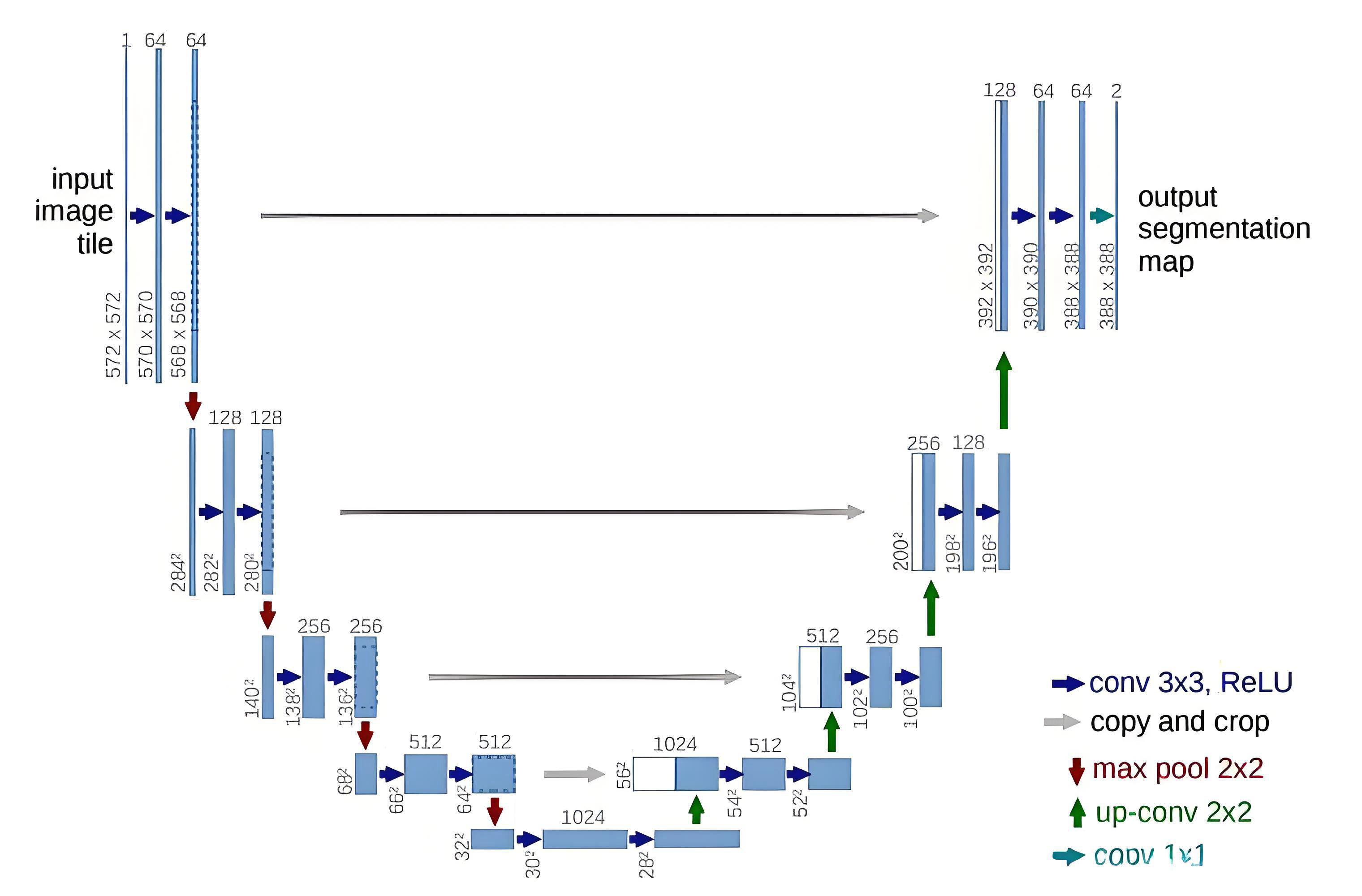

UNet网络结构,最主要的两个特点是:U型网络结构和Skip Connection跳层连接。
UNet是一个对称的网络结构,左侧为下采样,右侧为上采样。
UNET网络基本流程:先进性下采样+俩次卷积,进行到第四次之后进行上采样+编码部分。
假设给定的架构:
输入通道:1
输出通道:1
序列长度:1024
输入: batch, 1, 1024
↓ inc (DoubleConv)
x1: batch, 64, 1024 ← 保存用于跳跃连接
↓ down1 (MaxPool + DoubleConv)
x2: batch, 128, 512 ← 保存
↓ down2
x3: batch, 256, 256 ← 保存
↓ down3
x4: batch, 512, 128 ← 保存
↓ down4
x5: batch, 1024, 64 # 最深层特征
↓ up1 (上采样+拼接x4)
x : batch, 512, 128
↓ up2 (上采样+拼接x3)
x : batch, 256, 256
↓ up3 (上采样+拼接x2)
x : batch, 128, 512
↓ up4 (上采样+拼接x1)
x : batch, 64, 1024
↓ outc (1x1卷积)
输出: batch, n_classes, 1024 # 与输入相同长度
UNET1D代码实现:
功能描述:生成关于信号的异常点自动检测的过程。
import torch
import torch.nn as nn
import torch.nn.functional as F
#这个类表示下采样和上采样的过程中每次都要进行俩次卷积操作
class DoubleConv(nn.Module):
"""(卷积 => BN => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv1d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm1d(out_channels),
nn.ReLU(inplace=True),
nn.Conv1d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm1d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""下采样模块:最大池化 + DoubleConv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool1d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""上采样模块"""
def __init__(self, in_channels, out_channels):
super().__init__()
# 转置卷积上采样
self.up = nn.ConvTranspose1d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
"""x1: 来自解码器的特征, x2: 来自编码器的特征"""
x1 = self.up(x1)
# 确保尺寸匹配
diff = x2.size()[2] - x1.size()[2]
x1 = F.pad(x1, [diff // 2, diff - diff // 2])
# 跳跃连接
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class UNet1D(nn.Module):
def __init__(self, n_channels=1, n_classes=1):
super(UNet1D, self).__init__()
self.n_channels = n_channels#输入
self.n_classes = n_classes#表示分类
# 编码器路径
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
# 解码器路径
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
# 输出层
self.outc = nn.Conv1d(64, n_classes, kernel_size=1)
def forward(self, x):
# 编码器
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
# 解码器(带有跳跃连接)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
# 输出
logits = self.outc(x)
return logits
# 使用示例
if __name__ == "__main__":
# 创建模型
#n_channels输入的通道数
#n_classes输出的类别数
model = UNet1D(n_channels=1, n_classes=1)
print("模型结构:")
print(model)
# 测试输入
batch_size = 2
seq_length = 1024
x = torch.randn(batch_size, 1, seq_length)
print(f"\n输入尺寸: {x.shape}")
# 前向传播
with torch.no_grad():
output = model(x)
print(f"输出尺寸: {output.shape}")
# 计算参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"\n总参数量: {total_params:,}")核心组件详解:
1、DoubleConv类 - 双卷积块
**# 连续两次卷积操作,每次包含:
1. 卷积层(提取特征)
2. 批归一化(稳定训练,加速收敛)
3. ReLU激活(引入非线性)
作用:特征提取的基本单元**
2、Down类 - 下采样模块
**# 转置卷积上采样:扩大特征图尺寸
跳跃连接:拼接编码器特征和解码器特征
双卷积:融合特征并进一步处理
流程:上采样 → 跳跃连接 → 特征融合**
下采样:
输入 → 64通道 → 128通道 → 256通道 → 512通道 → 1024通道
↓ ↓ ↓ ↓ ↓
分辨率: 原尺寸 → 1/2尺寸 → 1/4尺寸 → 1/8尺寸 → 1/16尺寸
每次下采样:分辨率减半,通道数翻倍
目的:提取深层语义特征,扩大感受野
3、Up类 - 上采样模块
**# 转置卷积上采样:扩大特征图尺寸
跳跃连接:拼接编码器特征和解码器特征
双卷积:融合特征并进一步处理
流程:上采样 → 跳跃连接 → 特征融合**
上采样:
1024通道 → 512通道 → 256通道 → 128通道 → 64通道 → 输出
↑ ↑ ↑ ↑ ↑
分辨率: 1/16 → 1/8 → 1/4 → 1/2 → 原尺寸
每次上采样:分辨率翻倍,通道数减半
跳跃连接:将编码器的浅层特征(细节信息)与解码器的深层特征(语义信息)融合
4、跳跃连接(Skip Connection)
# 在Up.forward()中: x = torch.cat([x2, x1], dim=1) # 拼接编码器和解码器特征
作用:
恢复下采样过程中丢失的细节信息
解决梯度消失问题
实现多尺度特征融合
精确定位
main.py添加测试数据,然后开始训练
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
import torch
from unet1D import UNet1D
import torch.nn as nn
# 创建简单的模拟数据集
class SyntheticSignalDataset(Dataset):
def __init__(self, num_samples=1000, seq_length=1024):
self.num_samples = num_samples
self.seq_length = seq_length
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
# 生成随机信号
signal = np.random.randn(self.seq_length).astype(np.float32)
# 生成简单的目标(峰值检测)
target = np.zeros(self.seq_length, dtype=np.float32)
# 随机添加一些峰值
#表示生成一个随机整数,范围从3(包含)到10(不包含),即可能生成的整数是3、4、5、6、7、8、9
num_peaks = np.random.randint(3, 10)
peak_positions = np.random.choice(self.seq_length, num_peaks, replace=False)
target[peak_positions] = 1.0
# 添加一些高斯平滑
from scipy.ndimage import gaussian_filter1d
target = gaussian_filter1d(target, sigma=2)
return signal.reshape(1, -1), target.reshape(1, -1)
# 训练函数
def train_model():
# 参数设置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 创建数据
dataset = SyntheticSignalDataset(num_samples=100, seq_length=1024)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
# 初始化模型
model = UNet1D(n_channels=1, n_classes=1).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 训练循环
model.train()
for epoch in range(5): # 演示用5个epoch
epoch_loss = 0
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
if batch_idx % 10 == 0:
print(f'Epoch: {epoch}, Batch: {batch_idx}, Loss: {loss.item():.6f}')
print(f'Epoch {epoch} 平均损失: {epoch_loss / len(dataloader):.6f}')
# 运行训练
if __name__ == "__main__":
train_model()