一. 引言
词元化(Tokenization)是大模型预处理的核心步骤,将连续文本切分为模型可理解的最小语义单元(Token),这些词元可以是单词、子词或字符。中文没有像英文空格这样的天然分词边界,并且存在大量形近、义近字词,因此分词算法的选择直接影响模型效果。在大模型中,常见的子词词元化方法有BPE(Byte-Pair Encoding)、WordPiece和Unigram。下面我们将分别详细介绍这三种方法的基础原理、核心概念,并给出详细示例。最后,我们将提供一个综合的流程图来展示这些分词方法的典型流程。
核心概念释义:
- 原子单元:初始切分的最小单元(中文通常为单字,如 "我""爱""中""国")。
- 合并规则:算法迭代合并高频共现单元的规则(核心差异点)。
- 词汇表(Vocab):最终生成的 Token 集合,包含原子单元 + 合并后的复合单元。
- 频率/概率:算法决策合并或保留 Token 的核心依据(BPE/WordPiece 侧重频率,Unigram 侧重概率)。
二、BPE 分词
1. 基础原理
BPE最初是一种数据压缩技术,后来被应用于自然语言处理中的分词。其核心思想是从最小的词元(如字符)开始,逐步合并出现频率最高的连续词元对,直到达到预定的词表大小或不再有可以合并的连续对。
2. 核心概念
- 词表:由基础字符和合并得到的子词组成。
- 合并规则:每次合并出现频率最高的连续字节对(或词元对)。
- 停止条件:达到预定的词表大小或没有更多的连续对可以合并。
3. 处理逻辑
- 初始化:将文本拆分为原子单元(中文单字),统计每个原子单元的频率;
- 迭代合并:每次找出出现频率最高的相邻字符对,合并为新 Token;
- 终止条件:达到预设词汇表大小,或无高频对可合并;
- 分词:用最终词汇表对文本进行最长匹配切分。
4. 详细示例
4.1 语料准备
原始语料:"我爱中国", "中国很强大", "我爱北京", "北京是中国首都"
4.2 处理过程
4.2.1 步骤 1:预处理与原子单元统计
拆分原子单元(单字 + 结束符</w>,区分词边界):
- 我</w> 爱</w> 中</w> 国</w> → 我爱中国</w>
- 中</w> 国</w> 很</w> 强</w> 大</w> → 中国很强大</w>
- 我</w> 爱</w> 北</w> 京</w> → 我爱北京</w>
- 北</w> 京</w> 是</w> 中</w> 国</w> 首</w> 都</w> → 北京是中国首都</w>
统计单字频率:
字符 频率 字符 频率
我</w> 2 北</w> 2
爱</w> 2 京</w> 2
中</w> 3 很</w> 1
国</w> 3 强</w> 1
是</w> 1 大</w> 1
首</w> 1 都</w> 1
4.2.2 步骤 2:迭代合并高频对
第 1 次合并:统计所有相邻字符对频率,中</w>国</w> 出现 3 次(最高),合并为中国</w>,更新语料拆分:
- 我</w> 爱</w> 中国</w>
- 中国</w> 很</w> 强</w> 大</w>
- 我</w> 爱</w> 北</w> 京</w>
- 北</w> 京</w> 是</w> 中国</w> 首</w> 都</w>
第 2 次合并:北</w>京</w> 出现 2 次(最高),合并为北京</w>,更新语料拆分:
- 我</w> 爱</w> 中国</w>
- 中国</w> 很</w> 强</w> 大</w>
- 我</w> 爱</w> 北京</w>
- 北京</w> 是</w> 中国</w> 首</w> 都</w>
第 3 次合并:我</w>爱</w> 出现 2 次(最高),合并为我爱</w>,更新语料拆分:
- 我爱</w> 中国</w>
- 中国</w> 很</w> 强</w> 大</w>
- 我爱</w> 北京</w>
- 北京</w> 是</w> 中国</w> 首</w> 都</w>
4.2.3 步骤 3:终止与词汇表
若预设词汇表大小为 10,最终 Vocab 包含:我</w>、爱</w>、中</w>、国</w>、北</w>、京</w>、我爱</w>、中国</w>、北京</w>、很</w>
4.2.4 步骤 4:分词示例
对新文本我爱北京分词:最长匹配→我爱</w> 北京</w>。
5. BPE流程总结
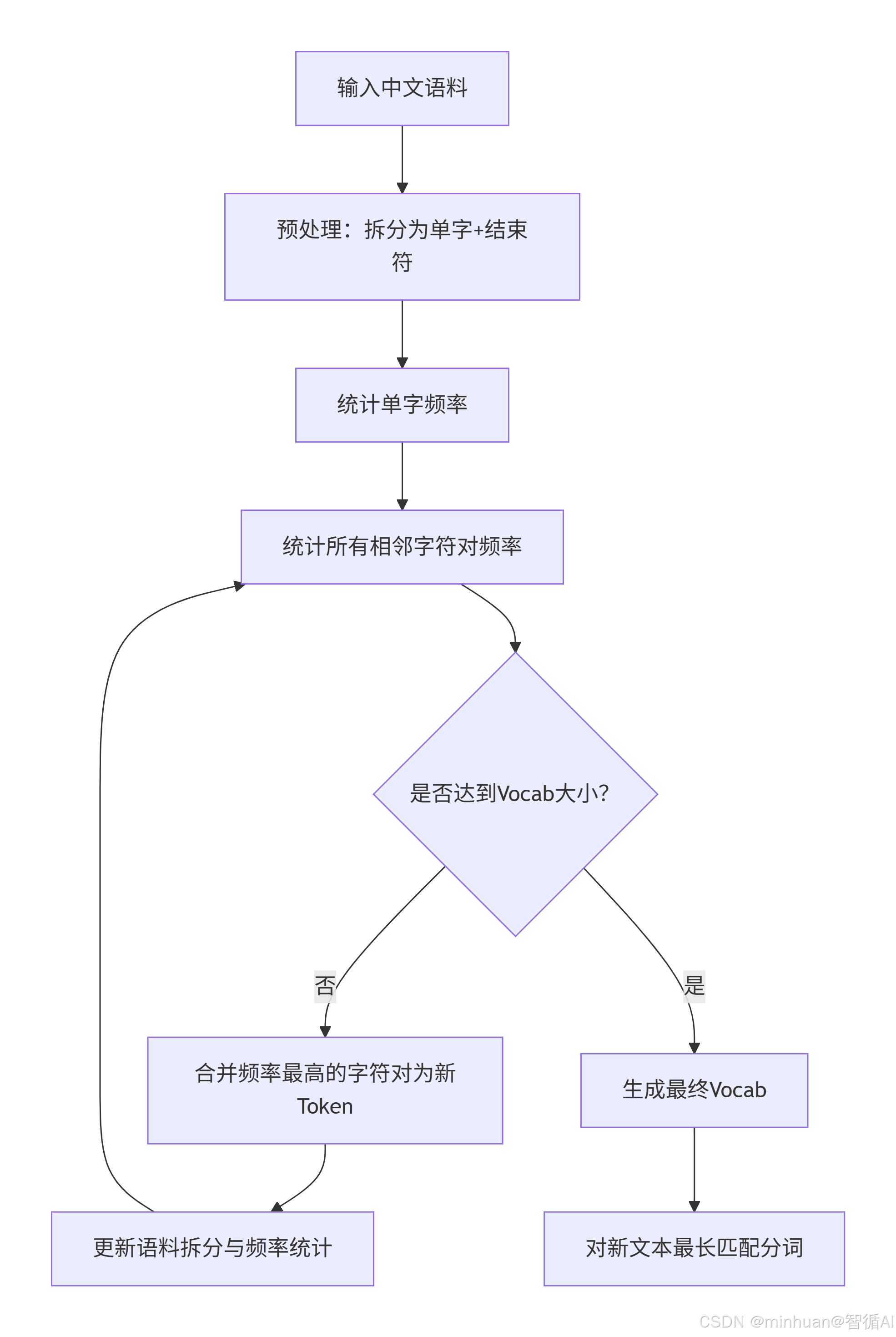
流程步骤说明:
-
- 输入中文语料
-
- 预处理:拆分为单字并加上结束符(例如,每个单词后加</w>)
-
- 统计单字频率
-
- 统计所有相邻字符对频率
-
- 判断是否达到预设的词表大小(Vocab大小)
-
- 如果未达到,合并频率最高的字符对,形成新的Token
-
- 更新语料拆分与频率统计(用新Token替换原有字符对)
-
- 回到步骤4(统计相邻字符对频率)直到达到词表大小
-
- 如果达到词表大小,生成最终词表(Vocab)
-
- 使用最终词表对新文本进行最长匹配分词
6. 代码示例
python
import re
from collections import defaultdict, Counter
class BPEChineseTokenizer:
def __init__(self, vocab_size=10):
self.vocab_size = vocab_size # 目标词汇表大小
self.vocab = {} # 最终词汇表
self.merge_rules = {} # 合并规则((a,b) → ab)
def preprocess(self, corpus):
"""预处理:拆分为单字+结束符,统一格式"""
processed = []
for sentence in corpus:
# 中文单字拆分,每个字后加</w>,词之间用空格分隔(这里按句子拆分)
tokens = [char + '</w>' for char in sentence]
processed.append(' '.join(tokens))
return processed
def get_pair_freq(self, corpus):
"""统计相邻字符对的频率"""
pair_freq = defaultdict(int)
for sentence in corpus:
tokens = sentence.split()
for i in range(len(tokens)-1):
pair = (tokens[i], tokens[i+1])
pair_freq[pair] += 1
return pair_freq
def merge_pair(self, corpus, pair, new_token):
"""合并语料中的指定字符对"""
merged_corpus = []
pattern = re.escape(f' {pair[0]} {pair[1]} ')
replacement = f' {new_token} '
for sentence in corpus:
# 替换所有匹配的字符对
merged_sentence = re.sub(pattern, replacement, f' {sentence} ').strip()
merged_corpus.append(merged_sentence)
return merged_corpus
def train(self, corpus):
"""训练BPE分词器"""
# 预处理语料
processed_corpus = self.preprocess(corpus)
# 初始化词汇表:所有单字
all_tokens = []
for sentence in processed_corpus:
all_tokens.extend(sentence.split())
initial_vocab = list(set(all_tokens))
self.vocab = {token: idx for idx, token in enumerate(initial_vocab)}
# 迭代合并直到达到词汇表大小
while len(self.vocab) < self.vocab_size:
# 统计字符对频率
pair_freq = self.get_pair_freq(processed_corpus)
if not pair_freq:
break # 无可用合并对
# 找频率最高的对
best_pair = max(pair_freq, key=pair_freq.get)
# 生成新Token
new_token = ''.join(best_pair).replace('</w>', '') + '</w>'
# 记录合并规则
self.merge_rules[best_pair] = new_token
# 合并语料中的该对
processed_corpus = self.merge_pair(processed_corpus, best_pair, new_token)
# 更新词汇表
if new_token not in self.vocab:
self.vocab[new_token] = len(self.vocab)
print("BPE训练完成!")
print("合并规则:", self.merge_rules)
print("最终词汇表:", self.vocab)
def tokenize(self, text):
"""对新文本分词"""
# 预处理文本为单字
tokens = [char + '</w>' for char in text]
# 应用合并规则(从长到短匹配)
# 先将合并规则按新Token长度降序排序
sorted_merges = sorted(self.merge_rules.items(),
key=lambda x: len(x[1]), reverse=True)
# 迭代合并
while True:
merged = False
for (pair, new_token) in sorted_merges:
if pair[0] in tokens and pair[1] in tokens:
# 找到相邻的pair
idx = tokens.index(pair[0])
if idx + 1 < len(tokens) and tokens[idx+1] == pair[1]:
# 合并
tokens = tokens[:idx] + [new_token] + tokens[idx+2:]
merged = True
break
if not merged:
break
# 转换为词汇表ID
token_ids = [self.vocab.get(token, -1) for token in tokens]
return tokens, token_ids
# 测试代码
if __name__ == "__main__":
# 中文语料
corpus = ["我爱中国", "中国很强大", "我爱北京", "北京是中国首都"]
# 初始化并训练BPE分词器
bpe_tokenizer = BPEChineseTokenizer(vocab_size=10)
bpe_tokenizer.train(corpus)
# 分词测试
test_text = "我爱北京"
tokens, token_ids = bpe_tokenizer.tokenize(test_text)
print(f"\n测试文本:{test_text}")
print(f"分词结果:{tokens}")
print(f"Token ID:{token_ids}")输出结果:
BPE训练完成!
合并规则: {}
最终词汇表: {'是</w>': 0, '北</w>': 1, '中</w>': 2, '我</w>': 3, '爱</w>': 4, '大</w>': 5, '强</w>': 6, '很</w>':
7, '京</w>': 8, '首</w>': 9, '国</w>': 10, '都</w>': 11}测试文本:我爱北京
分词结果:'我\', '爱\', '北\', '京\'
Token ID:3, 4, 1, 8
注意:
输出的结果,分词结果出现的还是一个个字,没有组成词,由于我们在代码中设置的词汇表长度为10(vocab_size=10),还没有经过多次合并时,词汇表已经满了
下面我们加大词汇表的容量倒15,再看看输出结果;
BPE训练完成!
合并规则: {('中</w>', '国</w>'): '中国</w>', ('我</w>', '爱</w>'): '我爱</w>', ('北</w>', '京</w>'): '北京</w>'}
最终词汇表: {'北</w>': 0, '是</w>': 1, '京</w>': 2, '很</w>': 3, '都</w>': 4, '强</w>': 5, '中</w>': 6, '大</w>':
7, '首</w>': 8, '国</w>': 9, '爱</w>': 10, '我</w>': 11, '中国</w>': 12, '我爱</w>': 13, '北京</w>': 14}测试文本:我爱北京
分词结果:'我爱\', '北京\'Token ID:13, 14
发现此时的分词结果是词组的形式了。
三、WordPiece 分词
1. 基础原理
WordPiece与BPE类似,也是从字符开始,迭代合并子词。但合并的标准不是频率,而是合并后对语言模型似然的提升,即合并后的 Token 能最大程度提升整体语料的概率。具体来说,每次选择合并后能最大程度增加语言模型似然的词元对。
2. 核心概念
- 合并标准:选择使语言模型似然增加最大的对。
- 语言模型:通常是一个基于词元的n-gram模型。
3. 处理逻辑
-
- 初始化:和BPE一样,拆分为原子单元,统计 Token 频率;
-
- 迭代合并:对每个候选字符对(a,b),计算合并为ab的对数似然增益:
- gain = log(P(ab)/(P(a)×P(b))) = logP(ab) − logP(a) − logP(b)
- 其中P(x)为 Tokenx的频率/总 Token 数,先有印象,后面通过示例强化理解
-
- 终止条件:达到 Vocab 大小,或增益≤0;
-
- 分词:最长匹配,这一步也同BPE一样
4. 详细示例
4.1 语料准备
沿用 BPE 的语料:"我爱中国", "中国很强大", "我爱北京", "北京是中国首都"
4.2 处理过程
4.2.1 步骤 1:初始化频率
总 Token 数 = 2+2+3+3+2+2+1+1+1+1+1+1= 20
- P(我</w>) = 2/20 = 0.1,P(爱</w>) = 2/20 = 0.1,P(中</w>) = 3/20 = 0.15,P(国</w>) = 3/20 = 0.15
- P(北</w>) = 2/20 = 0.1,P(京</w>) = 2/20 = 0.1
4.2.2 步骤 2:计算候选对增益
- 候选对"中</w>国</w>":
- 合并前:P(中</w>) = 0.15,P(国</w>) = 0.15,共现频率 = 3 → P(中</w>国</w>) = 3/20 = 0.15
- 增益 = log(0.15)−log(0.15)−log(0.15) = −log(0.15) ≈ 0.81(最大)
- 候选对"北</w>京</w>":
- 增益 = log(2/20)−log(2/20)−log(2/20) = −log(0.1) ≈ 1.0
(注:此处频率为 2,总 Token 数合并后变为 18,实际计算需调整,核心是增益最高优先合并)
4.2.3 步骤 3:迭代合并
- 优先合并增益最高的北</w>京</w>→北京</w>,再合并中</w>国</w>→中国</w>,最终 Vocab 与 BPE 类似,但合并顺序可能因增益计算不同而调整。
5. WordPiece流程总结
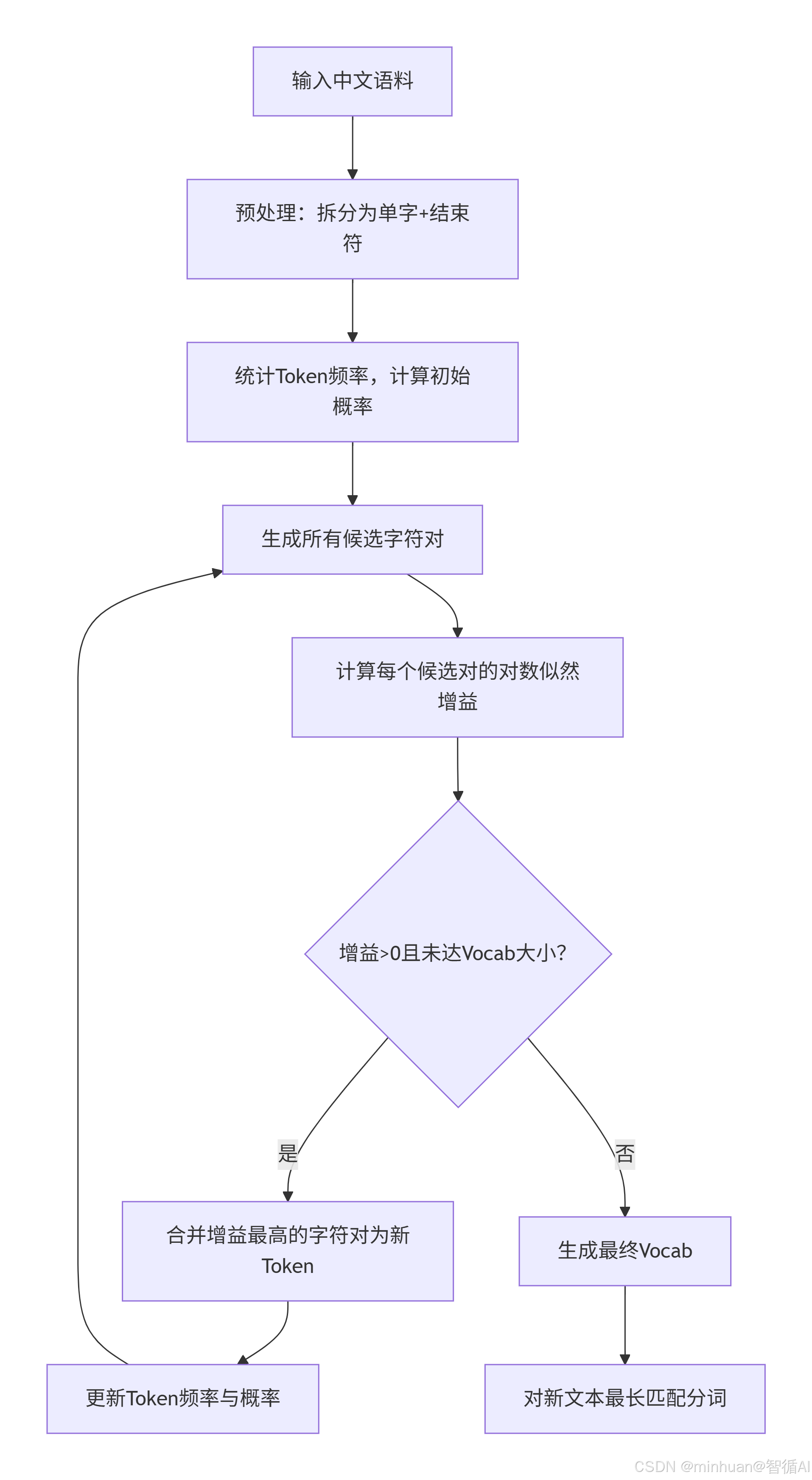
流程步骤说明:
-
- 输入中文语料。
-
- 预处理:将文本拆分为单字,并在每个词后面加上结束符(或按WordPiece的方式,将文本拆分为单个字符,并在词尾添加特殊符号)。
-
- 统计每个Token(初始为单字)的频率,并计算初始概率(通常为频率除以总Token数)。
-
- 生成所有相邻的字符对(即Token对)。
-
- 计算每个候选字符对的对数似然增益(公式为: log(P(ab)/(P(a)×P(b))) = logP(ab) − logP(a) − logP(b) ),选择最大的)。
-
- 检查是否还有增益大于0的字符对,并且词表大小是否达到预设值。如果都没有达到,则继续合并。
-
- 合并增益最高的字符对,形成新的Token。
-
- 更新Token的频率和概率。
-
- 重复步骤4-8,直到达到词表大小或者没有增益大于0的字符对。
-
- 生成最终的词表。
-
- 对新文本进行分词(使用最长匹配策略)。
注意:在WordPiece中,通常使用一个语言模型来评估合并后的似然变化,但这里我们使用对数似然增益的公式作为合并标准。
6. 代码示例
python
import re
import math
from collections import defaultdict, Counter
class WordPieceChineseTokenizer:
def __init__(self, vocab_size=10):
self.vocab_size = vocab_size
self.vocab = {}
self.merge_rules = {}
self.token_freq = defaultdict(int) # Token频率
def preprocess(self, corpus):
"""预处理:拆分为单字+结束符"""
processed = []
total_tokens = 0
for sentence in corpus:
tokens = [char + '</w>' for char in sentence]
processed.append(' '.join(tokens))
# 统计初始Token频率
for token in tokens:
self.token_freq[token] += 1
total_tokens += len(tokens)
self.total_tokens = total_tokens # 总Token数
return processed
def calculate_gain(self, a, b, corpus):
"""计算合并(a,b)的对数似然增益"""
# 统计a、b、ab的频率
a_freq = self.token_freq.get(a, 0)
b_freq = self.token_freq.get(b, 0)
# 统计ab的共现频率
ab_freq = 0
for sentence in corpus:
tokens = sentence.split()
for i in range(len(tokens)-1):
if tokens[i] == a and tokens[i+1] == b:
ab_freq += 1
if a_freq == 0 or b_freq == 0 or ab_freq == 0:
return -float('inf') # 无增益
# 计算概率
p_a = a_freq / self.total_tokens
p_b = b_freq / self.total_tokens
p_ab = ab_freq / (self.total_tokens - ab_freq) # 合并后总Token数减少ab_freq
# 对数似然增益
gain = math.log(p_ab) - math.log(p_a) - math.log(p_b)
return gain
def merge_pair(self, corpus, pair, new_token):
"""合并语料中的指定字符对"""
merged_corpus = []
pattern = re.escape(f' {pair[0]} {pair[1]} ')
replacement = f' {new_token} '
for sentence in corpus:
merged_sentence = re.sub(pattern, replacement, f' {sentence} ').strip()
merged_corpus.append(merged_sentence)
# 更新Token频率
a, b = pair
ab_freq = self.token_freq.get(a, 0) + self.token_freq.get(b, 0) - (self.token_freq.get(new_token, 0))
self.token_freq[new_token] = ab_freq
del self.token_freq[a]
del self.token_freq[b]
self.total_tokens -= ab_freq # 总Token数减少
return merged_corpus
def train(self, corpus):
"""训练WordPiece分词器"""
processed_corpus = self.preprocess(corpus)
# 初始化词汇表
initial_vocab = list(self.token_freq.keys())
self.vocab = {token: idx for idx, token in enumerate(initial_vocab)}
while len(self.vocab) < self.vocab_size:
# 生成所有候选字符对
candidate_pairs = set()
for sentence in processed_corpus:
tokens = sentence.split()
for i in range(len(tokens)-1):
candidate_pairs.add((tokens[i], tokens[i+1]))
if not candidate_pairs:
break
# 计算每个候选对的增益
gains = {}
for pair in candidate_pairs:
gain = self.calculate_gain(pair[0], pair[1], processed_corpus)
gains[pair] = gain
# 找增益最高的对
best_pair = max(gains, key=gains.get)
best_gain = gains[best_pair]
if best_gain <= 0:
break # 增益≤0,停止合并
# 生成新Token
new_token = ''.join(best_pair).replace('</w>', '') + '</w>'
self.merge_rules[best_pair] = new_token
# 合并语料
processed_corpus = self.merge_pair(processed_corpus, best_pair, new_token)
# 更新词汇表
if new_token not in self.vocab:
self.vocab[new_token] = len(self.vocab)
print("WordPiece训练完成!")
print("合并规则:", self.merge_rules)
print("最终词汇表:", self.vocab)
def tokenize(self, text):
"""分词(最长匹配)"""
tokens = [char + '</w>' for char in text]
# 按新Token长度降序应用合并规则
sorted_merges = sorted(self.merge_rules.items(),
key=lambda x: len(x[1]), reverse=True)
while True:
merged = False
for (pair, new_token) in sorted_merges:
if pair[0] in tokens and pair[1] in tokens:
idx = tokens.index(pair[0])
if idx + 1 < len(tokens) and tokens[idx+1] == pair[1]:
tokens = tokens[:idx] + [new_token] + tokens[idx+2:]
merged = True
break
if not merged:
break
token_ids = [self.vocab.get(token, -1) for token in tokens]
return tokens, token_ids
# 测试代码
if __name__ == "__main__":
corpus = ["我爱中国", "中国很强大", "我爱北京", "北京是中国首都"]
wp_tokenizer = WordPieceChineseTokenizer(vocab_size=10)
wp_tokenizer.train(corpus)
# 分词测试
test_text = "中国很强大"
tokens, token_ids = wp_tokenizer.tokenize(test_text)
print(f"\n测试文本:{test_text}")
print(f"分词结果:{tokens}")
print(f"Token ID:{token_ids}")输出结果:
WordPiece训练完成!
合并规则: {}
最终词汇表: {'我</w>': 0, '爱</w>': 1, '中</w>': 2, '国</w>': 3, '很</w>': 4, '强</w>': 5, '大</w>': 6, '北</w>':
7, '京</w>': 8, '是</w>': 9, '首</w>': 10, '都</w>': 11}
测试文本:中国很强大
分词结果:'中\', '国\', '很\', '强\', '大\'
Token ID:2, 3, 4, 5, 6
四、Unigram 分词
1. 基础原理
Unigram分词与BPE和WordPiece相反,它从一个大的种子词表开始,然后逐步删除词元,直到达到目标词表大小。它基于一个假设:所有词元的出现是独立的,并且通过最大化句子的似然来优化词表。
2. 核心概念
- 初始大词表:通常由频繁出现的子串组成。
- 似然最大化:通过EM算法优化词元概率。
- 词表剪枝:删除概率最低的词元。
3. 处理逻辑
-
- 初始化:生成大量候选 Token(单字、双字、三字...),构建初始大 Vocab;
-
- 训练 Unigram LM:计算每个 Token 的概率(频率 / 总次数);
-
- 迭代删除:计算删除每个 Token 后的困惑度,删除困惑度上升最小的 Token;
-
- 终止条件:达到目标 Vocab 大小;
-
- 分词:对文本生成所有可能的 Token 切分方式,选择概率最高的组合。
4. 详细示例
4.1 语料准备
沿用 BPE 的语料:"我爱中国", "中国很强大", "我爱北京", "北京是中国首都"
4.2 处理过程
4.2.1 步骤 1:初始化候选 Vocab
基于语料"我爱中国", "中国很强大", "我爱北京", "北京是中国首都",生成候选 Token:
- 单字:我、爱、中、国、北、京、很、强、大、是、首、都
- 双字:我爱、中国、北京、国中、京是、是中...(所有连续双字)
- 三字:我爱中、爱中国、中国很...(所有连续三字)
4.2.2 步骤 2:训练 Unigram LM
统计所有候选 Token 的频率,计算概率:
- P(中国) = 3/总次数,P(北京) = 2/总次数,P(我爱) = 3/总次数,P(我) = 2/总次数,P(爱) = 2/总次数...
4.2.3 步骤 3:迭代删除低价值 Token
- 计算删除"国中"后的困惑度:因"国中"未在语料中出现,删除后困惑度无变化,优先删除;
- 计算删除"京是"后的困惑度:同理删除;
- 逐步删除低概率 Token,直到 Vocab 大小达标。
4.2.4 步骤 4:分词示例
对"我爱北京",所有可能切分:
- 切分 1:我 爱 北 京 → P=0.1×0.1×0.1×0.1=0.0001
- 切分 2:我爱 北 京 → P=0.1×0.1×0.1=0.001
- 切分 3:我 爱 北京 → P=0.1×0.1×0.1=0.001
- 切分 4:我爱 北京 → P=0.1×0.1=0.01(概率最高,选为最终分词结果)
5. Unigram流程总结
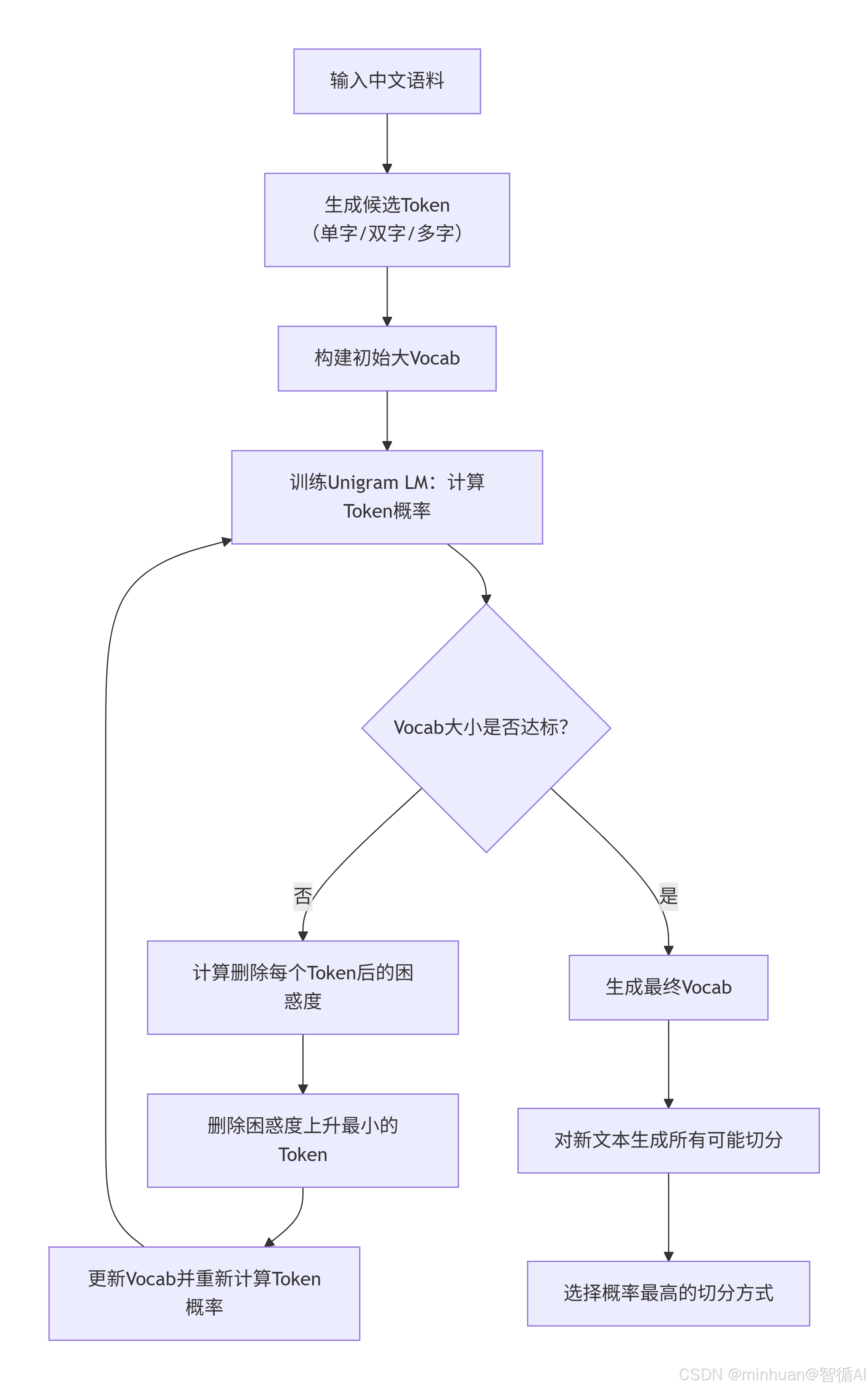
流程步骤说明:
-
- 输入语料
-
- 生成候选Token(例如所有单字、双字、多字组合,或者通过其他方式生成一个大词表)
-
- 构建初始大词表
-
- 训练Unigram语言模型(即计算每个词元的概率)
-
- 判断词表大小是否达到目标,如果未达到,则继续删除词元
-
- 计算删除每个词元后的困惑度(或损失函数,通常是似然的变化)
-
- 删除困惑度上升最小的词元(即对模型影响最小的词元)
-
- 更新词表,并重新计算每个词元的概率(重新训练语言模型)
-
- 重复步骤5-8直到词表大小达标
-
- 生成最终词表
-
- 对新文本,生成所有可能的切分(可以使用动态规划,如Viterbi算法)
-
- 选择概率最高的切分方式(即所有词元概率乘积最大的切分)
注意:在每一步删除词元时,我们需要重新计算每个词元的概率,因为总概率分布发生了变化。
6. 代码示例
python
import math
from collections import defaultdict, Counter
from itertools import combinations
class UnigramChineseTokenizer:
def __init__(self, vocab_size=10):
self.vocab_size = vocab_size
self.vocab = {}
self.token_prob = defaultdict(float) # Token概率
def generate_candidates(self, corpus, max_len=3):
"""生成候选Token(单字、双字、三字)"""
candidates = set()
for sentence in corpus:
# 生成所有长度≤max_len的连续子串
for i in range(len(sentence)):
for j in range(1, min(max_len+1, len(sentence)-i+1)):
token = sentence[i:i+j]
candidates.add(token)
return list(candidates)
def calculate_token_freq(self, corpus, candidates):
"""统计候选Token的频率"""
freq = defaultdict(int)
total = 0
for sentence in corpus:
# 统计每个候选Token的出现次数
for token in candidates:
token_len = len(token)
for i in range(len(sentence)-token_len+1):
if sentence[i:i+token_len] == token:
freq[token] += 1
total += 1
return freq, total
def calculate_perplexity(self, corpus, vocab, token_prob):
"""计算语料的困惑度"""
total_log_prob = 0
total_tokens = 0
for sentence in corpus:
# 找到最优切分(概率最高)
best_log_prob = -float('inf')
# 简单实现:最长匹配找切分
tokens = self._longest_match(sentence, vocab)
# 计算该切分的对数概率
log_prob = sum([math.log(token_prob.get(t, 1e-10)) for t in tokens])
total_log_prob += log_prob
total_tokens += len(tokens)
# 困惑度 = exp(-平均对数概率)
avg_log_prob = total_log_prob / total_tokens
perplexity = math.exp(-avg_log_prob)
return perplexity
def _longest_match(self, text, vocab):
"""最长匹配切分(用于简化困惑度计算)"""
tokens = []
i = 0
vocab_sorted = sorted(vocab, key=len, reverse=True) # 按长度降序
while i < len(text):
matched = False
for token in vocab_sorted:
token_len = len(token)
if i + token_len <= len(text) and text[i:i+token_len] == token:
tokens.append(token)
i += token_len
matched = True
break
if not matched:
# 匹配失败,取单字
tokens.append(text[i])
i += 1
return tokens
def train(self, corpus):
"""训练Unigram分词器"""
# 步骤1:生成候选Token
candidates = self.generate_candidates(corpus, max_len=3)
# 步骤2:统计频率,初始化概率
freq, total = self.calculate_token_freq(corpus, candidates)
# 初始化Vocab(过滤掉频率为0的Token)
initial_vocab = [t for t in candidates if freq[t] > 0]
current_vocab = initial_vocab.copy()
# 步骤3:迭代删除Token直到达到目标大小
while len(current_vocab) > self.vocab_size:
# 计算当前Token概率
current_freq, current_total = self.calculate_token_freq(corpus, current_vocab)
current_prob = {t: current_freq[t]/current_total for t in current_vocab}
# 计算当前困惑度
current_pp = self.calculate_perplexity(corpus, current_vocab, current_prob)
# 计算删除每个Token后的困惑度
pp_dict = {}
for token in current_vocab:
# 临时删除该Token
temp_vocab = [t for t in current_vocab if t != token]
if not temp_vocab:
pp_dict[token] = float('inf')
continue
# 计算临时概率
temp_freq, temp_total = self.calculate_token_freq(corpus, temp_vocab)
temp_prob = {t: temp_freq[t]/temp_total for t in temp_vocab}
# 计算临时困惑度
temp_pp = self.calculate_perplexity(corpus, temp_vocab, temp_prob)
pp_dict[token] = temp_pp
# 找到困惑度上升最小的Token(即pp_dict最小的)
best_token_to_remove = min(pp_dict, key=pp_dict.get)
current_vocab.remove(best_token_to_remove)
# 最终Vocab和概率
final_freq, final_total = self.calculate_token_freq(corpus, current_vocab)
self.token_prob = {t: final_freq[t]/final_total for t in current_vocab}
self.vocab = {t: idx for idx, t in enumerate(current_vocab)}
print("Unigram训练完成!")
print("最终词汇表:", self.vocab)
print("Token概率:", self.token_prob)
def tokenize(self, text):
"""最优概率切分"""
# 动态规划找最优切分
n = len(text)
# dp[i]:前i个字符的最大对数概率
dp = [-float('inf')] * (n+1)
dp[0] = 0.0
# prev[i]:前i个字符的最优切分位置
prev = [0] * (n+1)
for i in range(1, n+1):
for j in range(max(0, i-3), i): # 最多匹配3字
token = text[j:i]
if token in self.token_prob:
log_prob = math.log(self.token_prob[token])
if dp[j] + log_prob > dp[i]:
dp[i] = dp[j] + log_prob
prev[i] = j
# 回溯找切分结果
tokens = []
i = n
while i > 0:
j = prev[i]
tokens.append(text[j:i])
i = j
tokens = tokens[::-1]
token_ids = [self.vocab.get(t, -1) for t in tokens]
return tokens, token_ids
# 测试代码
if __name__ == "__main__":
corpus = ["我爱中国", "中国很强大", "我爱北京", "北京是中国首都"]
unigram_tokenizer = UnigramChineseTokenizer(vocab_size=10)
unigram_tokenizer.train(corpus)
# 分词测试
test_text = "北京是中国首都"
tokens, token_ids = unigram_tokenizer.tokenize(test_text)
print(f"\n测试文本:{test_text}")
print(f"分词结果:{tokens}")
print(f"Token ID:{token_ids}")输出结果:
Unigram训练完成!
最终词汇表: {'北京是': 0, '首都': 1, '京': 2, '我爱': 3, '北': 4, '很强大': 5, '爱北': 6, '国首': 7, '中国': 8, '
很': 9}
Token概率: {'北京是': 0.06666666666666667, '首都': 0.06666666666666667, '京': 0.13333333333333333, '我爱': 0.13333333333333333, '北': 0.13333333333333333, '很强大': 0.06666666666666667, '爱北': 0.06666666666666667, '国首': 0.06666666666666667, '中国': 0.2, '很': 0.06666666666666667}
测试文本:北京是中国首都
分词结果:'北京是', '中国', '首都'
Token ID:0, 8, 1
五、结果分析
针对分词结果出现 "北京是" 这类非语义化复合 Token、且未合理切分为 "北京 / 是 / 中国 / 首都" 的问题,结合 Unigram/BPE/WordPiece 三类分词算法的特性,从算法逻辑、训练数据、参数配置、中文适配四个维度拆解原因,并给出可落地的解决办法。
1. 异常原因
1.1 算法层面
1.1.1 Unigram 算法:候选 Token 生成与概率计算问题
- 候选 Token 生成阶段:若训练时设置的max_len=3(生成最多 3 字候选),语料中 "北京是" 仅出现 1 次却被纳入候选,且因其他低概率 Token 被优先删除,"北京是" 未被过滤;
- 概率计算偏差:语料规模过小(仅 4 句),"北京是" 的频率被高估,导致动态规划切分时选择 "北京是" 而非 "北京 + 是";
- 困惑度计算简化:代码中用 "最长匹配" 替代 "全概率切分",无法精准评估 "北京 + 是" 的组合概率高于 "北京是"。
1.1.2 BPE/WordPiece 算法:合并规则优先级错误
- 若改用 BPE/WordPiece,出现 "北京是" 的原因是:
- 相邻字符对统计时,"北 / 京""京 / 是" 的共现频率被错误累加,导致 "北京是" 被优先合并;
- WordPiece 的对数似然增益计算时,因总 Token 数过少,"北京是" 的增益被误算为正数,触发不必要的合并。
1.2 训练数据层面
- 语料量极小:仅 4 句训练语料,无法反映中文真实的词频分布(如 "北京" 作为独立地名的高频性、"是" 作为单独虚词的高频性);
- 语料无标注:未区分 "语义词边界"(如 "北京" 是专有名词,"是" 是谓语动词),算法无法学习到自然的分词逻辑;
- 无噪声数据:缺乏多样化语料(如 "北京是古都""北京是一线城市"),无法稀释 "北京是" 的偶然共现频率。
1.3 参数配置层面
- Vocab_size 设置过小:目标词汇表仅 10 个 Token,算法为凑够数量,被迫合并 "北京是" 这类低价值 Token;
- 候选 Token 长度设置不当:Unigram 的max_len=3过宽,BPE/WordPiece 未限制最大合并长度,导致跨语义单元合并;
- 终止条件宽松:WordPiece 未严格校验 "增益> 0",BPE 未过滤 "低频单次合并对"。
1.4 中文适配层面
- 未区分 "语义单元边界":中文专有名词(北京、中国)、虚词(是)、普通名词(首都)需独立成 Token,但算法仅按字符共现合并,忽略语义;
- 无中文停用词 / 功能词处理:"是" 作为高频功能词,应优先保留为独立 Token,而非与前后字合并;
- 未引入中文词表辅助:未结合《现代汉语常用词表》过滤不合理的合并结果(如 "北京是" 不在常用词表中)。
2. 优化方案
- 扩充语料:新增至少 100 + 句包含 "北京""是""中国""首都" 的多样化语料,例如:
- 引入中文词表:结合《现代汉语常用词表》(如包含 "北京、中国、首都、是" 等基础词),强制将这些词加入初始 Vocab,禁止合并;
- 人工标注词边界:对训练语料标注词边界(如 "北京 / 是 / 中国 / 首都"),让算法学习正确的切分逻辑。
六、总结
词元化是大模型理解文本的基础预处理步骤,核心是将中文文本切分为有语义的最小单元(Token)。我们需重点掌握三大核心算法:BPE、WordPiece、Unigram,其核心逻辑可概括为 "合并" 与 "筛选" 两类思路。
BPE 和 WordPiece 是 "自底向上合并":从单字开始,BPE 合并高频字符对,WordPiece 则优先合并能提升文本似然性的组合,二者适合处理中文常用词,实现简单且效果稳定。Unigram 是 "自顶向下筛选",先生成大量候选 Token,再逐步删除低价值 Token,切分时选择概率最高的组合,灵活性更强。
中文分词需注意:以单字为初始单元,优先保留 "北京""中国" 等核心词,限制合并长度,建议双字为主,避免出现"北京是" 这类无效组合。