Kafka-4 Kafka 中的消费者
前置文章中利用 docker 搭建了一个 kafka 实例:Docker 部署 Kafka,并结合 SpringBoot 进行了整合。
消费者消费消息时我们只需要使用 Spring-Kafka 的注解 KafkaListener 监听对应的主题并设置对应的消费者组 ID 即可
java
@Service("kafkaConsumerService")
@Slf4j
public class KafkaConsumerService {
@KafkaListener(topics = "test-topic", groupId = "test-group")
public void listen(ConsumerRecord<String, String> record) {
log.info("consumer Received message: {}", record.value());
}
}消费者组
消费者组,即 Consumer Group,这是 Kafka 中一个比较有特色的设计,具有以下的规定:
- Consumer Group 下可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
- GroupID 即 组ID 是每个 Consumer Group 的唯一标识。
- Consumer Group 订阅的主题的**
单个分区,只能分配给组内的某个 Consumer 实例消费**。这个主题及分区当然也可以被其他的 Consumer Group 消费。
第 3 点是消费者组的一个重要特性,意味着 Consumer 可能(用可能的原因是如果 consumer group 只有 1 个消费者还是需要全部分区都消费)只需要消费 topic 下部分分区的消息。
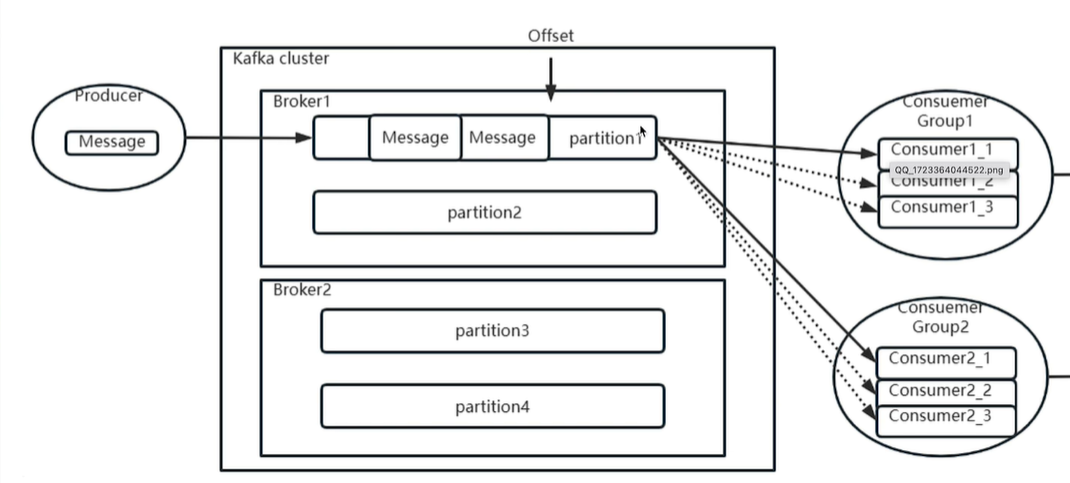
假设一个 Consumer Group 订阅了 3 个主题,分别是 A、B、C,它们的分区数依次是 1、2、3,那么通常情况下,为该 Group 设置 6 个 Consumer 实例是比较理想的情形,因为它能最大限度地实现高伸缩性。当然设置更少的 Consumer 也是可以的,如果设置为 3 个 Consumer,则每个负责两个分区也可以。但是不要让 Consumer 的数量高于分区总数,多余的实例只会一直空闲浪费资源,而没有任何好处。这也是 Kakfa 在消息积压时增加消费者实例不一定有用的原因之一。
消费者组位移
Kafka 一定是需要维护消息的消费进度的,这个位置信息有个专门的术语:位移(Offset)。
Kafka 集群中的 __consumer_offsets 内部主题中记录了每个消费者组在订阅主题的每个分区上的消费进度,类似于 Map<String,Long> 的结构,key 是 groupID-topic-partitionID,value 是位移量。
在 kafka 的容器里可以 使用如下命令查看消费者组的消费进度:
bash
$ kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-group
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test-group test-topic 0 113 113 0 consumer-test-group-1-f5b7d987-b237-416a-a547-534d49adea1e /[ip] consumer-test-group-1CURRENT-OFFSET 为当前提交位移
LOG-END-OFFSET 为最新消息位移
Lag 字段是【当前提交位移】与【最新位移的差值】,如果一直增大代表消费者跟不上生产者的速度,这有可能导致它消费的数据已经不在操作系统的页缓存中了,那么这些数据就会失去享有 Zero Copy 技术的资格。
假设有这样的情况,我向 kafka 推送了上千条消息,突然发现推送的消息中对某个字段忘了进行码值转换,想让消费者组忽略掉这些消息,这个时候就希望能重新设置消费者组位移。重设消费者组位移包含两个维度:
- 位移维度
- Earliest:把位移调整到当前的最早位移处。(注意这个不一定是0,因为 Kafka 会保存近一段时间的数据,可能是保存数据的最早值)
- Latest:最新位移处。(这个操作也可能造成前置消息"丢失"哈)
- Current:当前的最新提交位移处
- Specified-Offect:指定位移处
- Shift-By-N:当前位移 +N 处(N可以是负数)
- 时间维度
- DateTime:大于给定时间的最小位移处
- Duration:距离当前时间指定间隔的位移处
这些调整方式既可以通过 client api 进行也可以通过容器内脚本执行,以下是脚本执行的例子,可以把 --execute 替换为 --dry-run 来查看将要执行的操作,而不是直接执行
bash
# --to-earliest 可以换成 --to-latest、--to-current
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test-group --reset-offsets --all-topics --to-earliest --execute
bash
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test-group --reset-offsets --all-topics --to-offset <offset> --execute
bash
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test-group --reset-offsets --shift-by <offset_N> --execute
bash
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test-group --reset-offsets --to-datetime 2025-11-30T20:00:00.000 --execute
bash
# 30分钟前
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test-group --reset-offsets --by-duration PT0H30M0S --execute注意:重设消费者组位移需要消费者组停止,否则会出现如下错误:
java
Error: Assignments can only be reset if the group 'test-group' is inactive, but the current state is Stable.查看把 test-group 组的 test-topic 主题的位移重设为 60,注意最后是 --dry-run 而不是 --execute
bash
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test-group --reset-offsets --topic test-topic --to-offset 60 --dry-run
GROUP TOPIC PARTITION NEW-OFFSET
test-group test-topic 0 60修改为 execute 执行后验证
bash
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-group
Consumer group 'test-group' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test-group test-topic 0 60 113 53 - - -记得设置 consumer 的消费方式为从 CURRENT-OFFSET 位移开始哈,如果是 latest 则重设位移又被修改为最新位移了。
位移的提交可以自动也可以手动,对应 consumer 端配置项:enable-auto-commit,如果是 true,则配置项 auto.commit.interval 代表多久会自动提交一次位移,单位为毫秒。默认值为 5000ms(5秒)。
消费者重平衡
重平衡指重新平衡,Reblance,本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区。
在消费者组中提到:消费者组中的所有消费者消费所订阅主题的所有分区的消息。3 个消费者 6 个分区,则每个消费者可以平均分配两个,当然也可以按照 123 分配,那么如果是 5 个分区呢?或者某个消费者进程所在机器性能好,想多分配两个分区,配置差的少分配该怎么实现呢?
如果运行过程中组成员数变更或订阅主题数变更或订阅主题的分区数变更(消费者机器宕机、正则表达式订阅主题、新增主题分区),所有消费者需要参与重新分配分区,这也就是【重平衡】,在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成,类似于 Java 的 STW。这是 Rebalance 为人诟病的一个方面。
而实现这个分配功能的策略称为:消费者分区策略。
关于分区策略以及如何自定义分区策略的方法在很多文章里都有描述: 深入理解Kafka消费端分区分配策略
"本事大不如不摊上",最好还是避免 Rebalance 的发生吧。
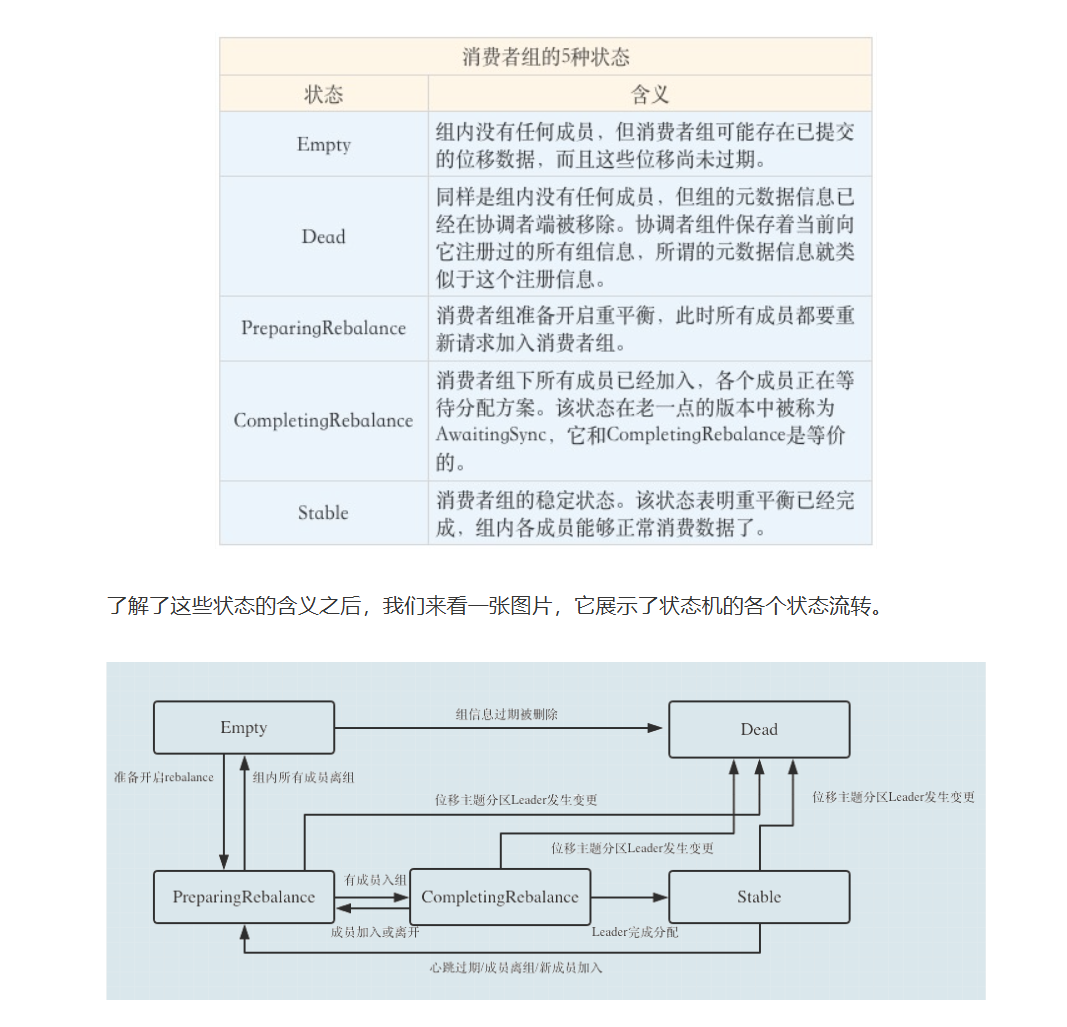
重平衡的发生原因中:【主题数】变更和【主题分区数】变更一般是我们的运维操作,这是可以通过人为控制减少影响时间,而组成员数的变动则不全是运维的操作,属于非预期的重平衡。
其实这就是一个心跳机制,每个 consumer 会定期地向 Coordinator (协调者,和 Broker 一起运行)发送心跳请求,既然是心跳机制,那么一定有一些关键参数:在一定的周期内收不到消费者的心跳包,认为消费者已经停止运行。
一定的周期对应配置项:session.timeout.ms 默认值 30000 即 30s,消费者发送心跳包的周期间隔配置项:heartbeat.interval.ms 默认值 10000 即 10s,请尽量让 session.timeout.ms >= 3 * heartbeat.interval.ms,避免由于网络波动而未能及时发送心跳包。每次 consumer 发送心跳时会顺带发送 session timeout 时间,这样 Coordinator 收到后会根据这个 session timeout 时间计算下次 deadline 时间,如果过了 deadline 还没有收到直接 fail 掉该 consumer。
同时,如果某个消费者消费特别缓慢,我们希望将其剥离出消费者组以免影响整体处理速度,配置项max.poll.interval.ms 代表消费者的最大拉取消息间隔,默认值 300000 即 5 分钟,消费者在 5 分钟内消费不完它上一批拉取的消息(这个数量上限由配置项max-poll-records 控制),则会脱离消费者组进而引发重平衡。因此如果消息的消费比较缓慢,可以适当调整上述配置项。
消费者拦截器
类似于生产者拦截器,消费者也有自己的拦截器
配置项:spring.kafka.consumer.properties.interceptor.classes
yaml
spring:
kafka:
consumer:
bootstrap-servers: ****:9094
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
auto-offset-reset: none
enable-auto-commit: off
properties:
interceptor:
classes: com.xsdl.config.KafkaInterceptor拦截器类只需要实现 ConsumerInterceptor 接口
java
@Slf4j
public class KafkaInterceptor implements ConsumerInterceptor {
@Override
public ConsumerRecords onConsume(ConsumerRecords records) {
return records;
}
@Override
public void onCommit(Map offsets) {
log.info("位移提交:{}", offsets);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}- onConsume:该方法在消息返回给 Consumer 程序之前调用。也就是说在开始正式处理消息之前,拦截器会先拦一道,搞一些事情,之后再返回给消费者。
- onCommit:Consumer 在提交位移之后调用该方法。通常可以在该方法中做一些记账类的动作,比如打日志等。
拦截器可以实现一些有意思的功能,例如统计消息从客户端发送到服务端消费者开始处理的耗时:
java
@Slf4j
public class KafkaInterceptor implements ProducerInterceptor<String, String>, ConsumerInterceptor<String, String> {
private final String key = "time";
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
log.info("消息:{}被发送了", record.value());
Headers headers = record.headers();
headers.add(new Header() {
@Override
public String key() {
return key;
}
@Override
public byte[] value() {
return String.valueOf(System.currentTimeMillis()).getBytes(StandardCharsets.UTF_8);
}
});
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception == null) {
long offset = metadata.offset();
log.info("消息的偏移量是:{}", offset);
}
}
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
for (ConsumerRecord<String, String> record : records) {
Headers headers = record.headers();
Header header = Arrays.stream(headers.toArray()).filter(i -> i.key().equals(key)).findFirst().orElse(null);
if (header != null) {
log.info("record:{}从生产者拦截器发送到消费者拦截器接收的时间间隔为:{}ms", record.value(),
System.currentTimeMillis() - Long.parseLong(new String(header.value(), StandardCharsets.UTF_8)));
}
}
return records;
}
@Override
public void onCommit(Map offsets) {
log.info("位移提交:{}完成", offsets);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}也可以借此观察一下 send 方法和 callback 方法等的执行顺序
对于 producer:send -> 拦截器中的 onSend -> 拦截器 onAcknowledgement -> callback 回调,注意 onSend 是 tomcat 线程执行的,而 onAcknowledgement 是 producer 线程执行的
对于 consumer:onConsume -> 处理方法 -> onCommit
参考资料
【2】知乎-Kafka专栏
【3】B站-Kafka教程