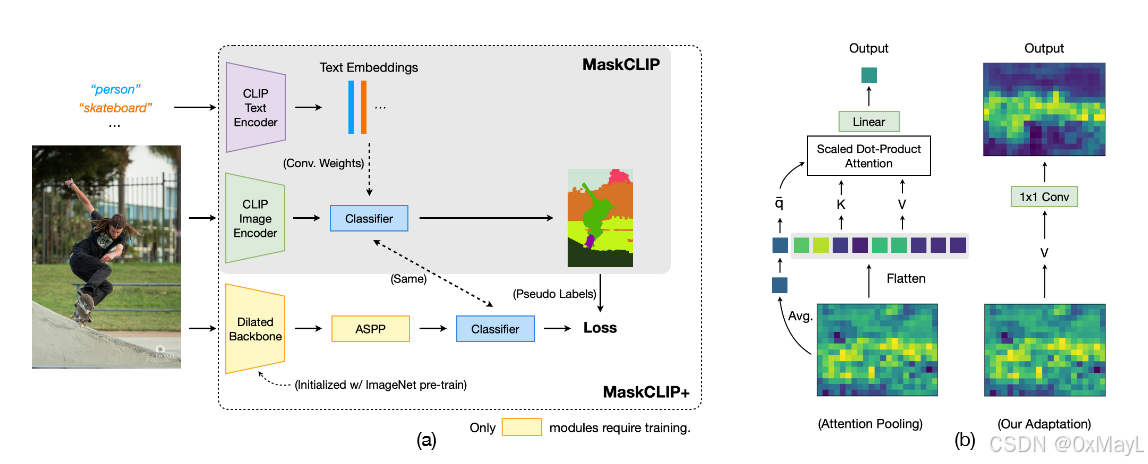
MaskCLIP
CLIP 是否仅能做图像级的零样本分类?还是其实已经隐含了局部/像素级的语义信息,可以直接用于语义分割?
结论是:
CLIP 内部确实已经隐含了丰富的局部语义,可直接输出密集预测,甚至能成为一种强大的开集伪监督方式。
千万不要 fine-tune CLIP,否则会破坏视觉---语言对齐
作者实验了两种天真的方案:
- 用 CLIP 的 backbone 初始化 DeepLab 再 fine-tune
- 使用映射器 M(text_embedding) → classifier weights
结果都失败,原因是: - fine-tune 会破坏 CLIP 原有的语义空间
- mapper 在 seen classes 上训练,无法泛化到 unseen classes
因此 必须保持 CLIP 冻结,否则开集能力崩溃
→ 这形成 MaskCLIP 的设计原则:"不破坏 CLIP 的语义空间"。
密集视觉特征
- 对于VIT,密集视觉特征就是patch嵌入
- 对于ResNet的骨干,其密集视觉特征是注意力池化层中的值嵌入。
作者发现ViT上的表现比ResNet强,因为其分辨率比ResNet高,VIT:32x32,ResNet:7x7
通过上采样 还原到原始图像的分辨率。
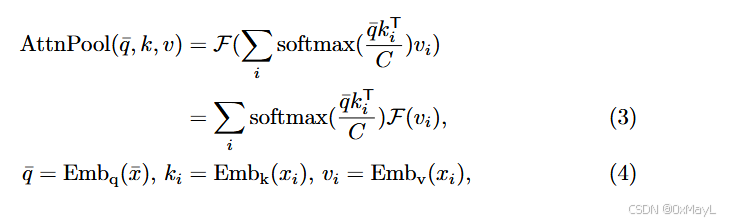
文本嵌入作为分类器权重
分类器权重就是将视觉特征HxWxC映射到HxWxK的矩阵,其中K是类别数。
作者直接将CLIP文本嵌入作为该权重。
去噪和平滑处理
- 作者将注意力池化层丢弃的k重新利用过来,用于平滑输出的分割掩膜
- 把在所有像素(位置)的预测概率都小于0.5的类别直接移除,用于去噪。


MaskCLIP+
- MaskCLIP已经可以实现开放词汇分割了,但是效果不一定强,主要是受限于特征图分辨率太低。
- 作者采用DeepLab作为主要分割网络,生成高质量高分辨率的特征图,利用MaskCLIP生成的分割掩码进行监督。
- 在前1/10轮,作者采用MaskCLIP进行监督,但是后面作者采用自训练的形式,对于没有注释的转导设置,作者直接利用主要分割网络自己产生的掩码用于自训练。