MySqlSource
Flink CDC MySqlSource可获取mysql表schema以及表数据变更,MySqlSource创建MySqlSourceEnumerator实现数据分片,创建MySqlSourceReader读取分片数据。
MySqlSourceEnumerator
MySqlSourceEnumerator根据是否读取全量数据区分不同的分片策略,需要读取全量数据用MySqlBinlogSplitAssigner,仅读取Binlog变更数据使用MySqlBinlogSplitAssigner
MySqlBinlogSplitAssigner
BinlogSplit创建比较简单,直接创建一个ID为binlog-split的MySqlSplit, 指定binlog起始位置,无停止位置
private MySqlBinlogSplit createBinlogSplit() {
return new MySqlBinlogSplit(
BINLOG_SPLIT_ID,
sourceConfig.getStartupOptions().binlogOffset,
BinlogOffset.ofNonStopping(),
new ArrayList<>(),
new HashMap<>(),
0);
}MySqlHybridSplitAssigner
基于无锁算法,先通过MySqlSnapshotSplitAssigner将全量snapshot数据按splitKey切分成多个split分发给SourceReader读取,snapshot读取完成后,再创建一个BinlogSplit读取增量变更数据。
MySqlSnapshotSplit
MySqlSnapshotSplitAssigner使用MySqlChunkSplitter基于均分算法将表划分为多个split
public List<MySqlSnapshotSplit> splitChunks(MySqlPartition partition, TableId tableId)
throws Exception {
if (!hasNextChunk()) {
analyzeTable(partition, tableId);
Optional<List<MySqlSnapshotSplit>> evenlySplitChunks =
trySplitAllEvenlySizedChunks(partition, tableId);
if (evenlySplitChunks.isPresent()) {
return evenlySplitChunks.get();
} else {
synchronized (lock) {
this.currentSplittingTableId = tableId;
this.nextChunkStart = ChunkSplitterState.ChunkBound.START_BOUND;
this.nextChunkId = 0;
return Collections.singletonList(
splitOneUnevenlySizedChunk(partition, tableId));
}
}
} else {
Preconditions.checkState(
currentSplittingTableId.equals(tableId),
"Can not split a new table before the previous table splitting finish.");
if (currentSplittingTable == null) {
analyzeTable(partition, currentSplittingTableId);
}
synchronized (lock) {
return Collections.singletonList(splitOneUnevenlySizedChunk(partition, tableId));
}
}
}MySqlBinlogSplit
MySqlHybridSplitAssigner::createBinlogSplit 根据snapshop split读取完成时的high watermark的最小值作为BinlogSplit的起始位值,BinlogSplitReader::shouldEmit会判断数据是否需要发送给下游,以避免与Snapshot阶段读取的数据发生重叠。
private MySqlBinlogSplit createBinlogSplit() {
final List<MySqlSchemalessSnapshotSplit> assignedSnapshotSplit =
snapshotSplitAssigner.getAssignedSplits().values().stream()
.sorted(Comparator.comparing(MySqlSplit::splitId))
.collect(Collectors.toList());
Map<String, BinlogOffset> splitFinishedOffsets =
snapshotSplitAssigner.getSplitFinishedOffsets();
final List<FinishedSnapshotSplitInfo> finishedSnapshotSplitInfos = new ArrayList<>();
BinlogOffset minBinlogOffset = null;
BinlogOffset maxBinlogOffset = null;
for (MySqlSchemalessSnapshotSplit split : assignedSnapshotSplit) {
// find the min and max binlog offset
BinlogOffset binlogOffset = splitFinishedOffsets.get(split.splitId());
if (minBinlogOffset == null || binlogOffset.isBefore(minBinlogOffset)) {
minBinlogOffset = binlogOffset; //全增量模式下增量阶段binlog起始位置
}
if (maxBinlogOffset == null || binlogOffset.isAfter(maxBinlogOffset)) {
maxBinlogOffset = binlogOffset;
}
finishedSnapshotSplitInfos.add(
new FinishedSnapshotSplitInfo(
split.getTableId(),
split.splitId(),
split.getSplitStart(),
split.getSplitEnd(),
binlogOffset));
}
// If the source is running in snapshot mode, we use the highest watermark among
// snapshot splits as the ending offset to provide a consistent snapshot view at the moment
// of high watermark.
BinlogOffset stoppingOffset = BinlogOffset.ofNonStopping();
if (sourceConfig.getStartupOptions().isSnapshotOnly()) {
stoppingOffset = maxBinlogOffset;
}
// the finishedSnapshotSplitInfos is too large for transmission, divide it to groups and
// then transfer them
boolean divideMetaToGroups = finishedSnapshotSplitInfos.size() > splitMetaGroupSize;
return new MySqlBinlogSplit(
BINLOG_SPLIT_ID,
minBinlogOffset == null ? BinlogOffset.ofEarliest() : minBinlogOffset,
stoppingOffset,
divideMetaToGroups ? new ArrayList<>() : finishedSnapshotSplitInfos,
new HashMap<>(),
finishedSnapshotSplitInfos.size());
}MySqlSourceReader
SourceReader在一个split读取完成后再去向SourceEnumerator请求下个split,使用MySqlSplitReader按顺序依次读取, 全量读取阶段多个SourceReader可并发执行,加快Snapshot数据读取完成时间。增量阶段只有一个SourceReader读取BinlogSplit。
全增量模式会先读取Snapshot Split数据,然后读取binlog数据。全量阶段的Snapshot spit完成后会向SourceEnumerator报告完成Split的High Watermark.
//Split完成后回调
protected void onSplitFinished(Map<String, MySqlSplitState> finishedSplitIds) {
boolean requestNextSplit = true;
if (isNewlyAddedTableSplitAndBinlogSplit(finishedSplitIds)) {
MySqlSplitState mySqlBinlogSplitState = finishedSplitIds.remove(BINLOG_SPLIT_ID);
finishedSplitIds
.values()
.forEach(
newAddedSplitState ->
finishedUnackedSplits.put(
newAddedSplitState.toMySqlSplit().splitId(),
newAddedSplitState.toMySqlSplit().asSnapshotSplit()));
Preconditions.checkState(finishedSplitIds.values().size() == 1);
LOG.info(
"Source reader {} finished binlog split and snapshot split {}",
subtaskId,
finishedSplitIds.values().iterator().next().toMySqlSplit().splitId());
this.addSplits(Collections.singletonList(mySqlBinlogSplitState.toMySqlSplit()));
} else {
Preconditions.checkState(finishedSplitIds.size() == 1);
for (MySqlSplitState mySqlSplitState : finishedSplitIds.values()) {
MySqlSplit mySqlSplit = mySqlSplitState.toMySqlSplit();
if (mySqlSplit.isBinlogSplit()) {
// Two possibilities that finish a binlog split:
//
// 1. Binlog reader is suspended by enumerator because new tables have been
// finished its snapshot reading.
// Under this case mySqlSourceReaderContext.isBinlogSplitReaderSuspended() is
// true and need to request the latest finished splits number.
//
// 2. Binlog reader reaches the ending offset of the split. We need to do
// nothing under this case.
if (mySqlSourceReaderContext.isBinlogSplitReaderSuspended()) {
suspendedBinlogSplit =
MySqlBinlogSplit.toSuspendedBinlogSplit(mySqlSplit.asBinlogSplit());
LOG.info(
"Source reader {} suspended binlog split reader success after the newly added table process, current offset {}",
subtaskId,
suspendedBinlogSplit.getStartingOffset());
context.sendSourceEventToCoordinator(
new LatestFinishedSplitsNumberRequestEvent());
// do not request next split when the reader is suspended
requestNextSplit = false;
}
} else {
finishedUnackedSplits.put(mySqlSplit.splitId(), mySqlSplit.asSnapshotSplit());
}
}
reportFinishedSnapshotSplitsIfNeed();
}
if (requestNextSplit) {
context.sendSplitRequest();
}
}
//报告split的HighWatermark
private void reportFinishedSnapshotSplitsIfNeed() {
if (!finishedUnackedSplits.isEmpty()) {
final Map<String, BinlogOffset> finishedOffsets = new HashMap<>();
for (MySqlSnapshotSplit split : finishedUnackedSplits.values()) {
finishedOffsets.put(split.splitId(), split.getHighWatermark());
}
FinishedSnapshotSplitsReportEvent reportEvent =
new FinishedSnapshotSplitsReportEvent(finishedOffsets);
context.sendSourceEventToCoordinator(reportEvent);
LOG.debug(
"Source reader {} reports offsets of finished snapshot splits {}.",
subtaskId,
finishedOffsets);
}
}MySqlSplitReader
MySqlSplitReader根据当前分配的split类型,决定使用SnapshotSplitReader还是BinlogSplitReader从源头读取变更数据。
SnapshotSplitReader
SnapshotSplitReader先创建MySqlSnapshotSplitReadTask读取snapshot split数据,然后创建MySqlBinlogSplitReadTask读取在snapshot阶段打点范围内的binlog,最后将snapshot数据和binlog数据normalize后发送到下游。
public void submitSplit(MySqlSplit mySqlSplit) {
this.currentSnapshotSplit = mySqlSplit.asSnapshotSplit();
statefulTaskContext.configure(currentSnapshotSplit);
this.queue = statefulTaskContext.getQueue();
this.nameAdjuster = statefulTaskContext.getSchemaNameAdjuster();
this.hasNextElement.set(true);
this.reachEnd.set(false);
this.splitSnapshotReadTask =
new MySqlSnapshotSplitReadTask(
statefulTaskContext.getSourceConfig(),
statefulTaskContext.getConnectorConfig(),
statefulTaskContext.getSnapshotChangeEventSourceMetrics(),
statefulTaskContext.getDatabaseSchema(),
statefulTaskContext.getConnection(),
statefulTaskContext.getDispatcher(),
statefulTaskContext.getTopicSelector(),
statefulTaskContext.getSnapshotReceiver(),
StatefulTaskContext.getClock(),
currentSnapshotSplit,
hooks,
statefulTaskContext.getSourceConfig().isSkipSnapshotBackfill());
executorService.execute(
() -> {
try {
currentTaskRunning = true;
final SnapshotSplitChangeEventSourceContextImpl sourceContext =
new SnapshotSplitChangeEventSourceContextImpl();
// Step 1: execute snapshot read task
SnapshotResult<MySqlOffsetContext> snapshotResult = snapshot(sourceContext); //读取snapshot split数据
// Step 2: read binlog events between low and high watermark and backfill
// changes into snapshot
backfill(snapshotResult, sourceContext); //读取打点范围内的binlog数据
} catch (Exception e) {
setReadException(e);
} finally {
stopCurrentTask();
}
});
}MySqlSnapshotSplitReadTask
MySqlSnapshotSplitReadTask读取SnapshotSplit范围内的数据,但是在读取数据前后有个获取binlog位置的打点操作,即读取数据前的binlog position作为当前split的lower watermark, 读取完后后获取的binlog position为当前split的high watermark, 并将low watermark、snapshot split data、high watermark依次放入队列中。
protected SnapshotResult<MySqlOffsetContext> doExecute(
ChangeEventSourceContext context,
MySqlOffsetContext previousOffset,
SnapshotContext<MySqlPartition, MySqlOffsetContext> snapshotContext,
SnapshottingTask snapshottingTask)
throws Exception {
final MySqlSnapshotContext ctx = (MySqlSnapshotContext) snapshotContext;
ctx.offset = previousOffset;
final SignalEventDispatcher signalEventDispatcher =
new SignalEventDispatcher(
previousOffset.getOffset(),
topicSelector.topicNameFor(snapshotSplit.getTableId()),
dispatcher.getQueue());
if (hooks.getPreLowWatermarkAction() != null) {
hooks.getPreLowWatermarkAction().accept(jdbcConnection, snapshotSplit);
}
final BinlogOffset lowWatermark = DebeziumUtils.currentBinlogOffset(jdbcConnection); //获取lower watermark
LOG.info(
"Snapshot step 1 - Determining low watermark {} for split {}",
lowWatermark,
snapshotSplit);
((SnapshotSplitReader.SnapshotSplitChangeEventSourceContextImpl) (context))
.setLowWatermark(lowWatermark); //context中保存low wartermark
signalEventDispatcher.dispatchWatermarkEvent(
snapshotSplit, lowWatermark, SignalEventDispatcher.WatermarkKind.LOW); //将low watermark存入队列
if (hooks.getPostLowWatermarkAction() != null) {
hooks.getPostLowWatermarkAction().accept(jdbcConnection, snapshotSplit);
}
LOG.info("Snapshot step 2 - Snapshotting data");
createDataEvents(ctx, snapshotSplit.getTableId()); //将snapshot数据存入队列
if (hooks.getPreHighWatermarkAction() != null) {
hooks.getPreHighWatermarkAction().accept(jdbcConnection, snapshotSplit);
}
BinlogOffset highWatermark;
if (isBackfillSkipped) {
// Directly set HW = LW if backfill is skipped. Binlog events created during snapshot
// phase could be processed later in binlog reading phase.
//
// Note that this behaviour downgrades the delivery guarantee to at-least-once. We can't
// promise that the snapshot is exactly the view of the table at low watermark moment,
// so binlog events created during snapshot might be replayed later in binlog reading
// phase.
highWatermark = lowWatermark;
} else {
// Get the current binlog offset as HW
highWatermark = DebeziumUtils.currentBinlogOffset(jdbcConnection); //获取high watermark
}
LOG.info(
"Snapshot step 3 - Determining high watermark {} for split {}",
highWatermark,
snapshotSplit);
signalEventDispatcher.dispatchWatermarkEvent(
snapshotSplit, highWatermark, SignalEventDispatcher.WatermarkKind.HIGH); //将high watermark存入队列
((SnapshotSplitReader.SnapshotSplitChangeEventSourceContextImpl) (context)) //context中保存high wartermark
.setHighWatermark(highWatermark);
if (hooks.getPostHighWatermarkAction() != null) {
hooks.getPostHighWatermarkAction().accept(jdbcConnection, snapshotSplit);
}
return SnapshotResult.completed(ctx.offset);
}backfill基于Snapshot阶段low watermark和high watermark创建BinlogSplit, 然后启动MySqlBinlogSplitReadTask读取BinlogSplit范围内的数据以及产生一个BINLOG_END的watermark放入Queue中。
private void backfill(
SnapshotResult<MySqlOffsetContext> snapshotResult,
SnapshotSplitChangeEventSourceContextImpl sourceContext)
throws Exception {
//基于context中保存的watermark创建BinlogSplit
final MySqlBinlogSplit backfillBinlogSplit = createBackfillBinlogSplit(sourceContext);
// Dispatch BINLOG_END event directly is backfill is not required
if (!isBackfillRequired(backfillBinlogSplit)) {
dispatchBinlogEndEvent(backfillBinlogSplit);
stopCurrentTask();
return;
}
// execute binlog read task
if (snapshotResult.isCompletedOrSkipped()) {
final MySqlBinlogSplitReadTask backfillBinlogReadTask =
createBackfillBinlogReadTask(backfillBinlogSplit); //启动MySqlBinlogSplitReadTask
final MySqlOffsetContext.Loader loader =
new MySqlOffsetContext.Loader(statefulTaskContext.getConnectorConfig());
final MySqlOffsetContext mySqlOffsetContext =
loader.load(backfillBinlogSplit.getStartingOffset().getOffset());
backfillBinlogReadTask.execute(
changeEventSourceContext,
statefulTaskContext.getMySqlPartition(),
mySqlOffsetContext);
} else {
throw new IllegalStateException(
String.format("Read snapshot for mysql split %s fail", currentSnapshotSplit));
}
}MySqlBinlogSplitReadTask
MySqlBinlogSplitReadTask读取BinlogSplit逻辑如下:
protected void handleEvent(
MySqlPartition partition, MySqlOffsetContext offsetContext, Event event) {
if (!eventFilter.test(event)) {
return;
}
super.handleEvent(partition, offsetContext, event);
// check do we need to stop for read binlog for snapshot split.
if (isBoundedRead()) { //全增量模式下,读取Snapshot Split打点范围内的Binlog后向Queue中插入BINLOG_END watermark
final BinlogOffset currentBinlogOffset =
RecordUtils.getBinlogPosition(offsetContext.getOffset());
// reach the high watermark, the binlog reader should finished
if (currentBinlogOffset.isAtOrAfter(binlogSplit.getEndingOffset())) {
// send binlog end event
try {
signalEventDispatcher.dispatchWatermarkEvent(
binlogSplit,
currentBinlogOffset,
SignalEventDispatcher.WatermarkKind.BINLOG_END);
} catch (InterruptedException e) {
LOG.error("Send signal event error.", e);
errorHandler.setProducerThrowable(
new DebeziumException("Error processing binlog signal event", e));
}
// tell reader the binlog task finished
((StoppableChangeEventSourceContext) context).stopChangeEventSource();
}
}
}pollSplitRecords方法将同一个split范围内的snapshot数据及binlog normalize后再依次发送到下游
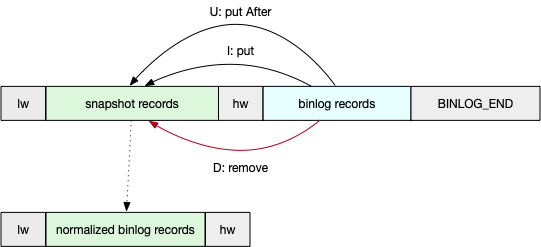
public Iterator<SourceRecords> pollSplitRecords() throws InterruptedException {
checkReadException();
if (hasNextElement.get()) {
// data input: [low watermark event][snapshot events][high watermark event][binlog
// events][binlog-end event] 输入模式
// data output: [low watermark event][normalized events][high watermark event] 输入模式
boolean reachBinlogStart = false;
boolean reachBinlogEnd = false;
SourceRecord lowWatermark = null;
SourceRecord highWatermark = null;
Map<Struct, List<SourceRecord>> snapshotRecords = new HashMap<>();
while (!reachBinlogEnd) {
checkReadException();
List<DataChangeEvent> batch = queue.poll();
for (DataChangeEvent event : batch) {
SourceRecord record = event.getRecord();
if (lowWatermark == null) {
lowWatermark = record;
assertLowWatermark(lowWatermark);
continue;
}
if (highWatermark == null && RecordUtils.isHighWatermarkEvent(record)) {
highWatermark = record;
// snapshot events capture end and begin to capture binlog events
reachBinlogStart = true;
continue;
}
if (reachBinlogStart && RecordUtils.isEndWatermarkEvent(record)) {
// capture to end watermark events, stop the loop
reachBinlogEnd = true;
break;
}
if (!reachBinlogStart) { //保存MySqlSnapshotSplitReadTask读取的数据
if (record.key() != null) {
snapshotRecords.put(
(Struct) record.key(), Collections.singletonList(record));
} else {
List<SourceRecord> records =
snapshotRecords.computeIfAbsent(
(Struct) record.value(), key -> new LinkedList<>());
records.add(record);
}
} else {
RecordUtils.upsertBinlog( //使用Binlog数据normalize MySqlSnapshotSplitReadTask读取的snapshot数据
snapshotRecords,
record,
currentSnapshotSplit.getSplitKeyType(),
nameAdjuster,
currentSnapshotSplit.getSplitStart(),
currentSnapshotSplit.getSplitEnd());
}
}
}
// snapshot split return its data once
hasNextElement.set(false);
final List<SourceRecord> normalizedRecords = new ArrayList<>();
normalizedRecords.add(lowWatermark);
normalizedRecords.addAll( //将normalize后的数据发送到下游
RecordUtils.formatMessageTimestamp(
snapshotRecords.values().stream()
.flatMap(Collection::stream)
.collect(Collectors.toList())));
normalizedRecords.add(highWatermark);
final List<SourceRecords> sourceRecordsSet = new ArrayList<>();
sourceRecordsSet.add(new SourceRecords(normalizedRecords));
return sourceRecordsSet.iterator();
}
// the data has been polled, no more data
reachEnd.compareAndSet(false, true);
return null;
}BinlogSplitReader
SourceEnumerator创建增量BinlogSplit时会将全量阶段完成Split及其High WaterMark传递给BinlogSplitReader。submitSplit 启动MySqlBinlogSplitReadTask前会取每个table下所有SnapshotSplit的High WaterMark的最大值作为该table的High WaterMark, 用于增量阶段判断是否到达PureBinlog阶段。
private void configureFilter() {
List<FinishedSnapshotSplitInfo> finishedSplitInfos =
currentBinlogSplit.getFinishedSnapshotSplitInfos();
Map<TableId, List<FinishedSnapshotSplitInfo>> splitsInfoMap = new HashMap<>();
Map<TableId, BinlogOffset> tableIdBinlogPositionMap = new HashMap<>();
// specific offset mode
if (finishedSplitInfos.isEmpty()) {
for (TableId tableId : currentBinlogSplit.getTableSchemas().keySet()) {
tableIdBinlogPositionMap.put(tableId, currentBinlogSplit.getStartingOffset()); //增量模式直接将起始值作为High Watermark
}
}
// initial mode
else { //全增量模式根据FinishedSnapshotSplitInfo获取table的High Watermark
for (FinishedSnapshotSplitInfo finishedSplitInfo : finishedSplitInfos) {
TableId tableId = finishedSplitInfo.getTableId();
List<FinishedSnapshotSplitInfo> list =
splitsInfoMap.getOrDefault(tableId, new ArrayList<>());
list.add(finishedSplitInfo);
splitsInfoMap.put(tableId, list);
BinlogOffset highWatermark = finishedSplitInfo.getHighWatermark();
BinlogOffset maxHighWatermark = tableIdBinlogPositionMap.get(tableId);
if (maxHighWatermark == null || highWatermark.isAfter(maxHighWatermark)) {
tableIdBinlogPositionMap.put(tableId, highWatermark); //保存table的High watermark
}
}
}
this.finishedSplitsInfo = splitsInfoMap;
this.maxSplitHighWatermarkMap = tableIdBinlogPositionMap;
this.pureBinlogPhaseTables.clear();
}BinlogSplitReader创建MySqlBinlogSplitReadTask从Split指定的起始位置读取变更数据放入Queue中缓存起来,然后从Queue中读取数据并判断是否与snapshot阶段有重叠,从而决定是否需要发送至下游。
如果未读取过全量数据,则BinlogSplit起始位置后的数据都该发送至下游。
如果先读取全量数据再读取binlog数据,在全增量切换时BinlogSplit的起始位置是全量阶段完成的所有split中high wartermark的最小值。
当某个表被读取的Binlog时间戳大于此表snapshot阶段完成的max(table split high watermark)时,此表进入PureBinlog阶段,后续binlog变更直接发送到下游。
非PureBinlog阶段,先从变更记录中获取splitKey, 再找到splitKey归属的全量阶段划分的split,如果binlog晚于snapshop split的high watermark, 则表示此变更snapshot阶段未输出,binlog阶段需发送到下游。
//判断是否应该发送至下游
private boolean shouldEmit(SourceRecord sourceRecord) {
if (RecordUtils.isDataChangeRecord(sourceRecord)) {
TableId tableId = RecordUtils.getTableId(sourceRecord);
if (pureBinlogPhaseTables.contains(tableId)) {
return true;
}
BinlogOffset position = RecordUtils.getBinlogPosition(sourceRecord);
if (hasEnterPureBinlogPhase(tableId, position)) { //进入PureBinlog阶段
return true;
}
// only the table who captured snapshot splits need to filter
if (finishedSplitsInfo.containsKey(tableId)) {
RowType splitKeyType =
ChunkUtils.getChunkKeyColumnType(
statefulTaskContext.getDatabaseSchema().tableFor(tableId),
statefulTaskContext.getSourceConfig().getChunkKeyColumns());
Struct target = RecordUtils.getStructContainsChunkKey(sourceRecord);
Object[] chunkKey =
RecordUtils.getSplitKey(
splitKeyType, statefulTaskContext.getSchemaNameAdjuster(), target);
for (FinishedSnapshotSplitInfo splitInfo : finishedSplitsInfo.get(tableId)) {
if (RecordUtils.splitKeyRangeContains(
chunkKey, splitInfo.getSplitStart(), splitInfo.getSplitEnd()) //找到binlog所属的split
&& position.isAfter(splitInfo.getHighWatermark())) { //如果binlog晚于所属binlog的high watermark
return true;
}
}
}
// not in the monitored splits scope, do not emit
return false;
} else if (RecordUtils.isSchemaChangeEvent(sourceRecord)) {
if (RecordUtils.isTableChangeRecord(sourceRecord)) {
TableId tableId = RecordUtils.getTableId(sourceRecord);
return capturedTableFilter.isIncluded(tableId);
} else {
// Not related to changes in table structure, like `CREATE/DROP DATABASE`, skip it
return false;
}
}
return true;
}
//判断是否进入PureBinlog阶段
private boolean hasEnterPureBinlogPhase(TableId tableId, BinlogOffset position) {
// the existed tables those have finished snapshot reading
if (maxSplitHighWatermarkMap.containsKey(tableId)
&& position.isAtOrAfter(maxSplitHighWatermarkMap.get(tableId))) {
pureBinlogPhaseTables.add(tableId);
return true;
}
// Use still need to capture new sharding table if user disable scan new added table,
// The history records for all new added tables(including sharding table and normal table)
// will be capture after restore from a savepoint if user enable scan new added table
if (!statefulTaskContext.getSourceConfig().isScanNewlyAddedTableEnabled()) {
// the new added sharding table without history records
return !maxSplitHighWatermarkMap.containsKey(tableId)
&& capturedTableFilter.isIncluded(tableId);
}
return false;
}总结
以上剖析了MySqlSourceEnumerator和MySqlSourceReader的核心逻辑,介绍了仅读取Binlog的Stream模式、仅读取全量数据的Snapshot模式以及全增量一体时Split创建及对应数据读取时切换控制逻辑。MySqlSourceEnumerator是整个流程的大脑,控制Split生成及提交执行时机,MySqlSourceReader则负责具体
Spit数据读取及判断是否需要发送到下游。
Ref: https://miaowenting.site/2022/02/17/Flink-CDC-增量快照读取算法/