生成式算法
- 生成对抗网络(GAN):由生成器和判别器组成,用于生成逼真数据 。
- 变分自编码器(VAE):通过概率建模生成数据,常用于数据增强 。
生成对抗网络(GAN)
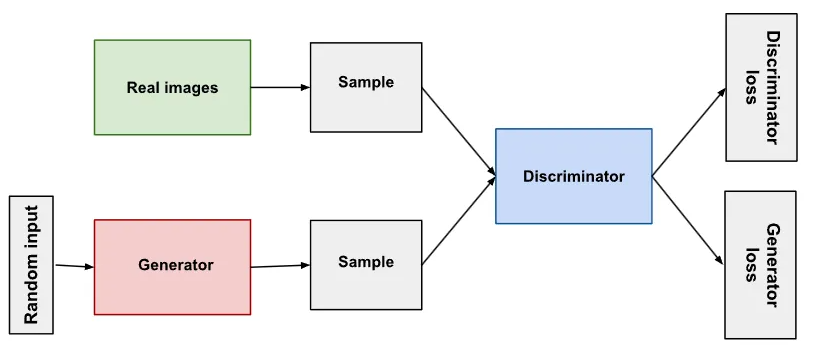
生成对抗网络(Generative Adversarial Network,GAN)是一种深度学习模型,由Ian Goodfellow及其同事于2014年提出。GAN的主要思想是通过两个相互竞争的神经网络模型------生成器(Generator)和判别器(Discriminator),来达到生成逼真数据的目的。生成器试图生成足以欺骗判别器的数据,而判别器则试图区分真实数据和生成器生成的数据。这一过程是一个不断迭代的博弈,直至生成器生成的数据无法被判别器区分为真实数据。
生成器就像一位技艺高超的 "造假者",它以随机噪声作为输入,通过神经网络的层层变换,努力生成看似真实的数据样本,如逼真的图像、生动的文本等;判别器则扮演着火眼金睛的 "鉴别专家",它接收真实数据和生成器生成的假数据,经过分析判断,输出一个概率值,表示输入数据是真实数据的可能性。
在训练过程中,生成器和判别器相互对抗、交替优化。生成器不断改进自己的 "造假技术",试图生成更逼真的数据,以迷惑判别器;判别器则不断提升自己的 "鉴别能力",力求准确地区分真实数据和假数据 。当生成器生成的数据足够逼真,判别器无法准确判断其真伪时,就达到了一种动态平衡,此时生成器便能够生成高质量的、与真实数据非常相似的数据。
生成器(Generator)
生成器是GAN的一部分,其任务是学习生成与真实数据相似的数据。生成器将输入噪声数据映射到生成数据的空间。其结构通常是一个由多层神经网络组成的模型。生成器的目标是最小化生成数据与真实数据之间的差异,以欺骗判别器。
判别器(Discriminator)
判别器是GAN的另一部分,其任务是学习区分生成器生成的数据和真实数据。判别器同样是一个多层神经网络,其输出为二进制,表示输入数据是真实数据还是生成数据。判别器的目标是最大化正确分类真实数据和生成数据的概率。
对抗训练过程
GAN的核心在于生成器和判别器之间的对抗训练。整个过程可分为以下几个步骤:
步骤1:初始化
• 随机初始化生成器和判别器的参数。
步骤2:生成器生成数据
• 生成器接收噪声数据作为输入,生成一批模拟数据。
步骤3:判别器评估数据
• 判别器接收一批真实数据和生成器生成的数据,分别进行评估,并输出相应的概率。
步骤4:计算损失
• 根据判别器对真实数据和生成数据的评估,计算生成器和判别器的损失。生成器的损失旨在欺骗判别器,使其将生成数据误认为真实数据;判别器的损失旨在正确分类真实和生成的数据。
步骤5:反向传播与参数更新
• 根据损失,进行反向传播,并更新生成器和判别器的参数。生成器的目标是减小判别器的损失,而判别器的目标是增大其对生成数据的区分能力。
步骤6:重复迭代
• 重复以上步骤,直至生成器生成的数据无法被判别器区分为真实数据。
参考链接:https://blog.csdn.net/xiaoyingxixi1989/article/details/151627962
GAN的应用
GAN 在图像生成领域有着广泛的应用。在人脸图像生成中,它可以生成各种不同表情、发型和肤色的人脸,这些生成的人脸图像细节丰富、栩栩如生,甚至能够以假乱真;
在图像风格迁移中,GAN 能够将一种图像的风格迁移到另一种图像上,如将梵高的绘画风格迁移到普通的风景照片上,创造出具有艺术感的新图像;
在数据增广方面,对于一些数据量较少的数据集,GAN 可以生成新的样本,扩充数据集,提高模型的泛化能力 。
超分辨率重建:GAN可以用于提高低分辨率图像的质量,生成高分辨率图像。
文本生成:虽然GAN主要用于图像生成,但也可以扩展到文本生成领域,用于自动写作、对话系统等。
GAN的使用方法
- 数据准备:收集并预处理训练数据集,确保数据质量。
定义生成器和判别器:根据具体任务选择合适的网络结构,如全连接层、卷积层等。 - 损失函数设计:通常使用交叉熵损失函数来衡量生成器和判别器的表现。
- 训练过程:
- 初始化生成器和判别器的参数。
- 训练判别器:输入真实数据和生成数据,更新判别器参数以提高其区分能力。
- 训练生成器:固定判别器参数,输入随机噪声,更新生成器参数以提高其生成能力。
- 交替训练生成器和判别器,直到达到预定的迭代次数或满足其他停止条件。
- 评估与调整:通过可视化生成结果、计算指标等方式评估模型性能,并根据需要调整网络结构和超参数。
变分自编码器(VAE)
变分自编码器(Variational Autoencoder,VAE)是一种基于概率模型的生成式算法,它的核心思想是将高维数据映射到一个低维的潜在空间,并在该空间中进行概率建模。
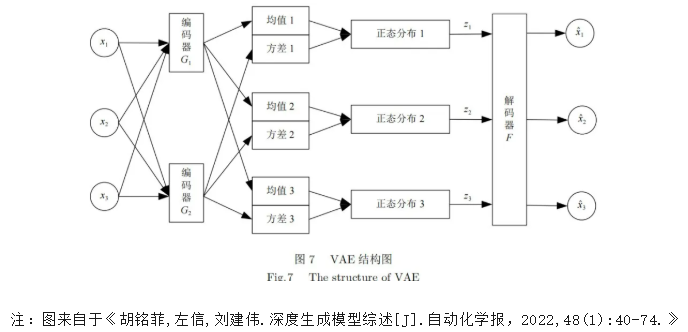
VAE 主要由编码器和解码器两部分组成。编码器 就像一个 "压缩器",它将输入数据压缩成潜在空间中的参数,即均值和方差,通过这些参数定义一个概率分布;然后从这个概率分布中采样得到一个潜在向量,这个过程引入了随机性,使得模型能够生成多样化的样本 。解码器 则是一个 "重建器",它将潜在向量作为输入,通过神经网络的运算,重建出与原始数据相似的数据样本。
在图像生成任务中,VAE 可以从潜在空间中随机采样,生成新的图像。这些生成的图像具有一定的多样性,且与训练数据的分布相似;在异常检测领域,VAE 可以通过学习正常数据的分布,当输入数据与正常数据的分布差异较大时,判断其为异常数据,例如在工业生产中检测产品的缺陷,在医疗影像中检测病变等 。
VAE 的优势在于它提供了一个连续且结构化的潜在空间,使得在潜在空间中进行操作更加自然,例如可以通过对潜在向量进行插值,生成具有中间特征的样本。但它生成的图像质量相对 GAN 来说可能略低,在一些对图像质量要求极高的场景中,可能无法满足需求 。
算法原理
VAE的核心思想是将输入数据映射到一个连续的概率分布中,通过采样该分布来生成新的数据。其模型基本结构与自编码器相似,都是由编码器(Encoder)和解码器(Decoder)两部分组成,两者区别在于VAE的隐藏变量z是随机变量,编码器将输入数据 x 映射到潜在空间的分布参数,通常是均值μ和方差σ,解码器则从潜在空间的样本z中重构出数据。
算法的应用
VAE 最广泛的应用之一是图像生成。它能够学习图像的潜在表示,并生成与训练数据相似的新图像,例如,使用 VAE 可以生成手写数字图像,通过在潜在空间中插值。VAE也常用于特征提取、文档检索、异常检测等,通过将高维数据映射到低维的潜在空间,VAE 能够提取数据的主要特征,同时去除噪声,这在处理大规模数据集时非常有用,可以减少存储空间和计算成本。在异常检测任务中,VAE 可以通过重建误差来判断数据是否异常,如果输入数据与重建数据之间的差异较大,则认为该数据是异常的,这种方法在金融欺诈检测、网络安全等领域具有重要应用。
在中医药领域,VAE展现出了巨大的潜力。中药方剂的组成复杂,传统方法依赖于中医专家的经验和知识,VAE可以用于中药方剂的生成,通过学习大量已有的中药方剂数据,提取方剂的潜在特征,从而生成新的方剂;通过对中药成分的光谱数据或色谱数据进行建模,VAE 可以学习中药成分的正常分布,如果某个样本的重建误差显著高于正常范围,则可以判断该样本存在质量问题。此外,研究者还可以将中药成分的化学数据或中医临床数据输入 VAE 模型,通过可视化潜在空间的分布,发现数据中的潜在规律和关联,以及中医药知识图谱的构建和完善等都可通过VAE提高效率与准确度。