一、ZSet(有序集合)
ZSet 是 Redis 非常重要的数据结构,用于实现排行榜、延迟队列、区间查询等功能。
其底层有两种编码:
- ziplist(小规模)
- skiplist + dict(大规模)
Redis 会根据数量和元素大小自动选择最优结构。
1.1 ZSet 的底层结构:两种编码
(1)OBJ_ENCODING_ZIPLIST(小数据)
满足两个条件会使用 ziplist:
- 元素数量 <
zset_max_ziplist_entries(默认 128) - 每个 element + score 的大小 <
zset_max_ziplist_value(默认 64 bytes)
ziplist 结构示意:

[zlbytes][zltail][zllen][element1][score1][element2][score2]...[zlend]特点:
- element 和 score 紧挨在一起:element 在前、score 在后
- score 越小越靠前(按 score 升序存放)
- ziplist 是连续内存,节省空间(但插入删除 O(n))
适用场景
- 小型排行榜
- 元素较少、value 较短
- 内存敏感场景
缺点
- 插入、删除需要整体移动(O(n))
- 没有 dict 的 O(1) 查询能力
- 不适合大规模
(2)OBJ_ENCODING_SKIPLIST(大数据)
当不满足 ziplist 条件时,使用:
dict + skiplist
示意图中结构如下:
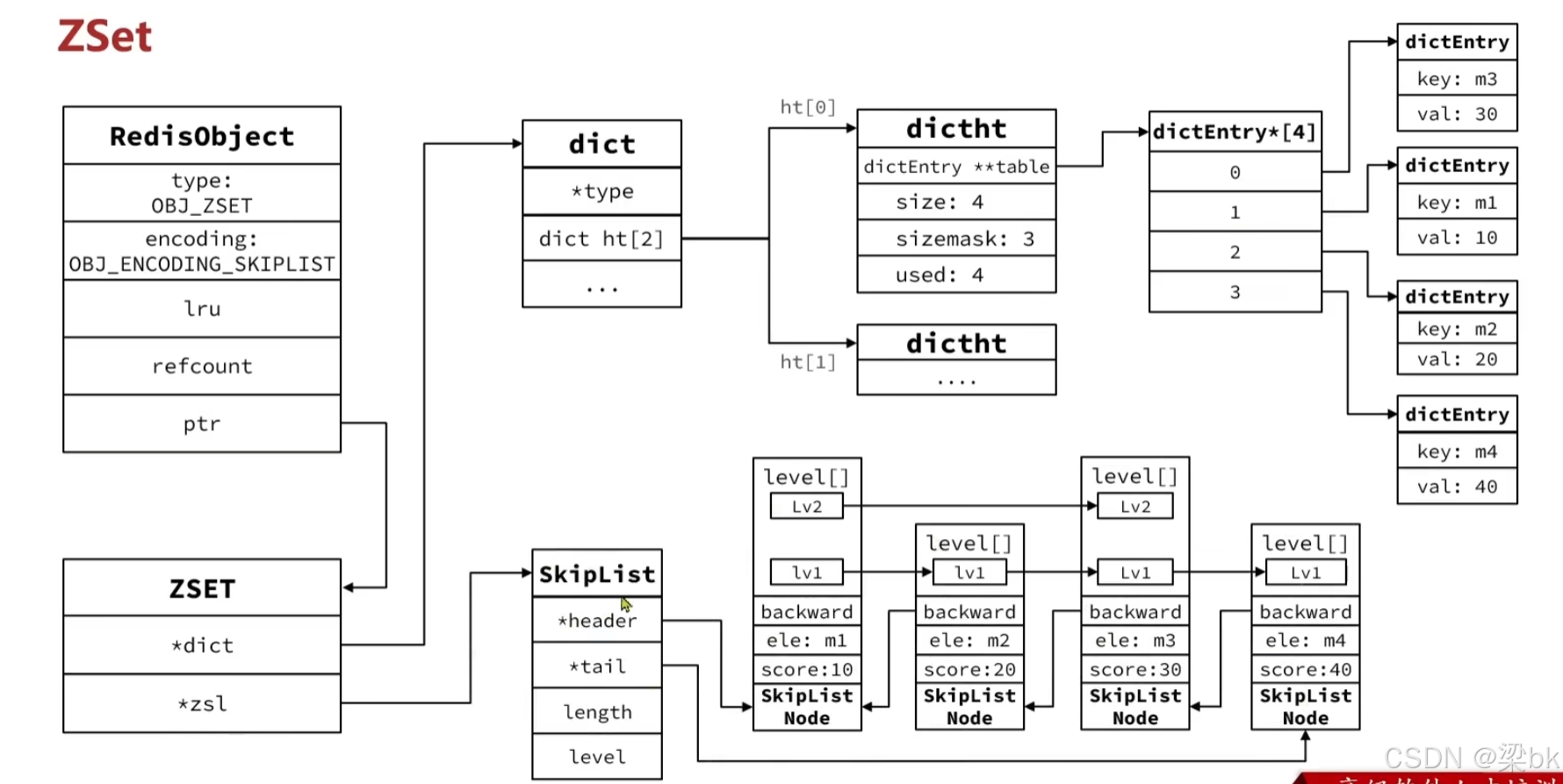
RedisObject
↓
ZSET
├ dict(member → score)
└ skiplist(score 排序)① dict(哈希表)
dict 保存:
member → score作用:
- 通过 member 找 score(O(1))
- 检查 member 是否存在
内部结构(你图中的 dict → dictht → dictEntry):
dictEntry(key=m1, val=10)
dictEntry(key=m2, val=20)
...② skiplist(跳表)
跳表保存:
member、score 按 score 排序结构示意图:
SkipList
├ header
├ tail
├ length
└ level
SkipListNode
├ backward
├ level[]
├ ele=member
└ score跳表支持的操作:
- 根据 score 查找区间
- ZRANGE / ZRANK / ZREVRANK / ZREMRANGEBYSCORE
时间复杂度:
| 操作 | 时间复杂度 |
|---|---|
| 插入 | O(logN) |
| 删除 | O(logN) |
| 按 score 查找 | O(logN) |
| 区间查找 | O(logN + M) |
1.2 ZSet 的核心设计思想(非常重要)
Redis 设计 ZSet 采用:
dict + skiplist(互补结构)目的:
- dict → 通过 member 获取 score(O(1))
- skiplist → 通过 score 排序(O(logN))
- 双结构保持同步
跳表提供排序能力,dict 提供快速检索能力。
1.3 ZSet 两种编码切换条件
| 条件 | 编码 |
|---|---|
| 元素少、元素小 | ziplist |
| 元素多或任一元素太大 | skiplist(dict + skiplist) |
Redis 自动完成转换。
二、Hash 类型
Hash 用于存储字段值对(field-value),底层也有两种编码:
- ziplist(小 Hash)
- dict(大 Hash)
与 ZSet 类似,只是 Hash 不需要排序,因此不需要 skiplist。
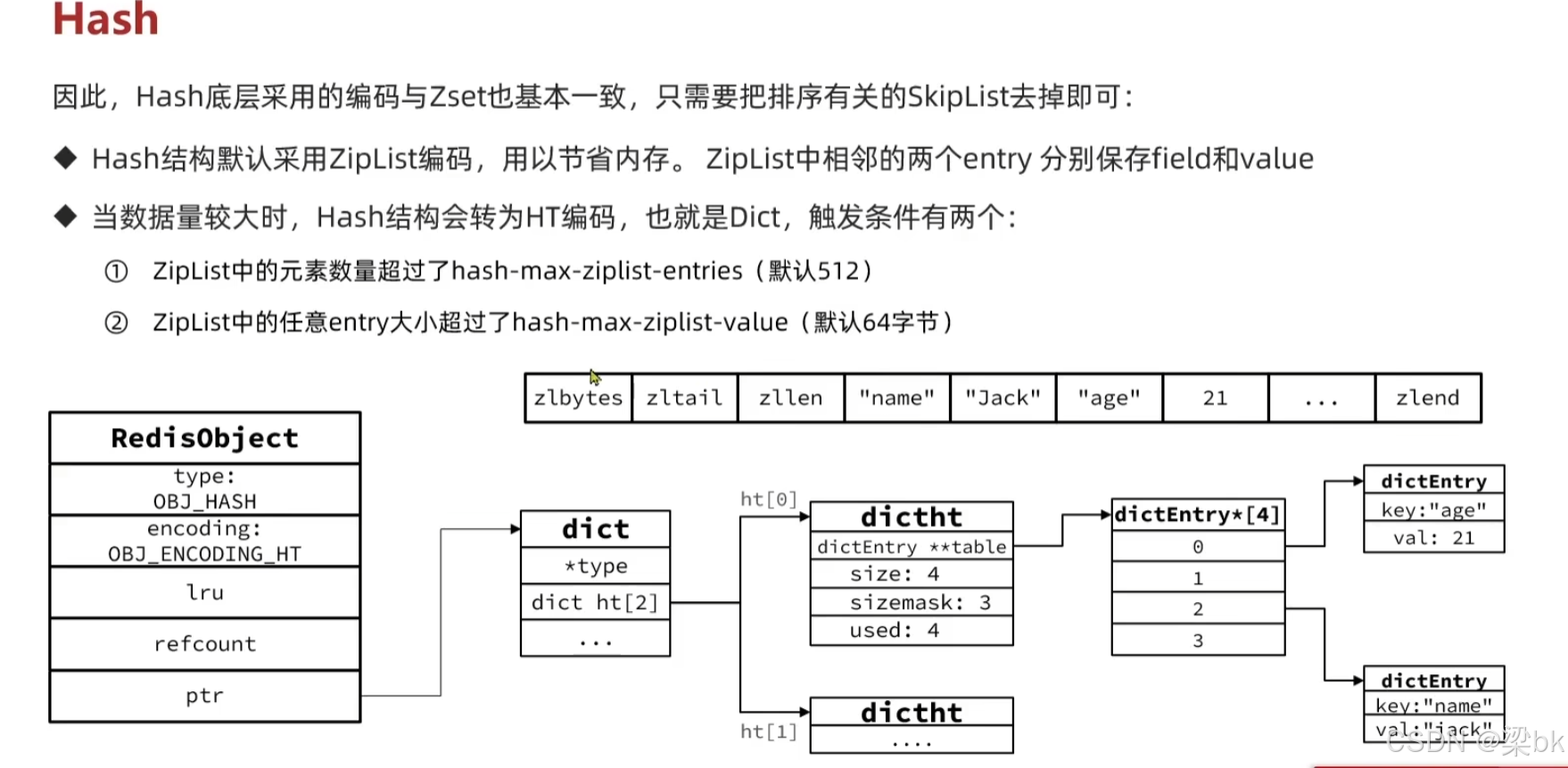
2.1 OBJ_ENCODING_ZIPLIST(小 Hash)
默认使用 ziplist:
条件:
- 元素数量 <
hash-max-ziplist-entries(默认 512) - 任意 entry 长度 <
hash-max-ziplist-value(默认 64 字节)
ziplist 在 Hash 中的存储方式:
[field1][value1][field2][value2]...[zlend]示意图(你的第三张图):
zlbytes | zltail | zllen | "name" | "Jack" | "age" | 21 | zlend特点:
- field 和 value 存成紧邻两条 entry
- 节省内存
- 顺序读取快
- 插入删除 O(n)
适合:
- 小型用户资料(name, age)
- 小结构配置数据
2.2 OBJ_ENCODING_HT(dict,大 Hash)
当 ziplist 超过阈值,会自动转换成 dict:
触发条件:
- 元素数量超过
hash-max-ziplist-entries - 任意 field 或 value 长度超过
hash-max-ziplist-value
dict 的内部结构同 ZSet 使用的 dict 完全一样:
dict
├ ht[0]
├ ht[1]
└ dictEntry(key=field, val=value)示意图中的结构:
dictEntry(key="name", val="jack")
dictEntry(key="age", val=21)特点:
- 通过哈希表查询(O(1))
- 插入、删除性能极高
- 支持渐进式 rehash
适合:
- 大型 Hash(几百、几千、几万 field)
- 动态频繁更新的业务
三、ZSet vs Hash 编码规则总结
| 类型 | 小数据编码 | 转换规则 | 大数据编码 |
|---|---|---|---|
| ZSet | ziplist | 元素多或 entry >64B | skiplist + dict |
| Hash | ziplist | 元素多或 entry >64B | dict |
两者最大区别:
| 项目 | ZSet | Hash |
|---|---|---|
| 是否需要排序 | Yes | No |
| 大数据结构 | skiplist + dict | dict |
| 小数据结构 | ziplist(element+score) | ziplist(field+value) |
四、面试重点总结(非常重要)
1. ZSet 为什么使用 dict + skiplist?
回答要点:
- dict 提供 O(1) 根据 member 查 score
- skiplist 提供 O(logN) 排序
- 互补结构、相互同步
- 适合 ZRange、ZRank、按区间查询等复杂操作
2. ziplist 是如何存 ZSet 的?
- element 和 score 挨在一起
- 按 score 升序排序
- 连续内存,节省空间
3. Hash 为什么也用 ziplist?
- 节省内存
- 小数据速度更快
- field 和 value 是连续存储的两个 entry
4. ziplist 的缺点?
- 插入 O(n)
- 删除 O(n)
- 可能产生连锁更新(prevlen 变大导致内存整体移动)
- 不适合大数据量
5. 各编码在什么情况下切换?
Hash:
- 超过 512 个 field → dict
- 任意 entry 超过 64 字节 → dict
ZSet:
- 超过 128 个元素 → skiplist
- 任一元素超过 64 字节 → skiplist
五、背诵版总结
ZSet:
- 小数据:ziplist(element + score 两个 entry)
- 大数据:skiplist + dict
- dict 做查找,skiplist 做排序
Hash:
- 小数据:ziplist(field + value 两个 entry)
- 大数据:dict
- 转换阈值:512 个元素/64 字节 entry