前言
关于本文档
本文档描述了 AMD GCN "Vega" 7nm 架构设备的环境、组织和程序状态。它详细介绍了该系列处理器可供程序员和编译器访问的指令集 和微码格式。
本文档规定了指令 (包括各类指令的格式)以及相关的程序状态 (包括程序状态如何与指令交互)。某些指令字段是相互依赖的;并非所有字段的所有可能设置都是合法的。本文档规定了有效的组合。
本文档的主要目的是:
-
规定语言结构和行为,包括各类指令在文本语法和二进制格式中的组织方式。
-
提供指令操作的参考,以便编译器编写者能够用以最大化处理器的性能。
目标读者
本文档面向编写应用程序 和系统软件的程序员 ,包括操作系统、编译器、加载器、链接器、设备驱动程序 和系统实用程序的开发者。本文档假设程序员正在编写计算密集型的并行应用程序(流式应用程序),并假设其已理解必要的编程实践。
文档结构
第 1 章概述 AMD GCN 处理器的硬件和编程环境。
第 2 章描述了 GCN 程序的组织结构。
第 3 章描述了所维护的程序状态。
第 4 章描述了程序流。
第 5 章描述了标量 ALU 操作。
第 6 章描述了向量 ALU 操作。
第 7 章描述了标量内存操作。
第 8 章描述了向量内存操作。
第 9 章提供了关于 Flat 内存指令的信息。
第 10 章描述了数据共享操作。
第 11 章描述了像素着色器和顶点着色器参数的导出。
第 12 章详细描述了指令,首先按其所属的微码格式分类,然后按字母顺序排列。
第 13 章提供了每种微码格式的详细规范。
约定
本文档使用以下约定:
|-----------|------------------------------------|
| 等宽字体 | 文件名、文件路径或代码。 |
| * | 代码格式、参数或指令名称中的任意数量的字母数字字符。 |
| < > | 尖括号表示流。 |
| [1,2) | 包含最左侧值(本例中为 1)但不包含最右侧值(本例中为 2)的范围。 |
| [1,2] | 包含最左侧和最右侧值的范围。 |
| {x | y} | 列出的多个选项之一。在本例中为 X 或 Y。 |
| 0.0 | 单精度(32 位)浮点值。 |
| 1011b | 二进制值,在此示例中为 4 位值。 |
| 7:4 | 位范围,从位 7 到位 4(包含)。高位在前。 |
| 斜体单词或短语 | 对理解流计算至关重要的术语或概念的首次使用。 |
相关文档
-
Intermediate Language (IL) Reference Manual。由 AMD 发布。
-
AMD Accelerated Parallel Processing OpenCL Programming Guide。由 AMD 发布。
-
The OpenCL Specification。由 Khronos Group 发布。Aaftab Munshi 编辑。
-
OpenGL Programming Guide,位于 http://www.glprogramming.com/red/
-
Microsoft DirectX® 参考网站,位于 https://msdn.microsoft.com/en-us/library/windows/desktop/ee663274(v=vs.85).aspx
"Vega" 7nm 设备的新特性
Vega GPU 内核指令变更摘要:
-
新增打包 16 位数学指令:
V_PK_MAD_I16V_PK_MUL_LO_U16V_PK_ADD_I16V_PK_SUB_I16
V_PK_LSHLREV_B16V_PK_LSHRREV_B16V_PK_ASHRREV_I16V_PK_MAX_I16
V_PK_MIN_I16V_PK_MAD_U16V_PK_ADD_U16V_PK_SUB_U16
V_PK_MAX_U16V_PK_MIN_U16V_PK_FMA_F16V_PK_ADD_F16
V_PK_MUL_F16V_PK_MIN_F16V_PK_MAX_F16V_MAD_MIX_F32
V_MAD_MIXLO_F16V_MAD_MIXHI_F16S_PACK_{LL,LH,HH}_B16_B32 -
TMA 和 TBA 寄存器现在按每个 VM-ID 存储,而不是按每次绘制或分派存储。
-
增加的 Image 操作支持 16 位地址和数据。
-
增加了全局内存和 Scratch 内存 的读/写操作。
◦ 同时增加了对 Scratch 内存的标量内存加载/存储。
-
增加了标量内存原子指令。
-
MIMG 微码格式:移除了 R128 位。
-
FLAT 微码格式:增加了一个偏移字段。
-
移除了
V_MOVEREL指令。 -
增加了对 FP16 VALU 操作算术溢出的控制。
-
修改了 surface 描述符和 samplers 的 bit 打包:
◦ T#:移除了
heap、elem_size、last_array、interlaced、uservm_mode位。◦ V#:移除了
mtype。◦ S#:移除了
astc_hdr字段。
新指令
Vega 7nm 包含以下附加指令:
V_FMAC_F32
V_XNOR_B32
V_DOT2_F32_F16
V_DOT2_I32_I16
V_DOT2_U32_U16
V_DOT4_I32_I8
V_DOT4_U32_U8
V_DOT8_I32_I4
V_DOT8_U32_U4
联系信息
有关 AMD Accelerated Parallel Processing 开发的信息,请参见:developer.amd.com/。
有关使用 AMD Accelerated Parallel Processing 进行开发的信息,请参见:developer.amd.com/appsdk。
我们还有一个不断壮大的 AMD Accelerated Parallel Processing 用户社区。欢迎访问 AMD Accelerated Parallel Processing 开发者论坛 (http://developer.amd.com/openclforum),了解其他用户正在其 AMD Accelerated Parallel Processing 产品上尝试哪些应用。
第 1 章 简介
AMD GCN 处理器实现了一种并行微架构,它不仅为计算机图形应用,也为通用数据并行应用提供了一个卓越的平台。需要高带宽或计算密集的数据密集型应用程序均可在 AMD GCN 处理器上运行。
下图展示了 AMD GCN Vega 架构系列处理器的框图:
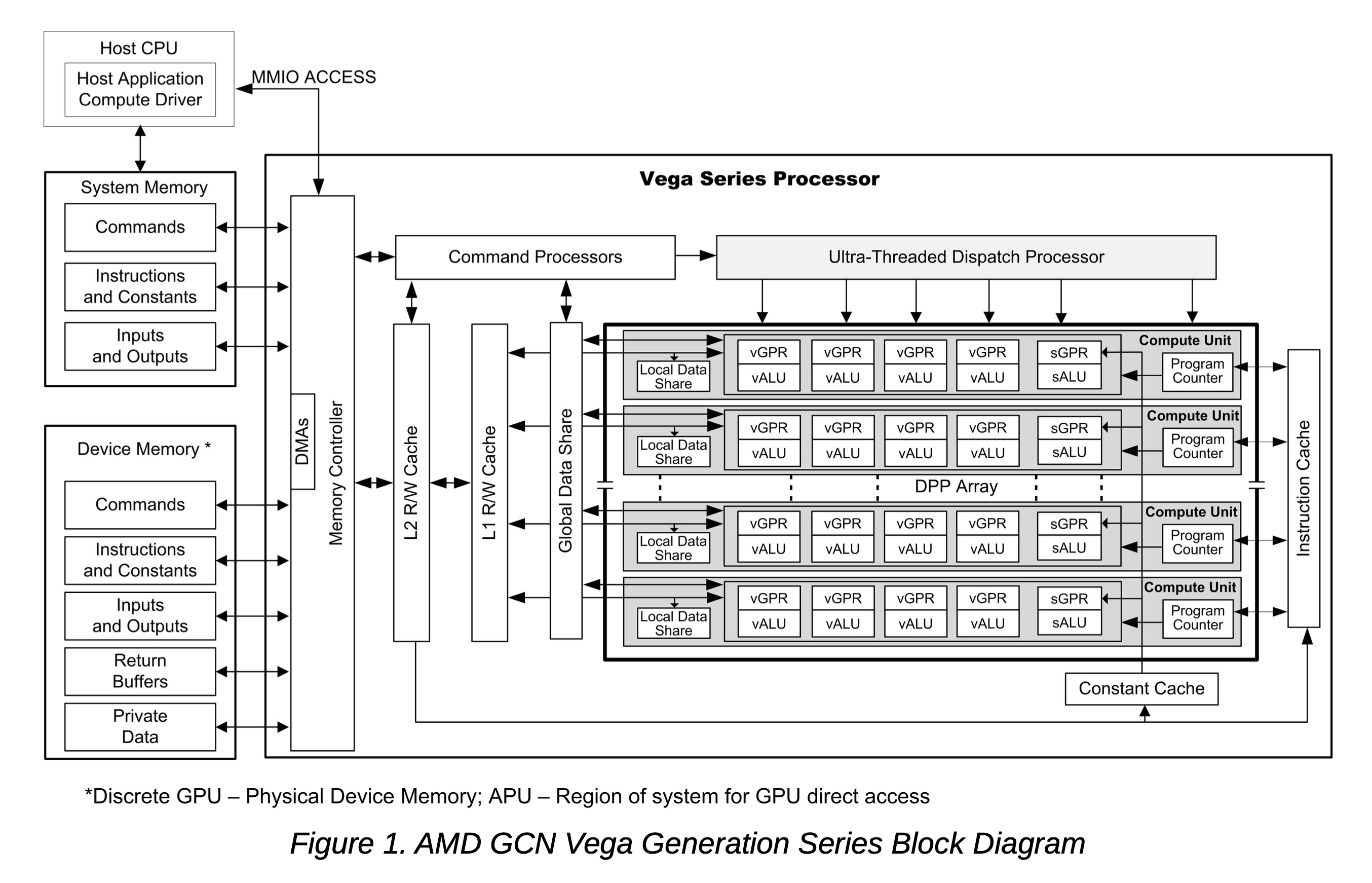
GCN 设备包含一个数据并行处理器阵列 、一个命令处理器 、一个内存控制器 以及其他逻辑 (未显示)。++GCN 命令处理器读取主机写入到系统内存地址空间中内存映射的 GCN 寄存器的命令。当命令执行完毕时,命令处理器会向主机发送硬件生成的中断。++ GCN 内存控制器可直接访问所有 GCN 设备内存 以及主机指定的系统内存区域 。为满足读写请求,内存控制器执行 DMA 控制器的功能,包括根据请求数据在内存中的格式计算内存地址偏移量。
在 GCN 环境中,一个完整的应用程序包括两个部分:
-
在主机处理器上运行的程序,以及
-
在 GCN 处理器上运行的、称为内核的程序。
GCN 程序由主机命令控制,这些命令用于:
-
设置 GCN 内部基地址和其他配置寄存器,
-
指定 GCN GPU 要操作的数据域,
-
使 GCN GPU 上的缓存失效并清空缓存
-
促使 GCN GPU 开始执行程序。
GCN 驱动程序运行在主机上。
DPP 阵列 是 GCN 处理器的心脏。该阵列被组织为一组计算单元流水线,每条流水线相互独立,对浮点或整数数据流进行并行操作。计算单元流水线可以处理数据,或者通过内存控制器与内存进行数据传输。计算单元流水线中的计算可以设置为有条件执行 。写入内存的输出也可以设置为有条件写入。
当接收到请求时,计算单元流水线从内存加载指令和数据,开始执行,并持续运行直至内核结束。在内核运行时,GCN 硬件自动从内存中获取指令到片上缓存中;GCN 软件在此过程中不发挥作用。GCN 内核可以将数据从片外内存 【注,指显存】加载到片上通用寄存器 (GPRs)和缓存中。
AMD GCN 设备能够检测浮点异常并生成中断 。具体来说,它们在硬件中检测 IEEE 浮点异常;这些异常可以被记录下来用于执行后分析。上图中从命令处理器到主机的软件中断代表了硬件生成的中断,用于通知命令完成 及相关管理功能。
GCN 处理器通过跟踪处于不同执行阶段的可能数百个 workitems,并通过重叠计算操作与内存访问操作,来隐藏内存延迟。
1.1. 术语
表 1. 基本术语
| 术语 | 描述 |
|---|---|
| GCN 处理器 | Graphics Core Next 着色器处理器,是一个标量和向量ALU,旨在代表一个 wavefront 执行复杂程序。 |
| 分派 | 一次分派会启动一个一维、二维或三维的工作网格到 GCN 处理器阵列。 |
| Workgroup | 工作组是一组能够快速相互同步的波前集合;它们还可以通过本地数据共享来共享数据。 |
| wavefront | wavefront 是在单个 GCN 处理器上并行执行的 64 个工作项的集合。类似 warp |
| Work-item | 单个工作元素:分派网格中的一个元素,或在图形应用中指一个像素或顶点。 |
| 字面常量 | 放置在指令流中的 32 位整数或浮点常量。 |
| 标量 ALU | 标量 ALU 对每个波前的一个值进行操作,并管理所有控制流。 |
| 向量 ALU | 向量 ALU 维护为每个工作项独有的向量通用寄存器,并对每个工作项独立执行算术运算。 |
| 微码格式 | 微码格式描述了用于编码指令的位模式。每条指令为 32 位或 64 位。 |
| 指令 | 指令是内核的基本单元。指令包括:向量 ALU 、标量 ALU 、内存传输 和控制流操作。 |
| 四边形 | 四边形是一组 2x2 的对齐屏幕的像素。这与采样纹理贴图相关。 |
| 纹理采样器 | 纹理采样器是一个128 位的实体 ,描述了向量内存系统如何读取和采样(过滤)纹理贴图。 |
| 纹理资源 | 纹理资源描述符描述了内存中的图像:地址、数据格式、步幅等。 |
| 缓冲区资源 | 缓冲区资源描述符描述了内存中的缓冲区:地址、数据格式、步幅等。 |