识别、句子解析等任务。通过捕获文本中的上下文关系,RNN能够理解并处理语言的复杂结构。 - 机器翻译
RNN能够理解和生成不同语言的句子结构,使其在机器翻译方面特别有效。 - 文本生成
利用RNN进行文本生成,如生成诗歌、故事等,实现了机器的创造性写作。
- 自然语言处理
- 语音识别与合成
- 语音到文本
RNN可以用于将语音信号转换为文字,即语音识别(Speech to Text),理解声音中的时序依赖关系。 - 文本到语音
RNN也用于文本到语音(Text to Speech)的转换,生成流畅自然的语音。
- 语音到文本
- 时间序列分析
- 股票预测
通过分析历史股票价格和交易量等数据的时间序列,RNN可以用于预测未来的股票走势。 - 气象预报
RNN通过分析气象数据的时间序列,可以预测未来的天气情况。
- 股票预测
- 视频分析与生成
- 动作识别
RNN能够分析视频中的时序信息,用于识别人物动作和行为模式等。 - 视频生成
RNN还可以用于视频内容的生成,如生成具有连续逻辑的动画片段。
- 动作识别
循环神经网络代码实现
参考链接:https://cloud.tencent.com/developer/article/2348483
环境准备
环境准备主要包括选择合适的编程语言、深度学习框架、硬件环境等。
- 编程语言:Python是深度学习中广泛使用的语言,有丰富的库和社区支持。
- 深度学习框架:PyTorch是一种流行的开源框架,具有强大的灵活性和易用性。
- 硬件要求:GPU加速通常可以显著提高训练速度。
数据预处理
数据预处理是机器学习项目中的关键步骤,可以显著影响模型的性能。
- 数据加载:首先加载所需的数据集。
- 数据清洗:删除或替换缺失、重复或错误的值。
- 文本分词:如果是NLP任务,需要对文本进行分词处理。
- 序列填充:确保输入序列具有相同的长度。
- 归一化:对特征进行标准化处理。
- 数据分割:将数据分为训练集、验证集和测试集。
使用PyTorch构建RNN模型
PyTorch是一种流行的深度学习框架,广泛用于构建和训练神经网络模型。
python
#定义RNN结构:RNN模型由输入层、隐藏层和输出层组成。
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out)
return out
#初始化模型:初始化模型涉及设置其参数和选择优化器与损失函数。
model = SimpleRNN(input_size=10, hidden_size=20, output_size=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
#训练模型
#训练模型包括以下步骤:
#1. 前向传播:通过模型传递输入数据并计算输出。
#2. 计算损失:使用预测输出和实际目标计算损失。
#3. 反向传播:根据损失计算梯度。
#4. 优化器步骤:更新模型权重。
# 训练循环示例
for epoch in range(epochs):
for batch in train_loader:
inputs, targets = batch
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
#模型评估和保存:通过在验证集或测试集上评估模型,您可以了解其泛化性能。一旦满意,可以保存模型供以后使用。
# 保存模型
torch.save(model.state_dict(), 'model.pth')
#评估模型:在验证集上评估模型可以了解模型在未见过的数据上的性能。
model.eval()
with torch.no_grad():
for batch in val_loader:
inputs, targets = batch
outputs = model(inputs)
val_loss += criterion(outputs, targets).item()
print(f'Validation Loss: {val_loss/len(val_loader)}')